对 Kubeflow 上的机器学习工作负载做基准测试
分享
点赞
3
收藏
0
下载 3
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
基准测试是机器学习研究和产品化的重要部分,其从模型和系统的角度提供有用的性能信息。尽管 Kubernetes 和 Kubeflow 为我们提供了让 ML 工作量运行的重要平台,他们并没有自动的提供执行基准任务的直接方式,特别是针对基于分布式任务的复杂 ML 工作量。在本次演讲中我们介绍基于 Kubeflow 的开源基准化工具 Kubebench,其帮助我们通过自动化和一致的规范,更好的理解 Kubernetes 上的 ML 工作量的性能特征。我们还说明我们可以怎样利用来自学术界和工业界的其他基准化成就,如 MLPerf 和 Dawnbench。
展开查看详情
1 .Kubebench:
Benchmarking ML Workloads on Kubernetes
Xinyuan Huang (Cisco) Ce Gao (Caicloud)
�
2 .Why Kubebench?
• Understanding system performance is essential for moving ML from
lab to production.
• Benchmarking and analyzing ML workloads on Kubernetes is not an
easy job today.
• Many requirements for a good benchmark: compliance, consistency,
reproducibility, …
�
3 .What is Kubebench?
Kubebench is a harness for benchmarking and analyzing
Machine Learning workloads on Kubernetes.
�
4 .Goals of Kubebench
• Support benchmarking in various scenarios
• Multi-cloud and various infrastructure
• Different ML frameworks
• Distributed workloads
• …
• Make it easier to manage benchmarks
• Consistent workloads
• Reproducible results
• Integrable with the rest of ML lifecycle
• …
�
5 .Tech Stack
Kubebench
Benchmark config/result management; Benchmark workflow deployment
ML job deployment / lifecycle management
Production grade container orchestration
Infrastructure
Cloud/On-premise infrastructure environment
�
6 . Kubebench-provided
Architecture User-defined
API Dashboard
Interface
Manage Read
Configurator Pre-process Job
Metrics Visualization
(Grafana)
Main Kubeflow Job
Job Deployer/Manager (TFJob/PyTorchJob/etc.)
Deploy Monitor
Monitoring Service
Reporter Post-process Job (Prometheus)
Workflow (Argo) Workload Monitoring
Read/Write Read/Write
Configs Data Experiment Records
Storage
�
7 .User’s Perspective
Job Developer Experiment Runner
Job
Pre-job pod Main job pods Post-job pod template
(.ksonnet)
Kubebench Benchmark
workflow results
Job
params
(.yaml)
Shared storage (auto mounted)
Kubebench workflow
�
8 .Where we are
Initial release (v0.3): Upcoming and Future releases:
• Support local/distributed training workloads • UI/UX
• Support multiple frameworks • Dashboard
• TFJob • Results/metrics visualizations
• PyTorchJob • API
• (more planned) • Kubebench CRD
• Support result aggregation for multi-experiments • More benchmarking scenarios
• Stored in filesystem • Serving/inference benchmarks
• (Remote/Cloud DB planned) • Mixed/scaled workloads
• Quick starter package • …
• E2E example for quick start
• Example workloads (TF-CNN)
�
9 .Demo
Kirill Prosvirov, Andrey Velichkevich
�
11 . Local Training Benchmark
TensorFlow CNN Benchmark
Dataset: imagenet (synthetic)
Mode: forward-only
SingleSess: False
Num batches: 100
Num epochs: 0.00
Data format: NCHW
Optimizer: sgd
Variables: parameter_server
Training performance among different GPU numbers, batch sizes, and platforms
�
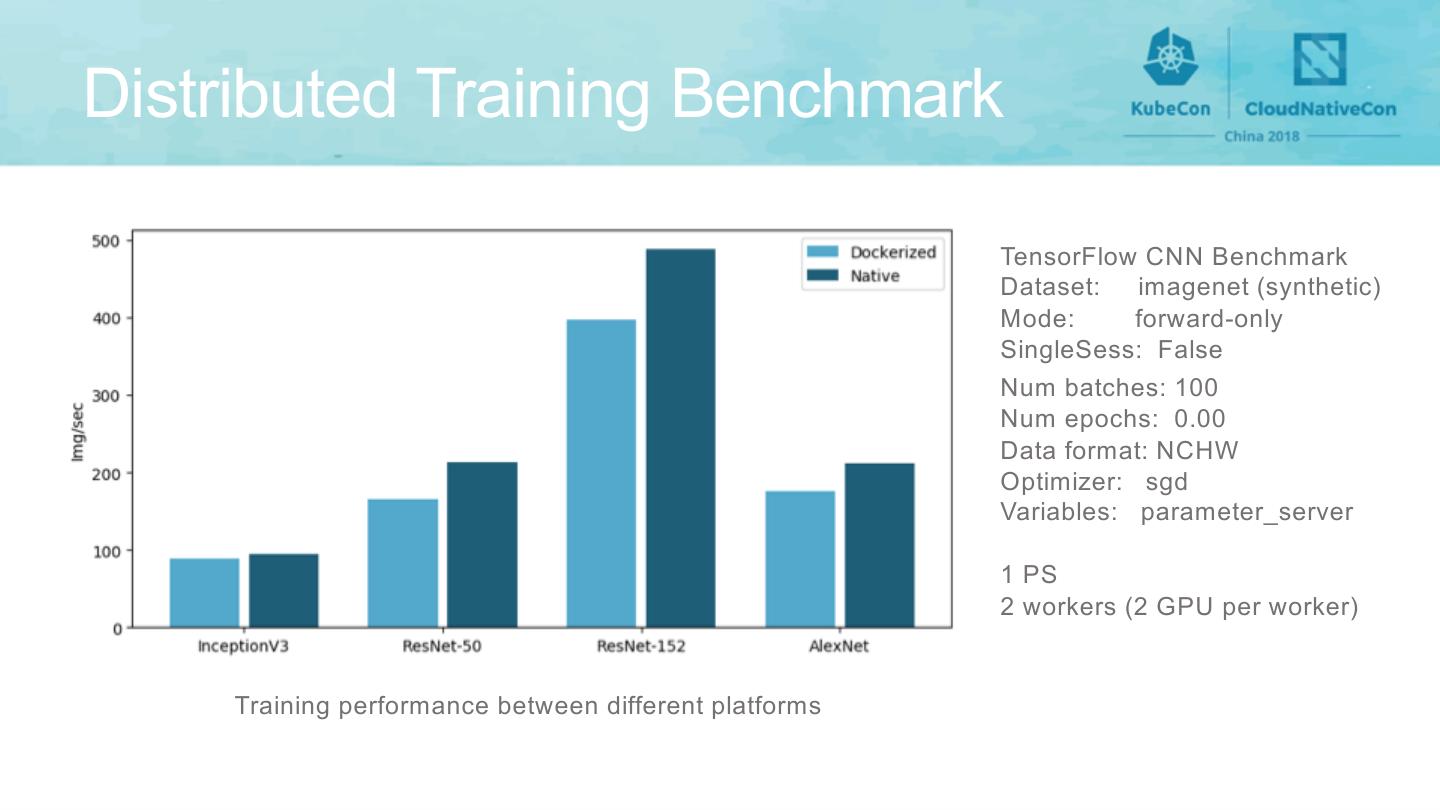
12 .Distributed Training Benchmark
TensorFlow CNN Benchmark
Dataset: imagenet (synthetic)
Mode: forward-only
SingleSess: False
Num batches: 100
Num epochs: 0.00
Data format: NCHW
Optimizer: sgd
Variables: parameter_server
1 PS
2 workers (2 GPU per worker)
Training performance between different platforms
�
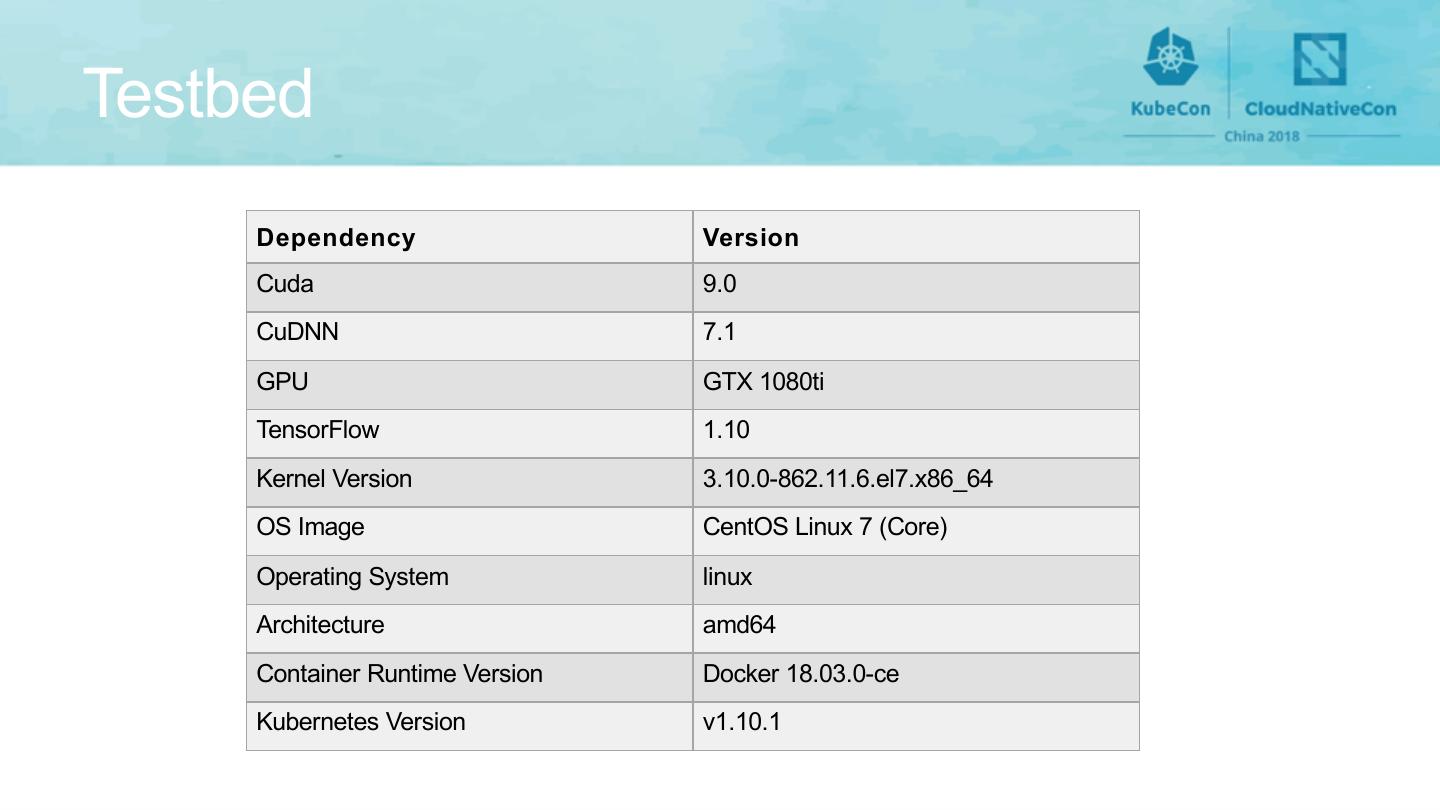
13 .Testbed
Dependency Version
Cuda 9.0
CuDNN 7.1
GPU GTX 1080ti
TensorFlow 1.10
Kernel Version 3.10.0-862.11.6.el7.x86_64
OS Image CentOS Linux 7 (Core)
Operating System linux
Architecture amd64
Container Runtime Version Docker 18.03.0-ce
Kubernetes Version v1.10.1
�
14 . Contributors & Advisors
(alphabetical order)
Adhita Selvaraj
Amit Kumar Saha
Andrey Velichkevich
Ce Gao
David Aronchick
Thanks! Debo Dutta
Jeremy Lewi
Johnu George
Kirill Prosvirov
Ramdoot Kumar Pydipaty
Xinyuan Huang
…
�