云原生世界中的当代数据科学
分享
点赞
3
收藏
0
下载 0
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
我们现今生活的 2018 年,大数据的思想持续膨胀。然而,大多数人正使用的工具及其数据要求大量的经验来理解和衡量。我们同时面临着一个时代,有必要为更好的理解以及对 GDPR 的服从而追踪数据流。
我将漫游于如何利用 Kubernetes 等云原生技术以及开源项目 Pachyderm 来创建易于开发、测试、部署和衡量的数据科学流水线。我还将提及如何在整个过程中使用数据版本控制来跟踪数据变更和正确理解您的数据是如何变化的。
讨论概要:
1.介绍数据流水线和版本控制的基本概念。
2.创建并测试简易模型。
4.将其按比例放大到生产规模的工作量并自动将变更部署于流水线中。
展开查看详情
1 .Introduction to
Modern Data Science
Sam Kreter
�
2 .Code and Slides
github.com/samkreter/KubeconAsia2018
�
3 . The Process
Business Need /
Problem Discovery
�
4 . The Process
Business Need /
Problem Discovery
Development
�
5 . The Process
Business Need /
Problem Discovery
Development
Production /
Actual User Impact
�
6 . The Process
Business Need /
Problem Discovery
Development
Production /
Actual User Impact
�
8 . The Process
Business Need /
Problem Discovery
Development
Production /
Actual User Impact
�
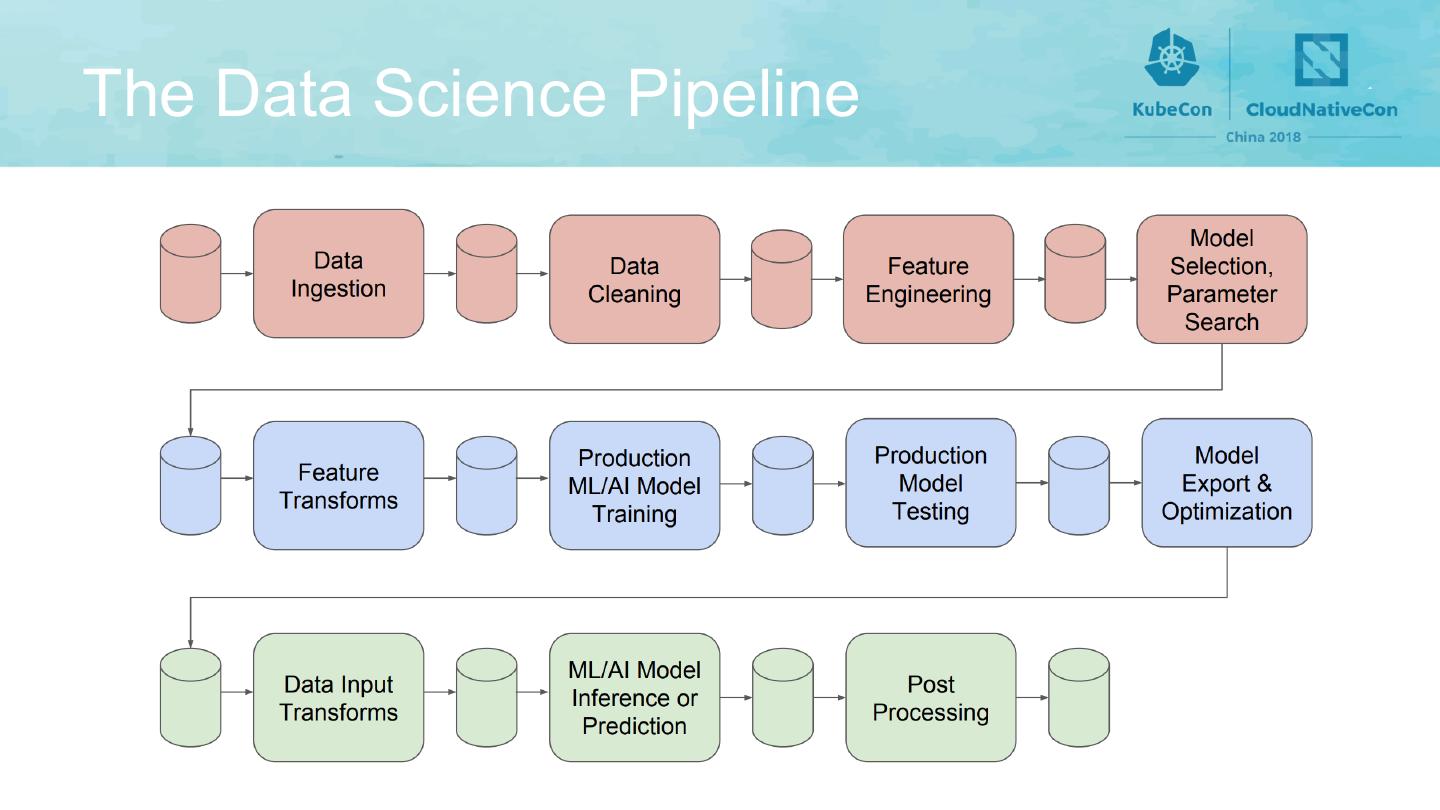
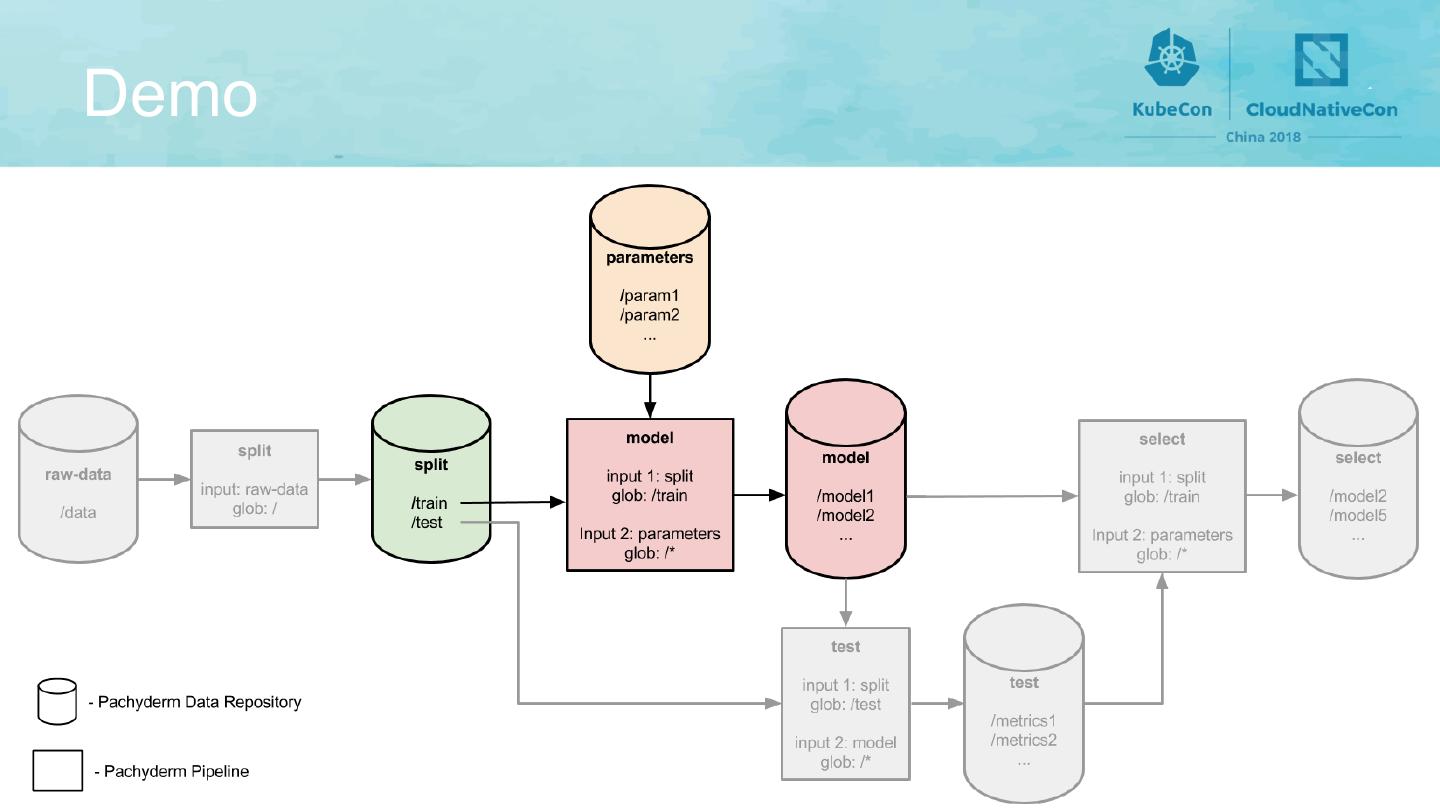
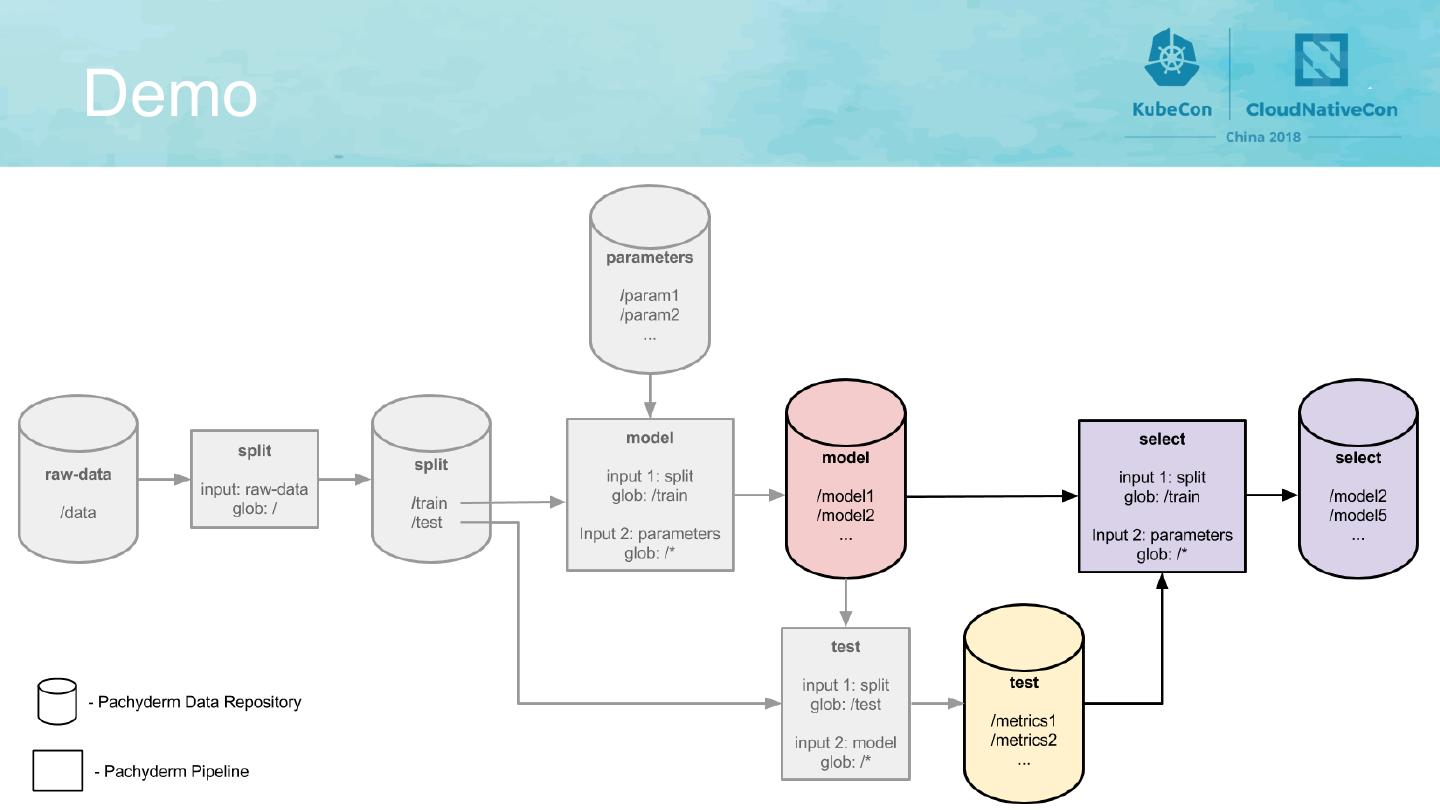
9 .The Data Science Pipeline
�
15 .The Data Science Pipeline
�
18 .I HAVE A VERY PARTICULAR SET OF SKILLS
�
23 .Containerization
1. Single Operations per Container
�
24 .Containerization
1. Single Operations per Container
2. Use Parameterize Data Flow
• Data Inputs
• Data Outputs
�
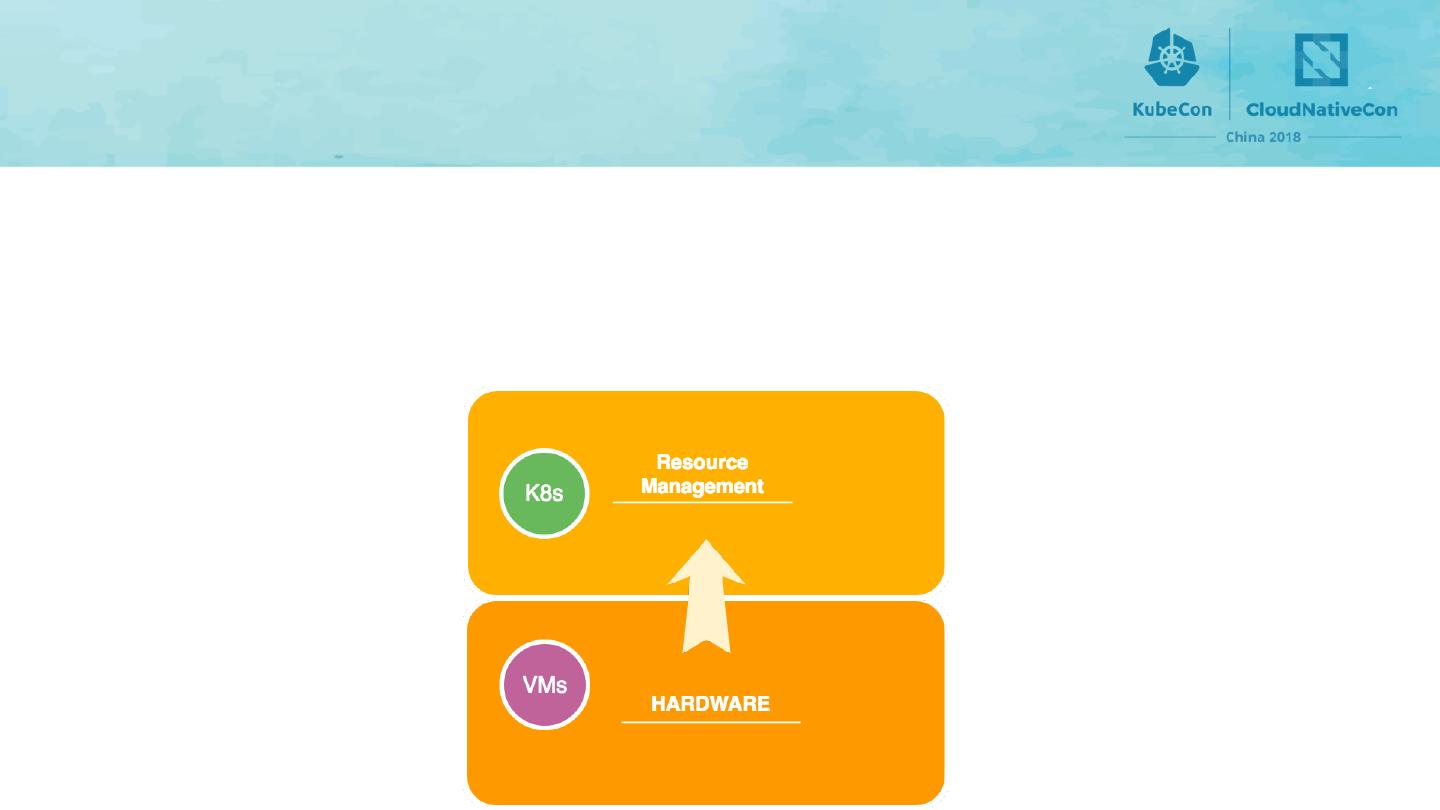
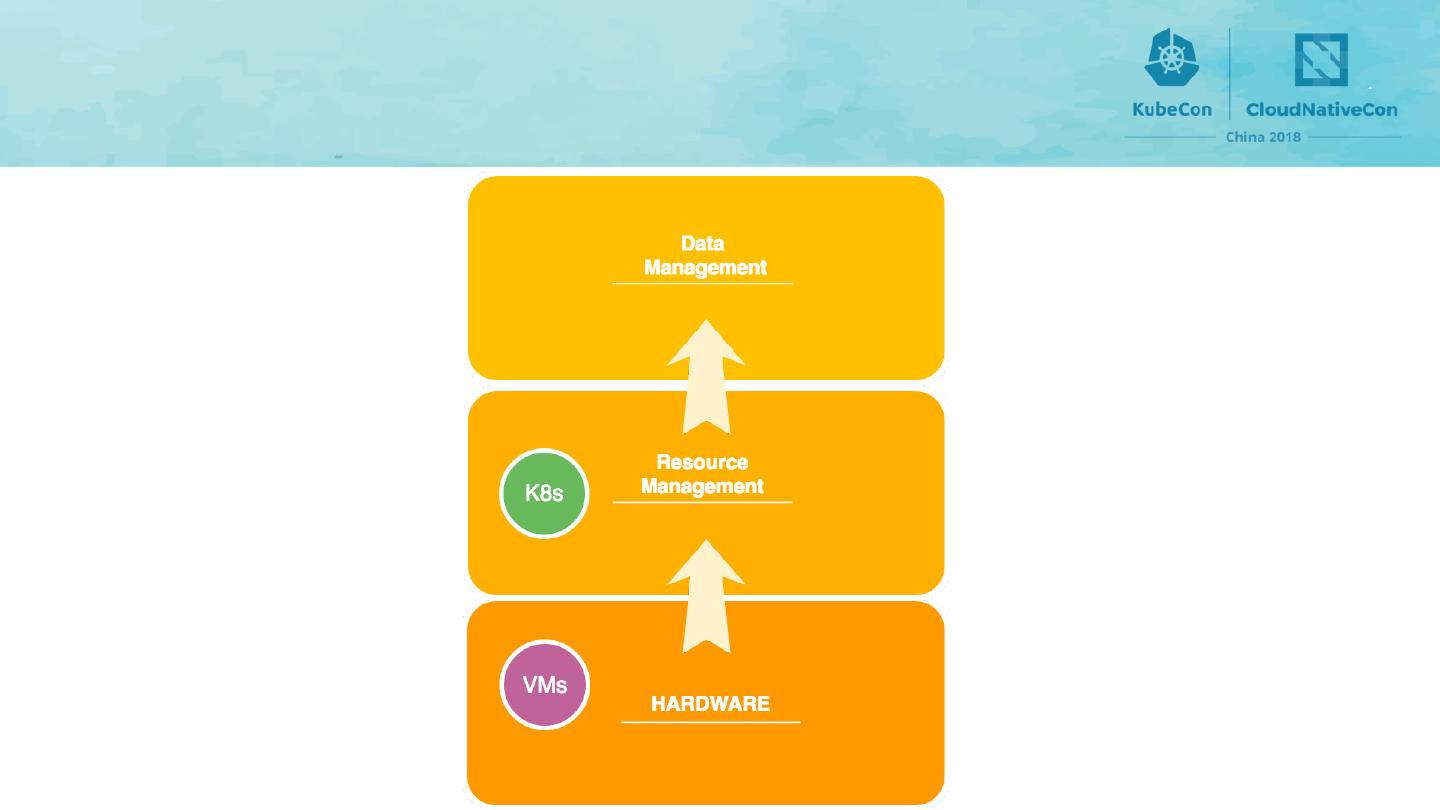
25 .Distributing Workloads
�
28 .Reproducibility
For Developers
�
29 .Reproducibility
For Developers
For the Team
�