
















































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Hprose_for_HTML5用户手册
Hprose是一个先进的轻量级的跨语言跨平台面向对象的高性能远程动态通讯中间件。
展开查看详情
1 .
2 . 目 录 致谢 Hprose for HTML5 用户手册 2.0 新特征 Hprose 中间件 Hprose 客户端 Hprose 序列化 Hprose 过滤器 Promise 异步编程 协程 客户端的特殊设置 推送服务 输入输出——BytesIO 本文档使用 书栈(BookStack.CN) 构建 - 2 -
3 .致谢 致谢 当前文档 《Hprose for HTML5 用户手册》 由 进击的皇虫 使用 书栈 (BookStack.CN) 进行构建,生成于 2018-07-09。 书栈(BookStack.CN) 仅提供文档编写、整理、归类等功能,以及对文档内 容的生成和导出工具。 文档内容由网友们编写和整理,书栈(BookStack.CN) 难以确认文档内容知 识点是否错漏。如果您在阅读文档获取知识的时候,发现文档内容有不恰当的地 方,请向我们反馈,让我们共同携手,将知识准确、高效且有效地传递给每一个 人。 同时,如果您在日常工作、生活和学习中遇到有价值有营养的知识文档,欢迎 分享到 书栈(BookStack.CN) ,为知识的传承献上您的一份力量! 如果当前文档生成时间太久,请到 书栈(BookStack.CN) 获取最新的文 档,以跟上知识更新换代的步伐。 文档地址:http://www.bookstack.cn/books/hprose-html5 书栈官网:http://www.bookstack.cn 书栈开源:https://github.com/TruthHun 分享,让知识传承更久远! 感谢知识的创造者,感谢知识的分享者,也感谢 每一位阅读到此处的读者,因为我们都将成为知识的传承者。 本文档使用 书栈(BookStack.CN) 构建 - 3 -
4 .Hprose for HTML5 用户手册 Hprose for HTML5 用户手册 Hprose for HTML5 用户手册 HPROSE 是 High Performance Remote Object Service Engine 的缩 写,翻译成中文就是“高性能远程对象服务引擎”。 它是一个先进的轻量级的跨语言跨平台面向对象的高性能远程动态通讯中间件。它 不仅简单易用,而且功能强大。你只需要稍许的时间去学习,就能用它轻松构建跨 语言跨平台的分布式应用系统了。 Hprose 支持众多流行的编程语言,例如: AAuto Quicker ActionScript ASP C++ Delphi/Free Pascal dotNET(C#, Visual Basic…) Golang Java JavaScript Node.js Objective-C Perl PHP Python Ruby 通过 Hprose,你就可以在这些语言之间方便高效的实现互通了。 本项目是 Hprose 的 HTML5 版本实现。 如果你喜欢本项目,请点击右上角的 Star,这样就可以将本项目放入您的收藏。 如果你非常喜欢,请点击右上角的 Fork,这样就可以直接将本项目直接复制到您 的名下。 如果您有问题需要反馈,请点击 github 上的 issues 提交您的问题。 如果您改进了代码,并且愿意将它合并到本项目中,你可以使用 github 的 pull requests 功能来提交您的修改。 接下来让我们开始 Hprose for HTML5 之旅吧。 原文: https://github.com/hprose/hprose-html5/wiki 本文档使用 书栈(BookStack.CN) 构建 - 4 -
5 .2.0 新特征 2.0 新特征 Hprose 2.0 for HTML5 新增了许多特征: 增加了数据推送的支持。 oneway 调用支持。 增加了对幂等性(idempotent)调用自动重试的支持。 增加了(伪)同步调用支持。 客户端增加了负载均衡,故障切换的支持。 对客户端调用的 API 进行了优化,将多余的位置参数改为命名参数。 增加了新的中间件处理器支持,可以实现更强大的 AOP 编程。 增强了批处理功能。 新的 Future 实现,不但完全实现了 Promises/A+ 规范,而且提供了许 多功能强大,使用方便的 API。另外,还提供了对 ECMAScript 6 中 Promise 对象的模拟实现。 原文: https://github.com/hprose/hprose-html5/wiki/2.0-%E6%96%B0%E7%89%B9%E5%BE%81 本文档使用 书栈(BookStack.CN) 构建 - 5 -
6 .Hprose 中间件 Hprose 中间件 简介 Hprose 过滤器的功能虽然比较强大,可以将 Hprose 的功能进行扩展。但是有 些功能使用它仍然难以实现,比如缓存。 为此,Hprose 2.0 引入了更加强大的中间件功能。Hprose 中间件不仅可以对 输入输出的数据进行操作,它还可以对调用本身的参数和结果进行操作,甚至你可 以跳过中间的执行步骤,或者完全由你来接管中间数据的处理。 Hprose 中间件跟普通的 HTTP 服务器中间件有些类似,但又有所不同。 Hprose 客户端中间件分为三种: 调用中间件 批处理调用中间件 输入输出中间件 另外,输入输出中间件又可以细分为 beforeFilter 和 afterFilter 两种, 但它们本质上没有什么区别,只是在执行顺序上有所区别。 执行顺序 Hprose 中间件的顺序执行是按照添加的前后顺序执行的,假设添加的中间件处理 器分别为: handler1 , handler2 … handlerN ,那么执行顺序就是 handler1 , handler2 … handlerN 。 不同类型的 Hprose 中间件和 Hprose 其它过程的执行流程如下图所示: 1. +------------------------------------------------------------------+ 2. | +-----------------batch invoke----------------+ | 3. | +------+ | +-----+ +------+ +------+ +-----+ | | 4. | |invoke| | |begin| |invoke| ... |invoke| | end | | | 5. | +------+ | +-----+ +------+ +------+ +-----+ | | 6. | ^ +---------------------------------------------+ | 7. | | ^ | 8. | | | | 9. | v v | 10. | +-------------------+ +------------------+ | 11. | | invoke middleware | | batch middleware | | 12. | +-------------------+ +------------------+ | 13. | ^ ^ | 14. | | +---------------+ | | 本文档使用 书栈(BookStack.CN) 构建 - 6 -
7 .Hprose 中间件 15. | +---->| encode/decode |<-----+ | 16. | +---------------+ | 17. | ^ | 18. | | | 19. | v | 20. | +--------------------------+ | 21. | | before filter middleware | | 22. | +--------------------------+ | 23. | ^ | 24. | | _ _ ___ ____ ____ ____ ____ | 25. | v |__| |__] |__/ | | [__ |___ | 26. | +--------+ | | | | \ |__| ___] |___ | 27. | | filter | | 28. | +--------+ ____ _ _ ____ _ _ ___ | 29. | ^ | | | |___ |\ | | | 30. | | |___ |___ | |___ | \| | | 31. | v | 32. | +-------------------------+ | 33. | | after filter middleware | | 34. | +-------------------------+ | 35. +------------------------------------------------------------------+ 36. ^ 37. | 38. | 39. v 40. +------------------------------------------------------------------+ 41. | _ _ ___ ____ ____ ____ ____ ____ ____ ____ _ _ ____ ____ | 42. | |__| |__] |__/ | | [__ |___ [__ |___ |__/ | | |___ |__/ | 43. | | | | | \ |__| ___] |___ ___] |___ | \ \/ |___ | \ | 44. +------------------------------------------------------------------+ 调用中间件 调用中间件的形式为: 1. function(name, args, context, next) { 2. ... 3. var result = next(name, args, context); 4. ... 5. return result; 6. } name 是调用的远程函数/方法名。 args 是调用参数。 本文档使用 书栈(BookStack.CN) 构建 - 7 -
8 .Hprose 中间件 context 是调用上下文对象。 next 表示下一个中间件。通过调用 next 将各个中间件串联起来。 在调用 next 之前的操作在调用发生前执行,在调用 next 之后的操作在调 用发生后执行,如果你不想修改返回结果,你应该将 next 的返回值作为该中间 件的返回值返回。 跟踪调试 我们来看一个例子: client.js 1. function loghandler(name, args, context, next) { 2. console.log("before invoke:", name, args); 3. var result = next(name, args, context); 4. result.then(function(result) { 5. console.log("after invoke:", name, args, result); 6. }); 7. return result; 8. } 9. var client = hprose.Client.create("http://www.hprose.com/example/", ['hello']); 10. client.use(loghandler); 11. client.hello("world", function(result) { 12. console.log(result); 13. }); 客户端输出 1. before invoke: hello ["world"] 2. after invoke: hello ["world"] Hello world 3. Hello world 通过上面的输出,我们会发现结果 result 是个 promise 对象。但参数值 args 在 loghandler 里并不包含 Promise 的值,原因是 Hprose 内部已 经对参数值处理过了。这样对于中间件编写就方便了很多,只需要处理异步结果就 可以了。 缓存调用 我们再来看一个实现缓存调用的例子,在这个例子中我们也使用了上面的日志中间 件,用来观察我们的缓存是否真的有效。 本文档使用 书栈(BookStack.CN) 构建 - 8 -
9 .Hprose 中间件 client.js 1. function loghandler(name, args, context, next) { 2. console.log("before invoke:", name, args); 3. var result = next(name, args, context); 4. result.then(function(result) { 5. console.log("after invoke:", name, args, result); 6. }); 7. return result; 8. } 9. var cache = {}; 10. function cachehandler(name, args, context, next) { 11. if (context.userdata.cache) { 12. var key = JSON.stringify(args); 13. if (name in cache) { 14. if (key in cache[name]) { 15. return cache[name][key]; 16. } 17. } 18. else { 19. cache[name] = {}; 20. } 21. var result = next(name, args, context); 22. cache[name][key] = result; 23. return result; 24. } 25. return next(name, args, context); 26. } 27. var client = hprose.Client.create("http://www.hprose.com/example/", ['hello']); 28. client.use(cachehandler) 29. .use(loghandler); 30. client.hello("cache world", function(result) { 31. console.log(result); 32. }, { userdata: { cache: true } }); 33. client.hello("cache world", function(result) { 34. console.log(result); 35. }, { userdata: { cache: true } }); 36. client.hello("no cache world", function(result) { 37. console.log(result); 38. }); 39. client.hello("no cache world", function(result) { 40. console.log(result); 41. }); 客户端输出 1. before invoke: hello ["cache world"] 2. before invoke: hello ["no cache world"] 3. before invoke: hello ["no cache world"] 本文档使用 书栈(BookStack.CN) 构建 - 9 -
10 .Hprose 中间件 4. after invoke: hello ["no cache world"] Hello no cache world 5. Hello no cache world 6. after invoke: hello ["no cache world"] Hello no cache world 7. Hello no cache world 8. after invoke: hello ["cache world"] Hello cache world 9. Hello cache world 10. Hello cache world 我们看到输出结果中 'cache world' 的日志只被打印了一次,而 'no cache world' 的日志被打印了两次。这说明 'cache world' 确实被缓存了。 在这个例子中,我们用到了 userdata 设置项和 context.userdata ,通过 userdata 配合 Hprose 中间件,我们就可以实现自定义选项功能了。 另外,我们在这个例子中可以看到, use 方法可以链式调用。 批处理调用中间件 上面的调用中间件对于批处理调用是不起作用的,因为批处理调用是单独处理的。 批处理调用中间件的形式为: 1. function(batches, context, next) { 2. ... 3. var result = next(batches, context); 4. ... 5. return result; 6. } 是个数组。它的每个元素都是一个对象,该对象表示一个单独的调用, batches 它包含有以下属性: name 是调用的远程函数/方法名。 args 是调用的参数。 context 是调用的上下文对象。 resolve 用于返回成功结果的回调函数。 reject 用于返回失败结果(异常)的回调函数。 context 是批处理调用的上下文对象。 next 表示下一个中间件。通过调用 next 将各个中间件串联起来。 在调用 next 之前的操作在批处理调用发生前执行,在调用 next 之后的操 作在批处理调用发生后执行,如果你不想修改返回结果,你应该将 next 的返回 值作为该中间件的返回值返回。 本文档使用 书栈(BookStack.CN) 构建 - 10 -
11 .Hprose 中间件 批处理跟踪调试 client.js 1. function batchloghandler(batches, context, next) { 2. console.log("before invoke:", batches); 3. var result = next(batches, context); 4. result.then(function(result) { 5. console.log("after invoke:", batches, result); 6. }); 7. return result; 8. } 9. var log = hprose.Future.wrap(console.log, console); 10. var client = hprose.Client.create("http://www.hprose.com/example/", ['hello']); 11. client.batch.use(batchloghandler); 12. client.batch.begin(); 13. var r1 = client.hello("world 1"); 14. var r2 = client.hello("world 2"); 15. var r3 = client.hello("world 3"); 16. client.batch.end(); 17. log(r1, r2, r3); 服务器端我们不修改,还用上面那个例子中的服务器。启动客户端之后,我们会看 到客户端输出如下内容: 1. before invoke: [Object, Object, Object] 2. after invoke: [Object, Object, Object] [Object, Object, Object] 3. Hello world 1 Hello world 2 Hello world 3 这段输出这里就不需要解释了。 这里有一点要注意,那就是批处理调用中间件使用: client.batch.use 方法来添 加,该方法也支持链式调用,链式调用方式为: 1. client.batch.use(handler1) 2. .use(handler2) 3. .use(handler3); 输入输出中间件 输入输出中间件可以完全代替 Hprose 过滤器。使用输入输出中间件还是使用 Hprose 过滤器完全看开发者喜好。 本文档使用 书栈(BookStack.CN) 构建 - 11 -
12 .Hprose 中间件 输入输出中间件的形式为: 1. function(request, context, next) { 2. ... 3. var response = next(request, context); 4. ... 5. return response; 6. } request 是原始请求数据,对于客户端来说它是输出数据。该数据的类型为 Uint8Array 类型对象。 context 是调用上下文对象。 next 表示下一个中间件。通过调用 next 将各个中间件串联起来。 next 的返回值 response 是返回的响应数据。 对于客户端来说,它是输入数据。这个 response 必须为 promise 对象,该 promise 对象的成功值必须为 Uint8Array 类型的对象,如果是失败值,则失 败原因可以是任意类型,但最好是 Error 类型(或子类型)的对象。 跟踪调试 下面我们来看一下 Hprose 过滤器中的跟踪调试的例子在这里如何实现。 client.js 1. function loghandler(request, context, next) { 2. console.log(request); 3. var response = next(request, context); 4. response.then(function(data) { 5. console.log(data); 6. }); 7. return response; 8. } 9. var client = hprose.Client.create("http://www.hprose.com/example/", ['hello']); 10. client.beforeFilter.use(loghandler); 11. client.hello("world", function(result) { 12. console.log(result); 13. }); 然后分别启动服务器和客户端,就会看到如下输出: 客户端输出 1. Cs5"hello"a1{s5"world"}z 本文档使用 书栈(BookStack.CN) 构建 - 12 -
13 .Hprose 中间件 2. Rs12"Hello world!"z 3. Hello world! 这个结果跟使用 Hprose 过滤器的例子的结果一模一样。 但是我们发现,这里使用 Hprose 中间件要写的代码比起 Hprose 过滤器来要 多一些。主要原因是在 Hprose 中间件中,返回的响应对象是 promise 对象, 需要单独处理。而 Hprose 过滤器则不需要。 另外,因为这个例子中,我们没有使用过滤器功能,因此使用 beforeFilter.use 方法或者 afterFilter.use 方法添加中间件处理器效果都是一样的。 但如果我们使用了过滤器的话,那么 beforeFilter.use 添加的中间件处理器的 request 数据是未经过过滤器处理的。过滤器的处理操作在 next 的最后一环 中执行。 next 返回的响应 response 是经过过滤器处理的。 如果某个通过 beforeFilter.use 添加的中间件处理器跳过了 next 而直接返 回了结果的话,则返回的 response 也是未经过过滤器处理的。而且如果某个 beforeFilter.use 添加的中间件处理器跳过了 next ,不但过滤器不会执行, 而且在它之后使用 beforeFilter.use 所添加的中间件处理器也不会执 行, afterFilter.use 方法所添加的所有中间件处理器也都不会执行。 而 afterFilter.use 添加的处理器所收到的 request 都是经过过滤器处理以 后的,但它当中使用 next 方法返回的 response 是未经过过滤器处理的。 关于 Hprose 中间件的更多用法,还可以参见 Hprose for Node.js 用户手 册的相关内容。它们的实现是完全一样的。 原文: https://github.com/hprose/hprose-html5/wiki/Hprose- %E4%B8%AD%E9%97%B4%E4%BB%B6 本文档使用 书栈(BookStack.CN) 构建 - 13 -
14 .Hprose 客户端 Hprose 客户端 概述 Hprose 2.0 for HTML5 支持多种底层网络协议绑定的客户端,比如:HTTP 客户端,TCP 客户端和 WebSocket 客户端。 其中 HTTP 客户端支持跟 HTTP、HTTPS 绑定的 hprose 服务器通讯。 TCP 客户端支持跟 TCP 绑定的 hprose 服务器通讯,并且支持全双工和半双工 两种模式。 WebSocket 客户端支持跟 ws、wss 绑定的 hprose 服务器通讯。 尽管支持这么多不同的底层网络协议,但除了在对涉及到底层网络协议的参数设置 上有所不同以外,其它的用法都完全相同。因此,我们在下面介绍 hprose 客户 端的功能时,若未涉及到底层网络协议的区别,就以 HTTP 客户端为例来进行说 明。 创建客户端 创建客户端有两种方式,一种是直接使用构造器函数,另一种是使用工厂方法 create 。 使用构造器函数创建客户端 hprose.Client 是一个抽象类,因此它不能作为构造器函数直接使用。如果你想 创建一个具体的底层网络协议绑定的客户端,你可以将它作为父类,至于如何实现 一个具体的底层网络协议绑定的客户端,这已经超出了本手册的内容范围,这里不 做具体介绍,有兴趣的读者可以参考 hprose.HttpClient 、 hprose.TcpClient 和 hprose.WebSocketClient 这几个底层网络协议绑定客户端的实现源码。 、 hprose.TcpClient 和 hprose.WebSocketClient 这三个函数 hprose.HttpClient 是可以直接使用的构造器函数。它们分别对应 http 客户端、tcp 客户端和 WebSocket 客户端。 1. new hprose.HttpClient([uri[, functions[, settings]]]); 2. new hprose.TcpClient([uri[, functions[, settings]]]); 3. new hprose.WebSocketClient([uri[, functions[, settings]]]); 这两个构造器的参数格式是相同的。开头的关键字 new 也可以省略,但最好不要 省略。 本文档使用 书栈(BookStack.CN) 构建 - 14 -
15 .Hprose 客户端 构造器中包含了 3 个参数,这 3 个参数都可以省略。 当 3 个参数都省略时,创建的客户端是未初始化的,后面需要使用 useService 方法进行初始化,这是后话,暂且不表。 第 1 个参数 uri 是服务器地址,该服务器地址可以是单个的 uri 字符 串,也可以是由多个 uri 字符串组成的数组。当该参数为多个 uri 字符串 组成的数组时,客户端会从这些地址当中随机选择一个作为服务地址。因此需要保 证这些地址发布的都是完全相同的服务。 第 2 个参数 functions 是远程函数名集合。它可以是单个函数名的字符串表 示,也可以是多个函数名的字符串数组,还可以是一个对象。 第 3 个参数 settings 用于初始化客户端的设置。它可以初始化客户端的以下 设置: failswitch timeout retry idempotent keepAlive byref simple useHarmonyMap filter 这些设置都有对应的客户端属性,这里暂不解释,在后面介绍属性时,再分别 介绍。 例如: 1. var client = new hprose.HttpClient(uri, 'hello', { timeout: 20000 }); 创建的 client 对象上,就有一个叫 hello 的远程方法,并且客户端的超时 被初始化为 20000ms。 这个 hello 方法可以直接这样调用: 1. var result = client.hello('world'); 再举一例: 1. var client = new hprose.HttpClient(uri, ['hello', 'sum']); 这样创建的 client 对象上,就有两个远程方法,他们分别是 hello 和 sum 。 本文档使用 书栈(BookStack.CN) 构建 - 15 -
16 .Hprose 客户端 1. var client = new hprose.HttpClient(uri, { 2. user: ['add', 'update', 'del', 'get'] 3. }); 这样创建的 client 对象上,就有一个叫 user 的对象,在这个 user 对 象上有 4 个方法,他们分别是 add , update , del , get 。 可以这样调用: 1. var result = client.user.get(id); 注意:这里的 user.add 、 user.update 、 user.del 和 user.get 分别对应服 务器端发布的别名为: user_add , user_update , user_del 和 user_get 方法。 服务器端的别名可以通过 _ 分隔成好几段,每一段都可以转换为 . 调用的 方式。 另外,对象和数组方式还可以组合使用,例如下面这个复杂一点的例子: 1. var functions = { 2. user: ['add', 'update', 'del', 'get'], 3. order: [ 'add', 'update', 'del', 'get', { 4. today: [ 'add', 'udate', 'del', 'get' ], 5. yesterday: [ 'add', 'udate', 'del', 'get' ], 6. tomorrow: [ 'add', 'udate', 'del', 'get' ] 7. }] 8. }; 9. 10. var client = new hprose.HttpClient(uri, functions); 在上面的例子中: 方法对应服务器端的 order_add 方法,而 client.order.add client.order.today.add 方法则对应服务器端的 order_today_add 方法。 当然,如果方法有很多,像这样一个一个都列出来,或许有些麻烦。所以这个函数 列表可以省略。 如果省略的话,想要直接使用方法名调用需要在 client 对象的 ready 方法 回调中才能使用,例如: 1. var client = new hprose.HttpClient(uri); 2. client.ready(function(proxy) { 3. proxy.hello('world', function(result) { 4. console.log(result); 5. }); 6. }); 因为当省略函数名列表时,客户端会向服务器端请求这个函数名列表,当获取到之 本文档使用 书栈(BookStack.CN) 构建 - 16 -
17 .Hprose 客户端 后才会将这些函数绑定到客户端对象上。而获取的过程是异步的,因此需要使用 ready 方法。 在省略函数名列表的情况下,对于 user_add 这样的方法,在旧版本中是不能使 用 user.add 的方式调用的。 但是从 hprose-html5 v2.0.35 版本之后,也可以使用 user.add 这种方式 了。 而且从 v2.0.36 版本之后,hprose-html5 已通过浏览器内置的 Proxy 实 现了动态代理,无需再通过网络获取远程方法列表,但是请注意,IE 系列浏览器 不支持此功能。 通过工厂方法 create 创建客户端 1. hprose.Client.create(uri[, functions[, settings]]); 2. hprose.HttpClient.create(uri[, functions[, settings]]); 3. hprose.TcpClient.create(uri[, functions[, settings]]); 4. hprose.WebSocketClient.create(uri[, functions[, settings]]); 与构造器函数不同,工厂方法 create 可以在 hprose.Client 上被调用,它会 根据 uri 的协议来决定创建什么类型的客户端。 create 方法与构造器函数的参数一样,返回结果也一样。但是第一个参数 uri 不能被省略。 方法与构造器函数还有一点不同, create 会检查 uri 的有效性 create (是指格式是否有效,而不是指服务器是否可以连通),而构造器函数不会检查。 因此,除非在创建客户端的时候,不想指定服务地址,否则,应该优先考虑使用 create 方法来创建客户端。 使用 hprose.Client.create 方法还有个好处,当你变更底层通讯协议不需要修改 代码,只需要修改 uri 地址就可以了,而 uri 地址可以通过各种方式动态 加载,因此更加灵活。 uri 地址格式 HTTP 服务地址格式 HTTP 服务地址与普通的 URL 地址没有区别,支持 http 和 https 两种协 议,这里不做介绍。 WebSocket 服务地址格式 本文档使用 书栈(BookStack.CN) 构建 - 17 -
18 .Hprose 客户端 除了协议从 http 改为 ws (或 wss ) 以外,其它部分与 http 地址表 示方式完全相同,这里不再详述。 TCP 服务地址格式 1. <protocol>://<ip>:<port> <ip> 是服务器的 IP 地址,也可以是域名。 <port> 是服务器的端口号,hprose 的 TCP 服务没有默认端口号,因此不可 省略。 <protocol> 表示协议,它可以为以下取值: tcp tcp4 tcp6 tls tcps tcp4s tcp6s tcp 表示 tcp 协议,地址可以是 ipv6 地址,也可以是 ipv4 地址。 tcp4 表示地址为 ipv4 的 tcp 协议。 tcp6 表示地址为 ipv6 的 tcp 协议。 和 tcps 意义相同,表示安全的 tcp 协议,地址可以是 ipv6 地址, tls 也可以是 ipv4 地址。如有必要,可设置客户端安全证书。 tcp4s 表示地址为 ipv4 的安全的 tcp 协议。 tcp6s 表示地址为 ipv6 的安全的 tcp 协议。 客户端属性 uri 属性 只读属性。该属性表示客户端当前所使用的地址。如果客户端在创建时设置了多个 服务地址,该属性的值仅为这多个地址中当前正在使用中的那个地址。 uriList 属性 读写属性。该属性表示客户端可以使用的服务器地址列表。 本文档使用 书栈(BookStack.CN) 构建 - 18 -
19 .Hprose 客户端 id 属性 只读属性。该属性表示当前客户端在进行推送订阅时的唯一编号。在没有进行推送 订阅或者使用自己指定 id 方式进行推送订阅时,该属性的值为 null。你也可 以调用 client'#'; 方法来手动从服务器端获取该 id 的值。 failswitch 属性 该属性为 Boolean 类型。默认值为 false 。 该属性表示当前客户端在因网络原因调用失败时是否自动切换服务地址。当客户端 服务地址仅设置一个时,不管该属性值为何,都不会切换地址。 你也可以针对某个调用进行单独设置。 failround 属性 整数类型,只读属性。初始值为 0。当调用中发生服务地址切换时,如果服务列表 中所有的服务地址都切换过一遍之后,该属性值会加 1。你可以根据该属性来决定 是否更新服务列表。更新服务列表可以通过设置 uriList 属性来完成。 timeout 属性 该属性为整数类型,默认值为 30000 ,单位是毫秒(ms)。 该属性表示当前客户端在调用时的超时时间,如果调用超过该时间后仍然没有返 回,则会以超时错误返回。 你也可以针对某个调用进行单独设置。 idempotent 属性 该属性为 Boolean 类型,默认值为 false 。 该属性表示调用是否为幂等性调用,幂等性调用表示不论该调用被重复几次,对服 务器的影响都是相同的。幂等性调用在因网络原因调用失败时,会自动重试。如果 failswitch 属性同时被设置为 true ,并且客户端设置了多个服务地址,在重 试时还会自动切换地址。 你也可以针对某个调用进行单独设置。 retry 属性 本文档使用 书栈(BookStack.CN) 构建 - 19 -
20 .Hprose 客户端 该属性为整数类型,默认值为 10 。 该属性表示幂等性调用在因网络原因调用失败后的重试次数。只有 idempotent 属性为 true 时,该属性才有作用。 你也可以针对某个调用进行单独设置。 byref 属性 该属性为 Boolean 类型,默认值为 false 。 该属性表示调用是否为引用参数传递。当设置为引用参数传递时,服务器端会传回 修改后的参数值(即使没有修改也会传回)。因此,当不需要该功能时,设置为 false 会比较节省流量。 你也可以针对某个调用进行单独设置。 simple 属性 该属性为 Boolean 类型,默认值为 false 。 该属性表示调用中所传输的数据是否为简单数据。简单数据是指:null、数字 (包括整数、长整数、浮点数)、Boolean 值、字符串、二进制数据、日期时间 等基本类型的数据或者不包含引用的数组、Map 和对象。当该属性设置为 true 时,在进行序列化操作时,将忽略引用处理,加快序列化速度。但如果数据不是简 单类型的情况下,将该属性设置为 true ,可能会因为死循环导致堆栈溢出的错 误。 简单的讲,用 JSON 可以表示的数据都是简单数据。但是对于比较复杂的 JSON 数据,设置 simple 为 true 可能不会加快速度,反而会减慢,比如 对象数组。因为默认情况下,hprose 会对对象数组中的重复字符串的键值进行引 用处理,这种引用处理可以对序列化起到优化作用。而关闭引用处理,也就关闭了 这种优化。 你也可以针对某个调用进行单独设置。 因为不同调用的数据可能差别很大,因此,建议不要修改默认设置,而是针对某个 调用进行单独设置。 useHarmonyMap 属性 该属性为 Boolean 类型,默认值为 false 。 该属性表示调用所返回的数据中,如果包含有 Map 类型的数据,是否反序列化为 ECMAScript 6 中的 Map 类型对象。当该属性设置为 false 时(即默认 本文档使用 书栈(BookStack.CN) 构建 - 20 -
21 .Hprose 客户端 值),Map 类型的数据将会被反序列化为 Object 实例对象的数据。 除非 Map 中的键不是字符串类型,否则没必要将该属性设置为 true 。 你也可以针对某个调用进行单独设置。 keepAlive 属性 该属性为 Boolean 类型,默认值为 true 。 该属性表示客户端和服务器端之间是否保持长连接。该属性只对 WebSocket 客 户端有效。 filter 属性 该属性可以为对象类型或对象数组类型。默认值为 null。 该属性的作用是可以设置一个或多个 Filter 对象。关于 Filter 对象,我们 将作为单独的章节进行介绍,这里暂且略过。 客户端事件属性 onerror 事件 该事件属性为函数类型,默认值为空函数(即无任何操作的函数)。 当客户端调用发生错误时,如果没有为调用设置异常处理回调函数,则该属性事件 将被回调。回调函数有两个参数,第一个参数是方法名(字符串类型),第二个参 数是调用中发生的错误(通常为 Error 对象)。 onfailswitch 事件 该事件属性为函数类型,默认值为空函数(即无任何操作的函数)。 当调用的 failswitch 属性设置为 true 时,如果在调用中出现网络错误,进 行服务器切换时,该事件会被触发。该事件的回调函数只有一个参数,即客户端对 象本身。 客户端方法 addFilter 方法 本文档使用 书栈(BookStack.CN) 构建 - 21 -
22 .Hprose 客户端 1. client.addFilter(filter); 该方法同设置 filter 属性类似。该方法用于添加一个 filter 对象到 Filter 链的末尾。 removeFilter 方法 1. client.removeFilter(filter); 该方法同设置 filter 属性类似。该方法用于从 Filter 链中删除指定的 filter 对象。 useService 方法 1. client.useService(); 2. client.useService(uri); 3. client.useService(functions); 4. client.useService(uri, functions); 该方法的用处是对于未初始化的客户端对象,进行后期初始化设置,或者用于变更 服务器地址。 当未设置任何参数调用时,该客户端返回一个 promise 对象,该 promise 对 象的成功值为远程服务代理对象。 当仅设置了 uri 参数时,跟上面的功能相同,但是会替换当前的 uri 设 置。注意,这里的 uri 地址只能是单个的服务地址,而不能是服务地址数组列 表。 参数是一个服务方法列表,与创建客户端时的 functions 参数相 functions 同,但不能是单个的字符串方法名。当设置了该列表参数后,会直接返回一个远程 服务代理对象。 例如: 1. var client = new hprose.HttpClient('http://www.hprose.com/example/', ['hello']); 2. client.hello("World", function(result) { console.log(result); }); 跟下面的代码的效果完全相同。 1. var client = new hprose.HttpClient(); 2. var proxy = client.useService('http://www.hprose.com/example/', ['hello']); 3. proxy.hello("World", function(result) { console.log(result); }); 本文档使用 书栈(BookStack.CN) 构建 - 22 -
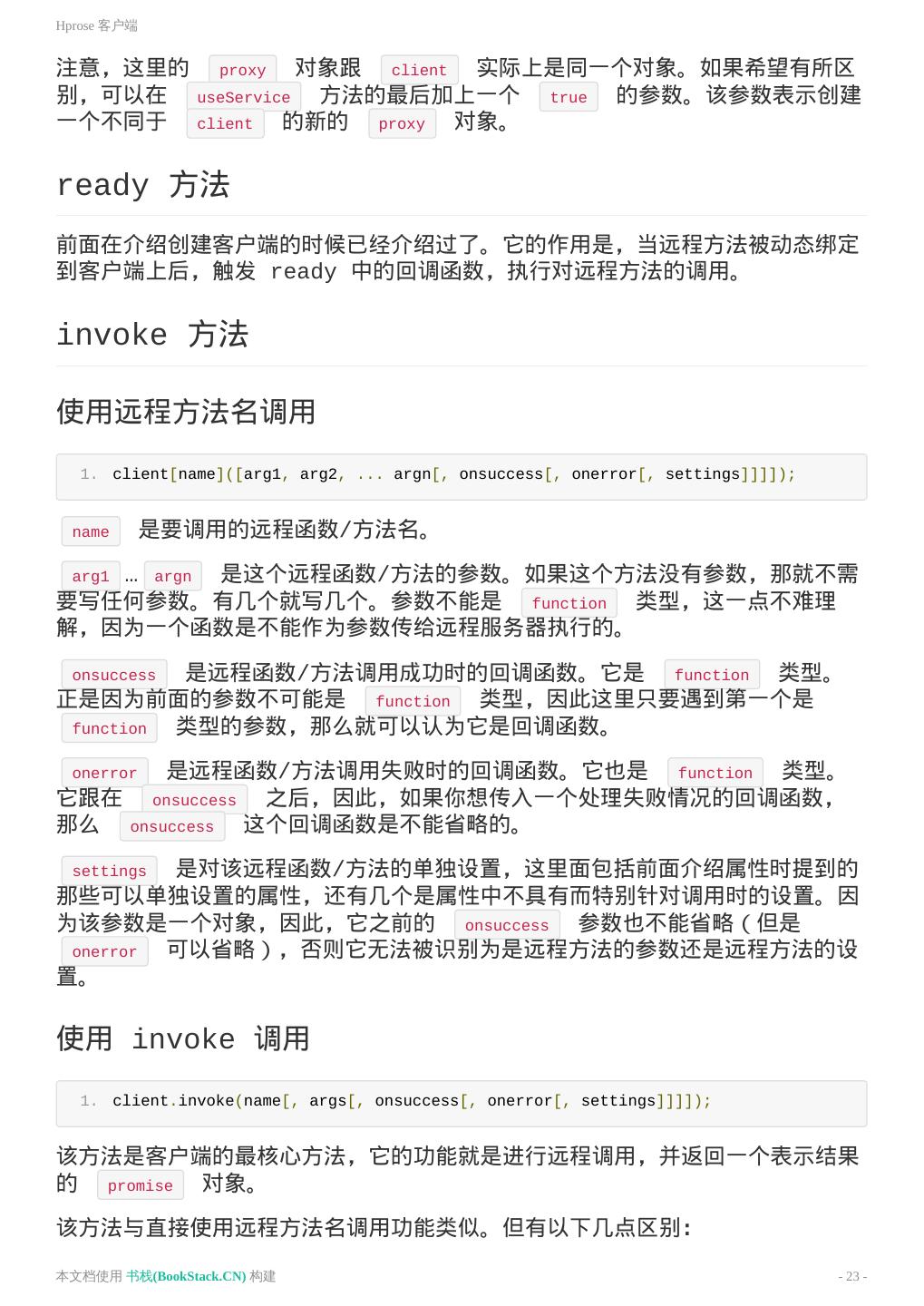
23 .Hprose 客户端 注意,这里的 proxy 对象跟 client 实际上是同一个对象。如果希望有所区 别,可以在 useService 方法的最后加上一个 true 的参数。该参数表示创建 一个不同于 client 的新的 proxy 对象。 ready 方法 前面在介绍创建客户端的时候已经介绍过了。它的作用是,当远程方法被动态绑定 到客户端上后,触发 ready 中的回调函数,执行对远程方法的调用。 invoke 方法 使用远程方法名调用 1. client[name]([arg1, arg2, ... argn[, onsuccess[, onerror[, settings]]]]); name 是要调用的远程函数/方法名。 … argn 是这个远程函数/方法的参数。如果这个方法没有参数,那就不需 arg1 要写任何参数。有几个就写几个。参数不能是 function 类型,这一点不难理 解,因为一个函数是不能作为参数传给远程服务器执行的。 onsuccess 是远程函数/方法调用成功时的回调函数。它是 function 类型。 正是因为前面的参数不可能是 function 类型,因此这里只要遇到第一个是 function 类型的参数,那么就可以认为它是回调函数。 是远程函数/方法调用失败时的回调函数。它也是 function 类型。 onerror 它跟在 onsuccess 之后,因此,如果你想传入一个处理失败情况的回调函数, 那么 onsuccess 这个回调函数是不能省略的。 settings 是对该远程函数/方法的单独设置,这里面包括前面介绍属性时提到的 那些可以单独设置的属性,还有几个是属性中不具有而特别针对调用时的设置。因 为该参数是一个对象,因此,它之前的 onsuccess 参数也不能省略(但是 onerror 可以省略),否则它无法被识别为是远程方法的参数还是远程方法的设 置。 使用 invoke 调用 1. client.invoke(name[, args[, onsuccess[, onerror[, settings]]]]); 该方法是客户端的最核心方法,它的功能就是进行远程调用,并返回一个表示结果 的 promise 对象。 该方法与直接使用远程方法名调用功能类似。但有以下几点区别: 本文档使用 书栈(BookStack.CN) 构建 - 23 -
24 .Hprose 客户端 直接使用远程方法名调用时,参数 arg1…argn 中的参数可以是 promise 对象。直接使用 invoke 方法时,args 是参数数组,里面的元素不可以包 含 promise 对象。 当同时使用远程方法名和 invoke 方法进行远程调用时,不管哪个写在前 面,都是 invoke 方法先执行,原因是使用远程方法名调用时,会先对对参 数中的 promise 对象进行取值操作,而 invoke 方法调用不会有这个过 程。 invoke 方法的 args 必须是数组类型,但可以省略,省略的话,被认为该 调用没有参数。 invoke 方法的 onsuccess 在省略的情况下,仍然可以带入 settings 参数。但直接使用远程方法名调用时,如果 onsuccess 省略,则不能带入 settings 参数。 settings 参数可以包括以下设置: mode byref simple failswitch timeout idempotent retry oneway sync onsuccess onerror useHarmonyMap userdata 下面来分别介绍一下这些设置的意义: mode 该设置表示结果返回的类型,它有4个取值,分别是: hprose.Normal (或 hprose.ResultMode.Normal) hprose.Serialized (或 hprose.ResultMode.Serialized) hprose.Raw (或 hprose.ResultMode.Raw) hprose.RawWithEndTag (或 hprose.ResultMode.RawWithEndTag) hprose.Normal 是默认值,表示返回正常的已被反序列化的结果。 hprose.Serialized 表示返回的结果保持序列化的格式。 hprose.Raw 表示返回原始数据。 本文档使用 书栈(BookStack.CN) 构建 - 24 -
25 .Hprose 客户端 hprose.RawWithEndTag 表示返回带有结束标记的原始数据。 这样说明也许有些晦涩,让我们来看一个例子就清楚了: 1. var BytesIO = hprose.BytesIO; 2. var client = hprose.Client.create('http://www.hprose.com/example/', ['hello']); 3. function onsuccess(result) { 4. console.log(result.constructor, BytesIO.toString(result)); 5. } 6. client.hello("World", onsuccess, { mode: hprose.Normal, sync: true }); 7. client.hello("World", onsuccess, { mode: hprose.Serialized, sync: true }); 8. client.hello("World", onsuccess, { mode: hprose.Raw, sync: true }); 9. client.hello("World", onsuccess, { mode: hprose.RawWithEndTag, sync: true }); 为了保证执行顺序,这里还加了一个 sync 设置,对于该设置在后面再做详细解 释。 该程序执行结果如下: 1. [Function: String] 'Hello World' 2. [Function: Uint8Array] 's11"Hello World"' 3. [Function: Uint8Array] 'Rs11"Hello World"' 4. [Function: Uint8Array] 'Rs11"Hello World"z' 由于历史原因,为了兼容旧版本的 hprose 的写法,该设置也可以不写在 settings 对象中,例如上面程序还可以这样写: 1. var BytesIO = hprose.BytesIO; 2. var client = hprose.Client.create('http://www.hprose.com/example/', ['hello']); 3. function onsuccess(result) { 4. console.log(result.constructor, BytesIO.toString(result)); 5. } 6. client.hello("World", onsuccess, hprose.Normal, { sync: true }); 7. client.hello("World", onsuccess, hprose.Serialized, { sync: true }); 8. client.hello("World", onsuccess, hprose.Raw, { sync: true }); 9. client.hello("World", onsuccess, hprose.RawWithEndTag, { sync: true }); 但在新版本中,不再推荐这种写法。 byref 该设置表示调用是否为引用参数传递方式。例如: 1. var client = hprose.Client.create('http://www.hprose.com/example/', 2. ['swapKeyAndValue']); 本文档使用 书栈(BookStack.CN) 构建 - 25 -
26 .Hprose 客户端 3. var weeks = { 4. 'Monday': 'Mon', 5. 'Tuesday': 'Tue', 6. 'Wednesday': 'Wed', 7. 'Thursday': 'Thu', 8. 'Friday': 'Fri', 9. 'Saturday': 'Sat', 10. 'Sunday': 'Sun', 11. }; 12. function onsuccess(result, args) { 13. console.log(weeks.constructor, weeks); 14. console.log(result.constructor, result); 15. console.log(args.constructor, args); 16. } 17. client.swapKeyAndValue(weeks, onsuccess, { byref: true }); 该程序执行结果为: 1. [Function: Object] { Monday: 'Mon', 2. Tuesday: 'Tue', 3. Wednesday: 'Wed', 4. Thursday: 'Thu', 5. Friday: 'Fri', 6. Saturday: 'Sat', 7. Sunday: 'Sun' } 8. [Function: Object] { Mon: 'Monday', 9. Tue: 'Tuesday', 10. Wed: 'Wednesday', 11. Thu: 'Thursday', 12. Fri: 'Friday', 13. Sat: 'Saturday', 14. Sun: 'Sunday' } 15. [Function: Array] [ { Mon: 'Monday', 16. Tue: 'Tuesday', 17. Wed: 'Wednesday', 18. Thu: 'Thursday', 19. Fri: 'Friday', 20. Sat: 'Saturday', 21. Sun: 'Sunday' } ] 我们可以看到在回调方法中的 args 参数被改变了,但是原来的参数对象 weeks 并没有被改变。也就是说,这里的引用参数传递只体现在回调函数返回的 参数上,对原始的参数并不会修改。 同样,由于历史原因,为了兼容旧版本的 hprose 的写法,该设置也可以不写在 本文档使用 书栈(BookStack.CN) 构建 - 26 -
27 .Hprose 客户端 settings 对象中,而直接将 true 跟在 onsuccess 之后也是可以的。 simple 该设置表示本次调用中所传输的参数是否为简单数据。前面在属性介绍中已经进行 了说明,这里就不在重复。 failswitch 该设置表示当前调用在因网络原因失败时是否自动切换服务地址。 timeout 该设置表示本次调用的超时时间,如果调用超过该时间后仍然没有返回,则会以超 时错误返回。 idempotent 该设置表示本次调用是否为幂等性调用,幂等性调用在因网络原因调用失败时,会 自动重试。 retry 该设置表示幂等性调用在因网络原因调用失败后的重试次数。只有 idempotent 设置为 true 时,该设置才有作用。 oneway 该设置表示当前调用是否不等待返回值。当该设置为 true 时,请求发送之后, 并不等待服务器返回结果,回调函数将立即被调用,结果被设置为 undefined 。 sync 该设置表示当前调用是否为“同步”调用。这里的“同步”调用是伪同步。它仅表示 在该调用之后,同一个客户端所发起的其它远程调用一定是在本次调用执行完之后 才会被调用。它可以保证几个连续的调用将按书写顺序执行。但每个调用本身还是 异步的。 onsuccess 该设置表示调用成功时的回调函数,跟 invoke 方法的 onsuccess 参数是一 个意思。它通常不会在 settings 参数中设置,因为在使用方法名调用时,没有 本文档使用 书栈(BookStack.CN) 构建 - 27 -
28 .Hprose 客户端 参数的情况下,无法传递 settings 参数。但是如果在 settings onsuccess 参数中也设置了该属性,那么它将会覆盖 invoke 方法的 onsuccess 参数的 设置。 onerror 该设置表示调用失败时的回调函数,跟 invoke 方法的 onerror 参数是一个 意思。它通常也不会在 settings 参数中设置。但是如果在 settings 参数中 也设置了该属性,那么它将会覆盖 invoke 方法的 onerror 参数的设置。 useHarmonyMap 该设置跟前面介绍的 useHarmonyMap 属性功能相同,但只针对当前调用有效。 userdata 该属性是一个对象,它用于存放一些用户自定义的数据。这些数据可以通过 context 对象在整个调用过程中进行传递。当你需要实现一些特殊功能的 Filter 或 Handler 时,可能会用到它。 上面这些设置除了可以作为 settings 参数的属性传入以外,还可以在远程方法 上直接进行属性设置,这些设置会成为 settings 参数的默认值。例如上面那个 引用参数传递的例子还可以写成这样: 1. var client = hprose.Client.create('http://www.hprose.com/example/', 2. ['swapKeyAndValue']); 3. var weeks = { 4. 'Monday': 'Mon', 5. 'Tuesday': 'Tue', 6. 'Wednesday': 'Wed', 7. 'Thursday': 'Thu', 8. 'Friday': 'Fri', 9. 'Saturday': 'Sat', 10. 'Sunday': 'Sun', 11. }; 12. 13. client.swapKeyAndValue.onsuccess = function(result, args) { 14. console.log(weeks.constructor, weeks); 15. console.log(result.constructor, result); 16. console.log(args.constructor, args); 17. }; 18. 19. client.swapKeyAndValue.byref = true; 20. 21. client.swapKeyAndValue(weeks); 运行结果是一样的。这里就不在重复了。 本文档使用 书栈(BookStack.CN) 构建 - 28 -
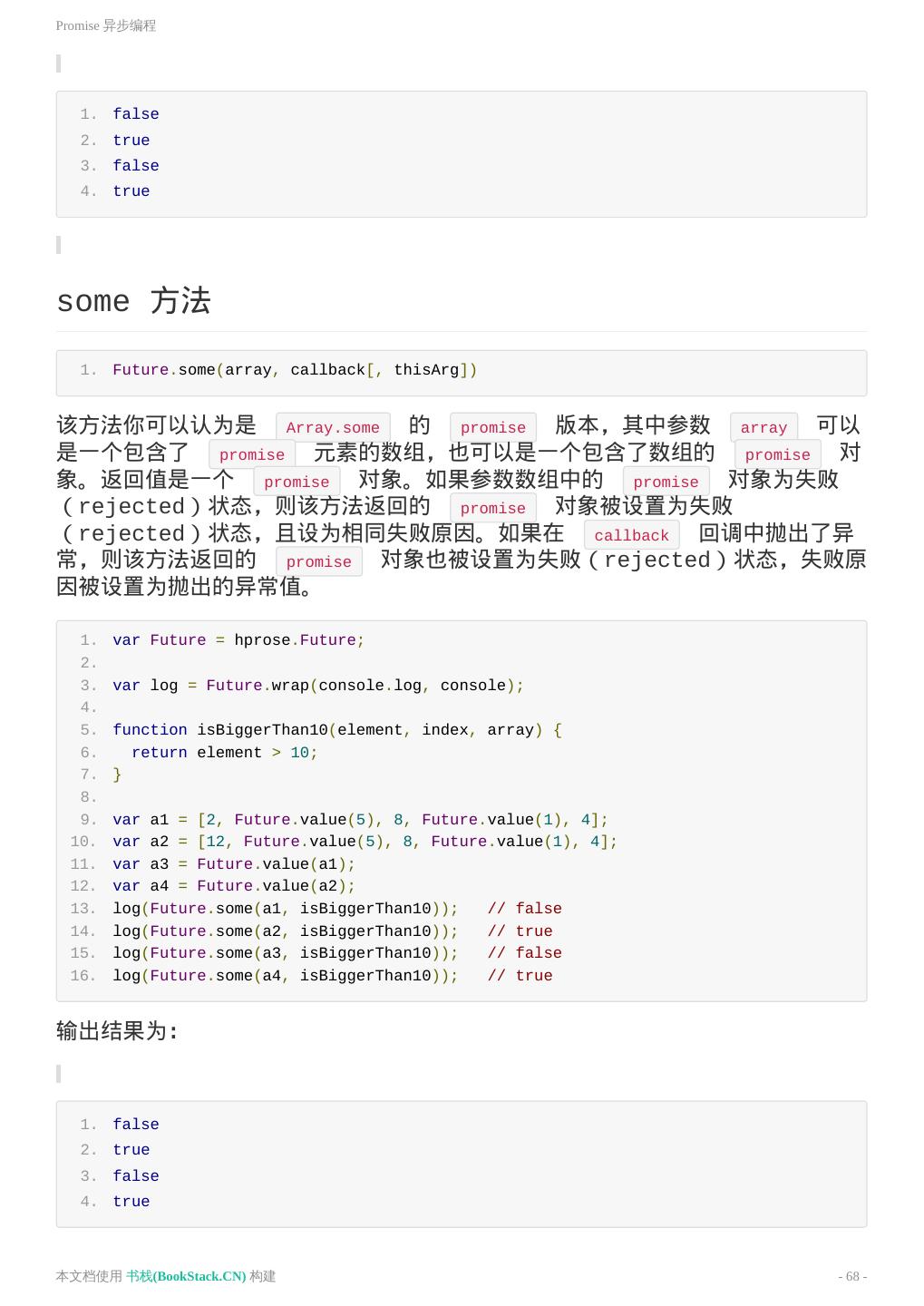
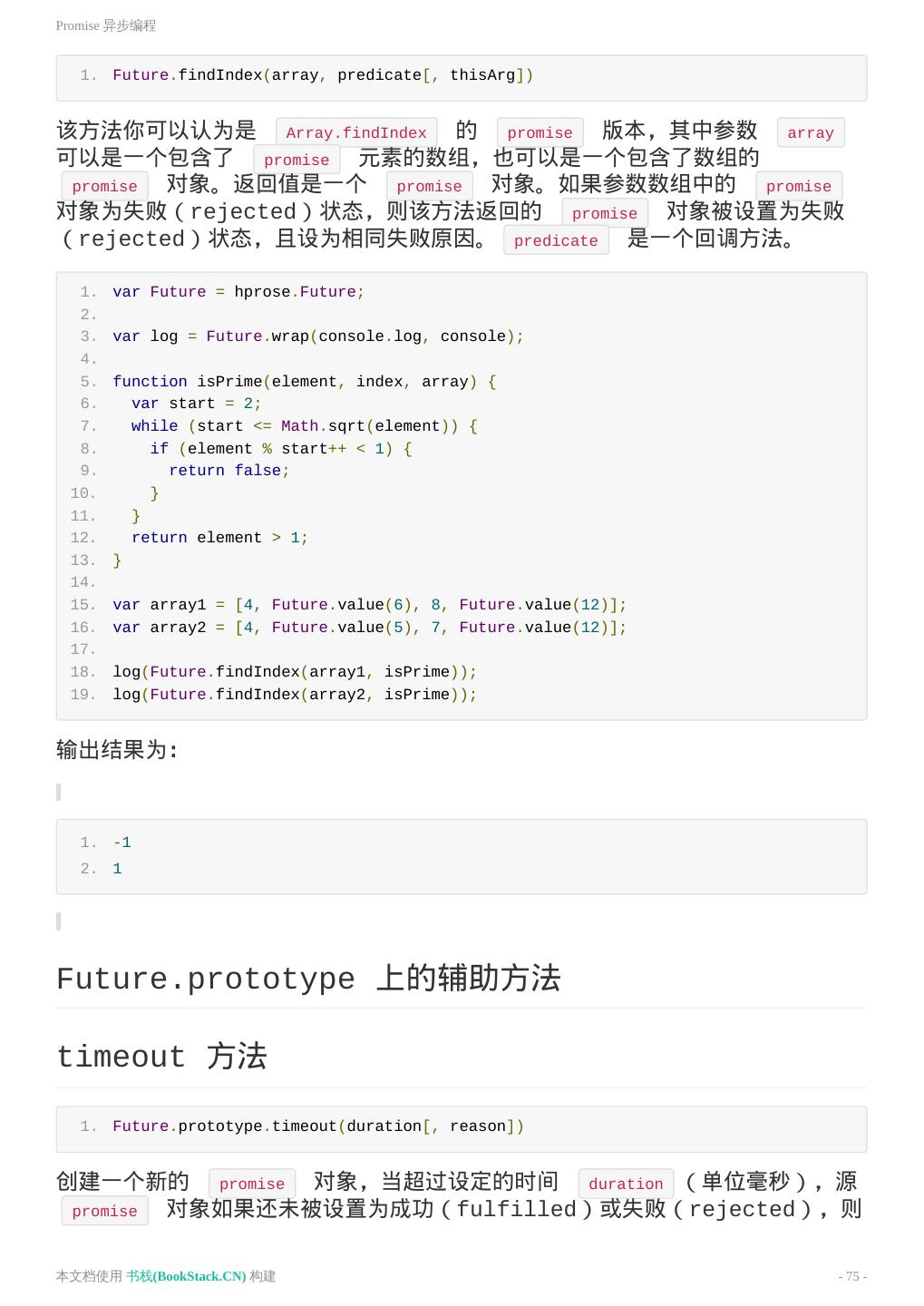
29 .Hprose 客户端 链式调用 因为 invoke 方法的返回值是一个 promise 对象,因此它可以进行链式调用, 例如: 1. var client = hprose.Client.create('http://www.hprose.com/example/', ['sum']); 2. client.sum(1, 2) 3. .then(function(result) { 4. return client.sum(result, 3); 5. }) 6. .then(function(result) { 7. return client.sum(result, 4); 8. }) 9. .then(function(result) { 10. console.log(result); 11. }); 该程序的结果为: 1. 10 更简单的顺序调用 前面我们讲过,当使用方法名调用时,远程调用的参数本身也可以是 promise 对象。 因此,上面的链式调用还可以直接简化为: 1. var client = hprose.Client.create('http://www.hprose.com/example/', ['sum']); 2. client.sum(client.sum(client.sum(1, 2), 3), 4).then(function(result) { 3. console.log(result); 4. }); 这比上面的链式调用更加直观。尤其是当一个调用的参数依赖于其它几个调用的结 果时候,例如: 1. var hprose = require('hprose'), 2. wrap = hprose.Future.wrap, 3. client = hprose.Client.create('http://www.hprose.com/example/', ['sum']), 4. log = wrap(console.log, console), 5. r1 = client.sum(1, 3, 5, 7, 9), 6. r2 = client.sum(2, 4, 6, 8, 10), 7. r3 = client.sum(r1, r2); 8. log(r1, r2, r3); 本文档使用 书栈(BookStack.CN) 构建 - 29 -
3秒后跳转登录页面
去登陆

