





























































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Modern Main-Memory Database Systems
现代内存数据库研究已经存在很多年了,本文作者在2016年的VLDB上对MM-DB进行了一些分析,可以说是现代内存数据库研究方向的总结,这篇文章以SQL Server Hekaton, SAP HANA, HyPer, H-Store/VoltDb 为背景:介绍内存数据库的历史以及现代硬件技术的更新,详细描述了架构选择和相关问题探讨:数据组织,索引,分布式与集群,同步控制,持久化与故障恢复,高可用,查询处理与编译,数据(实时)分析,也探讨了数据库领域的新的研究趋势,非易失内存,硬件事务性内存,冷数据管理,RDMA等快速网络互联等课题。
展开查看详情
1 .Modern Main-Memory Database Systems Paul Larson | Justin Levandoski Microsoft 9/9/2016 MM-DB Tutorial VLDB 2016 1
2 .Tutorial Overview Main-memory database research has been going on for a long time Only recently do we have a number of general-purpose commercial main-memory databases This tutorial focuses on modern main-memory database design, with examples primarily from: SQL Server Hekaton SAP HANA HyPer H-Store/VoltDb Associated survey/book to appear: Faerber, Kemper, Larson, Levandoski, Neumann, and Pavlo. Modern Main Memory Database Systems in Foundations and Trends in Database Systems. Ask Questions! 9/9/2016 MM-DB Tutorial VLDB 2016 2
3 .Outline Introduction Overview Historical Overview Modern Hardware Environment Issues and Architectural Choices Data organization Indexing Distribution and Clustering Concurrency control Durability and recovery High availability Query processing and compilation Supporting operational (real-time) analytics 9/9/2016 MM-DB Tutorial VLDB 2016 3 Research Trends Non-volatile memory Hardware transactional memory Cold-data management RDMA/Fast networks Time Permitting Other systems Longer historical overview
4 .Historical Overview Summary of previous research in main-memory database systems 9/9/2016 MM-DB Tutorial VLDB 2016 4
5 .Historical Overview: 1984 - 1994 Assume buffer pool fits in memory Group commit/fast commit optimizations from University of Wisconsin IMS Fastpath memory-resident optimizations Direct memory access to records Main-memory optimized indexing methods (T-Trees) Durability and recovery Functional partitioning of engine into runtime processor and recovery processor Redo-only logging: avoid space overhead for undo bytes Partitioned main-memory databases (PRISMA) Concurrency Course-grained locking 9/9/2016 MM-DB Tutorial VLDB 2016 5
6 .Historical Overview: 1994 - 2005 Commercial systems targeting specialized workloads (e.g., telecom) Dali from Bell Labs, later DataBlitz ClustRa HP Smallbase, later TimesTen Multi-core optimizations P*-Time Lock-free implementation techniques 9/9/2016 MM-DB Tutorial VLDB 2016 6
7 .Previous Techniques in the Modern Era (Spoiler Alert) Direct memory pointers vs buffer pool indirection (e.g., MM-DBMS) Modern systems avoid page based indirection for performance reasons Data partitioning Some modern systems like H-Store/VoltDB choose to partition the database (e.g., across cores, machines) Lock-free (as much as possible), cache-conscious data structures Coarse-grain locking (e.g., Starburst Memory Resident Storage) Possibly OK on early systems due to few cores Not used today due to bottlenecks with raw parallelism on modern machines (as we will see) Lock-based concurrency control is in fact rare in modern systems Functional partitioning (e.g., MARS, System M, TPK) Functional handoff between threads (input, output, recovery duties, durability) is not done in (most)modern systems 9/9/2016 MM-DB Tutorial VLDB 2016 7
8 .The Modern Hardware Environment Hardware trends that enable the modern breed of main-memory database systems 9/9/2016 MM-DB Tutorial VLDB 2016 8
9 .RAM Prices 9/9/2016 MM-DB Tutorial VLDB 2016 9 RAM prices have made a precipitous fall since the previous era of main-memory database systems 2015 average price per GB of RAM: $4.37 http://www.statisticbrain.com/average-historic-price-of-ram/
10 .RAM Sizes Servers can be configured with up to 12TB of RAM Lenovo System x3950 X6 Non-clustered TPC-H@30,000GB w/ SQL Server 12TB of RAM 144 processor cores This size can accommodate most OLTP databases 9/9/2016 MM-DB Tutorial VLDB 2016 10 https://lenovopress.com/lp0502-x3950-x6-tpch-30tb-benchmark-result-2016-05-02
11 .RAM Sizes Servers can be configured with up to 12TB of RAM Lenovo System x3950 X6 Non-clustered TPC-H@30,000GB w/ SQL Server 12TB of RAM 144 processor cores This size can accommodate most OLTP databases 9/9/2016 MM-DB Tutorial VLDB 2016 10 https://lenovopress.com/lp0502-x3950-x6-tpch-30tb-benchmark-result-2016-05-02
12 .Main-Memory Optimizations 9/9/2016 MM-DB Tutorial VLDB 2016 12 OLTP Through the Looking Glass, and What we Found There SIGMOD, pp. 981-992, 2008 Where are the optimization opportunities in main-memory database systems? Remove overheads of Buffer pool Lock manager Making progress in eliminating runtime recovery overhead Records live in memory, but still need to log to Disk/SSD NVRAM will help greatly (more later) Aggressive compilation All transactions/queries compiled to byte code; no interpretation Scalable high-performance indexing methods Latch-freedom coupled with memory-optimized layout
13 .Data Organization 9/9/2016 MM-DB Tutorial VLDB 2016 13
14 .Disk-Based Relational System Classical disk-based relational systems page data to and from disk on demand Pages are fixed-size blocks (e.g., 8KB) Storage engine manages buffer pool Page frames are in-memory representation of page Hash table maps page id to location in pool If page is not in memory, disk I/O needed to populate a target page frame Elegant solution for abstracting disk away from other layers of the database stack Too much overhead for main-memory systems 9/9/2016 MM-DB Tutorial VLDB 2016 14 Frame 1 Frame 2 Frame 3 Frame 4 Frame 5 Frame 6 Frame 7 Frame 8 Frame 9 Pages on disk Buffer pool with page frames Hash table
15 .Main-Memory Database Systems Data lives in RAM in main-memory databases; no need to page from disk Modern systems avoid page indirection through buffer pool Avoid logical record identifiers: (page id, offset) Common practice to use in-memory pointers for direct record access Can result in order of magnitude performance improvements Avoids page-based indirection to resolve record pointer Avoids page latch overhead 9/9/2016 MM-DB Tutorial VLDB 2016 15
16 .Avoiding Page Indirection Classic relational architectures require two layers of indirection to resolve pointer to record Hash table access to resolve page frame in buffer pool Calculate pointer to record using offset within page No indirection in modern main-memory systems Internal structures like indexes store memory pointers Early experimental evaluation from the Starburst main-memory project revealed order or magnitude performance improvement by removing buffer pool 9/9/2016 MM-DB Tutorial VLDB 2016 16 page-id hash table page frame B-tree node key, page-id key, page-id record* B-tree node key, record* key, record* record record
17 .Avoiding Page Latching Accessing a page in a classical database design requires latch on page frame Readers: shared latch Writers: update latch (possibly exclusive) Latching leads to overhead for main-memory data Internal manipulation of latch requires atomic operation Shared read latch: update of reference count Update latch: variable to mark exclusion Commercial systems have several latch types, so thread could end up acquiring several latches! Most commercial systems use partitioned latches to help situation (does not completely overcome the bottleneck) SQL Server Hekaton achieves a 15.7x performance boost Hekaton is a completely latch-free design Scalability of classic engine limited by latch overhead 9/9/2016 MM-DB Tutorial VLDB 2016 17 buffer pool read read update update atomic_cas(latch) atomic_increment(readers)
18 .Organization Choices Partitioning Partitioned systems : Disjoint partitioning of the database, assign partition to node, core, etc. Simple per-node implementation (serial execution, no concurrent data structures) Partition management burden: rebalance for hotspots Non-partitioned systems : Any thread/core can access any record in the database Self-balancing system: no need to worry about partition management Increased implementation complexity (e.g., concurrent data structures) Multi-Versioning Allows for high concurrency; important in multi-core environments Readers allow to execute uncontested, do not block writers Row/Columnar Layout Reasonable OLTP performance on in-memory columnar layout; not true for disk-based column stores 9/9/2016 MM-DB Tutorial VLDB 2016 18
19 .Organization Choices 9/9/2016 MM-DB Tutorial VLDB 2016 19 Partitioned Multi-Versioned Row/Columnar Hekaton No Yes Row HyPer No Yes Hybrid SAP HANA No Yes Hybrid H-Store/VoltDB Yes No Row
20 .Organization Choices 9/9/2016 MM-DB Tutorial VLDB 2016 19 Partitioned Multi-Versioned Row/Columnar Hekaton No Yes Row HyPer No Yes Hybrid SAP HANA No Yes Hybrid H-Store/VoltDB Yes No Row
21 .H-Store/VoltDB Partitioned system Distributes data across compute nodes (or cores) in shared-nothing configuration Serial execution at partitions: avoids concurrency control and find-grained locks Two-tiered architecture Transaction coordinator Execution engine: data storage, indexing, and transaction execution. Single-version Row Store Execution engines maintain single version of records (snapshots supported) Storage divided into pools for fixed-size and variable-size blocks, with fixed-pool as primary storage All tuples are fixed size (per table) to ensure they remain byte-aligned Fields larger than 8-bytes stored as variable-length blocks, all other fields stored inline in tuple (1 byte for snapshotting) Lookup table translates block id (4 bytes) to physical location (8 bytes), allows engine to address blocks using 4 bytes. 9/9/2016 MM-DB Tutorial VLDB 2016 21
22 .HyPer (2011) Partitioned System Database partitioned across cores in shared-nothing configuration Serial execution of transactions within a partition Single versioned OLTP workloads work on single-version database OLAP queries run over virtual memory snapshot using fork Forked snapshot taken between transaction for consistency Row and Column support HyPer can be configured as either a row or column store Initial implementation reported numbers as a pure column store 9/9/2016 MM-DB Tutorial VLDB 2016 22 HyPer: A Hybrid OLTP&OLAP Main Memory Database System based on Virtual Memory Snapshots ICDE, pp. 195-206, 2011 Partition 1 Partition 2 Partition 3 OLTP Transactions single-threaded execution within partition OLAP Queries OLAP Queries VM Snapshot VM Snapshot
23 .HyPer (current) Not partitioned Any transaction can touch any record due to changes in concurrency control Versioned OLAP queries still run over virtual memory snapshots Support transient per-record undo buffers to support multiple versions for concurrency control (more on concurrency later) Hybrid row/column layout HyPer explored a hybrid record layout that clustered frequently-accessed columns together Most commonly configured as a column store in most experiments 9/9/2016 MM-DB Tutorial VLDB 2016 23 Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems SIGMOD, pp. 677-689, 2015 Ada Bob Cid Dan Etta Fran Gene Hoss Ivan Jill Kent Larry 10 60 25 60 30 10 25 20 35 20 25 5 100,Bal, 70 105,Bal, 45 105,Bal, 40 Version Vector Name Col Balance Col Undo Buffer Undo Buffer
24 .HyPer Data Blocks Immutable cold data storage Only deletes are possible with tombstones OLTP and OLAP friendly Occasional point lookup for OLTP Mostly OLAP scans Features Min/Max per attribute for skipping during scans SARGable evaluation on compressed data using SIMD Positional small materialization aggregates (SMAs) serve as lightweight index to find ranges within block Integrated with JIT-compiled query pipeline 9/9/2016 MM-DB Tutorial VLDB 2016 24 Data Blocks: Hybrid OLTP and OLAP on Compressed Storage using both Vectorization and Compilation SIGMOD, pp. 311-326, 2016 Min 0 Max 0 Positional SMA 0 (lightweight index) Dictionary 0 Compressed Data 0 String Data 0 Min 1 Max 1 Positional SMA 1 (lightweight index) Dictionary 1 Compressed Data 1 String Data 1 …
25 .SAP HANA Not partitioned Any thread can access any record Versioned Internally, records go through lifetime management (row-to-column) Versioning persists throughout entire lifetime Hybrid storage format Three stages of physical record representation L1-Delta: Write-optimized row format, no data compression (10K to 100K rows per node) L2-Delta: Column format, unsorted dictionary encoding (~10M rows) Main: Column format, highly compressed and sorted dictionary encoding More on conversion/merge steps in hybrid OLTP/OLAP section 9/9/2016 MM-DB Tutorial VLDB 2016 25 Efficient Transaction Processing in SAP HANA Database: the End of a Column Store Myth SIGMOD, pp. 731-742, 2012 Unified Table L1-Delta Row Store L2-Delta Column Store Main Column Store Write Optimized Read Optimized
26 .Indexing 9/9/2016 MM-DB Tutorial VLDB 2016 26
27 .Overview Cache-awareness Since the mid-90’s CPU and RAM speed gap has been an issue Indexing techniques created to keep as much data in CPU cache as possible Still relevant today Multi-core and multi-socket parallelism Modern multi-core machines have massive amount of raw parallelism Current focus is to enable high performance parallel indexing methods 9/9/2016 MM-DB Tutorial VLDB 2016 27
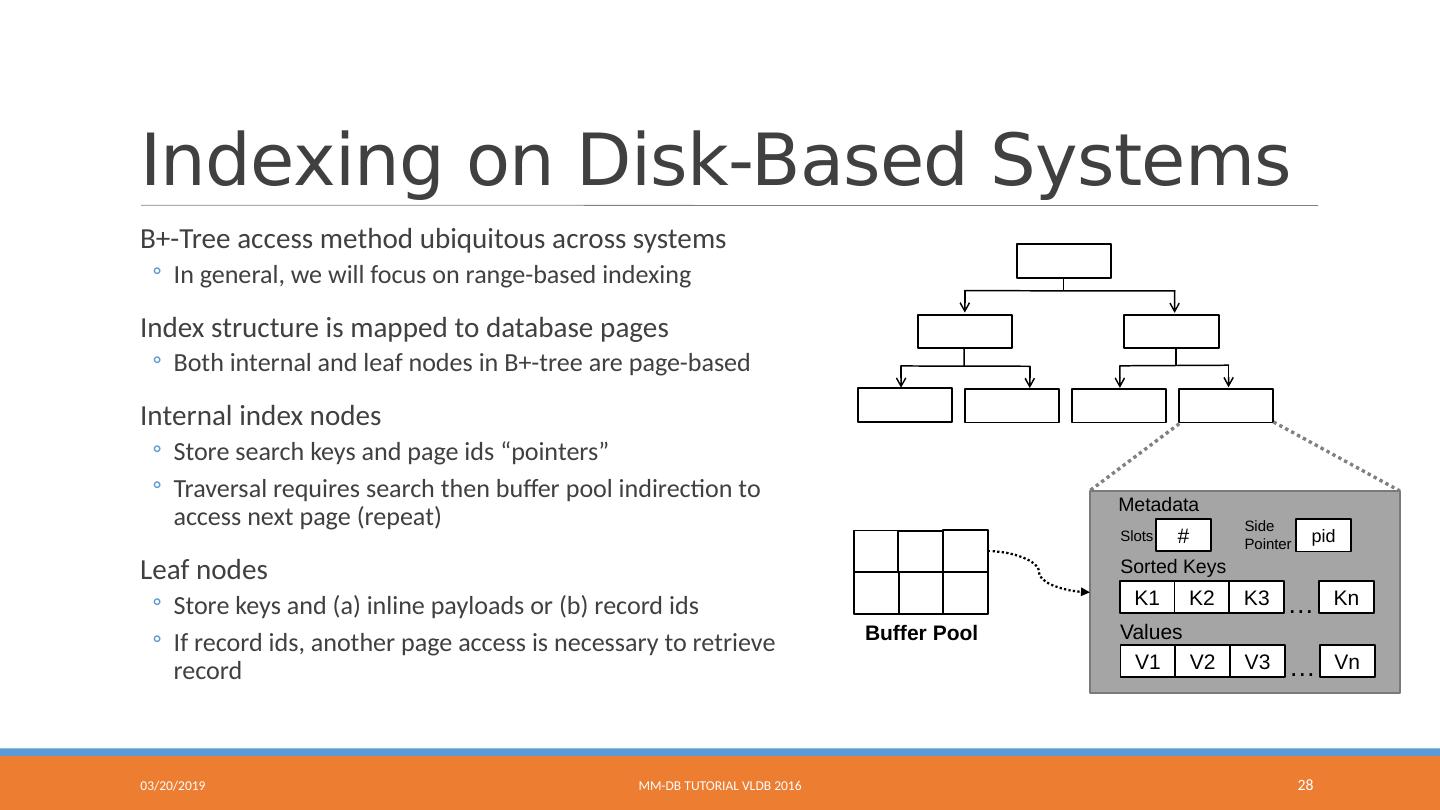
28 .Indexing on Disk-Based Systems B+-Tree access method ubiquitous across systems In general, we will focus on range-based indexing Index structure is mapped to database pages Both internal and leaf nodes in B+-tree are page-based Internal index nodes Store search keys and page ids “pointers” Traversal requires search then buffer pool indirection to access next page (repeat) Leaf nodes Store keys and (a) inline payloads or (b) record ids If record ids, another page access is necessary to retrieve record 9/9/2016 MM-DB Tutorial VLDB 2016 28 K1 K2 K3 … Kn V1 V2 V3 Sorted Keys Vn … Values Metadata # Slots pid Side Pointer Buffer Pool
29 .T-Trees: Space Savings in a Main-Memory Environment Index in the MM-DBMS project at U. Wisconsin (1986) Based on AVL tree; nodes store record pointers, sorted by key value for that node Comparison/search requires pointer dereference to retrieve full key Internal nodes index data; similar to B-Tree, not a B+-Tree Min/Max boundary values define key space for a node Advantages Low memory overhead (important in 80s) Disadvantages Rebalance, scans, pointer dereference (though less pronounced today due to cpu vs. cache speed of the 80s) Used in early commercial main-memory systems (e.g, TimesTen) 9/9/2016 MM-DB Tutorial VLDB 2016 29 parent min max Record pointers A Study of Index Structures for a Main Memory Database Management System VLDB, pp. 294-303, 1986 Slide material borrowed from A. Pavlo: http://15721.courses.cs.cmu.edu/spring2016/slides/06.pdf 1 2 3 4 5 6 7 key space (low high) 1 2 3 4 5 6 7
3秒后跳转登录页面
去登陆

