展开查看详情
1 .TDengine © TAOS Data, Inc. All rights reserved. 专 为物联网而生的大数据平台
2 .大数据时代 数据采集 后被源源不断的发 往云端 © TAOS Data, Inc. All rights reserved.
3 .4 通常将开源的 Kafka, Redis, Hbase , MongoDB, Cassandra, ES, Hadoop, Spark , Zookeeper 等大数据软件拼装起来,利用集群来处理海量数据。 开发效率低 因牵涉到多种系统,每种系统有自己的开发语言和工具,开发精力花在了系统联调上,而且数据的一致性难以保证 运维复杂 每个系统都有自己的运维后台,带来更高的运维代价,出问题后难以跟踪解决,系统的不稳定性大幅上升 运行效率差 非结构化数据技术来处理结构化数据,整体性能不够,系统资源消耗大。因为多套系统,数据需要在各系统之间传输,造成额外的运行代价 应用推向市场慢 集成复杂,得不到专业服务,项目实施周期长,导致人力攀升,利润缩水 通用大数据方案的挑战:低效、复杂、高成本
4 .所有采集的数据都是时序的 数据都是结构化的 一个采集点的数据 源是唯一的 数据很少有更新或删除操作 数据一般是按到期日期来删除的 物联网、工业 4.0 数据特征:时序空间数据 采集的数据量巨大,但有典型特征 : 数据以写操作为主,读操作为辅 数据流量平稳,可以较为准确的计算 数据都有统计、聚合等实时计算操作 数据一定是指定时间段和指定区域查找的 数据量巨大,一天的数据量就超过 100 亿条 1 2 3 4 6 7 8 9 © TAOS Data, Inc. All rights reserved. 5 10
5 .TDengine 应运而生 © TAOS Data, Inc. All rights reserved.
6 .TDengine 提供的 主要 功能 © TAOS Data, Inc. All rights reserved. 实时数据库 , 历史数据库 , 操作合一透明 缓存 , 所有设备最新记录实时返回 流式计算 , 对一个或多个数据流实时聚合计算 数据订阅 , 最新的数据可实时推送到应用 物联网数据的全栈解决方案
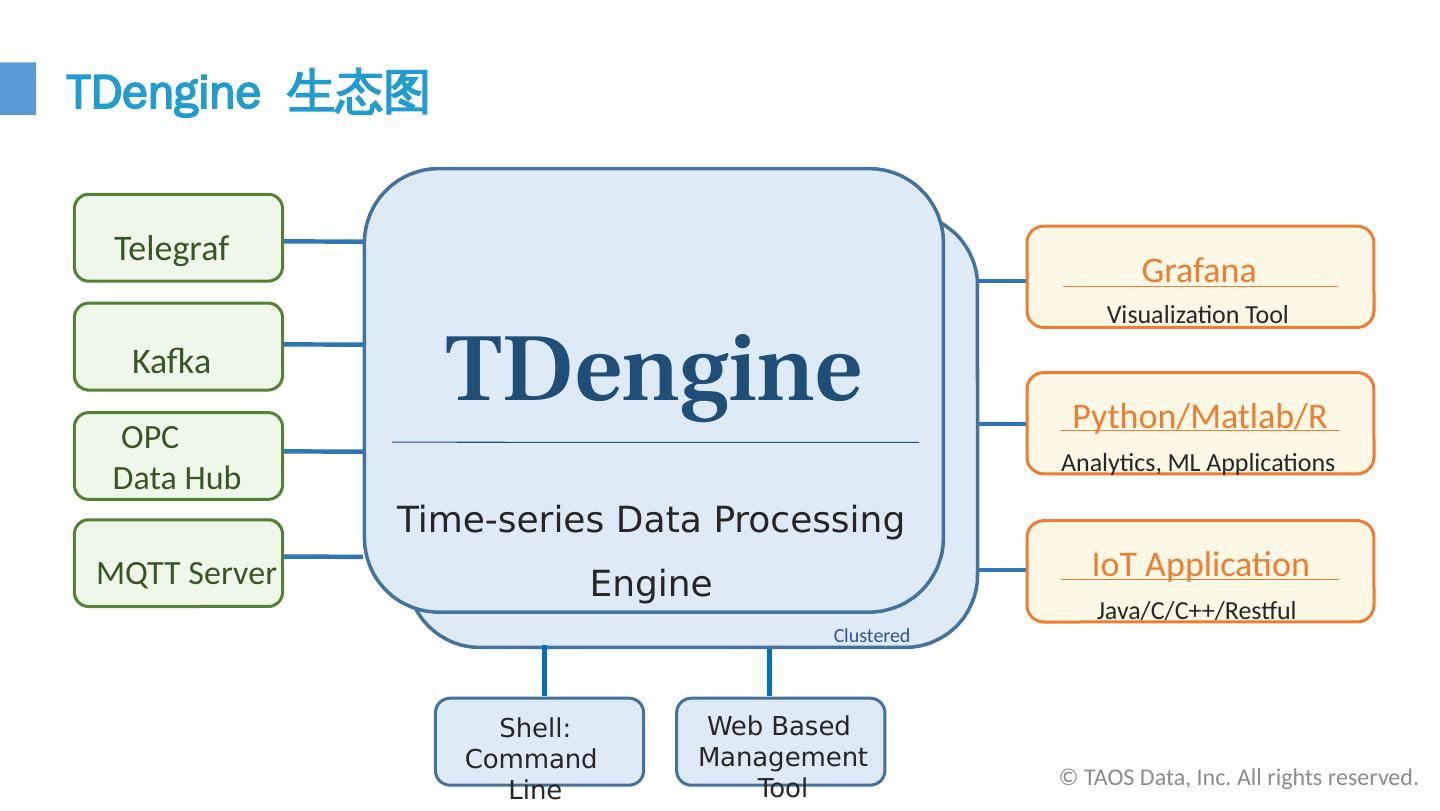
7 .© TAOS Data, Inc. All rights reserved. TDengine 生态图 Shell: Command Line Interface Visualization Tool Grafana Time-series Data Processing Engine TDengine Analytics, ML Applications Python/Matlab/R Java/C/C++/Restful IoT Application Telegraf Kafka OPC Data Hub MQTT Server Web Based Management Tool Clustered
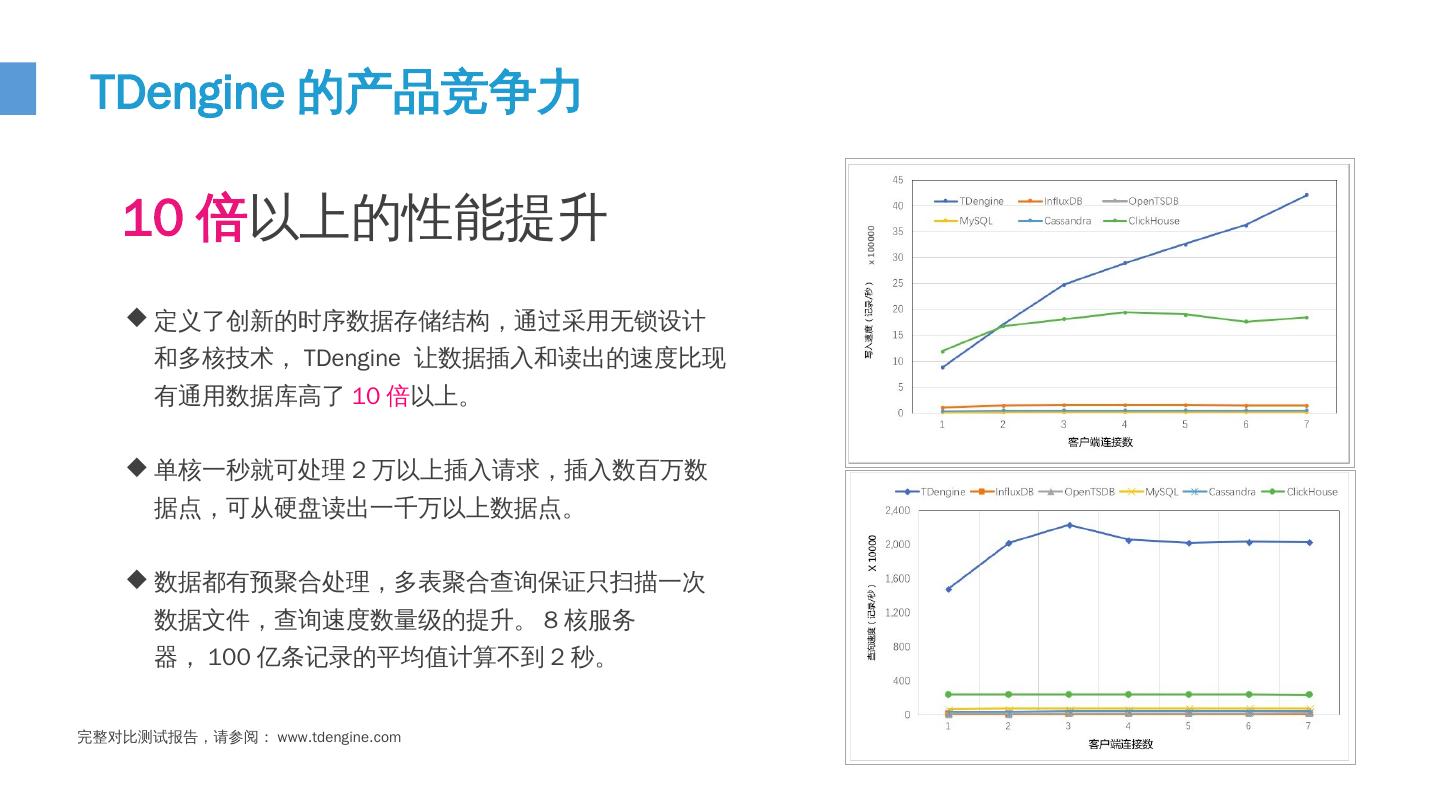
8 .9 定义了创新的时序数据存储结构,通过采用无锁设计和多核技术,TDengine 让数据插入和 读出 的速度比现有通用数据库高了 10倍 以上。 单核一秒就可处理 2 万以上插入请求 , 插入数百万数据点 , 可从硬盘读出一千万以上数据点 。 数据都有预聚合处理 , 多表聚合查询保证只扫描一次数据文件 , 查询速度数量级的提升 。 8 核服务器 , 100 亿条记录的平均值计算不到 2 秒 。 完整对比测试报告,请参阅: www.tdengine.com 10 倍 以上的性能提升 TDengine 的产品竞争力
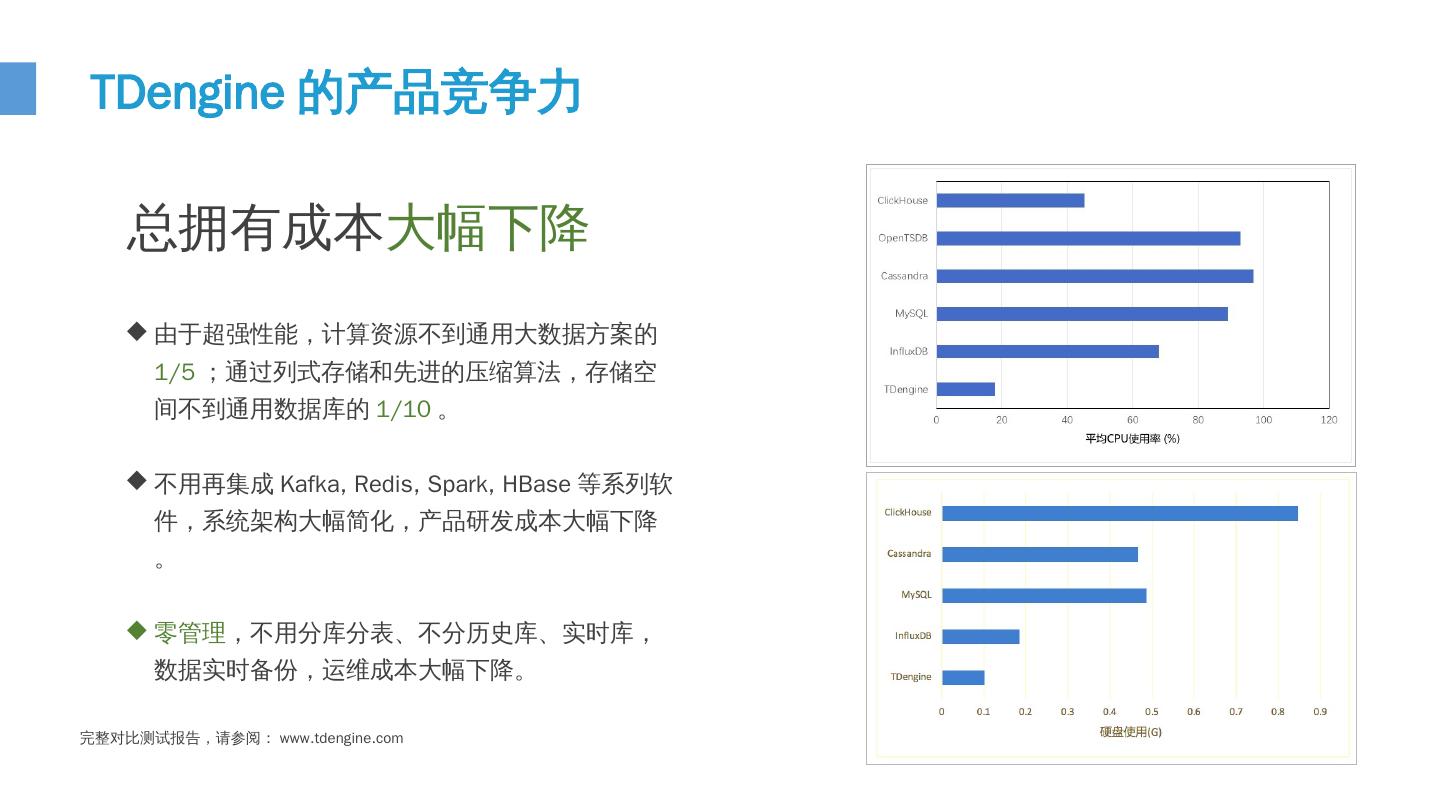
9 .10 由于超强性能,计算资源不到通用大数据方案的 1/5 ;通过列式存储和先进的压缩算法,存储空间不到通用数据库的 1/10 。 不用再集成 Kafka, Redis, Spark, HBase 等系列软件,系统架构大幅简化,产品研发成本大幅下降 。 零管理 , 不用分库分表 、 不分历史库 、 实时库 , 数据实时备份 , 运维成本大幅下降 。 总拥有成本 大幅下降 TDengine 的产品竞争力 完整对比测试报告,请参阅: www.tdengine.com
10 .11 零 学习成本 安装包仅仅 1.5M ,不依赖任何其他软件。 从下载 、 安装到成功运行几秒搞定 使用 标准的 SQL 语法 ,并支持 C/C++, JAVA, GO, Python, RESTful 接口,应用 API 与 MySQL 高度相似,让学习成本几乎为零 无论是十年前还是一秒钟前的数据,指定时间范围即可查询。数据可在时间轴或多个设备上进行聚合。临时查询可通过 Shell/Python/R/ Matlab 随时进行 与第三方工具 Telegraf , Grafana, Matlab , R 等无缝链接 create database demo; use demo; create table t1( ts timestamp, degree float); insert into t1 values(now, 28.5); insert into t1 values(now, 29.0); select * from t1; select avg (degree), count( * ) from t1; TDengine 的产品竞争力
11 .TDengine 应用领域 上网记录、通话记录 交易记录 、 卡口数据 智能电表、 水表 、 气表 电网 、 管道 、 智慧城市 服务器 / 应用监测 用户访问日志、广告点击日志 火车 / 汽车 / 出租 / 飞机 自行车的实时监测 电梯 、 锅炉 、 机床 机械设备 实时监测 © TAOS Data, Inc. All rights reserved. 天气、空气、水文 地质环境监测
12 .© TAOS Data, Inc. All rights reserved. TDengine 技术介绍
13 .C/C++ Java 、 Python Client 接口 REST API Client 接口 SPARK Hadoop 接口 Meter 数据采集点 DBA Tool 引擎管理工具 Meter 数据采集点 TDengine Cluster TDengine 对外接口 © TAOS Data, Inc. All rights reserved.
14 .TDengine 系统结构 © TAOS Data, Inc. All rights reserved. V0 V1 V3 dnode 7 V0 V1 V3 M0 V0 V1 V3 V2 V0 V1 V3 V2 dnode 0 V0 V1 V3 V2 dnode1 dnode 2 dnode 3 V0 V1 V2 dnode 4 V0 V1 M1 V2 dnode 5 V0 V2 V3 V1 dnode 6 M2 V3
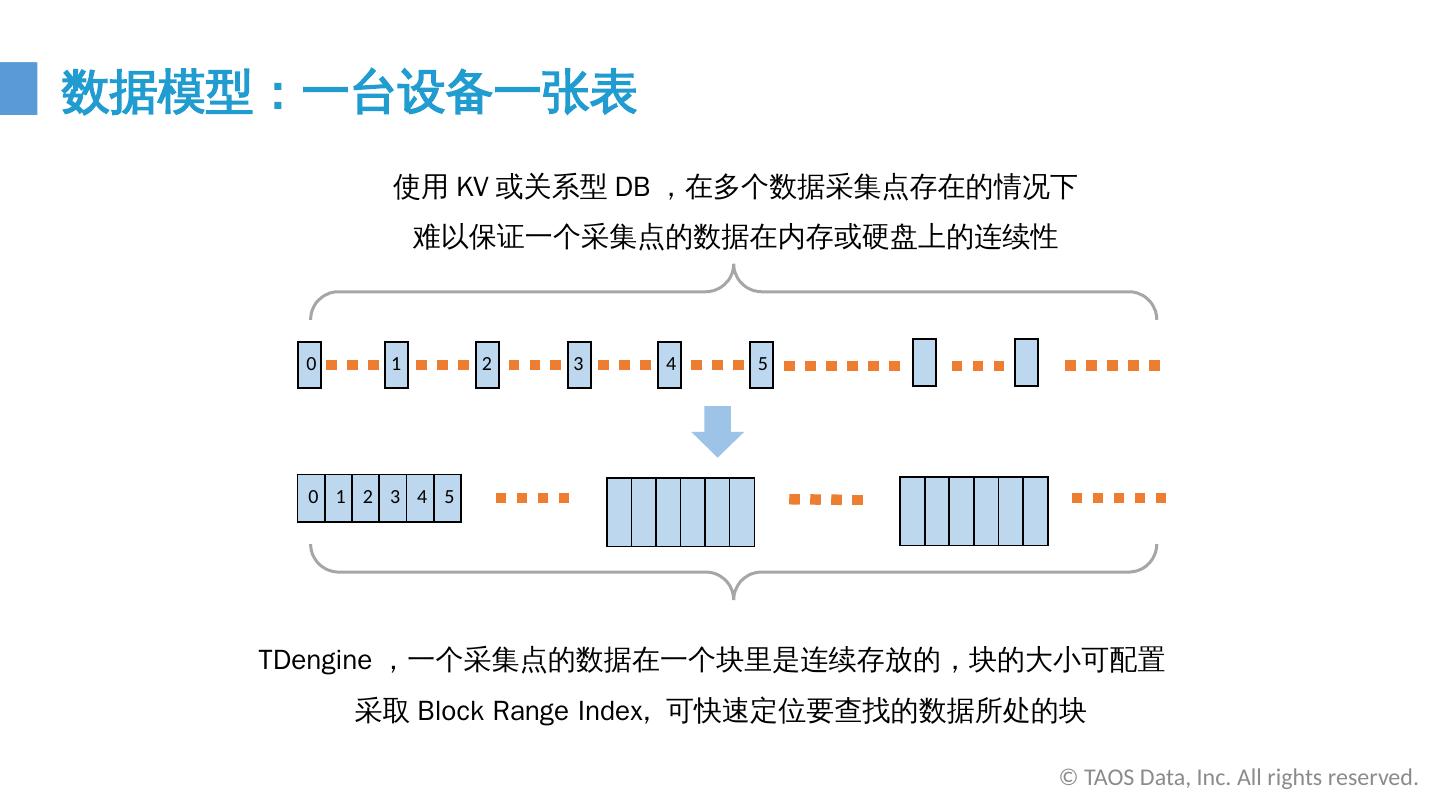
15 .使用 KV 或关系型 DB , 在多个数据采集点存在的情况下 难以保证一个采集点的数据在内存或硬盘上的连续性 TDengine , 一个采集点的数据 在一个块里是连续存放的,块的大小可配置 采取 Block Range Index, 可快速定位要查找的数据所处的块 0 1 2 3 4 5 0 1 2 3 4 5 数据模型 : 一台设备一张表 © TAOS Data, Inc. All rights reserved.
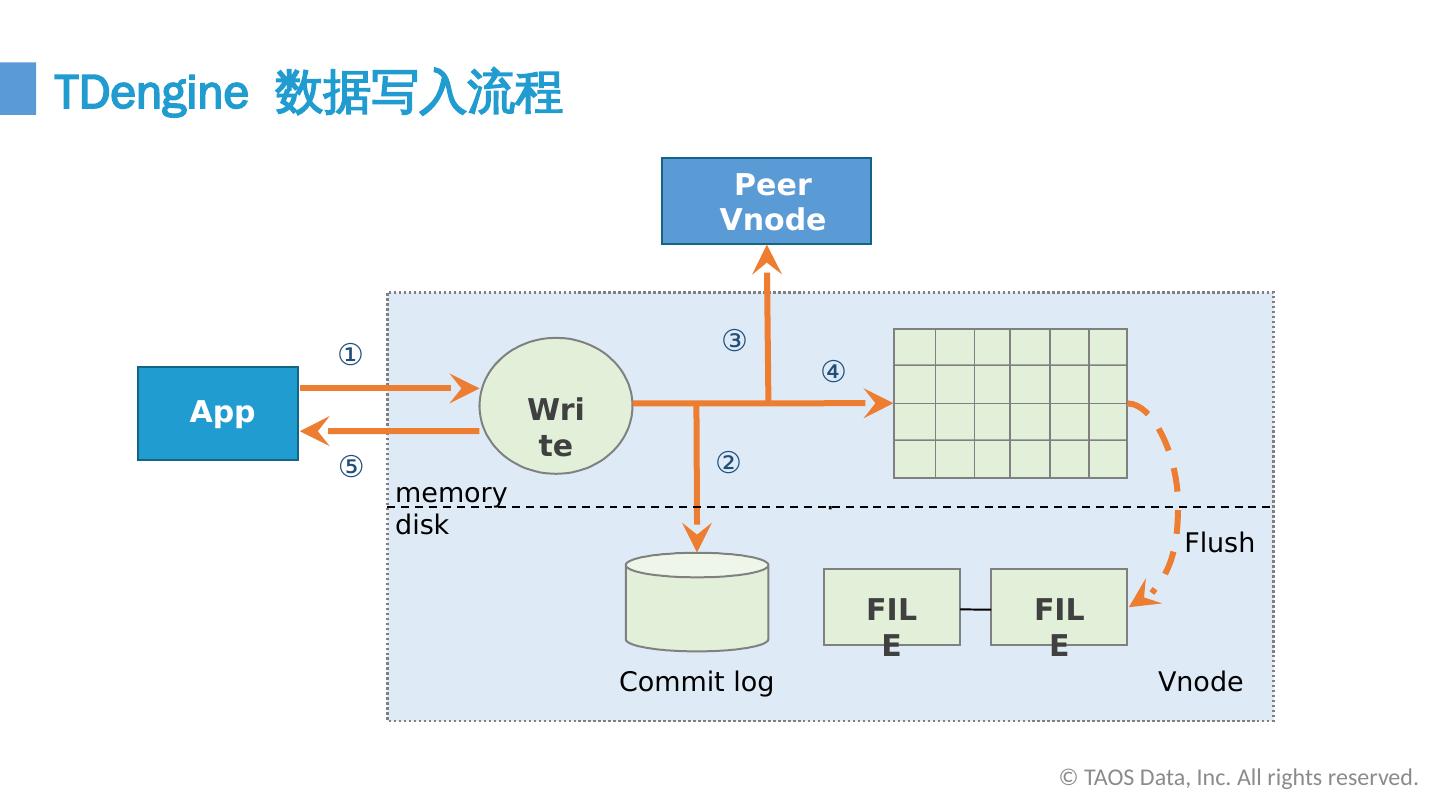
16 .· ① ⑤ Write App ③ ④ ② memory disk Commit log Vnode FILE FILE Peer Vnode Flush TDengine 数据写入流程 © TAOS Data, Inc. All rights reserved.
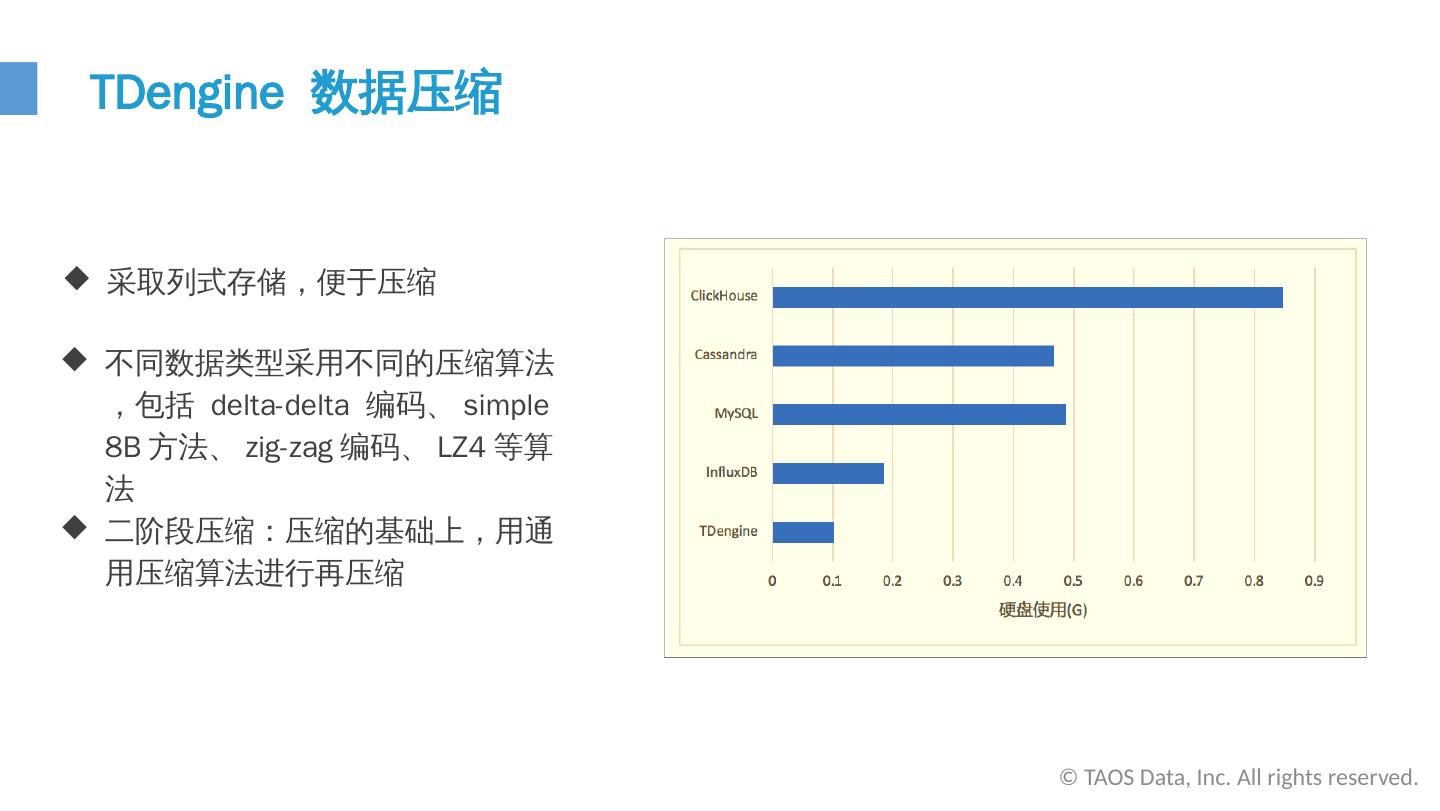
17 .TDengine 数据 压缩 © TAOS Data, Inc. All rights reserved. 采取列式存储 , 便于压缩 不同数据类型采用不同的压缩算法,包括 delta-delta 编码、 simple 8B 方法、 zig-zag 编码、 LZ4 等算法 二阶段压缩 : 压缩的基础上 , 用通用压缩算法进行再压缩
18 .TDengine 单个采集点数据插入、查询示例 © TAOS Data, Inc. All rights reserved. 与传统关系型数据库一样,采用 SQL 语法,应用需先创建库,然后建表,就可以插入、查询 create database demo; use demo; create table t1 ( ts timestamp, degree float); insert into t1 values(now, 28.5); select * from t1; 上述 SQL 为一个温度传感器创建一张表,并插入一条记录、然后查询
19 .TDengine 超级表 :多个采集点的数据聚合 © TAOS Data, Inc. All rights reserved. STable ( 超级表 )是表的集合,包含多张表,而且每张表的 schema 是一样的。同一类型的采集设备可以是一个 STable ,除定义 Schema 外 , 还可定义多个标签。标签定义表的静态属性,如设备型号、颜色等。具体创建表时,指定使用哪个 STable (采集点的类型),并指定标签值。 应用可以象查询表一样查询 STable , 但可以通过标签过滤条件查询部分或全部数据采集点的记录,并且可以做各种聚合、计算等,方便支持复杂查询,应对业务需求。 实际场景中,经常需要将多个采集点数据进行聚合处理,比如所有温度传感器采集的温度的平均值。因为一个传感器就是一张表,这样需要将多张表聚合。为减少应用的复杂性, TDengine 引入 STable 概念。 每个表(采集点)都有对应一行的标签数据,保存在 Meta 节点,而且存放在内存并建有索引。标签数据可以任意增加、删除、修改。标签数据与采集数据完全分离,大大节省存储空间,并提高访问效率。而且对于已经采集的历史数据,事后可以打上新的标签。
20 .TDengine 超级表 实例 © TAOS Data, Inc. All rights reserved. create table thermometer ( ts timestamp, degree float ) tags ( loc binary(20), type int ) ; 为温度传感器建立一个 STable , 有两个标签:位置和类型 create table t1 using thermometer tags (‘ beijing ’, 1); create table t2 using thermometer tags (‘ beijing ’, 2); create table t3 using thermometer tags (‘ tianjin ’, 1); create table t4 using thermometer tags (‘ tianjin ’, 2); create table t5 using thermometer tags (‘shanghai’,1); 用 STable 创建 4 张表 , 对应 4 个温度传感器,地理位置标签为北京、天津、上海等 select max(degree), min(degree) from thermometer where loc =‘ beijing ’ or loc =‘ tianjin ’; 查询北京和天津所有温度传感器记录的最高值和最小值
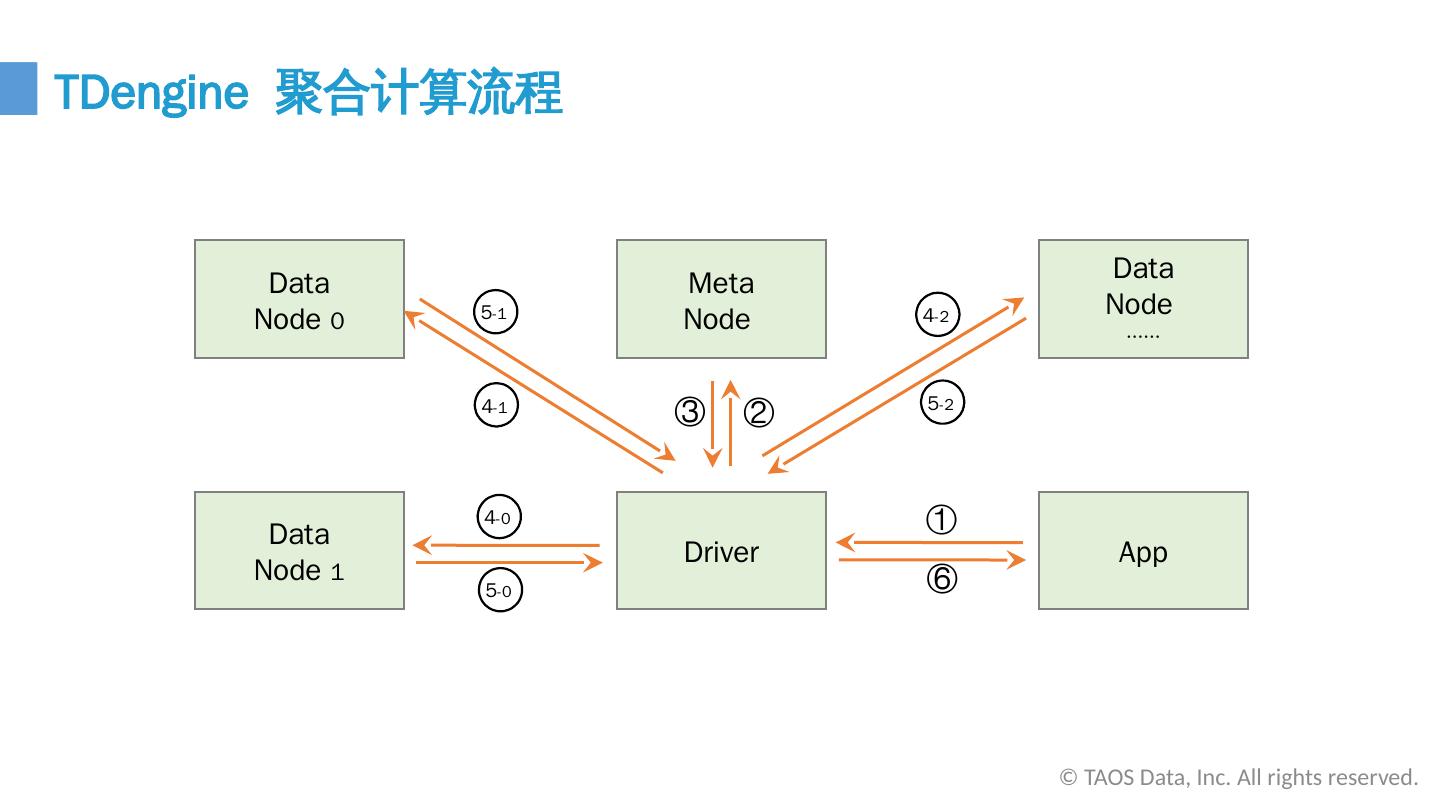
21 .TDengine 聚合计算流程 © TAOS Data, Inc. All rights reserved. Data Node 0 Data Node 1 Meta Node Driver Data Node ······ App ① ⑥ 4 -1 ② ③ 5 -1 4 -0 5 -0 5 -2 4 -2
22 .TDengine 时间轴上的数据聚合 © TAOS Data, Inc. All rights reserved. 实际场景中,经常需要将一段时间的数据进行聚合,比如 downsampling , 采样频率为一秒一次,但最终只记录一分钟的平均值。 TDengine 引入关键词 interval, 以进行时间轴上的聚合操作。时间轴的聚合既可以针对单独一张表,也可以针对符合标签过滤条件的一组表进行。 select avg (degree) from t1 interval (5m); 查询温度传感器 t1 记录的温度每五分钟的平均值 select avg (degree) from thermometer where loc =‘ beijing ’ interval (5m); 查询北京所有温度传感器记录的温度每五分钟的平均值
23 .TDengine 实时 Stream 计算 © TAOS Data, Inc. All rights reserved. 目前支持 Avg, Max, Min, Percentile, Sum, Count, Dev, First, Last, Diff, Scale, WAvg , Spread 等操作。计算是针对时间段,同时可针对一张表或符合过滤条件的一组表进行聚合。 实时计算的衍生数据可以实时写入新的表,方便后续的查询操作。衍生数据还可以与其他原始数据或其他衍生数据进行各种聚合计算,生成新的数据。 select avg (degree) from thermometer where loc =‘ beijing ’ interval (5m) sliding (1m); 每隔一分钟计算北京刚刚过去的五分钟的温度平均值 create table d1 as select avg (degree) from thermometer where loc =‘ beijing ’ interval (5m) sliding (1m); 每分钟计算一次北京刚过去的 5 分钟的温度平均值,并写入新的表 d1
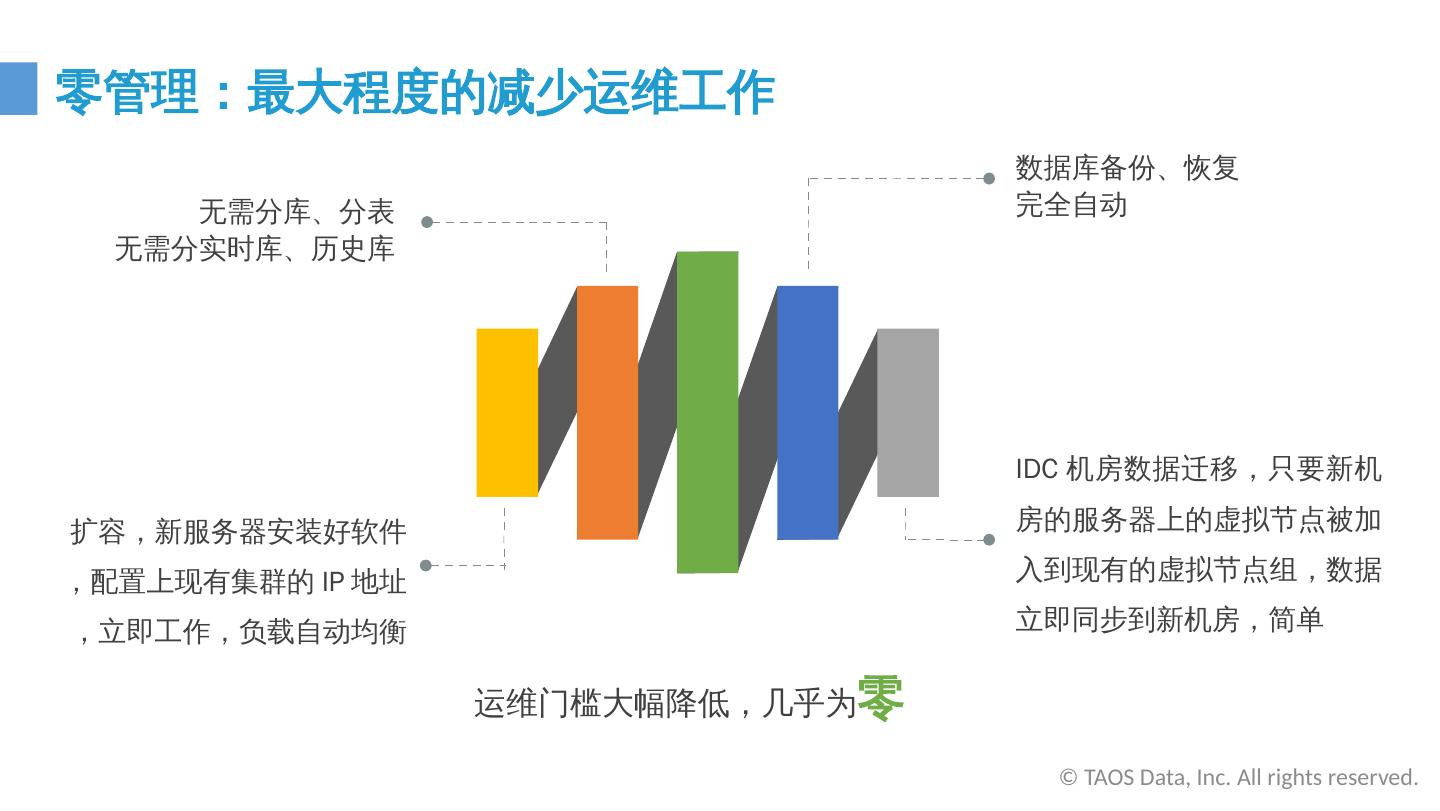
24 .运维门槛大幅降低,几乎为 零 无需分库、分表 无需分实时库、历史库 扩容,新服务器安装好软件,配置上现有集群的 IP 地址,立即工作,负载自动均衡 数据库备份、恢复 完全自动 IDC 机房数据迁移,只要新机房的服务器上的虚拟节点被加入到现有的虚拟节点组,数据立即同步到新机房,简单 零管理:最大程度的减少运维工作 © TAOS Data, Inc. All rights reserved.
25 .陶建辉 (Jeff Tao) jhtao@taosdata.com Weibo : 陶建辉 -Jeff © TAOS Data, Inc. All rights reserved.