


























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
In-Datacenter Performance Analysis of Tensor Processing Unit
Motivation
• Purpose of the paper
• Summary of neural networks
• Overview of the proposed architecture
• Results and comparison between TPU, CPU & GPU
展开查看详情
1 .In-Datacenter Performance Analysis of Tensor Processing Unit Draft Paper Overview
2 . Overview • Motivation • Purpose of the paper • Summary of neural networks • Overview of the proposed architecture • Results and comparison between TPU, CPU & GPU
3 . Motivation • 2006: only a few applications could run on custom H/W (ASIC, FPGA, GPUs) —> thus you could easily find those resources in a datacenter (due to under-utilization) • 2013: predictions on the wide applicability of another computational paradigm called Neural Networks (NN), could double the computation demands on datacenters. • It would be very expensive to increase the GPUs in order to satisfy those needs
4 . Tensor Processing Unit (TPU) • Proposal: Design a custom ASIC for the inference phase of NN (training still happens using GPUs) • Principles: • improve cost-performance by 10X compared to GPUs • simple design for response time guarantees (single-thread, no prefetching, no OOO etc) • Characteristics: • More like a co-processor to reduce time-to- market delays • Host sends instructions to TPU • connected through PCIe I/O bus
5 . Neural Network • Artificial NN approximately simulate the functionality of the brain • Breakthroughs (of “Deep” NNs): • Beat human champion at Go • Decreasing the error in Natural VS artificial neuron • image recognition from 26 to 3.5% • speech recognition by 30% over other approaches
6 .Neural Networks Structure • Artificial neurons are divided into layers • Three kind of layers: • Input Layer • Hidden Layer(s) • Output Layer • “Deep” NN refers to many layers (higher level of patterns —> better accuracy) • Results may require much computation but: • parallelism can be extracted in-between layers and • all of these computation follow the pattern of multiply and add
7 . Neural Network Phases • Two phases of NN: • Inference (prediction) • You can quantize (transform floating points to • Training (calculation of weights) 8-bit integers) • Usually floating point operations • Trade accuracy (addition-multiplication): • 6-13x less energy / area Adapted from https://blogs.nvidia.com/blog/2016/08/22/difference-deep-learning-training-inference-ai/
8 .Popular NN Architectures • 3 Kinds of NNs are popular today: • Multi-Layer Perceptrons (MLP): (fully connected) output of each layer feed into every neuron on the next layer • Convolutional Neural Networks (CNN): each neuron get as input the results of spatial nearby output of the previous layer • Recurent Neural Networks (RNN): some outputs of the previous layer and its previous state
9 . Paper Synopsis • Description and Evaluation of the Tensor Processing Unit (TPU) • By comparing power and performance between the TPU, a GPU and a CPU • Using 6 representative NN applications (see table below).
10 . TPU Block Diagram • The Matrix Multiply Unit (MMU) is the TPU’s heart • contains 256 x 256 MACs • Weight FIFO (4 x 64KB tiles deep) uses 8GB off-chip DRAM to provide weights to the MMU • Unified Buffer (24 MB) keeps activation input/output of the MMU & host • Accumulators: (4MB = 4096 x 256 x 32bit) collect the16 bit MMU products • 4096 (1350 ops/per byte to reach peak performance ~= 2048 x2 for double buffering)
11 . Matrix Multiply Unit • MMU uses a Systolic execution • Using 256x256 MACs that perform 8-bit integer multiply & add (enough for results) • Holds 64KB tile of weights + 1 more tile (hide 256 cycles that need to shift one tile in) • less SRAM accesses • lower power consumption • higher performance • MatrixMultiply(B) A matrix instruction takes a variable-sized B*256 input, multiplies it by a 256x256 constant weight input, and produces a B*256 output, taking B pipelined cycles to complete.
12 .Adapted from Matrix-Multiplication-systolic.pdf
13 .Adapted from Matrix-Multiplication-systolic.pdf
14 . Evaluation • Haswell CPU: 18-cores (no turbo, 2.3GHz with AVX) • K80 GPU: Boost mode of is disabled (enabling it would increases the total cost of ownership, since due to cooling demands they should deploy less GPUs than 8) • Roofline model adapted (from HPC) (assuming the application data does not fit in on-chip memory then you are either memory BW bottlenecked or computation-limited) • Results are normalised per die
15 . TPU micro-bench results Compute limited • Without sufficient operational intensity, a program is memory bandwidth-bound and lives under the slanted part of the roofline.
16 . TPU Micro-bench Breakdown • The table below doesn’t account for host server time, which can be divided into: • running the host share of the application • and talking to the TPU. Stalls due 2 Memory Low utilization
17 . CPU & GPU micro-bench • Inference, in contrast with training, prefers latency over throughput. (end-user facing services) • Response time guarantees is the reason that the applications are generally further below their ceilings than was in the TPU.
18 . Minimalism is a virtue of domain-specific processors • CPU & GPU have higher throughput, which is wasted if they don’t meet the response time limits • TPU is also affected by response time but only at 80% • The single-threaded TPU has none of the sophisticated micro-architectural features that • consume transistors and energy • to improve the average case but NOT the 99th-percentile case. • (no caches, branch prediction, out-of-order execution, multiprocessing, speculative prefetching, address coalescing, multithreading, context switching, and so forth.)
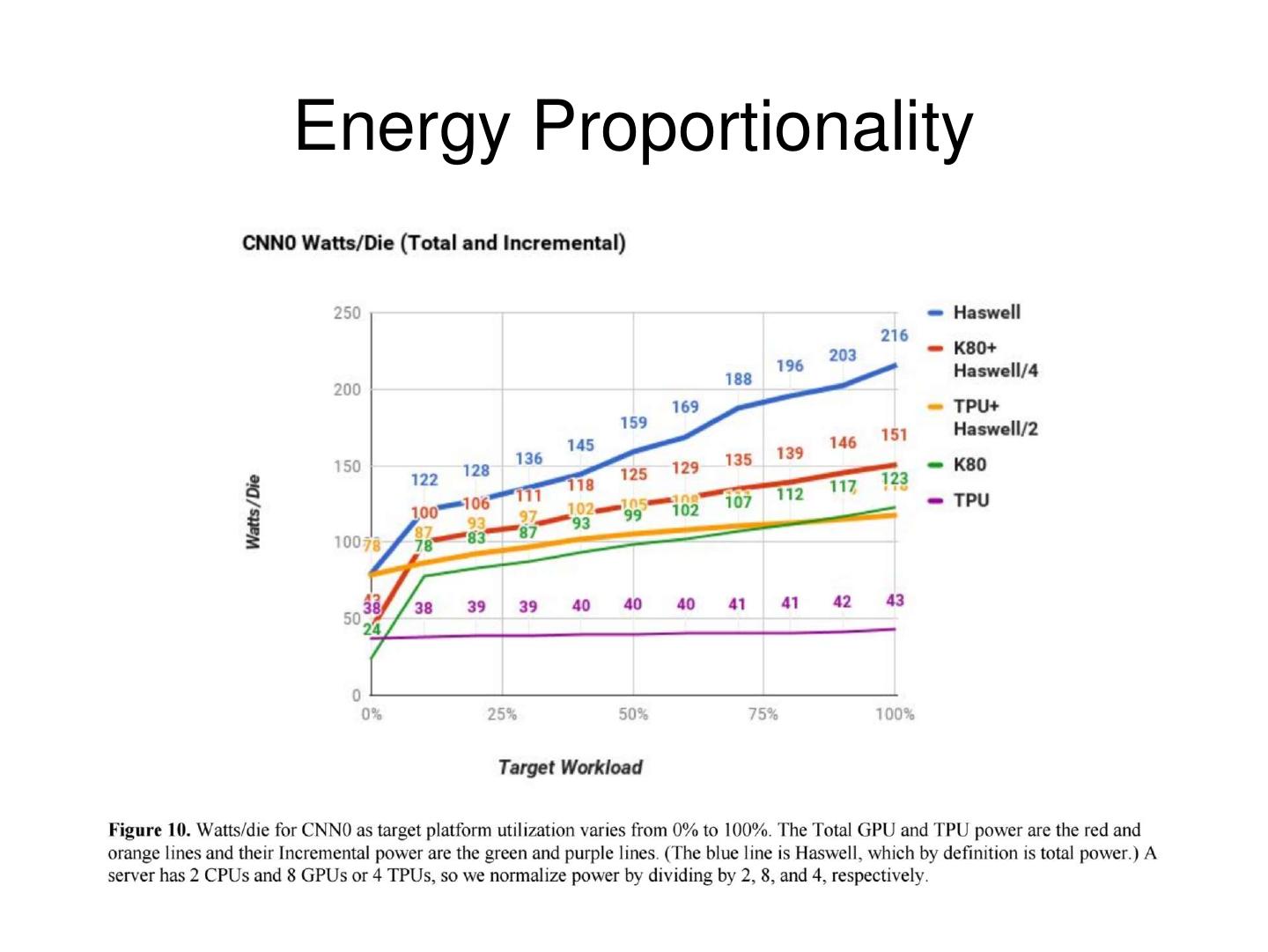
19 .Energy Proportionality
20 . Evaluation of Alternative TPU Design • The graph below is created by a performance model of the TPU for the 6 NN apps which is about 10% accurate compared to the existing TPU results. 4x memory BW —> 3x Avg. performance
21 .Cost-Performance Results
22 . Conclusion • Although most researchers are optimizing CNNs, they represent just 5% of google’s datacenter workload. • Since Inference apps are user-facing, they emphasize response-time over throughput • Due to latency limits, the K80 GPU is just a little faster than the CPU, for inference. • Despite having a much smaller and lower power chip, the TPU has 25 times as many MACs and 3.5 times as much on-chip memory as the K80 GPU. • The TPU is about 15X - 30X faster at inference than the K80 GPU and the Haswell CPU. • Four of the six NN apps are memory-bandwidth limited on the TPU; if the TPU were revised to have the same memory system as the K80 GPU, it would be about 30X - 50X faster than the GPU and CPU. • The performance/Watt of the TPU is 30X - 80X that of contemporary products; the revised TPU with K80 memory would be 70X - 200X better.
23 . TPU vs FPGA • Jouppi says, that the hardware engineering team did look to FPGAs to solve the problem of cheap, efficient, and high performance inference early on before shifting to a custom ASIC. • FPGA vs ASIC: there ends up being a big difference in performance and performance per watt • However, the TPU is programmable like a CPU or GPU, it is not for just one neural network.
24 . NVIDIA response • Unfair comparison (out-dated GPU) • TPU is limited to only Inference phase
25 . References • http://www.cs.iusb.edu/~danav/teach/c463/12_nn.html • https://blogs.nvidia.com/blog/2017/04/10/ai-drives-rise-accelerated- computing-datacenter/ • https://cloudplatform.googleblog.com/2017/04/quantifying-the-performance- of-the-TPU-our-first-machine-learning-chip.html • Draft Paper: https://drive.google.com/file/d/0Bx4hafXDDq2EMzRNcy1vSUxtcEk/view • https://www.nextplatform.com/2017/04/05/first-depth-look-googles-tpu- architecture/ • Systolic Execution: http://web.cecs.pdx.edu/~mperkows/temp/May22/0020.Matrix-multiplication- systolic.pdf
3秒后跳转登录页面
去登陆

