
















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Building a scalable focused web crawler with Flink
能否用Flink构建一个高效的网页爬虫引擎?这个就是我们Flink-Crawler开源项目诞生的动机,我们将会谈到通过AsyncFunction,多次迭代调用等方式来构造一个可伸缩的网页爬虫,这个爬虫可以不间断的高性执行网页爬取工作,幸运的是,我们还不需要对Flink的框架进行额外的修改。当然,我也会重点介绍一些测试和调试中碰到的关于AsyncFunction和多步迭代问题。
展开查看详情
1 . Flink Web Crawler Ken Krugler | President, Scale Unlimited
2 .whoami? • Ken Krugler, Scale Unlimited • Krugle code search startup in 2006 • Lots of big data / web crawl / search projects • Started working with Flink in 2016
3 .What I’m Really Covering • Some advanced features of Flink • AsyncFunctions • Iterations • Abusing state as a DB
4 .The Cover Story • Can I use Flink to build a web crawler? • Scalable - One would hope so • Focused - only fetch the “good stuff” • Efficient - Always Be Crawling • Simple - no other infrastructure
5 .Web Crawling 101
6 .Conceptually Simple Seed URLs URL DB
7 .Conceptually Simple Seed Robots URLs URL DB Checker
8 .Conceptually Simple Seed Robots URLs URL DB Checker Page Fetcher
9 .Conceptually Simple Seed Robots URLs URL DB Checker Page Content Parser Fetcher
10 .It Seemed Too Easy
11 .It Just Worked • But then we needed better performance • Throughput was really stinky • Like a few pages per second, yikes • That’s not the beautiful scaling I want
12 .Massive Parallelism • Functions make HTTP GET calls Robots • Most time spent waiting for response Checker • We need 1000+ active requests/server • Please don’t do this… • fetchStream.setParallelism(1000); Page Fetcher
13 .AsyncFunctions
14 .AsyncFunction DataStream<Result> postRobotsUrls = AsyncDataStream.unorderedWait( preRobotsUrls, new CheckUrlWithRobotsFunction(), 20, TimeUnit.SECONDS); public class CheckUrlWithRobotsFunction extends RichAsyncFunction<FetchUrl, Result> { @Override public void asyncInvoke(FetchUrl url, ResultFuture<Result> futureResult) { …some async stuff happens, and then… futureResult.complete(result); } }
15 .Timeout Failures • A timeout kills the workflow • So make sure client times out • Maybe use Flink timeout as a safety net Caused by: java.util.concurrent.TimeoutException: Async function call has timed out. at AsyncWaitOperator$1.onProcessingTime(AsyncWaitOperator.java:212) at SystemProcessingTimeService$TriggerTask.run(SystemProcessingTimeService.java:249) at Executors$RunnableAdapter.call(Executors.java:511) at FutureTask.run(FutureTask.java:266) at ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
16 .What backpressure? • Async I/O thread handles complete() call • Which means nobody is calling collect() • But that’s what is monitored for back pressure • So UI shows no backpressure, ever
17 .No Side Outputs • No side outputs for AsyncFunctions • But we have multiple outputs Robots Checker Status Page Sitemap Update Fetcher Fetcher
18 .Tuple3<x, y, z> Output public class CheckUrlWithRobotsFunction extends RichAsyncFunction<FetchUrl, Tuple3<CrawlStateUrl, FetchUrl, FetchUrl>> { • Emit “combo” record • Only one field will be non-null Robots Checker • Split into three streams later Status Sitemap Select Update Fetcher Page Fetcher
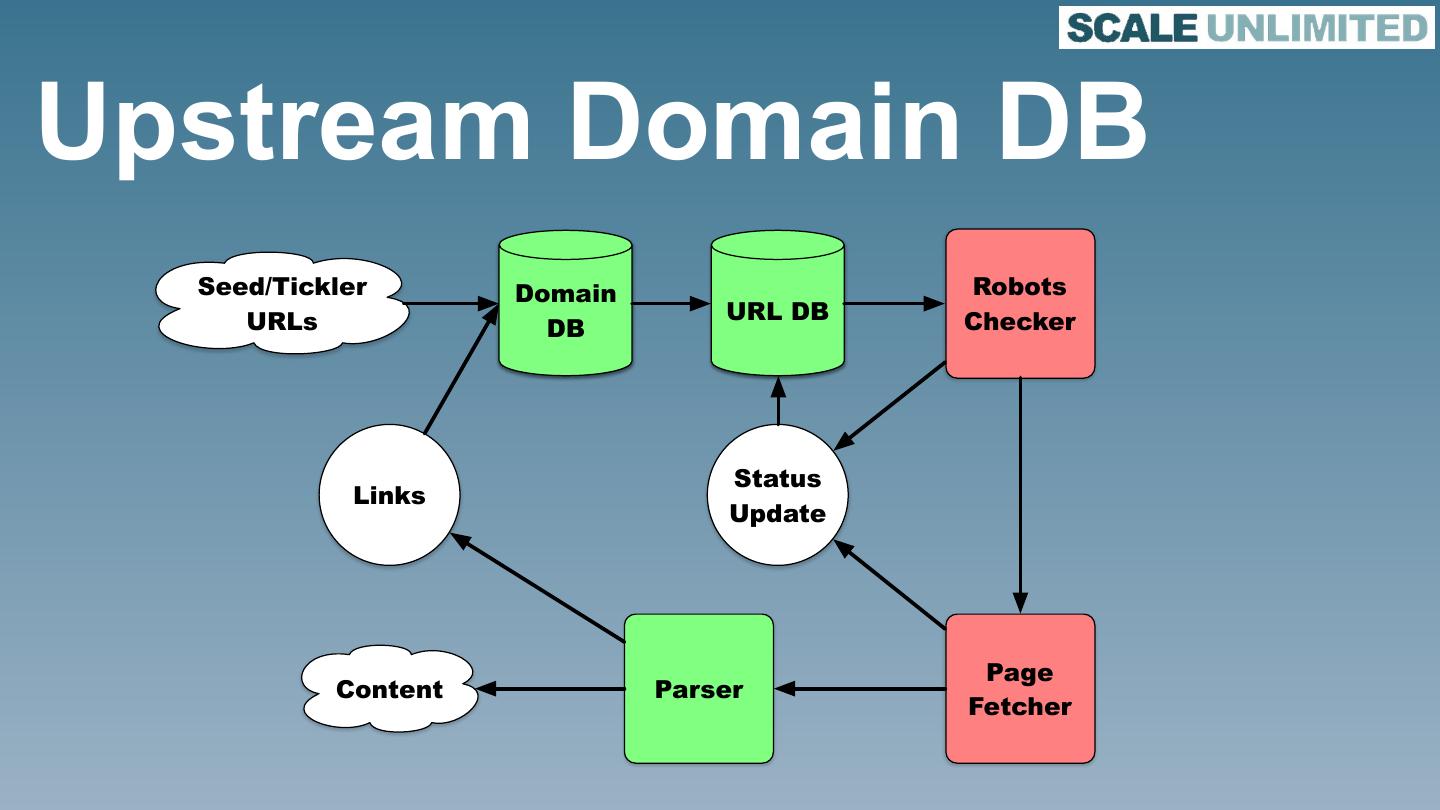
19 .Chaining backpressure • Flink “chains” operators • This happens in Async I/O thread • Often later operators need higher parallelism Page Content Parser Fetcher
20 .That’s not a Crawler!
21 .Status Updates Seed Robots URLs URL DB Checker Status Update Page Content Parser Fetcher
22 .And Outlinks Seed Robots URLs URL DB Checker Status Links Update Page Content Parser Fetcher
23 .Iterations to the Rescue
24 .Iterations IterativeStream<CrawlStateUrl> urlDbIteration = seedUrls.iterate(maxWaitTime); … urlDbIteration.closeWith(robotBlockedUrls); IterationSource • Timeout is optional UrlDBFunction • Creates a virtual source & sink Functions… • Memory-based queue in between IterationSink
25 .Fun with Fan-out • Every page can have 100s of links • So you get “fan-out” • Which fills up network buffers • Causing gridlock • And the entire workflow locks up
26 .Throttling • We track “in-flight” URLs in URL DB function • Don’t emit URL to fetch if “too busy” • Not a great solution URL DB (1/2) Parser (1/2) • Assumes no data skew • In-flight limit is rough approx. Links • Network buffer size URL DB Parser (2/2) • Fan-out record size (2/2)
27 .Checkpointing • Only works when sources are emitting • We have to emit “tickler” tuples Seed/tickler Robots URLs URL DB Checker Status Links Update Page Content Parser Fetcher
28 .Dropping In-flight Data • Can’t checkpoint “in flight” data • FLIP-15/16 will address this • But we don’t really care URL DB Robots Checker Status Page Update Fetcher
29 .When are we done? • Normally when source is empty • So that’s how you cancel a job • Iteration timeout is fragile • We emit special “termination” tuple • Shuts down rest of workflow • Work in progress
相关推荐
3秒后跳转登录页面
去登陆

