























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Embedding Flink Throughout an Operationalized Streaming ML LC
在实际生产环境中运营机器学习模型向来都不是一件简单的事情。来自Comcast公司的技术团队就面临很多的挑战,来操作那些机器学习模型来改善用户体验。Apache Flink是一个非常不错的实时流数据处理引擎,可以解决机器学习完整生命周期中所有的工作,比如数据科学家们可以用它来做数据探查和准备,尝试发布一个基于实时机器学习模型来做预测,并验证结果正确性,并据此来决定是否需要重新训练和继续迭代。这个ppt将分享使用Apache Flink来完成实时机器学习工作中的最佳实践和碰到的问题。
展开查看详情
1 .EMBEDDING FLINK THROUGHOUT AN OPERATIONALIZED STREAMING ML LIFECYCLE Dave Torok, Senior Principal Architect Sameer Wadkar, Senior Principal Architect 10 April, 2018
2 .INTRODUCTION AND BACKGROUND CUSTOMER EXPERIENCE TEAM 27 MILLION CUSTOMERS (HIGH SPEED DATA, VIDEO, VOICE, HOME SECURITY, MOBILE) INGESTING ABOUT 2 BILLION EVENTS / MONTH SOME HIGH-VOLUME MACHINE-GENERATED EVENTS TYPICAL STREAMING DATA ARCHITECTURE DATA ETL, LAND IN A TIME SERIES DATA LAKE GREW FROM A FEW DOZEN TO 150+ DATA SOURCES / FEEDS IN ABOUT A YEAR Comcast collects, stores, and uses all data in accordance with our privacy disclosures to users and applicable laws. 2
3 .BUSINESS PROBLEM INCREASE POSITIVE CUSTOMER EXPERIENCES RESOLVE POTENTIAL ISSUES CORRECTLY AND QUICKLY PREDICT AND DIAGNOSE SERVICE TROUBLE ACROSS MULTIPLE KNOWLEDGE DOMAINS REDUCE COSTS THROUGH EARLIER RESOLUTION AND BY REDUCING AVOIDABLE TECHNICIAN VISITS 3
4 .TECHNICAL PROBLEM MULTIPLE PROGRAMMING AND DATA SCIENCE ENVIRONMENTS WIDESPREAD AND DISCORDANT DATA SOURCES THE “DATA PLANE” PROBLEM: COMBINING DATA AT REST AND DATA IN MOTION ML VERSIONING: DATA, CODE, FEATURES, MODELS 4
5 .SOLUTION MOTIVATION SELF-SERVICE MODELS TREATED PLATFORM AS CODE ALIGN DATA SCIENTISTS HIGH THROUGHPUT AND PRODUCTION STREAM PLATFORM 5
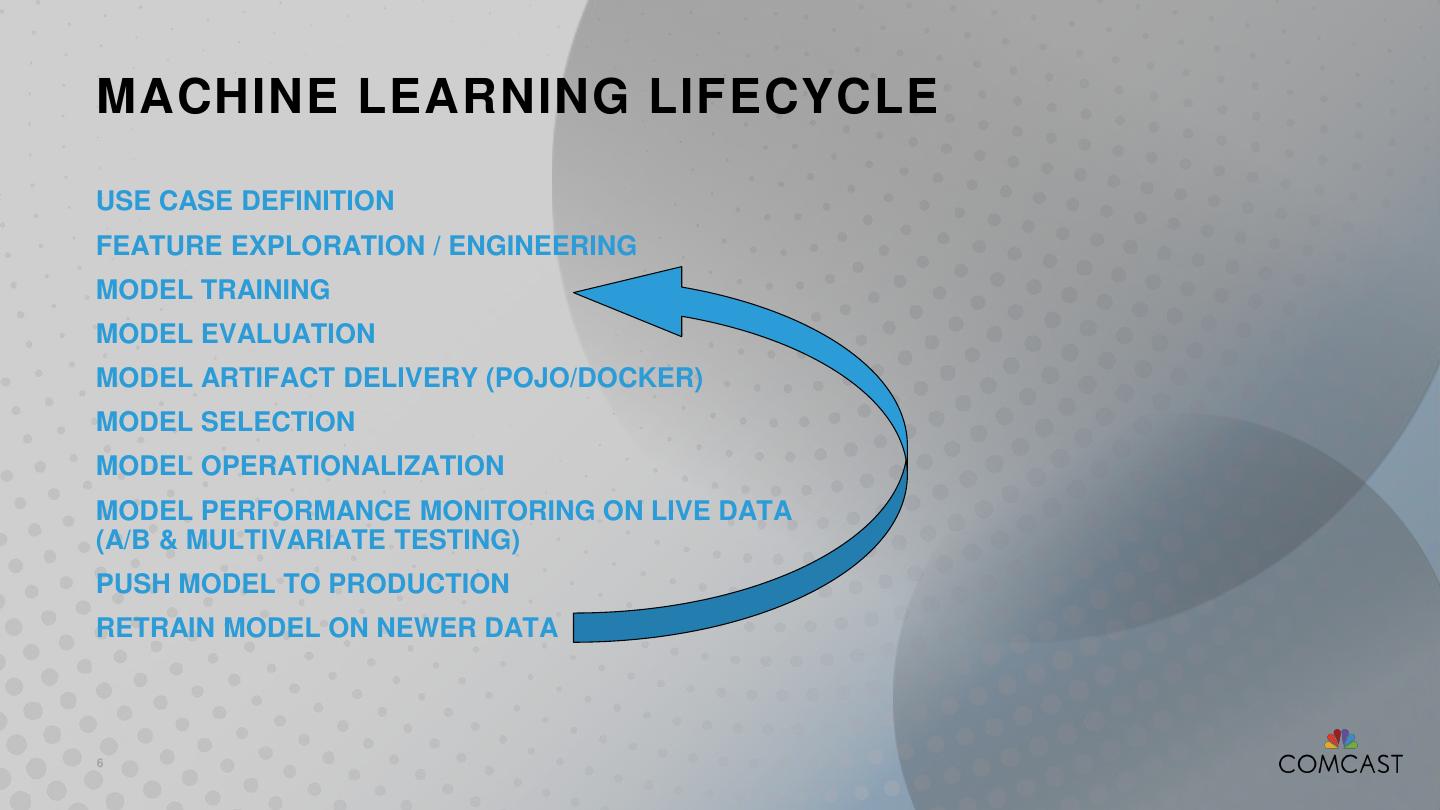
6 .MACHINE LEARNING LIFECYCLE USE CASE DEFINITION FEATURE EXPLORATION / ENGINEERING MODEL TRAINING MODEL EVALUATION MODEL ARTIFACT DELIVERY (POJO/DOCKER) MODEL SELECTION MODEL OPERATIONALIZATION MODEL PERFORMANCE MONITORING ON LIVE DATA (A/B & MULTIVARIATE TESTING) PUSH MODEL TO PRODUCTION RETRAIN MODEL ON NEWER DATA 6
7 .EXAMPLE NEAR REAL TIME Event PREDICTION USE CASE Detect CUSTOMER RUNS A “SPEED TEST” Slow Speed? EVENT TRIGGERS A PREDICTION FLOW Enrich Network Diagnostic Services ENRICH WITH NETWORK HEALTH AND OTHER Gather Data INDICATORS Additional Context Services EXECUTE ML MODEL Predict Run ML Prediction Model PREDICT WHETHER IT IS A WIFI, MODEM, OR NETWORK ISSUE Engage Customer 7 Act / Notify
8 . ML PIPELINE ARCHITECTURE PRINCIPLES Iterative/Consistent Rapid Monitoring and Metadata Driven Automation Model Data Consistency Onboarding Metrics Development Feature/Model Orchestrated Multiple versions of Portal for Model Feature store Ability to execute Definition, Deployment for the model can be and Feature enforces a & monitor Versioning , Feature new features and developed Management as consistent data multiple models Assembly, Model models iteratively while well Model pipeline ensuring in production to Deployment, Model Monitoring is consuming from a Deployment that the data enable real-time metadata driven consistent dataset used for training metrics driven (feature store), is functionally model selection enables A/B & identical to the Multivariate Testing data used for predictions 8
9 . ML PIPELINE – ROLES & WORKFLOW Model Candidate Model Model Model Go Live Inception Exploration Development Selection Operationalization Evaluation Phase Define Model Model Evaluate Go Live with Use Review Selection Live Model Selected Case Performance Models Business User Iterate Explore Create & Features Validate Models Monitor Live Collect new data & retrain Models Data Scientist Iterate • Define Online Feature Assembly Create and • Define pipeline to publish new collect outcomes features • Model Deployment and Monitoring ML Operations 9
10 .WHY APACHE FLINK? UTILIZED AS ORCHESTRATION & ETL ENGINE FIRST-CLASS STREAMING MODEL PERFORMANCE RICH STATEFUL SEMANTICS TEAM EXPERIENCE OPEN SOURCE GROWING COMMUNITY Apache®, Apache Flink®, and the squirrel logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. 10
11 .THE “DATA PLANE” PROBLEM Enterprise Services Streaming Compute Pipeline QUERY Sum Stream Avg Streaming Databases Data Time State MODEL Buckets Data File Abstraction AWS HDFS S3 11 Data Sets at Rest
12 .ML MODEL EXECUTION 1. Payload only contains Model 4. Pass full set of Name & Account assembled features Number for model execution MODEL FEATURE MODEL EXECUTION ASSEMBLY EXECUTION TRIGGER 5. Prediction 2. Model Metadata 3. Pull required informs which Online Model Feature features by account features are needed Metadata Store number for a model 12
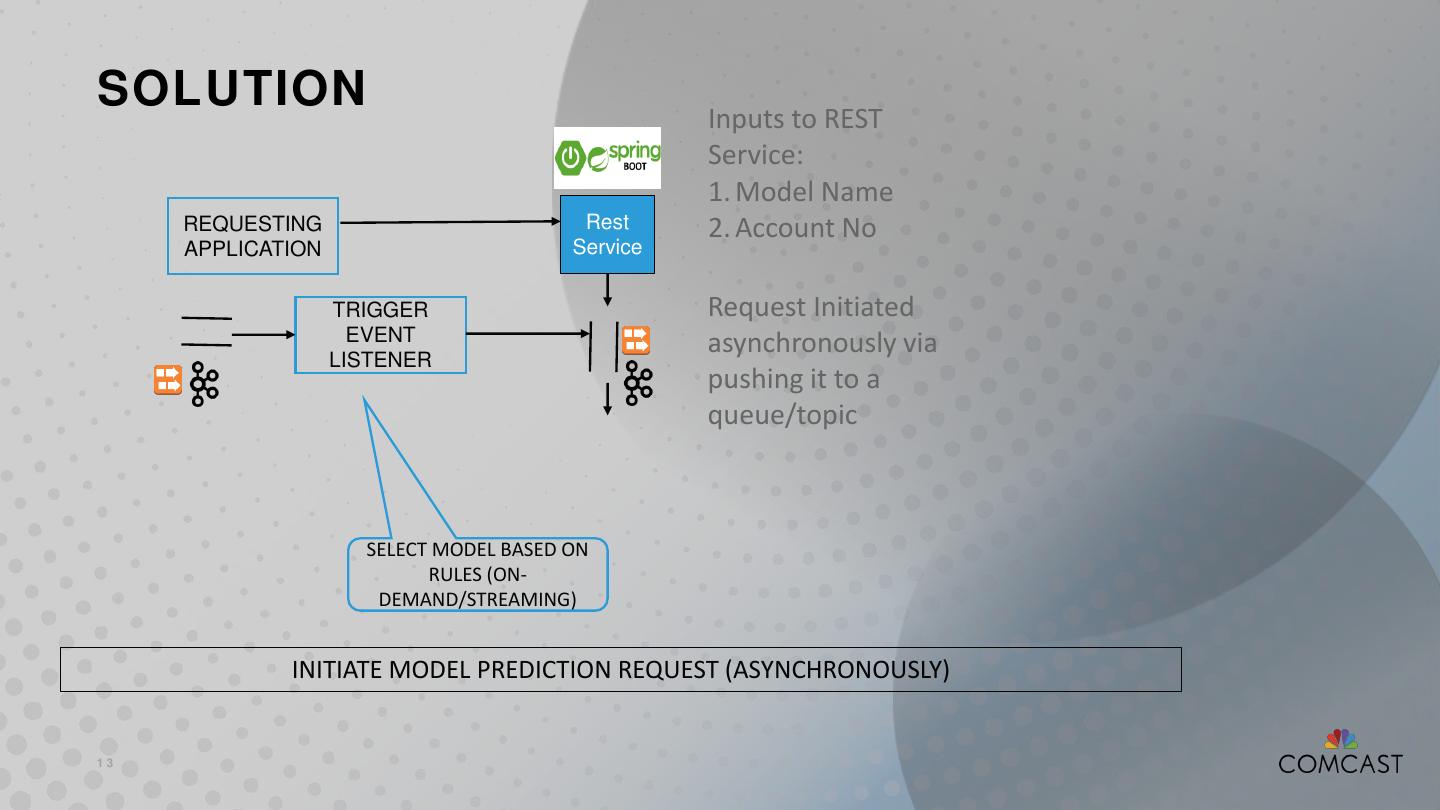
13 .SOLUTION Inputs to REST Service: 1. Model Name REQUESTING Rest 2. Account No APPLICATION Service TRIGGER Request Initiated EVENT asynchronously via LISTENER pushing it to a queue/topic SELECT MODEL BASED ON RULES (ON- DEMAND/STREAMING) INITIATE MODEL PREDICTION REQUEST (ASYNCHRONOUSLY) 13
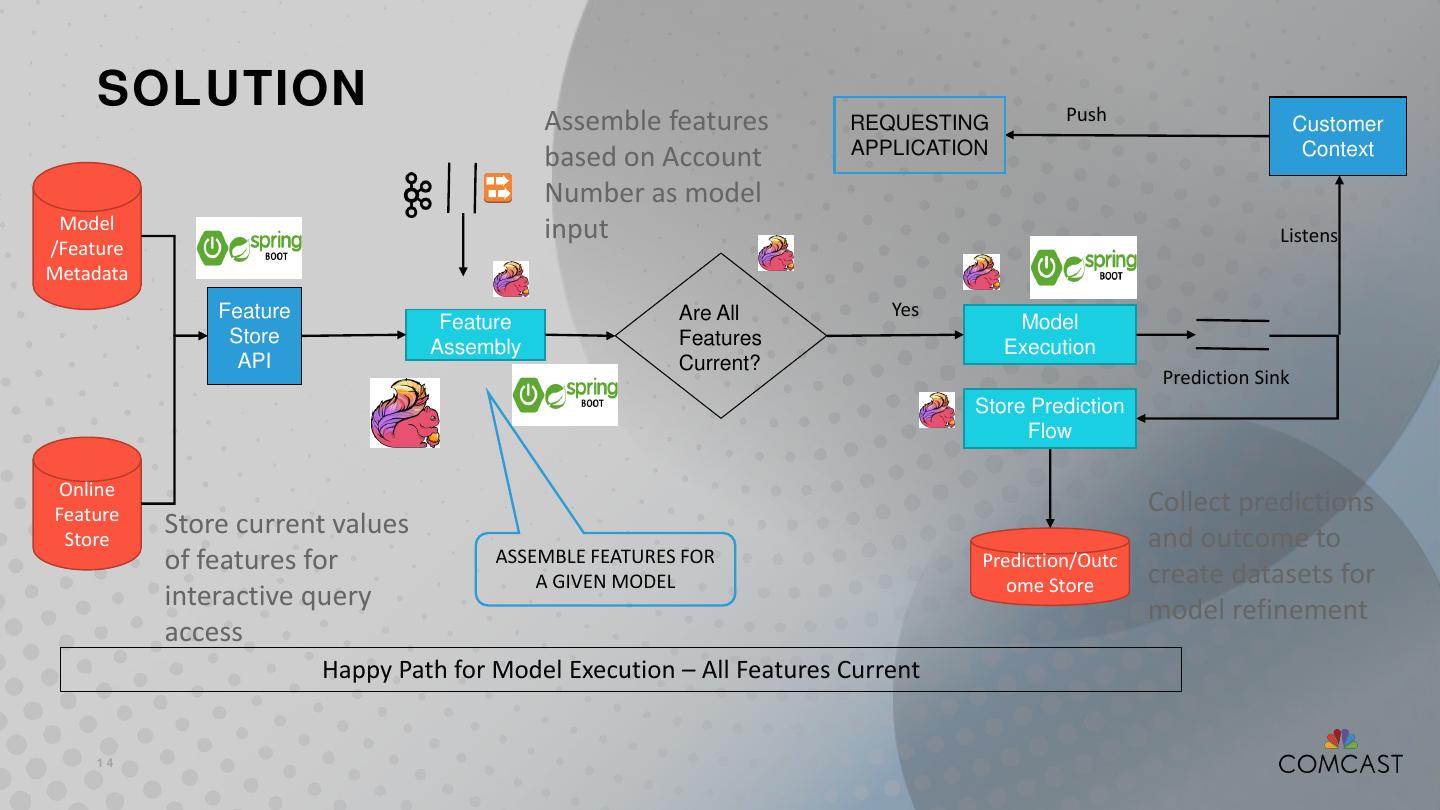
14 . SOLUTION Push Assemble features REQUESTING Customer APPLICATION Context based on Account Number as model Model input Listens /Feature Metadata Feature Are All Yes Feature Model Store Features Assembly Execution API Current? Prediction Sink Store Prediction Flow Online Feature Collect predictions Store Store current values and outcome to of features for ASSEMBLE FEATURES FOR Prediction/Outc create datasets for A GIVEN MODEL ome Store interactive query model refinement access Happy Path for Model Execution – All Features Current 14
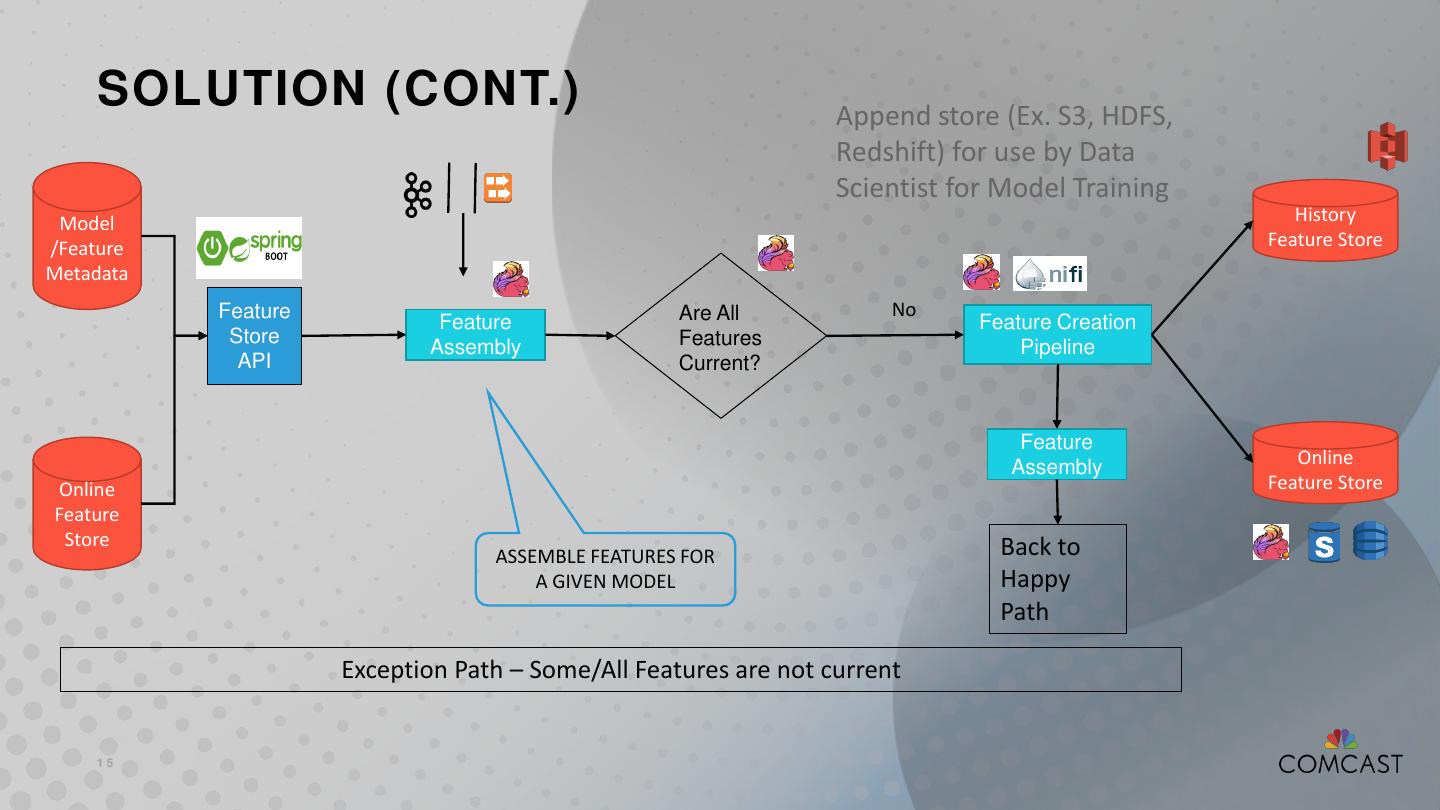
15 . SOLUTION (CONT.) Append store (Ex. S3, HDFS, Redshift) for use by Data Scientist for Model Training Model History /Feature Feature Store Metadata Feature Are All No Feature Feature Creation Store Features Assembly Pipeline API Current? Feature Online Assembly Online Feature Store Feature Store Back to ASSEMBLE FEATURES FOR A GIVEN MODEL Happy Path Exception Path – Some/All Features are not current 15
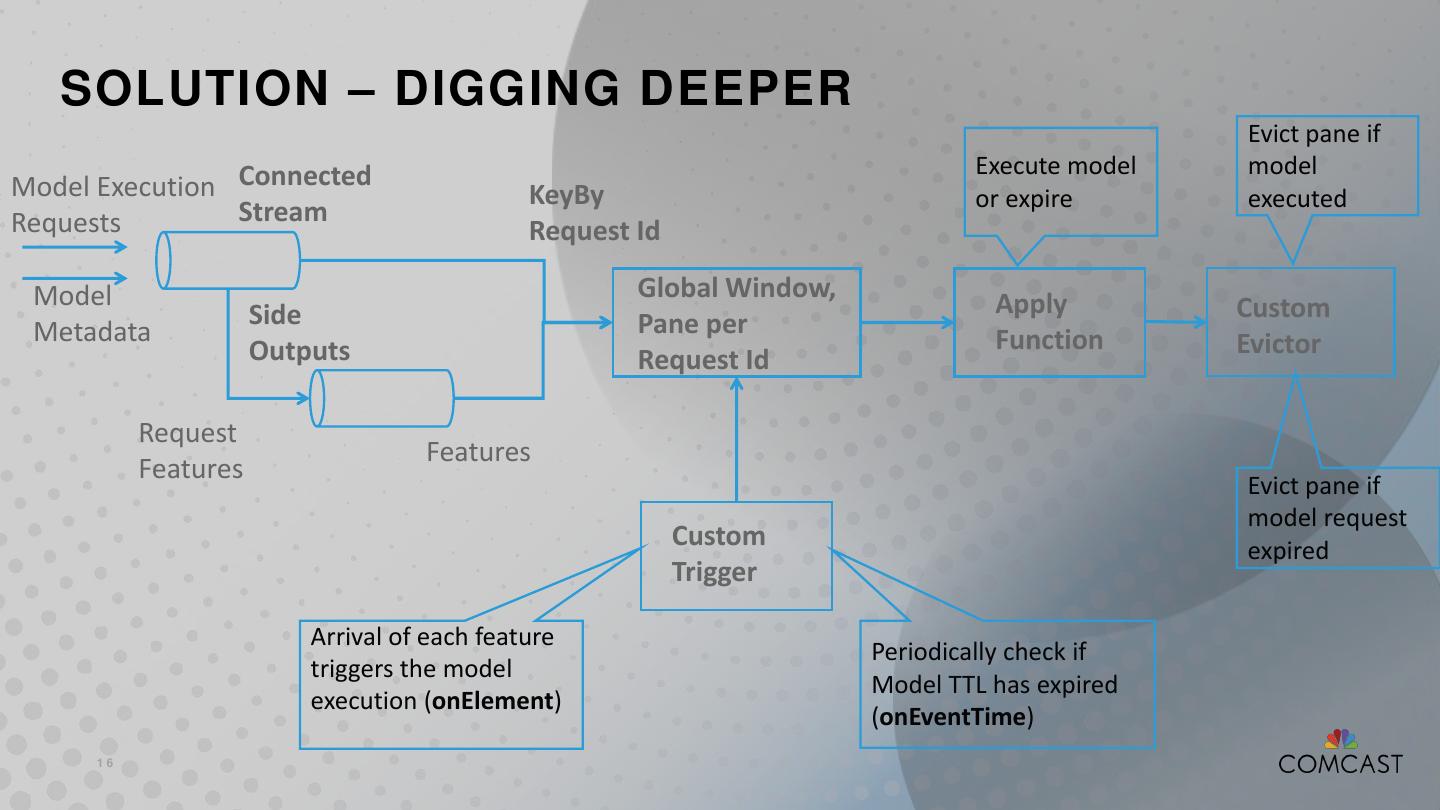
16 . SOLUTION – DIGGING DEEPER Evict pane if Execute model model Model Execution Connected KeyBy or expire executed Requests Stream Request Id Model Global Window, Side Apply Custom Metadata Pane per Outputs Function Evictor Request Id Request Features Features Evict pane if model request Custom expired Trigger Arrival of each feature Periodically check if triggers the model Model TTL has expired execution (onElement) (onEventTime) 16
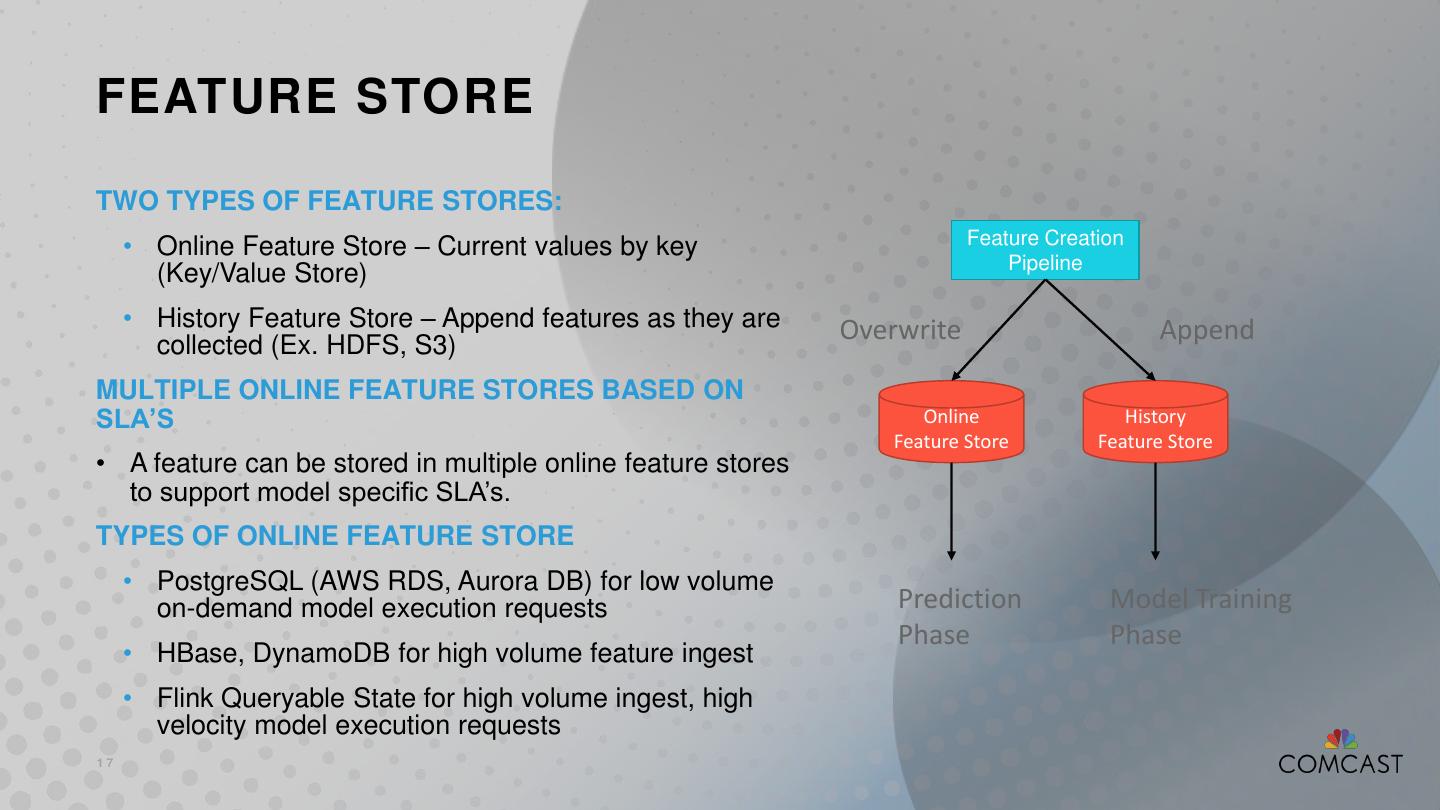
17 .FEATURE STORE TWO TYPES OF FEATURE STORES: Feature Creation • Online Feature Store – Current values by key Pipeline (Key/Value Store) • History Feature Store – Append features as they are Overwrite Append collected (Ex. HDFS, S3) MULTIPLE ONLINE FEATURE STORES BASED ON SLA’S Online History Feature Store Feature Store • A feature can be stored in multiple online feature stores to support model specific SLA’s. TYPES OF ONLINE FEATURE STORE • PostgreSQL (AWS RDS, Aurora DB) for low volume on-demand model execution requests Prediction Model Training Phase Phase • HBase, DynamoDB for high volume feature ingest • Flink Queryable State for high volume ingest, high velocity model execution requests 17
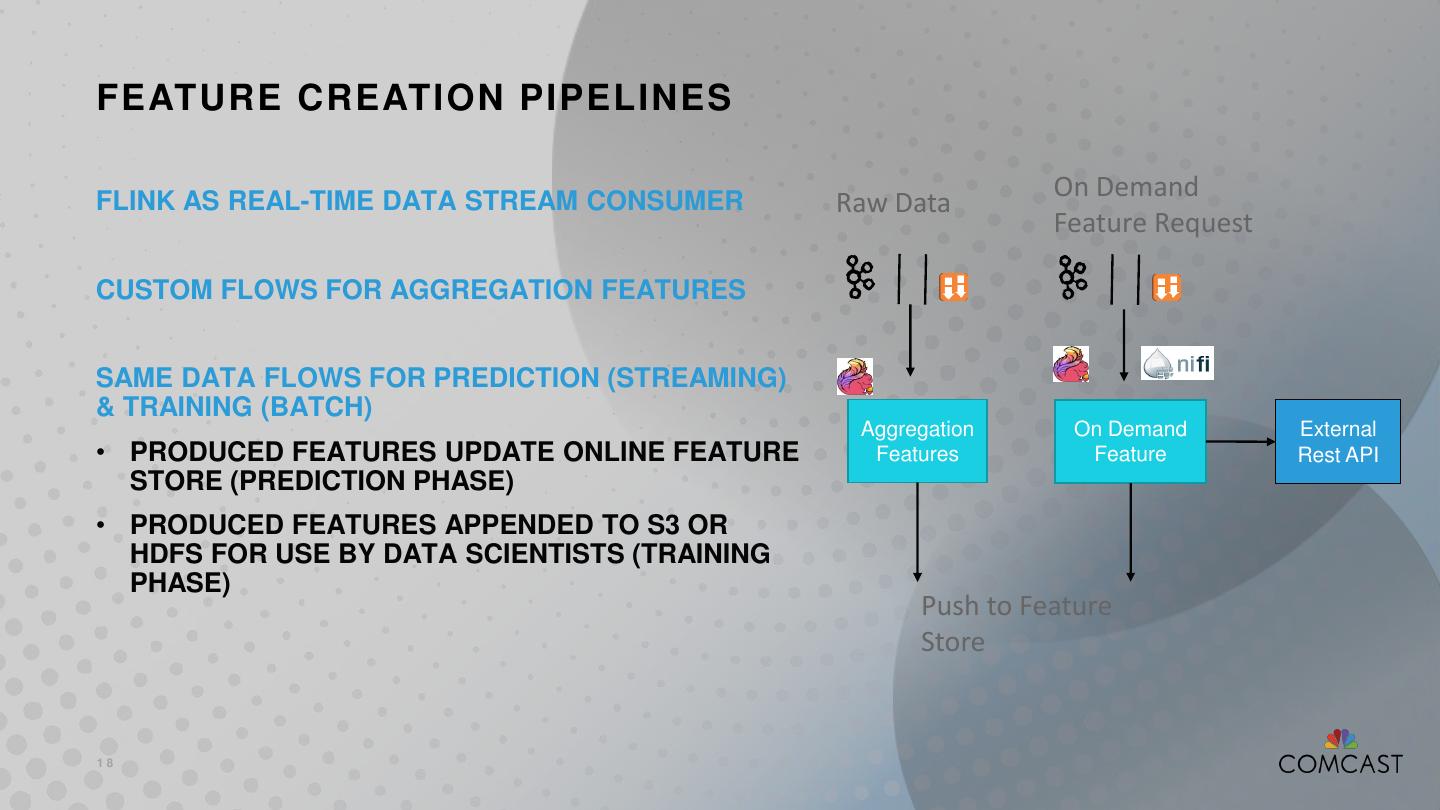
18 .FEATURE CREATION PIPELINES On Demand FLINK AS REAL-TIME DATA STREAM CONSUMER Raw Data Feature Request CUSTOM FLOWS FOR AGGREGATION FEATURES SAME DATA FLOWS FOR PREDICTION (STREAMING) & TRAINING (BATCH) Aggregation On Demand External • PRODUCED FEATURES UPDATE ONLINE FEATURE Features Feature Rest API STORE (PREDICTION PHASE) • PRODUCED FEATURES APPENDED TO S3 OR HDFS FOR USE BY DATA SCIENTISTS (TRAINING PHASE) Push to Feature Store 18
19 .STREAMING FEATURE EXAMPLE KAFKA ERROR STREAM (~150 / SECOND) Flink Features Used: DETECT ACCOUNTS WITH SIGNAL ERROR WITH COUNT > 2000 IN TRAILING 24 HOURS Kafka Source Keyed Stream SOLUTION: Value State AVRO DESERIALIZER WITH KEY = ACCOUNT “24 HOUR ROLLING” HASH STRUCTURE AS STATE Sliding Window FILTER FUNCTION WITH SIGNAL THRESHOLD Filter Function 19
20 .ON-DEMAND FEATURE EXAMPLE PREMISE HEATH TEST Flink Features Used: • DIAGNOSTIC TELEMETRY INFORMATION FOR EACH DEVICE FOR A GIVEN CUSTOMER Async Operator • EXPENSIVE - ONLY REQUESTED ON DEMAND • MODELS USING SUCH A FEATURE WILL EXTRACT SUB-ELEMENTS USING SCRIPTING CAPABILITIES (MODEL METADATA & FEATURE ENGINEERING) • MODEL METADATA WILL CONTAIN TTL ATTRIBUTE FOR SUCH FEATURES INDICATING THEIR TOLERANCE FOR STALE DATA SOLUTION: MAKE AN ON-DEMAND REQUEST FOR PHT TELEMETRY DATA FOR IF IT IS STALE OR ABSENT FOR A GIVEN ACCOUNT 20
21 .ML PREDICTION COMPONENT • REST SERVICE • Same Code Base • H2O.ai Model Container (POJO) • Python based service running specialized ML Models • Multiple Deployment Models • Any stateless REST service • FLINK MAP OPERATOR • REST – Low velocity, on- • H2O.ai Model Container (POJO) wrapped in a Flink demand model invocations Map Operator • Possibly support native calls via Flink Map Operators • Map Operators – High running specialized Models (Ex. Tensorflow GPU velocity, streaming model based predictions) invocations 21
22 .VERSIONING AND DEVOPS EVERYTHING IS VERSIONED • Feature/Model Metadata • Feature Data & Model Execution environments • Training, Validation datasets are versioned • Feature creation pipelines are versioned VERSIONING ALLOWS PROVENANCE & AUDITABILITY & REPEATABILITY OF EVERY PREDICTION 22
23 .FEATURES OF THE ML PIPELINE TRACEABILITY & REPEATABILITY & CLOUD AGNOSTIC AUDITABILITY • Integrates with the AWS Cloud but not • Model to be traced back to business use- dependent on it cases • Framework should be able to work in a • Full traceability from raw data to feature non-AWS distributed environment with engineering to predictions configuration (not code) changes • “Everything Versioned” enables repeatability CI/CD SUPPORT • Code, Metadata (Hyper-Parameters) and Data (Training/Validation Data) are versioned. Deployable artifacts to integrate with CI/CD Pipeline 23
24 .FEATURES OF THE ML PIPELINE (CONT.) PLUGGABLE (DATA AND COMPUTE) MULTI-DEPLOYMENT OPTIONS ARCHITECTURE • Supports Throughput vs. Latency • De-coupled architecture based on Tradeoffs- Process in stream/batch/on- message driven inter-component demand communication. • Allows multiple versions of the • Failure of an isolated component does same/different models to be compared not fail the entire platform with one another on live data • A/B testing & Multivariate testing • Asynchronous behavior • Live but dark deployments • Micro-Services based design which supports independent deployment of • Supports integration of outcomes with components predictions to measure production performance & support continuous model re-training 24
25 .NEXT STEPS AND FUTURE WORK GENERATING “FLINK NATIVE” FEATURE FLOWS • Evaluating Uber’s “AthenaX” Project / Similar Approaches UI PORTAL FOR • MODEL / FEATURE AND METADATA MANAGEMENT • CONTAINERIZATION SUPPORT FOR MODEL EXECUTION PHASE • WORKBENCH FOR DATA SCIENTIST • CONTINUOUS MODEL MONITORING QUERYABLE STATE AUTOMATING THE RETRAINING PROCESS SUPPORT FOR MULTIPLE/PLUGGABLE FEATURE STORES (SLA DRIVEN) 25
26 .SUMMARY & LESSONS LEARNED FLINK IS HELPING ACHIEVE OUR BUSINESS GOALS • Near-real-time streaming context • Container for ML Prediction Pipeline • Stateful Feature Generation • Multiple Solutions to the “Data Plane” Problem • Natural Asynchronous support • Rich windowing semantics support various aspects of our ML Pipeline (Training/Prediction/ETL) • Connected Streams simplify pushing metadata updates (reduced querying load with better performance) • Queryable State is a natural fit for high velocity and high volume data being pushed to the online feature store 26
27 .THANK YOU!
28 .
相关推荐
3秒后跳转登录页面
去登陆

