



























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Bootstrapping State In Apache Flink
Apache Flink是一个非常受欢迎的实时流式数据处理引擎。很多流处理算法需要计算在拖尾的时间窗口内的结果,比如,计算最近7天的用户登陆数量,难点于我们程序往往都还没有运行到7天时间,一个解决办法是先让程序把历史数据撸一遍,然后再接上实时数据流,今天我们就来讨论Flink中实时流接入前的初始状态问题,这个问题的解决办法有很多,Lyft公司采用优化Flink源数据处理的方式,我们今天将重点讨论这个方案以及未来优化思路。
展开查看详情
1 .Bootstrapping State in Flink Gregory Fee
2 .What did the message queue say to Flink?
3 .Dwarf for Link!
4 .Dwarf for Link?
5 .DwarfforLink! FlinkForward!
6 .About Me ● Engineer @ Lyft ● Teams - ETA, Data Science Platform, Data Platform ● Accomplishments ○ ETA model training from 4 months to every 10 minutes ○ Real-time traffic updates ○ Flyte - Large Scale Orchestration and Batch Compute ○ Lyftlearn - Custom Machine Learning Library ○ Dryft - Real-time Feature Generation for Machine Learning
7 .Dryft ● Need - Consistent Feature Generation ○ The value of your machine learning results is only as good as the data ○ Subtle changes to how a feature value is generated can significantly impact results ● Solution - Unify feature generation ○ Batch processing for bulk creation of features for training ML models ○ Stream processing for real-time creation of features for scoring ML models ● How - SPaaS ○ Use Flink as the processing engine ○ Add automation to make it super simple to launch and maintain feature generation programs at scale
8 .What is Bootstrapping?
9 .Bootstrapping is not Backfilling ● Using historic data to calculate historic results ● Typical uses: ○ Correct for missing data based on pipeline malfunction ○ Generate output for new business logic ● So what is bootstrapping?
10 .Stateful Stream Programs Counts of the words that appear in the stream over the last 7 days updated every hour counts = stream .flatMap((x) -> x.split("\\s")) .map((x) -> new KV(x, 1)) .keyBy((x) -> x.key) .window(Time.days(7),Time.hours(1)) .sum((x) -> x.value);
11 .The Waiting is the Hardest Part Day 1 Day 3 Day 6 Day 8 Launch Program Anger Bargaining Relief A program with a 7 day window needs to process for 7 days before it has enough data to answer the query correctly.
12 .What about forever? Counts of the number of rides each user has ever taken Table table = tableEnv.sql( "SELECT user_lyft_id, COUNT(ride_id) FROM event_ride_completed GROUP BY user_lyft_id");
13 .Bootstrapping -7 -6 -5 -4 -3 -2 -1 1 2 3 4 5 6 7 Start Program + Validate Results Read historic data store to “bootstrap” the program with 7 days worth of data. Now your program returns results on day 1.
14 .Provisioning ● We want bootstrapping to be super fast == set parallelism high ○ Processing a week of data should take less than a week ● We want real-time processing to be super cheap == set parallelism low ○ Need to host thousands of feature generation programs
15 .Keep in Mind ● Generality is desirable ○ There are potentially simpler ways of bootstrapping based on your application logic ○ General solution needed to scale to thousands of programs ● Production Readiness is desirable ○ Observability, scalability, stability, and all those good things are all considerations ● What works for Lyft might not be right for you
16 .Use Stream Retention consumerConfig.put( ConsumerConfigConstants.STREAM_INITIAL_POSITION, "TRIM_HORIZON"); • Use the retention policy on your stream technology to retain data for as long as you need ‒ Kinesis maximum retention is 7 days ‒ Kafka has no maximum, stores all data to disks, not capable of petabytes of storage, suboptimal to spend disk money on infrequently accessed data • If this is feasible for you then you should do it
17 .Kafka “Infinite Retention” ● Alter Kafka to allow for tiered storage ○ Write partitions that age out to secondary storage ○ Push data to S3/Glacier ● Advantages ○ Effectively infinite storage at a reasonable price ○ Use existing Kafka connectors to get data ● Disadvantages ○ Very different performance characteristics of underlying storage ○ No easy way to use different Flink configuration between bootstrapping and steady state ○ Does not exist today ● Apache Pulsar and Pravega ecosystems might be a viable alternative
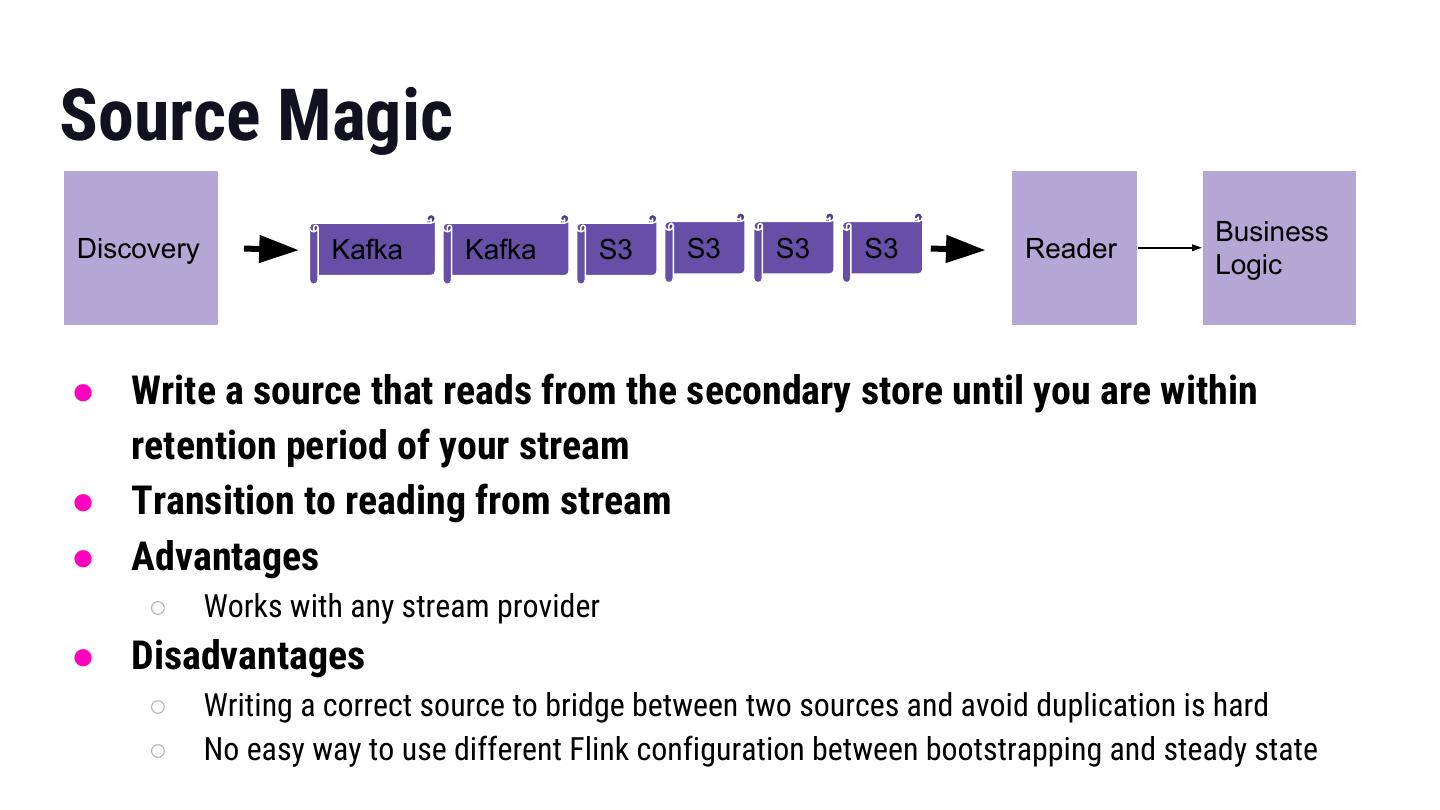
18 .Source Magic Business Discovery Kafka Kafka S3 S3 S3 S3 Reader Logic ● Write a source that reads from the secondary store until you are within retention period of your stream ● Transition to reading from stream ● Advantages ○ Works with any stream provider ● Disadvantages ○ Writing a correct source to bridge between two sources and avoid duplication is hard ○ No easy way to use different Flink configuration between bootstrapping and steady state
19 .Application Level Attempt #1 1. Run the bootstrap program a. Read historic data using a normal source b. Process the data with selected business logic c. Wait for all processing to complete d. Trigger a savepoint and cancel the program 2. Run the steady state program a. Start the program from the savepoint b. Read stream data using a normal source ● Advantages ○ No modifications to streams or sources ○ Allows for Flink configuration between bootstrapping and steady state ● Disadvantages ○ Let’s find out
20 .How Hard Can It Be? S3 Source Business Logic Sink Kinesis Source Business Logic Sink ● How do we make sure there is no repeated data?
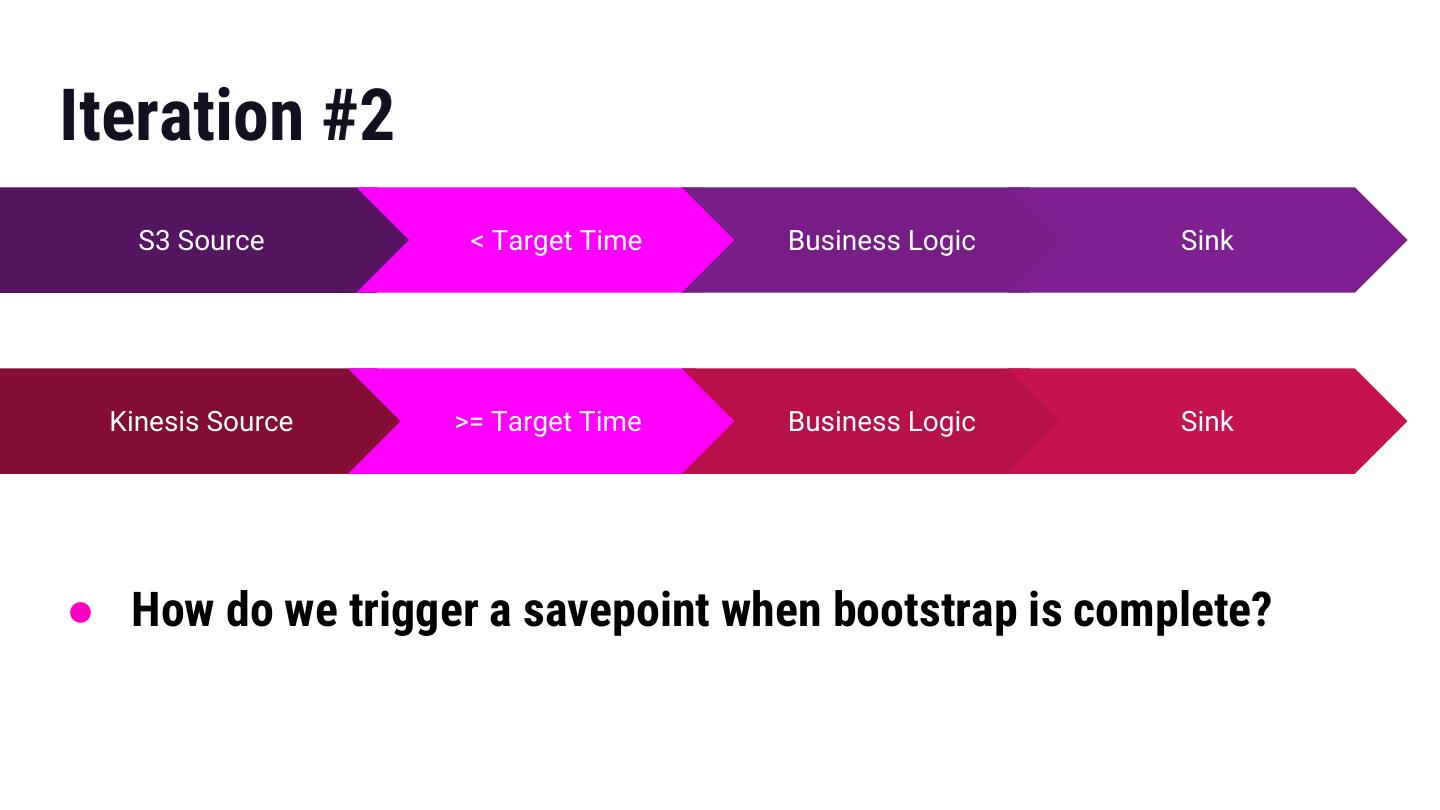
21 .Iteration #2 S3 Source < Target Time Business Logic Sink Kinesis Source >= Target Time Business Logic Sink ● How do we trigger a savepoint when bootstrap is complete?
22 .Iteration #3 S3 Source + Termination < Target Time Business Logic “Sink” Termination Detector Kinesis Source >= Target Time Business Logic Sink ● After the S3 data is read, push a record that is at (target time + 1) ● Termination detector looks for low watermark to reach (target time + 1)
23 .What Did I Learn? ● Automating Flink from within Flink is possible but fragile ○ Eg If you have multiple partitions reading S3 then you need to make sure all of them process a message that pushes the watermark to (target time + 1) ● Savepoint logic is via uid so make sure those are applied on your business logic ○ No support for setting uid on operators generated via SQL
24 .Application Level Attempt #2 1. Run a high provisioned job a. Read from historic data store b. Read from live stream c. Union the above d. Process the data with selected business logic e. After all S3 data is processed, trigger a savepoint and cancel program 2. Run a low provisioned job a. Exact same ‘shape’ of program as above, but with less parallelism b. Restore from savepoint
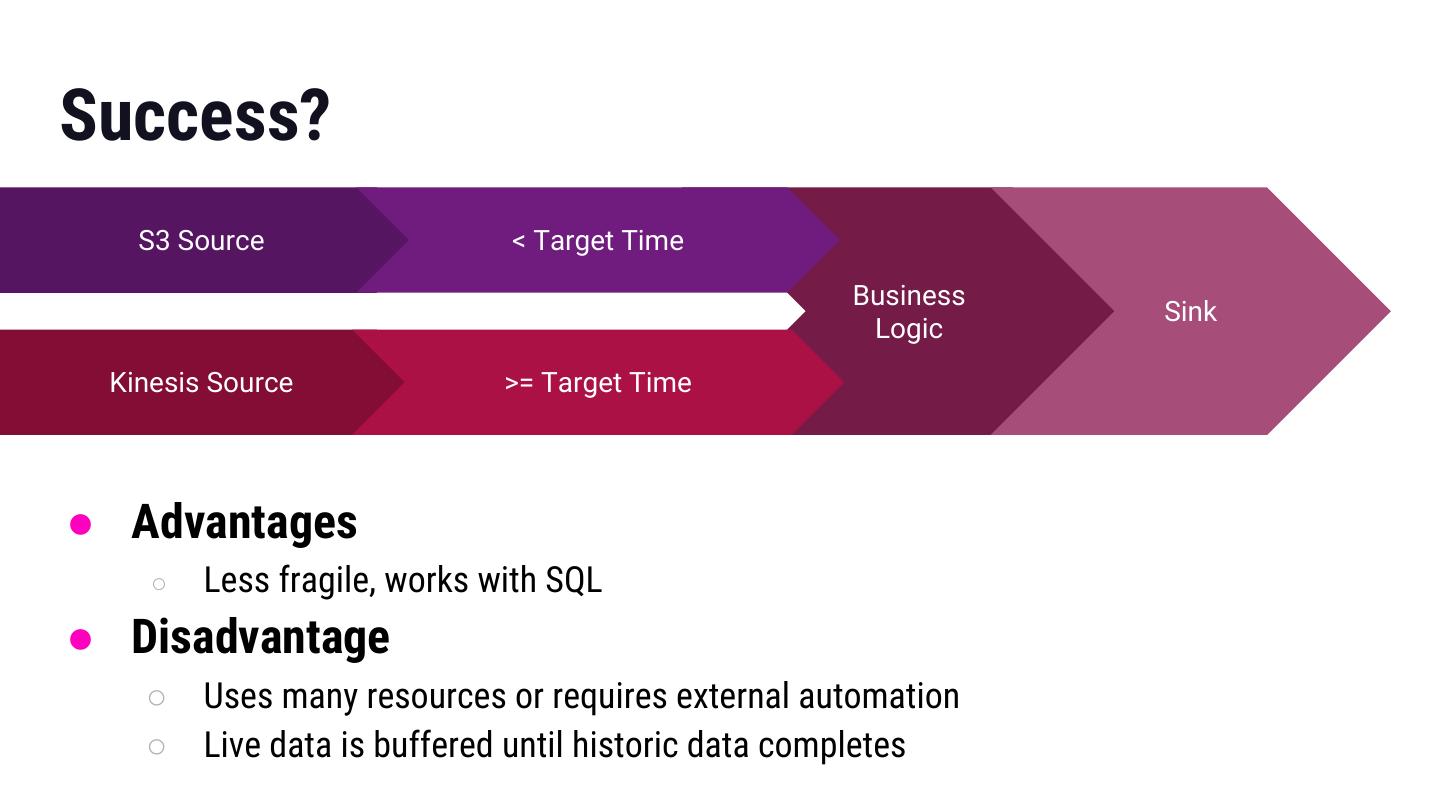
25 .Success? S3 Source < Target Time Business Sink Logic Kinesis Source >= Target Time ● Advantages ○ Less fragile, works with SQL ● Disadvantage ○ Uses many resources or requires external automation ○ Live data is buffered until historic data completes
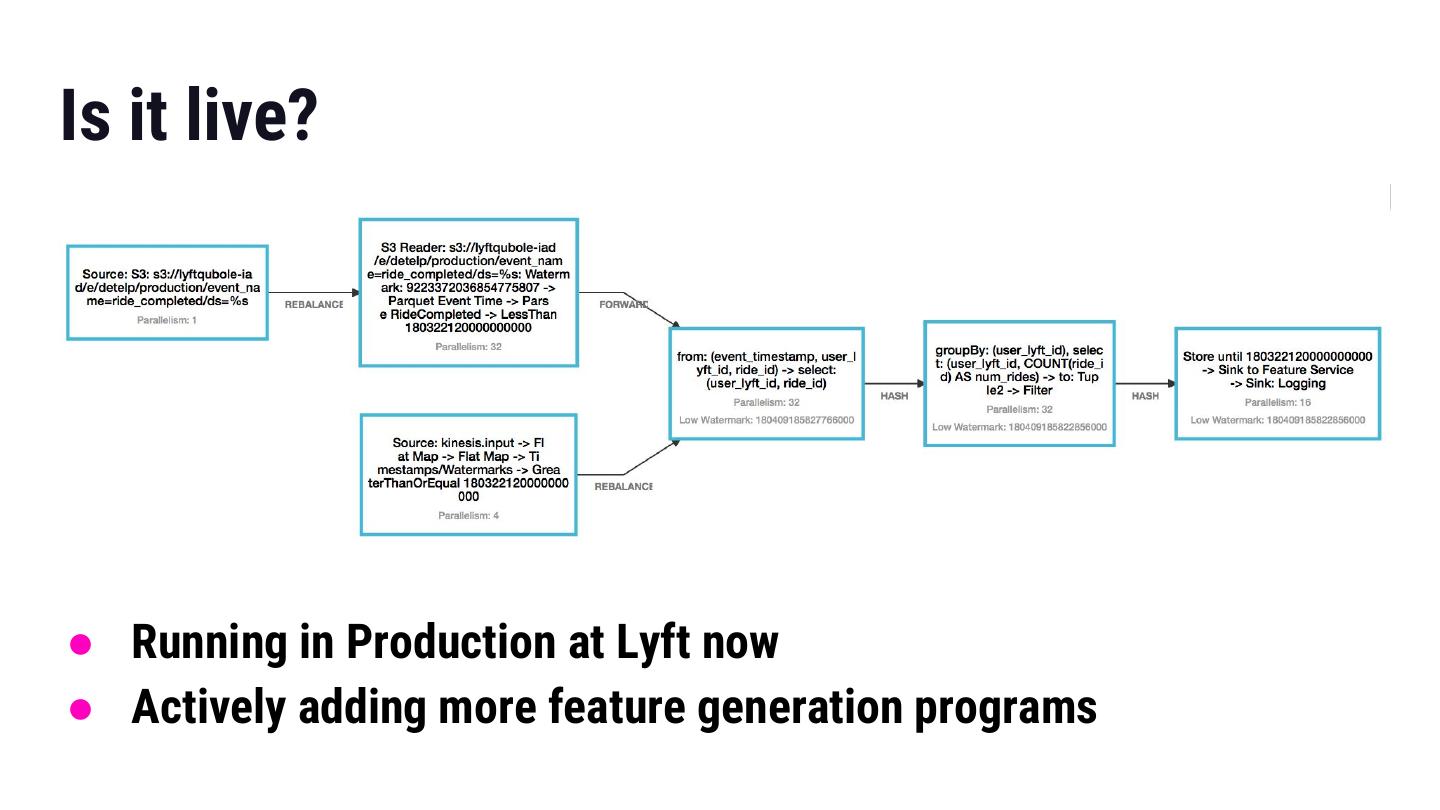
26 .Is it live? ● Running in Production at Lyft now ● Actively adding more feature generation programs
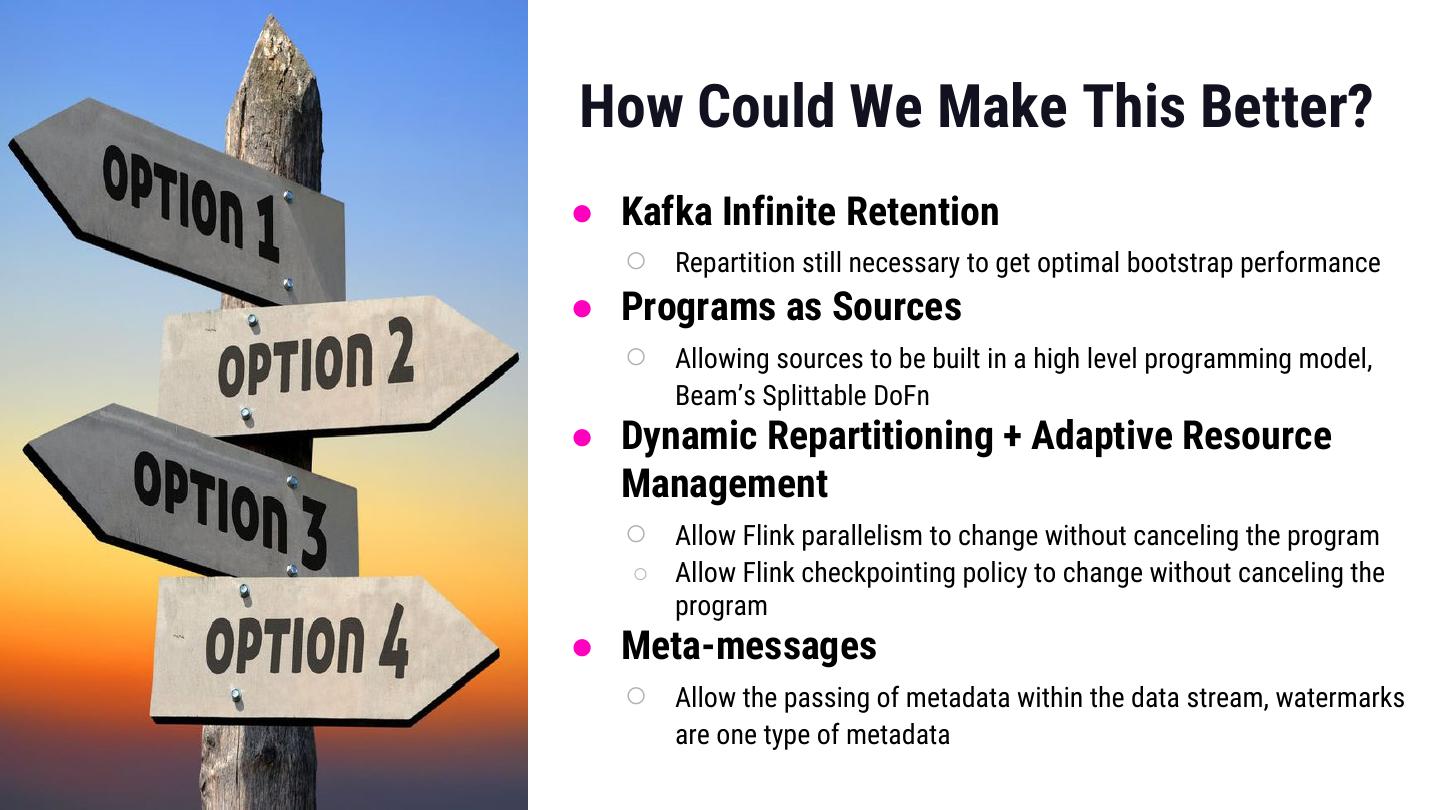
27 .How Could We Make This Better? ● Kafka Infinite Retention ○ Repartition still necessary to get optimal bootstrap performance ● Programs as Sources ○ Allowing sources to be built in a high level programming model, Beam’s Splittable DoFn ● Dynamic Repartitioning + Adaptive Resource Management ○ Allow Flink parallelism to change without canceling the program ○ Allow Flink checkpointing policy to change without canceling the program ● Meta-messages ○ Allow the passing of metadata within the data stream, watermarks are one type of metadata
28 .What about Batch Mode? ● Batch Mode can be more efficient than Streaming Mode ○ Offline data has different properties than stream data ● Method #1 ○ Use batch mode to process historic data, make a savepoint at the end ○ Start a streaming mode program from the savepoint, process stream data ● Method #2 ○ Modify Flink to understand a transition watermark, batch runtime automatically transitions to streaming runtime, requires unified source
29 .What Did We Learn? ● Many stream programs are stateful ● Faster than real-time bootstrapping using Flink is possible ● There are many opportunities for improvement
相关推荐
3秒后跳转登录页面
去登陆

