




















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Why and how to leverage the simplicity and power of SQL on Flink
一句话,用SQL来处理流式数据和批量数据,这很重要!!当然也会举例说明Flink的SQL的各种应用场景,特别是还集成了查询接口,可以提供查询,追加数据,更新数据集等功能。
展开查看详情
1 .WHY AND HOW TO LEVERAGE THE POWER AND SIMPLICITY OF SQL ON APACHE FLINK® - FABIAN HUESKE, SOFTWARE ENGINEER - TIMO WALTHER, SOFTWARE ENGINEER
2 .ABOUT DATA ARTISANS Original creators of Open Source Apache Flink Apache Flink® + dA Application Manager 2 © 2018 data Artisans
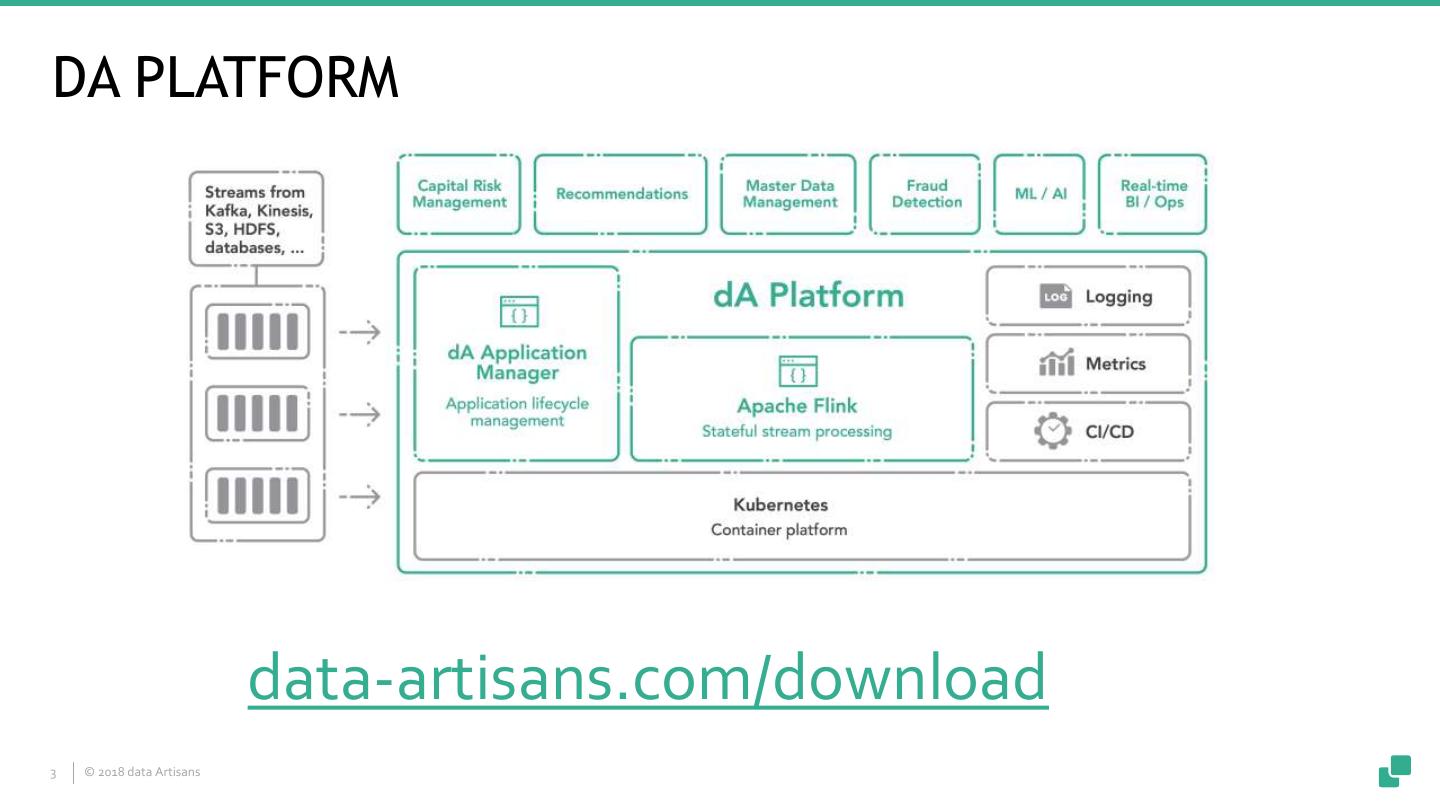
3 .DA PLATFORM data-artisans.com/download 3 © 2018 data Artisans
4 .POWERED BY APACHE FLINK 4 © 2018 data Artisans
5 .FLINK’S POWERFUL ABSTRACTIONS Layered abstractions to navigate simple to complex use cases High-level Analytics API SQL / Table API (dynamic tables) val stats = stream Stream- & Batch DataStream API (streams, windows) .keyBy("sensor") .timeWindow(Time.seconds(5)) Data Processing .sum((a, b) -> a.add(b)) Stateful Event- Process Function (events, state, time) Driven Applications def processElement(event: MyEvent, ctx: Context, out: Collector[Result]) = { // work with event and state (event, state.value) match { … } out.collect(…) // emit events state.update(…) // modify state // schedule a timer callback 5 © 2018 data Artisans ctx.timerService.registerEventTimeTimer(event.timestamp + 500) }
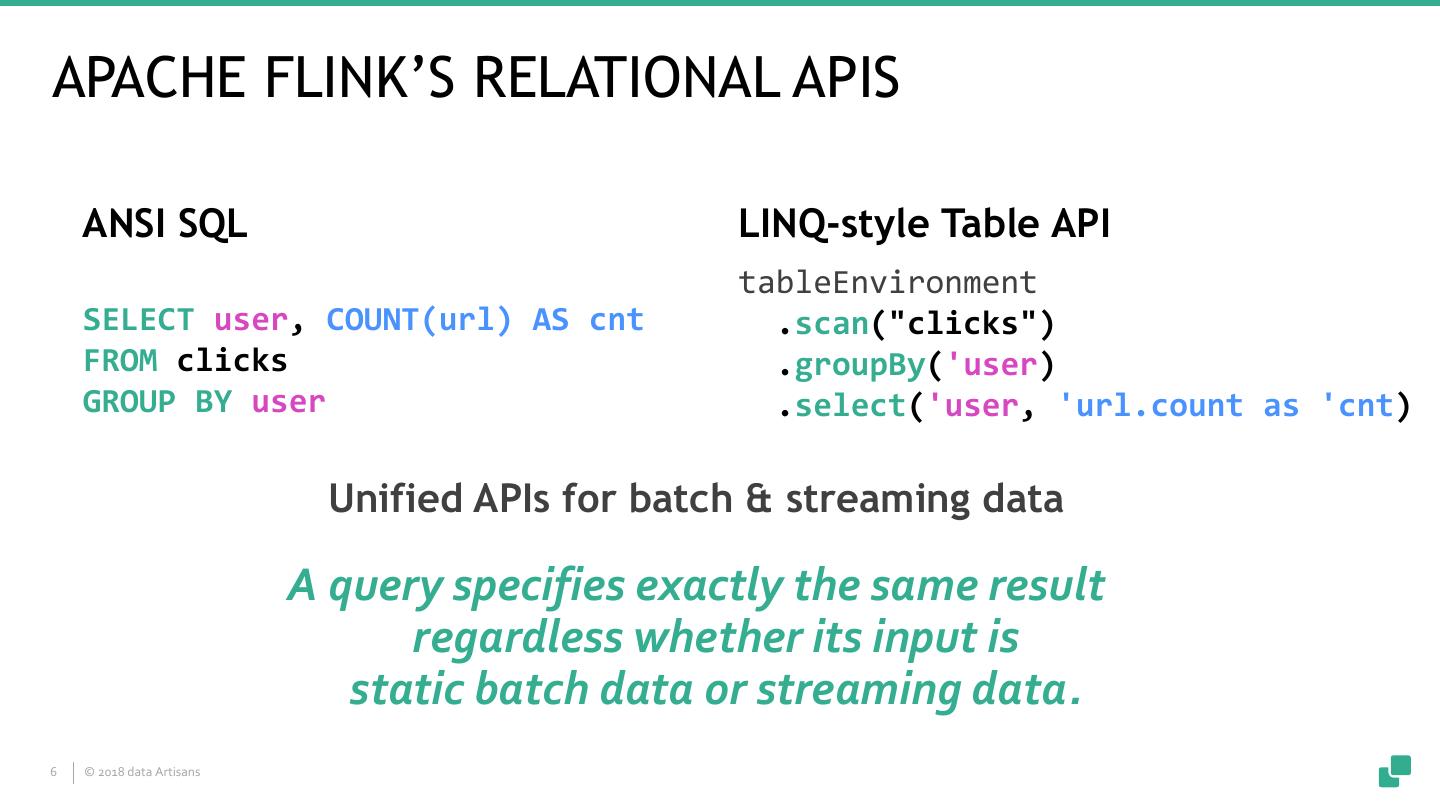
6 .APACHE FLINK’S RELATIONAL APIS ANSI SQL LINQ-style Table API tableEnvironment SELECT user, COUNT(url) AS cnt .scan("clicks") FROM clicks .groupBy('user) GROUP BY user .select('user, 'url.count as 'cnt) Unified APIs for batch & streaming data A query specifies exactly the same result regardless whether its input is static batch data or streaming data. 6 © 2018 data Artisans
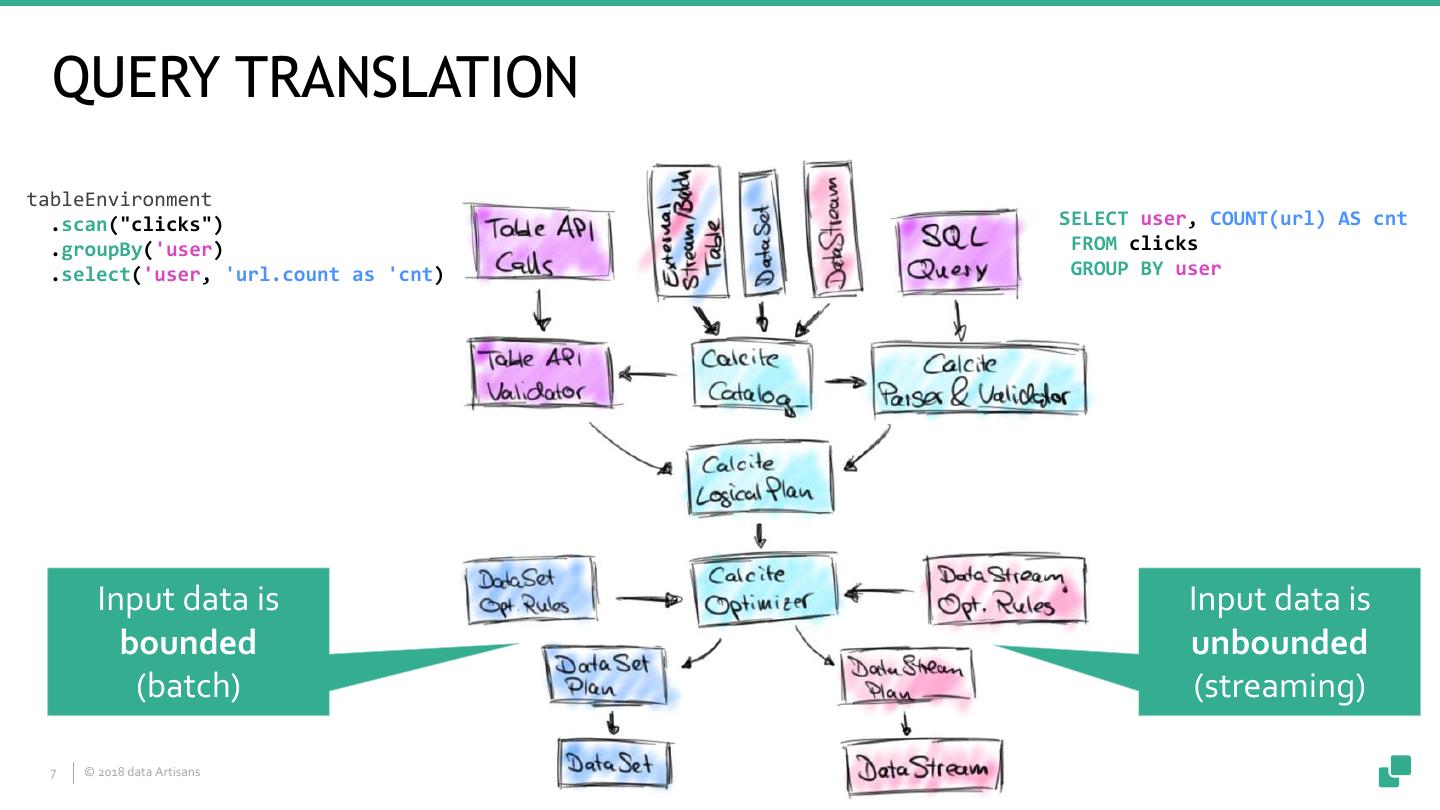
7 . QUERY TRANSLATION tableEnvironment .scan("clicks") SELECT user, COUNT(url) AS cnt .groupBy('user) FROM clicks .select('user, 'url.count as 'cnt) GROUP BY user Input data is Input data is bounded unbounded (batch) (streaming) 7 © 2018 data Artisans
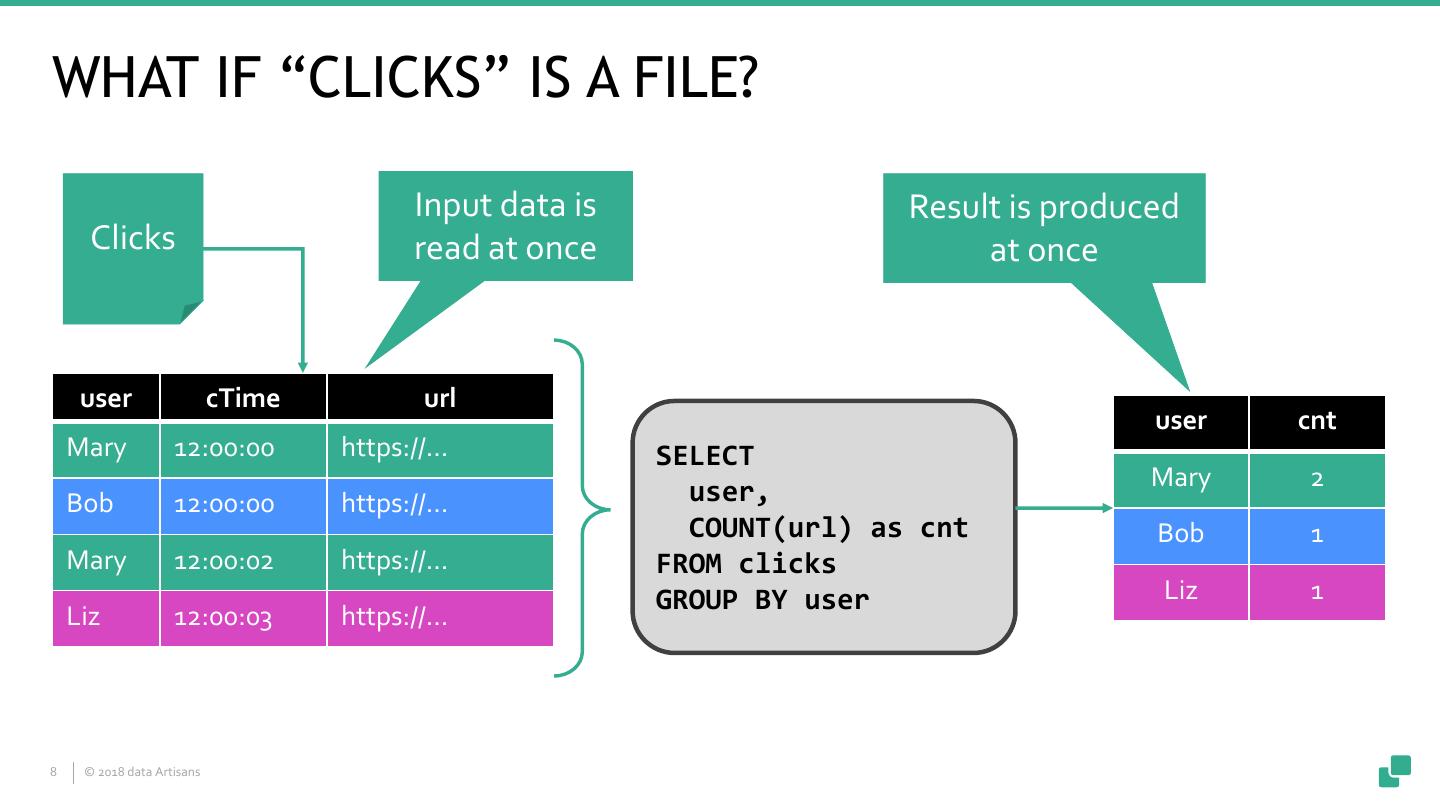
8 .WHAT IF “CLICKS” IS A FILE? Input data is Result is produced Clicks read at once at once user cTime url user cnt Mary 12:00:00 https://… SELECT Mary 2 Bob 12:00:00 https://… user, COUNT(url) as cnt Bob 1 Mary 12:00:02 https://… FROM clicks GROUP BY user Liz 1 Liz 12:00:03 https://… 8 © 2018 data Artisans
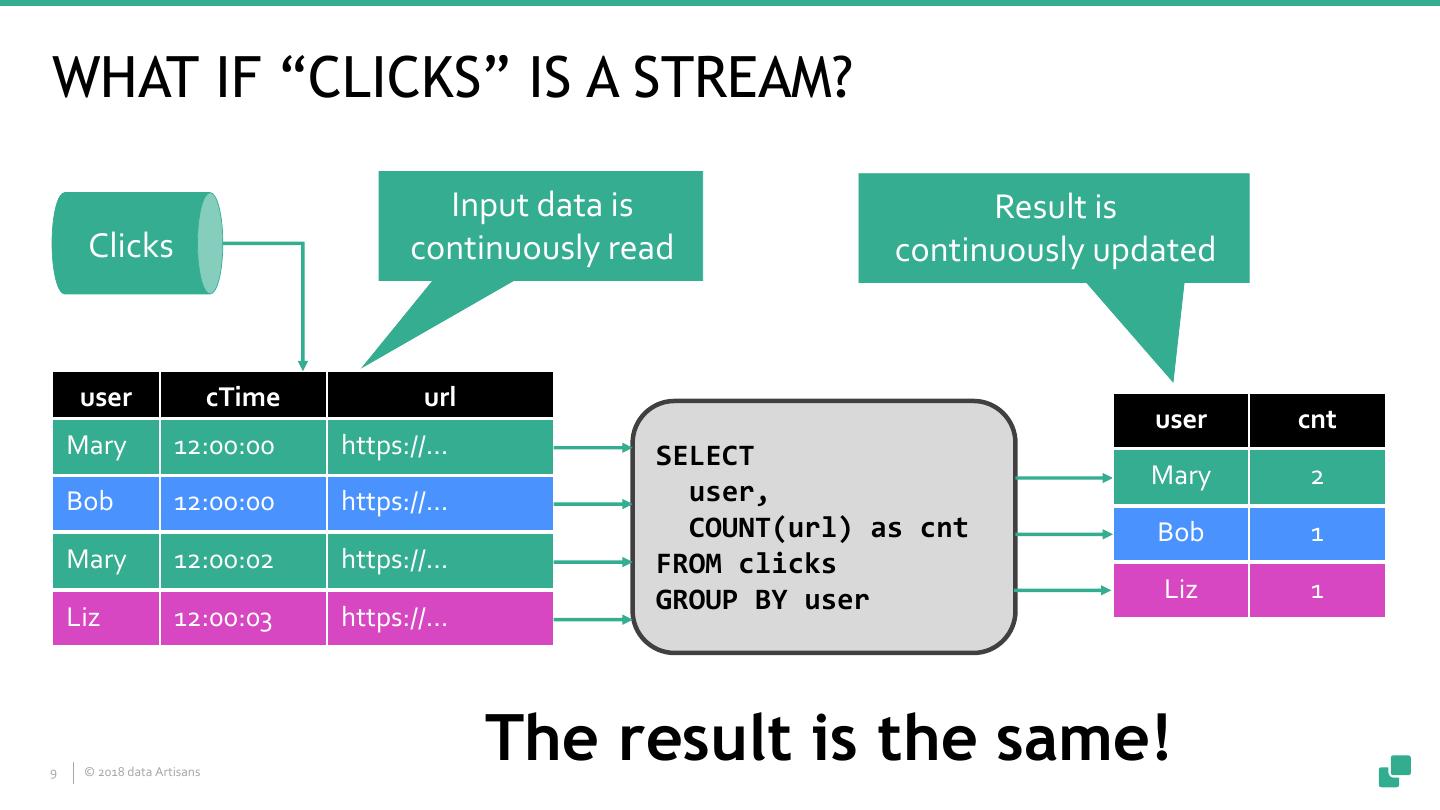
9 .WHAT IF “CLICKS” IS A STREAM? Input data is Result is Clicks continuously read continuously updated user cTime url user cnt Mary 12:00:00 https://… SELECT Mary 21 Bob 12:00:00 https://… user, COUNT(url) as cnt Bob 1 Mary 12:00:02 https://… FROM clicks GROUP BY user Liz 1 Liz 12:00:03 https://… 9 © 2018 data Artisans The result is the same!
10 .WHY IS STREAM-BATCH UNIFICATION IMPORTANT? • Usability ‒ ANSI SQL syntax: No custom “StreamSQL” syntax. ‒ ANSI SQL semantics: No stream-specific results. • Portability ‒ Run the same query on bounded and unbounded data ‒ Run the same query on recorded and real-time data bounded query bounded query start of the stream past now future unbounded query unbounded query • How can we achieve SQL semantics on streams? 10 © 2018 data Artisans
11 .DATABASE SYSTEMS RUN QUERIES ON STREAMS • Materialized views (MV) are similar to regular views, but persisted to disk or memory ‒ Used to speed-up analytical queries ‒ MVs need to be updated when the base tables change • MV maintenance is very similar to SQL on streams ‒ Base table updates are a stream of DML statements ‒ MV definition query is evaluated on that stream ‒ MV is query result and continuously updated 11 © 2018 data Artisans
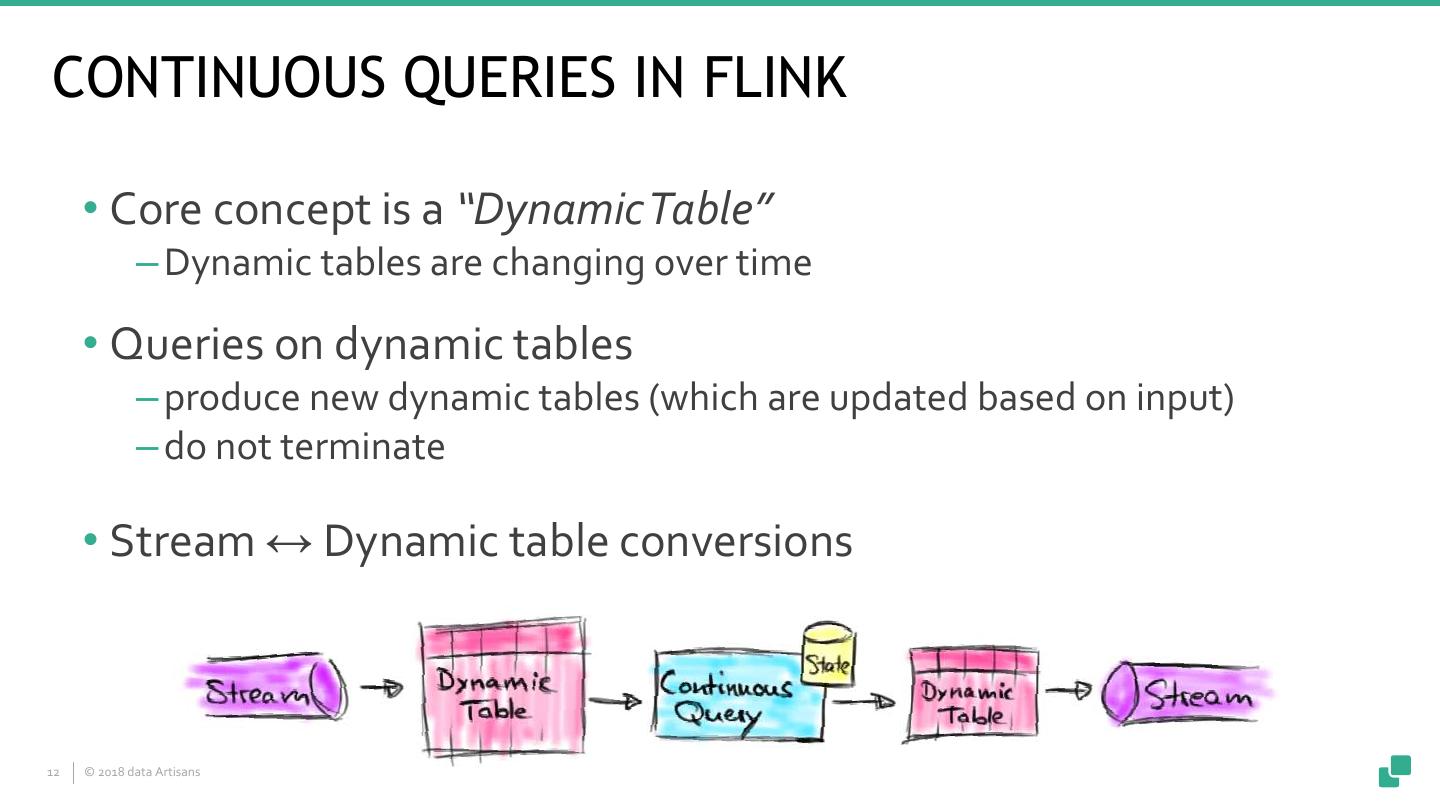
12 .CONTINUOUS QUERIES IN FLINK • Core concept is a “Dynamic Table” ‒ Dynamic tables are changing over time • Queries on dynamic tables ‒ produce new dynamic tables (which are updated based on input) ‒ do not terminate • Stream ↔ Dynamic table conversions 12 © 2018 data Artisans 12
13 .STREAM ↔ DYNAMIC TABLE CONVERSIONS • Append Conversions ‒Records are only inserted/appended • Upsert Conversions ‒Records are inserted/updated/deleted ‒Records have a (composite) unique key • Changelog Conversions ‒Records are inserted/updated/deleted 13 © 2018 data Artisans
14 .SQL FEATURE SET IN FLINK 1.5.0 • SELECT FROM WHERE • GROUP BY / HAVING ‒ Non-windowed, TUMBLE, HOP, SESSION windows • JOIN ‒ Windowed INNER, LEFT / RIGHT / FULL OUTER JOIN ‒ Non-windowed INNER JOIN • Scalar, aggregation, table-valued UDFs • SQL CLI Client (beta) • [streaming only] OVER / WINDOW ‒ UNBOUNDED / BOUNDED PRECEDING • [batch only] UNION / INTERSECT / EXCEPT / IN / ORDER BY 14 © 2018 data Artisans
15 .WHAT CAN I BUILD WITH THIS? • Data Pipelines ‒ Transform, aggregate, and move events in real-time • Low-latency ETL ‒ Convert and write streams to file systems, DBMS, K-V stores, indexes, … ‒ Ingest appearing files to produce streams • Stream & Batch Analytics ‒ Run analytical queries over bounded and unbounded data ‒ Query and compare historic and real-time data • Power Live Dashboards ‒ Compute and update data to visualize in real-time 15 © 2018 data Artisans
16 .THE NEW YORK TAXI RIDES DATA SET • The NewYork City Taxi & Limousine Commission provides a public data set about past taxi rides in New York City • We can derive a streaming table from the data • Table: TaxiRides rideId: BIGINT // ID of the taxi ride isStart: BOOLEAN // flag for pick-up (true) or drop-off (false) event lon: DOUBLE // longitude of pick-up or drop-off location lat: DOUBLE // latitude of pick-up or drop-off location rowtime: TIMESTAMP // time of pick-up or drop-off event 16 © 2018 data Artisans
17 .IDENTIFY POPULAR PICK-UP / DROP-OFF LOCATIONS Compute every 5 minutes for each location the number of departing and arriving taxis of the last 15 minutes. SELECT cell, isStart, HOP_END(rowtime, INTERVAL '5' MINUTE, INTERVAL '15' MINUTE) AS hopEnd, COUNT(*) AS cnt FROM (SELECT rowtime, isStart, toCellId(lon, lat) AS cell FROM TaxiRides) GROUP BY cell, isStart, HOP(rowtime, INTERVAL '5' MINUTE, INTERVAL '15' MINUTE) 17 © 2018 data Artisans
18 .AVERAGE RIDE DURATION PER PICK-UP LOCATION Join start ride and end ride events on rideId and compute average ride duration per pick-up location. SELECT pickUpCell, AVG(TIMESTAMPDIFF(MINUTE, e.rowtime, s.rowtime) AS avgDuration FROM (SELECT rideId, rowtime, toCellId(lon, lat) AS pickUpCell FROM TaxiRides WHERE isStart) s JOIN (SELECT rideId, rowtime FROM TaxiRides WHERE NOT isStart) e ON s.rideId = e.rideId AND e.rowtime BETWEEN s.rowtime AND s.rowtime + INTERVAL '1' HOUR GROUP BY pickUpCell 18 © 2018 data Artisans
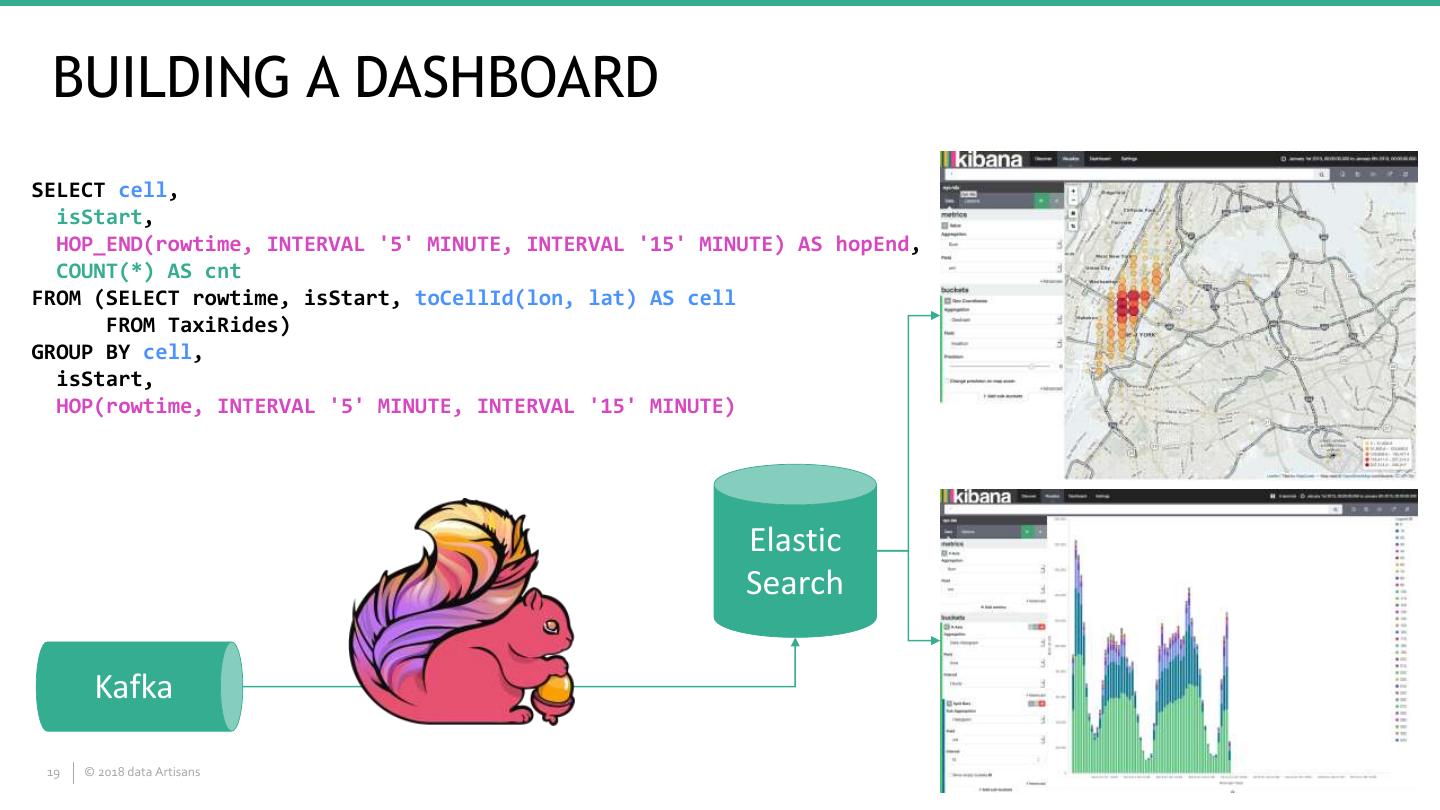
19 . BUILDING A DASHBOARD SELECT cell, isStart, HOP_END(rowtime, INTERVAL '5' MINUTE, INTERVAL '15' MINUTE) AS hopEnd, COUNT(*) AS cnt FROM (SELECT rowtime, isStart, toCellId(lon, lat) AS cell FROM TaxiRides) GROUP BY cell, isStart, HOP(rowtime, INTERVAL '5' MINUTE, INTERVAL '15' MINUTE) Elastic Search Kafka 19 © 2018 data Artisans
20 . SOUNDS GREAT! HOW CAN I USE IT? • ATM, SQL queries must be embedded in Java/Scala code ‒ Tight integration with DataStream and DataSet APIs • Community focused on internals (until Flink 1.4.0) ‒ Operators, types, built-in functions, extensibility (UDFs, extern. catalog) ‒ Proven at scale by Alibaba, Huawei, and Uber ‒ All built their own submission system & connectors library • Community neglected user interfaces ‒ No query submission client, no CLI ‒ No integration with common catalog services ‒ Limited set of TableSources and TableSinks 20 © 2018 data Artisans
21 .COMING IN FLINK 1.5.0 - SQL CLI Demo Time! That’s a nice toy, but … ... can I use it for anything serious? 21 © 2018 data Artisans
22 .FLIP-24 – A SQL QUERY SERVICE • REST service to submit & manage SQL queries ‒ SELECT … ‒ INSERT INTO SELECT … ‒ CREATE MATERIALIZE VIEW … • Serve results of “SELECT …” queries • Provide a table catalog (integrated with external catalogs) • Use cases ‒ Data exploration with notebooks like Apache Zeppelin ‒ Access to real-time data from applications ‒ Easy data routing / ETL from management consoles 22 © 2018 data Artisans
23 .CHALLENGE: SERVE DYNAMIC TABLES Unbounded input yields unbounded results (Serving bounded results is easy) SELECT user, url SELECT user, COUNT(url) AS cnt FROM clicks FROM clicks WHERE url LIKE '%xyz.com' GROUP BY user Append-only Table Continuously updating Table • Result rows are never changed • Result rows can be updated or • Consume, buffer, or drop rows deleted • Consume changelog or periodically query result table • Result table must be maintained 23 © 2018 data Artisans somewhere
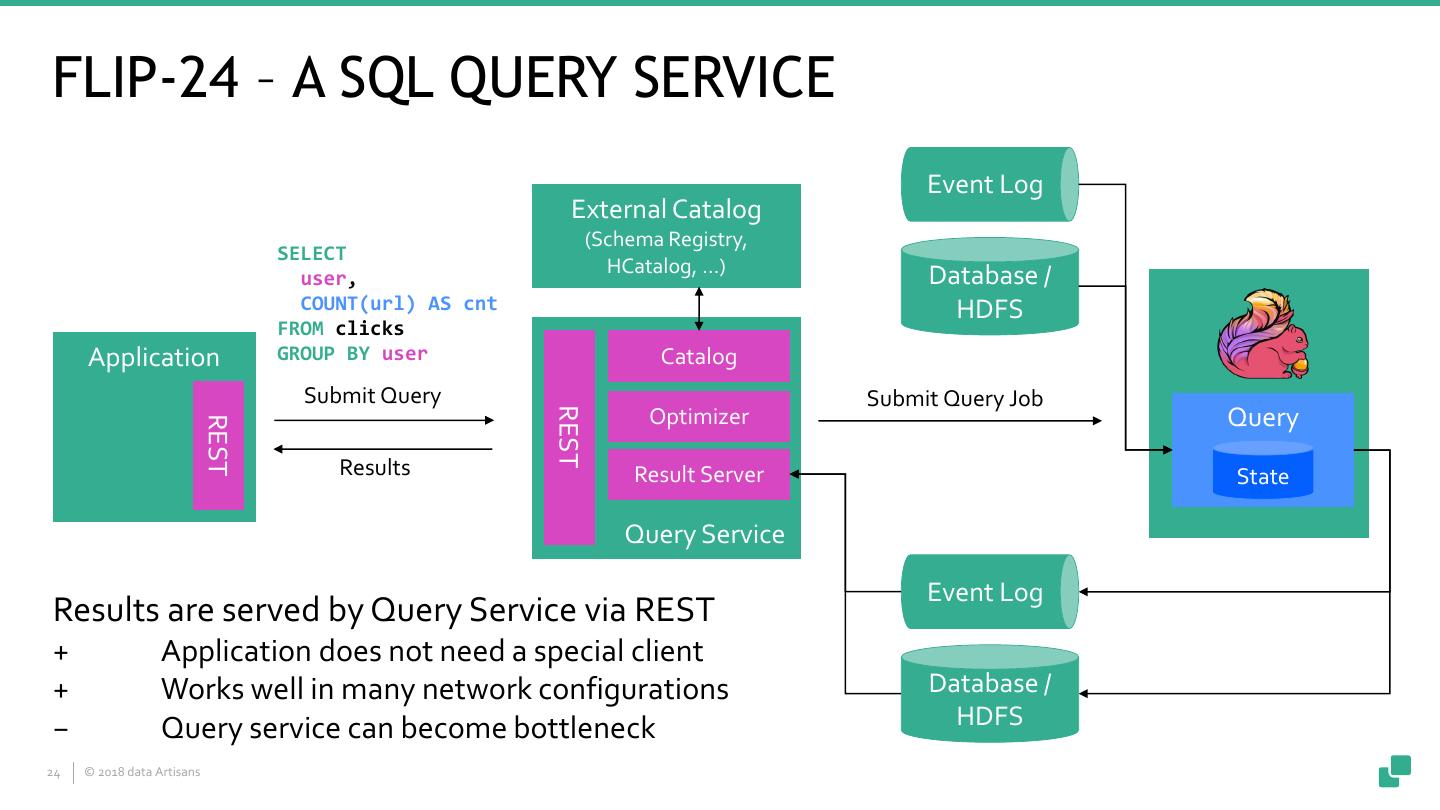
24 .FLIP-24 – A SQL QUERY SERVICE Event Log External Catalog (Schema Registry, SELECT HCatalog, …) user, Database / COUNT(url) AS cnt HDFS FROM clicks Application GROUP BY user Catalog Submit Query Submit Query Job REST Optimizer Query REST Results Result Server State Query Service Event Log Results are served by Query Service via REST + Application does not need a special client + Works well in many network configurations Database / − Query service can become bottleneck HDFS 24 © 2018 data Artisans
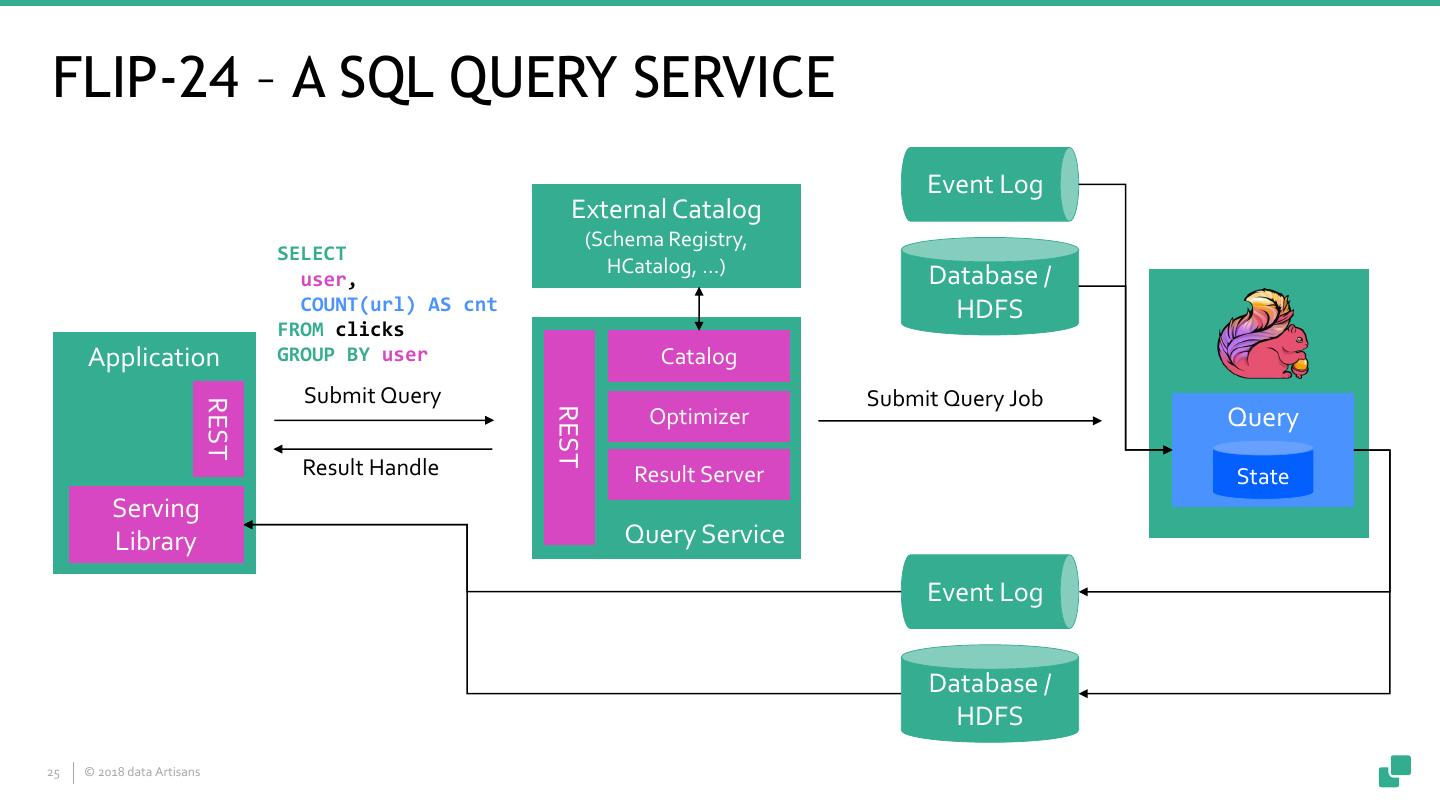
25 .FLIP-24 – A SQL QUERY SERVICE Event Log External Catalog (Schema Registry, SELECT HCatalog, …) user, Database / COUNT(url) AS cnt HDFS FROM clicks Application GROUP BY user Catalog Submit Query Submit Query Job REST REST Optimizer Query Result Handle Result Server State Serving Library Query Service Event Log Database / HDFS 25 © 2018 data Artisans
26 .WE WANT YOUR FEEDBACK! • The design of SQL Query Service is not final yet. • Check out FLIP-24 and FLINK-7594 • Share your ideas and feedback and discuss on JIRA or dev@flink.apache.org. 26 © 2018 data Artisans
27 .SUMMARY • Unification of stream and batch is important. • Flink’s SQL solves many streaming and batch use cases. • Runs in production at Alibaba, Uber, and others. • The community is working on improving user interfaces. • Get involved, discuss, and contribute! 27 © 2018 data Artisans
28 .THANK YOU! Available on O’Reilly Early Release!
29 .THANK YOU! @fhueske & @twalthr @dataArtisans WE ARE HIRING @ApacheFlink data-artisans.com/careers
相关推荐
3秒后跳转登录页面
去登陆

