展开查看详情
1 .Stream Processing
Revolutionizing Big Data
Srikanth Satya
April 2018
�
2 .Data-Intensive Apps Need Disruptive Technologies
The Unbundled Database vision sounds awesome!
Loosely coupled data derivations and transformations
Update derived state by observing data changes
Observe changes in derived state – all the way to the edge
Integrity and correctness: end-to-end IDs, idempotence, data
consistency and exactly once semantics
BUT realizing it requires disruptive systems capabilities
Shared, durable, consistent, unbound distributed log storage
Ability to dynamically scale both the log(s) and downstream
processors in coordination with data arrival volume
Ability to deliver timely and accurate results processing the log
continuously even with late arriving or out of order data
pravega.io
�
3 .Data-Intensive Apps Are Disruptive
The Unbundled Database vision sounds awesome!
Loosely coupled data derivations and transformations
We
Update derived state by observing
passionately believe data
inchanges
these principles.
Observe changes in derived state – all the way to the edge
Integrity and correctness: end-to-end IDs, idempotence, data
As the industry
consistency leaders
and exactly once in storage, we’re
semantics
developing a new, open storage primitive
BUT realizingall
enabling it requires
of us todisruptive
realize systems
the fullcapabilities
potential of
Shared, durable, consistent, unbound distributed log storage
this powerful vision.
Ability to dynamically scale both the log(s) and downstream
processors in coordination with data arrival volume
Ability to deliver timely and accurate results processing the log
continuously even with late arriving or out of order data
pravega.io
�
4 .Introducing Pravega Stream Storage
pravega.io
�
5 .Introducing Pravega Stream Storage
A new storage abstraction – a stream – for continuous and infinite data
Named, durable, append-only, infinite sequence of bytes
With low-latency appends to and reads from the tail of the sequence
With high-throughput reads for older portions of the sequence
Coordinated scaling of stream storage and stream processing
Stream writes partitioned by app-defined routing key
Stream reads independently and automatically partitioned by arrival rate SLO
Scaling protocol to allow stream processors to scale in lockstep with storage
Enabling system-wide exactly once processing across multiple apps
Streams are ordered and strongly consistent
Chain independent streaming apps via streams
Stream transactions integrate with checkpoint schemes such as the one used in Flink
pravega.io
�
6 .Revisiting the Disruptive Capabilities
Required Systems Capabilities Enabling Pravega Features
Shared, durable, consistent, Durable, append-only byte streams
unbound distributed log storage Consistent tail and replay reads
Unlimited retention, storage efficiency
Dynamically scale logs in Auto-scaling
coordination with downstream
processors Independently scale readers/writers
Deliver accurate results processing Transactions and exactly once
continuously even with late arriving Event time and processing time
or out of order data
pravega.io
�
7 .The Streaming Revolution
Enabling continuous pipelines w/ consistent replay, composability, elasticity, exactly once
Ingest Buffer State Streaming Streaming
& Pub/Sub Synchronizer Analytics Search
Pravega Stream Store
Cloud-Scale Storage
pravega.io
�
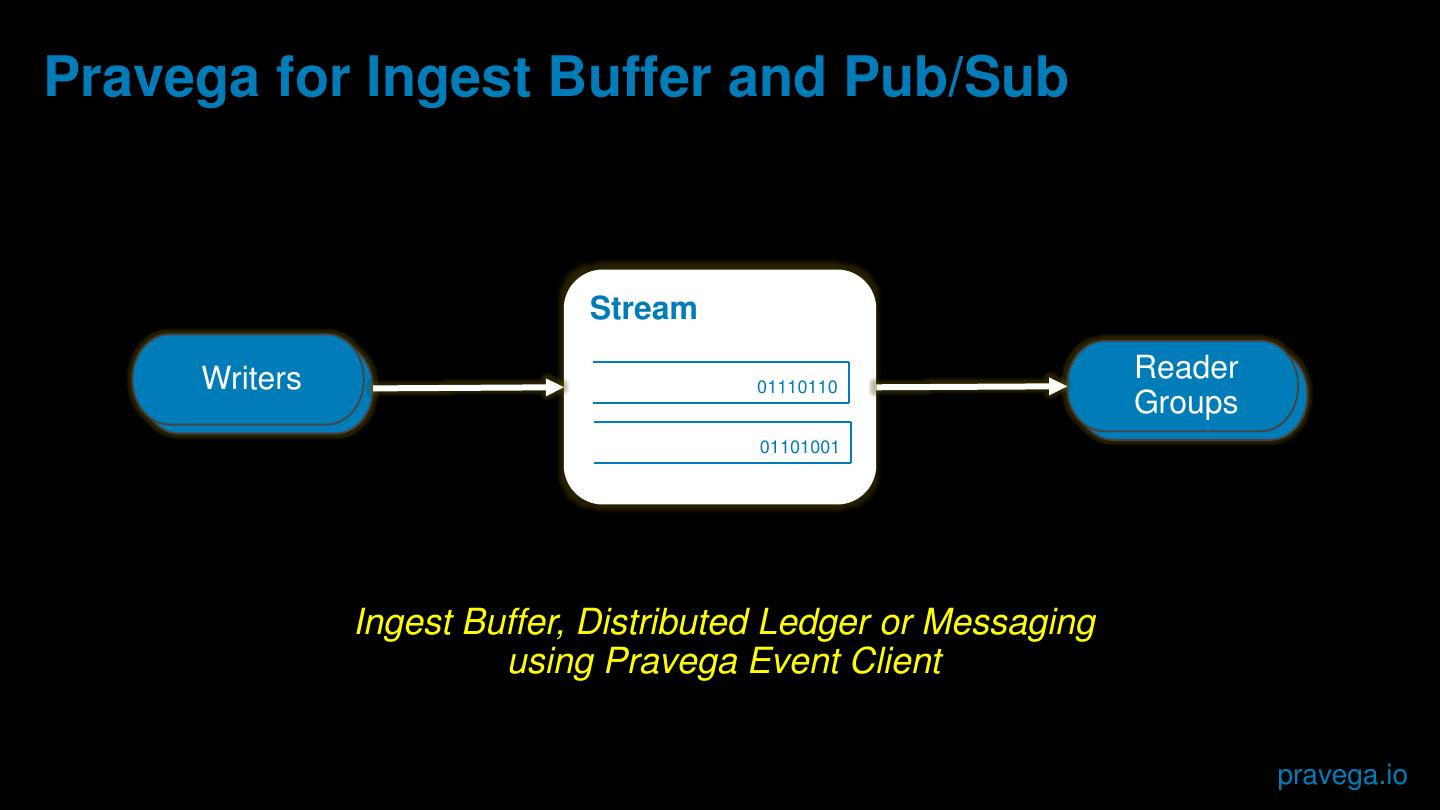
8 .Pravega for Ingest Buffer and Pub/Sub
Stream
Consumer
Writers 01110110
Reader
Consumer
s Groups
s
01101001
Ingest Buffer, Distributed Ledger or Messaging
using Pravega Event Client
pravega.io
�
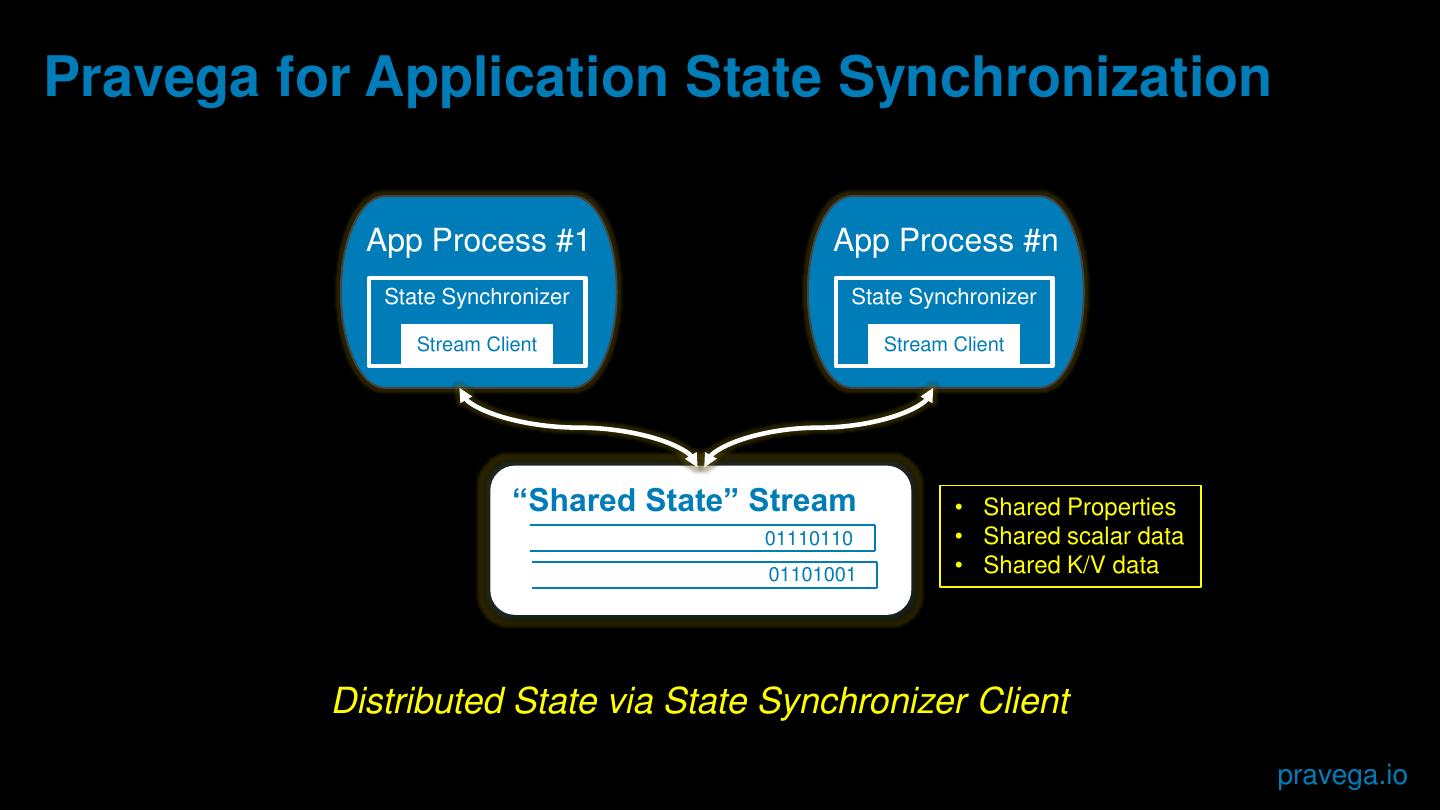
9 .Pravega for Application State Synchronization
App Process #1 App Process #n
State Synchronizer State Synchronizer
Stream Client Stream Client
“Shared State” Stream • Shared Properties
01110110 • Shared scalar data
01101001 • Shared K/V data
Distributed State via State Synchronizer Client
pravega.io
�
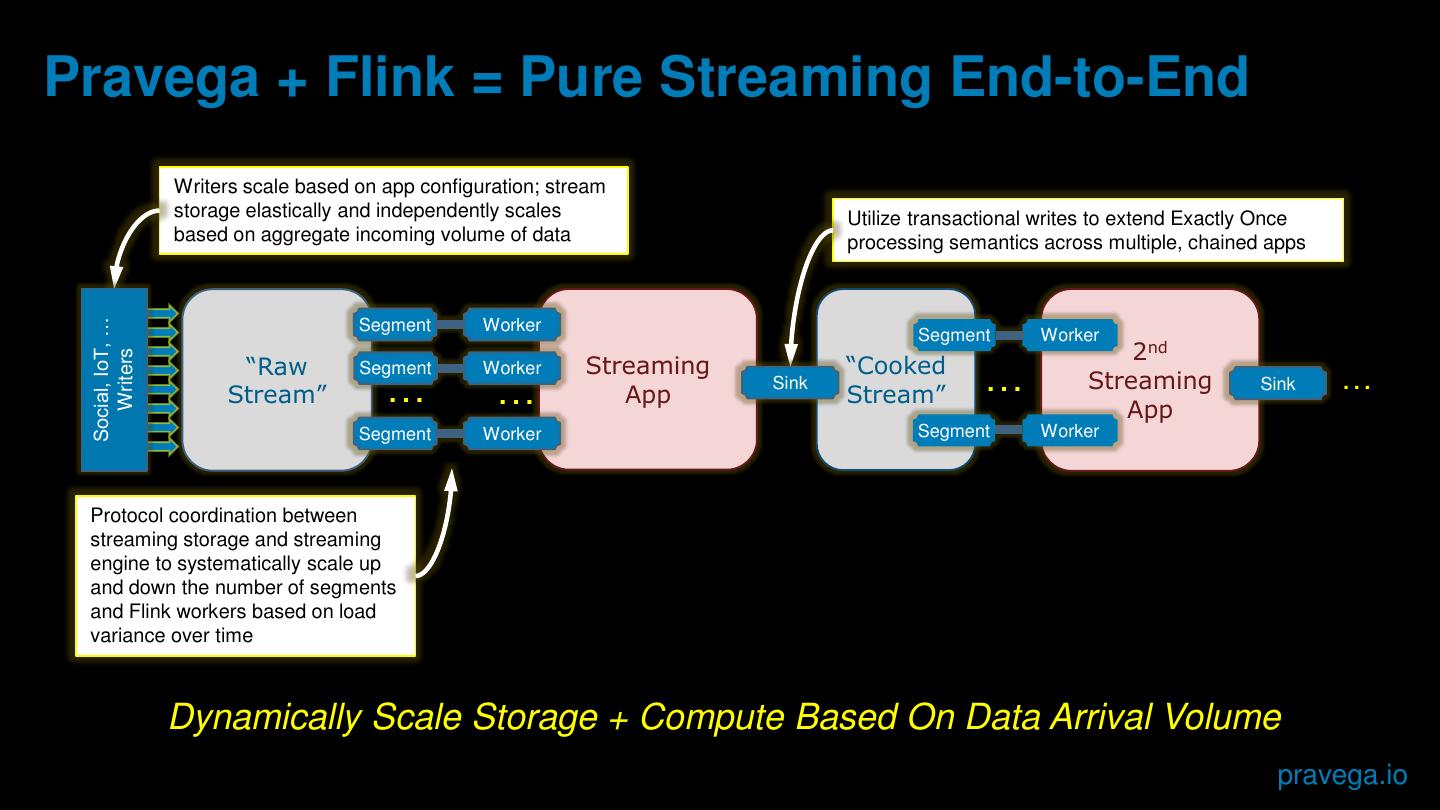
10 .Pravega + Flink = Pure Streaming End-to-End
Writers scale based on app configuration; stream
storage elastically and independently scales Utilize transactional writes to extend Exactly Once
based on aggregate incoming volume of data processing semantics across multiple, chained apps
Social, IoT, …
Segment Worker
Segment Worker
2nd
Writers
“Raw Streaming “Cooked
Stream”
Segment
…
Worker
… App
Sink
Stream”
… Streaming Sink …
App
Segment Worker Segment Worker
Protocol coordination between
streaming storage and streaming
engine to systematically scale up
and down the number of segments
and Flink workers based on load
variance over time
Dynamically Scale Storage + Compute Based On Data Arrival Volume
pravega.io
�
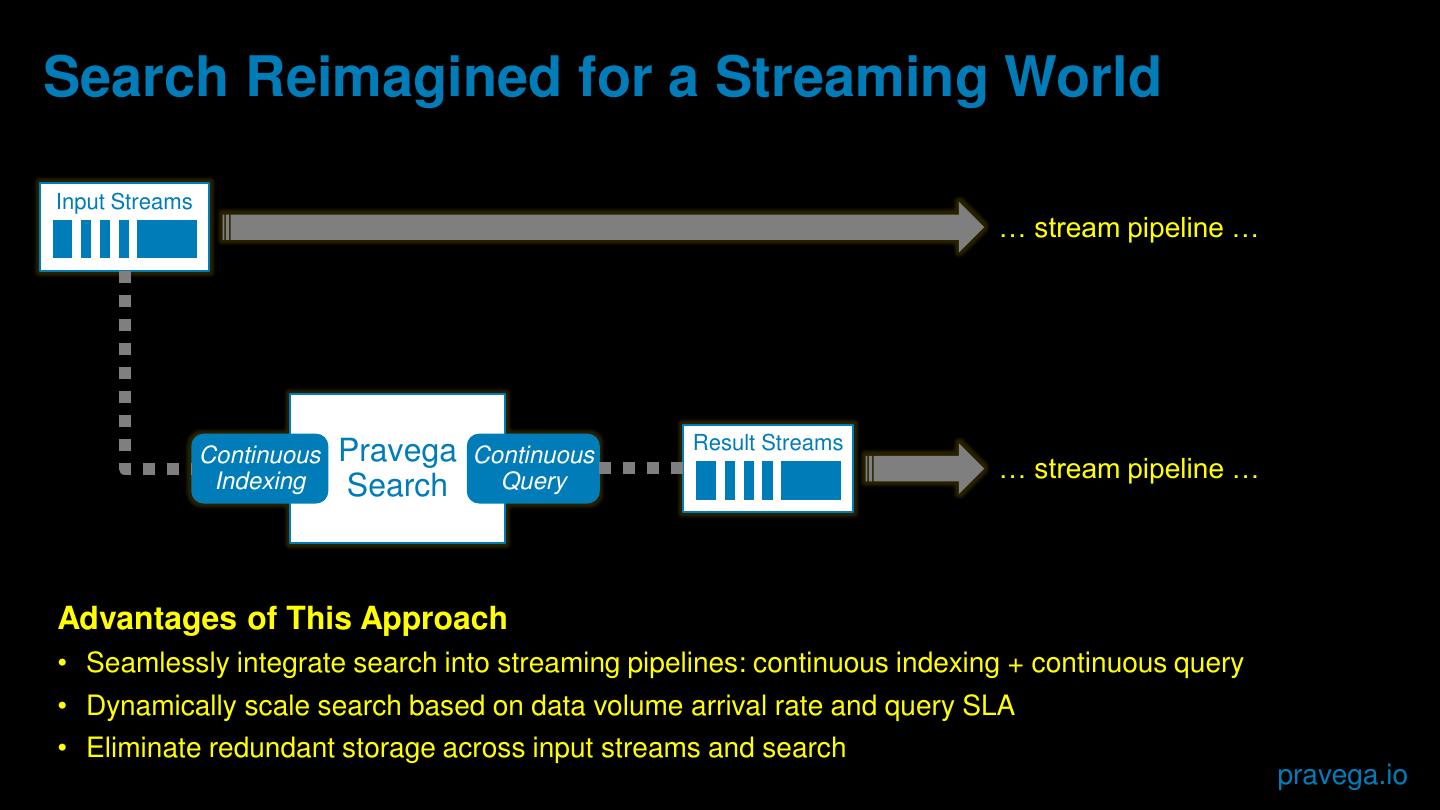
11 .Search Reimagined for a Streaming World
Input Streams
… stream pipeline …
Pravega Result Streams
Continuous Continuous
Indexing Query … stream pipeline …
Search
Advantages of This Approach
• Seamlessly integrate search into streaming pipelines: continuous indexing + continuous query
• Dynamically scale search based on data volume arrival rate and query SLA
• Eliminate redundant storage across input streams and search
pravega.io
�
12 . Pravega: an open source project with an open community
Software includes infinite byte stream primitive, event abstraction, ingest
buffer, and pub/sub services
Flink integration for scale, elasticity, and system-wide exactly once
Join the community at pravega.io
pravega.io
�