

































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Scaling Flink in Cloud
每天都有超过1.09亿Netflix用户观看1.25亿小时的电视和电影,大量的数据将会流向了我们的数据分析平台,用以分析用户行为,并改善用户体验,诸如个性化,诈骗检测等等。数据平台的核心是每天处理3兆亿(3 trillion)事件和12PB的数据集合,我们将分享这个过程中使用Flink碰到的问题和挑战。
展开查看详情
1 .Scaling Flink in Cloud Steven Wu @stevenzwu
2 .Agenda ● Introduction ● Scaling stateless jobs ● Scaling stateful jobs
3 .Agenda ● Introduction ● Scaling stateless jobs ● Scaling stateful jobs
4 .Running Flink on Titus (Netflix’s in-house container runtime)
5 . Job isolation: single job Flink standalone Titus Job #1 cluster Job Manager Titus Job #2 Task Task ... Task Manager Manager Manager
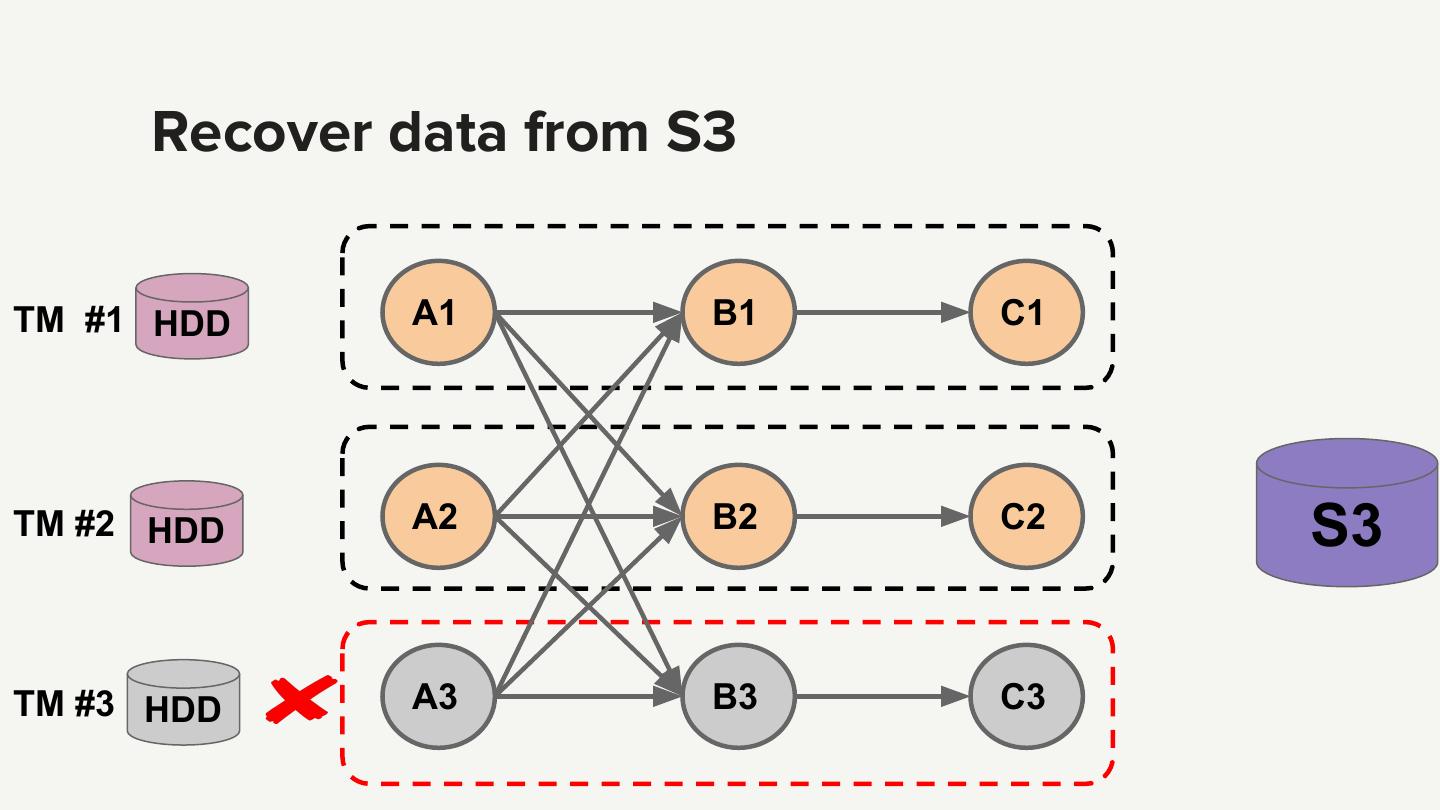
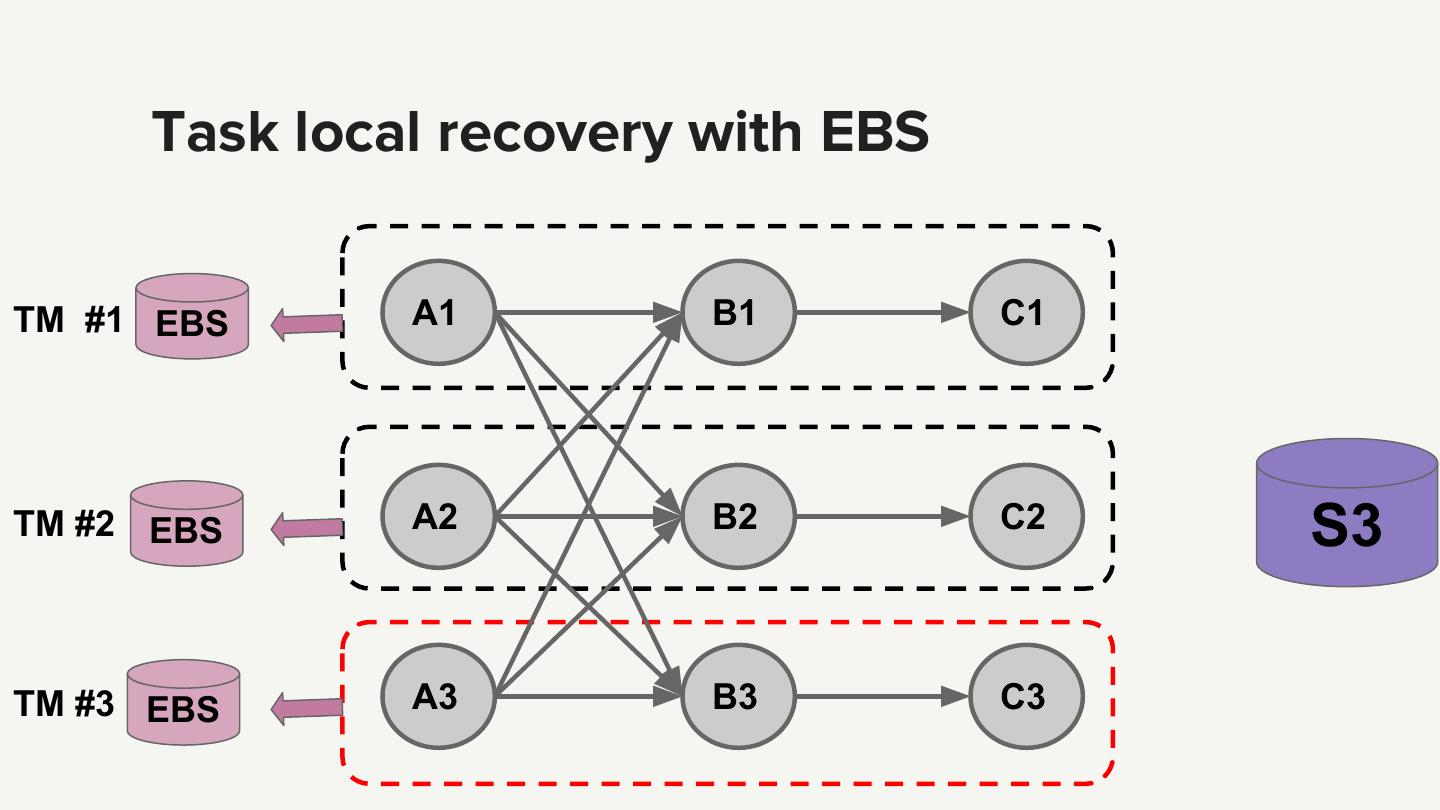
6 .State backend and checkpoint store State backend ● Memory ● File system ● RocksDB checkpoint store ● HDFS ● S3 Source: http://flink.apache.org/
7 . Why S3 as the snapshot store ● Only out-of-the-box support for Amazon cloud ● Cost-effective, scalability, durability
8 . S3 concepts ● Massive storage system ● Bucket: container for objects ● Object: identified by a key (and a version) ● Filesystem like operations ○ GET, PUT, DELETE, LIST, HEAD
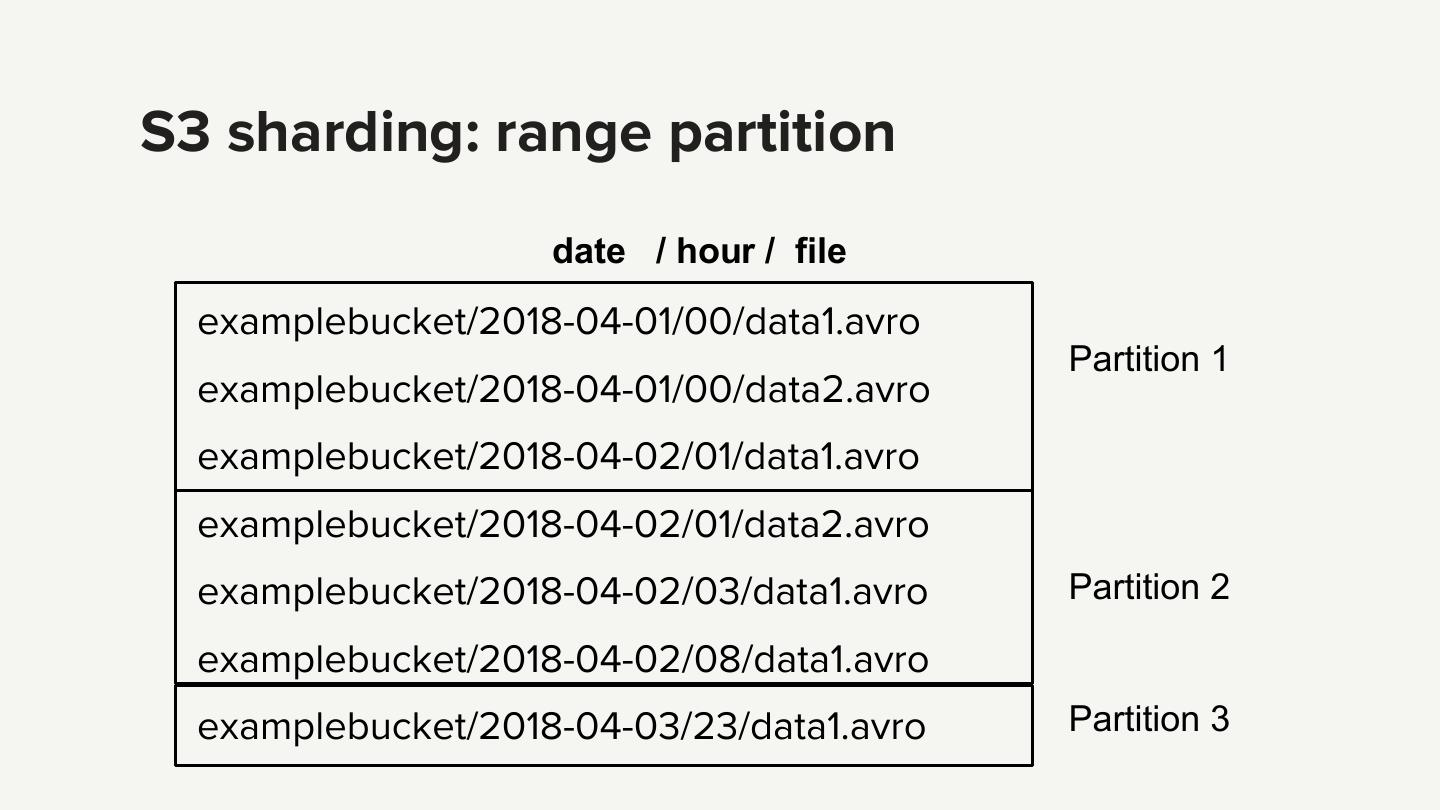
9 .S3 sharding: range partition date / hour / file examplebucket/2018-04-01/00/data1.avro Partition 1 examplebucket/2018-04-01/00/data2.avro examplebucket/2018-04-02/01/data1.avro examplebucket/2018-04-02/01/data2.avro examplebucket/2018-04-02/03/data1.avro Partition 2 examplebucket/2018-04-02/08/data1.avro examplebucket/2018-04-03/23/data1.avro Partition 3
10 .LIST (prefix query) date / hour / file examplebucket/2018-04-01/00/data1.avro Partition 1 examplebucket/2018-04-01/00/data2.avro examplebucket/2018-04-02/01/data1.avro examplebucket/2018-04-02/01/data2.avro examplebucket/2018-04-02/03/data1.avro Partition 2 examplebucket/2018-04-02/08/data1.avro examplebucket/2018-04-03/23/data1.avro Partition 3
11 . S3 scaling ● If request rate grows steadily, S3 automatically partitions buckets as needed to support higher request rates
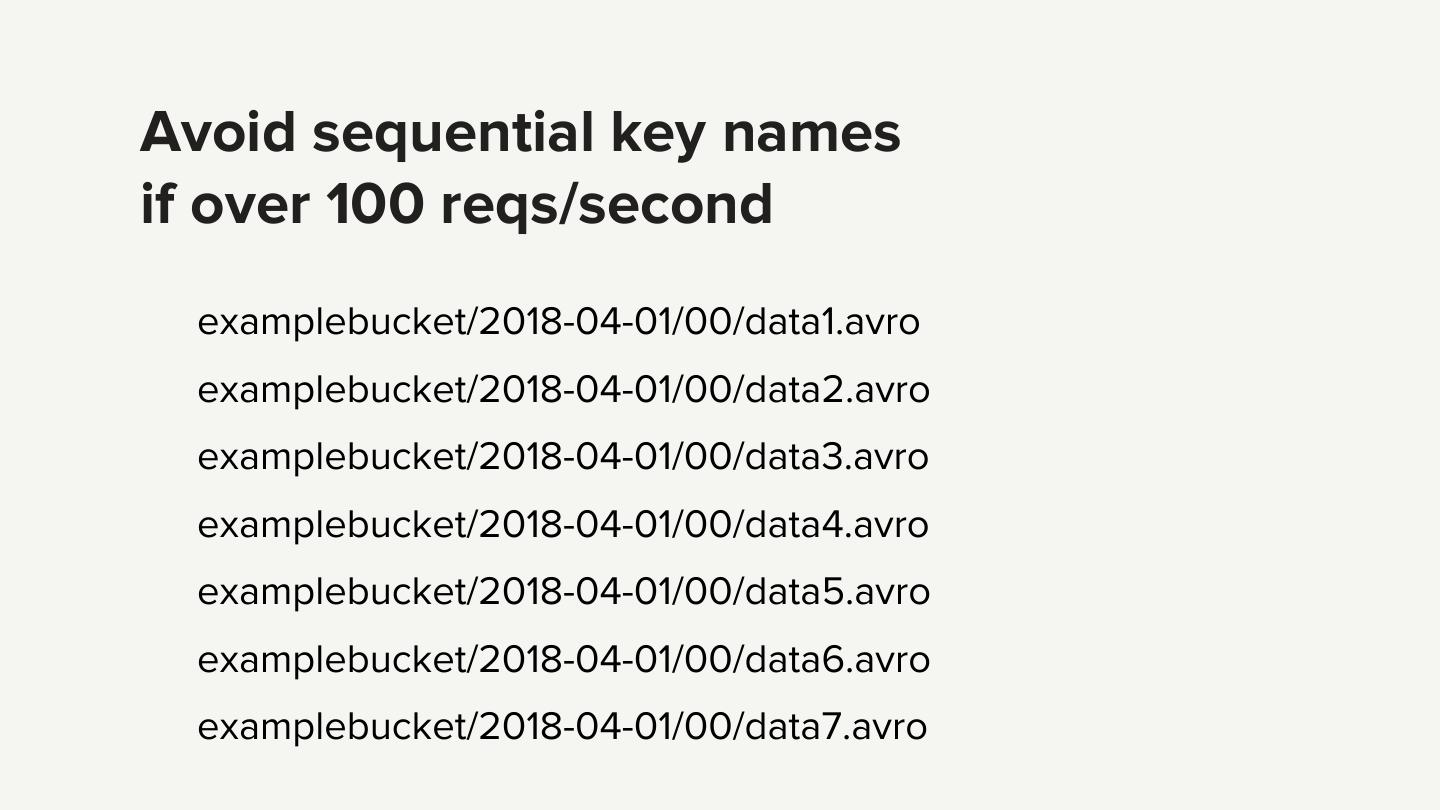
12 .Avoid sequential key names if over 100 reqs/second examplebucket/2018-04-01/00/data1.avro examplebucket/2018-04-01/00/data2.avro examplebucket/2018-04-01/00/data3.avro examplebucket/2018-04-01/00/data4.avro examplebucket/2018-04-01/00/data5.avro examplebucket/2018-04-01/00/data6.avro examplebucket/2018-04-01/00/data7.avro
13 .Introduce random prefix in key name examplebucket/232a/2018-04-01/00/data1.avro examplebucket/7b54/2018-04-01/00/data2.avro examplebucket/921c/2018-04-01/00/data3.avro examplebucket/ba65/2018-04-01/00/data4.avro examplebucket/8761/2018-04-01/00/data5.avro examplebucket/a390/2018-04-01/00/data6.avro examplebucket/5d6c/2018-04-01/00/data7.avro
14 . S3 Performance ● Optimized for high I/O throughput ● Not optimized for high request rate without tweaking key names ● Not optimized for small files ● Not optimized for consistent low latency
15 .Agenda ● Introduction ● Scaling stateless jobs ● Scaling stateful jobs
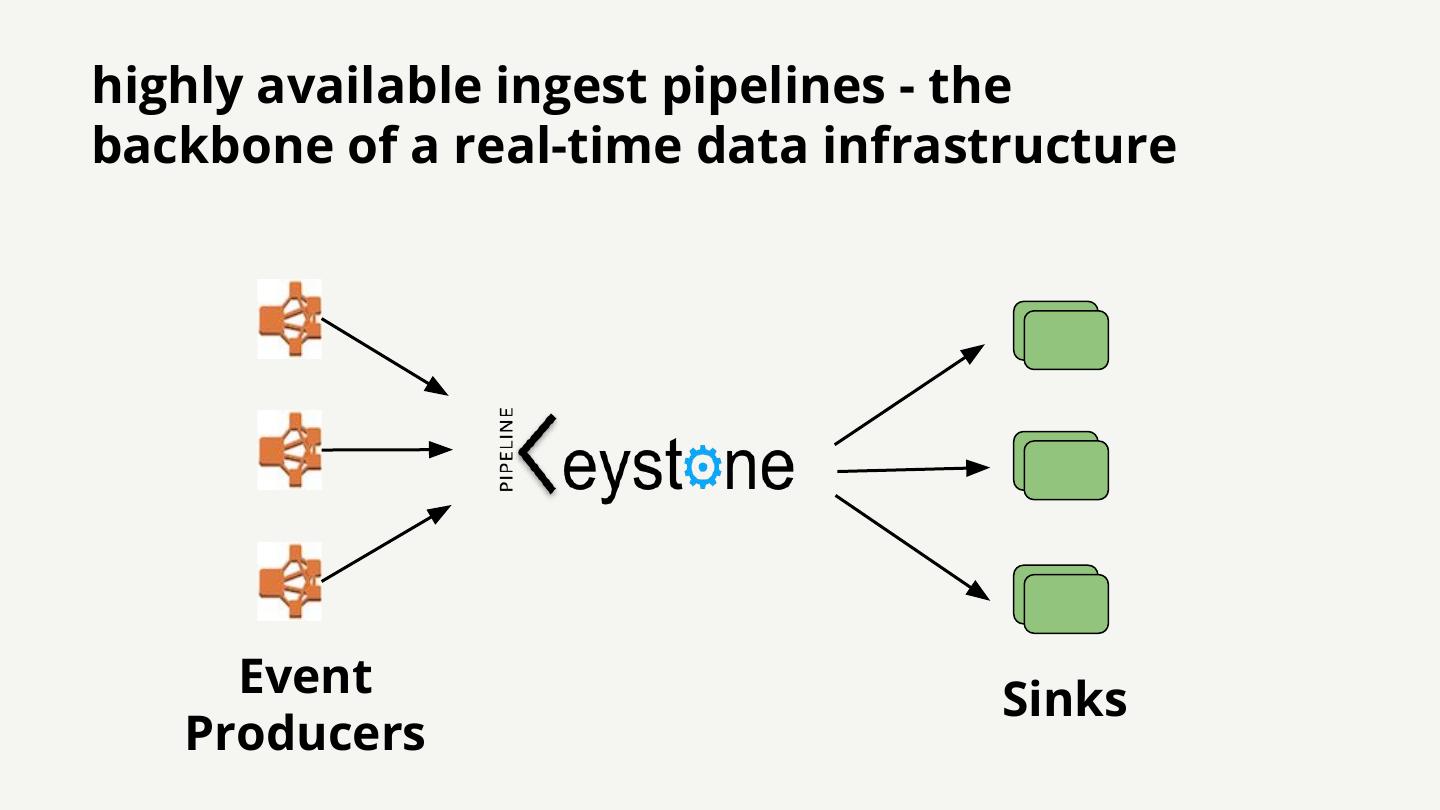
16 .highly available ingest pipelines - the backbone of a real-time data infrastructure Event Sinks Producers
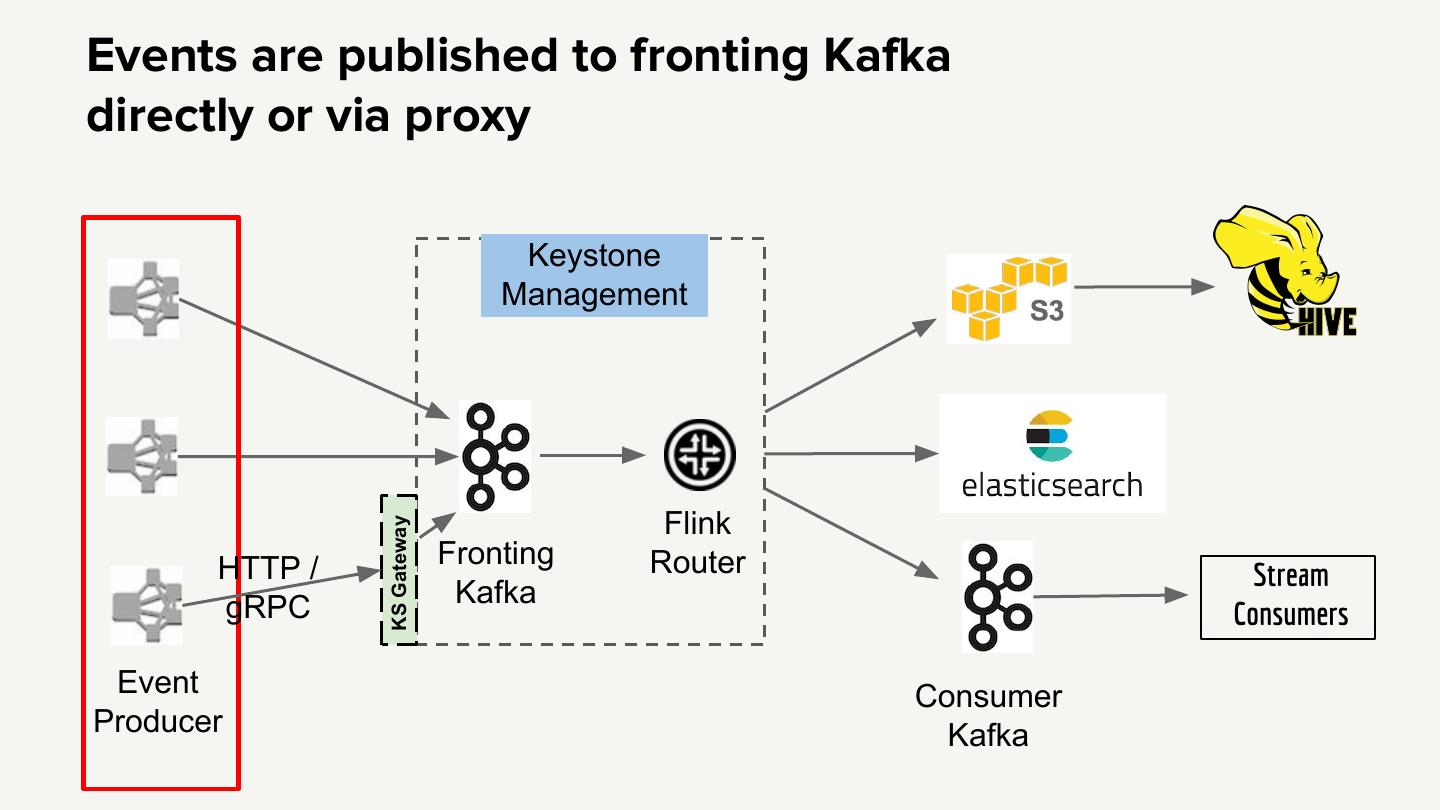
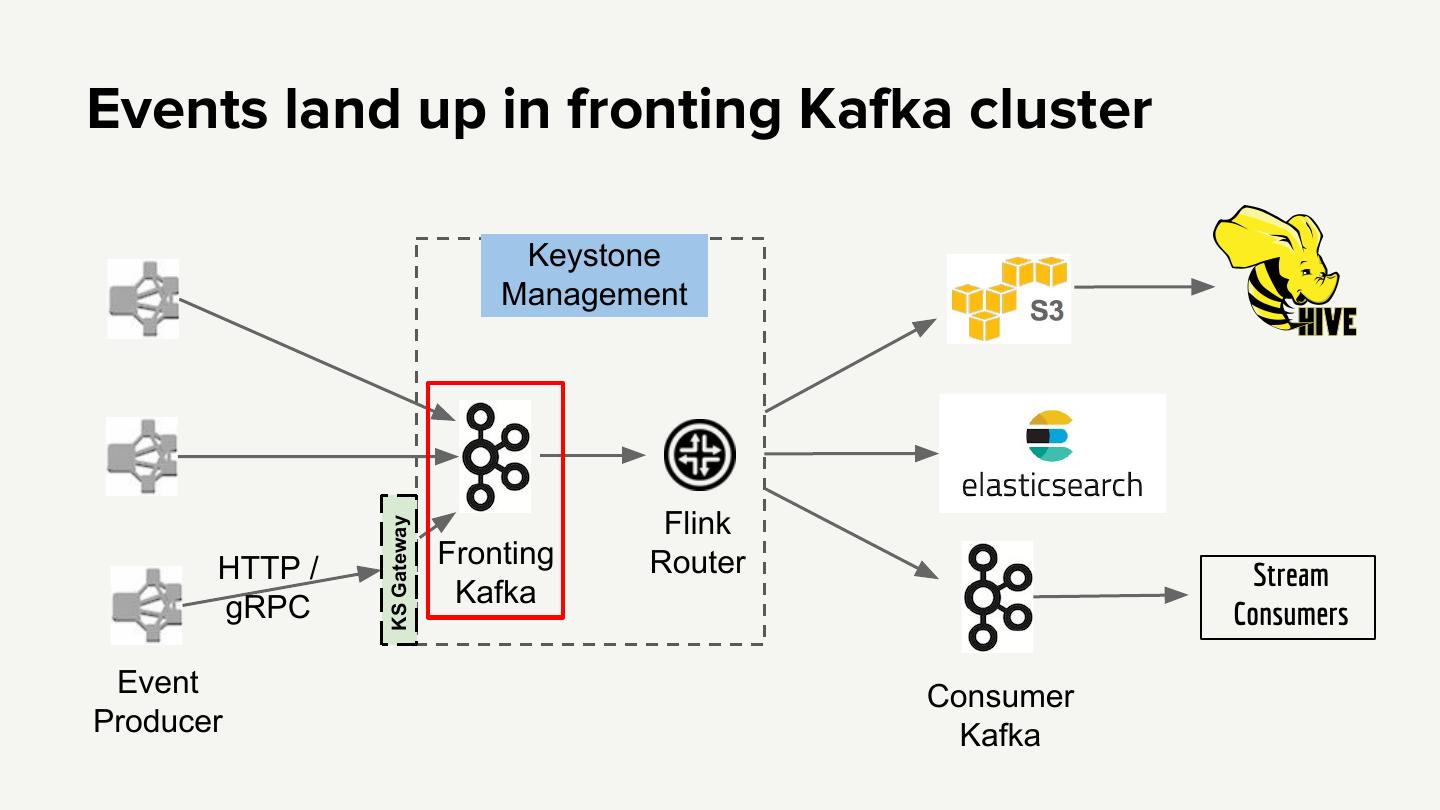
17 .Events are published to fronting Kafka directly or via proxy Keystone Management Flink KS Gateway HTTP / Fronting Router Stream gRPC Kafka Consumers Event Consumer Producer Kafka
18 .Events land up in fronting Kafka cluster Keystone Management Flink KS Gateway HTTP / Fronting Router Stream gRPC Kafka Consumers Event Consumer Producer Kafka
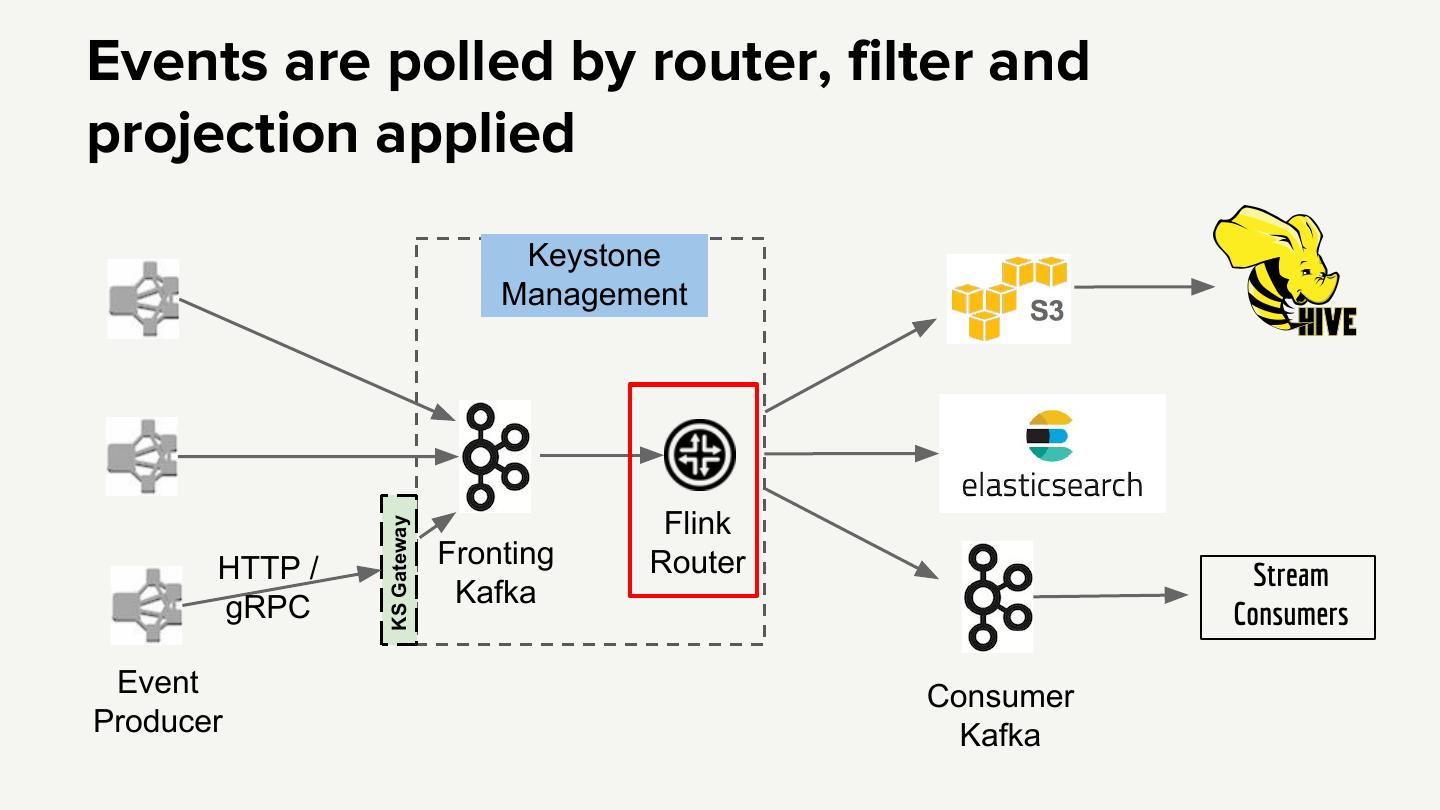
19 .Events are polled by router, filter and projection applied Keystone Management Flink KS Gateway HTTP / Fronting Router Stream gRPC Kafka Consumers Event Consumer Producer Kafka
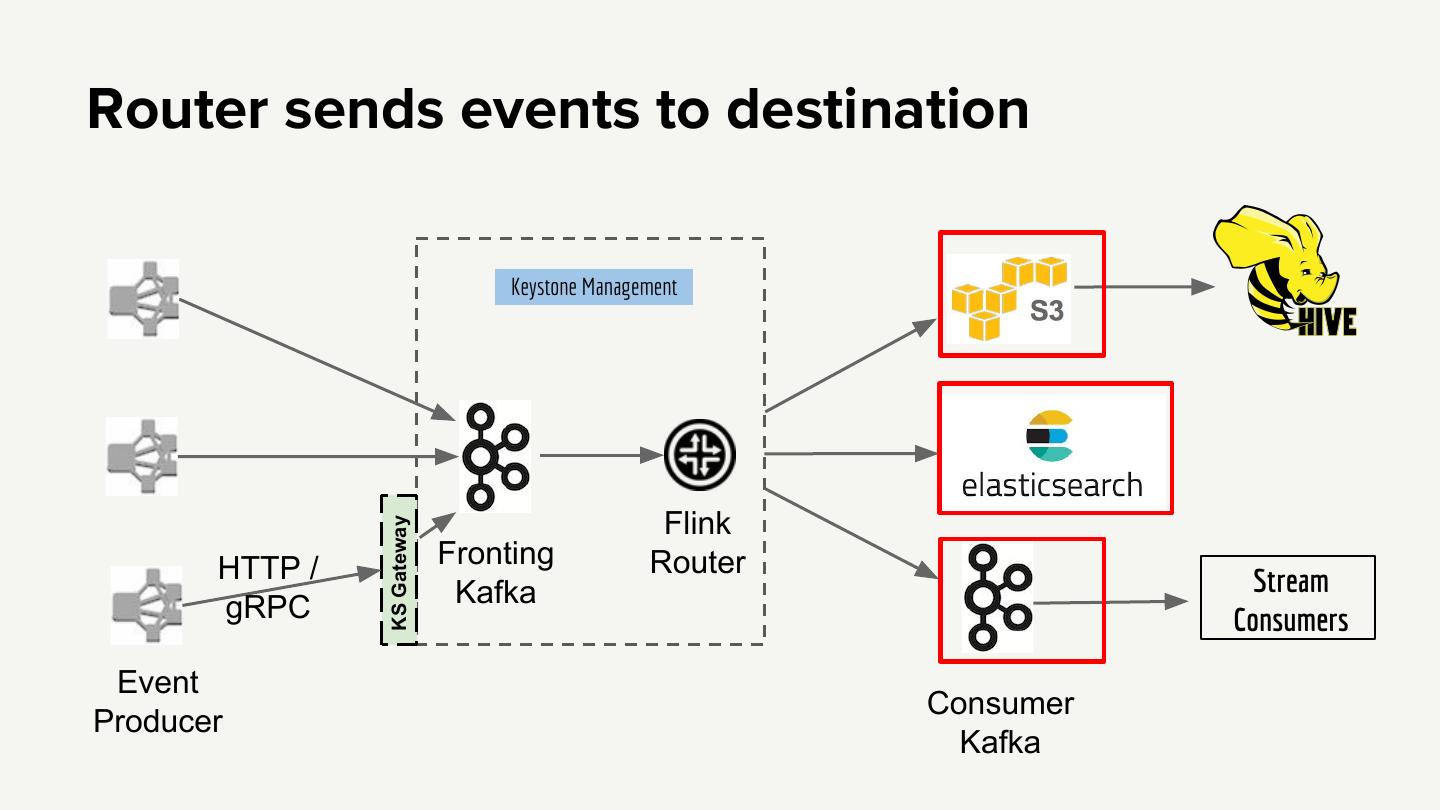
20 .Router sends events to destination Keystone Management Flink KS Gateway HTTP / Fronting Router Kafka Stream gRPC Consumers Event Consumer Producer Kafka
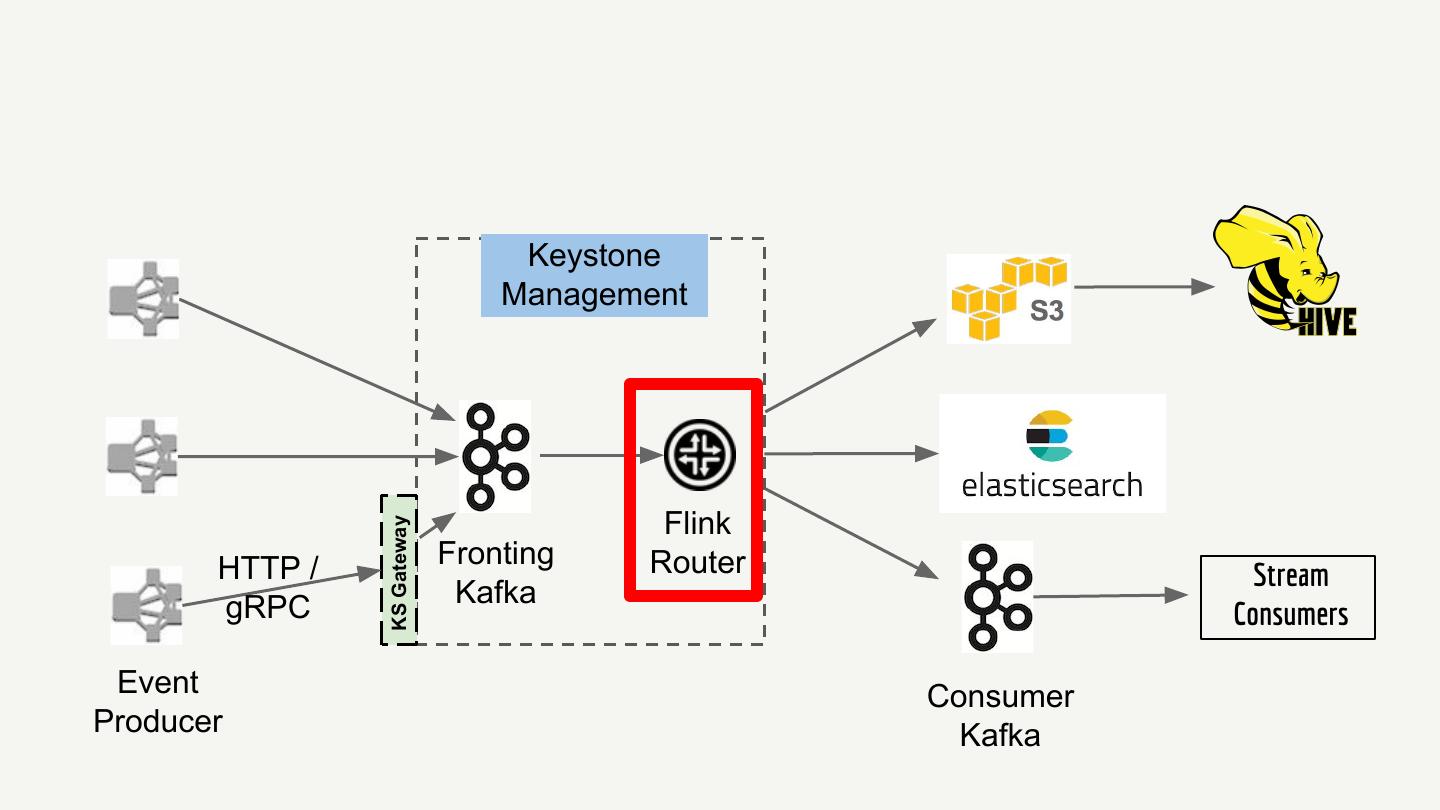
21 . Keystone Management Flink KS Gateway HTTP / Fronting Router Stream gRPC Kafka Consumers Event Consumer Producer Kafka
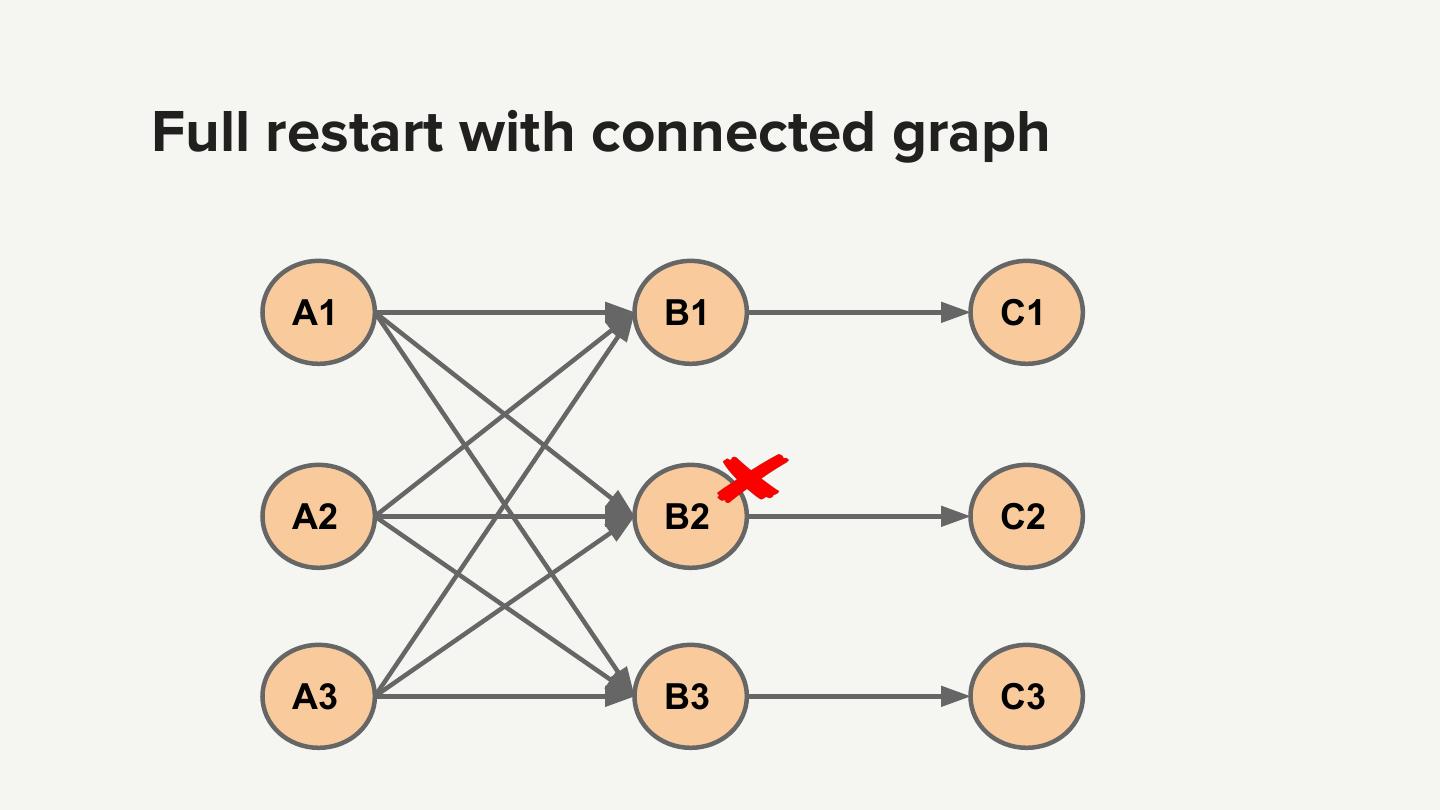
22 . Keystone routing jobs ● Stateless ● Embarrassingly parallel
23 . Keystone router scale ● ~3 trillion events/day ● ~2,000 routing jobs ● ~10,000 containers ● ~200,000 parallel operator instances
24 .Math 101: S3 writes ● ~2,000 routing jobs ● checkpoint interval is 30 seconds ● ~67 (= 2,000 / 30) S3 writes per second?
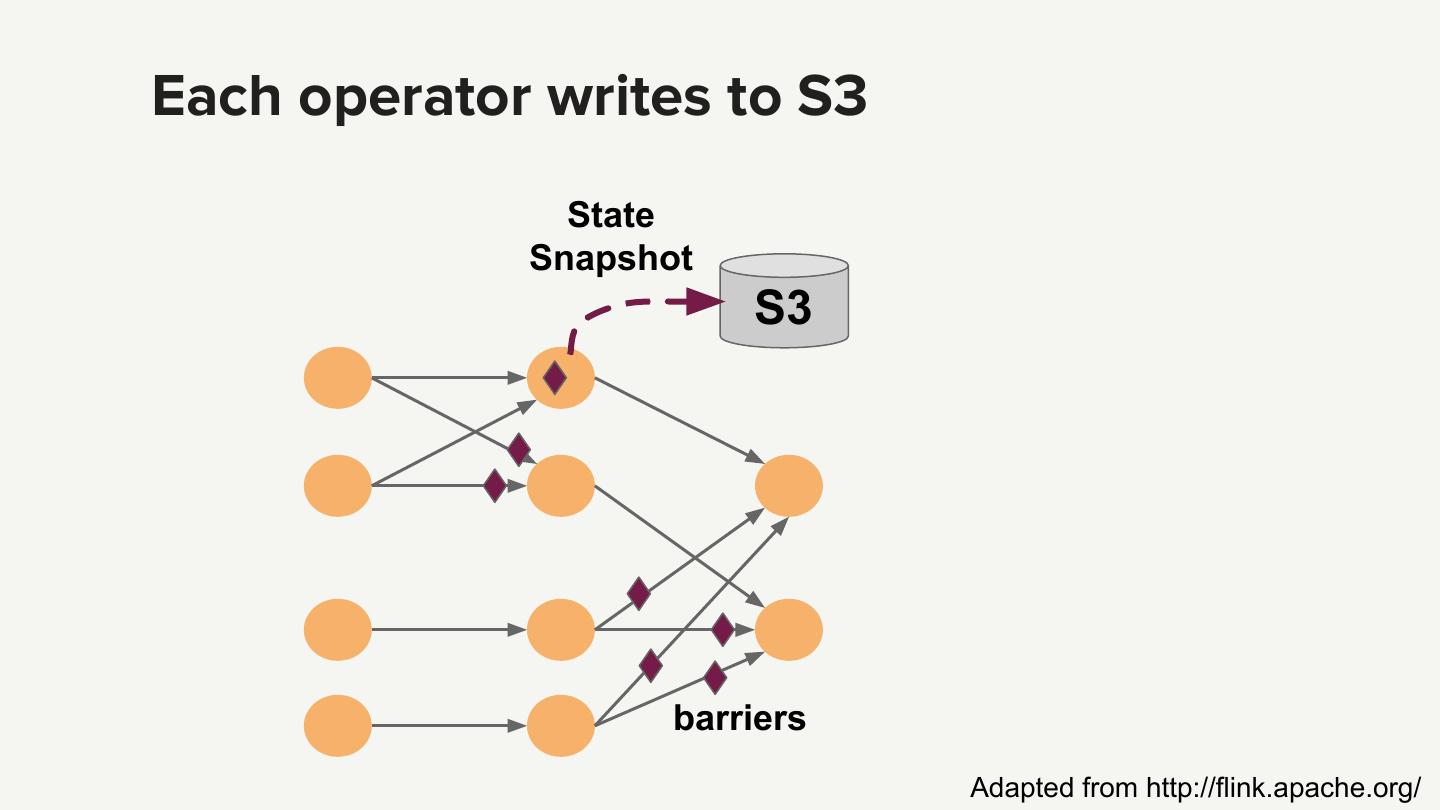
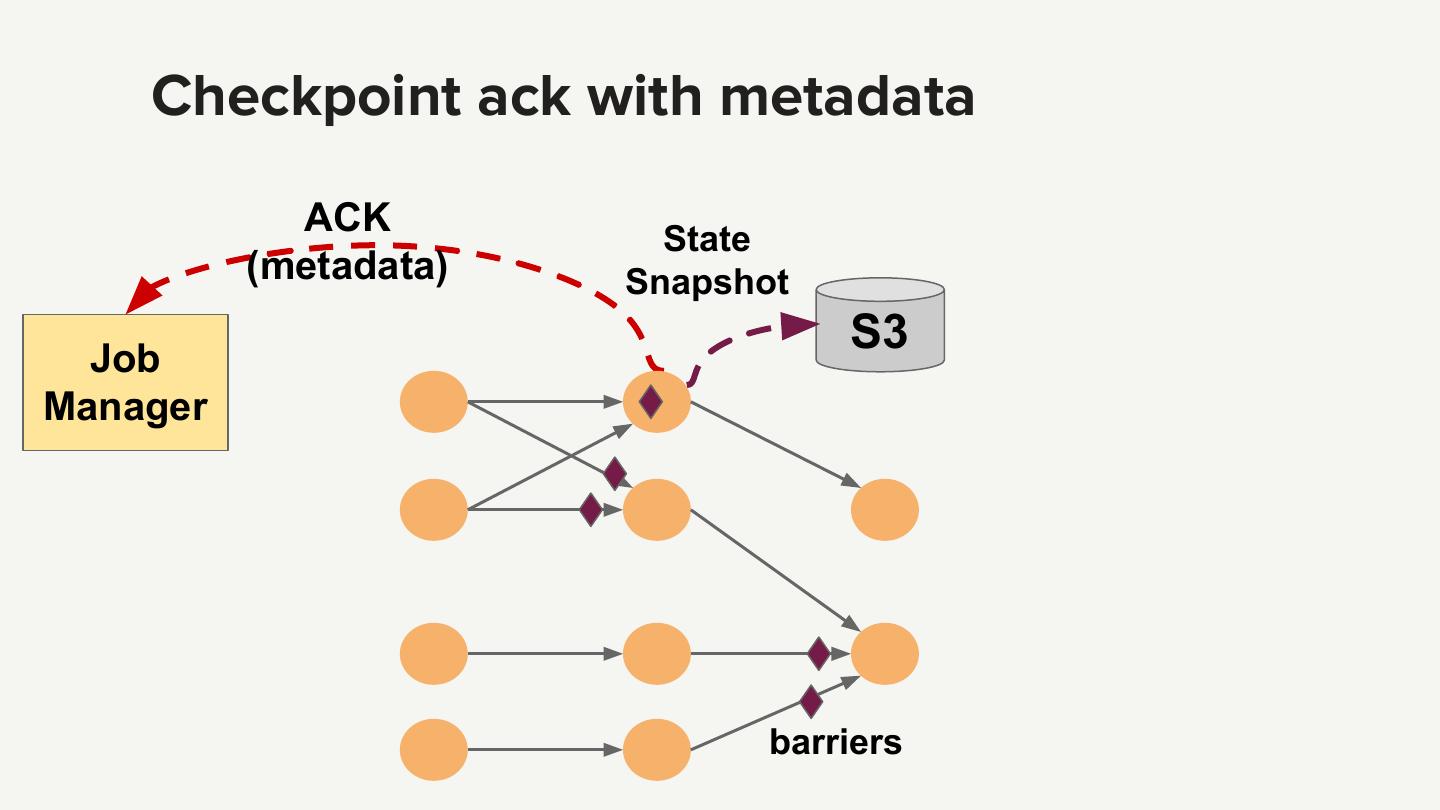
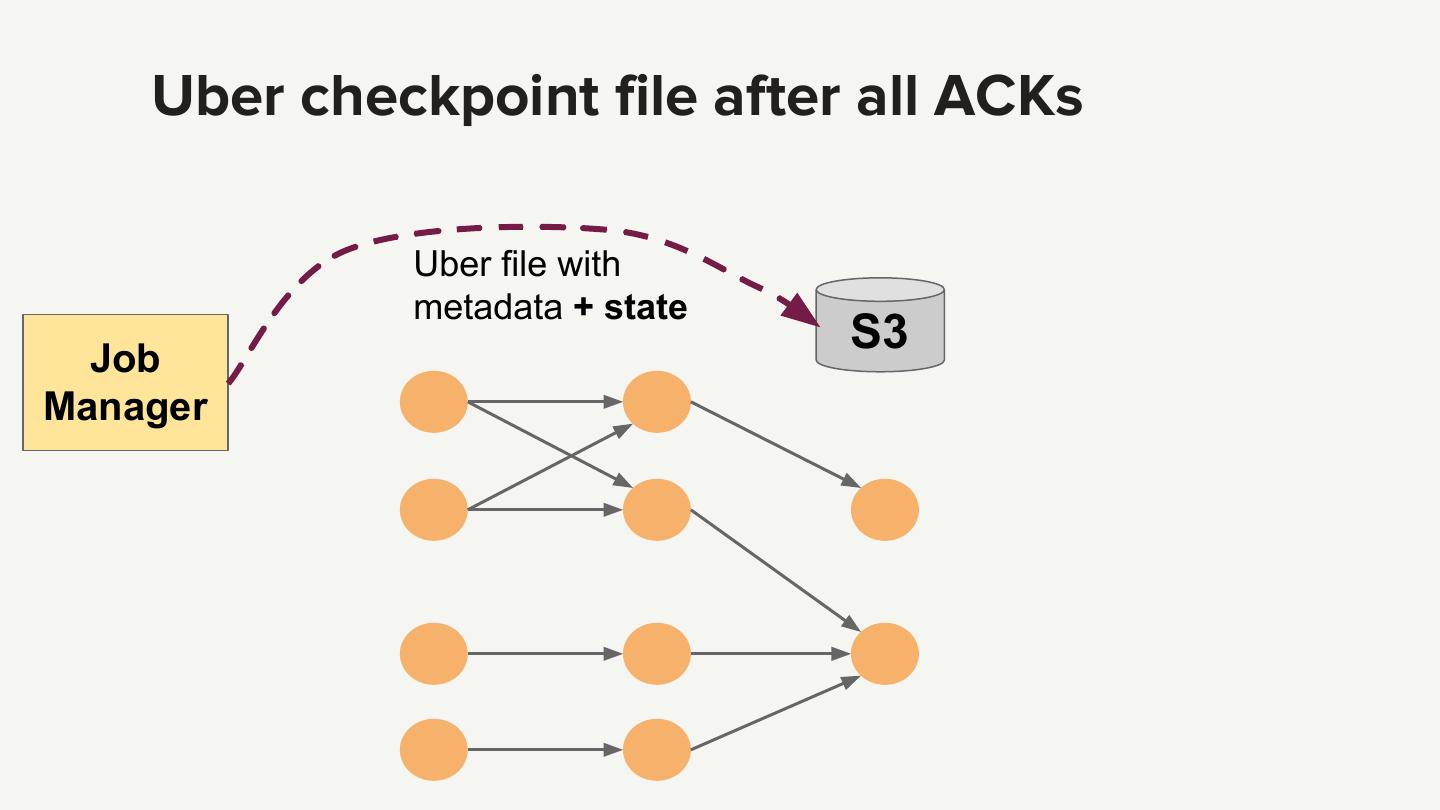
25 .Each operator writes to S3 State Snapshot S3 barriers Adapted from http://flink.apache.org/
26 .Math 201: S3 writes ● ~200,000 operators. Each operator writes checkpoint to S3 ● checkpoint interval is 30 seconds ● ~6,600 writes (= 200,000 / 30) per second ○ Actual writes 2-3x smaller because only Kafka source operators have state
27 .S3 throttling!
28 .S3 not optimized for high request rate without tweaking key names
29 .Checkpoint path state.checkpoints.dir:
相关推荐
3秒后跳转登录页面
去登陆

