














- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/u5/From_Ali_HBase_to_Lindorm_thinking_an_devolution_after_seven_years_of_large_scale_structured_storage?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
阿里巴巴 沈春辉 - 《从阿里HBase到Lindorm:大规模结构化存储七年实践背后的思考与进化》
分享
点赞
9
收藏
3
下载 13
本演讲会先简要陈述阿里HBase过去的实践与改进历程,然后介绍我们过去支撑大规模业务时的一些核心痛点以及碰到的新挑战,最后会着重介绍Lindorm(灵动),这是阿里巴巴研发的新一代高性能、可跨域、多一致的结构化存储产品,其起源于Ali-HBase,但在架构、存储引擎、访问交互方面做了重大的改造,使之相比于HBase,在易用性、可用性、性能、运维性等方面具有重大的能力进化。
展开查看详情
1 . 从阿里HBase到Lindorm 大规模结构化存储的演进与思考 阿里巴巴-沈春辉(天梧) 2018年4月
2 .自我介绍 p 沈春辉,花名:天梧 p @阿里巴巴-存储事业部,资深技术专家 p HBase Committer&PMC p 专注在大数据领域,多次参与双11狂欢节的技术 保障,在分布式、性能优化、系统架构等方面有 丰富的积累与实战 p 目前负责新一代大规模NoSQL系统(Lindorm)的 建设 4
3 .背景 互联网数据的爆发增长 5
4 .背景 数据驱动的新兴场景 风控大脑 芝麻信用 借贷保险决策 实时大屏 生意参谋 智能客服 6
5 .阿里HBase的发展 分布式NoSQL的选择 • Why HBase – 2011年启用 – 活跃社区,Hadoop生态 • 表格模型 • 基本功能(Join、GroupBy) – Facebook成功案例 • 分库分表 – 理论信仰 (Google Paper: BigTable) • Other Choice – Cassandra – 自研 7
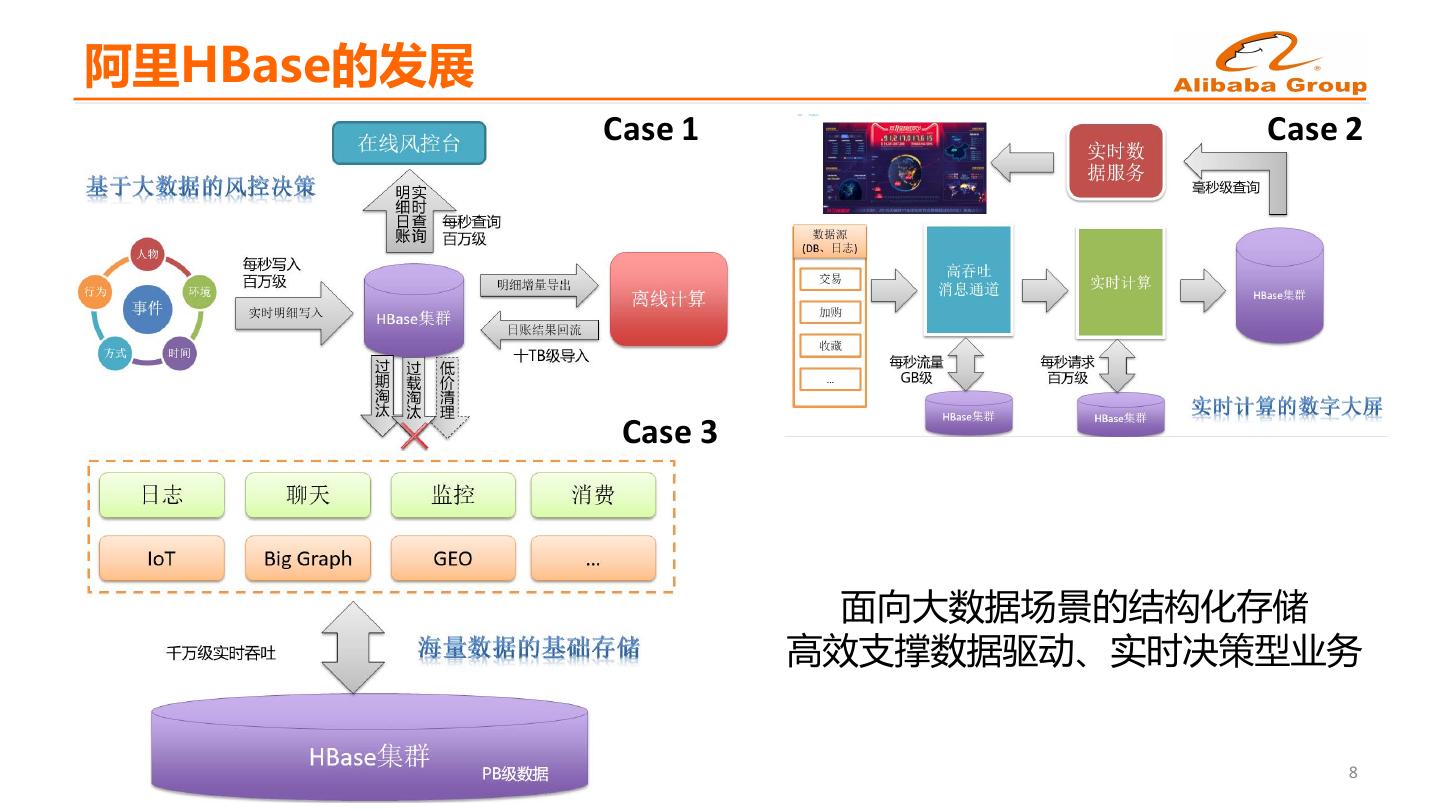
6 .阿里HBase的发展 Case 1 Case 2 Case 3 面向大数据场景的结构化存储 高效支撑数据驱动、实时决策型业务 8
7 .阿里HBase的发展 p 性能领先 ü 高效数据结构、锁优化、请求合并等 AliHB(内部分支) p 功能丰富 ü SQL、二级索引 (七年锤炼,数千优化,上百回馈,多名PMC/Committer) ü 多租户、异构存储、异步接口等 p 稳定可靠 ü 完善的HA架构 Ali-HDFS Zookeeper-CDH ü MTTR快2-10倍 ü 多年双11沉淀 p 运维灵活 ü 全面的监控埋点 Ali-JDK ü 全链路跟踪 ü 无缝迁移 p 版本迭代 ü 0.90、0.92、0.94、1.1、1.2 • 面向阿里经济体中所有BU及6000+开发者,提供一站式大数据场景的结构化存储服务 • 维护管理1万+个物理节点,100+个集群,支撑亿级TPS,百PB数据 9
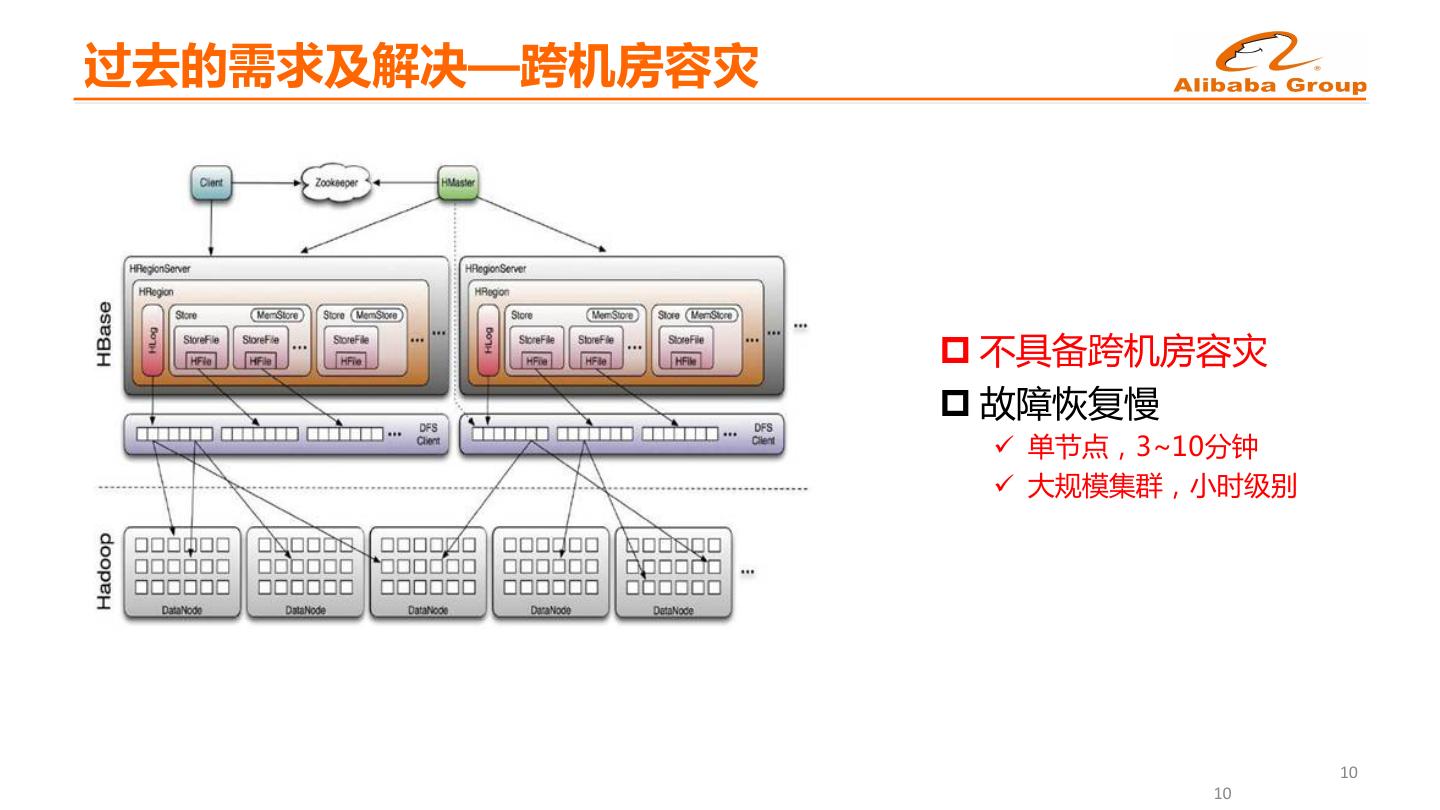
8 .过去的需求及解决—跨机房容灾 p 不具备跨机房容灾 p 故障恢复慢 ü 单节点,3~10分钟 ü 大规模集群,小时级别 10 10
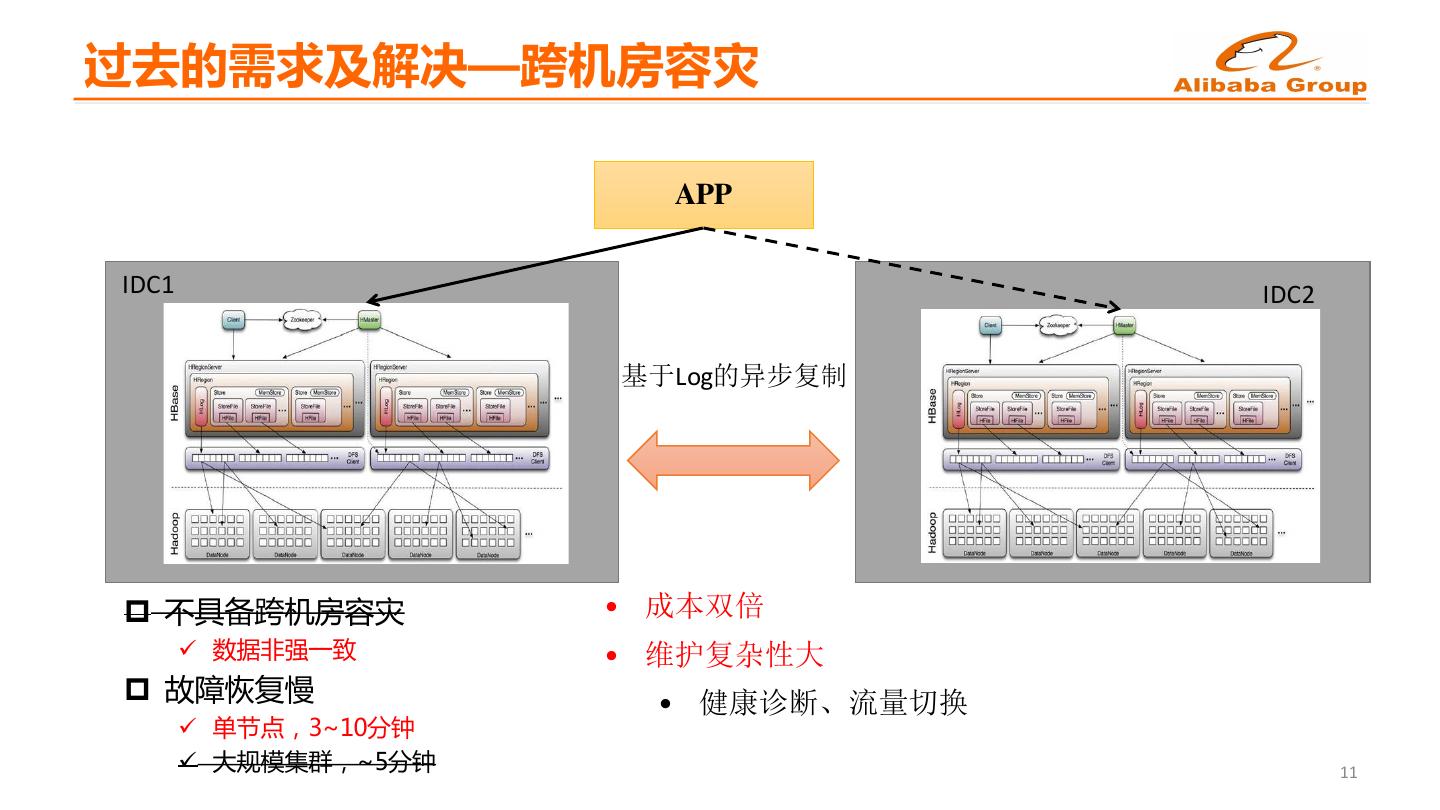
9 .过去的需求及解决—跨机房容灾 APP IDC1 IDC2 基于Log的异步复制 p 不具备跨机房容灾 • 成本双倍 ü 数据非强一致 • 维护复杂性大 p 故障恢复慢 • 健康诊断、流量切换 ü 单节点,3~10分钟 ü 大规模集群,~5分钟 11
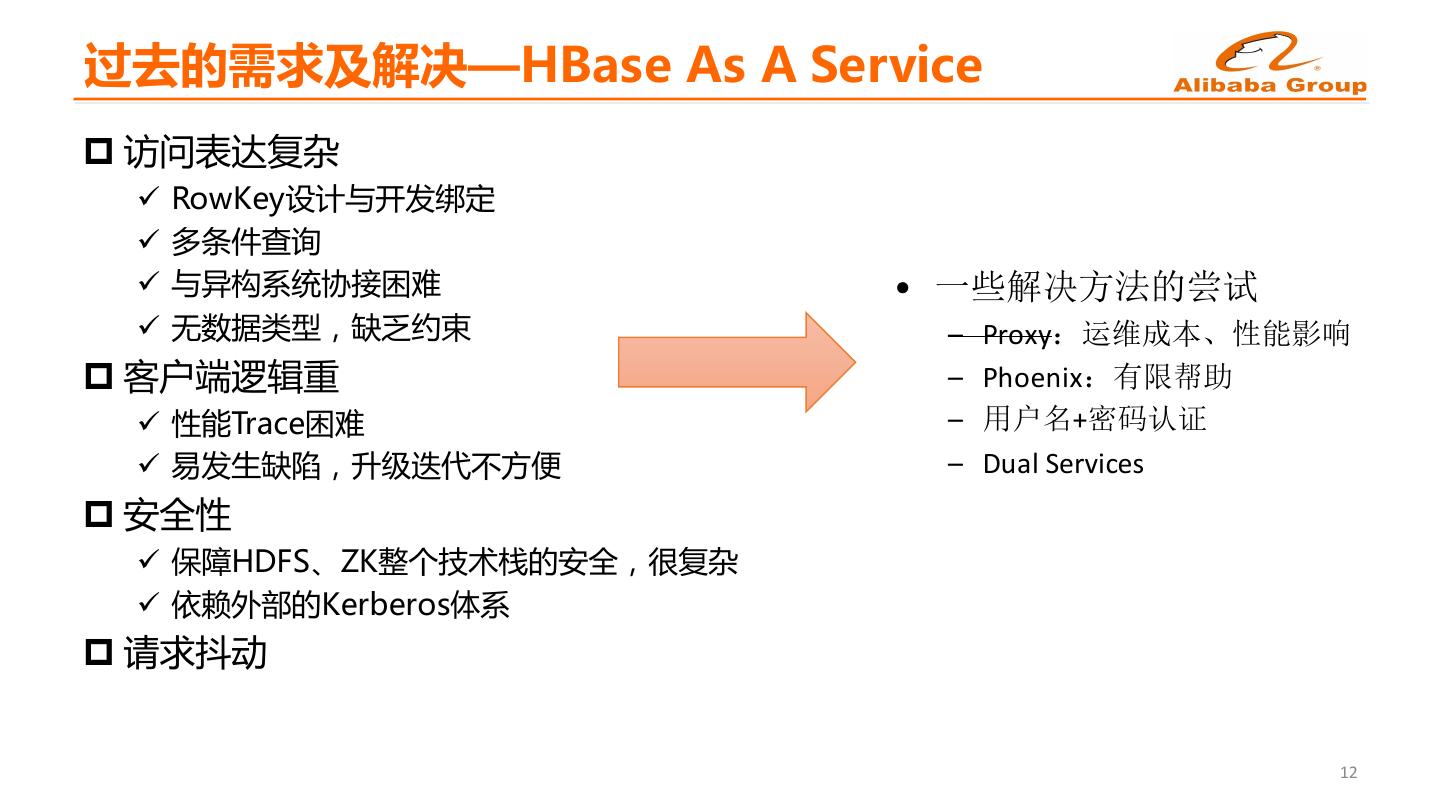
10 .过去的需求及解决—HBase As A Service p 访问表达复杂 ü RowKey设计与开发绑定 ü 多条件查询 ü 与异构系统协接困难 • 一些解决方法的尝试 ü 无数据类型,缺乏约束 – Proxy:运维成本、性能影响 p 客户端逻辑重 – Phoenix:有限帮助 ü 性能Trace困难 – 用户名+密码认证 ü 易发生缺陷,升级迭代不方便 – Dual Services p 安全性 ü 保障HDFS、ZK整个技术栈的安全,很复杂 ü 依赖外部的Kerberos体系 p 请求抖动 12
11 .小结 HBase’s good sides Auto Layered Schema M-S LSM Sharding Storage Free Framework Not enough for some requirements Query Cross-Region Thin Latency Availability Ability Consistency Client Less-Spiking 13
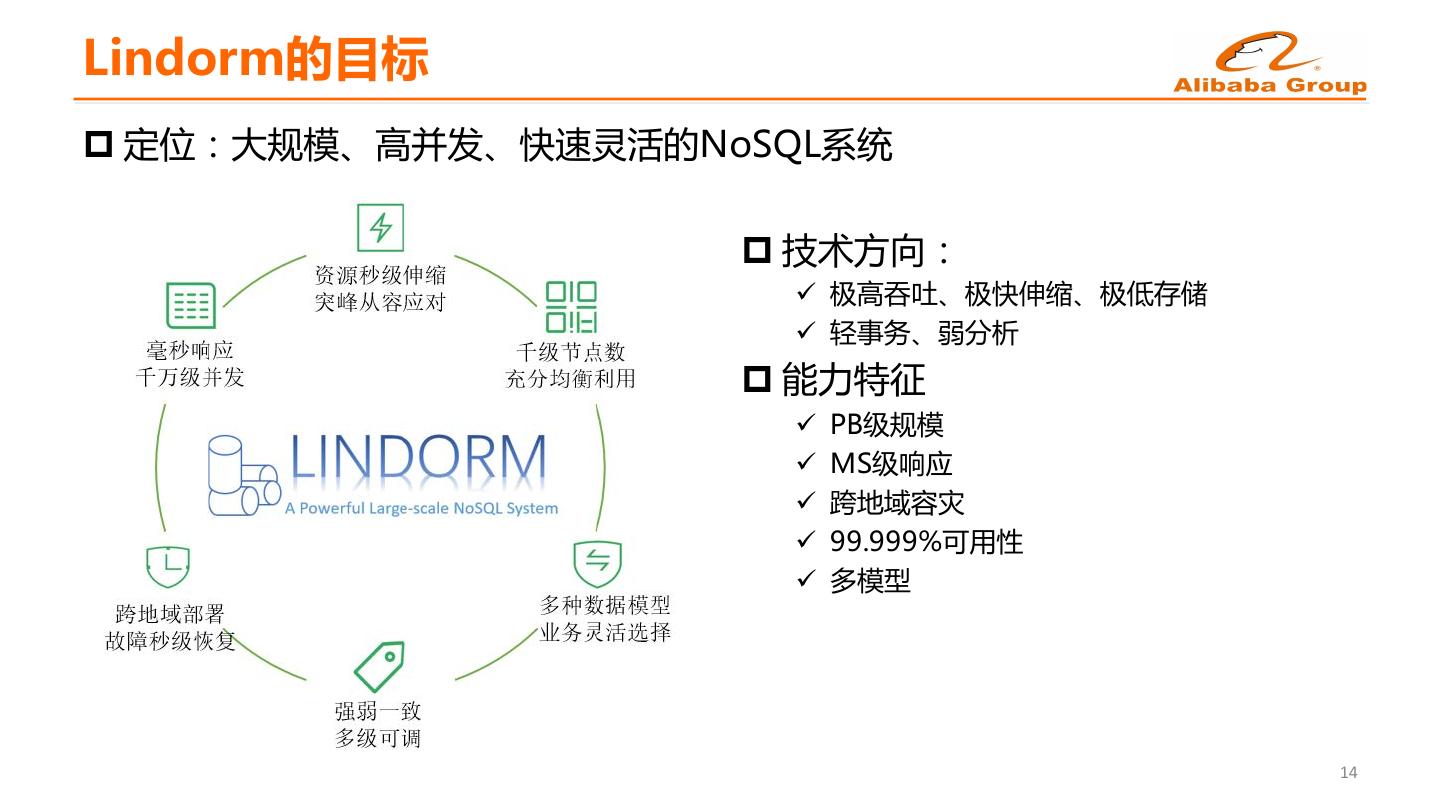
12 .Lindorm的目标 p 定位:大规模、高并发、快速灵活的NoSQL系统 p 技术方向: ü 极高吞吐、极快伸缩、极低存储 ü 轻事务、弱分析 p 能力特征 ü PB级规模 ü MS级响应 ü 跨地域容灾 ü 99.999%可用性 ü 多模型 14
13 .Lindorm的功能 p 基本概念 ü 用户(UserName + Password) ü 访问权限(ACL):Universe/Namespace/Table/ ü 命名空间(namespace) ü 生命周期(TTL) ü 多版本(Version) p 数据模型 ü Relational Table ü Wide Column ü More in future… 15
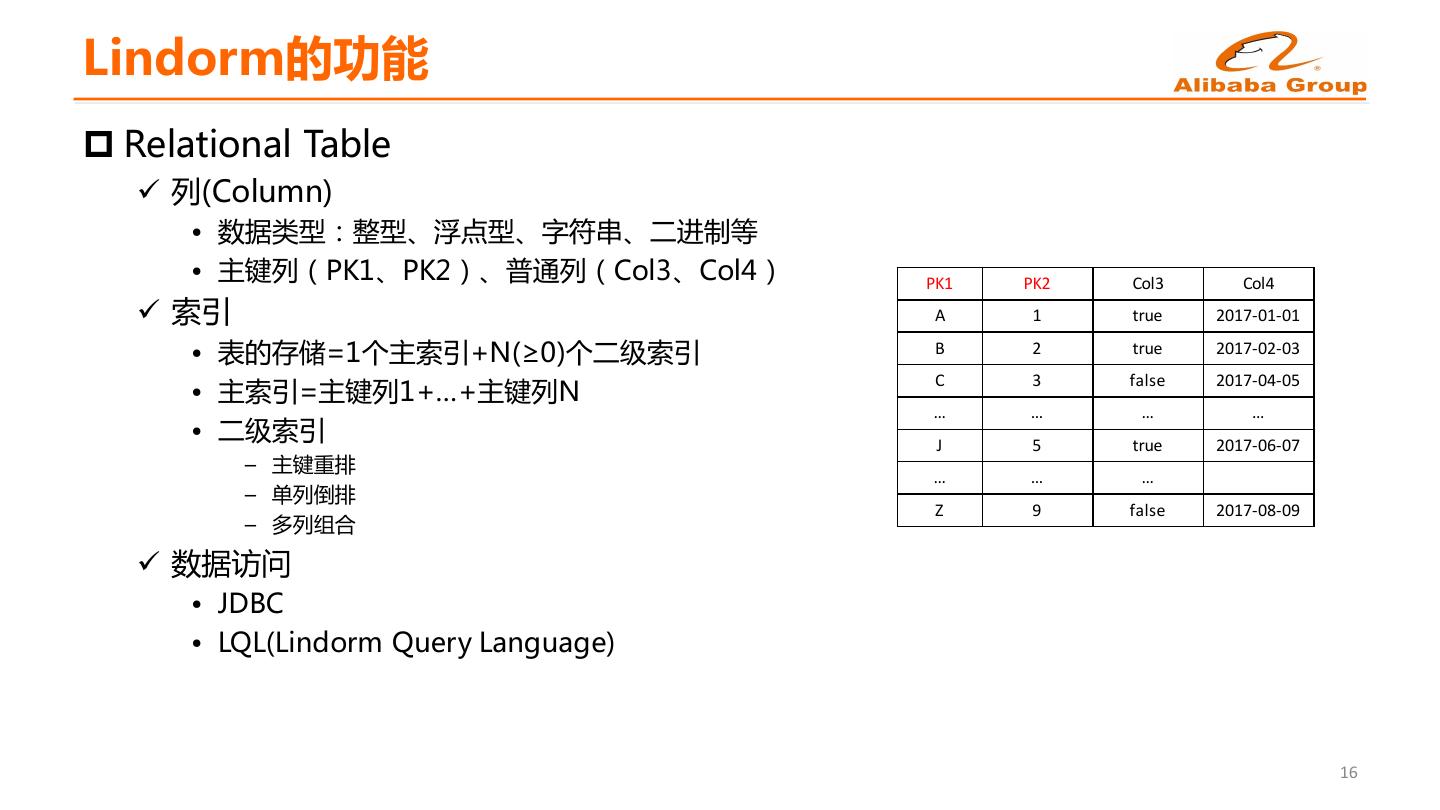
14 .Lindorm的功能 p Relational Table ü 列(Column) • 数据类型:整型、浮点型、字符串、二进制等 • 主键列(PK1、PK2)、普通列(Col3、Col4) PK1 PK2 Col3 Col4 ü 索引 A 1 true 2017-01-01 • 表的存储=1个主索引+N(≥0)个二级索引 B 2 true 2017-02-03 C 3 false 2017-04-05 • 主索引=主键列1+…+主键列N … … … … • 二级索引 J 5 true 2017-06-07 – 主键重排 … … … – 单列倒排 Z 9 false 2017-08-09 – 多列组合 ü 数据访问 • JDBC • LQL(Lindorm Query Language) 16
15 .Lindorm的功能 p Wide Column ü RowKey • 行记录的唯一排序键 ü 列簇(Column Family) • 纵向切割,面向列的存储思想 ü 列(Column) • 无需定义,完全动态,无数量上限 • 统一的数据类型byte[] • 独立的数据时间戳 ü 数据访问 • 自定义API:Put/Get/Scan/Delete 17
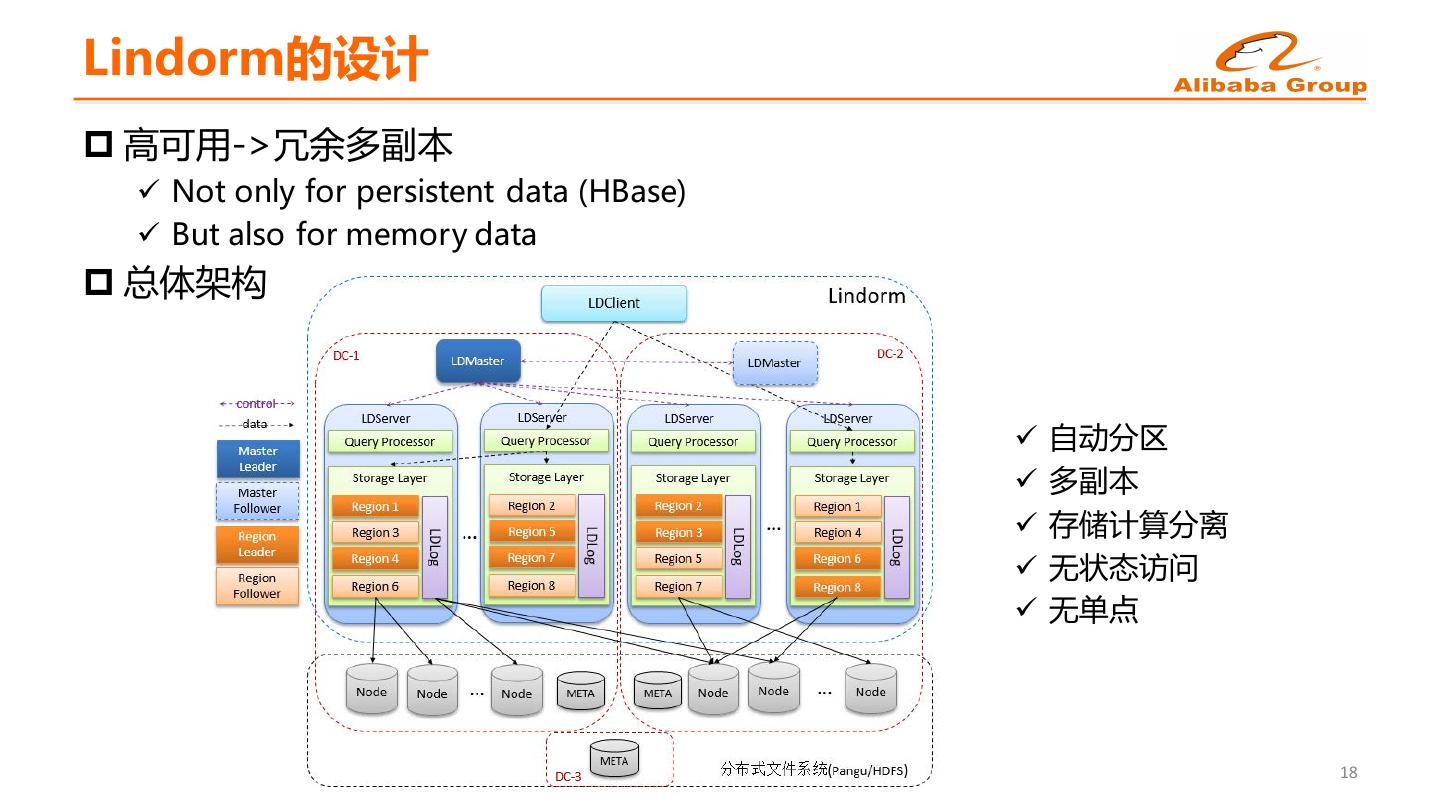
16 .Lindorm的设计 p 高可用->冗余多副本 ü Not only for persistent data (HBase) ü But also for memory data p 总体架构 ü 自动分区 ü 多副本 ü 存储计算分离 ü 无状态访问 ü 无单点 18
17 .Lindorm的设计 p 持久化存储在分布式文件系统 ü 成本更弹性 ü 抗热点更优秀 ü 负载更均衡 ü 数据管理更个性 p 使用盘古作为Lindorm的底层文件系统 ü 全分布式元数据管理 ü 充分发挥新一代网络和存储硬件的红利(e.g. SPDK, RDMA) ü 高效远程访问,支持统一大存储 19
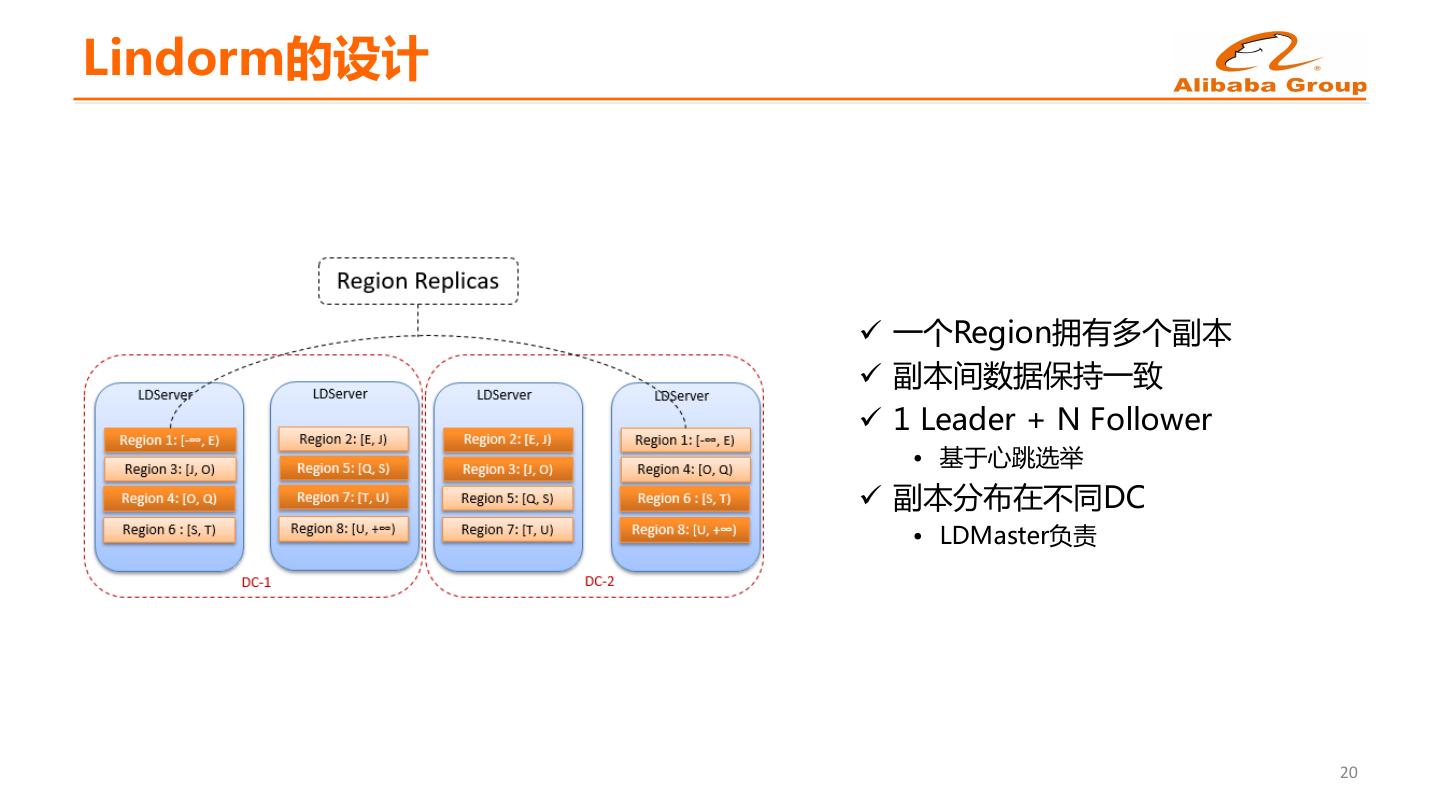
18 .Lindorm的设计 ü 一个Region拥有多个副本 ü 副本间数据保持一致 ü 1 Leader + N Follower • 基于心跳选举 ü 副本分布在不同DC • LDMaster负责 20
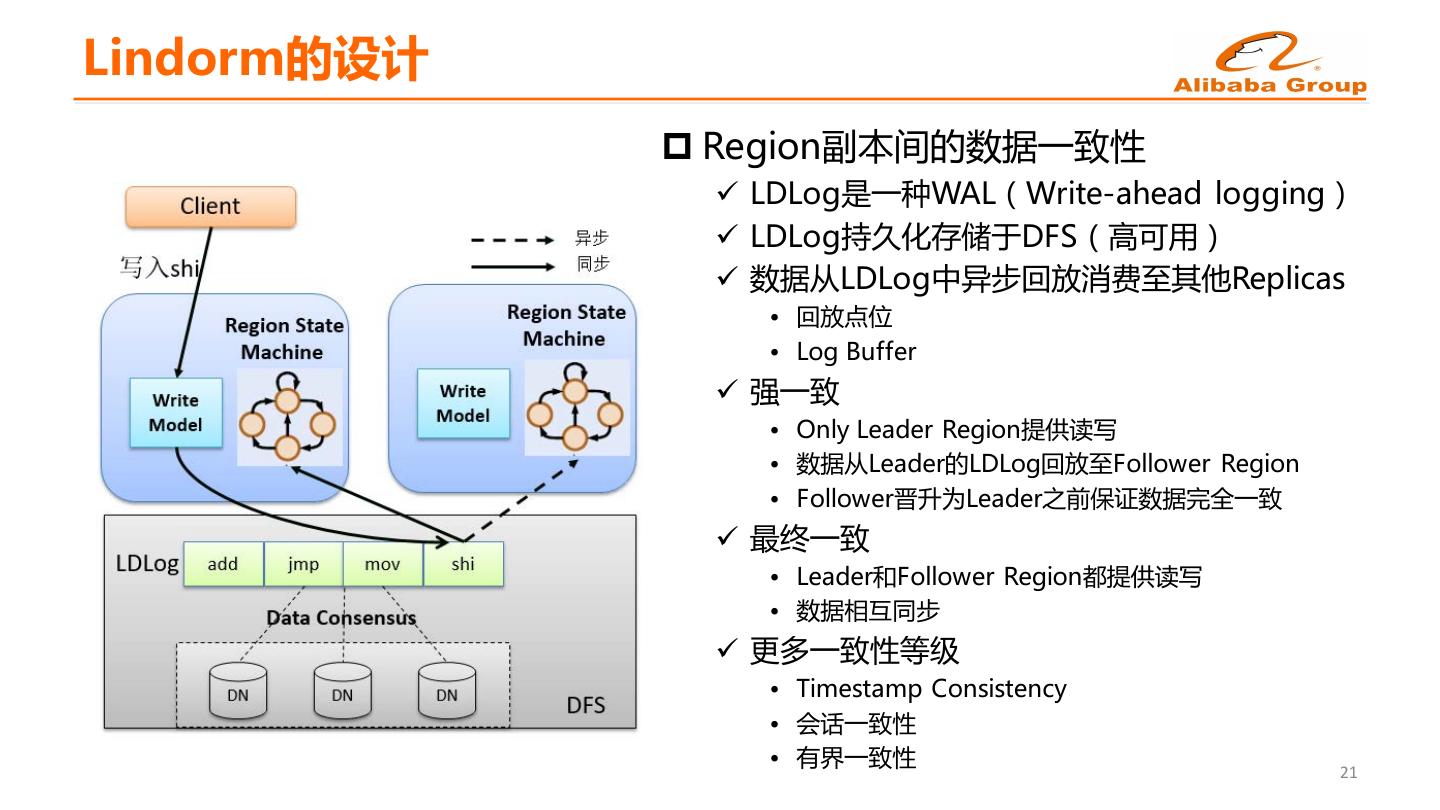
19 .Lindorm的设计 p Region副本间的数据一致性 ü LDLog是一种WAL(Write-ahead logging) ü LDLog持久化存储于DFS(高可用) ü 数据从LDLog中异步回放消费至其他Replicas • 回放点位 • Log Buffer ü 强一致 • Only Leader Region提供读写 • 数据从Leader的LDLog回放至Follower Region • Follower晋升为Leader之前保证数据完全一致 ü 最终一致 • Leader和Follower Region都提供读写 • 数据相互同步 ü 更多一致性等级 • Timestamp Consistency • 会话一致性 • 有界一致性 21
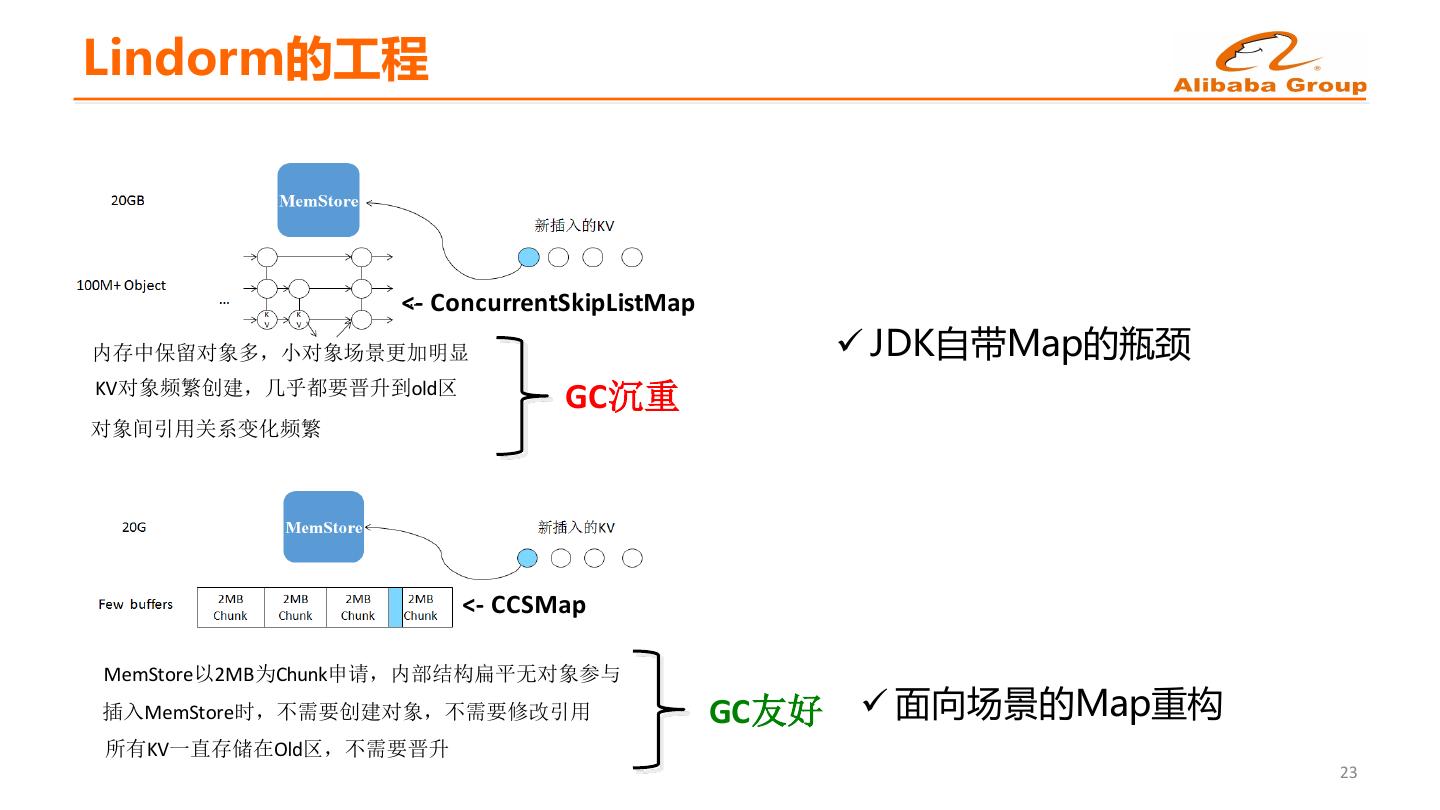
20 .Lindorm的工程 p 在HBase上遇到的GC挑战 ü 内存规模越来越大,堆空间百GB以上 ü YGC频率高,停顿时间100ms以上 ü 内存碎片导致超长停顿的FullGC p 在Lindorm消除JVM GC影响 ü 写buffer+读cache,使用新型数据结构,在应用态管理内存 ü 使用新GC算法(powered by Alibaba JVM),优化频繁创建与回收的临时对象 ü GC停顿控制在5ms 22
21 .Lindorm的工程 <- ConcurrentSkipListMap 内存中保留对象多,小对象场景更加明显 ü JDK自带Map的瓶颈 KV对象频繁创建,几乎都要晋升到old区 GC沉重 对象间引用关系变化频繁 <- CCSMap MemStore以2MB为Chunk申请,内部结构扁平无对象参与 插入MemStore时,不需要创建对象,不需要修改引用 GC友好 ü 面向场景的Map重构 所有KV一直存储在Old区,不需要晋升 23
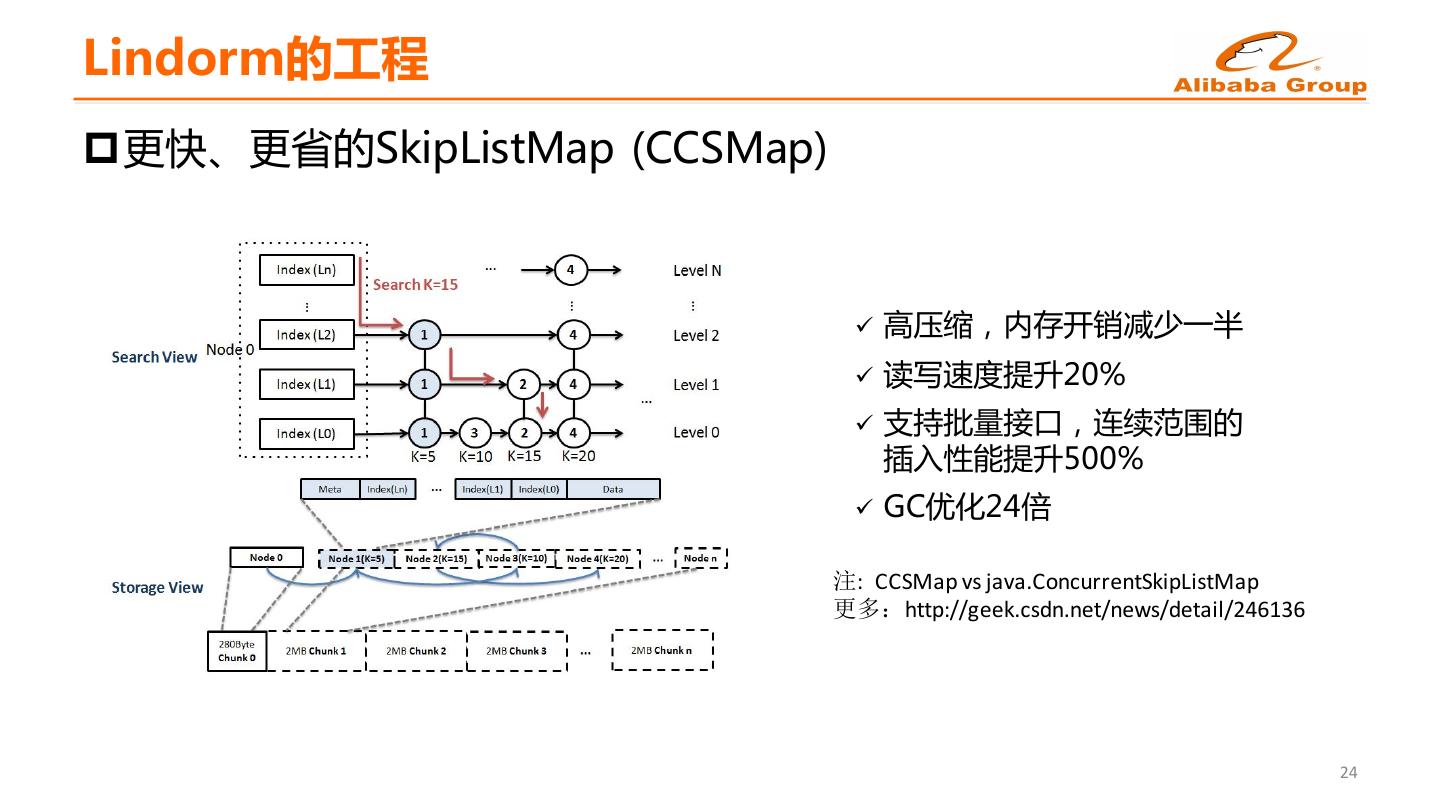
22 .Lindorm的工程 p更快、更省的SkipListMap (CCSMap) ü 高压缩,内存开销减少一半 ü 读写速度提升20% ü 支持批量接口,连续范围的 插入性能提升500% ü GC优化24倍 注: CCSMap vs java.ConcurrentSkipListMap 更多:http://geek.csdn.net/news/detail/246136 24
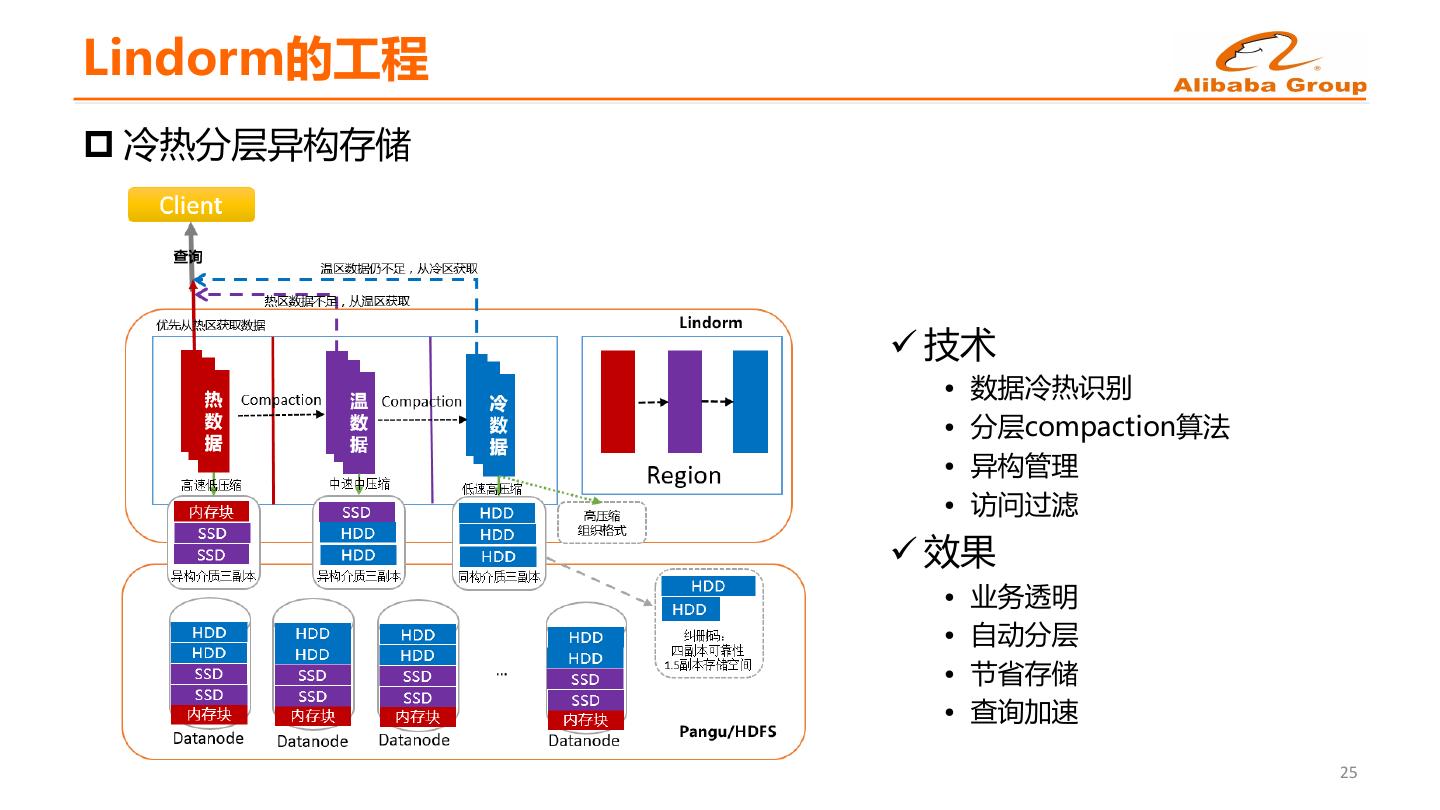
23 .Lindorm的工程 p 冷热分层异构存储 ü 技术 • 数据冷热识别 • 分层compaction算法 • 异构管理 • 访问过滤 ü 效果 • 业务透明 • 自动分层 • 节省存储 • 查询加速 25
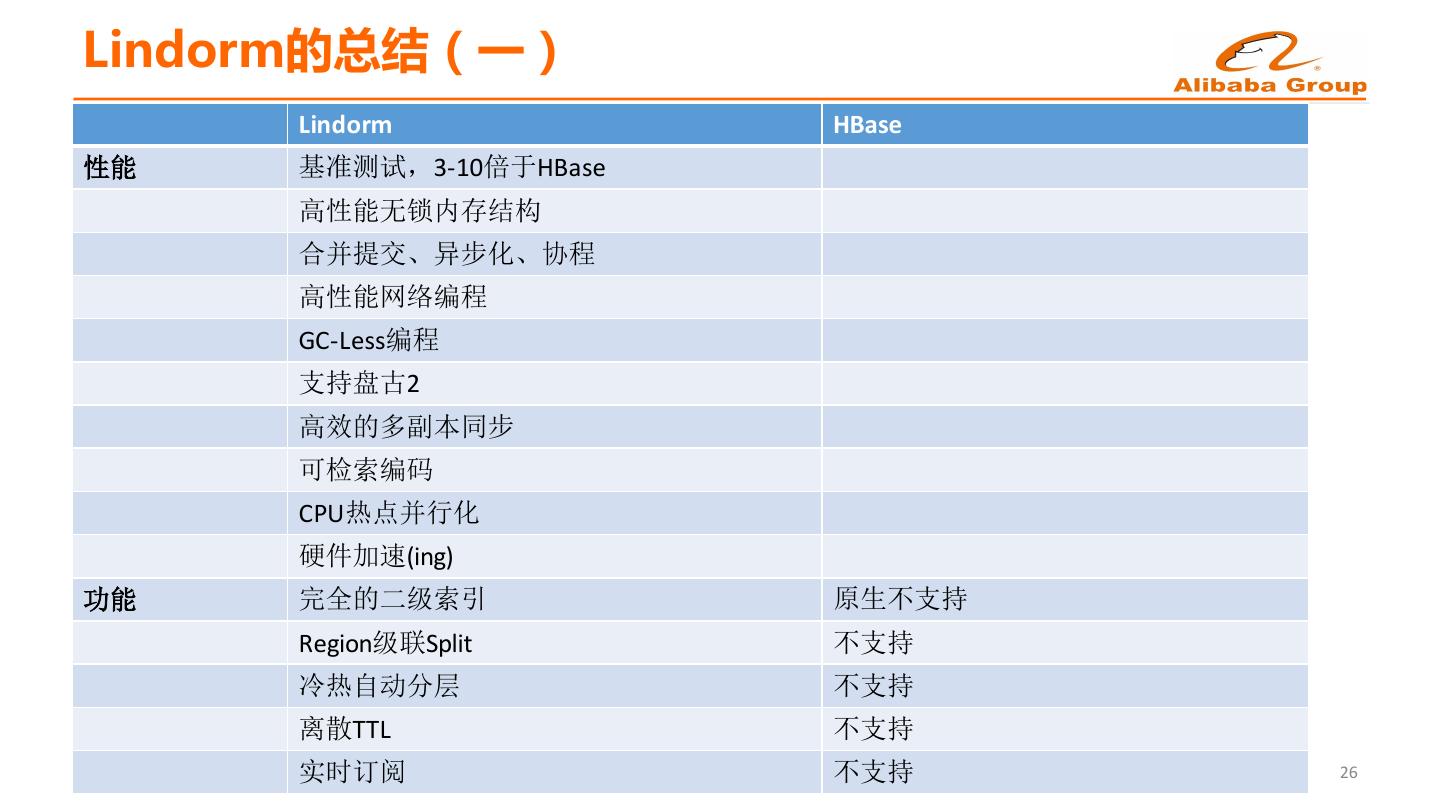
24 .Lindorm的总结(一) Lindorm HBase 性能 基准测试,3-10倍于HBase 高性能无锁内存结构 合并提交、异步化、协程 高性能网络编程 GC-Less编程 支持盘古2 高效的多副本同步 可检索编码 CPU热点并行化 硬件加速(ing) 功能 完全的二级索引 原生不支持 Region级联Split 不支持 冷热自动分层 不支持 离散TTL 不支持 实时订阅 不支持 26
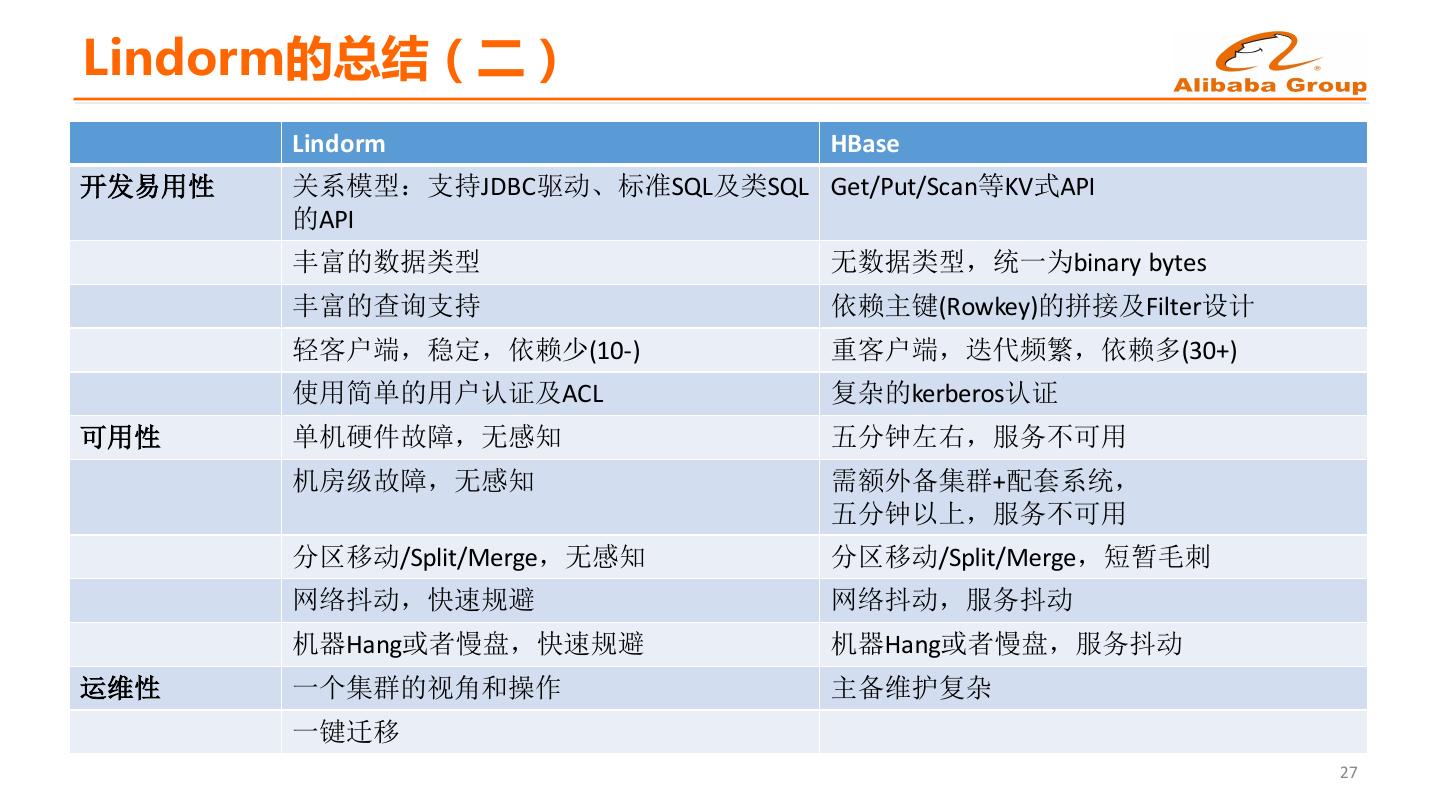
25 .Lindorm的总结(二) Lindorm HBase 开发易用性 关系模型:支持JDBC驱动、标准SQL及类SQL Get/Put/Scan等KV式API 的API 丰富的数据类型 无数据类型,统一为binary bytes 丰富的查询支持 依赖主键(Rowkey)的拼接及Filter设计 轻客户端,稳定,依赖少(10-) 重客户端,迭代频繁,依赖多(30+) 使用简单的用户认证及ACL 复杂的kerberos认证 可用性 单机硬件故障,无感知 五分钟左右,服务不可用 机房级故障,无感知 需额外备集群+配套系统, 五分钟以上,服务不可用 分区移动/Split/Merge,无感知 分区移动/Split/Merge,短暂毛刺 网络抖动,快速规避 网络抖动,服务抖动 机器Hang或者慢盘,快速规避 机器Hang或者慢盘,服务抖动 运维性 一个集群的视角和操作 主备维护复杂 一键迁移 27
26 .未来规划 p统一存储、容器化 pPluggable存储引擎 p新硬件结合: AEP、FPGA p更多模型支持:对象、图、时空等 p开源 28
27 . 谢谢指导 THANKS! 求才若渴,欢迎加入我们,杭州、硅谷、深圳、北京 29
相关推荐
3秒后跳转登录页面
去登陆

