展开查看详情
1 .Extending Flink Metrics:
real-time BI atop existing streaming pipelines
Andrew Torson, Walmart Labs
�
2 .Smart Pricing @ Walmart Labs
• Algorithmic: competitive analysis, economic modeling, cost/profit margin/sales/inventory data
• Rich ingestion: Walmart Stores, Walmart.com, Merchants, Competition, 3rd party data
• Large catalog size: ~ 5M 1st party catalog; ~100M 3rd party/marketplace catalog
• Multi-strategy: competitive leadership/revenue management/liquidation/trending/bidding
• Real-time: essential inputs ingestion (competition/trends/availability)
• Real-time: any 1P item price is refreshed within 5 minutes on all important input triggers
• Quasi real-time: push-rate-controlled 3P catalog price valuation
• Throughput control: probabilistic filtering/caching/micro-batching/streaming API/backpressure
• Regular batch jobs for quasi-static data: sales forecast/demand elasticity/marketplace statistics
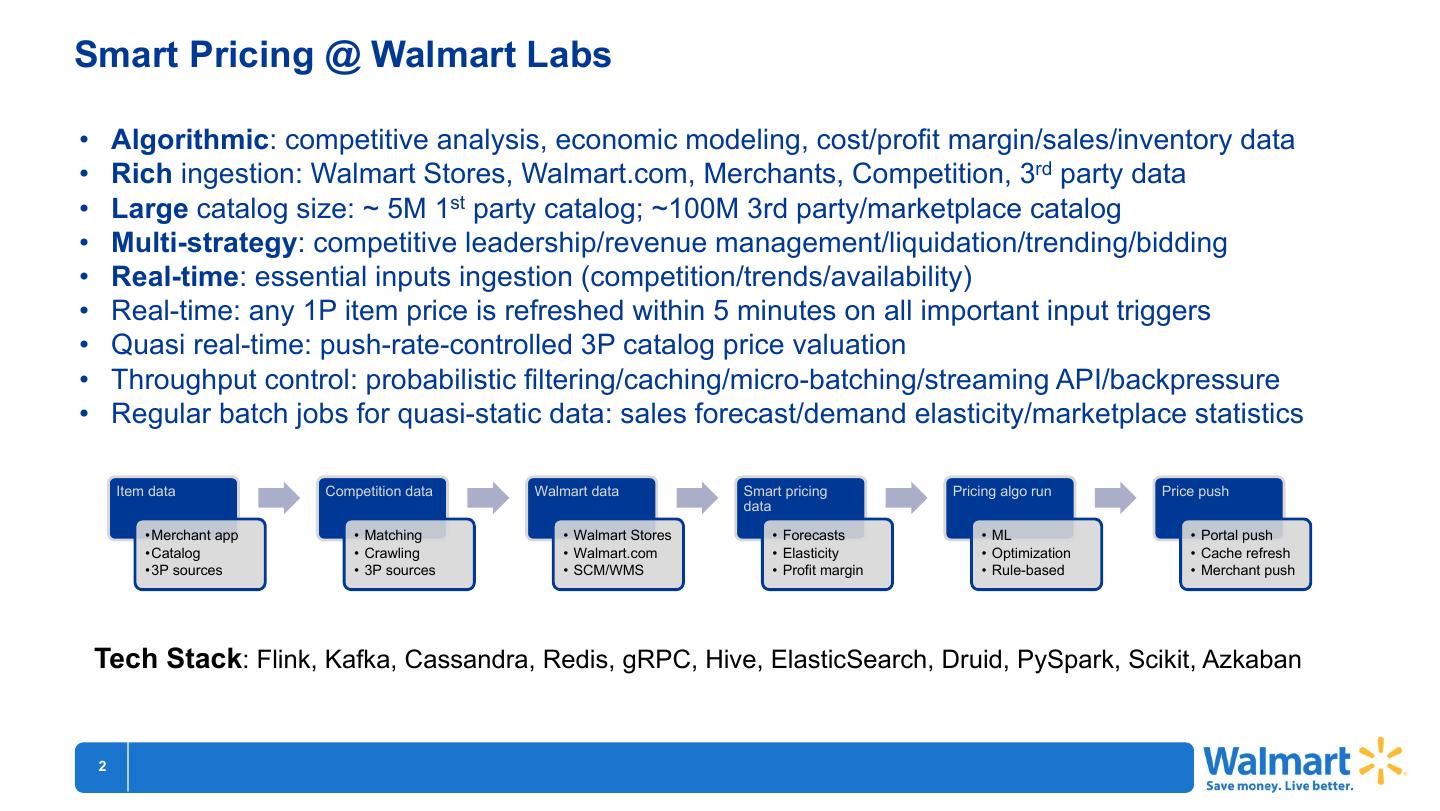
Item data Competition data Walmart data Smart pricing Pricing algo run Price push
data
•Merchant app • Matching • Walmart Stores • Forecasts • ML • Portal push
•Catalog • Crawling • Walmart.com • Elasticity • Optimization • Cache refresh
•3P sources • 3P sources • SCM/WMS • Profit margin • Rule-based • Merchant push
Tech Stack: Flink, Kafka, Cassandra, Redis, gRPC, Hive, ElasticSearch, Druid, PySpark, Scikit, Azkaban
2
150406
CHICategory Prioritization ...
�
3 .Monitoring & BI
• Health-check: metrics/Graphite/Prometheus/Grafana/New Relic
• Reporting: Hive/Tableau
• Auditing: Hive/Presto
• BI: Druid
Going beyond Druid: real-time BI
• Multi-dimensional KPI monitoring & alerting: meet/beat score, stop-loss category P&L
• Categorized Top-K counters: merchant ‘hot-item’ search ranking, trending items
• Anomaly detection: stateful outlier input detectors, categorized tail statistics
• Price strategy selection: item-level descriptive/prescriptive time-window snapshot
If all the data is already flowing through Flink pipelines – why not
enrich them to compute real-time BI metrics as well?
• Pros: existing Flink pipelines scalability; data locality; incremental code decoration with metric
aspects; powerful Flink function APIs
• Cons: metrics dimensionality curse/abuse; Flink performance side-effects;
3
150406
CHICategory Prioritization ...
�
4 .Quick tour of Flink-metrics
• Dropwizard-like metrics: counters/gauges/histograms/meters
• Metric key scoping: system-level(TM/task/operator) + custom user-level (Metric Group feature)
• Flink Runtime Context: allows to register operator-level metric groups via Flink RichFunction API
• Flink Metric Reporter: is notified of metric registry changes and micro-batches the metrics push
• Built-in metrics and reporters: scheduled Dropwizard reporter; Kafka metrics; IO/latency metrics
• Flink web-GUI: basic metric navigation & charting (no aggregates)
ü Good fit for health-checking
ü Simple and extensible
x How to define metrics logic?
x How to decorate/attach metrics to existing Flink operators?
x How to make adding more/new metrics a quick/simple exercise?
x How to handle dynamic/BI-like metric dimensions?
x How to handle metrics aggregation?
Million-dollar question: KSQL vs Flink for real-time BI?
4
150406
CHICategory Prioritization ...
�
5 .Extending Flink metrics:
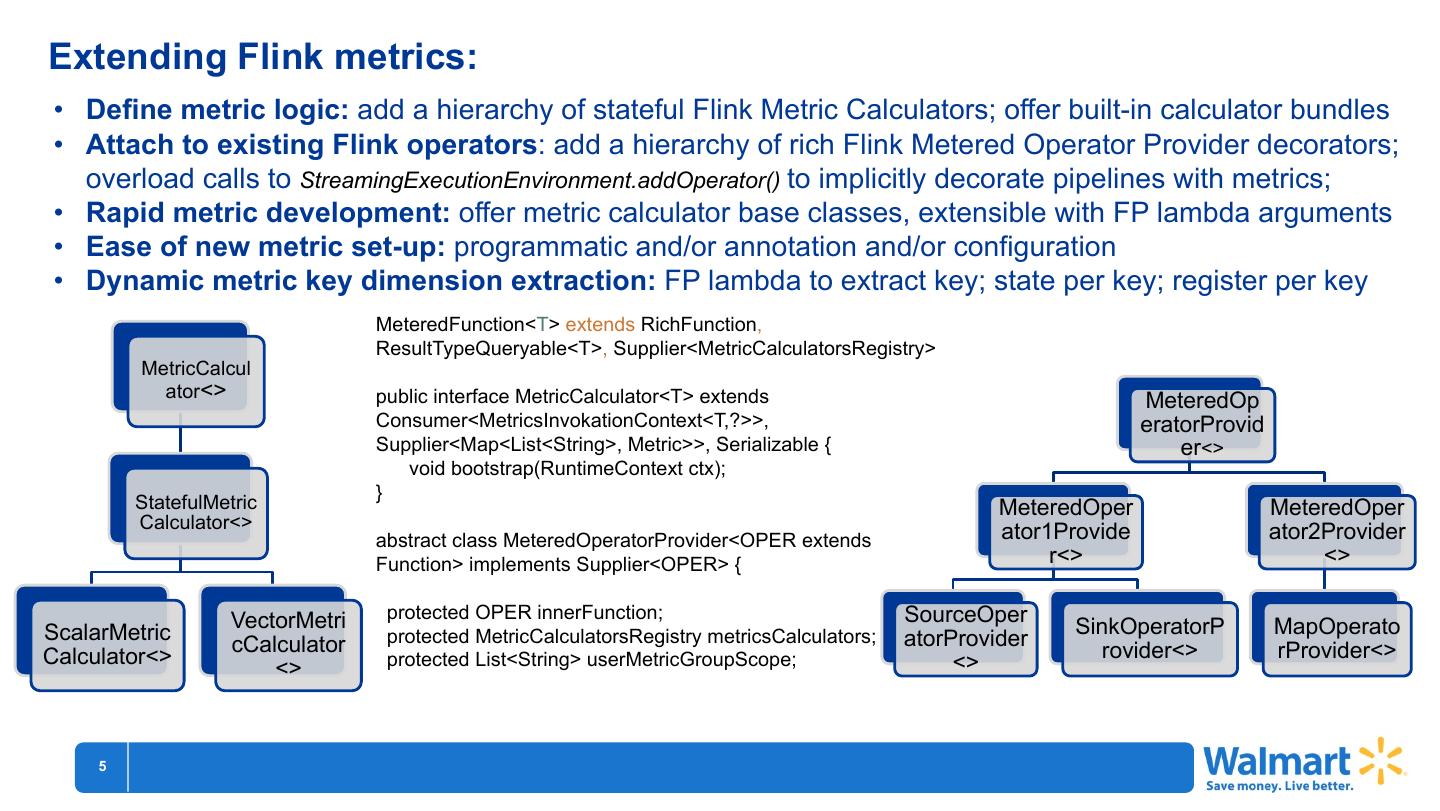
• Define metric logic: add a hierarchy of stateful Flink Metric Calculators; offer built-in calculator bundles
• Attach to existing Flink operators: add a hierarchy of rich Flink Metered Operator Provider decorators;
overload calls to StreamingExecutionEnvironment.addOperator() to implicitly decorate pipelines with metrics;
• Rapid metric development: offer metric calculator base classes, extensible with FP lambda arguments
• Ease of new metric set-up: programmatic and/or annotation and/or configuration
• Dynamic metric key dimension extraction: FP lambda to extract key; state per key; register per key
MeteredFunction<T> extends RichFunction,
ResultTypeQueryable<T>, Supplier<MetricCalculatorsRegistry>
MetricCalcul
ator<> public interface MetricCalculator<T> extends MeteredOp
Consumer<MetricsInvokationContext<T,?>>, eratorProvid
Supplier<Map<List<String>, Metric>>, Serializable { er<>
void bootstrap(RuntimeContext ctx);
StatefulMetric }
MeteredOper MeteredOper
Calculator<> ator1Provide ator2Provider
abstract class MeteredOperatorProvider<OPER extends
Function> implements Supplier<OPER> { r<> <>
VectorMetri protected OPER innerFunction; SourceOper
ScalarMetric protected MetricCalculatorsRegistry metricsCalculators; SinkOperatorP MapOperato
cCalculator atorProvider
Calculator<> protected List<String> userMetricGroupScope; rovider<> rProvider<>
<> <>
5
150406
CHICategory Prioritization ...
�
6 .Basic Code Examples:
Metric calculator :
public class MetricUtils {
public static <T> MetricsCalculator<T> basicMetricsPackage() {
return new CompositeMetricsCalculator<T>()
.withCalculator(new ResettingEventCounterCalculator<T>().withScope("EventCounter"))
.withCalculator(new SimpleRateMeterCalculator<T>().withScope("RateMeter"))
.withCalculator(new SimpleTrafficHistogramCalculator<T>().withScope("TrafficHistogram"));}}
Programmatic pipeline decoration:
stream.map(MeteredMapProvider.<ItemPushRequest,Tuple2<String,String>>of(jsonMarshallerOperator,
MetricUtils.basicMetricsPackage(),"SuccessfulPricing-Map”, null).get());
Configuration pipeline decoration:
YAML: { metrics : { packages: [ core : { class: ‘com.walmartlabs.smartpricing.streaming.metrics.MetricUtils’ ,
staticmethods = [ basicMetricsPackage ] } ], pipelines: [ OptimizationPricing : { operators: [ SuccessfulPricing-Map: {
inputcalculators : [ { core : basicMetricsPackage } ] } ] } ] } }
….
Java: stream.uid(“SuccessfulPricing”).map(jsonMarshallerOperator);
Annotation pipeline decoration:
@MetricsCalculator(package=“basicMetricsPackage”, scope=“SuccessfulPricing-Map”)
private MapFunction<ItemPushRequest,Tuple2<String,String>> jsonMarshaller;
…
stream.map(jsonMarshallerOperator);
6
150406
CHICategory Prioritization ...
�
7 .BI metrics: in-process
In-process: fits small BI dimension cardinality & domain cases
• just a regular operator metric extending VectorMetricsCalculator, with custom key extractor FP lambda
• metric keys will be extracted on the fly from data and new Metrics will be registered & reported dynamically
• keyed metric state will be kept per each metric key
• keyed metric state will be updated in-process within each operator invocation (only for the extracted key)
• each task operator will keep a partition of metric keys that it has observed
• no aggregation in Flink: BI metrics are kept & reported without aggregation as regular Metric Groups
• abuse of dimensionality: may bloat the TM memory and/or operator state in Flink and/or Flink metrics reporter
public static MetricsCalculator<ItemPushRequest> priceChangePackage(){
return new ResettingVectorCounterCalculator<ItemPushRequest>().withSimpleEvaluator(
(data, s) -> Arrays.asList("PriceChangeDescTotalCounter", data.getItemPricePushData().getPriceChangeDesc())
, (k, s) -> !k.get().isEmpty()? 1L: null);
}
7
150406
CHICategory Prioritization ...
�
8 .BI metrics: side output
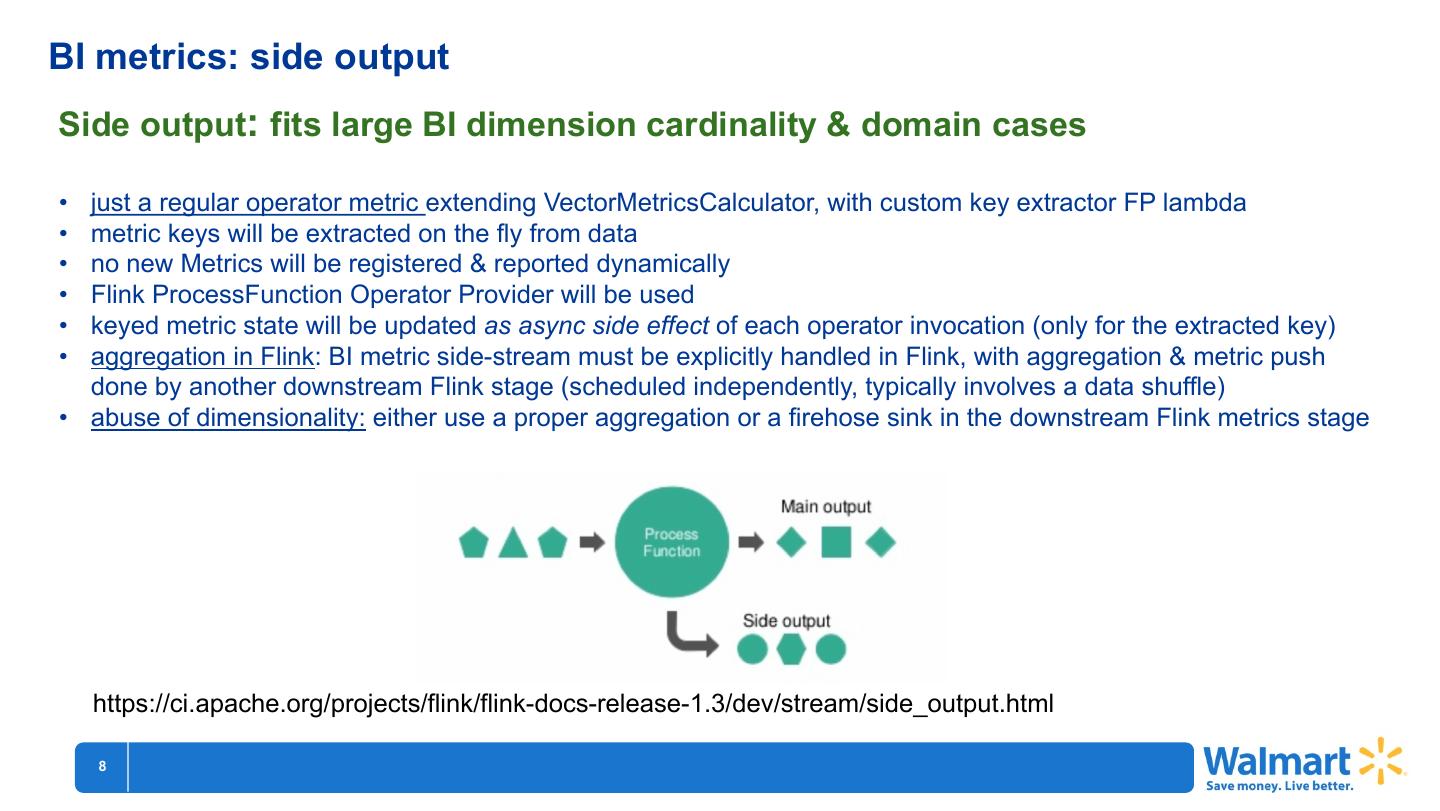
Side output: fits large BI dimension cardinality & domain cases
• just a regular operator metric extending VectorMetricsCalculator, with custom key extractor FP lambda
• metric keys will be extracted on the fly from data
• no new Metrics will be registered & reported dynamically
• Flink ProcessFunction Operator Provider will be used
• keyed metric state will be updated as async side effect of each operator invocation (only for the extracted key)
• aggregation in Flink: BI metric side-stream must be explicitly handled in Flink, with aggregation & metric push
done by another downstream Flink stage (scheduled independently, typically involves a data shuffle)
• abuse of dimensionality: either use a proper aggregation or a firehose sink in the downstream Flink metrics stage
https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/stream/side_output.html
8
150406
CHICategory Prioritization ...
�
9 . A final bit of advice:
Make a proper choice of the metrics DB/aggregation tech
Pay attention to the limits of metric dashboarding tools
9
150406
CHICategory Prioritization ...
�