





















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Flink + Apache Beam: Expanding the horizons of Big Data
在过去的几个月里,Apache Flink和Apache Beam开源社区一直在忙于开发最先进的工业级解决方案,通过修改Beam的接口,构建相应的Flink Runner代码,同时简化Flink的分发和部署机制,让Python可以完成批量数据和实时流数据作业。有了这个工作基础,大数据领域杀手级程序就这么诞生了,让用户可以轻易集成超大数据处理结果,输入到TensorFlow的Pipeline中,完成基于大数据实时计算平台的深度学习和数据预测功能。这篇PPT将介绍一系列Google开发的基于Beam的Python SDK开源库,让超大规模的数据预处理更有效的和TensorFlow完美集成。
展开查看详情
1 .Apache Flink + Expanding the horizons of Big-Data Apache Beam Presenter: Anand Iyer Product Manager, Google Cloud © 2017 Google Inc. All rights reserved.
2 . Rich history of collaboration Comprehensive Comprehensive Streaming SQL Unified streaming streaming& (w/ Apache Streaming SQL Batch Unified & Streaming semantics semantics & Calcite) (w/ Apache Calcite) Batch & Streaming correctness correctness © 2017 Google Inc. All rights reserved.
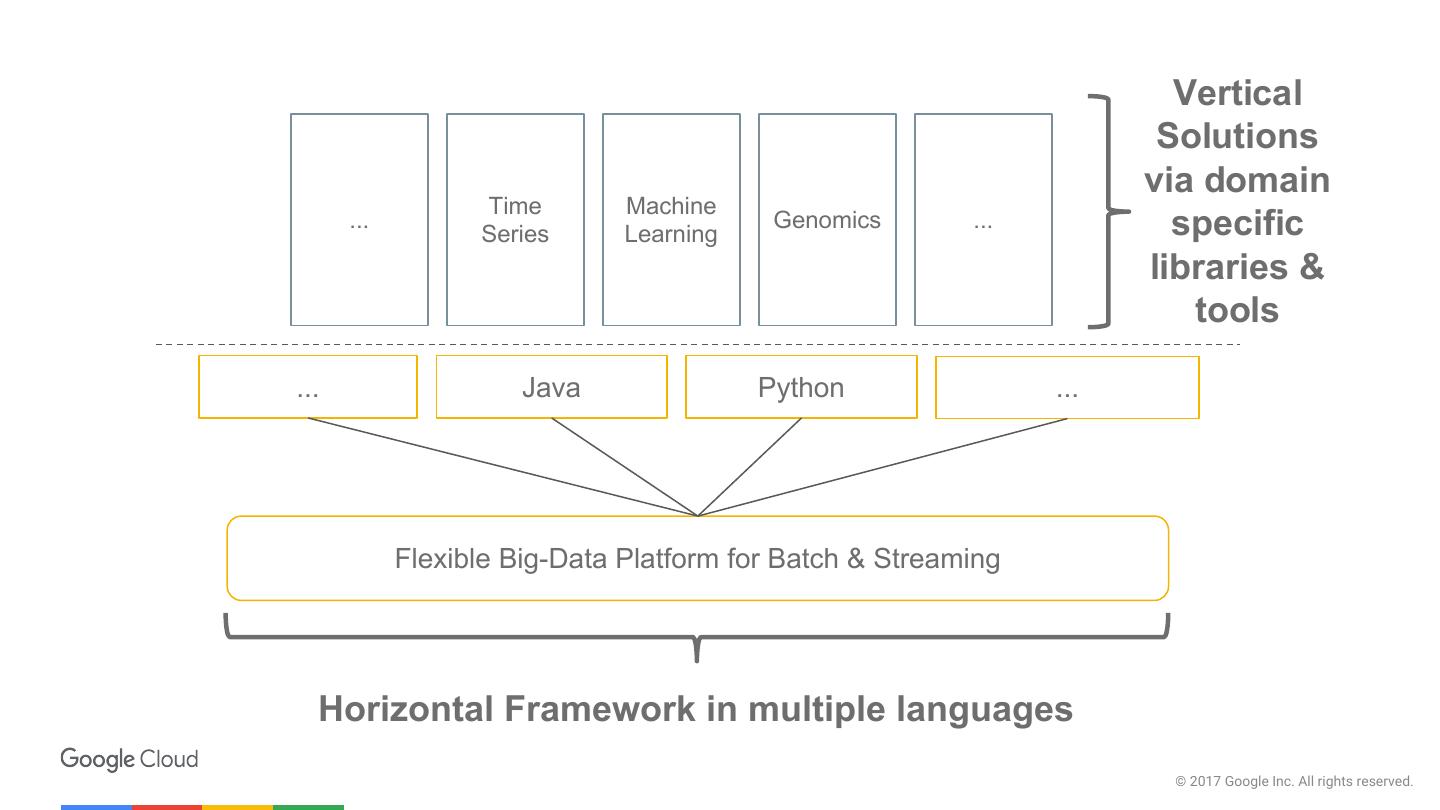
3 . Vertical Solutions via domain Time Machine ... Series Learning Genomics ... specific libraries & tools ... Java Python ... Flexible Big-Data Platform for Batch & Streaming Horizontal Framework in multiple languages © 2017 Google Inc. All rights reserved.
4 .Making the power of Flink available in multiple languages © 2017 Google Inc. All rights reserved.
5 .The Apache Beam Model © 2017 Google Inc. All rights reserved.
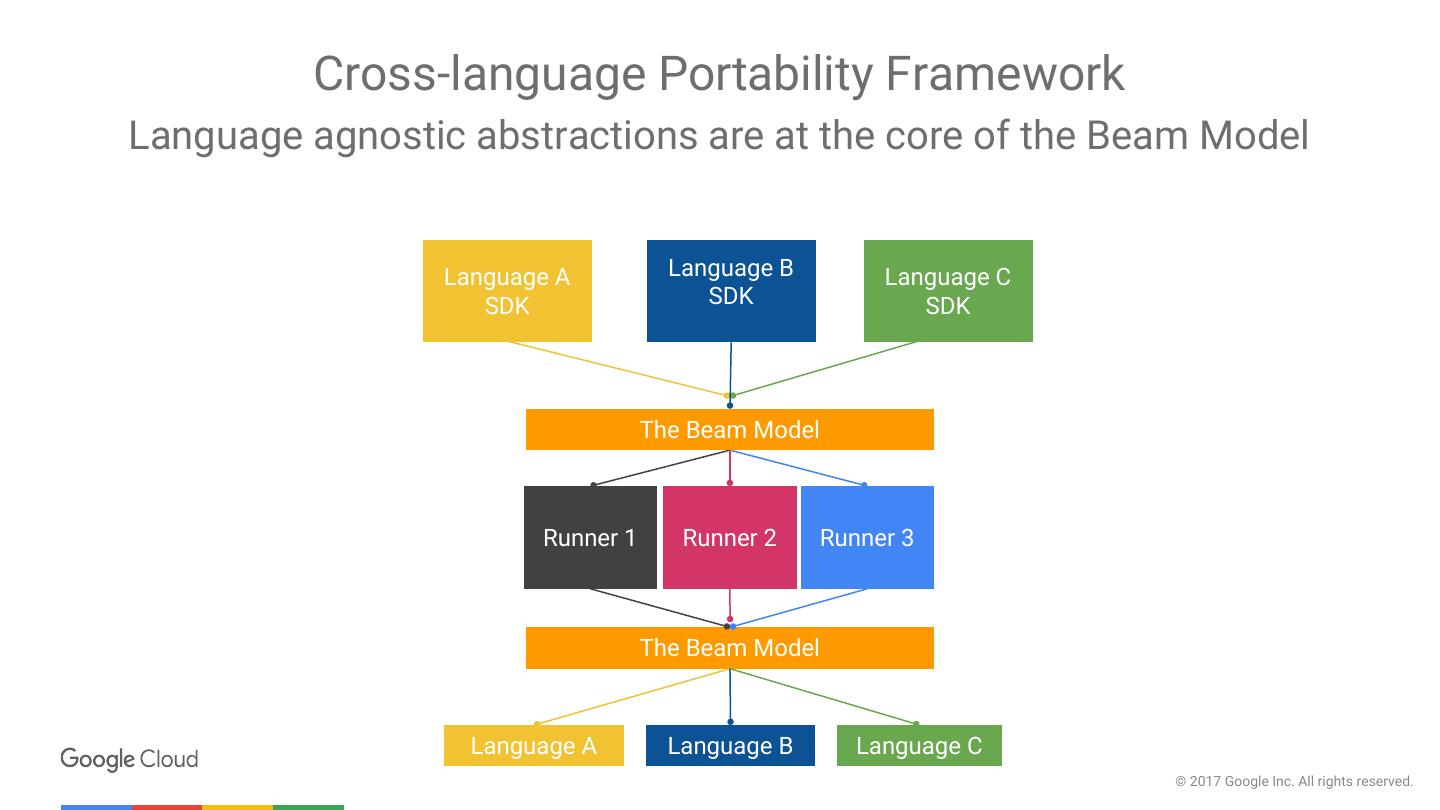
6 . Cross-language Portability Framework Language agnostic abstractions are at the core of the Beam Model Language A Language B Language C SDK SDK SDK The Beam Model Runner 1 Runner 2 Runner 3 The Beam Model Language A Language B Language C © 2017 Google Inc. All rights reserved.
7 .Prototype Flink Runner ❏ Works with Beam’s Python SDK ❏ Collaborators: Flink, Beam, Lyft, GetInData ❏ https://issues.apache.org/jira/browse/ BEAM-2889 ❏ For updates, please subscribe to Apache Flink and Apache Beam Blogs © 2017 Google Inc. All rights reserved.
8 .Prototype Flink Runner ❏ Currently supports batch workloads ❏ Streaming capabilities on the roadmap © 2017 Google Inc. All rights reserved.
9 .Tools & libraries for compelling use case verticals © 2017 Google Inc. All rights reserved.
10 .Machine-Learning + Big-Data Joined at the Hip © 2017 Google Inc. All rights reserved.
11 .© 2017 Google Inc. All rights reserved.
12 .Because, in addition to the actual ML... ML Code © 2017 Google Inc. All rights reserved.
13 ....you have to worry about so much more. Data Monitoring Verification Configuration Data Collection ML Analysis Tools Code Cod Serving Process Management Machine Infrastructure Tools Resource Feature Engineering Management © 2017 Google Inc. All rights reserved.
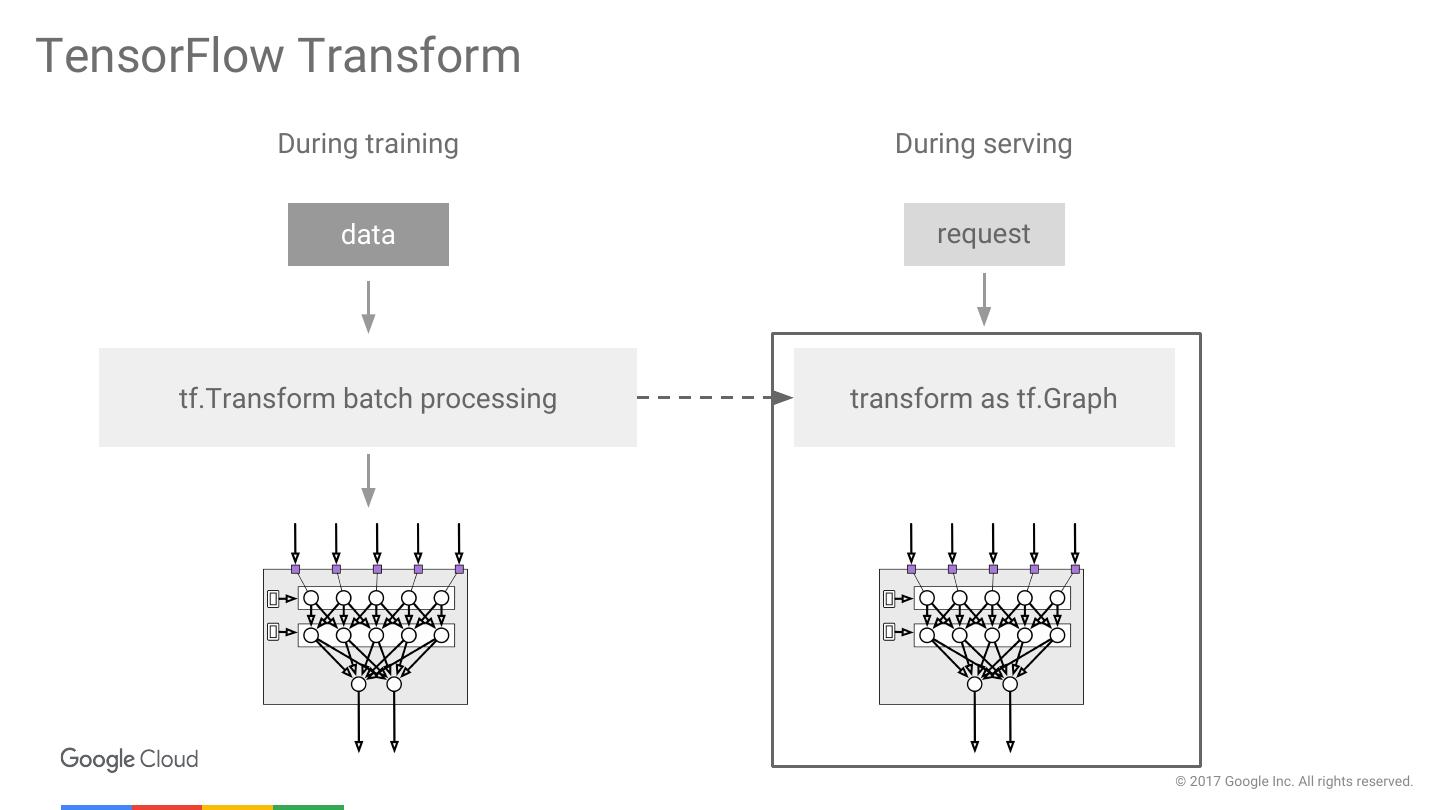
14 .TensorFlow Transform Consistent In-Graph Transformations in Training and Serving © 2017 Google Inc. All rights reserved.
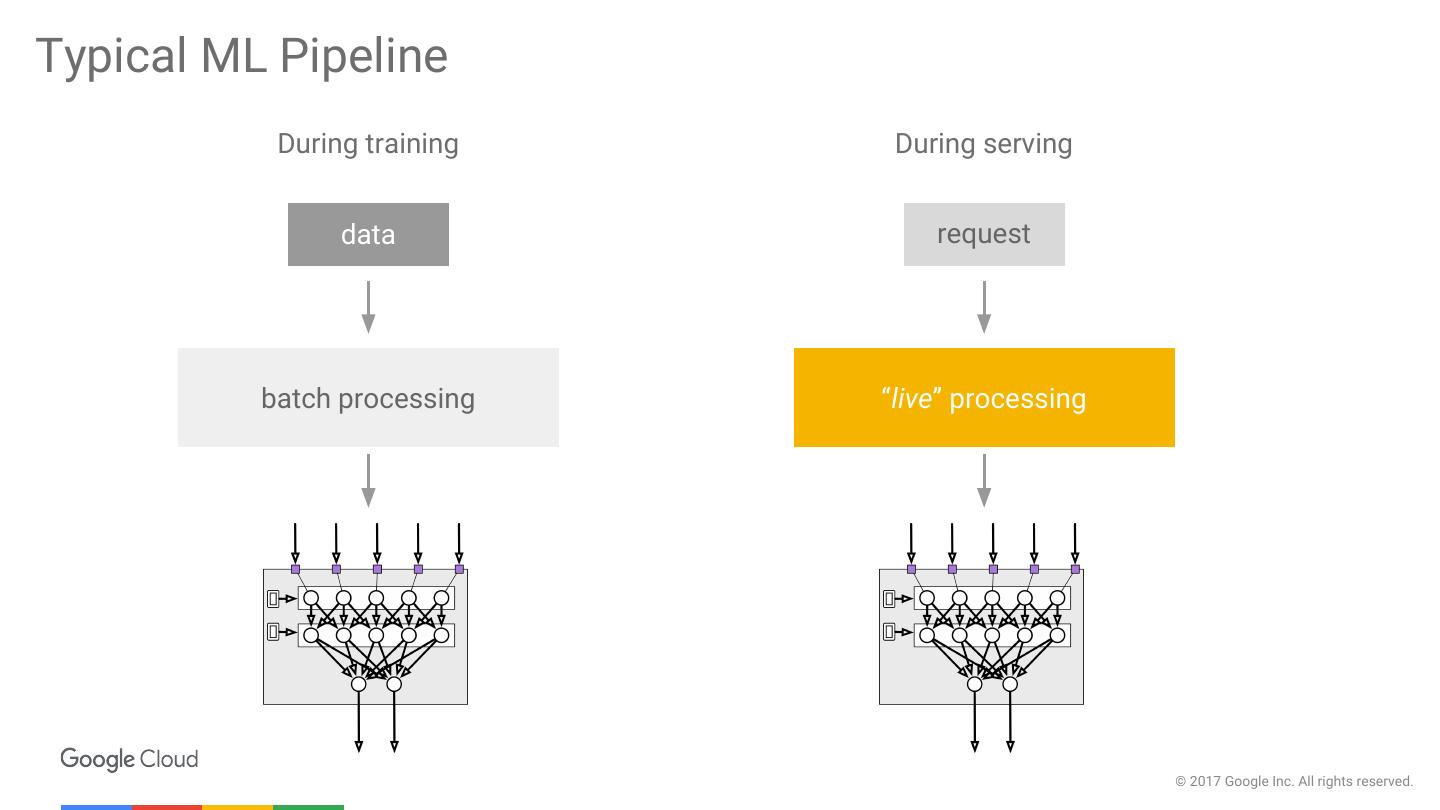
15 .Typical ML Pipeline During training During serving data request batch processing “live” processing © 2017 Google Inc. All rights reserved.
16 .Typical ML Pipeline During training During serving data request batch processing “live” processing © 2017 Google Inc. All rights reserved.
17 .TensorFlow Transform During training During serving data request tf.Transform batch processing transform as tf.Graph © 2017 Google Inc. All rights reserved.
18 .Rich collection of pre-implemented transforms Scale to ... Bag of Words / N-Grams tf.string_split tft.scale_to_z_score tft.ngrams ... tft.string_to_int Bucketization Feature Crosses tft.quantiles tf.string_join tft.apply_buckets tft.string_to_int © 2017 Google Inc. All rights reserved.
19 .Rich collection of pre-implemented transforms Scale to ... Bag of Words / N-Grams tf.string_split tft.scale_to_z_score tft.ngrams ... tft.string_to_int Bucketization Feature Crosses tft.quantiles tf.string_join tft.apply_buckets tft.string_to_int Apply another TensorFlow Model tft.apply_saved_model © 2017 Google Inc. All rights reserved.
20 .github.com/tensorflow/transform © 2017 Google Inc. All rights reserved.
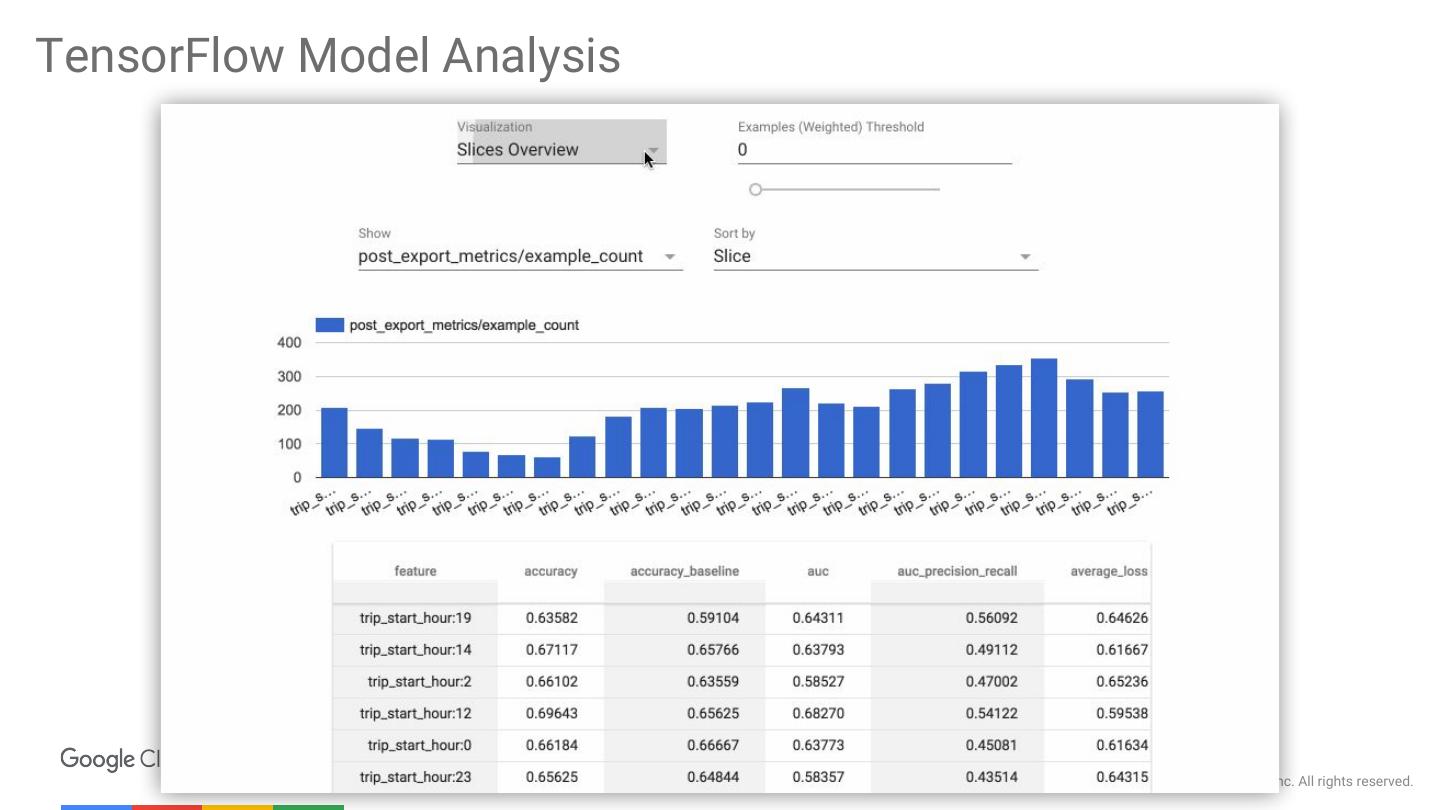
21 .TensorFlow Model Analysis Scalable, sliced, and full-pass metrics © 2017 Google Inc. All rights reserved.
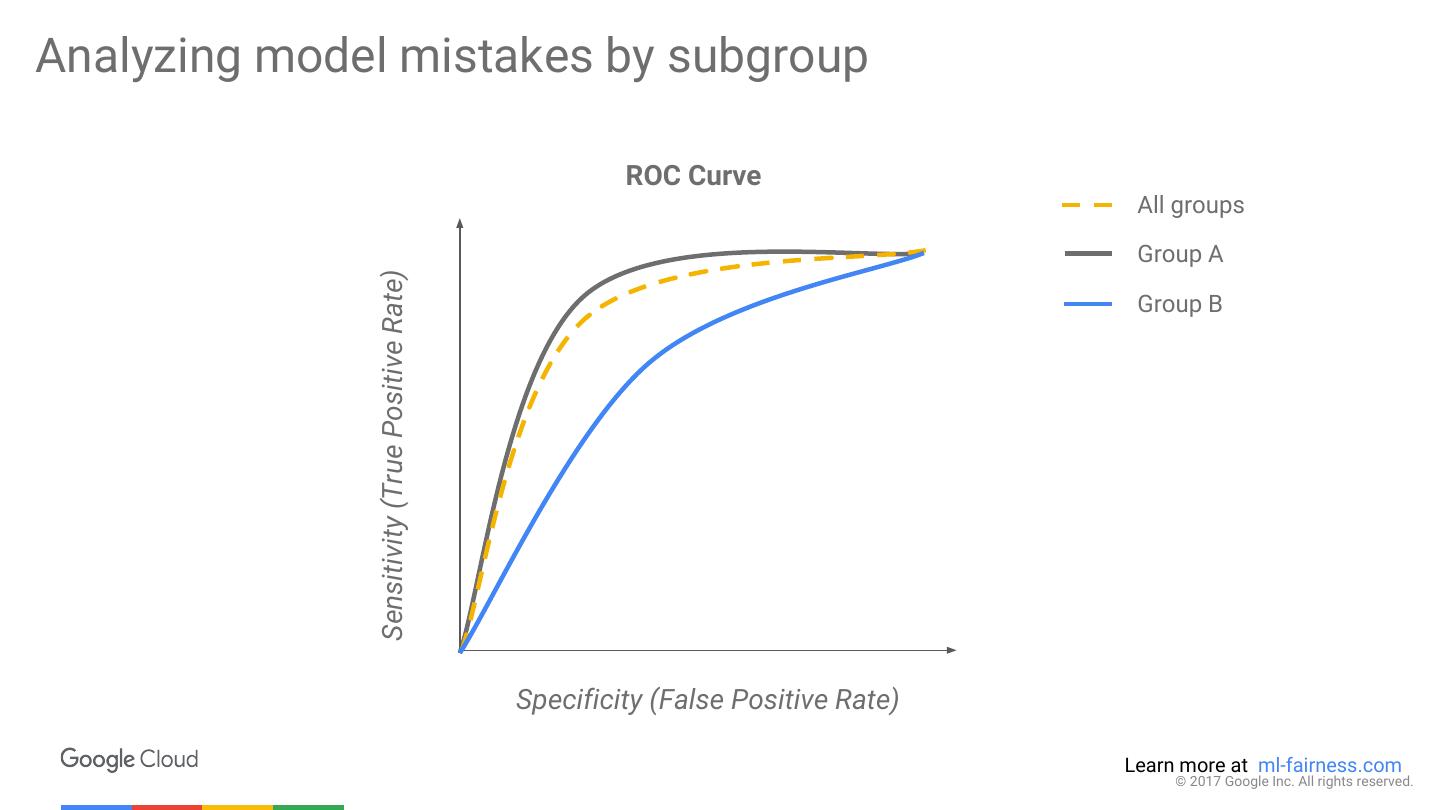
22 .Analyzing model mistakes by subgroup ROC Curve All groups Sensitivity (True Positive Rate) Specificity (False Positive Rate) Learn more at ml-fairness.com © 2017 Google Inc. All rights reserved.
23 .Analyzing model mistakes by subgroup ROC Curve All groups Group A Sensitivity (True Positive Rate) Group B Specificity (False Positive Rate) Learn more at ml-fairness.com © 2017 Google Inc. All rights reserved.
24 .TensorFlow Model Analysis © 2017 Google Inc. All rights reserved.
25 . github.com/tensorflow/model-analysis https://medium.com/tensorflow/introducing-tensorflow-model-anal ysis-scaleable-sliced-and-full-pass-metrics-5cde7baf0b7b © 2017 Google Inc. All rights reserved.
26 .Tensorflow Extended https://youtu.be/vdG7uKQ2eKk © 2017 Google Inc. All rights reserved.
27 .TFX: A TensorFlow-Based Production-Scale Machine Learning Platform. KDD (2017). https://youtu.be/fPTwLVCq00U © 2017 Google Inc. All rights reserved.
28 . Big-Data in Genomics Beam library for transforming and processing VCF files at scale https://github.com/googlegenomics/gcp-variant-transforms © 2017 Google Inc. All rights reserved.
29 . Come join us! Add new language Complete the Flink Build vertical SDKs. Runner libraries & tools Javascript anyone? © 2017 Google Inc. All rights reserved.
相关推荐
3秒后跳转登录页面
去登陆

