21 .A brief interlude on algorithms A batch algorithm does a computation all in one go given an entire dataset Closed-form solution to linear regression Selection sort Quicksort Pretty much anything involving gradient descent. An online algorithm incrementally computes as new data becomes available Heap algorithm for the k th largest element in a stream Perceptron algorithm Insertion sort Greedy algorithms
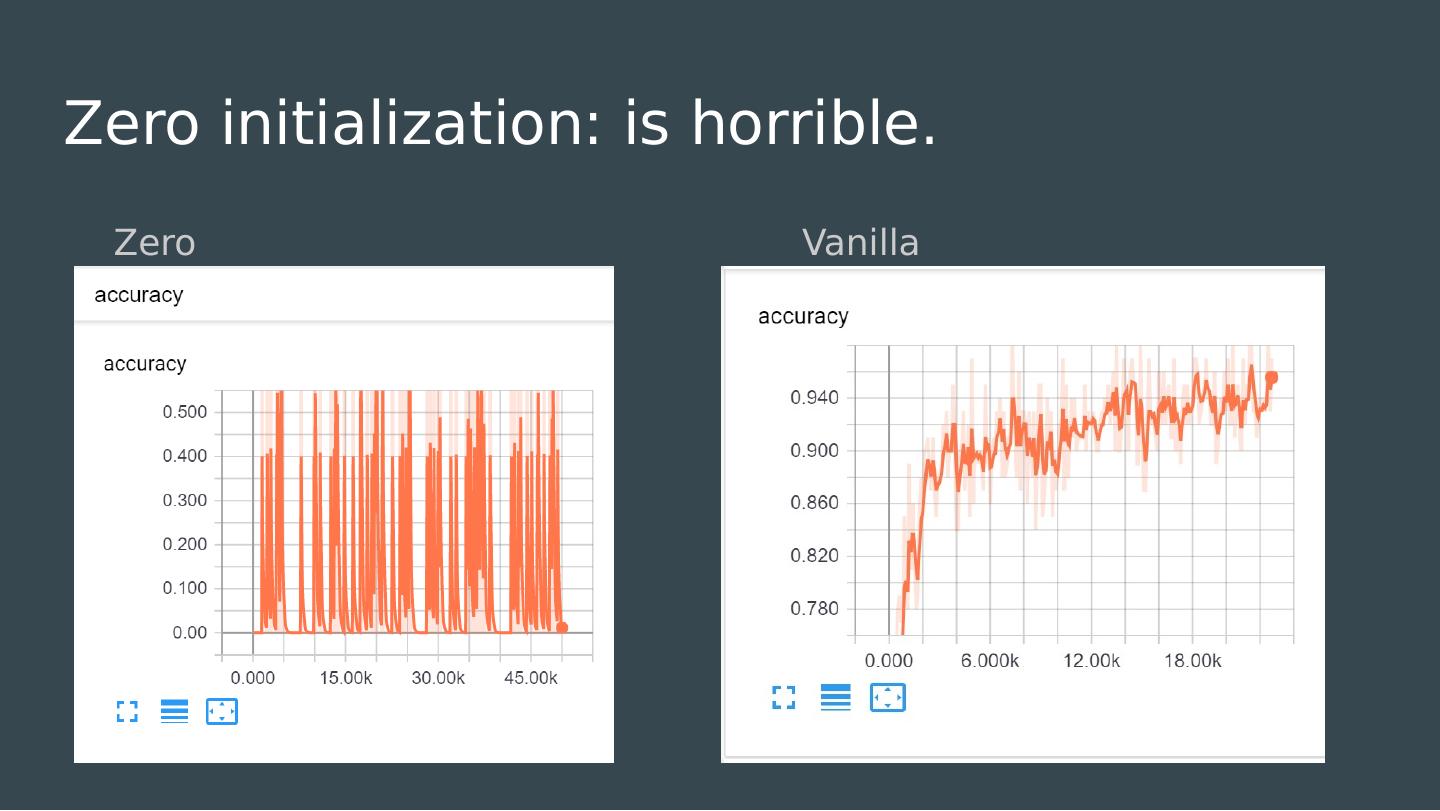
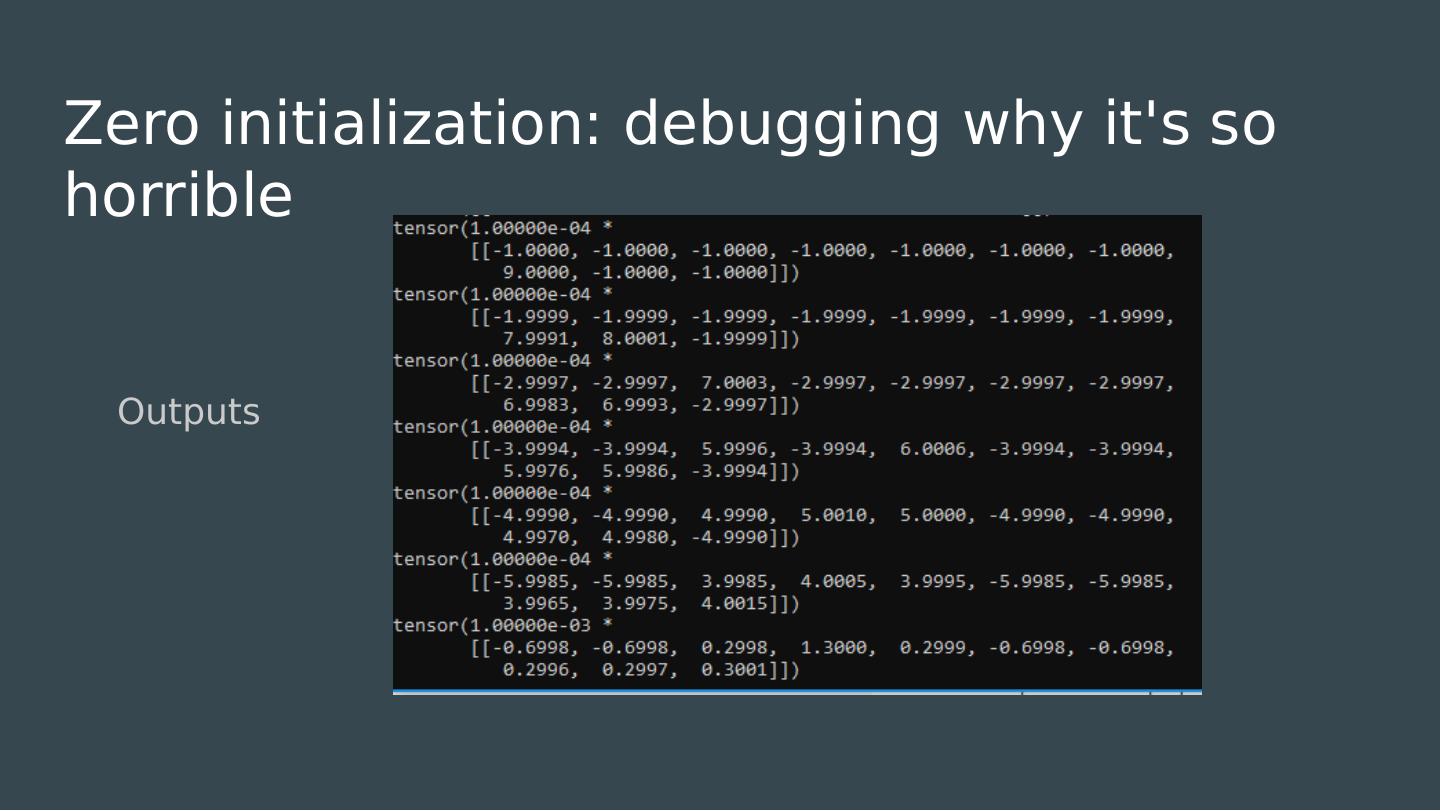
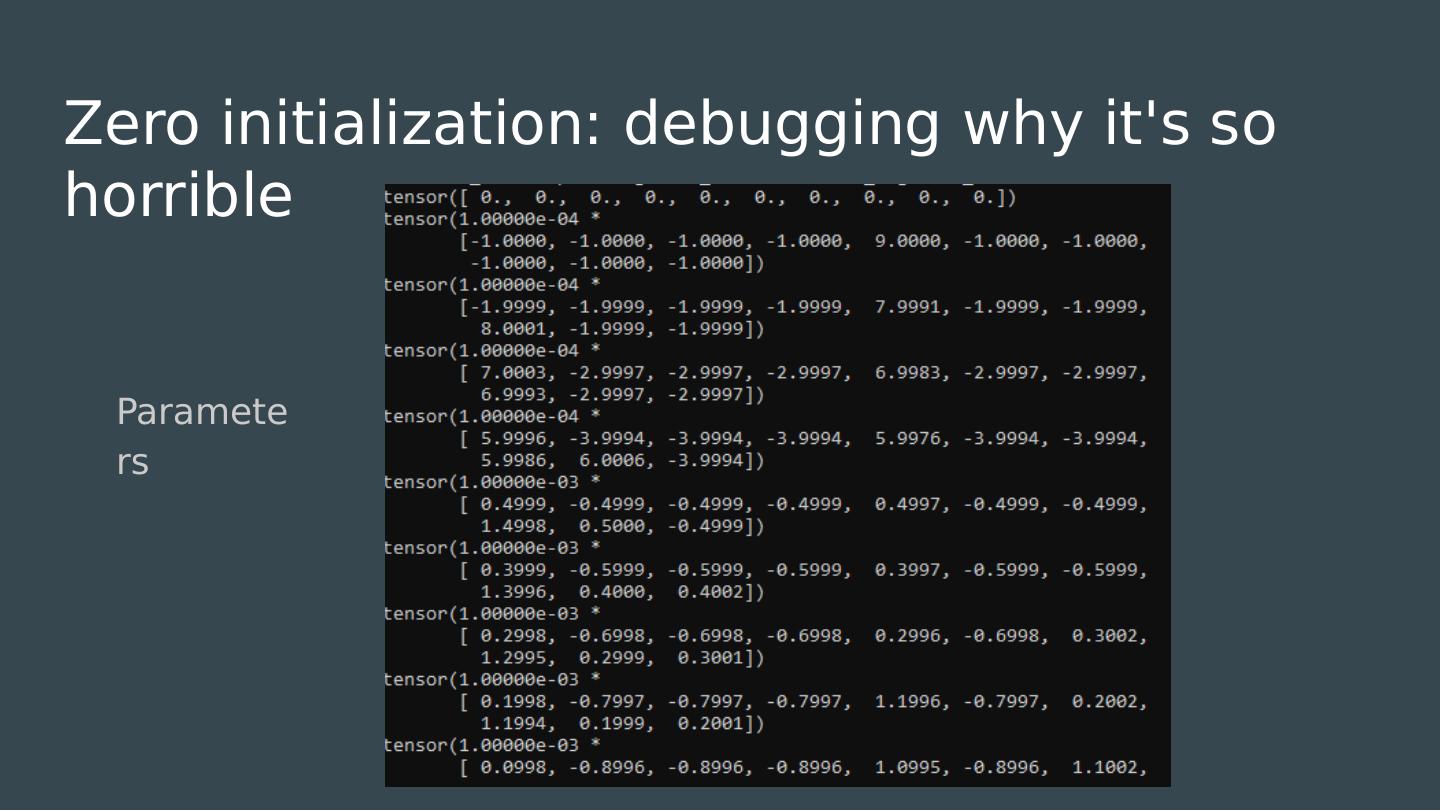
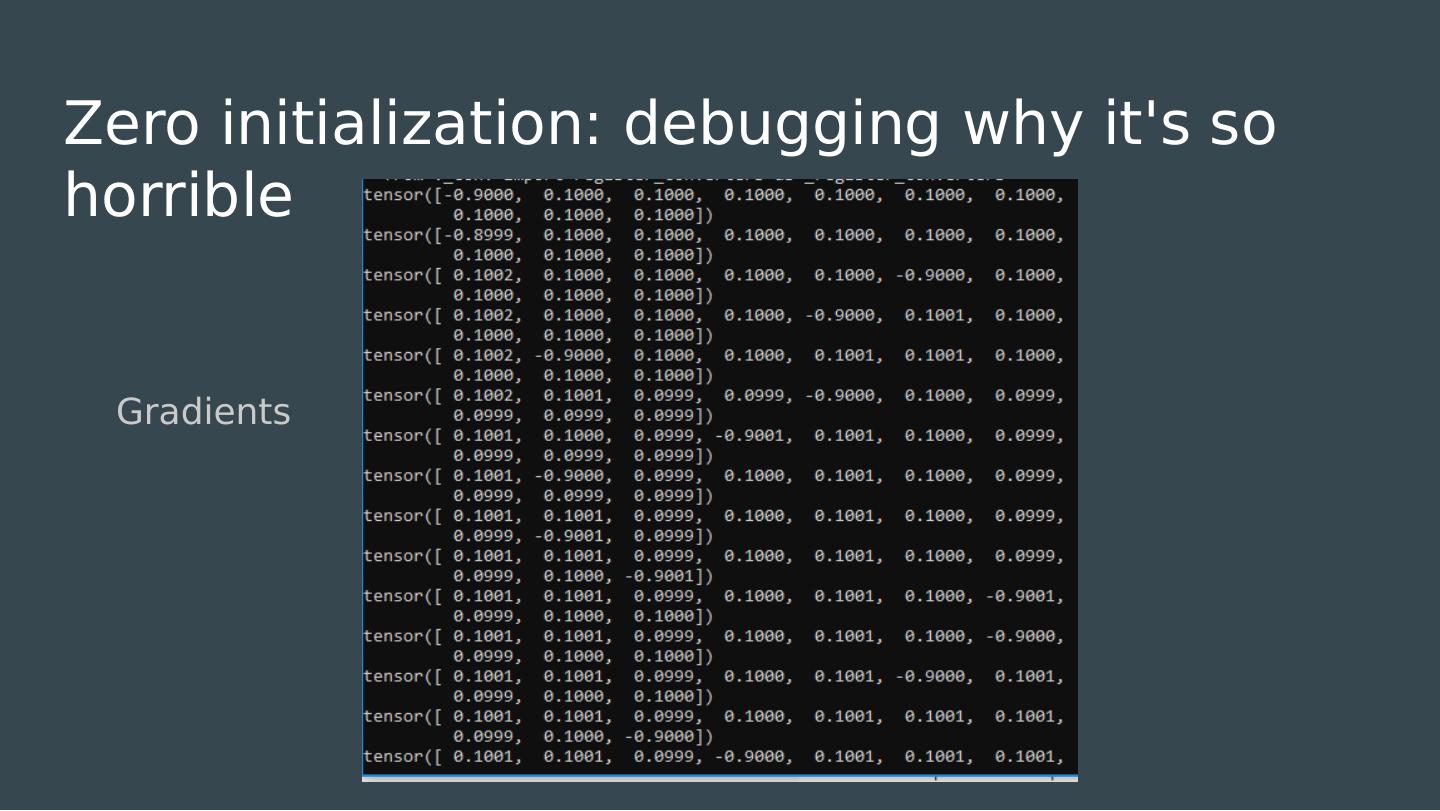
22 .How do we initialize our weights? Most models work best when normalized around zero. All of our choices of activation functions inflect about zero. What is the simplest possible initialization strategy?
23 .How do we initialize our weights? Most models work best when normalized around zero. All of our choices of activation functions inflect about zero. What is the simplest possible initialization strategy?
24 .Looking forward HW0 is due tonight. HW1 will be released later this week. Next week, we discuss architecture tradeoffs and begin computer vision.
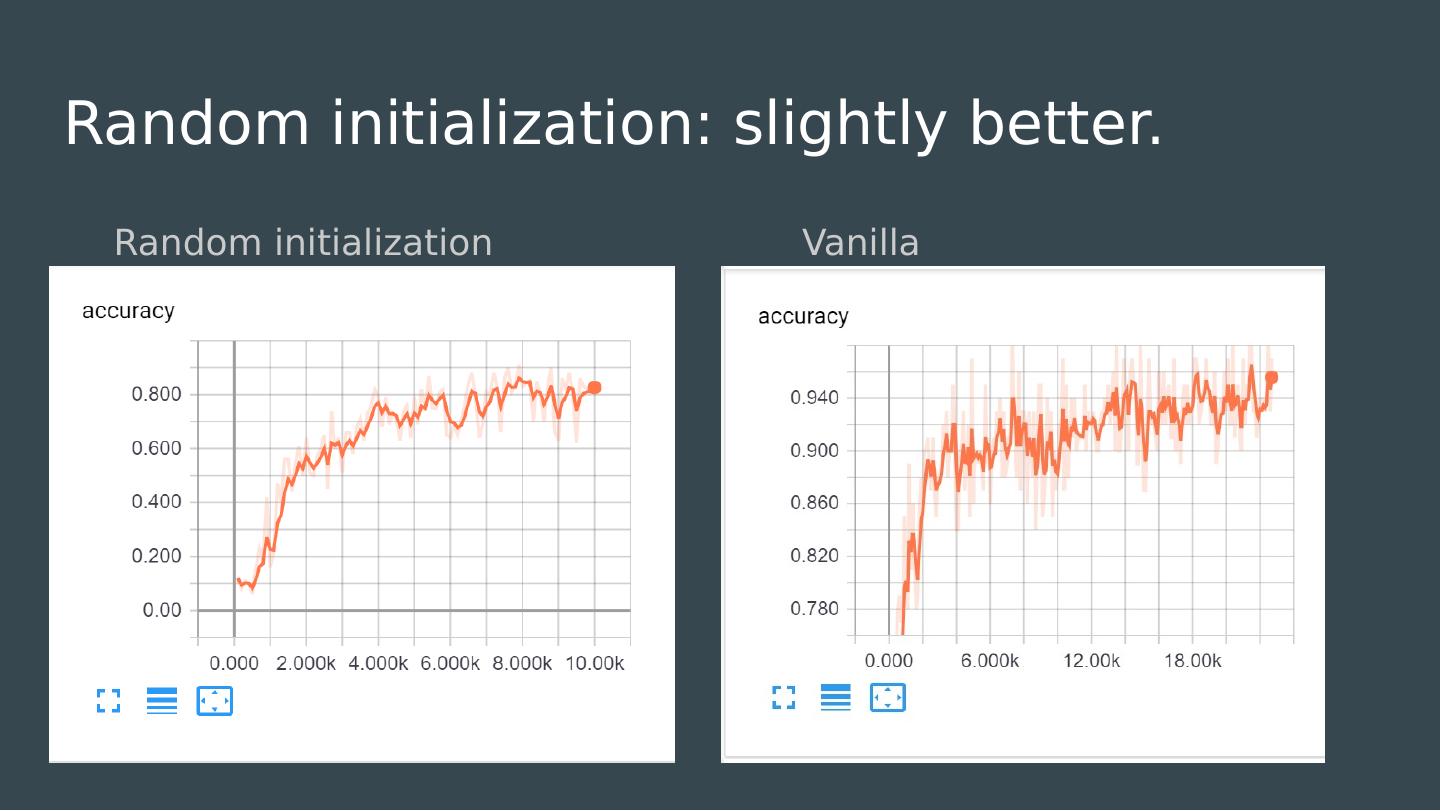
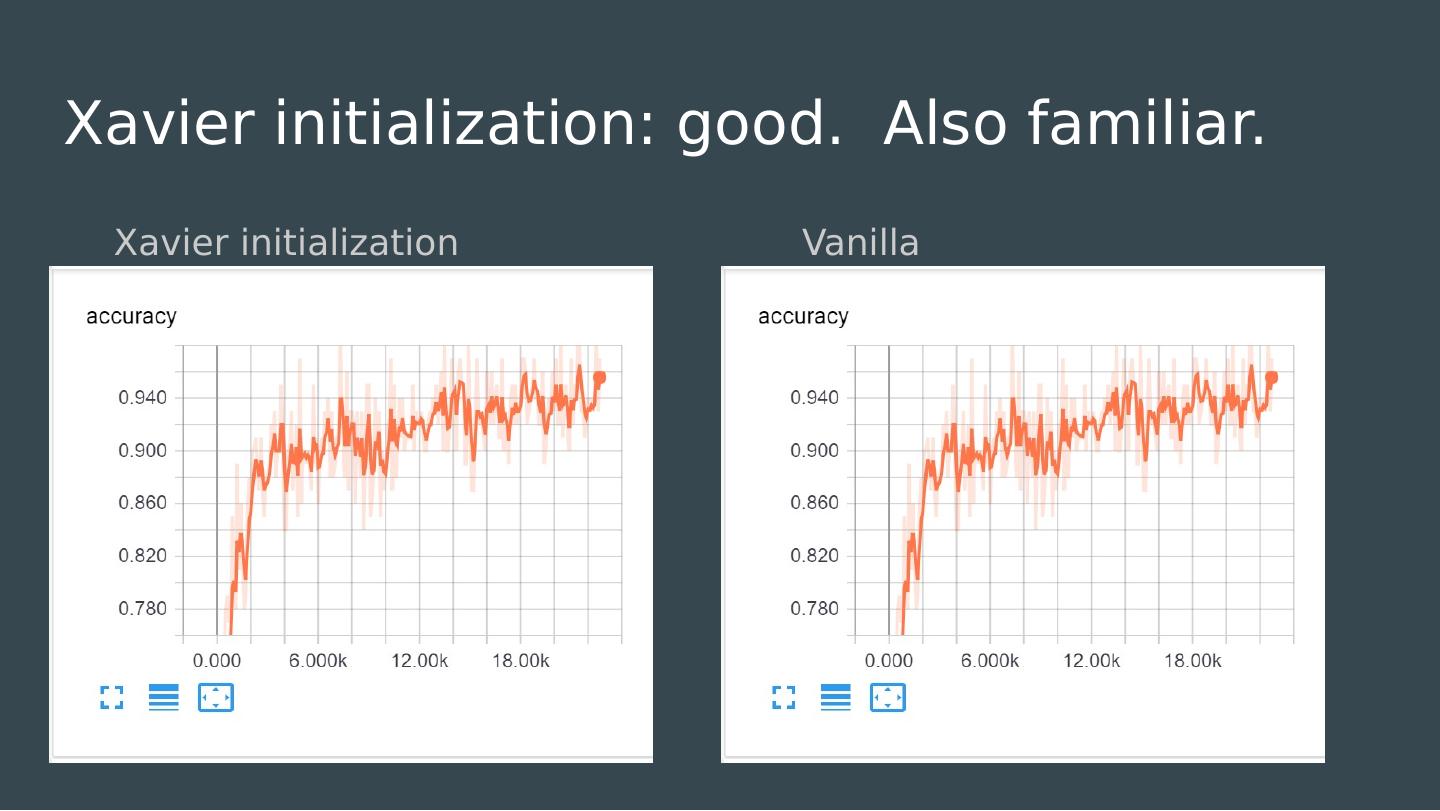
25 .What to do when your gradients are too small Find a better activation? Find a better architecture? Find a better initialization? Find a better career?
26 .What to do when your gradients are too small Find a better activation? Find a better architecture? Find a better initialization? Find a better career?