









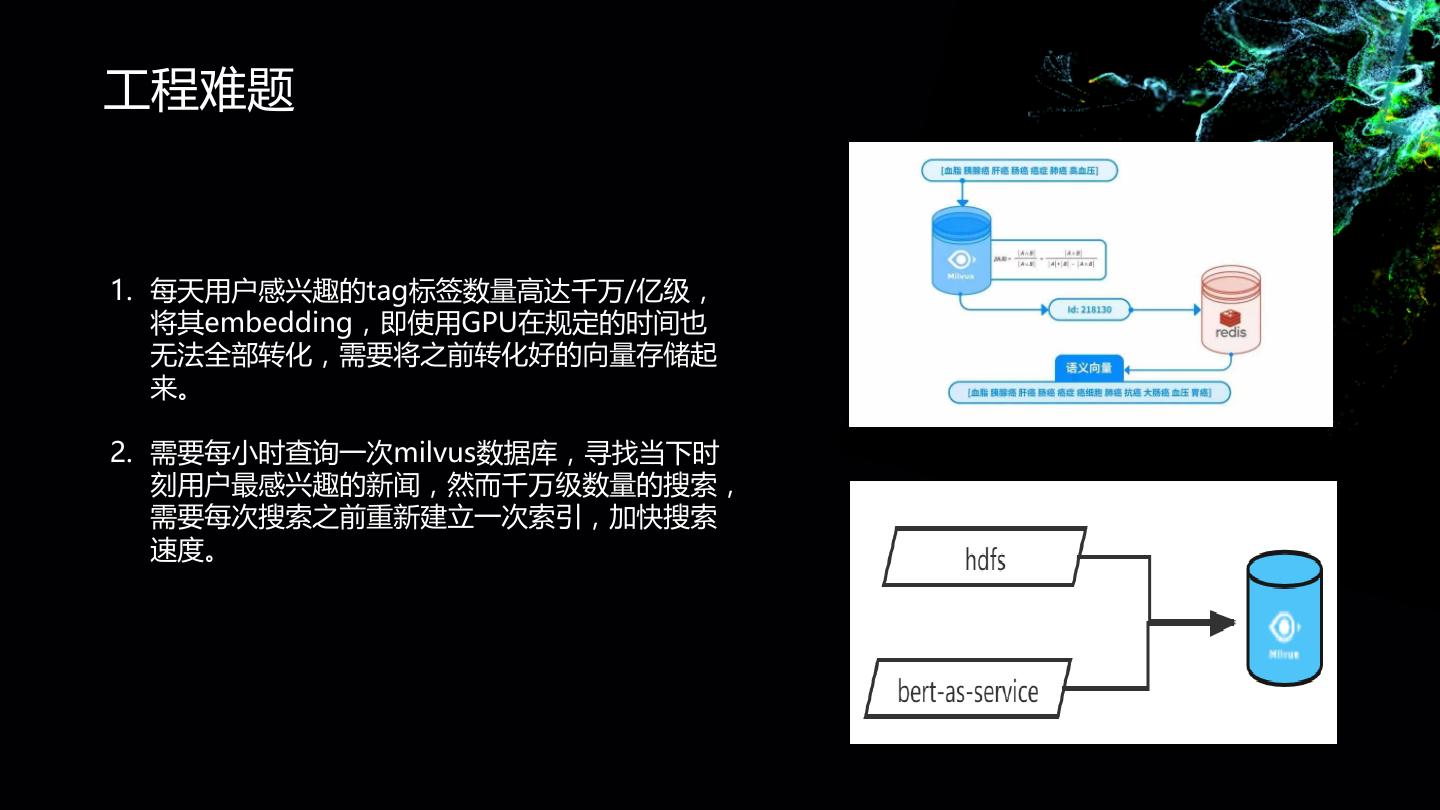


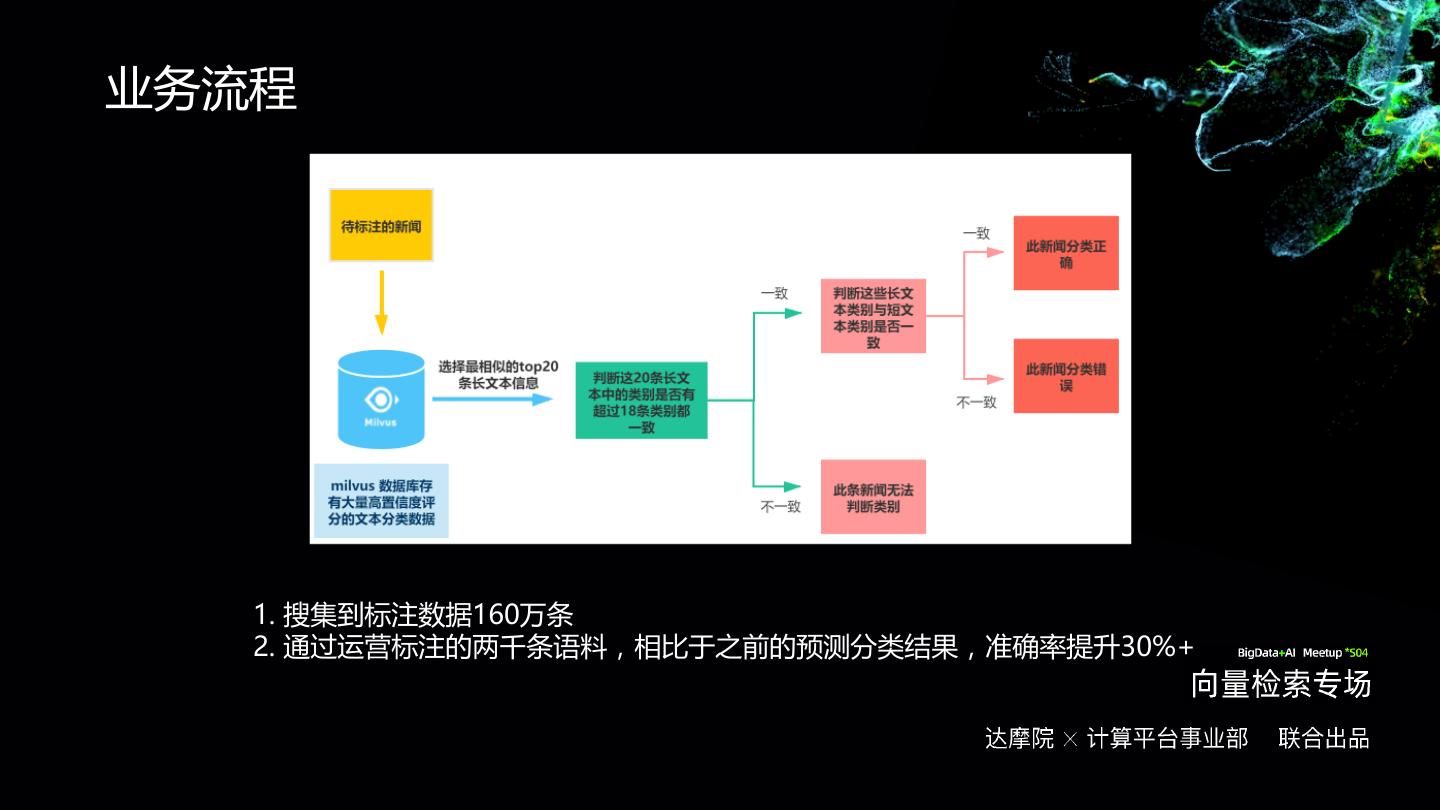





- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
8 Milvus 向量搜索工具在搜狐的应用-王婷婷
议题简介:
得益于 Mlivus 向量搜索工具的高效部署,在处理海量数据时准确快速,本次演讲中,我们将分享利用 Milvus 向量搜索工具解决语义向量召回时的向量搜索问题和短新闻文本分类时文本的标注问题。
嘉宾简介:
王婷婷,搜狐自然语言处理工程师。
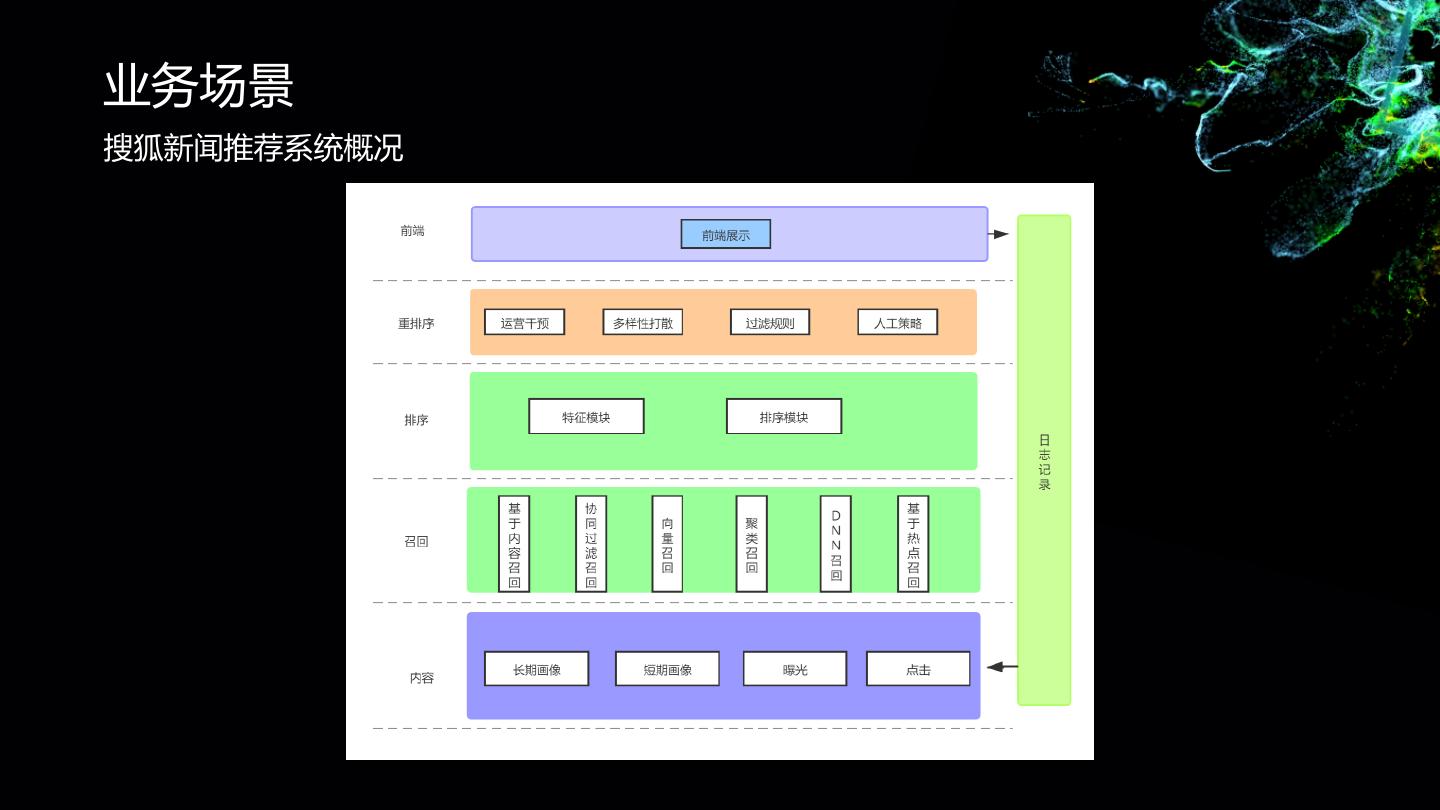
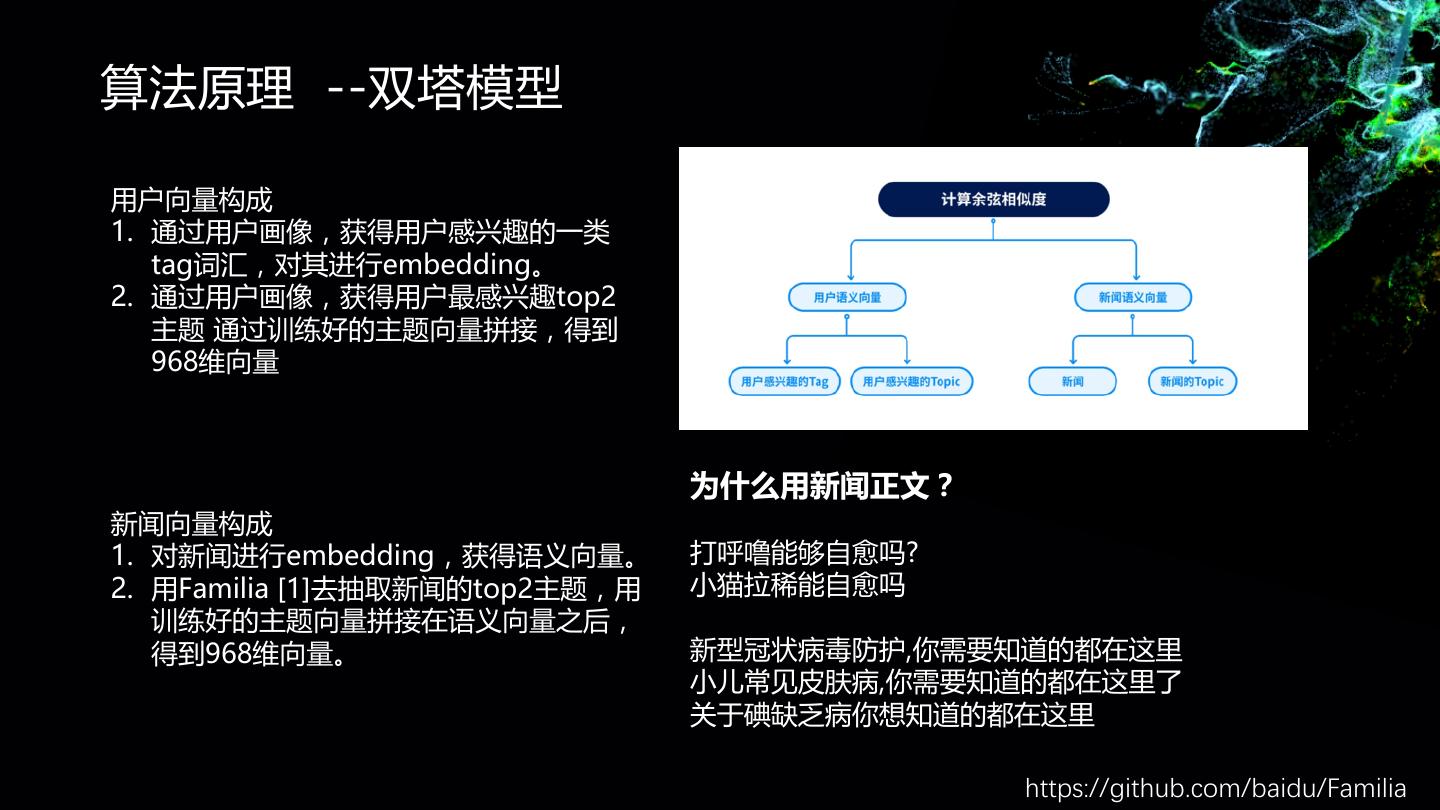
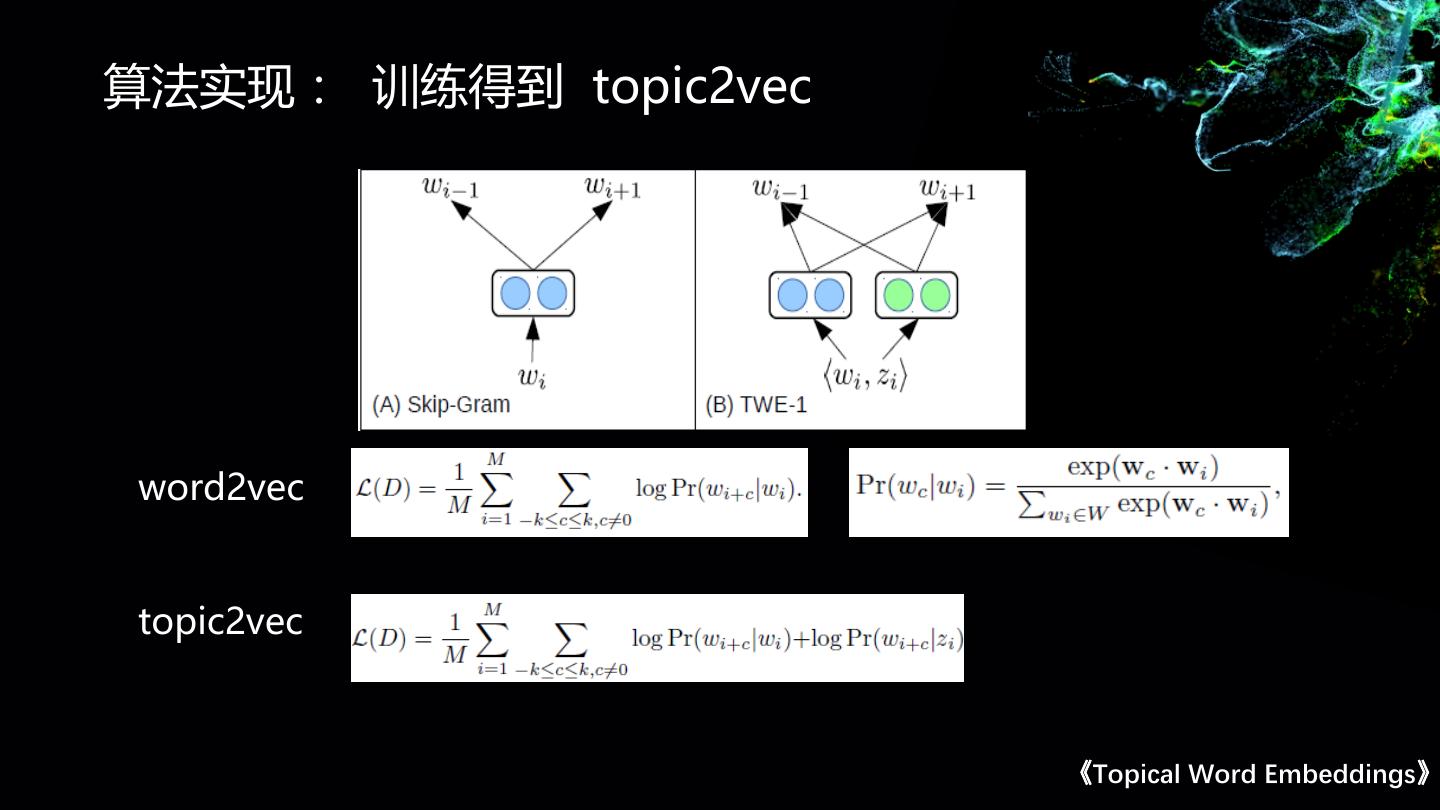
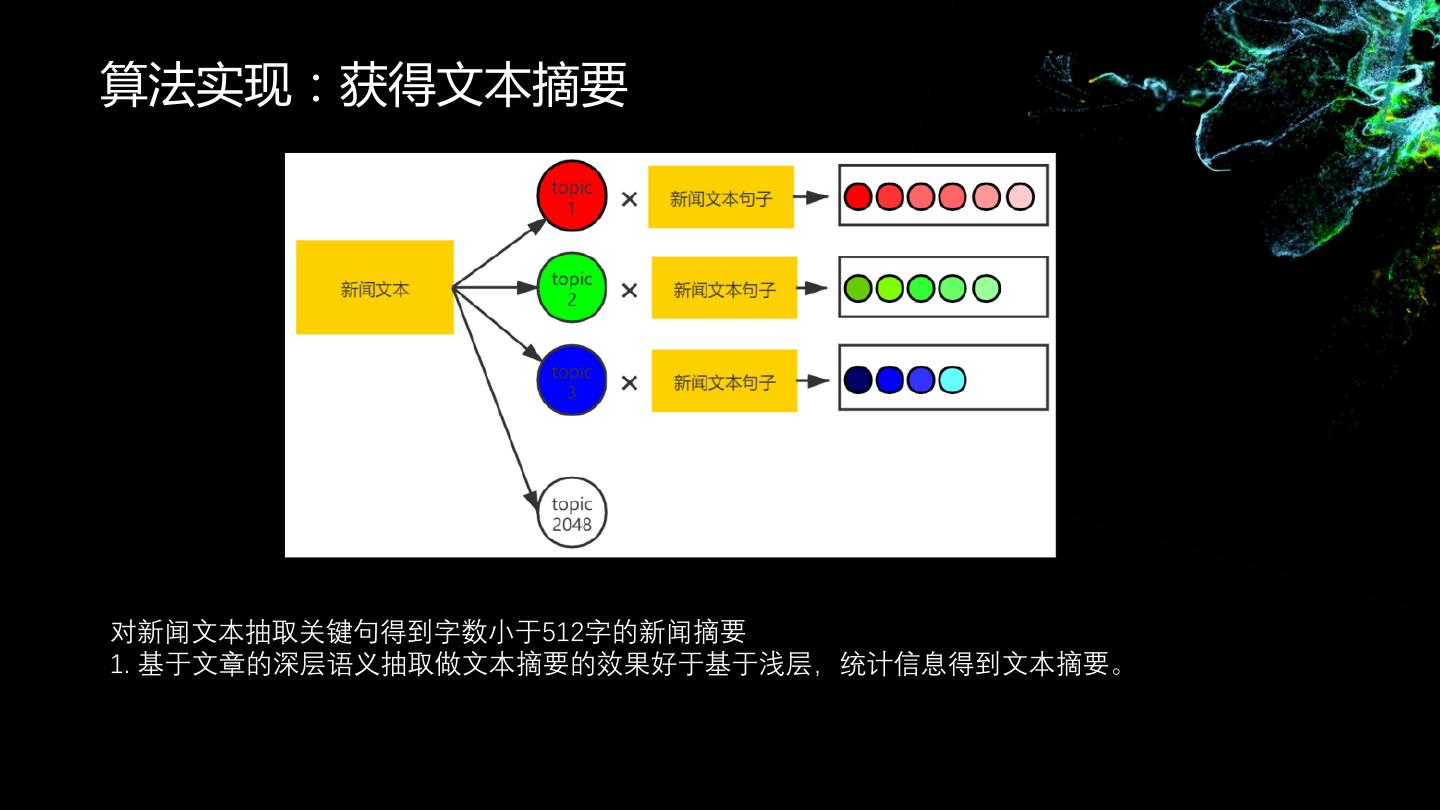
在搜狐主要从事基于内容的语义向量召回,文本分类,文本摘要,新闻聚类,新闻关键词提取等相关工作。
3秒后跳转登录页面
去登陆

