









































































































































































































































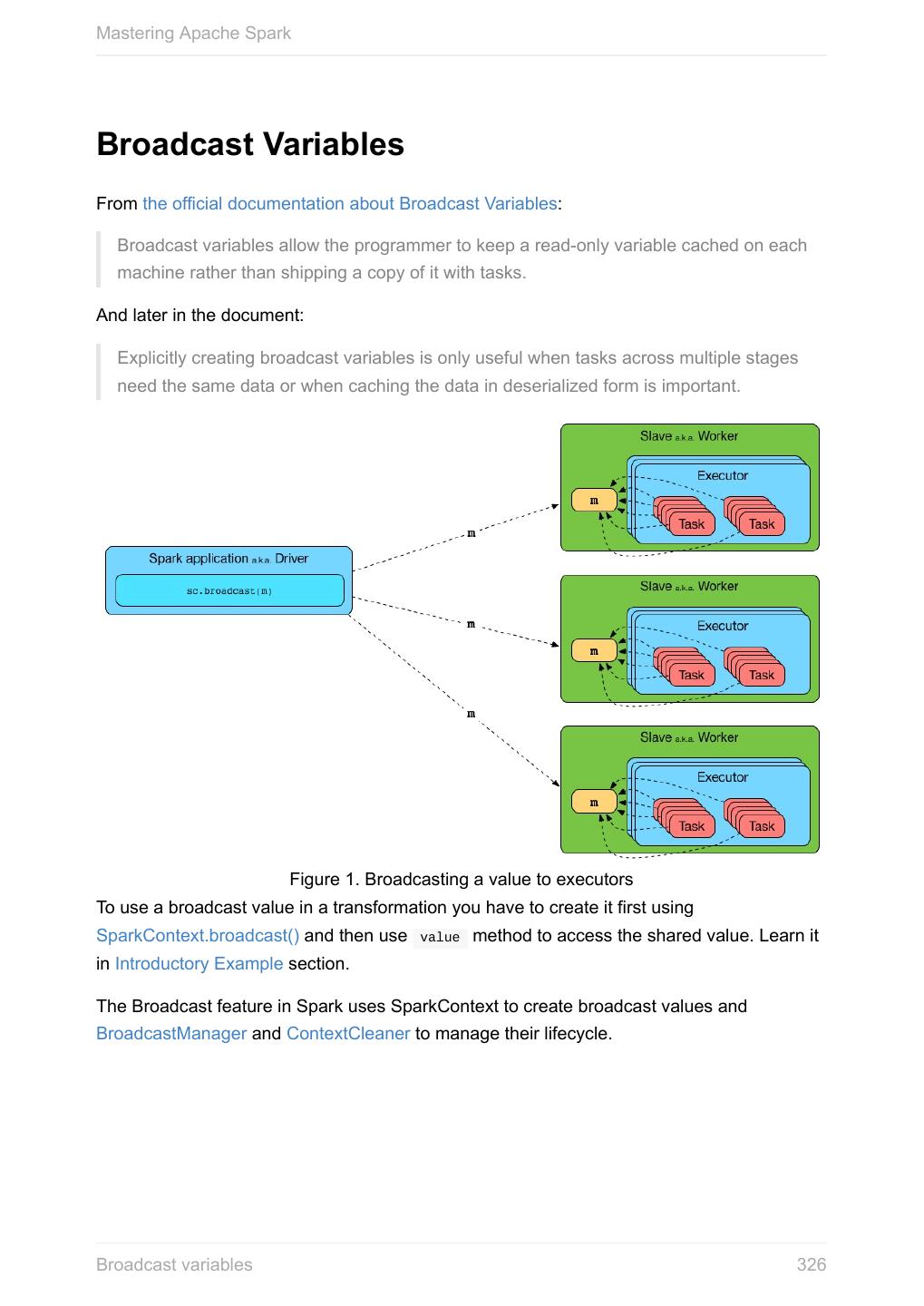





















































































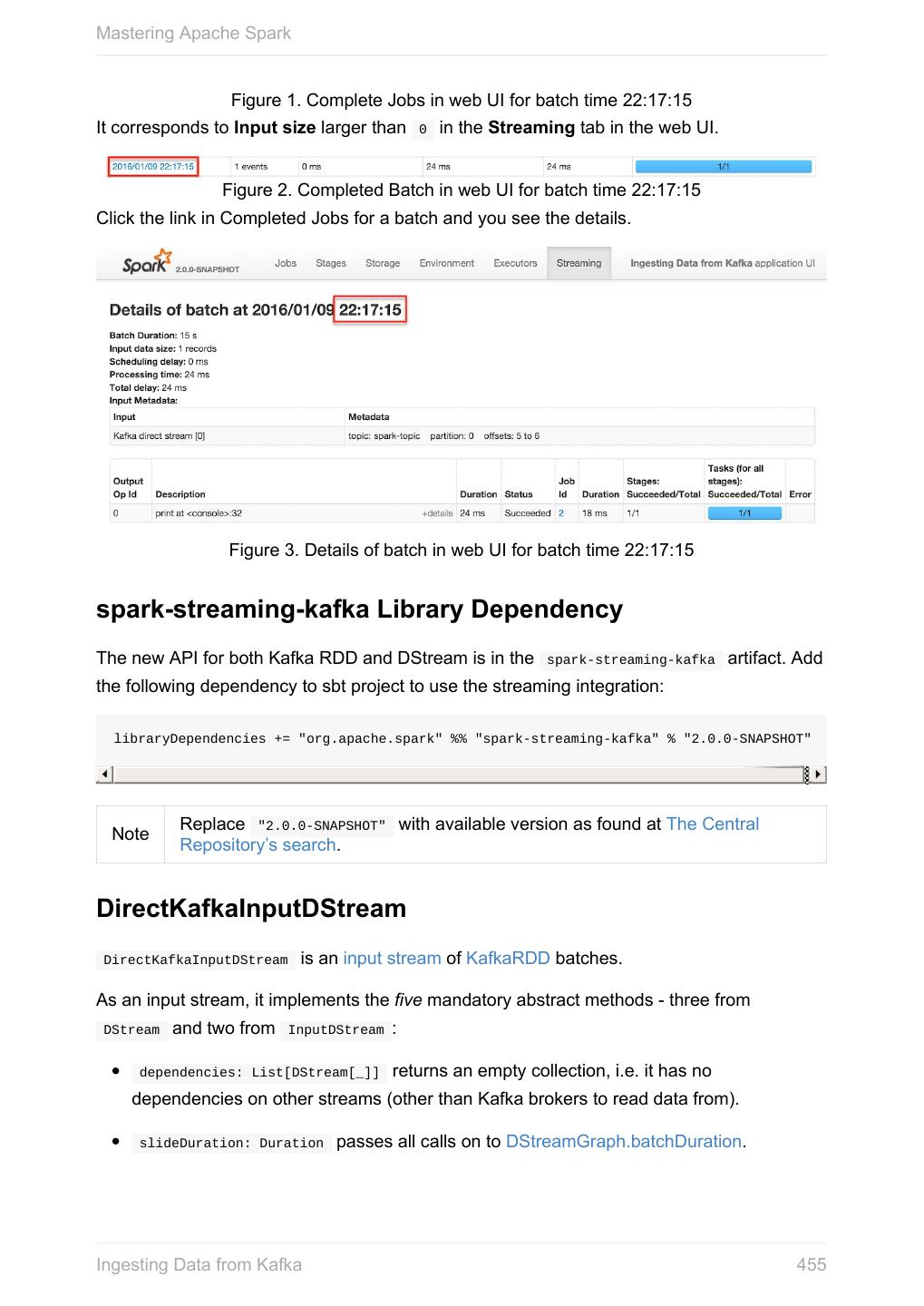
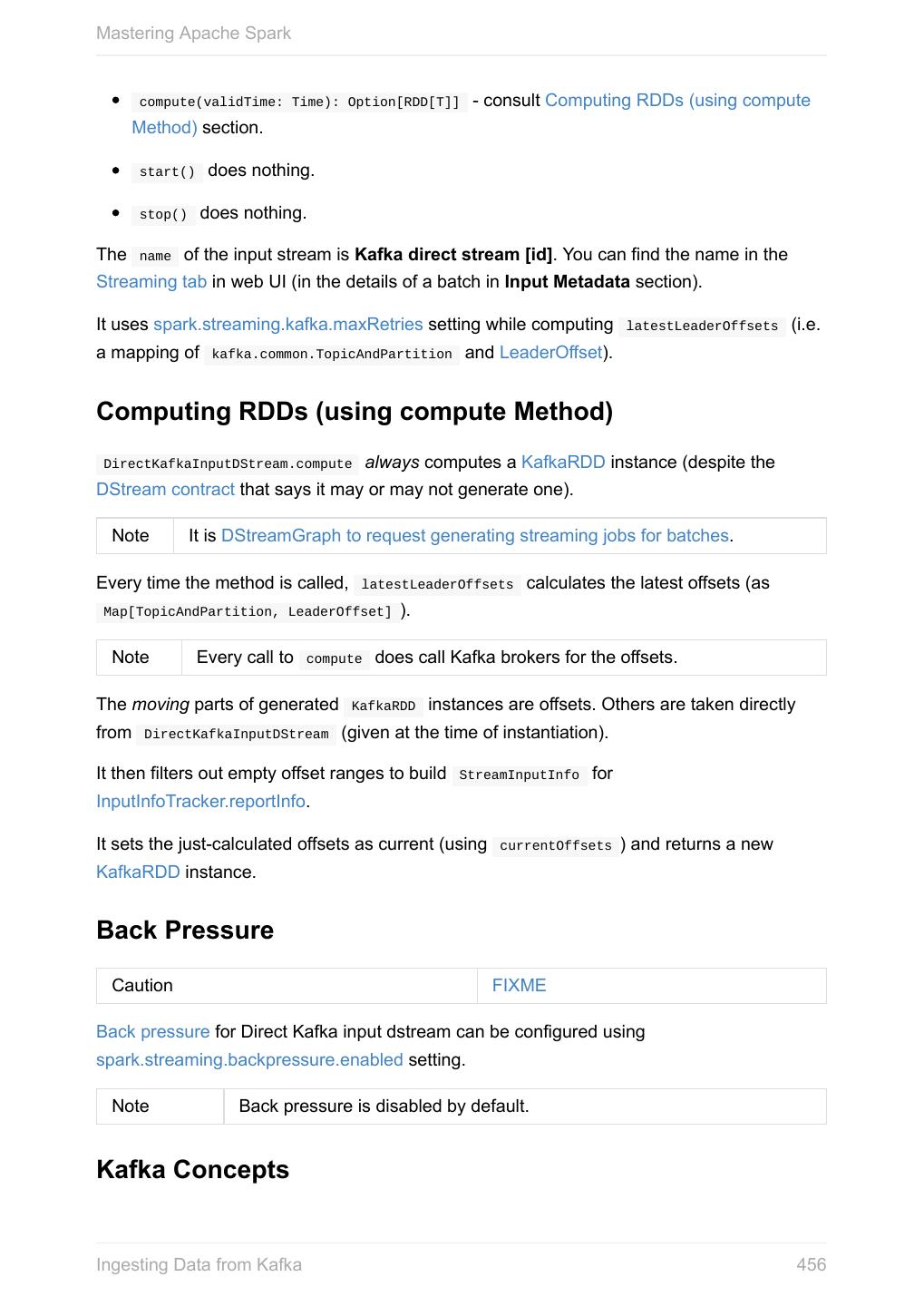


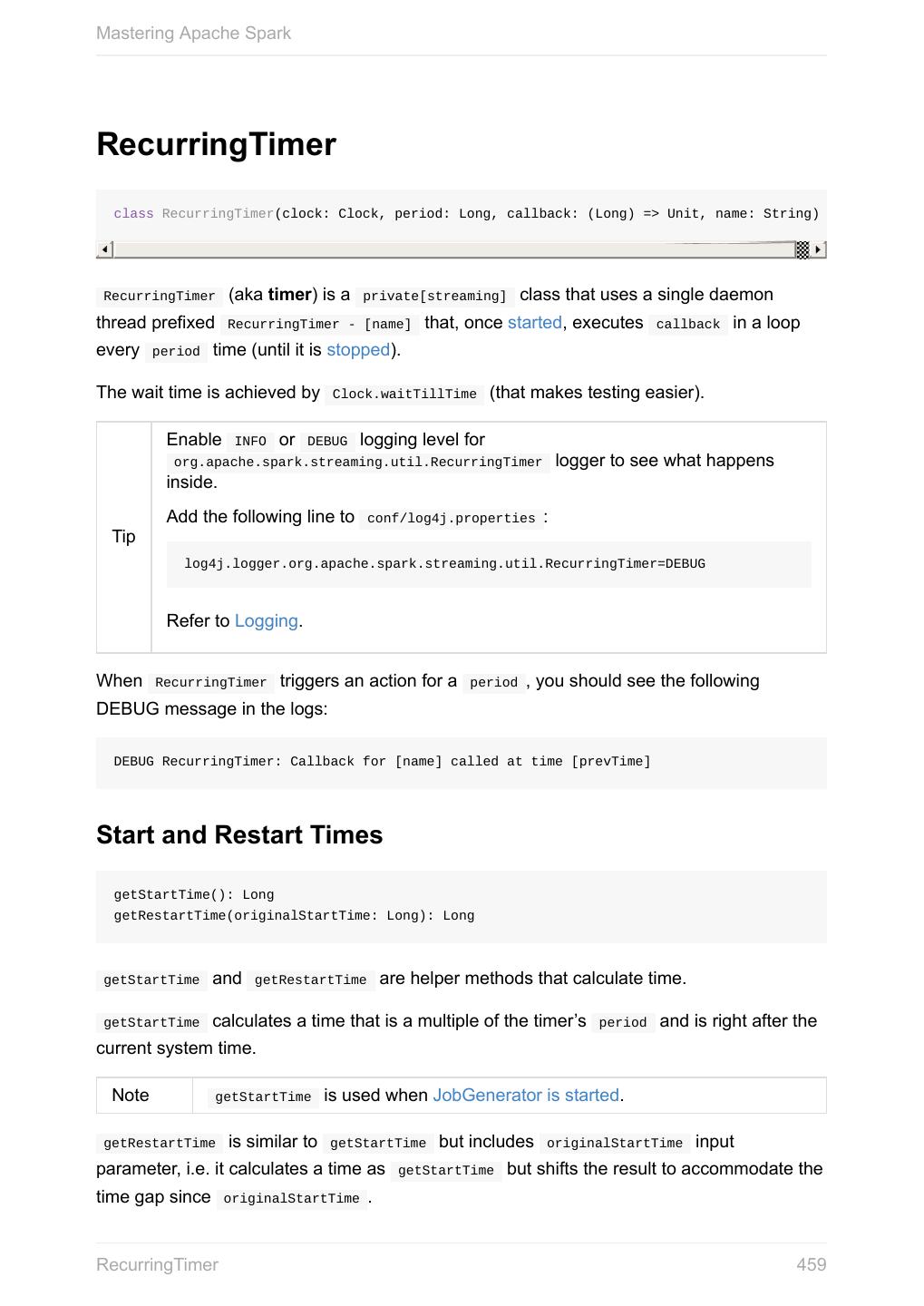
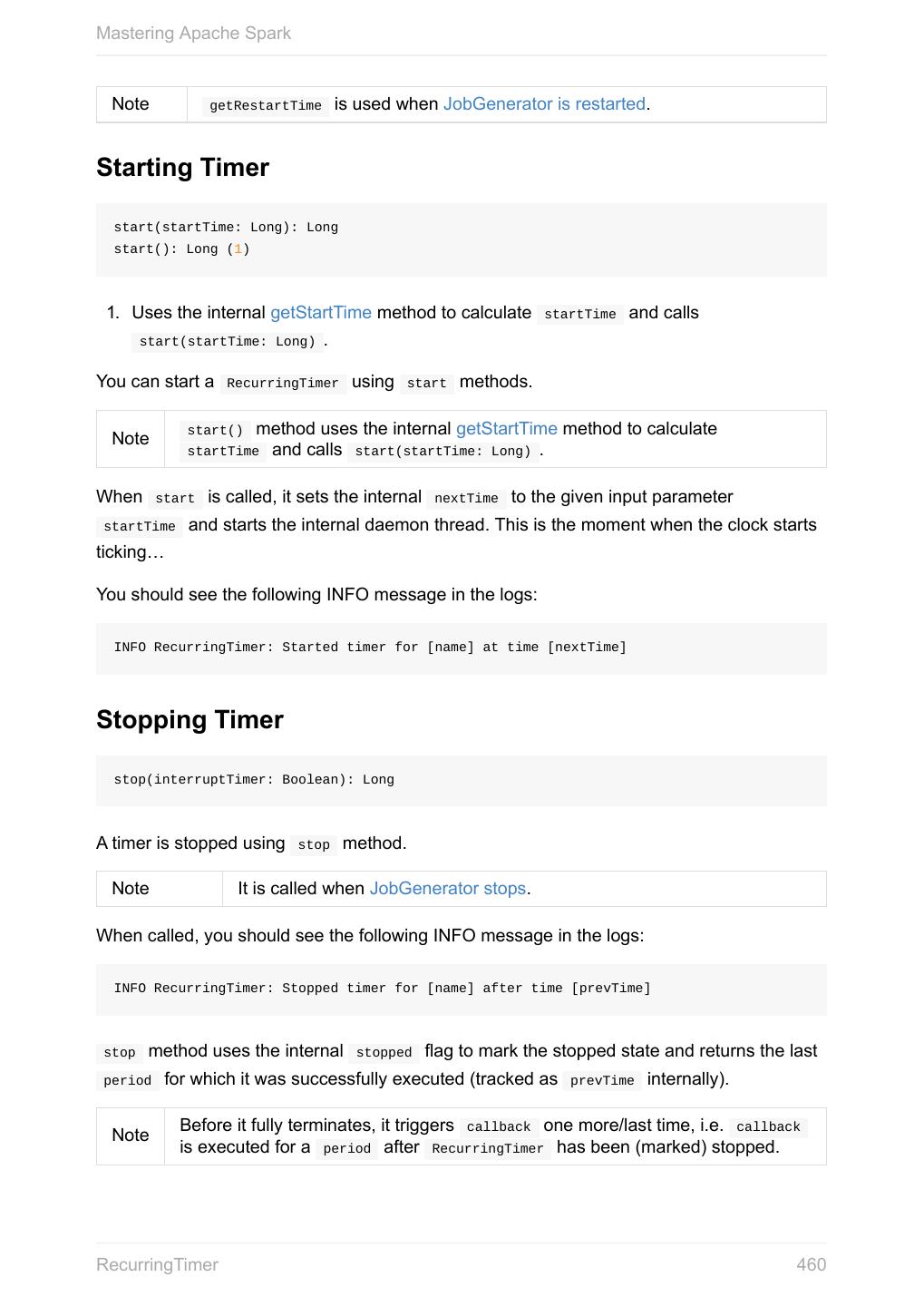
















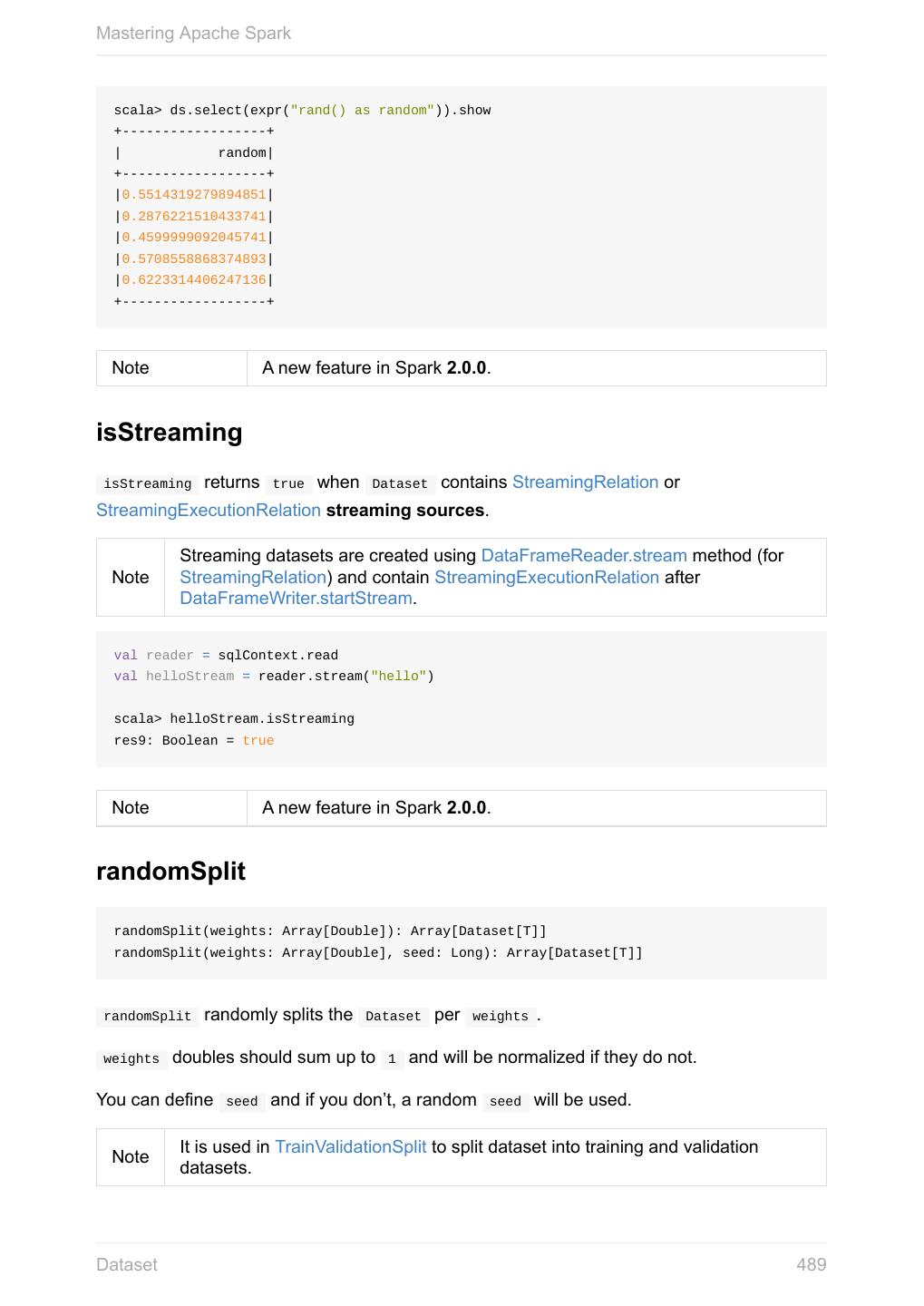
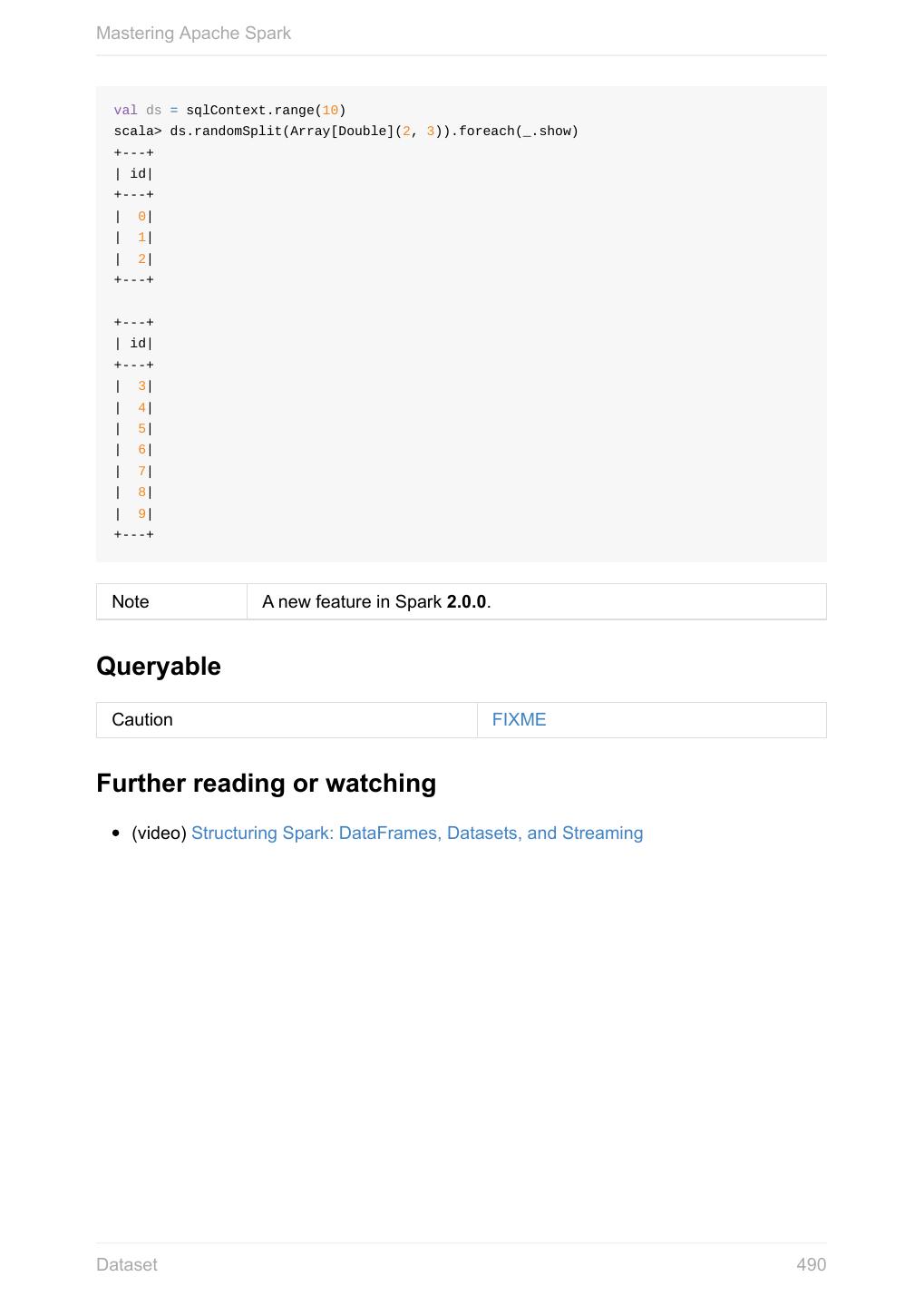
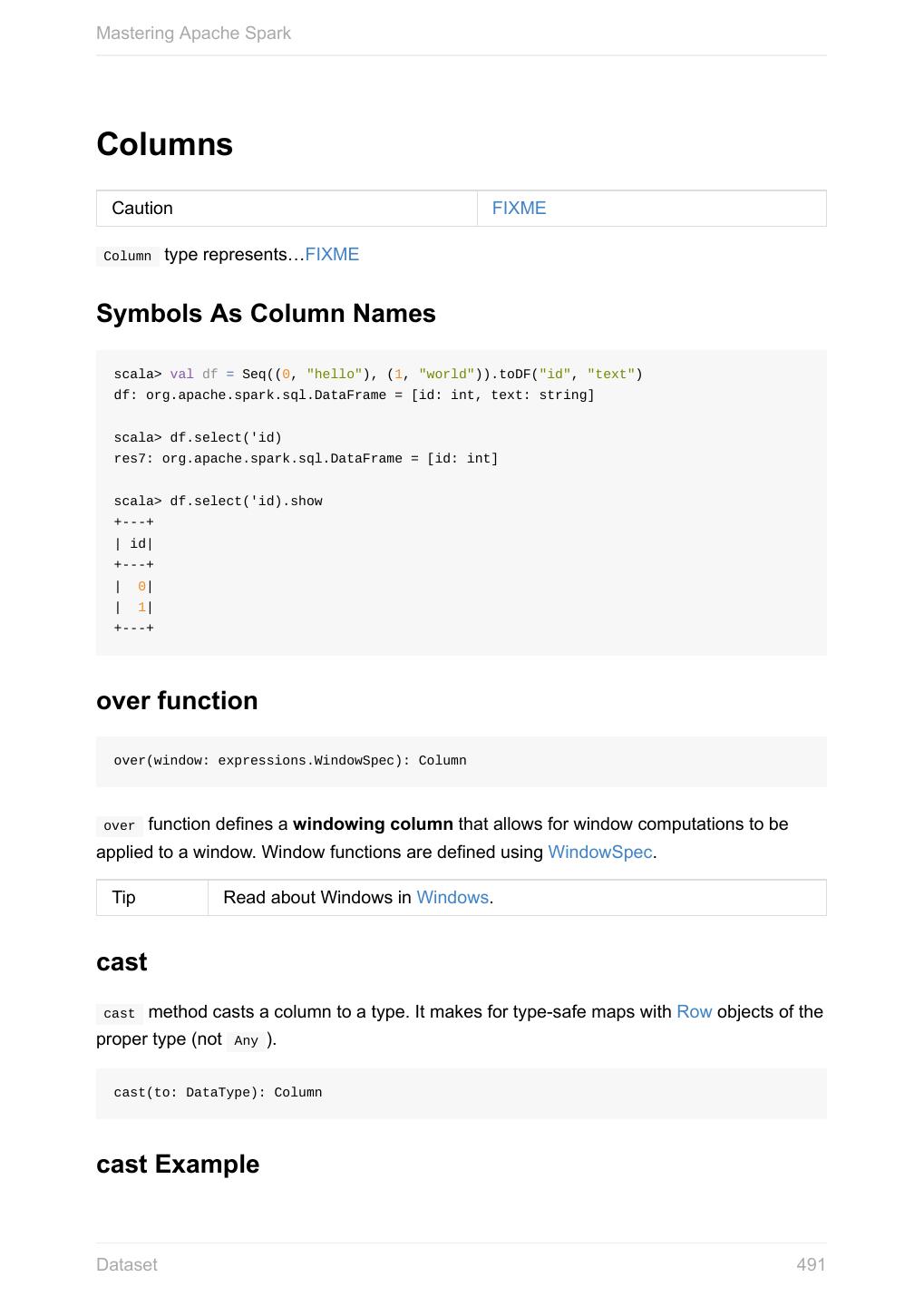
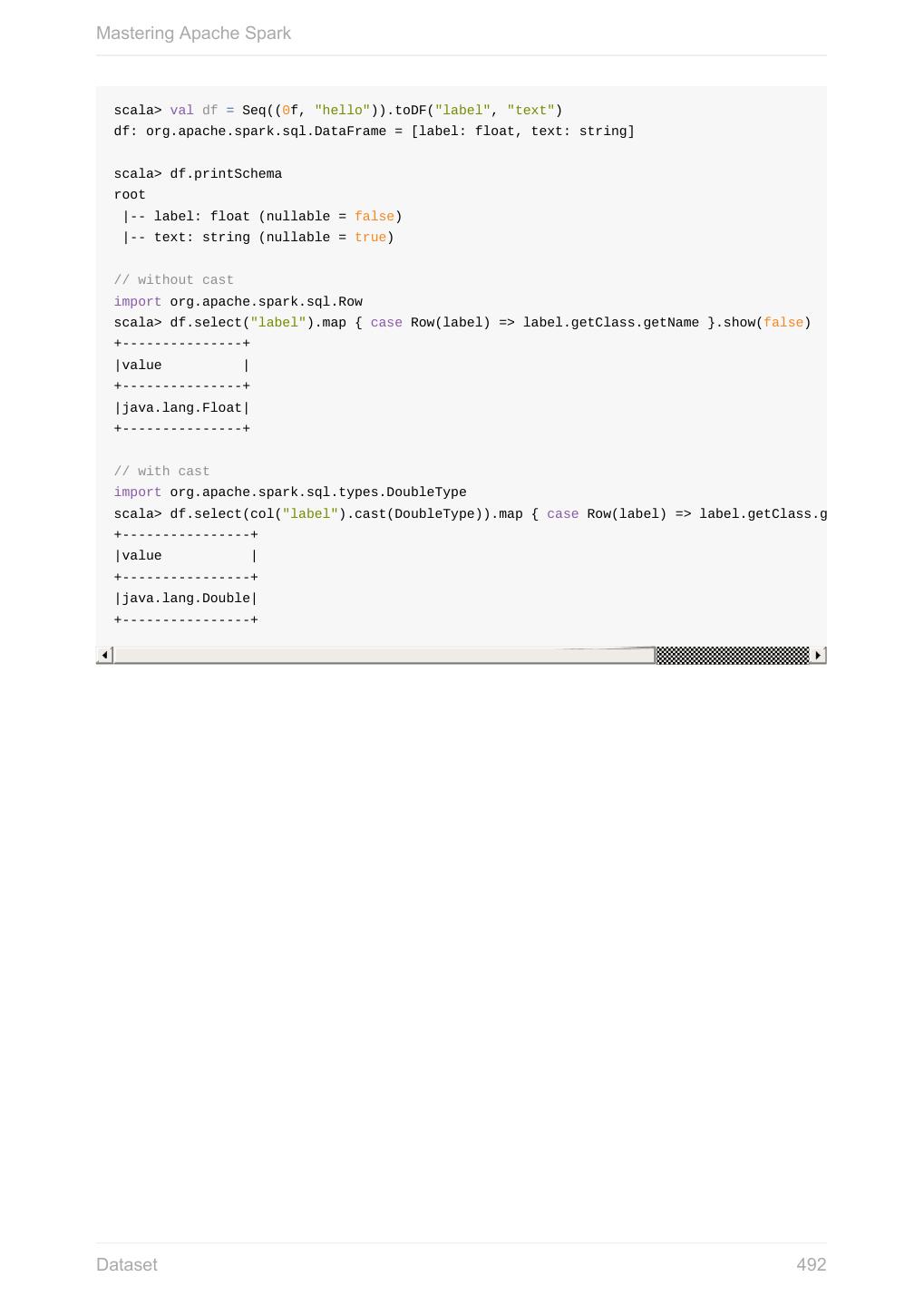









































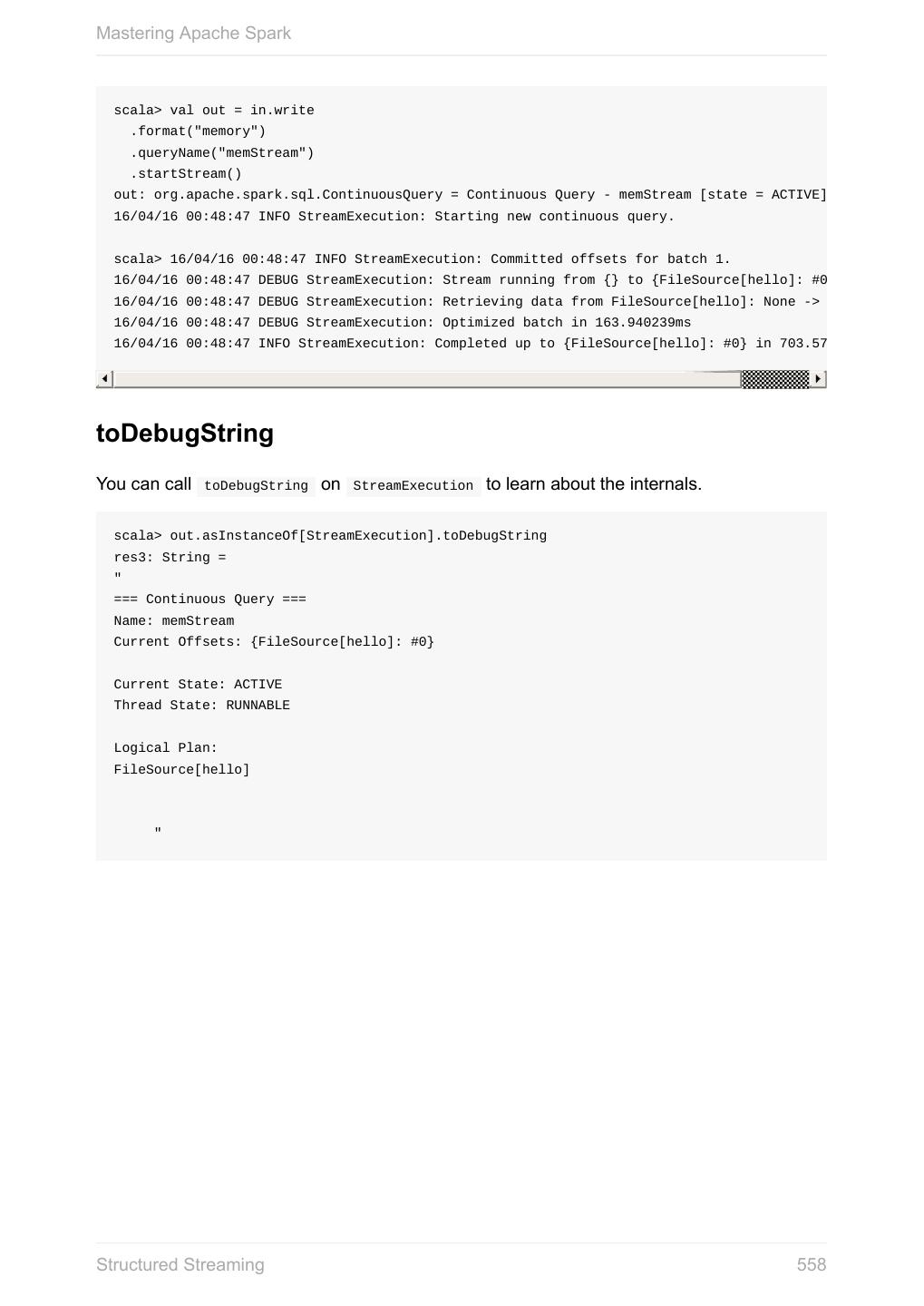



























































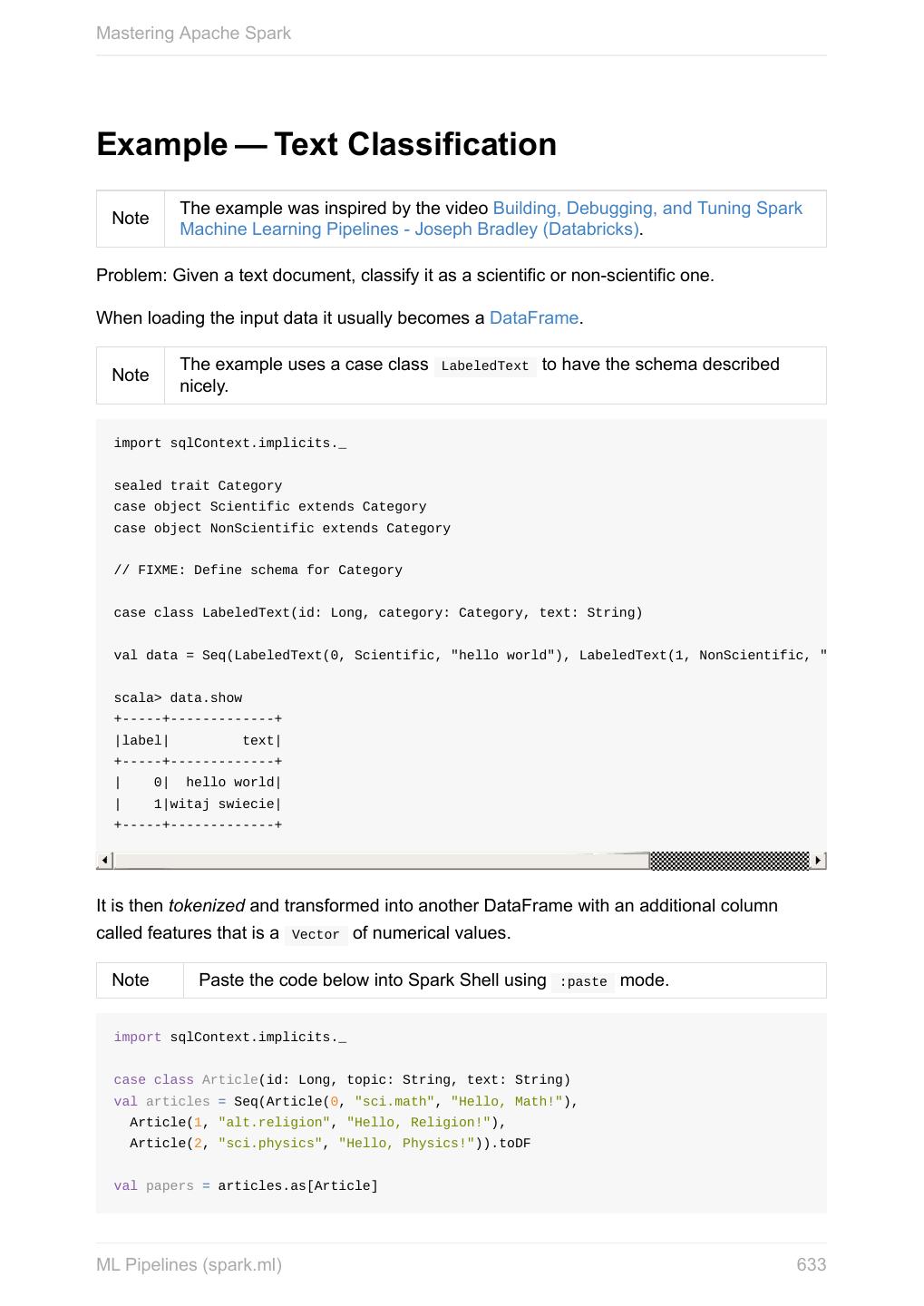






























































- 快召唤伙伴们来围观吧
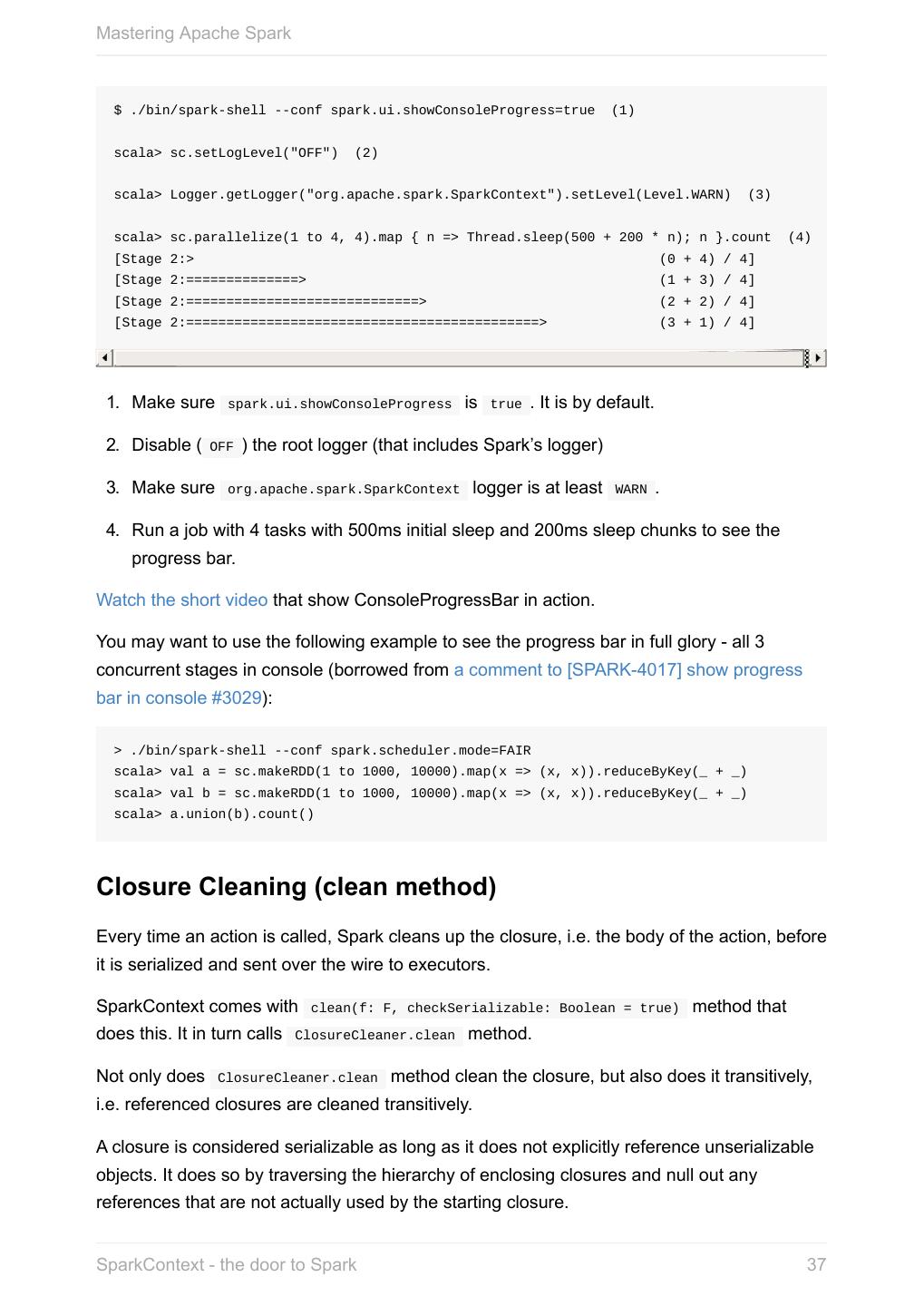
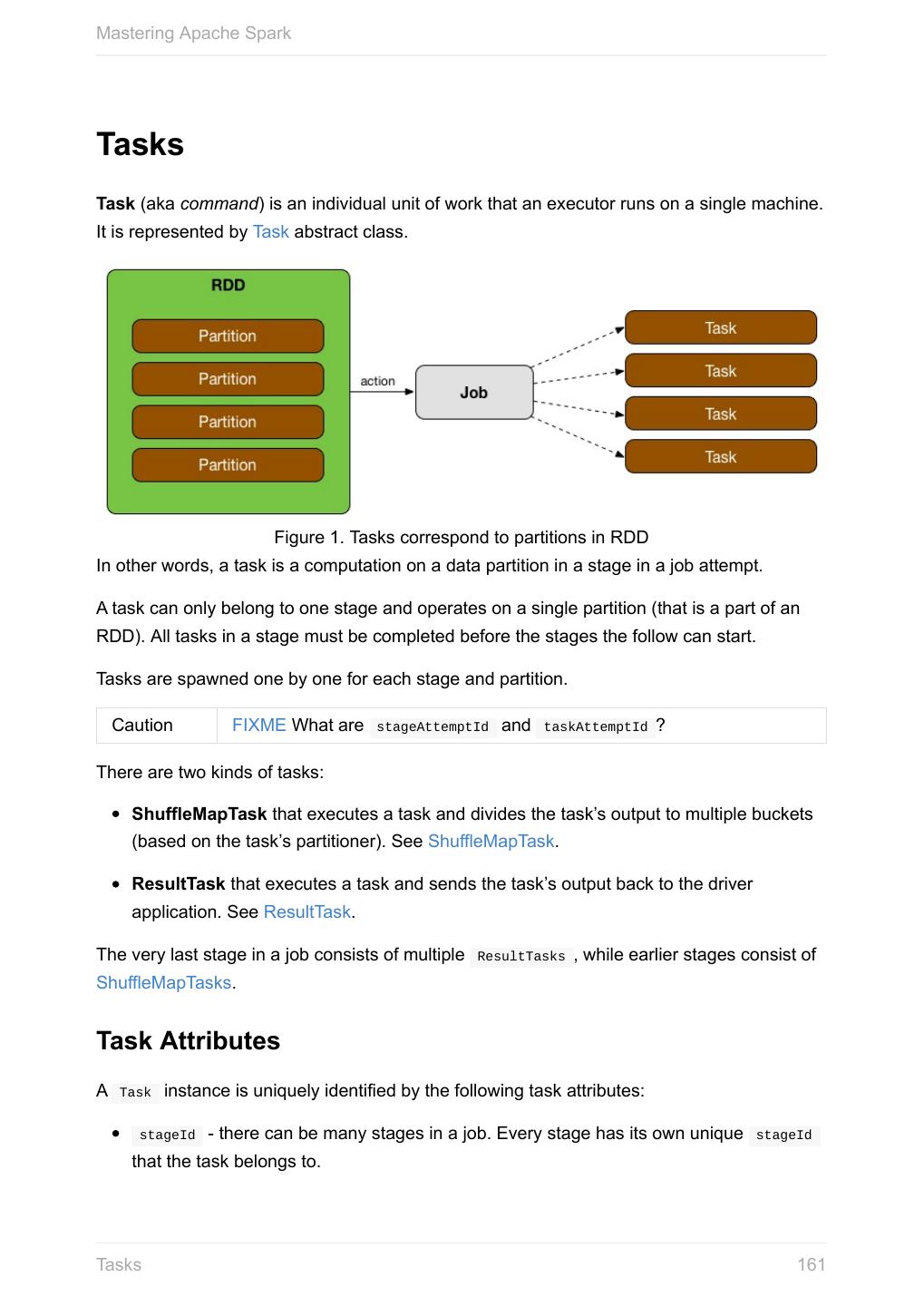
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
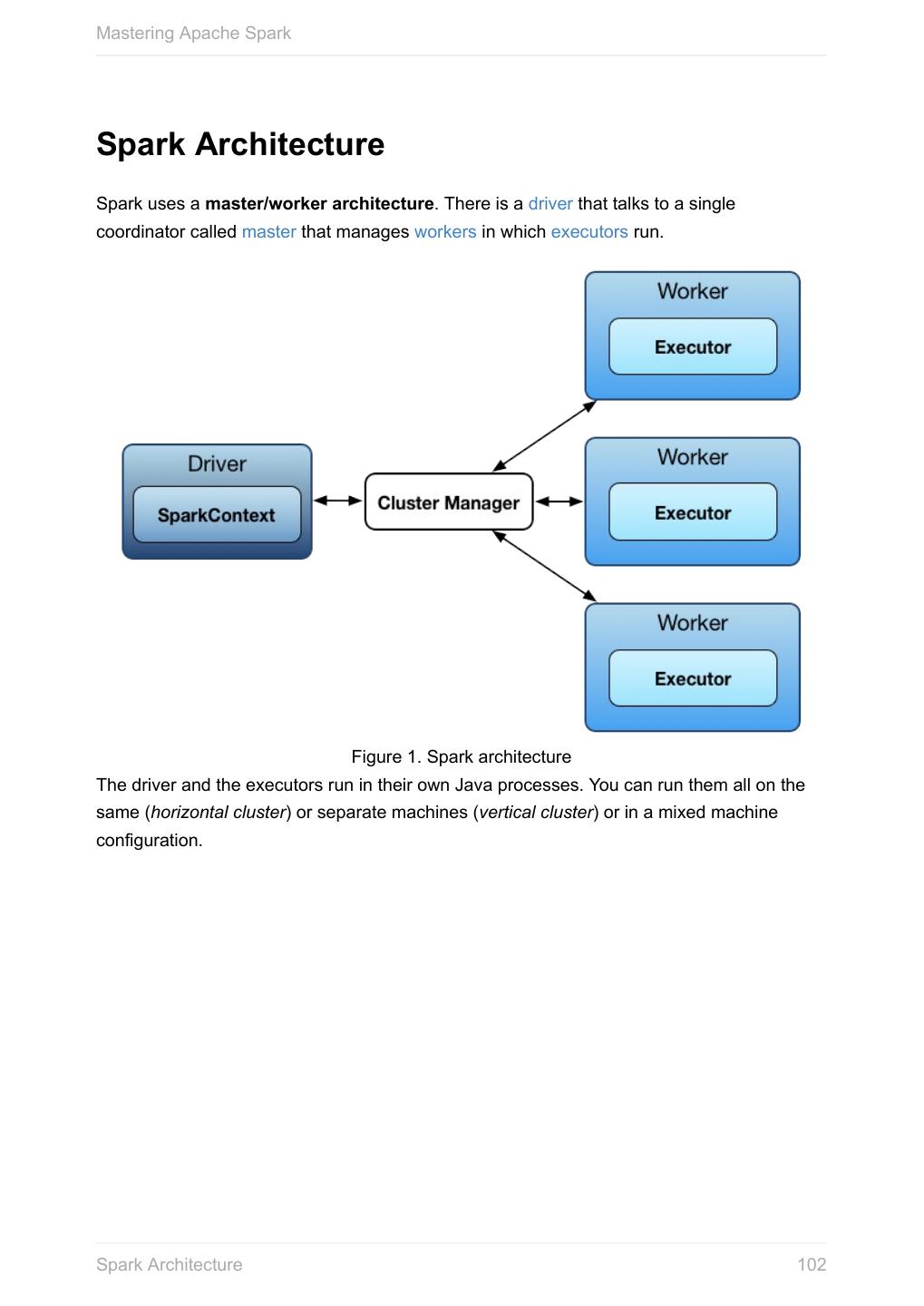
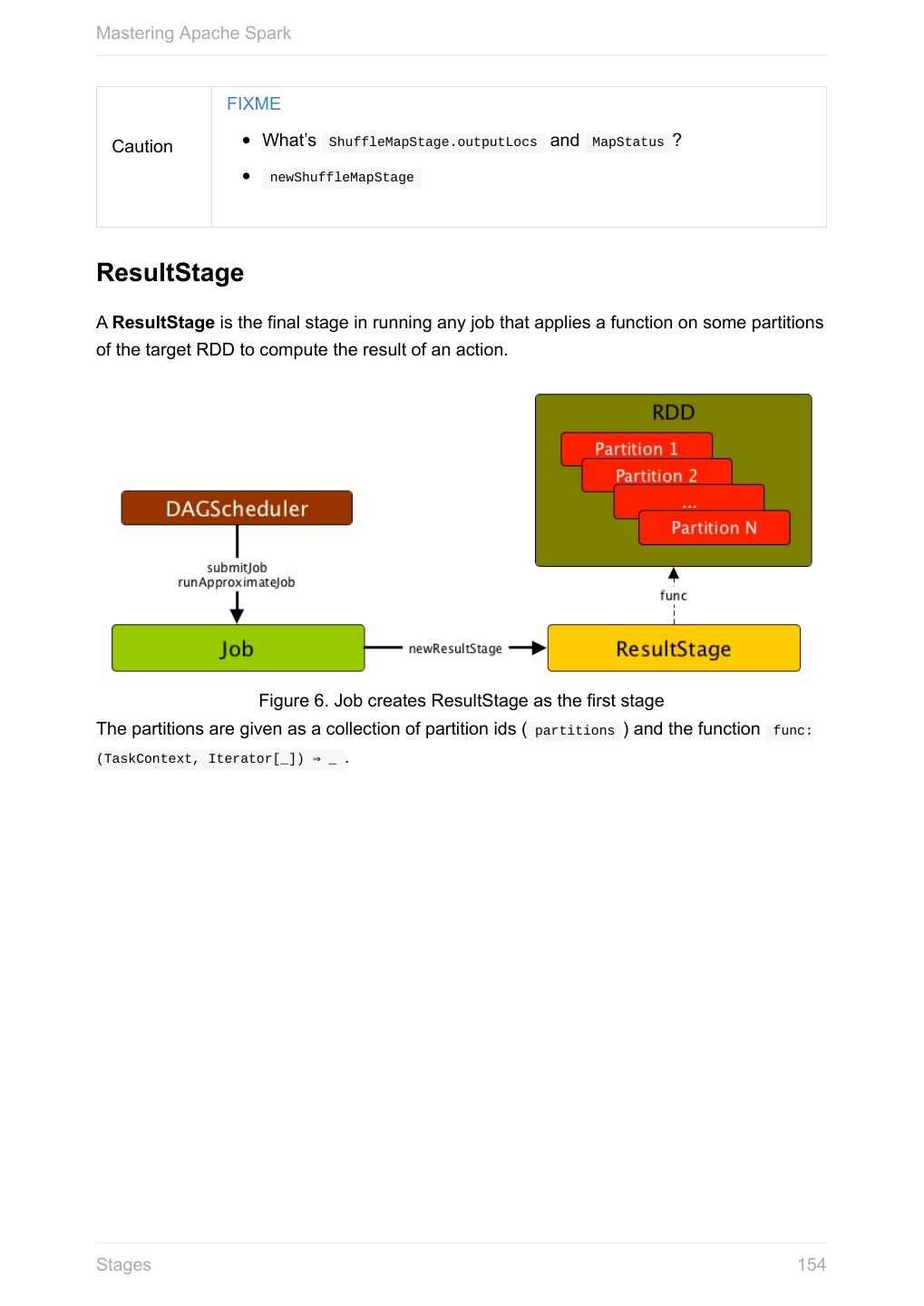
Mastering Apache Spark
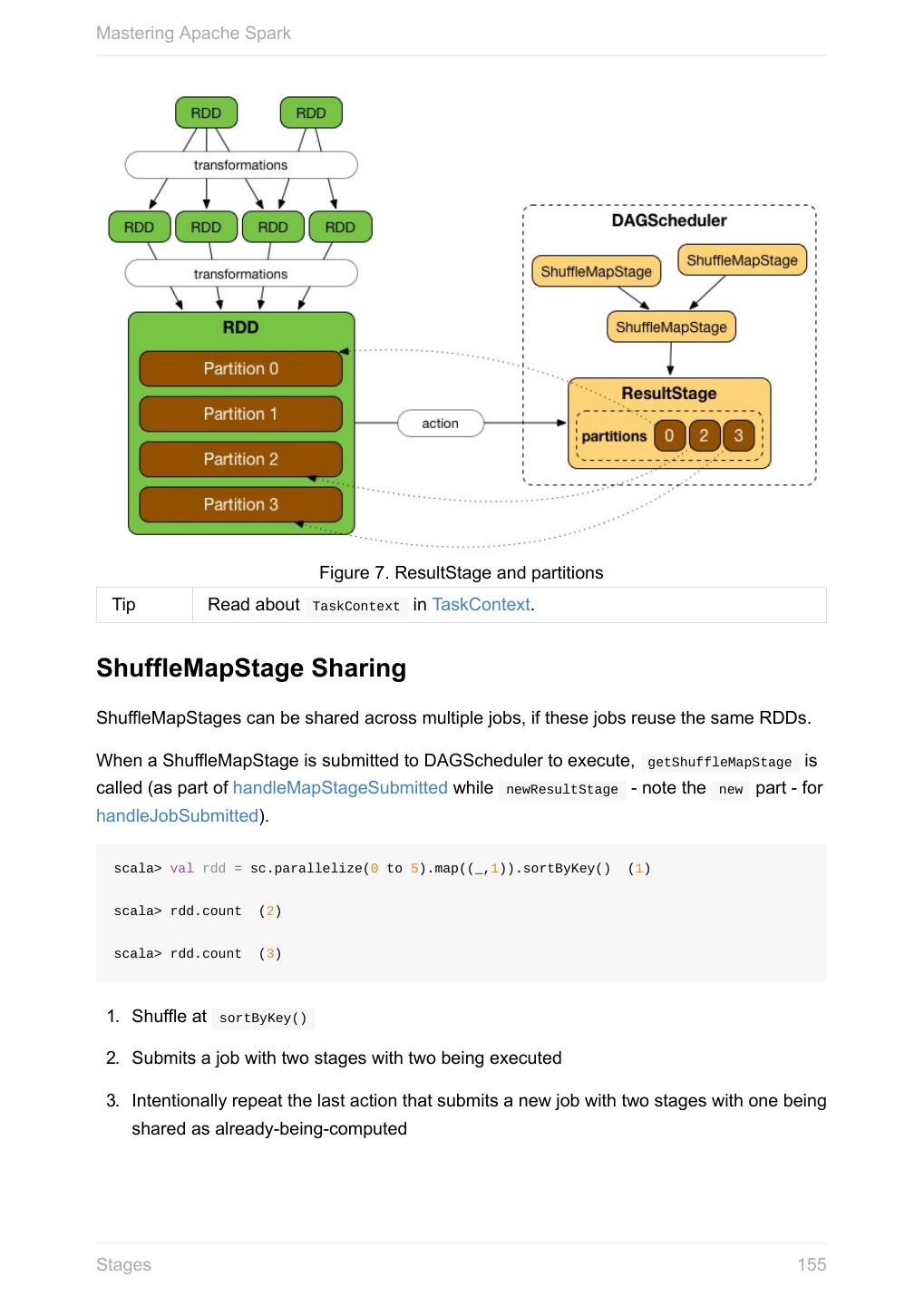
掌握Apache Spark的电子书
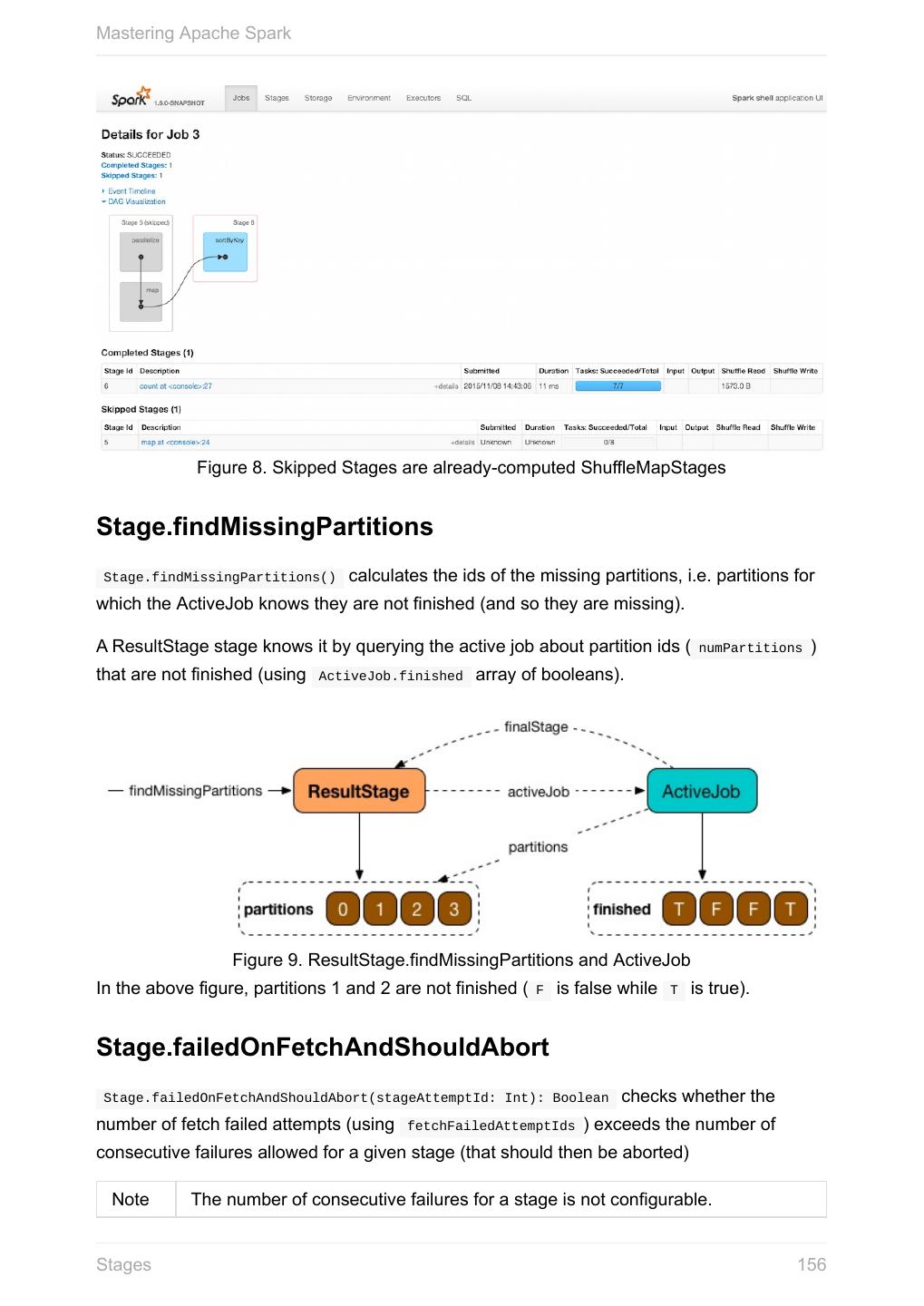
展开查看详情
1 .
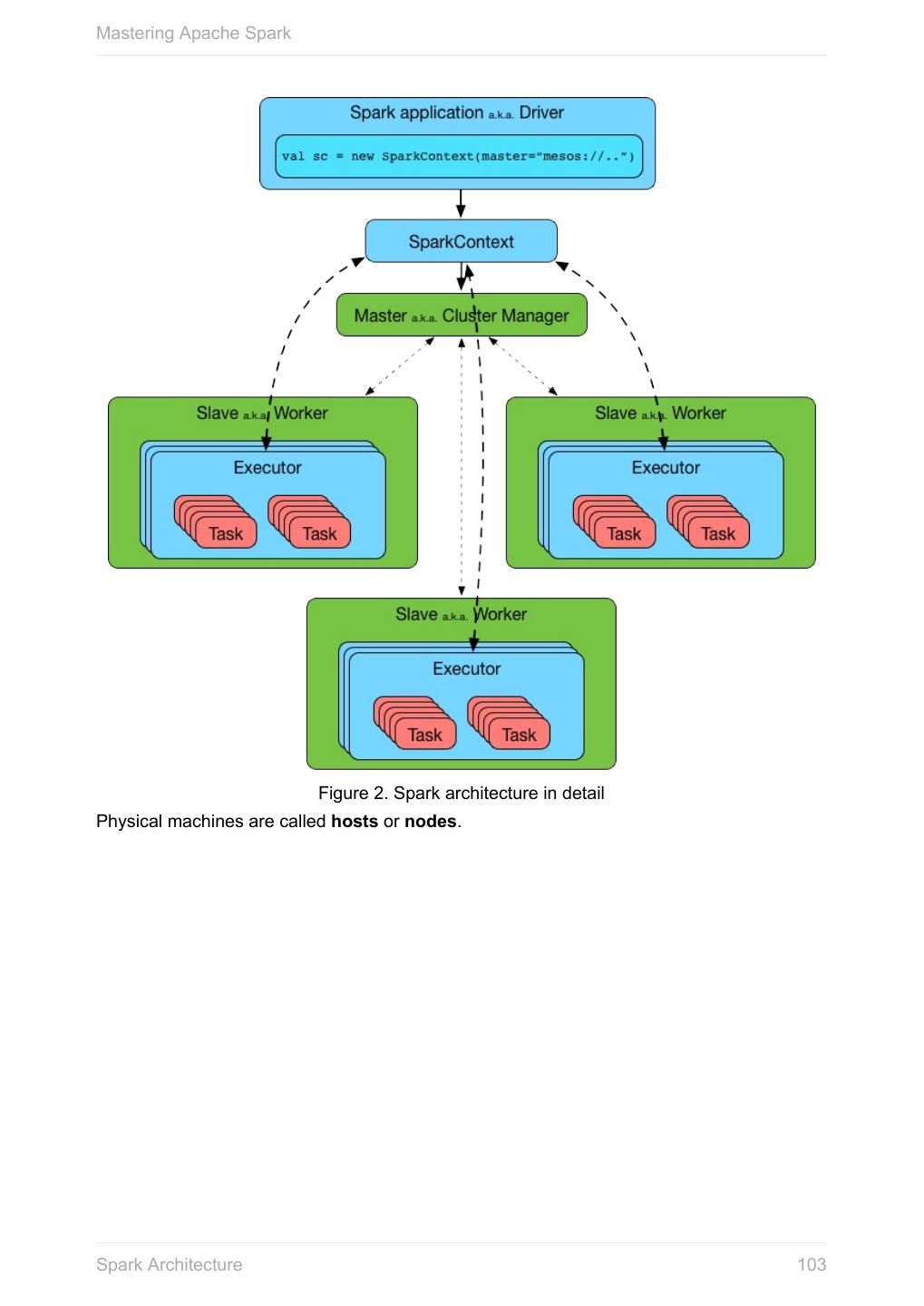
2 .Mastering Apache Spark Table of Contents Introduction 0 Overview of Spark 1 Anatomy of Spark Application 2 SparkConf - Configuration for Spark Applications 2.1 SparkContext - the door to Spark 2.2 RDD - Resilient Distributed Dataset 2.3 Operators 2.3.1 Transformations 2.3.1.1 Actions 2.3.1.2 Partitions and Partitioning 2.3.2 Shuffling 2.3.3 Checkpointing 2.3.4 Dependencies 2.3.5 Types of RDDs 2.3.6 ParallelCollectionRDD 2.3.6.1 MapPartitionsRDD 2.3.6.2 PairRDDFunctions 2.3.6.3 CoGroupedRDD 2.3.6.4 HadoopRDD 2.3.6.5 ShuffledRDD 2.3.6.6 BlockRDD 2.3.6.7 Spark Tools 3 Spark Shell 3.1 WebUI - UI for Spark Monitoring 3.2 Executors Tab 3.2.1 spark-submit 3.3 spark-class 3.4 Spark Architecture 4 Driver 4.1 Master 4.2 2
3 .Mastering Apache Spark Workers 4.3 Executors 4.4 Spark Runtime Environment 5 DAGScheduler 5.1 Jobs 5.1.1 Stages 5.1.2 Task Scheduler 5.2 Tasks 5.2.1 TaskSets 5.2.2 TaskSetManager 5.2.3 TaskSchedulerImpl - Default TaskScheduler 5.2.3.1 TaskContext 5.2.4 TaskMetrics 5.2.5 SchedulableBuilders 5.2.6 Scheduler Backend 5.3 CoarseGrainedSchedulerBackend 5.3.1 Executor Backend 5.4 CoarseGrainedExecutorBackend 5.4.1 Shuffle Manager 5.5 Block Manager 5.6 HTTP File Server 5.7 Broadcast Manager 5.8 Dynamic Allocation 5.9 Data Locality 5.10 Cache Manager 5.11 Spark, Akka and Netty 5.12 OutputCommitCoordinator 5.13 RPC Environment (RpcEnv) 5.14 Netty-based RpcEnv 5.14.1 ContextCleaner 5.15 MapOutputTracker 5.16 ExecutorAllocationManager 5.17 Deployment Environments 6 Spark local 6.1 3
4 .Mastering Apache Spark Spark on cluster 6.2 Spark Standalone 6.2.1 Standalone Master 6.2.1.1 Standalone Worker 6.2.1.2 web UI 6.2.1.3 Submission Gateways 6.2.1.4 Management Scripts for Standalone Master 6.2.1.5 Management Scripts for Standalone Workers 6.2.1.6 Checking Status 6.2.1.7 Example 2-workers-on-1-node Standalone Cluster (one executor per worker) 6.2.1.8 Spark on Mesos 6.2.2 Spark on YARN 6.2.3 Client 6.2.3.1 YarnRMClient 6.2.3.2 ApplicationMaster 6.2.3.3 Client Deploy Mode and YarnClientSchedulerBackend 6.2.3.4 Cluster Deploy Mode and YarnClusterSchedulerBackend 6.2.3.5 Introduction to Hadoop YARN 6.2.3.6 Setting up YARN Cluster 6.2.3.7 Settings 6.2.3.8 Execution Model 7 Optimising Spark 8 Caching and Persistence 8.1 Broadcast variables 8.2 Accumulators 8.3 Security 9 Spark Security 9.1 Securing Web UI 9.2 Data Sources in Spark 10 Using Input and Output (I/O) 10.1 Spark and Parquet 10.1.1 Serialization 10.1.2 Using Apache Cassandra 10.2 4
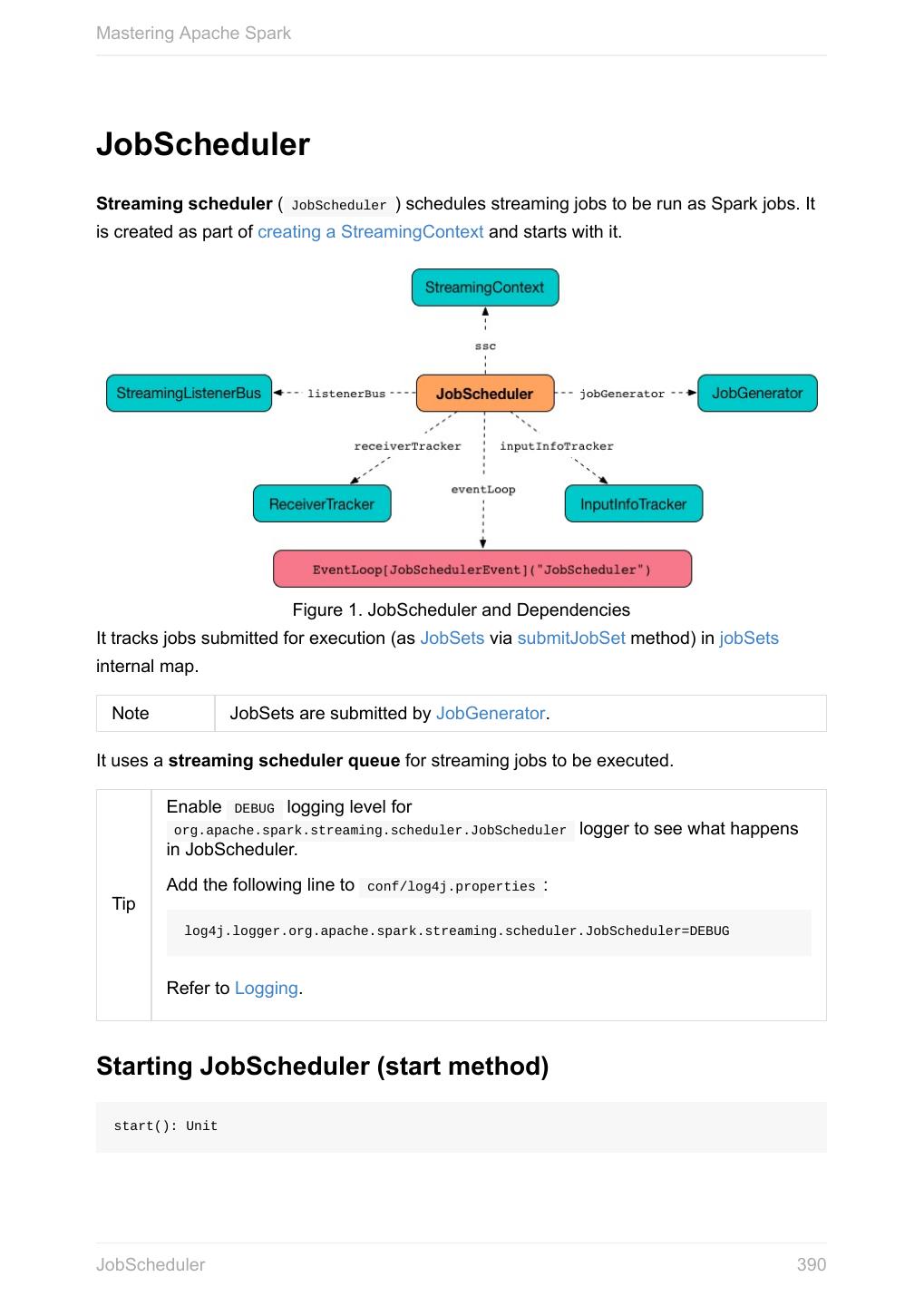
5 .Mastering Apache Spark Using Apache Kafka 10.3 Spark Application Frameworks 11 Spark Streaming 11.1 StreamingContext 11.1.1 Stream Operators 11.1.2 Windowed Operators 11.1.2.1 SaveAs Operators 11.1.2.2 Stateful Operators 11.1.2.3 web UI and Streaming Statistics Page 11.1.3 Streaming Listeners 11.1.4 Checkpointing 11.1.5 JobScheduler 11.1.6 JobGenerator 11.1.7 DStreamGraph 11.1.8 Discretized Streams (DStreams) 11.1.9 Input DStreams 11.1.9.1 ReceiverInputDStreams 11.1.9.2 ConstantInputDStreams 11.1.9.3 ForEachDStreams 11.1.9.4 WindowedDStreams 11.1.9.5 MapWithStateDStreams 11.1.9.6 StateDStreams 11.1.9.7 TransformedDStream 11.1.9.8 Receivers 11.1.10 ReceiverTracker 11.1.10.1 ReceiverSupervisors 11.1.10.2 ReceivedBlockHandlers 11.1.10.3 Ingesting Data from Kafka 11.1.11 KafkaRDD 11.1.11.1 RecurringTimer 11.1.12 Backpressure 11.1.13 Dynamic Allocation (Elastic Scaling) 11.1.14 Settings 11.1.15 5
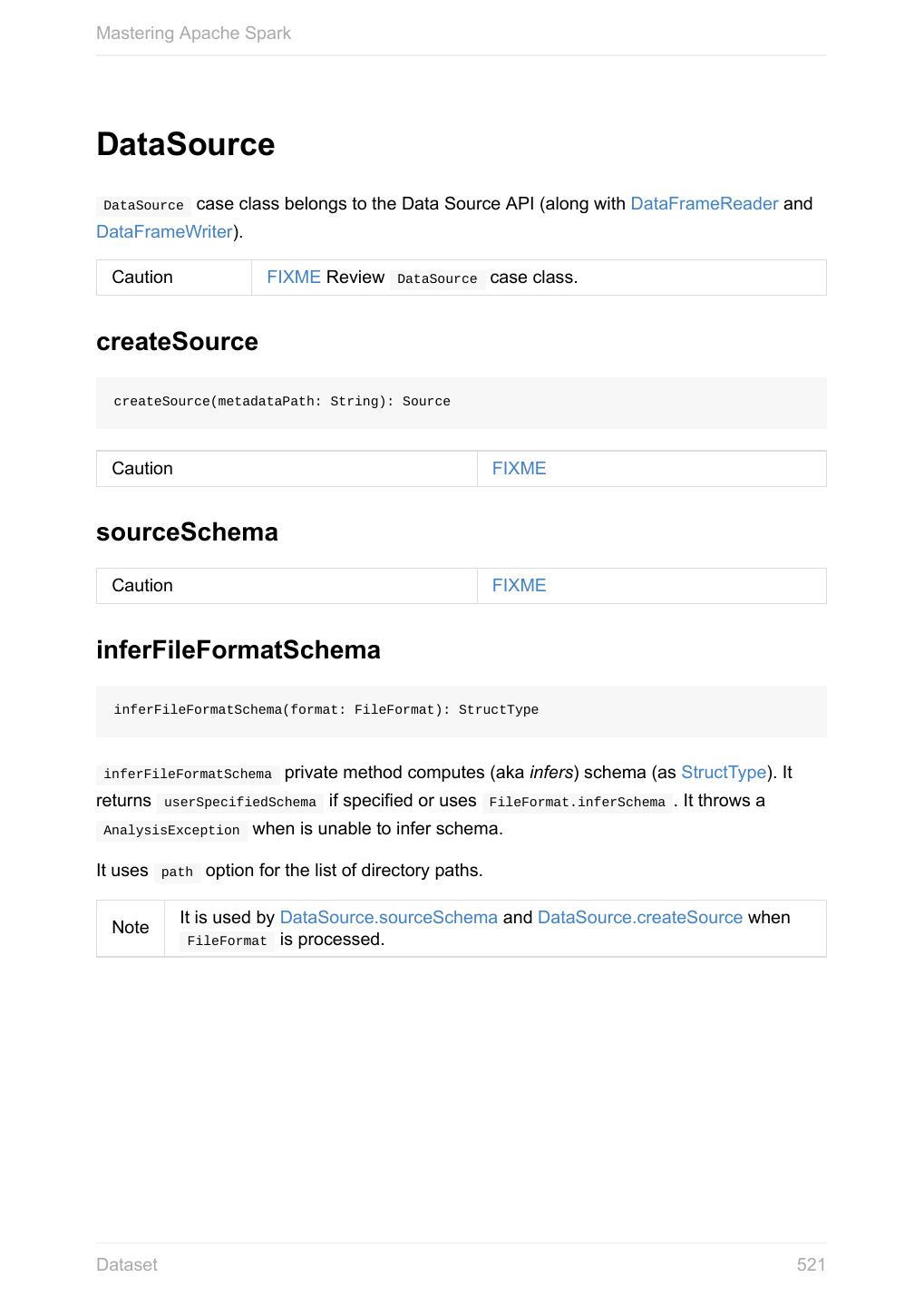
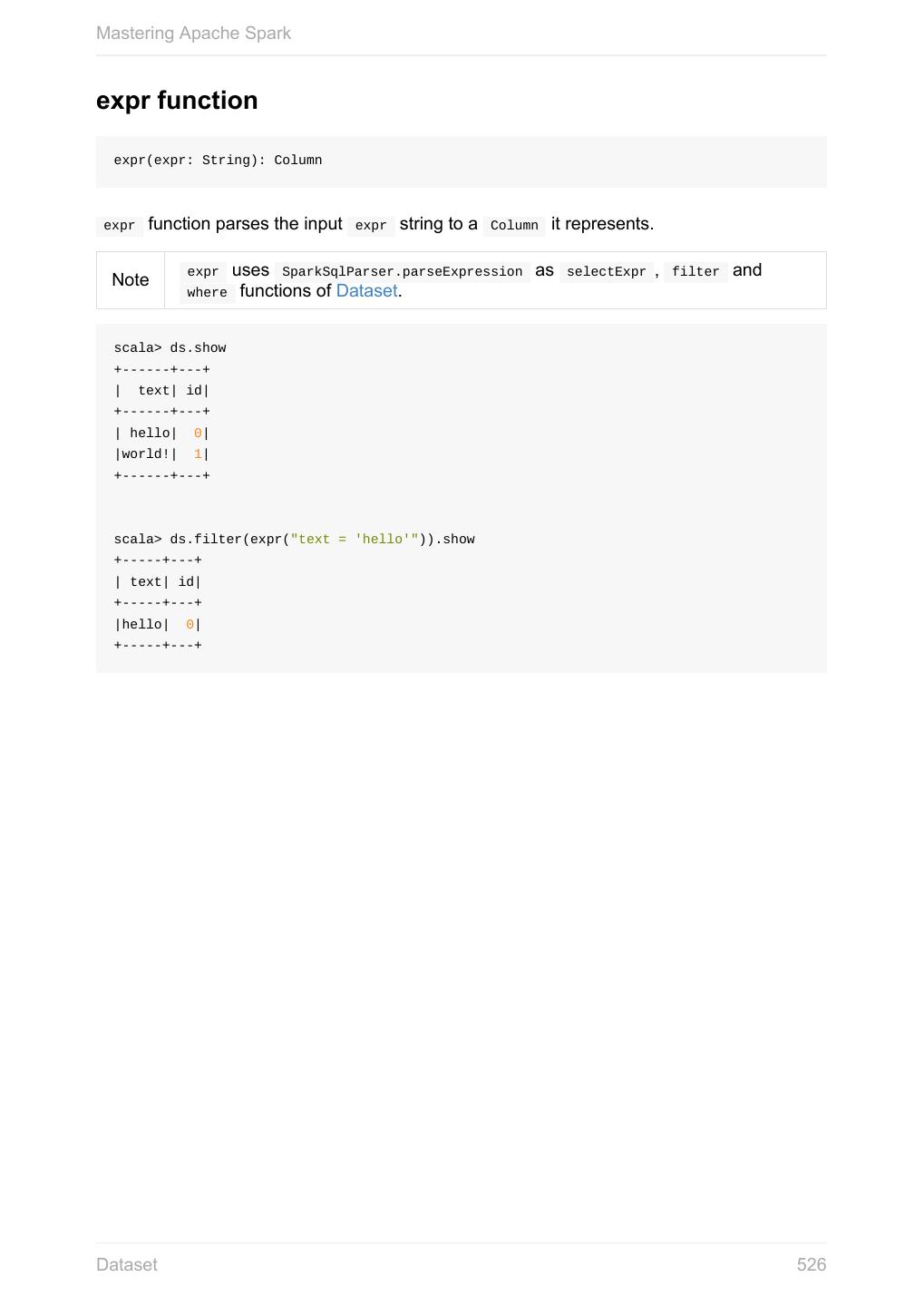
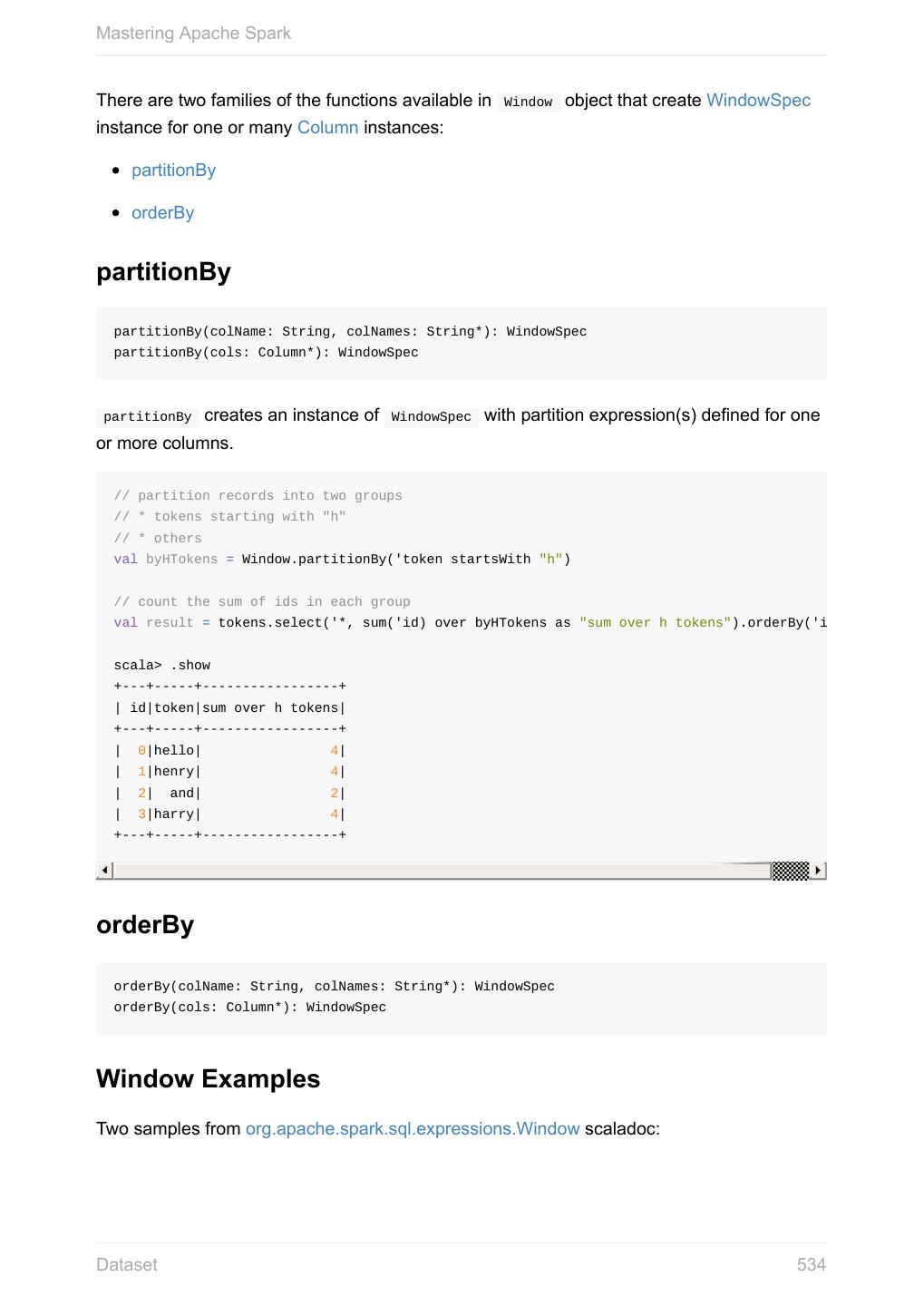
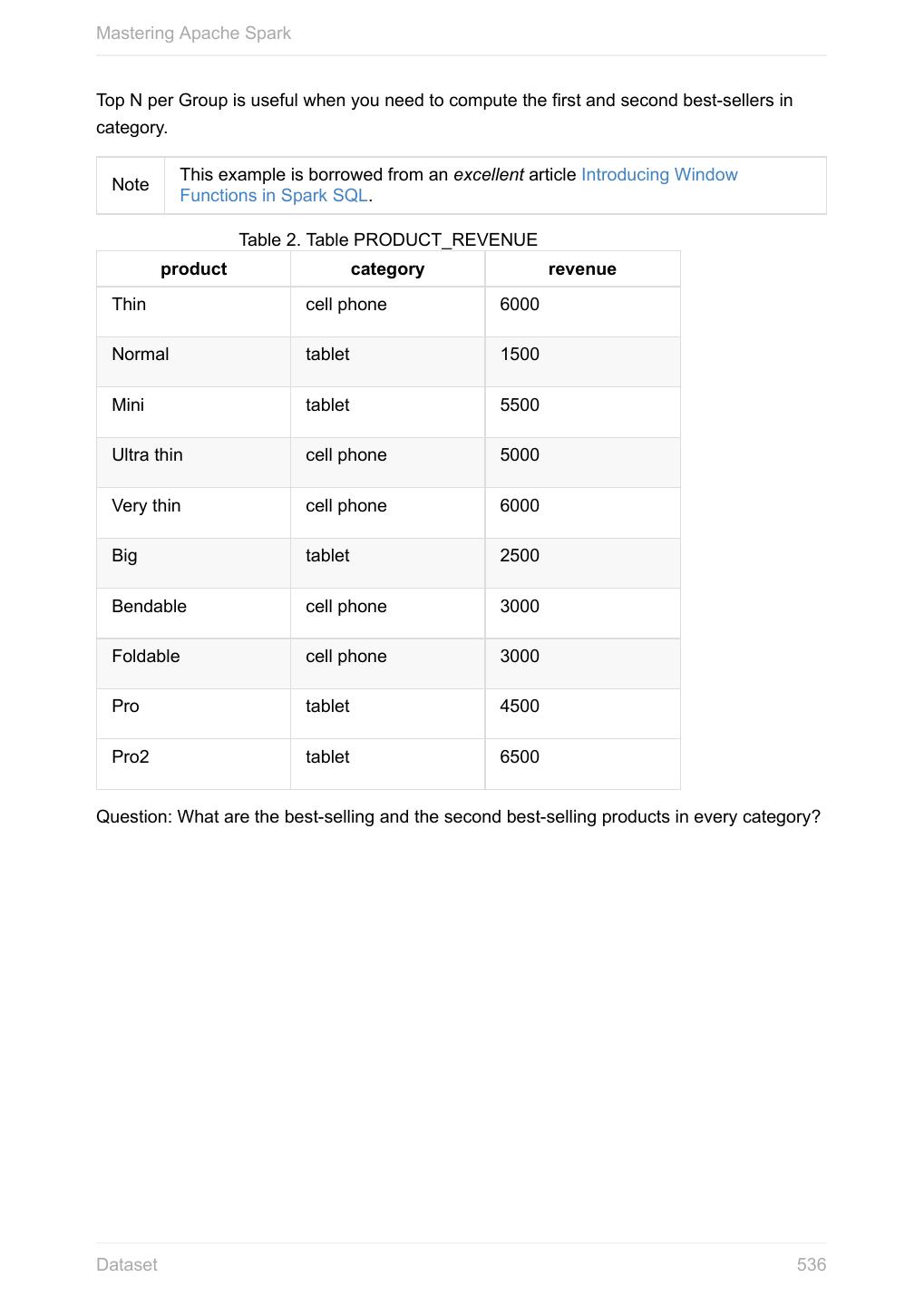
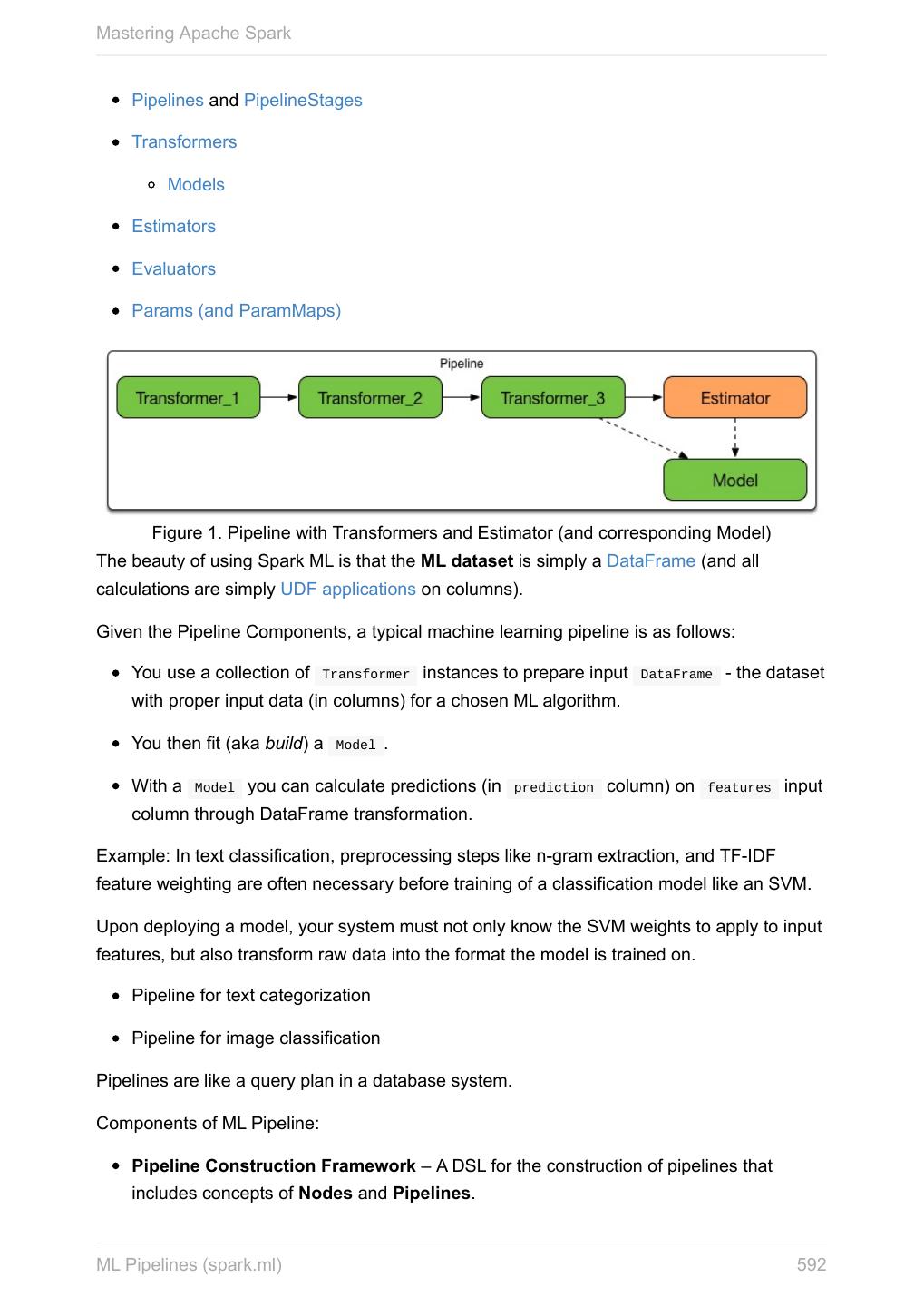
6 .Mastering Apache Spark Spark SQL 11.2 SQLContext - The Entry Point 11.2.1 Dataset 11.2.2 Columns 11.2.2.1 Schema 11.2.2.2 DataFrame (Dataset[Row]) 11.2.2.3 Row 11.2.2.4 Data Source API - Loading and Saving Datasets 11.2.3 DataFrameReader 11.2.3.1 DataFrameWriter 11.2.3.2 DataSource 11.2.3.3 Functions - Computations on Rows 11.2.4 Standard Functions (functions object) 11.2.4.1 Aggregation (GroupedData) 11.2.4.2 User-Defined Functions (UDFs) 11.2.4.3 Window Aggregates (Windows) 11.2.4.4 Structured Streaming 11.2.5 Source 11.2.5.1 Sink 11.2.5.2 ContinuousQueryManager 11.2.5.3 ContinuousQuery 11.2.5.4 Trigger 11.2.5.5 StreamExecution 11.2.5.6 StreamingRelation 11.2.5.7 Joins 11.2.6 Hive Integration 11.2.7 Spark SQL CLI - spark-sql 11.2.7.1 SQL Parsers 11.2.8 Caching 11.2.9 Datasets vs RDDs 11.2.10 SessionState 11.2.11 Performance Optimizations 11.2.12 Catalyst Query Optimizer 11.2.12.1 Predicate Pushdown 11.2.12.1.1 6
7 .Mastering Apache Spark QueryPlan 11.2.12.1.2 SparkPlan 11.2.12.1.3 LogicalPlan 11.2.12.1.4 QueryPlanner 11.2.12.1.5 QueryExecution 11.2.12.1.6 Whole Stage Codegen 11.2.12.1.7 Project Tungsten 11.2.12.2 Settings 11.2.13 Spark MLlib - Machine Learning in Spark 11.3 ML Pipelines (spark.ml) 11.3.1 Transformers 11.3.1.1 Estimators 11.3.1.2 Models 11.3.1.3 Evaluators 11.3.1.4 CrossValidator 11.3.1.5 Persistence (MLWriter and MLReader) 11.3.1.6 Example — Text Classification 11.3.1.7 Example — Linear Regression 11.3.1.8 Latent Dirichlet Allocation (LDA) 11.3.2 Vector 11.3.3 LabeledPoint 11.3.4 Streaming MLlib 11.3.5 Spark GraphX - Distributed Graph Computations 11.4 Graph Algorithms 11.4.1 Monitoring, Tuning and Debugging 12 Logging 12.1 Performance Tuning 12.2 Spark Metrics System 12.3 Scheduler Listeners 12.4 EventLoggingListener 12.4.1 Debugging Spark using sbt 12.5 Varia 13 Building Spark 13.1 7
8 .Mastering Apache Spark Spark and Hadoop 13.2 Spark and software in-memory file systems 13.3 Spark and The Others 13.4 Distributed Deep Learning on Spark 13.5 Spark Packages 13.6 Spark Tips and Tricks 14 Access private members in Scala in Spark shell 14.1 SparkException: Task not serializable 14.2 Running Spark on Windows 14.3 Exercises 15 One-liners using PairRDDFunctions 15.1 Learning Jobs and Partitions Using take Action 15.2 Spark Standalone - Using ZooKeeper for High-Availability of Master 15.3 Spark’s Hello World using Spark shell and Scala 15.4 WordCount using Spark shell 15.5 Your first complete Spark application (using Scala and sbt) 15.6 Spark (notable) use cases 15.7 Using Spark SQL to update data in Hive using ORC files 15.8 Developing Custom SparkListener to monitor DAGScheduler in Scala 15.9 Developing RPC Environment 15.10 Developing Custom RDD 15.11 Creating DataFrames from Tables using JDBC and PostgreSQL 15.12 Further Learning 16 Courses 16.1 Books 16.2 Commercial Products using Apache Spark 17 IBM Analytics for Apache Spark 17.1 Google Cloud Dataproc 17.2 Spark Advanced Workshop 18 Requirements 18.1 Day 1 18.2 Day 2 18.3 Spark Talks Ideas (STI) 19 10 Lesser-Known Tidbits about Spark Standalone 19.1 8
9 .Mastering Apache Spark Learning Spark internals using groupBy (to cause shuffle) 19.2 Glossary 9
10 .Mastering Apache Spark Mastering Apache Spark Welcome to Mastering Apache Spark (aka #SparkNotes)! I’m Jacek Laskowski, an independent consultant who offers development and training services for Apache Spark (and Scala, sbt with a bit of Apache Kafka, Apache Hive, Apache Mesos, Akka Actors/Stream/HTTP, and Docker). I run Warsaw Scala Enthusiasts and Warsaw Spark meetups. Contact me at jacek@japila.pl or @jaceklaskowski to discuss Spark opportunities, e.g. courses, workshops, or other mentoring or development services. If you like the notes you may consider participating in my own, very hands-on Spark and Scala Workshop. This collections of notes (what some may rashly call a "book") serves as the ultimate place of mine to collect all the nuts and bolts of using Apache Spark. The notes aim to help me designing and developing better products with Spark. It is also a viable proof of my understanding of Apache Spark. I do eventually want to reach the highest level of mastery in Apache Spark. It may become a book one day, but surely serves as the study material for trainings, workshops, videos and courses about Apache Spark. Follow me on twitter @jaceklaskowski to know it early. You will also learn about the upcoming events about Apache Spark. Expect text and code snippets from Spark’s mailing lists, the official documentation of Apache Spark, StackOverflow, blog posts, books from O’Reilly, press releases, YouTube/Vimeo videos, Quora, the source code of Apache Spark, etc. Attribution follows. Introduction 10
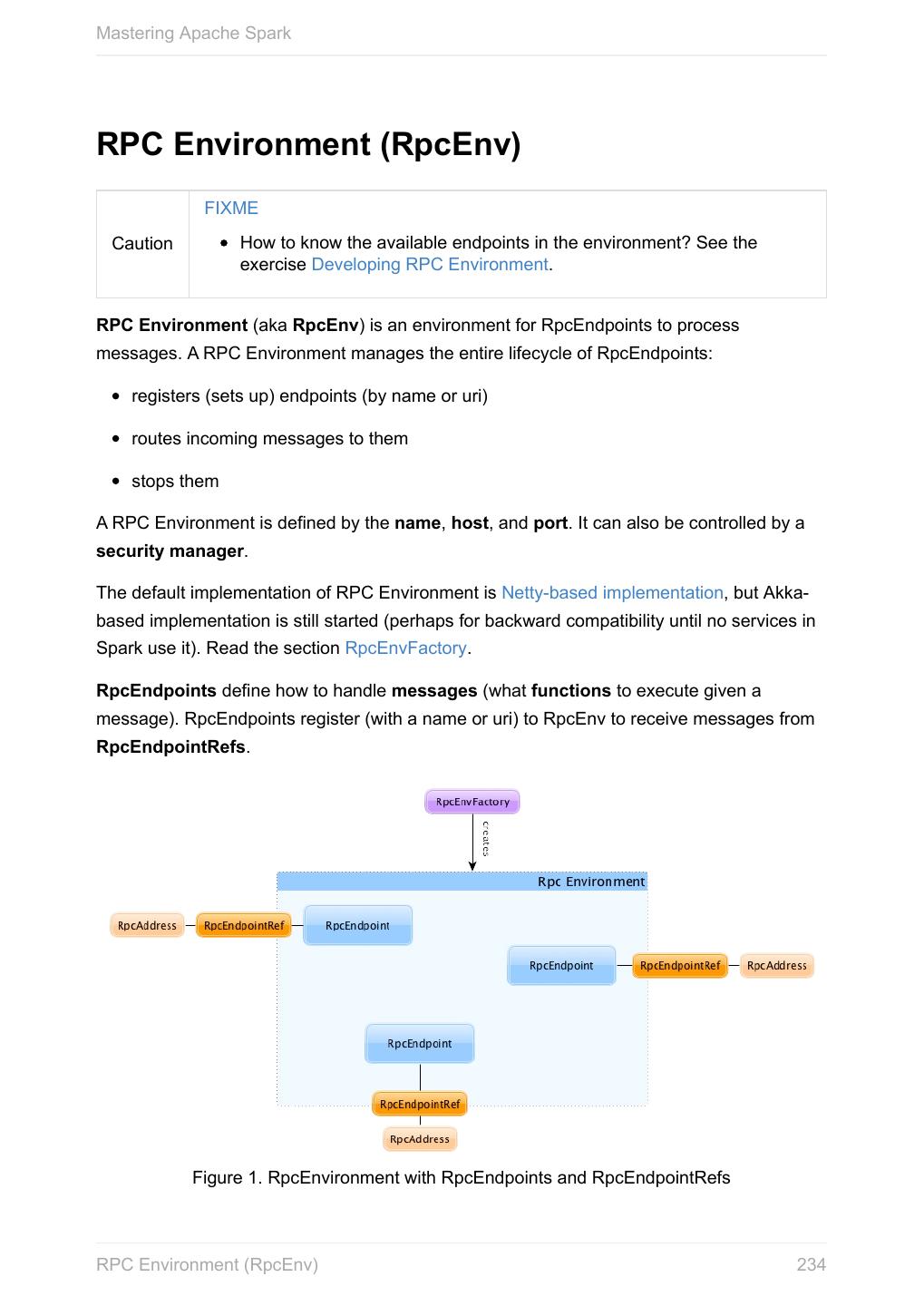
11 .Mastering Apache Spark Overview of Spark When you hear Apache Spark it can be two things - the Spark engine aka Spark Core or the Spark project - an "umbrella" term for Spark Core and the accompanying Spark Application Frameworks, i.e. Spark SQL, Spark Streaming, Spark MLlib and Spark GraphX that sit on top of Spark Core and the main data abstraction in Spark called RDD - Resilient Distributed Dataset. Figure 1. The Spark Platform It is pretty much as Hadoop where it can mean different things for different people, and Spark has heavily been and still is influenced by Hadoop. Why Spark Let’s list a few of the many reasons for Spark. We are doing it first, and then comes the overview that lends a more technical helping hand. Diverse Workloads As said by Matei Zaharia - the author of Apache Spark - in Introduction to AmpLab Spark Internals video (quoting with few changes): Overview of Spark 11
12 .Mastering Apache Spark One of the Spark project goals was to deliver a platform that supports a very wide array of diverse workflows - not only MapReduce batch jobs (there were available in Hadoop already at that time), but also iterative computations like graph algorithms or Machine Learning. And also different scales of workloads from sub-second interactive jobs to jobs that run for many hours. Spark also supports near real-time streaming workloads via Spark Streaming application framework. ETL workloads and Analytics workloads are different, however Spark attempts to offer a unified platform for a wide variety of workloads. Graph and Machine Learning algorithms are iterative by nature and less saves to disk or transfers over network means better performance. There is also support for interactive workloads using Spark shell. You should watch the video What is Apache Spark? by Mike Olson, Chief Strategy Officer and Co-Founder at Cloudera, who provides a very exceptional overview of Apache Spark, its rise in popularity in the open source community, and how Spark is primed to replace MapReduce as the general processing engine in Hadoop. Leverages the Best in distributed batch data processing When you think about distributed batch data processing, Hadoop naturally comes to mind as a viable solution. Spark draws many ideas out of Hadoop MapReduce. They work together well - Spark on YARN and HDFS - while improving on the performance and simplicity of the distributed computing engine. For many, Spark is Hadoop++, i.e. MapReduce done in a better way. And it should not come as a surprise, without Hadoop MapReduce (its advances and deficiencies), Spark would not have been born at all. RDD - Distributed Parallel Scala Collections As a Scala developer, you may find Spark’s RDD API very similar (if not identical) to Scala’s Collections API. It is also exposed in Java, Python and R (as well as SQL, i.e. SparkSQL, in a sense). Overview of Spark 12
13 .Mastering Apache Spark So, when you have a need for distributed Collections API in Scala, Spark with RDD API should be a serious contender. Rich Standard Library Not only can you use map and reduce (as in Hadoop MapReduce jobs) in Spark, but also a vast array of other higher-level operators to ease your Spark queries and application development. It expanded on the available computation styles beyond the only map-and-reduce available in Hadoop MapReduce. Unified development and deployment environment for all Regardless of the Spark tools you use - the Spark API for the many programming languages supported - Scala, Java, Python, R, or the Spark shell, or the many Spark Application Frameworks leveraging the concept of RDD, i.e. Spark SQL, Spark Streaming, Spark MLlib and Spark GraphX, you still use the same development and deployment environment to for large data sets to yield a result, be it a prediction (Spark MLlib), a structured data queries (Spark SQL) or just a large distributed batch (Spark Core) or streaming (Spark Streaming) computation. It’s also very productive of Spark that teams can exploit the different skills the team members have acquired so far. Data analysts, data scientists, Python programmers, or Java, or Scala, or R, can all use the same Spark platform using tailor-made API. It makes for bringing skilled people with their expertise in different programming languages together to a Spark project. Interactive exploration It is also called ad hoc queries. Using the Spark shell you can execute computations to process large amount of data (The Big Data). It’s all interactive and very useful to explore the data before final production release. Also, using the Spark shell you can access any Spark cluster as if it was your local machine. Just point the Spark shell to a 20-node of 10TB RAM memory in total (using --master ) and use all the components (and their abstractions) like Spark SQL, Spark MLlib, Spark Streaming, and Spark GraphX. Overview of Spark 13
14 .Mastering Apache Spark Depending on your needs and skills, you may see a better fit for SQL vs programming APIs or apply machine learning algorithms (Spark MLlib) from data in graph data structures (Spark GraphX). Single environment Regardless of which programming language you are good at, be it Scala, Java, Python or R, you can use the same single clustered runtime environment for prototyping, ad hoc queries, and deploying your applications leveraging the many ingestion data points offered by the Spark platform. You can be as low-level as using RDD API directly or leverage higher-level APIs of Spark SQL (DataFrames), Spark MLlib (Pipelines), Spark GraphX (???), or Spark Streaming (DStreams). Or use them all in a single application. The single programming model and execution engine for different kinds of workloads simplify development and deployment architectures. Rich set of supported data sources Spark can read from many types of data sources - relational, NoSQL, file systems, etc. Both, input and output data sources, allow programmers and data engineers use Spark as the platform with the large amount of data that is read from or saved to for processing, interactively (using Spark shell) or in applications. Tools unavailable then, at your fingertips now As much and often as it’s recommended to pick the right tool for the job, it’s not always feasible. Time, personal preference, operating system you work on are all factors to decide what is right at a time (and using a hammer can be a reasonable choice). Spark embraces many concepts in a single unified development and runtime environment. Machine learning that is so tool- and feature-rich in Python, e.g. SciKit library, can now be used by Scala developers (as Pipeline API in Spark MLlib or calling pipe() ). DataFrames from R are available in Scala, Java, Python, R APIs. Single node computations in machine learning algorithms are migrated to their distributed versions in Spark MLlib. Overview of Spark 14
15 .Mastering Apache Spark This single platform gives plenty of opportunities for Python, Scala, Java, and R programmers as well as data engineers (SparkR) and scientists (using proprietary enterprise data warehousesthe with Thrift JDBC/ODBC server in Spark SQL). Mind the proverb if all you have is a hammer, everything looks like a nail, too. Low-level Optimizations Apache Spark uses a directed acyclic graph (DAG) of computation stages (aka execution DAG). It postpones any processing until really required for actions. Spark’s lazy evaluation gives plenty of opportunities to induce low-level optimizations (so users have to know less to do more). Mind the proverb less is more. Excels at low-latency iterative workloads Spark supports diverse workloads, but successfully targets low-latency iterative ones. They are often used in Machine Learning and graph algorithms. Many Machine Learning algorithms require plenty of iterations before the result models get optimal, like logistic regression. The same applies to graph algorithms to traverse all the nodes and edges when needed. Such computations can increase their performance when the interim partial results are stored in memory or at very fast solid state drives. Spark can cache intermediate data in memory for faster model building and training. Once the data is loaded to memory (as an initial step), reusing it multiple times incurs no performance slowdowns. Also, graph algorithms can traverse graphs one connection per iteration with the partial result in memory. Less disk access and network can make a huge difference when you need to process lots of data, esp. when it is a BIG Data. ETL done easier Spark gives Extract, Transform and Load (ETL) a new look with the many programming languages supported - Scala, Java, Python (less likely R). You can use them all or pick the best for a problem. Scala in Spark, especially, makes for a much less boiler-plate code (comparing to other languages and approaches like MapReduce in Java). Overview of Spark 15
16 .Mastering Apache Spark Unified API (for different computation models) Spark offers one unified API for batch analytics, SQL queries, real-time analysis, machine learning and graph processing. Developers no longer have to learn many different processing engines per use case. Different kinds of data processing using unified API Spark offers three kinds of data processing using batch, interactive, and stream processing with the unified API and data structures. Little to no disk use for better performance In the no-so-long-ago times, when the most prevalent distributed computing framework was Hadoop MapReduce, you could reuse a data between computation (even partial ones!) only after you’ve written it to an external storage like Hadoop Distributed Filesystem (HDFS). It can cost you a lot of time to compute even very basic multi-stage computations. It simply suffers from IO (and perhaps network) overhead. One of the many motivations to build Spark was to have a framework that is good at data reuse. Spark cuts it out in a way to keep as much data as possible in memory and keep it there until a job is finished. It doesn’t matter how many stages belong to a job. What does matter is the available memory and how effective you are in using Spark API (so no shuffle occur). The less network and disk IO, the better performance, and Spark tries hard to find ways to minimize both. Fault Tolerance included Faults are not considered a special case in Spark, but obvious consequence of being a parallel and distributed system. Spark handles and recovers from faults by default without particularly complex logic to deal with them. Small Codebase Invites Contributors Spark’s design is fairly simple and the code that comes out of it is not huge comparing to the features it offers. The reasonably small codebase of Spark invites project contributors - programmers who extend the platform and fix bugs in a more steady pace. Overview of Spark 16
17 .Mastering Apache Spark Overview Apache Spark is an open-source parallel distributed general-purpose cluster computing framework with in-memory big data processing engine with programming interfaces (APIs) for the programming languages: Scala, Python, Java, and R. Or, to have a one-liner, Apache Spark is a distributed, data processing engine for batch and streaming modes featuring SQL queries, graph processing, and Machine Learning. In contrast to Hadoop’s two-stage disk-based MapReduce processing engine, Spark’s multi- stage in-memory computing engine allows for running most computations in memory, and hence very often provides better performance (there are reports about being up to 100 times faster - read Spark officially sets a new record in large-scale sorting!) for certain applications, e.g. iterative algorithms or interactive data mining. Spark aims at speed, ease of use, and interactive analytics. Spark is often called cluster computing engine or simply execution engine. Spark is a distributed platform for executing complex multi-stage applications, like machine learning algorithms, and interactive ad hoc queries. Spark provides an efficient abstraction for in-memory cluster computing called Resilient Distributed Dataset. Using Spark Application Frameworks, Spark simplifies access to machine learning and predictive analytics at scale. Spark is mainly written in Scala, but supports other languages, i.e. Java, Python, and R. If you have large amounts of data that requires low latency processing that a typical MapReduce program cannot provide, Spark is an alternative. Access any data type across any data source. Huge demand for storage and data processing. The Apache Spark project is an umbrella for SQL (with DataFrames), streaming, machine learning (pipelines) and graph processing engines built atop Spark Core. You can run them all in a single application using a consistent API. Spark runs locally as well as in clusters, on-premises or in cloud. It runs on top of Hadoop YARN, Apache Mesos, standalone or in the cloud (Amazon EC2 or IBM Bluemix). Spark can access data from many data sources. Apache Spark’s Streaming and SQL programming models with MLlib and GraphX make it easier for developers and data scientists to build applications that exploit machine learning and graph analytics. Overview of Spark 17
18 .Mastering Apache Spark At a high level, any Spark application creates RDDs out of some input, run (lazy) transformations of these RDDs to some other form (shape), and finally perform actions to collect or store data. Not much, huh? You can look at Spark from programmer’s, data engineer’s and administrator’s point of view. And to be honest, all three types of people will spend quite a lot of their time with Spark to finally reach the point where they exploit all the available features. Programmers use language-specific APIs (and work at the level of RDDs using transformations and actions), data engineers use higher-level abstractions like DataFrames or Pipelines APIs or external tools (that connect to Spark), and finally it all can only be possible to run because administrators set up Spark clusters to deploy Spark applications to. It is Spark’s goal to be a general-purpose computing platform with various specialized applications frameworks on top of a single unified engine. In Going from Hadoop to Spark: A Case Study, Sujee Maniyam 20150223: Spark is like emacs - once you join emacs, you can’t leave emacs. Overview of Spark 18
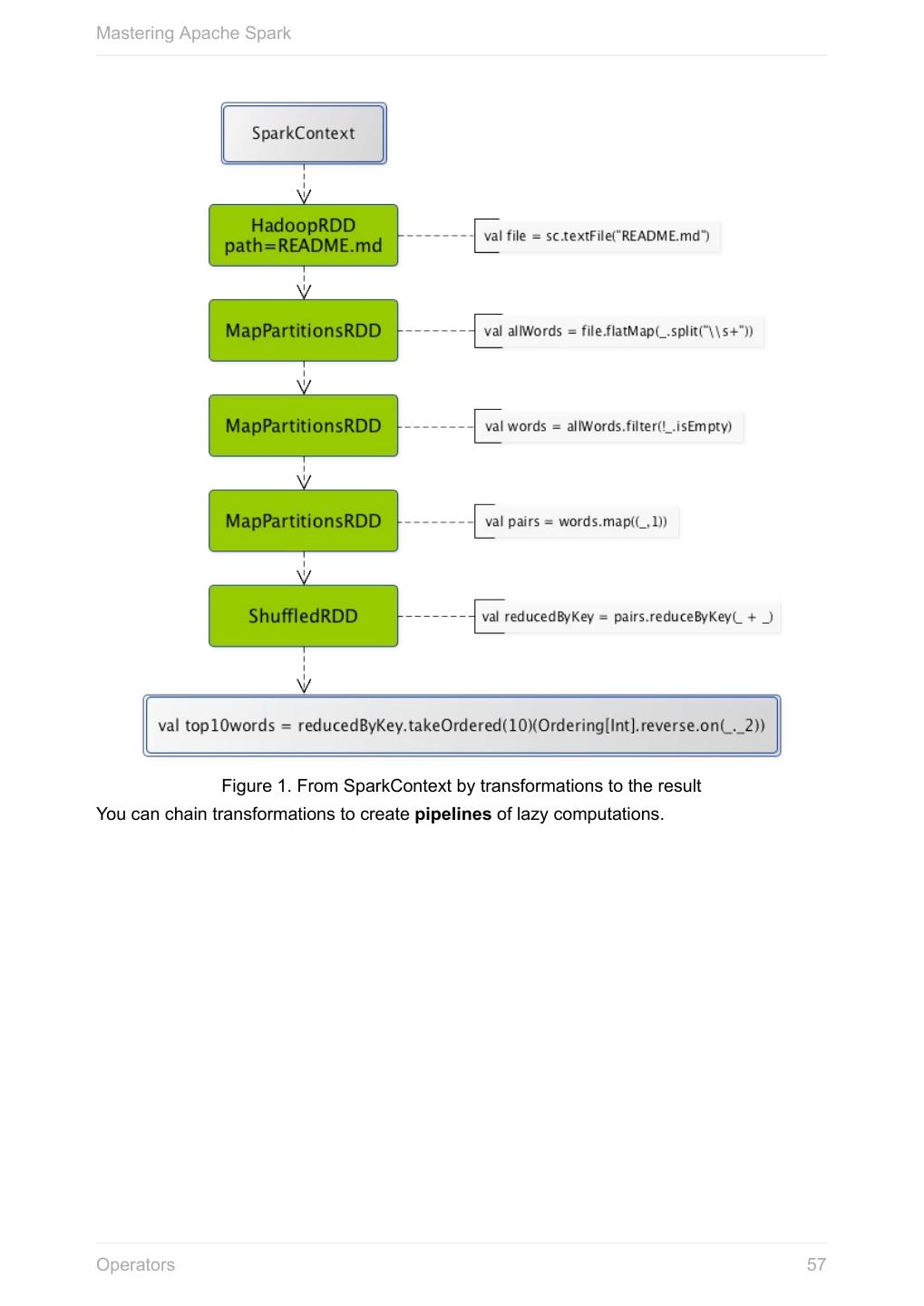
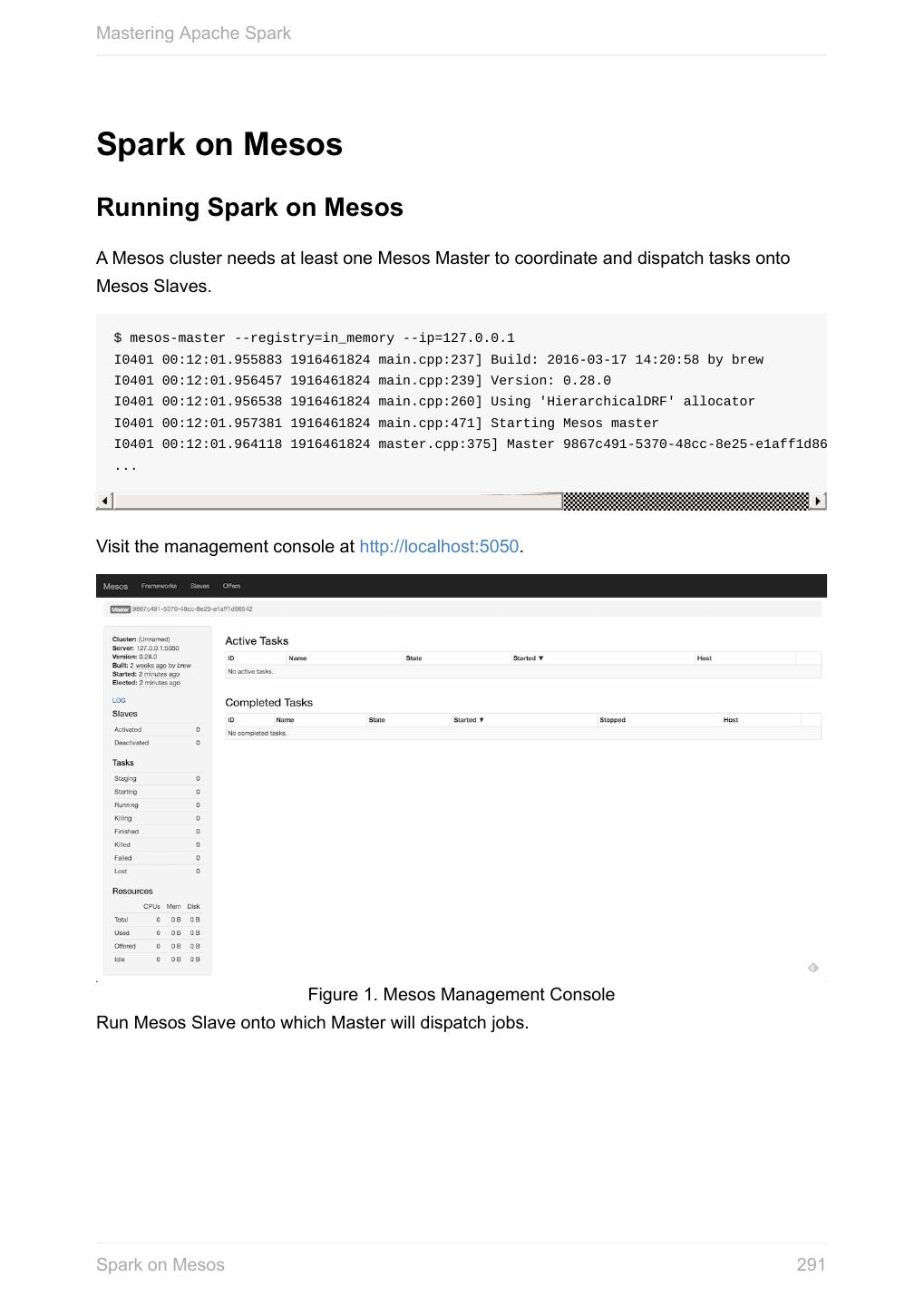
19 .Mastering Apache Spark Anatomy of Spark Application Every Spark application starts at instantiating a Spark context. Without a Spark context no computation can ever be started using Spark services. A Spark application is an instance of SparkContext. Or, put it differently, a Spark Note context constitutes a Spark application. For it to work, you have to create a Spark configuration using SparkConf or use a custom SparkContext constructor. package pl.japila.spark import org.apache.spark.{SparkContext, SparkConf} object SparkMeApp { def main(args: Array[String]) { val masterURL = "local[*]" (1) val conf = new SparkConf() (2) .setAppName("SparkMe Application") .setMaster(masterURL) val sc = new SparkContext(conf) (3) val fileName = util.Try(args(0)).getOrElse("build.sbt") val lines = sc.textFile(fileName).cache() (4) val c = lines.count() (5) println(s"There are $c lines in $fileName") } } 1. Master URL to connect the application to 2. Create Spark configuration 3. Create Spark context 4. Create lines RDD 5. Execute count action Tip Spark shell creates a Spark context and SQL context for you at startup. Anatomy of Spark Application 19
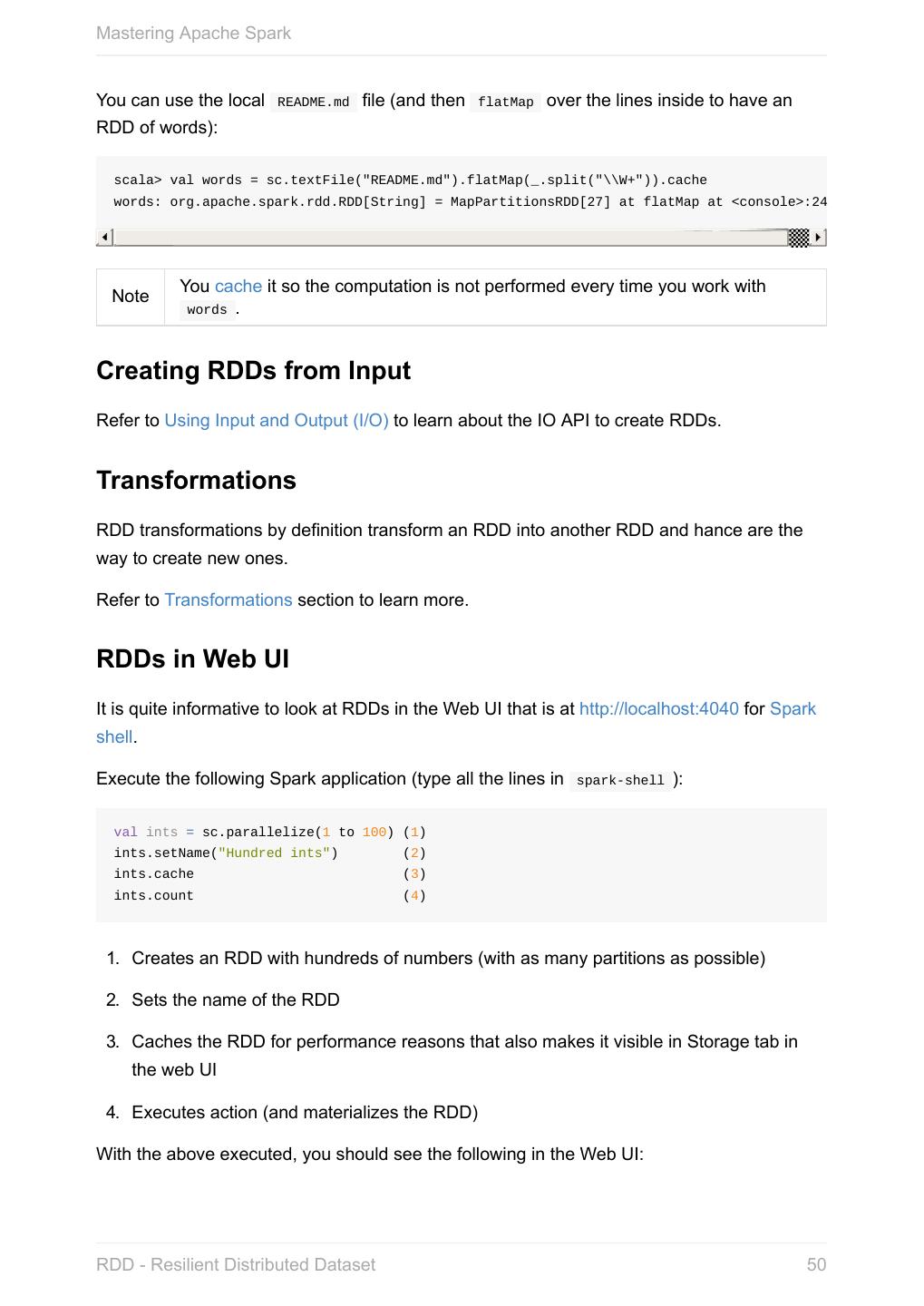
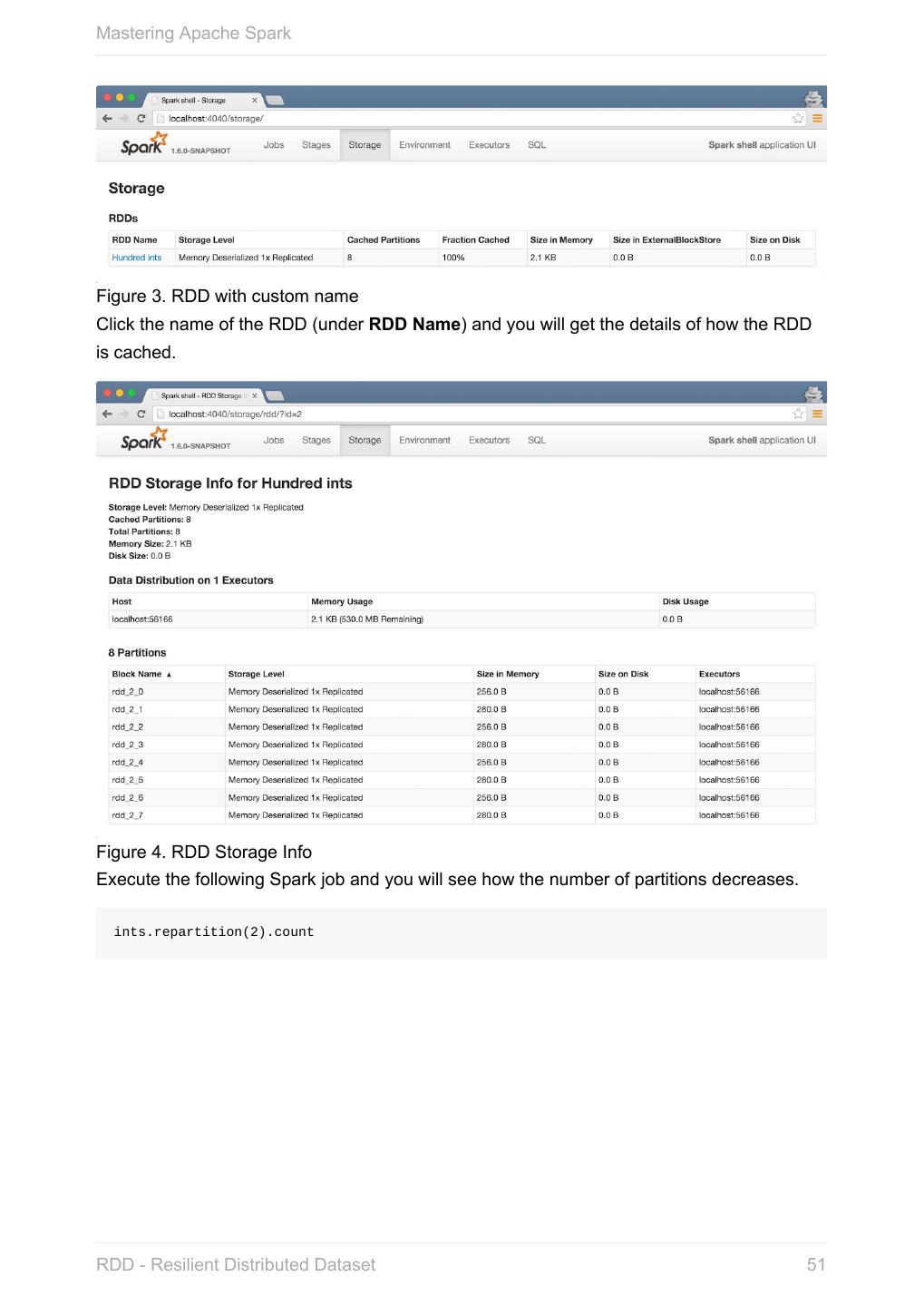
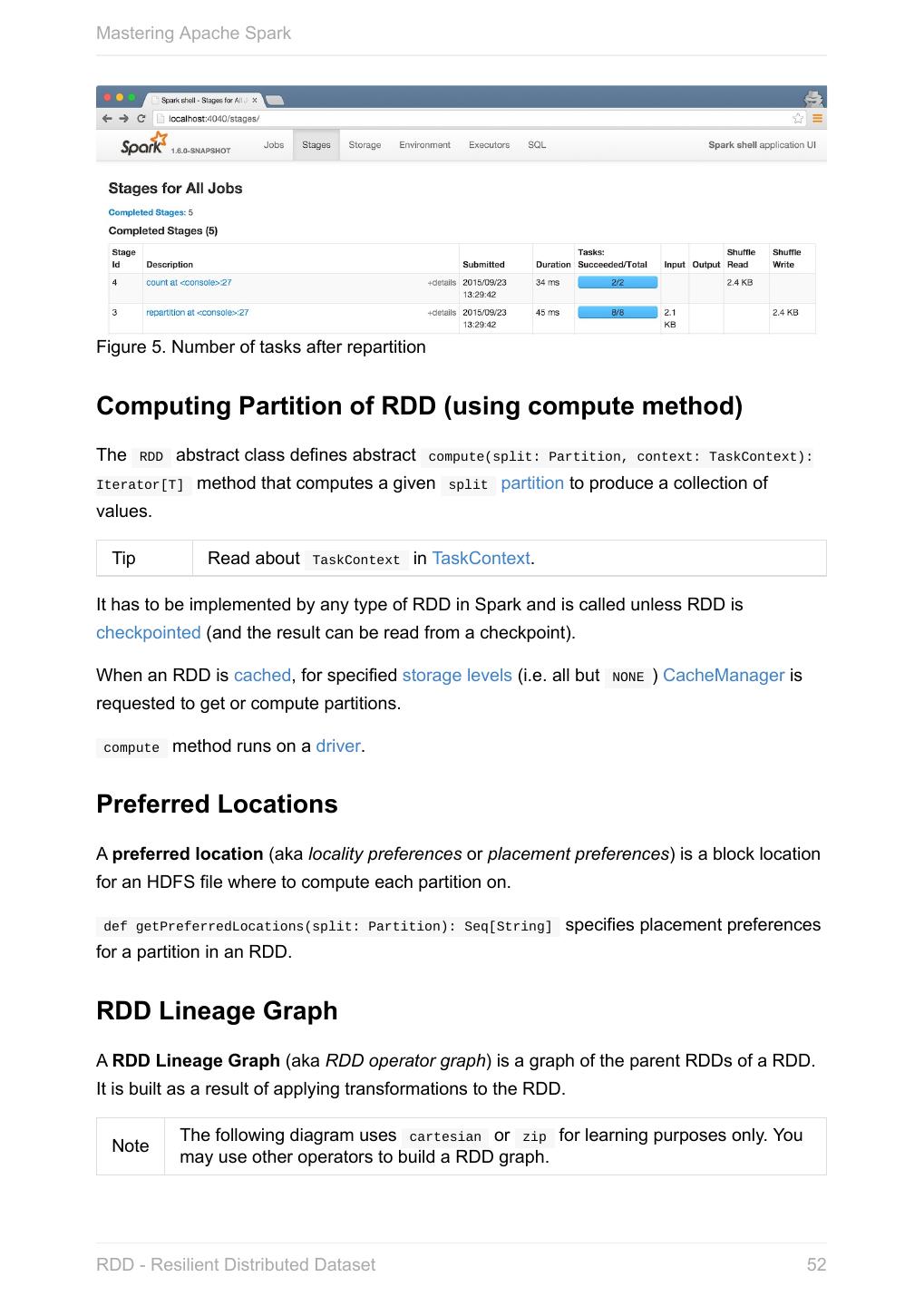
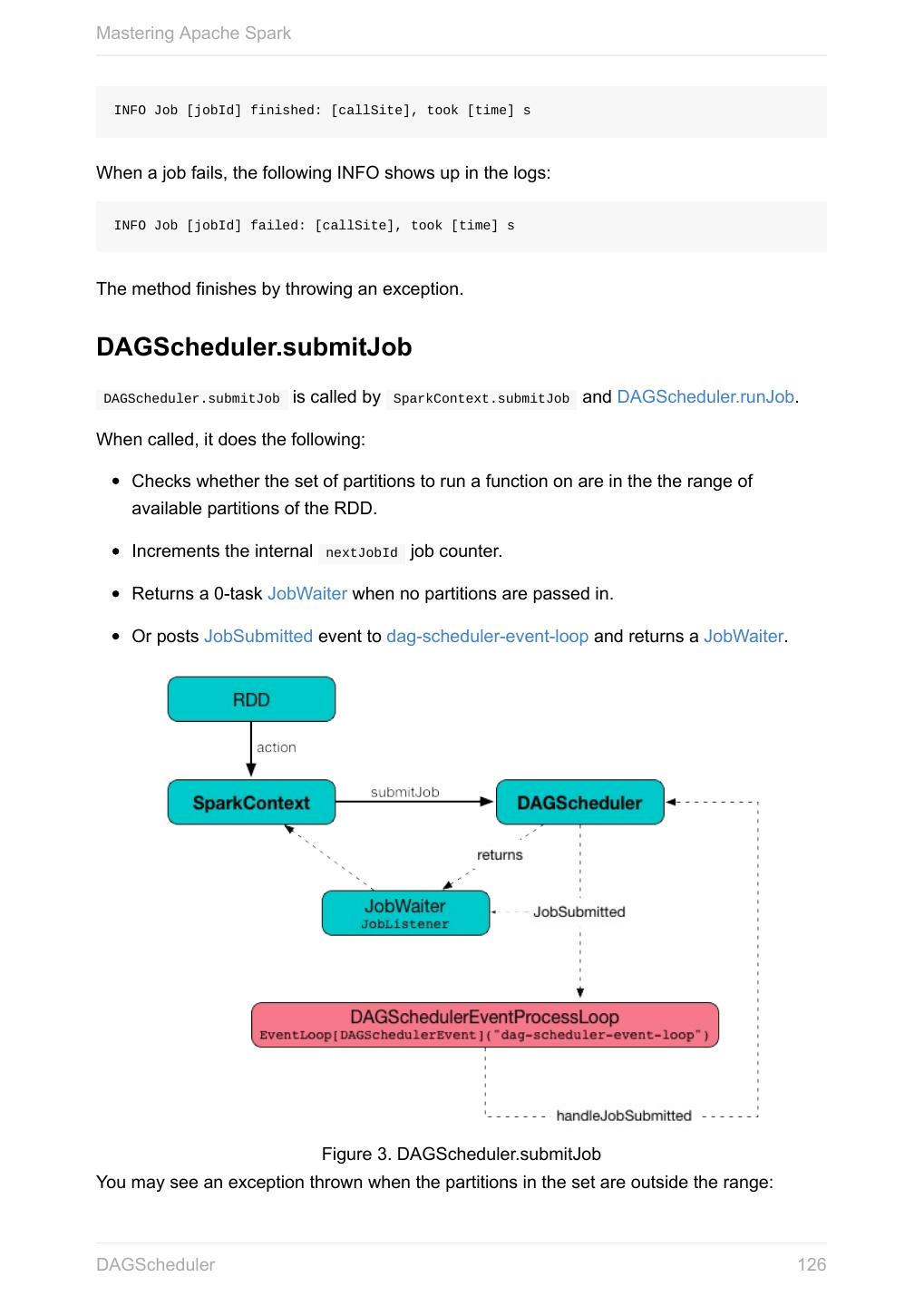
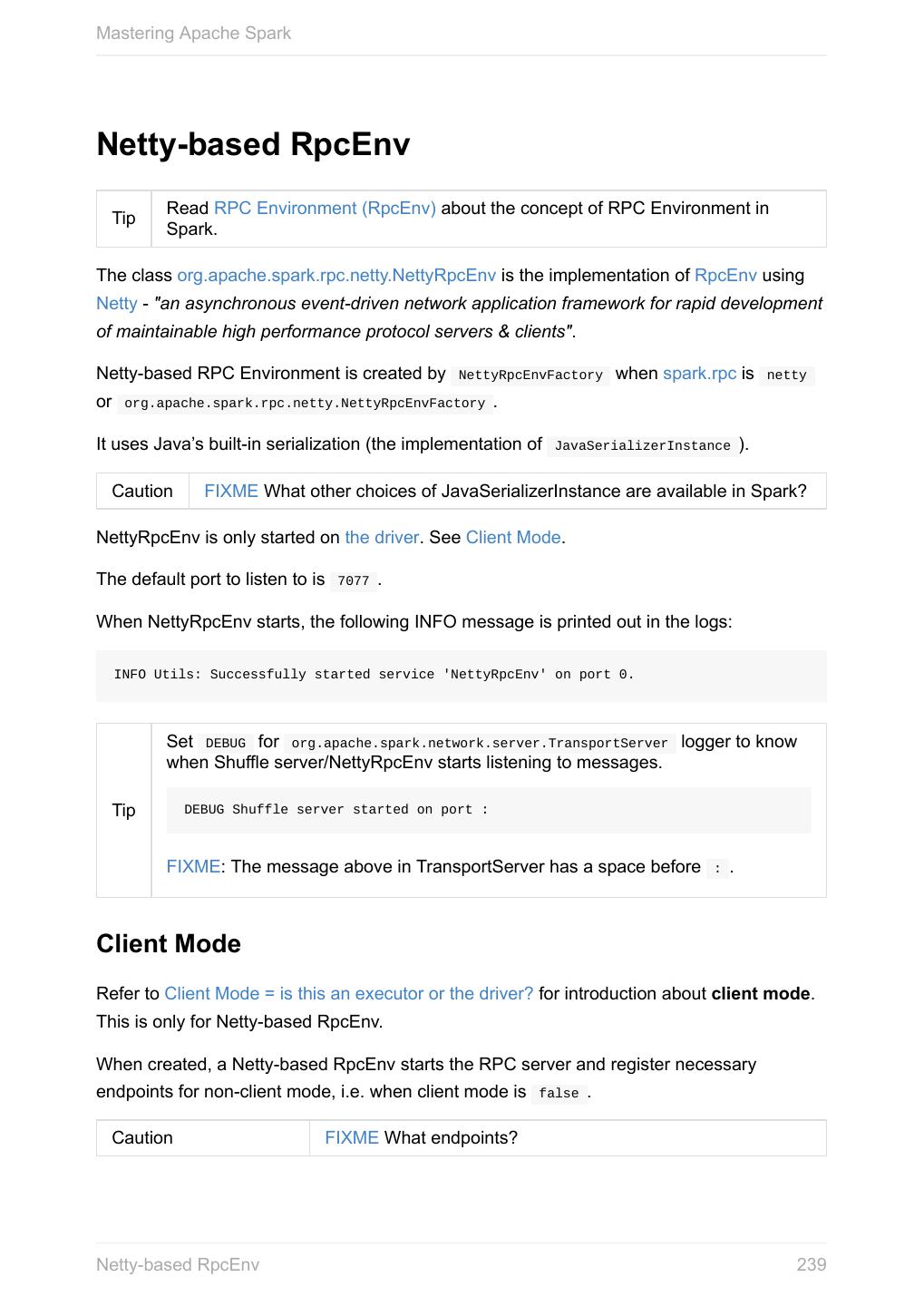
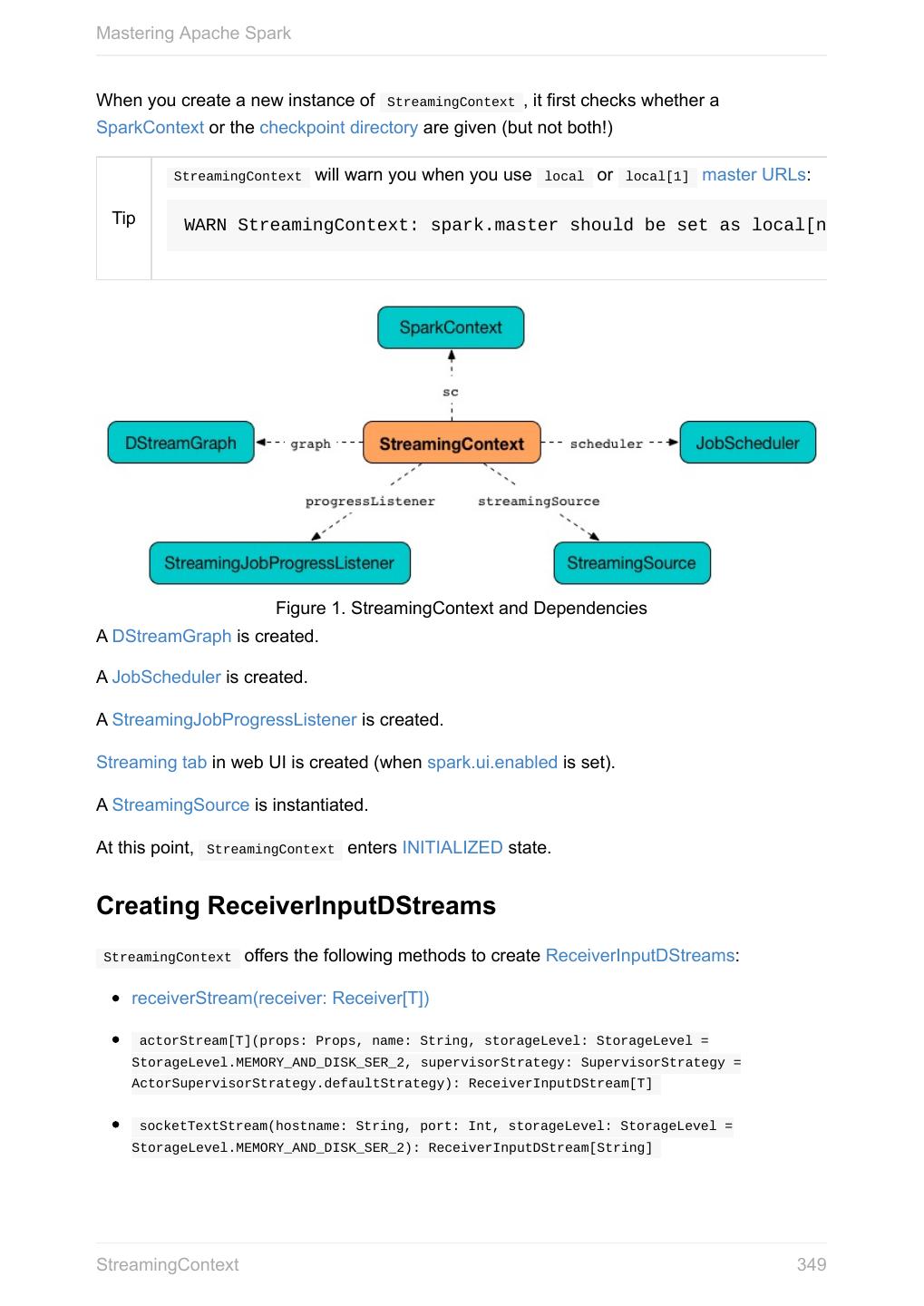
20 .Mastering Apache Spark When a Spark application starts (using spark-submit script or as a standalone application), it connects to Spark master as described by master URL. It is part of Spark context’s initialization. Figure 1. Submitting Spark application to master using master URL Your Spark application can run locally or on the cluster which is based on the Note cluster manager and the deploy mode ( --deploy-mode ). Refer to Deployment Modes. You can then create RDDs, transform them to other RDDs and ultimately execute actions. You can also cache interim RDDs to speed up data processing. After all the data processing is completed, the Spark application finishes by stopping the Spark context. Anatomy of Spark Application 20
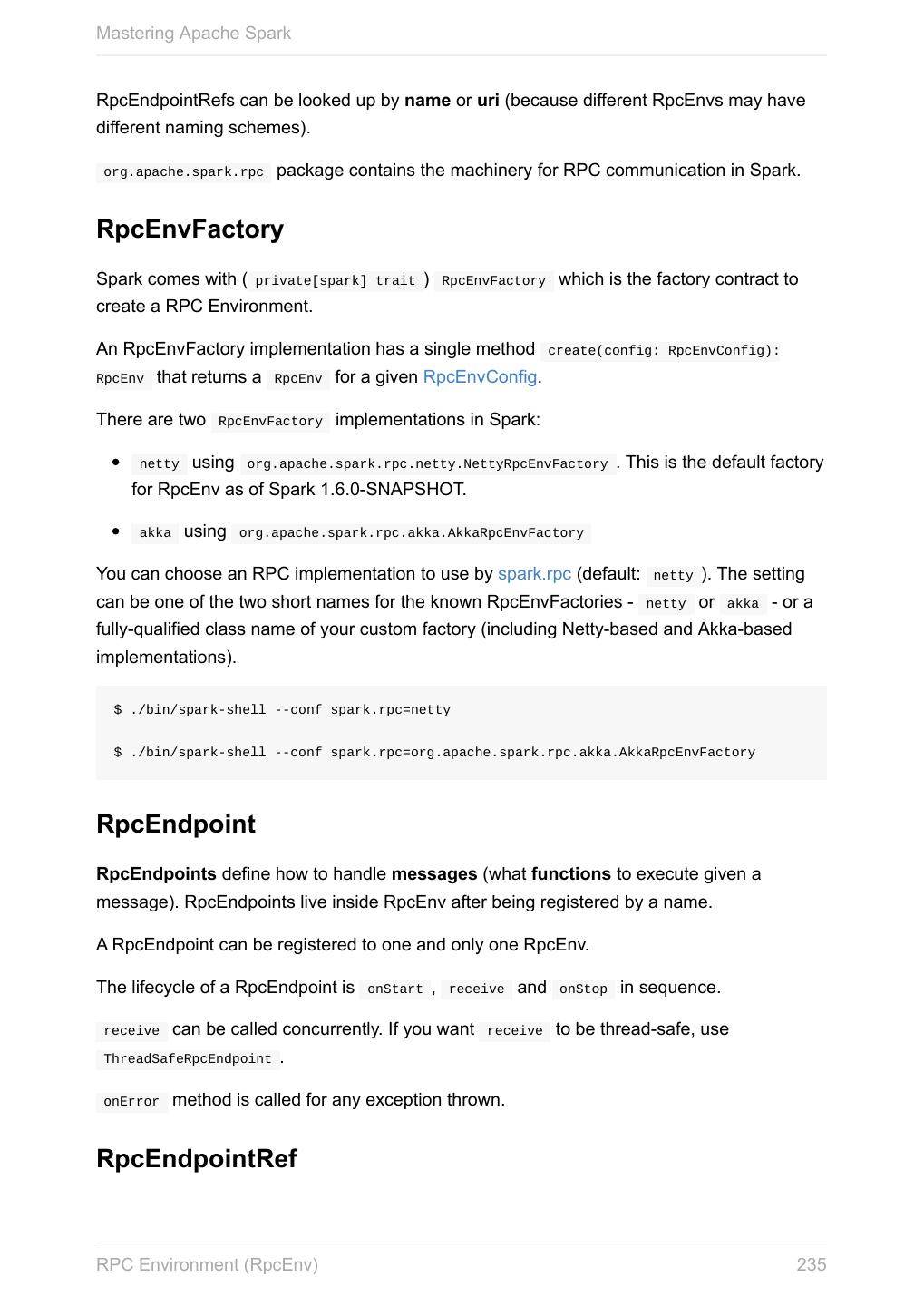
21 .Mastering Apache Spark SparkConf - Configuration for Spark Applications Refer to Spark Configuration for extensive coverage of how to configure Spark Tip and user programs. TODO Describe SparkConf object for the application configuration. Caution the default configs system properties There are three ways to configure Spark and user programs: Spark Properties - use Web UI to learn the current properties. … Spark Properties Every user program starts with creating an instance of SparkConf that holds the master URL to connect to ( spark.master ), the name for your Spark application (that is later displayed in web UI and becomes spark.app.name ) and other Spark properties required for proper runs. An instance of SparkConf is then used to create SparkContext. Start Spark shell with --conf spark.logConf=true to log the effective Spark configuration as INFO when SparkContext is started. $ ./bin/spark-shell --conf spark.logConf=true ... 15/10/19 17:13:49 INFO SparkContext: Running Spark version 1.6.0-SNAPSHOT 15/10/19 17:13:49 INFO SparkContext: Spark configuration: spark.app.name=Spark shell spark.home=/Users/jacek/dev/oss/spark Tip spark.jars= spark.logConf=true spark.master=local[*] spark.repl.class.uri=http://10.5.10.20:64055 spark.submit.deployMode=client ... Use sc.getConf.toDebugString to have a richer output once SparkContext has finished initializing. You can query for the values of Spark properties in Spark shell as follows: SparkConf - Configuration for Spark Applications 21
22 .Mastering Apache Spark scala> sc.getConf.getOption("spark.local.dir") res0: Option[String] = None scala> sc.getConf.getOption("spark.app.name") res1: Option[String] = Some(Spark shell) scala> sc.getConf.get("spark.master") res2: String = local[*] Setting up Properties There are the following ways to set up properties for Spark and user programs (in the order of importance from the least important to the most important): conf/spark-defaults.conf - the default --conf - the command line option used by spark-shell and spark-submit SparkConf Default Configuration The default Spark configuration is created when you execute the following code: import org.apache.spark.SparkConf val conf = new SparkConf It merely loads any spark.* system properties. You can use conf.toDebugString or conf.getAll to have the spark.* system properties loaded printed out. SparkConf - Configuration for Spark Applications 22
23 .Mastering Apache Spark scala> conf.getAll res0: Array[(String, String)] = Array((spark.app.name,Spark shell), (spark.jars,""), (spark.master,lo scala> conf.toDebugString res1: String = spark.app.name=Spark shell spark.jars= spark.master=local[*] spark.submit.deployMode=client scala> println(conf.toDebugString) spark.app.name=Spark shell spark.jars= spark.master=local[*] spark.submit.deployMode=client SparkConf - Configuration for Spark Applications 23
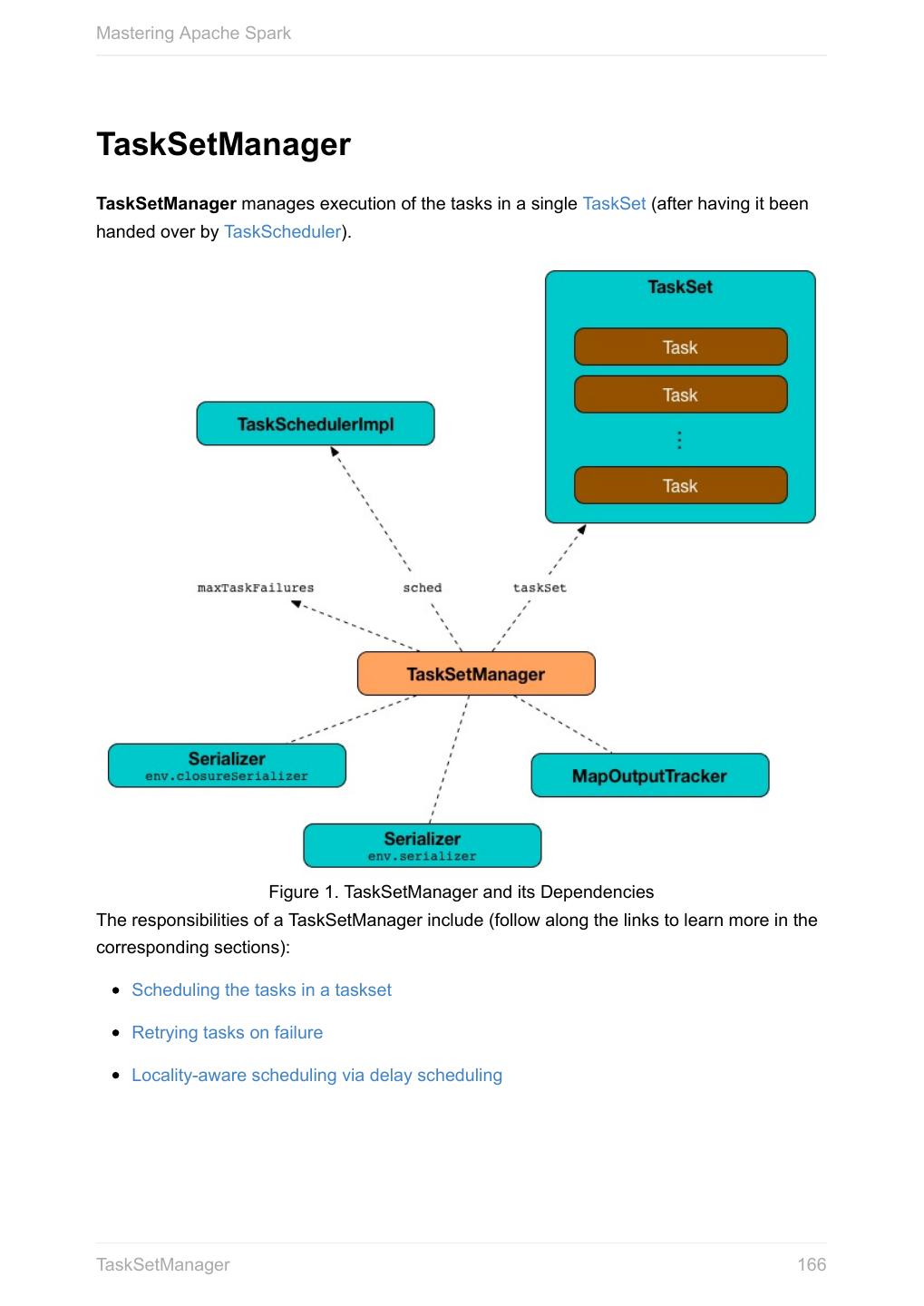
24 .Mastering Apache Spark SparkContext - the door to Spark SparkContext (aka Spark context) represents the connection to a Spark execution environment (deployment mode). You have to create a Spark context before using Spark features and services in your application. A Spark context can be used to create RDDs, accumulators and broadcast variables, access Spark services and run jobs. A Spark context is essentially a client of Spark’s execution environment and acts as the master of your Spark application (don’t get confused with the other meaning of Master in Spark, though). Figure 1. Spark context acts as the master of your Spark application SparkContext offers the following functions: Default Level of Parallelism Specifying mandatory master URL Specifying mandatory application name Creating RDDs Creating accumulators Creating broadcast variables SparkContext - the door to Spark 24
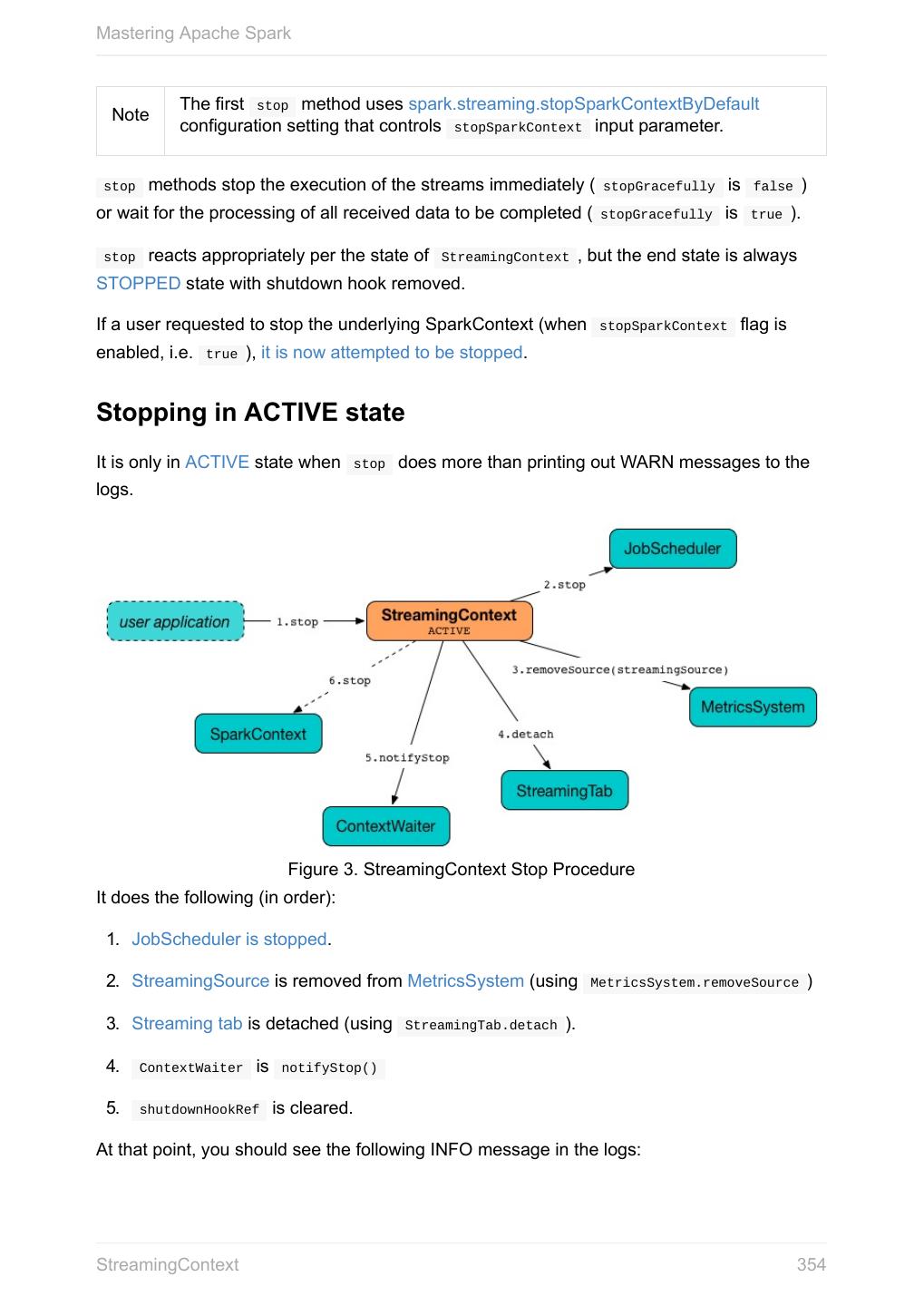
25 .Mastering Apache Spark Accessing services, e.g. Task Scheduler, Listener Bus, Block Manager, Scheduler Backends, Shuffle Manager. Running jobs Setting up custom Scheduler Backend, Task Scheduler and DAGScheduler Closure Cleaning Submitting Jobs Asynchronously Unpersisting RDDs, i.e. marking RDDs as non-persistent Setting local properties Read the scaladoc of org.apache.spark.SparkContext. Master URL Caution FIXME Connecting to a cluster Application Name Caution FIXME Specifying mandatory application name Default Level of Parallelism Default level of parallelism is the number of partitions when not specified explicitly by a user. It is used for the methods like SparkContext.parallelize , SparkContext.range and SparkContext.makeRDD (as well as Spark Streaming's DStream.countByValue and DStream.countByValueAndWindow and few other places). It is also used to instantiate HashPartitioner or for the minimum number of partitions in HadoopRDDs. SparkContext queries TaskScheduler for the default level of parallelism (refer to TaskScheduler Contract). Setting Local Properties Caution FIXME SparkContext - the door to Spark 25
26 .Mastering Apache Spark FIXME It’d be nice to have an intro page about local properties. Dunno Caution where it could belong to (?) SparkContext.makeRDD Caution FIXME Submitting Jobs Asynchronously SparkContext.submitJob submits a job in an asynchronous, non-blocking way (using DAGScheduler.submitJob method). It cleans the processPartition input function argument and returns an instance of SimpleFutureAction that holds the JobWaiter instance (it has received from DAGScheduler.submitJob ). Caution FIXME What are resultFunc ? It is used in: AsyncRDDActions methods Spark Streaming for ReceiverTrackerEndpoint.startReceiver Spark Configuration Caution FIXME Creating SparkContext You create a SparkContext instance using a SparkConf object. scala> import org.apache.spark.SparkConf import org.apache.spark.SparkConf scala> val conf = new SparkConf().setMaster("local[*]").setAppName("SparkMe App") conf: org.apache.spark.SparkConf = org.apache.spark.SparkConf@7a8f69d6 scala> import org.apache.spark.SparkContext import org.apache.spark.SparkContext scala> val sc = new SparkContext(conf) (1) sc: org.apache.spark.SparkContext = org.apache.spark.SparkContext@50ee2523 SparkContext - the door to Spark 26
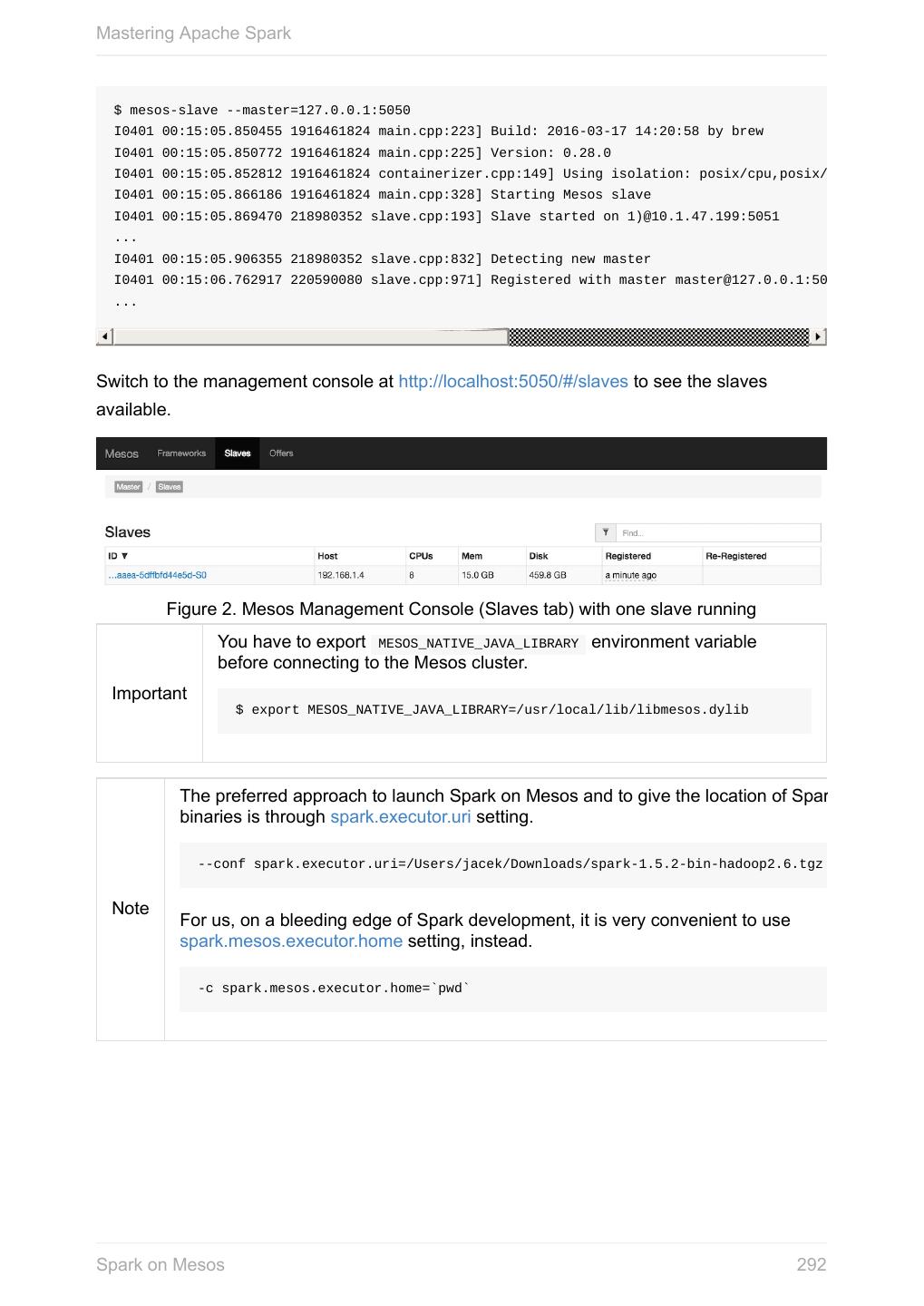
27 .Mastering Apache Spark 1. You can also use the other constructor of SparkContext , i.e. new SparkContext(master="local[*]", appName="SparkMe App", new SparkConf) , with master and application name specified explicitly When a Spark context starts up you should see the following INFO in the logs (amongst the other messages that come from services): INFO SparkContext: Running Spark version 1.6.0-SNAPSHOT Only one SparkContext may be running in a single JVM (check out SPARK-2243 Support multiple SparkContexts in the same JVM). Sharing access to a SparkContext in the JVM is the solution to share data within Spark (without relying on other means of data sharing using external data stores). spark.driver.allowMultipleContexts Quoting the scaladoc of org.apache.spark.SparkContext: Only one SparkContext may be active per JVM. You must stop() the active SparkContext before creating a new one. The above quote is not necessarily correct when spark.driver.allowMultipleContexts is true (default: false ). If true , Spark logs warnings instead of throwing exceptions when multiple SparkContexts are active, i.e. multiple SparkContext are running in this JVM. When creating an instance of SparkContext , Spark marks the current thread as having it being created (very early in the instantiation process). It’s not guaranteed that Spark will work properly with two or more Caution SparkContexts. Consider the feature a work in progress. SparkContext and RDDs You use a Spark context to create RDDs (see Creating RDD). When an RDD is created, it belongs to and is completely owned by the Spark context it originated from. RDDs can’t by design be shared between SparkContexts. SparkContext - the door to Spark 27
28 .Mastering Apache Spark Figure 2. A Spark context creates a living space for RDDs. SparkContext in Spark shell In Spark shell, an instance of SparkContext is automatically created for you under the name sc . Read Spark shell. Creating RDD SparkContext allows you to create many different RDDs from input sources like: Scala’s collections, i.e. sc.parallelize(0 to 100) local or remote filesystems, i.e. sc.textFile("README.md") Any Hadoop InputSource using sc.newAPIHadoopFile Read Creating RDDs in RDD - Resilient Distributed Dataset. Unpersisting RDDs (Marking RDDs as non-persistent) It removes an RDD from the master’s Block Manager (calls removeRdd(rddId: Int, blocking: Boolean) ) and the internal persistentRdds mapping. SparkContext - the door to Spark 28
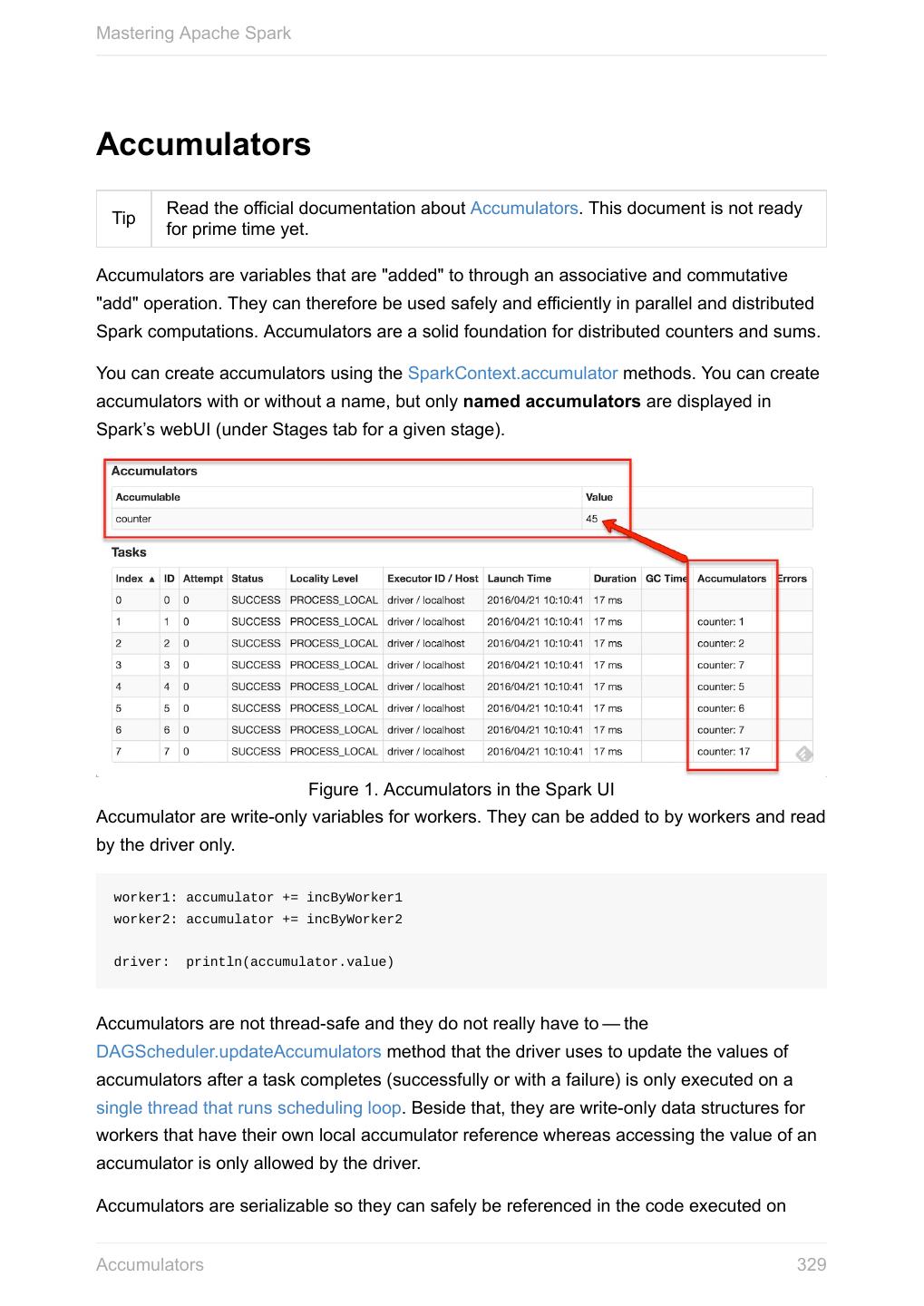
29 .Mastering Apache Spark It finally posts an unpersist notification (as SparkListenerUnpersistRDD event) to listenerBus . Setting Checkpoint Directory (setCheckpointDir method) setCheckpointDir(directory: String) setCheckpointDir method is used to set up the checkpoint directory…FIXME Caution FIXME Creating accumulators accumulator[T](initialValue: T)(implicit param: AccumulatorParam[T]): Accumulator[T] accumulator[T](initialValue: T, name: String)(implicit param: AccumulatorParam[T]): Accumulator accumulator methods create accumulators of type T with the initial value initialValue . scala> val acc = sc.accumulator(0) acc: org.apache.spark.Accumulator[Int] = 0 scala> val counter = sc.accumulator(0, "counter") counter: org.apache.spark.Accumulator[Int] = 0 scala> counter.value res2: Int = 0 scala> sc.parallelize(0 to 9).foreach(n => counter += n) scala> counter.value res4: Int = 45 name input parameter allows you to give a name to accumulators and have them displayed in the Spark UI (under Stages tab for a given stage). SparkContext - the door to Spark 29
相关推荐

加关注
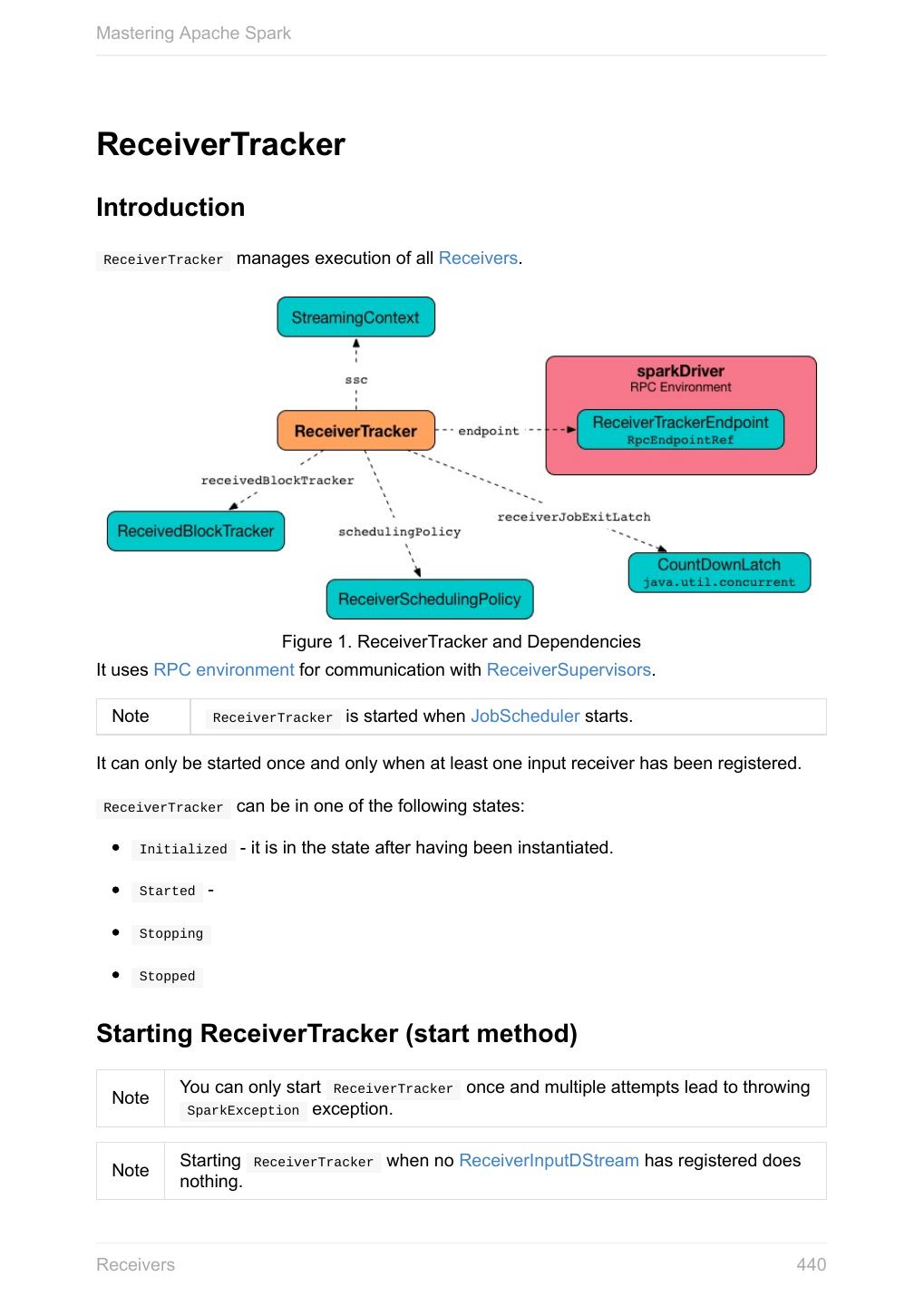
3秒后跳转登录页面
去登陆

