展开查看详情
3 . 日程 传统企业面临的挑战与 Pivotal介绍 Pivotal对于大数据的理解 大数据套件介绍 客户案例参考 典型架构与配置
5 .新时代需要一个全新的计算平台:第三平台 互联网平台时代 ,第三代IT代系的代表
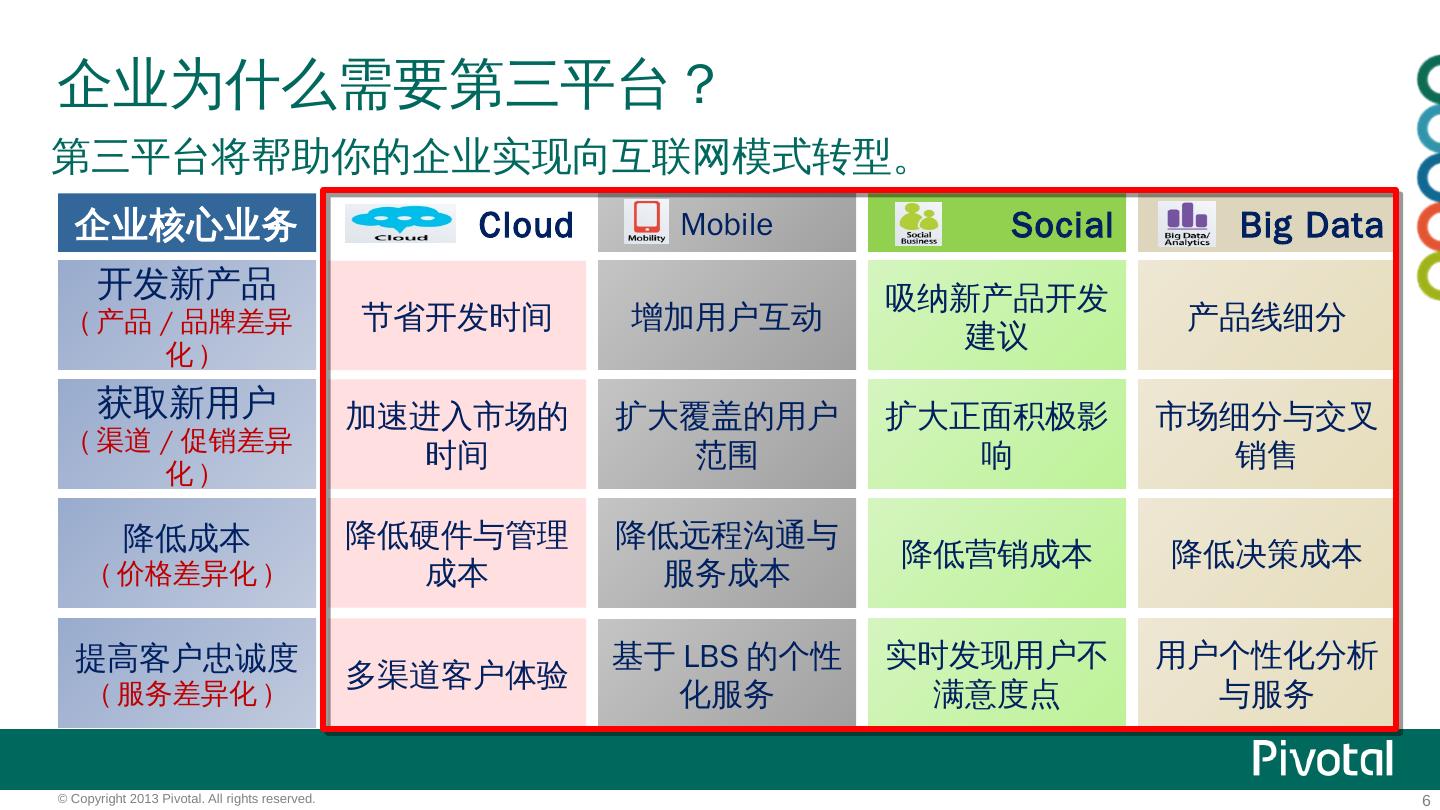
6 .企业为什么需要第三平台? 第三平台将帮助你的企业实现向互联网模式转型。 企业核心业务 Cloud Mobile Social Big Data 开发新产品 ( 产品 / 品牌差异化 ) 节省开发时间 增加用户互动 吸纳新产品开发建议 产品线细分 获取新用户 ( 渠道 / 促销差异化 ) 加速进入市场的时间 扩大覆盖的用户范围 扩大正面积极影响 市场细分与交叉销售 降低成本 ( 价格差异化 ) 降低硬件与管理成本 降低远程沟通与服务成本 降低营销成本 降低决策成本 提高客户忠诚度 ( 服务差异化 ) 多渠道客户体验 基于 LBS 的个性化服务 实时发现用户不满意度点 用户个性化分析与服务
7 .Pivotal的使命 独立于 EMC , VMWare 和 GE 的公司 , 但是受到各股东大力支持 使命 : 为一个崭新的技术时代构建支撑平台 把 服务于海量消费者的互联网架构与能力带给企业 首先提出并实现集成 : 新的数据支撑架构 , 现代化的开发框架与多种支撑云平台 传承自强有力的研发团队,数据科学家群体与开源精神
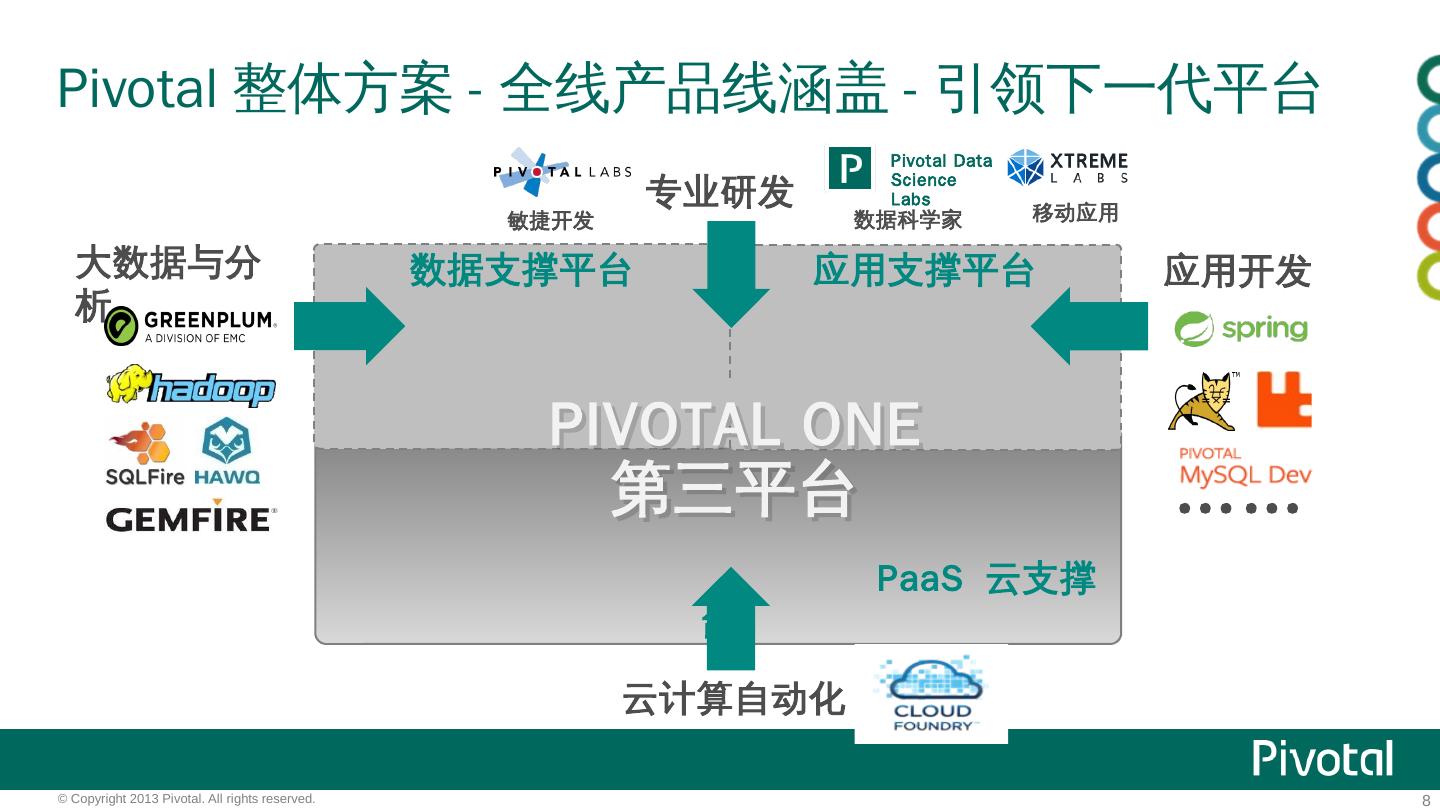
8 . PaaS 云支撑台 数据支撑平台 应用支撑平台 大数据与分析 应用开发 云计算自动化 专业研发 Pivotal One 第三平台 Pivotal Data Science Labs 敏捷开发 数据科学家 移动应用 …… Pivotal整体方案-全线产品线涵盖-引领下一代平台
10 .Pivotal对于大数据的理解 只有Hadoop,DB等等远远不能满足企业对于大数据的要求 Pivotal Data Labs Pivotal Big Data Suite 没有任何一个单独的大数据产品能够胜任企业的大数据处理挑战
11 .市场动态发展到数据湖阶段 传统的数据消费模式不能扩展到“大数据” 因为数据存储和处理成本高昂和复杂,在生成的有效数据中,只有非常少的一部分被实际利用 访问“原子 ” 水平的原始数据非常困难 现有的关系型数据库管理系统在存储非结构化数据方面效果不佳 新型的数据源 不适用传统的存储范例
12 .数据湖 将交易数据同结构化 / 半结构化 / 非结构化数据融入共存的环境之中 Analyze & Report Client/Portal Device Data Security, Backup Structured, Semi-Structured & Unstructured Data Transactional Data Data Transformation Client/Portal Devices Analyze & Report Enterprise DWH ETL/ELT CRM ERP OLTP DB Hadoop Based Data Lake
13 .World’s Leading Experts Pivotal Labs – Pivotal Data Labs On Demand Services Pivotal Data Dispatch BATCH Process ( Hadoop ) BATCH Process ( Hadoop ) Agile Analytic Agile Analytic ( Hadoop ) HAWQ Greenplum DB Pivotal HD REAL TIME Analytic REAL TIME Analytic ( Hadoop ) GemFire XD GemFire Pivotal Big Data Suite 我们推出 BigData Suite
14 .Machine latency Interactive reports Batch processing Human interactions Milliseconds Seconds Seconds, Minutes Minutes, Hours 分布式流计算, MPP DB Real-time analytic/ 目前Hadoop中 只有Hbase可以做简单实时查询 复杂类实时查询无法实现 MPP/SQL on Hadoop Near-real-time analytic 涵盖大数据处理各个细分领域 MapReduce offline analytic/ 目前Hadoop MR, Hive可实现 GAP,目前单纯和开源的 Hadoop平台无法满足 * Fire* *GP*,HAWQ *GP*,HAWQ HAWQ,PHD
15 .Pivotal 大数据套件 对企业用户的价值 Pivotal 大数据套件 全新商务模式保证客户投资保护 灵活配置模式从容应对未来的数据处理的不确 定性挑战 统一集成平台完成各种大数据数据分析处理 要求 大量国内各行业客户 同行业大数据建设经验借鉴 Pivotal BigData Suite Gemfire
18 .Pivotal整体数据架构的实现 全分布式,涵盖数据处理的各个领域,BDS内部产品无缝集成,数据自由交换 时 时
19 .Greenplum 数据库:极 速分析平台 并行处理架构 MPP shared-nothing 架构,基于通用 X86 平台 PB 级以上海量存储,最大支持 10000 节点以上 所有节点并发 IO ,实现超大 IO 吞吐,并行运行 SQL 自动化并行且简单 自动化并行计算 , 实现超大计算能力 使用同传统 DB 一样,加载和运行 SQL 数据多节点分布及高可用性都由 DB 自身实现 极佳的横向扩展性 在线横向扩展 容量、加载和 SQL 查询性能随节点线性增加 专为 BI 及数据分析优化 深度整合统计数学模块( SAS,SOLR,MADLIB,R ) 高性能并行 SQL 执行器 MPP shared-nothing 架构 构建在 X86 开放平台上的并行处理架构
20 .Greenplum 数据 处理 架构 SUN HP IBM ORACLE DB2 EMC Hitachi 支持各种 数据源 抽取、转换、加载 (ETL) Informatica DataStage GoldenGate …… 分析型应用 JavaEE .Net SAP BO Tableau QlikView Cognos SAS Microstrategy Cisco 支持众多硬件平台 支持 ODBC/JDBC 等多种接口 支持各种 ETL 工具 支持 SQL 直接并行访问外部数据文件 支持外部编程直接使用 SQL 并行访问数据库 MySQL Postgres SQL Server IBM DB2 Oracle 数据文件
21 .Load Balancer Web and App Servers Application Tier Middleware Tier Database Tier OS App OS App 在 新一代数据库 NoSQL 技术 领域,利用弹性的内存数据网格计算架构,为 业务 系统提供高并发、低延迟的数据处理能力,同时保障数据的最终一致性和完整性 OS App OS App OS App OS App OS App OS App Memory Tier Data Grid in Memory
22 .GemFire :产品竞争优势 工业标准的 X86 平台 服务器资源按需分配,按需搭建集群,按需缩放集群规模 兼容 SQL-92 标准,支持 SQL 直接操作内存数据库数据 支持应用程序通过 JDBC 、 ODBC 、等编程接口访 问内存数据库 开放弹性集群 在线线 性扩展 持续安全可用 标准 SQL 访问 极速内存处理 面向高并发、高时效的 OLTP 、 OLAP 应用 多级缓存机制 在内存中完成所有数据处理,获得最的性 能 增加节点可线性增加存储、查询和加载性能 扩容后数据自动在所有节点上重新分布 多个数据备份 数据自动同步 数据可以写入磁盘,并支持数据库和文件多种介质,写入操作可以同步进行,也可以滞后进行 跨广域网分布 GemFire 数据库集群支持跨广域网 部署,实现双活体系或灾备体系 自动实现数据同步 自动实现冲突检测和冲突解决 .
23 .全新的实时计算和深度高性能分析 on HADOOP HAWQ & GemFire XD on Pivotal Hadoop HDFS HBase Pig, Hive, Mahout Map Reduce Sqoop Flume Resource Management & Workflow Yarn Zookeeper Apache Pivotal Command Center Configure, Deploy, Monitor, Manage Data Loader Pivotal HD Enterprise Spring Unified Storage Service Xtension Framework Catalog Services Query Optimizer Dynamic Pipelining ANSI SQL + Analytics HAWQ – Advanced Database Services Hadoop Virtualization Extension Distrubuted In-memory Store Query Transactions Ingestion Processing Hadoop Driver – Parallel with Compaction ANSI SQL + In-Memory GemFire XD – Real-Time Database Services MADlib Algorithms
24 .HAWQ: SQL on Hadoop方案之中的明珠 高性能SQL查询处理 PB级别的横向扩展能力 标准ANSI SQL的真正支持 可编程的分析能力 企业级别的数据库服务 列式存储 与压缩 工作负载管理 全套的数据管理方案 无共享全分布式并发加载能力 多层次与级别的数据分区功能 3 rd 方的各种工具和报表集成互操作能力
25 .SQL支持能力比较 – HAWQ与其他对比 TPCDS 总共111条Query, 下面是不做任何更改的优化和执行能力
26 .Performance – HAWQ vs. Impala
28 .资料汇总 Web & App Servers N > 100 Web 服务器集群 应用 服务器集群 数据库 ( x86) SQL 语句抽取 Rabbit MQ (x86) 集群 数据同 步 Gemfire 服务器 (x86) 集群 > 5 . . . 28 个局 实时 数据流 数据分流 云应用系统设计结构 实时数据 复制 实时数据 复制 中央数据库 小型机 数据库小型机 N > 5 数据库小型机 M > 50 12306 网上订票系统架构改造 原有系统只做热备
29 . 单次查询耗时 15 秒 左右 无法支持高流量并发查询,只能通过分库来实现, 在极端高流量并发情况,系统无法支撑 高峰期间无法访问,也无法动态增加机器来应当 运行在 UNIX 小型机 单次订票查询最长耗时 150-200 毫秒, 单次查询最短耗时 1-2 毫秒。 提高 100 倍 -1000 倍 支 持 每秒上万次的并发查询,高峰期间 2.6 万个并发 / 秒,查询速度依然是平均 200 毫秒左右 按需弹性动态扩展,并发量增加还可以动态增加机器应对,同步 实时变化的数据耗时秒 级 运行在 Linux X86 服务器集群 12306 改造后 12306 改造之前 改造后取得的效果 — 来自 网上订票系统实际运行数据