


































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Flink Big Data Stream Processing
Apache Flink Big Data Stream Processing
• Background & APIs (-> Polystore functionality)
• Execution Engine
• Some key features
Stream Processing with Apache Flink
• Key features
展开查看详情
1 . Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de | bbdc.berlin | rabl@tu-berlin.de XLDB – 11.10.2017 1 © 2013 Berlin Big Data Center • All Rights Reserved © DIMA 2017
2 . Agenda Disclaimer: I am neither a Flink developer nor affiliated with data Artisans. 2 2 © DIMA 2017
3 . Agenda Flink Primer • Background & APIs (-> Polystore functionality) • Execution Engine • Some key features Stream Processing with Apache Flink • Key features With slides from data Artisans, Volker Markl, Asterios Katsifodimos 3 3 © DIMA 2017
4 . Flink Timeline 4 © 2013 Berlin Big Data Center • All Rights Reserved 4 © DIMA 2017
5 . Stratosphere: General Purpose Programming + Database Execution Draws on Adds Draws on Database Technology MapReduce Technology • Relational Algebra • Iterations • Scalability • Declarativity • Advanced Dataflows • User-defined • Query Optimization • General APIs Functions • Robust Out-of-core • Native Streaming • Complex Data Types • Schema on Read 5 © DIMA 2017
6 . The APIs Analytics Stream SQL Stream- & Table API (dynamic tables) Batch Processing 6 Stateful DataStream API (streams, windows) Event-Driven Applications Process Function (events, state, time) 6 © 2013 Berlin Big Data Center • All Rights Reserved 6 © DIMA 2017
7 . Process Function class MyFunction extends ProcessFunction[MyEvent, Result] { // declare state to use in the program lazy val state: ValueState[CountWithTimestamp] = getRuntimeContext().getState(…) def processElement(event: MyEvent, ctx: Context, out: Collector[Result]): Unit = { // work with event and state (event, state.value) match { … } out.collect(…) // emit events state.update(…) // modify state // schedule a timer callback ctx.timerService.registerEventTimeTimer(event.timestamp + 500) } def onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[Result]): Unit = { // handle callback when event-/processing- time instant is reached } } 7 © 2013 Berlin Big Data Center • All Rights Reserved 7 7 © DIMA 2017
8 . Data Stream API val lines: DataStream[String] = env.addSource( new FlinkKafkaConsumer09<>(…)) val events: DataStream[Event] = lines.map((line) => parse(line)) val stats: DataStream[Statistic] = stream .keyBy("sensor") .timeWindow(Time.seconds(5)) .sum(new MyAggregationFunction()) stats.addSink(new RollingSink(path)) 8 © 2013 Berlin Big Data Center • All Rights Reserved 8 8 © DIMA 2017
9 . Table API & Stream SQL 9 © 2013 Berlin Big Data Center • All Rights Reserved 9 9 © DIMA 2017
10 . What can I do with it? Batch Machine Learning at scale processing Stream processing Complex event Graph Analysis processing Flink An engine that can natively support all these workloads. 10 © 2013 Berlin Big Data Center • All Rights Reserved 10 © DIMA 2017
11 . Flink in the Analytics Ecosystem Hive Cascading Giraph Applications & Languages Mahout Pig Crunch MapReduce Flink Data processing engines Spark Storm Tez App and resource Yarn Mesos management HDFS HBase Kafka … Storage, streams 11 11 © 2013 Berlin Big Data Center • All Rights Reserved 11 © DIMA 2017
12 . Where in my cluster does Flink fit? Gathering Integration Analysis Server Upstream logs systems Trxn logs Sensor logs - Gather and backup streams - Analyze and correlate streams - Offer streams for consumption - Create derived streams and state - Provide stream recovery - Provide these to upstream systems 12 © DIMA 2017
13 . Architecture • Hybrid MapReduce and MPP database runtime • Pipelined/Streaming engine – Complete DAG deployed Worker 1 Worker 2 Job Manager Worker 3 Worker 4 13 13 © DIMA 2017
14 . Flink Execution Model • Flink program = DAG* of operators and intermediate streams • Operator = computation + state • Intermediate streams = logical stream of records 14 14 © DIMA 2017
15 . Technology inside Flink case class Path (from: Long, to: GroupRed Long) sort val tc = edges.iterate(10) { Type extraction Dataflow paths: DataSet[Path] => stack val next = paths forward Graph .join(edges) Join Hybrid Hash .where("to") Cost-based build probe .equalTo("from") { HT (path, edge) => optimizer hash-part [0] hash-part [0] Path(path.from, edge.to) Map DataSourc e } Filter lineitem.tbl .union(paths) .distinct() Pre-flight (Client) DataSourc e orders.tbl next } Program deploy operators Recovery Memory Out-of-core manager algorithms metadata Task Batch & State & streaming checkpoints track scheduling intermediate results Master Workers 15 © 2013 Berlin Big Data Center • All Rights Reserved 15 © DIMA 2017
16 . Rich set of operators Map, Reduce, Join, CoGroup, Union, Iterate, Delta Iterate, Filter, FlatMap, GroupReduce, Project, Aggregate, Distinct, Vertex-Update, Accumulators, … 1616 16 © DIMA 2017
17 . Effect of optimization Hash vs. Sort Partition vs. Broadcast Caching Execution Reusing partition/sort Plan A Execution Execution Plan C Plan B Run on a sample on the laptop Run on large files Run a month later on the cluster after the data evolved 17 17 17 © DIMA 2017
18 . Flink Optimizer Transitive Closure Co-locate DISTINCT + JOIN replace Iterate Iterate Forward Hybrid Hash Join Group Reduce (Sorted (on [0])) HDF new Distinc Paths Join Union S Co-locate JOIN + UNION Hash Partitionton [1] Hash Partition on [1] Step function Hash Partition on [0] paths Loop-invariant data cached in memory • What you write is not what is executed • Flink Optimizer decides: • No need to hardcode execution strategies – Pipelines and dam/barrier placement – Sort- vs. hash- based execution – Data exchange (partition vs. broadcast) – Data partitioning steps – In-memory caching 18 18 © DIMA 2017
19 . Scale Out 1919 19 © DIMA 2017
20 . Stream Processing with Flink 20 © DIMA 2017
21 . 8 Requirements of Big Streaming • Keep the data moving • Integrate stored and streaming data – Streaming architecture – Hybrid stream and batch • Declarative access • Data safety and availability – E.g. StreamSQL, CQL – Fault tolerance, durable state • Handle imperfections • Automatic partitioning and scaling – Late, missing, unordered items – Distributed processing • Predictable outcomes • Instantaneous processing and – Consistency, event time response The 8 Requirements of Real-Time Stream Processing – Stonebraker et al. 2005 21 21 © DIMA 2017
22 . 8 Requirements of Streaming Systems • Keep the data moving • Integrate stored and streaming data – Streaming architecture – Hybrid stream and batch – see StreamSQL • Declarative access • Data safety and availability – E.g. StreamSQL, CQL – Fault tolerance, durable state • Handle imperfections • Automatic partitioning and scaling – Late, missing, unordered items – Distributed processing • Predictable outcomes • Instantaneous processing and – Consistency, event time response The 8 Requirements of Real-Time Stream Processing – Stonebraker et al. 2005 22 22 © DIMA 2017
23 . How to keep data moving? Discretized Streams (mini-batch) Stream discretizer while (true) { Job Job Job Job // get next few records // issue batch computation } Native streaming Long-standing while (true) { operators // process next record } 23 23 © DIMA 2017
24 . Declarative Access – Stream SQL Stream / Table Duality Table without Primary Key Table with Primary Key 24 © 2013 Berlin Big Data Center • All Rights Reserved 24 24 © DIMA 2017
25 . Handle Imperfections - Event Time et al. • Event time – Data item production time • Ingestion time – System time when data item is received • Processing time – System time when data item is processed • Typically, these do not match! • In practice, streams are unordered! Image: Tyler Akidau 25 25 © DIMA 2017
26 . Time: Event Time Example Event Time Episode Episode Episode Episode Episode Episode Episode IV V VI I II III VII 1977 1980 1983 1999 2002 2005 2015 Processing Time 26 © 2013 Berlin Big Data Center • All Rights Reserved 26 26 © DIMA 2017
27 . Flink’s Windowing • Windows can be any combination of (multiple) triggers & evictions – Arbitrary tumbling, sliding, session, etc. windows can be constructed. • Common triggers/evictions part of the API – Time (processing vs. event time), Count • Even more flexibility: define your own UDF trigger/eviction • Examples: dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))); dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5))); • Flink will handle event time, ordering, etc. 27 27 © DIMA 2017
28 . Example Analysis: Windowed Aggregation (2) StockPrice(HDP, 23.8) StockPrice(SPX, 2113.9) (1) StockPrice(FTSE, 6931.7) StockPrice(SPX, 2113.9) StockPrice(HDP, 23.8) (3) StockPrice(FTSE, 6931.7) StockPrice(HDP, 26.6) StockPrice(HDP, 26.6) StockPrice(SPX, 2113.9) (4) StockPrice(FTSE, 6931.7) StockPrice(HDP, 25.2) (1) val windowedStream = stockStream.window(Time.of(10, SECONDS)).every(Time.of(5, SECONDS)) (2) val lowest = windowedStream.minBy("price") (3) val maxByStock = windowedStream.groupBy("symbol").maxBy("price") (4) val rollingMean = windowedStream.groupBy("symbol").mapWindow(mean _) 28 © DIMA 2017
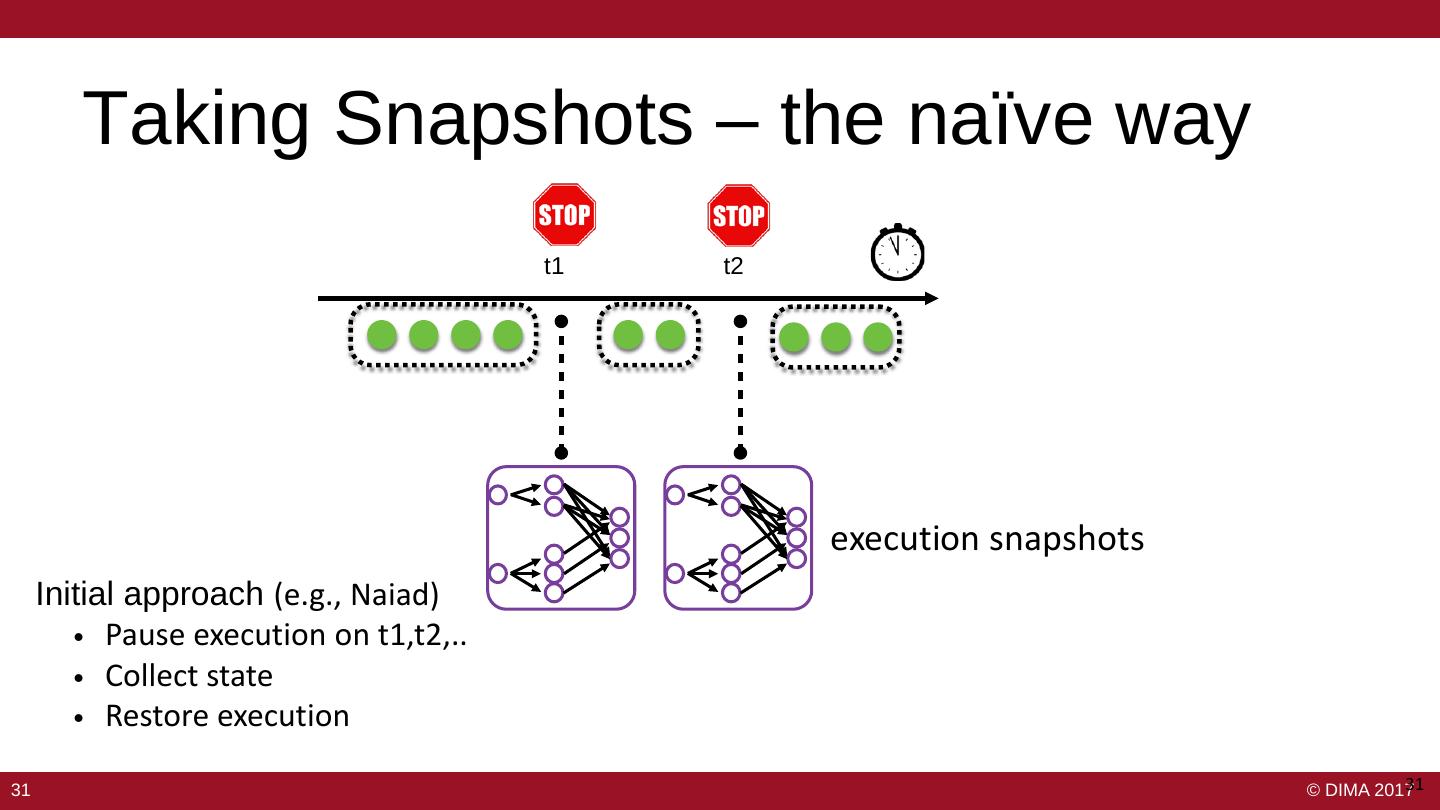
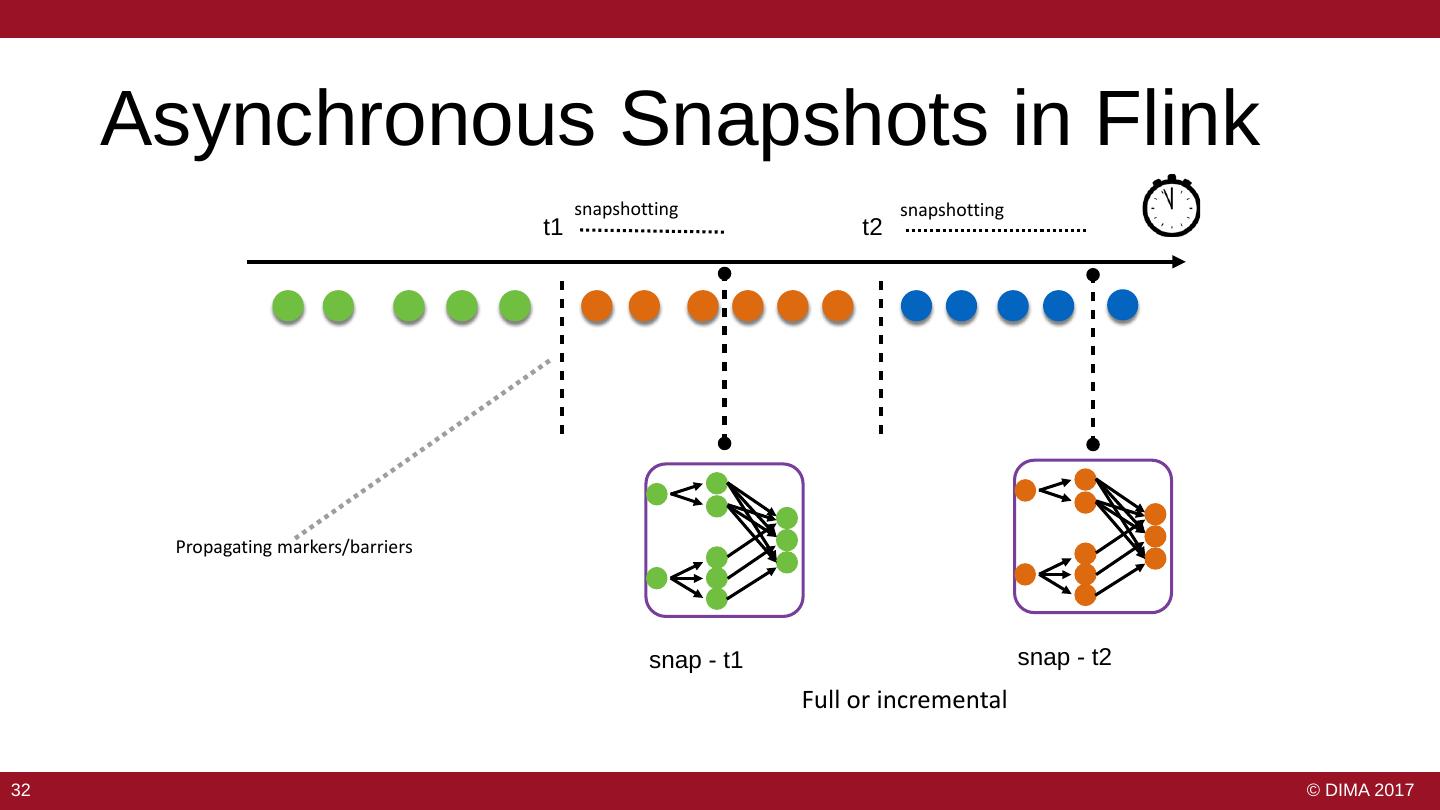
29 . Data Safety and Availability • Ensure that operators see all events – “At least once” – Solved by replaying a stream from a checkpoint – No good for correct results • Ensure that operators do not perform duplicate updates to their state – “Exactly once” – Several solutions • Ensure the job can survive failure 2929 29 © DIMA 2017
3秒后跳转登录页面
去登陆

