































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
10_physics_data_analytics
Physics Data Analytics and Data Reduction with Apache Spark
展开查看详情
1 . Physics Data Analytics and Data Reduction with Apache Spark Evangelos Motesnitsalis 11 October 2017 1
2 .Contents 1. Goal 2. Motivation and Vision 3. Collaboration Members 4. Standard HEP Analysis Procedures 5. Progress • Read Files in ROOT Format directly from Spark • Access files stored in EOS directly from Spark/Hadoop 6. Planned Architecture Overview 7. Demo 8. Future Steps 9. Summary and Outlook Evangelos Motesnitsalis 2
3 .Goal Evangelos Motesnitsalis 3
4 .Goal “to perform Physics Analysis and Data Reduction with Big Data Technologies over data acquired from the CMS Experiment” Evangelos Motesnitsalis 4
5 .Motivation and Vision Why Data Analytics and Reduction with Spark? Evangelos Motesnitsalis 5
6 .Motivation and Vision Why Data Analytics and Reduction with Spark? • Investigate new ways to analyse physics data and improve resource utilization and time-to-physics Evangelos Motesnitsalis 6
7 .Motivation and Vision Why Data Analytics and Reduction with Spark? • Investigate new ways to analyse physics data and improve resource utilization and time-to-physics • Adopt new technologies widely used in the industry • Open the HEP field to a larger community of data scientists • Improve chance of researchers on the job market outside academia Evangelos Motesnitsalis 7
8 .Collaboration Members Who is participating? Evangelos Motesnitsalis 8
9 .Collaboration Members Who is participating? • CERN IT Department (openlab and IT-DB) • The CMS Experiment • Intel Evangelos Motesnitsalis 9
10 .Standard HEP Analysis Procedures How is Physics Analysis done currently? Evangelos Motesnitsalis 10
11 .Standard HEP Analysis Procedures How is Physics Analysis done currently? Until today, the vast majority of high energy physics analysis is done with the ROOT Framework which uses physics data that are stored in ROOT format files, within the EOS Storage Service of CERN. Evangelos Motesnitsalis 11
12 .Standard HEP Analysis Procedures How is Physics Analysis done currently? Until today, the vast majority of high energy physics analysis is done with the ROOT Framework which uses physics data that are stored in ROOT format files, within the EOS Storage Service of CERN. ROOT Data Analysis Framework A modular scientific software framework which provides all the functionalities needed to deal with big data processing, statistical analysis, visualization and file storage. It is mainly written in C++ but also integrated with Python and R. Evangelos Motesnitsalis 12
13 .Standard HEP Analysis Procedures How is Physics Analysis done currently? Until today, the vast majority of high energy physics analysis is done with the ROOT Framework which uses physics data that are stored in ROOT format files, within the EOS Storage Service of CERN. ROOT Data Analysis Framework A modular scientific software framework which provides all the functionalities needed to deal with big data processing, statistical analysis, visualization and file storage. It is mainly written in C++ but also integrated with Python and R. EOS Service A disk-based, low-latency storage service with a highly-scalable hierarchical namespace, which enables data access through the XROOT protocol. It provides storage for both physics and user use cases via different service instances such as EOSPUBLIC, EOSATLAS, EOSCMS. Evangelos Motesnitsalis 13
14 .Progress What has been done to date? Evangelos Motesnitsalis 14
15 .Progress What has been done to date? Two Main Challenges have been solved: 1. Read files in ROOT Format using Spark 2. Access files stored in EOS directly from Hadoop/Spark Evangelos Motesnitsalis 15
16 .Progress What has been done to date? Two Main Challenges have been solved: 1. Read files in ROOT Format using Spark 2. Access files stored in EOS directly from Hadoop/Spark We now have fully functioning Analysis & Reduction examples tested over CMS Open Data (1 TB) Evangelos Motesnitsalis 16
17 .1. Read Files in ROOT Format directly from Spark DIANA-HEP developed “spark-root” A Scala library which implements DataSource for Apache Spark Spark can read ROOT TTrees and infer their schema Root files are imported to Spark Dataframes/Datasets/RDDs Evangelos Motesnitsalis 17
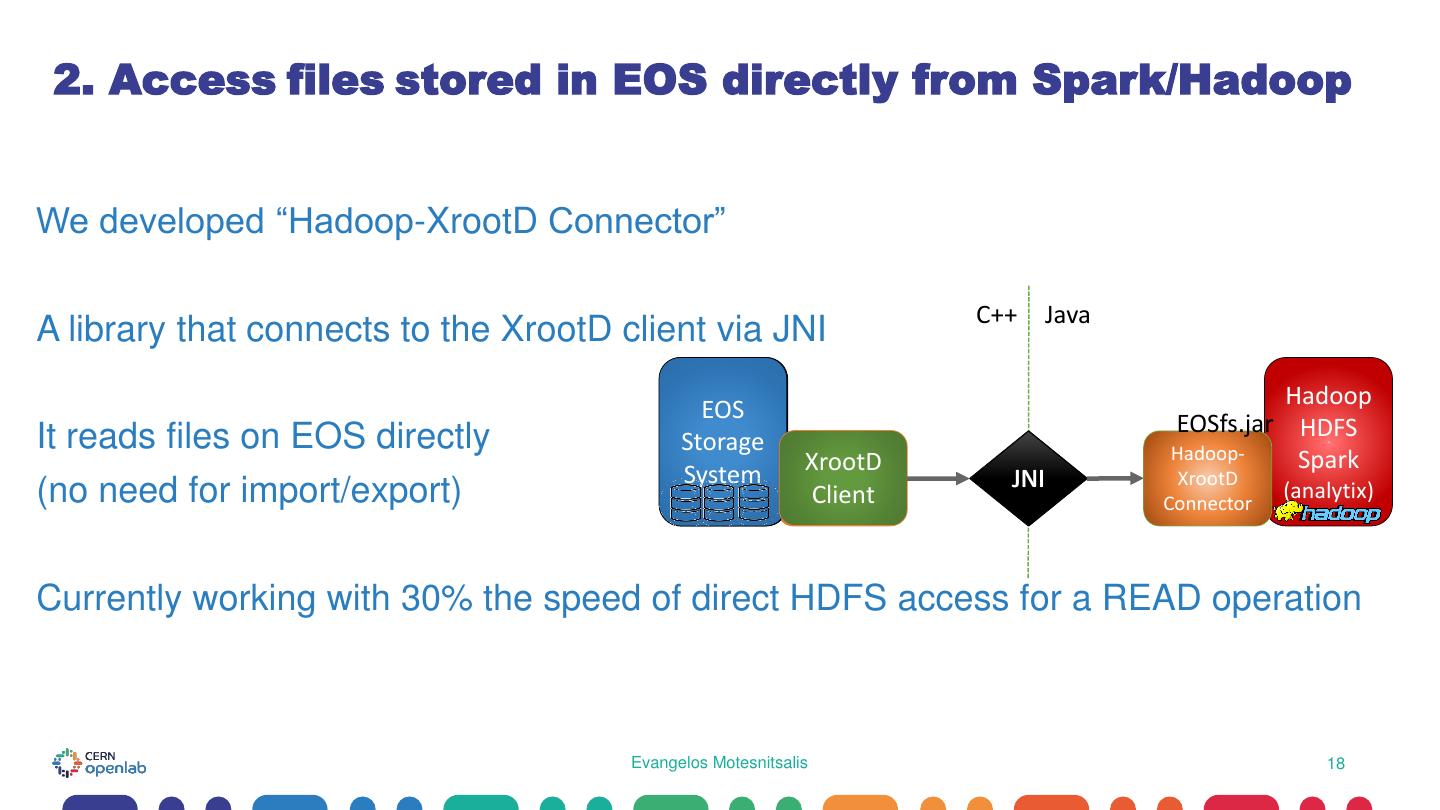
18 . 2. Access files stored in EOS directly from Spark/Hadoop We developed “Hadoop-XrootD Connector” C++ Java A library that connects to the XrootD client via JNI Hadoop EOS EOSfs.jar HDFS It reads files on EOS directly Storage Hadoop- XrootD Xrootd Spark System JNI XrootD (no need for import/export) Client Connector (analytix) Currently working with 30% the speed of direct HDFS access for a READ operation Evangelos Motesnitsalis 18
19 .Planned Architecture Overview What is the long term goal? Evangelos Motesnitsalis 19
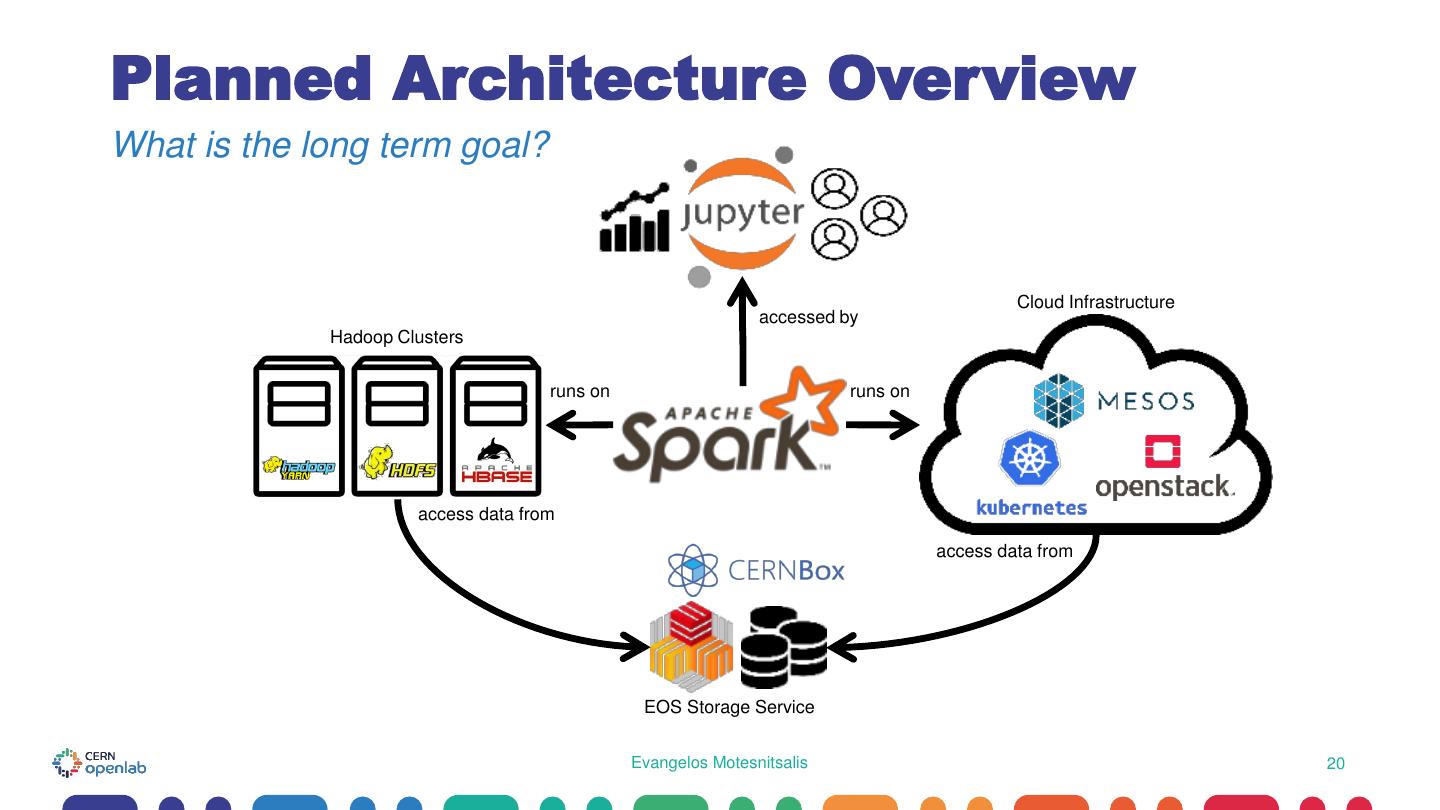
20 .Planned Architecture Overview What is the long term goal? Cloud Infrastructure accessed by Hadoop Clusters runs on runs on access data from access data from EOS Storage Service Evangelos Motesnitsalis 20
21 .Lightning Demo Evangelos Motesnitsalis 21
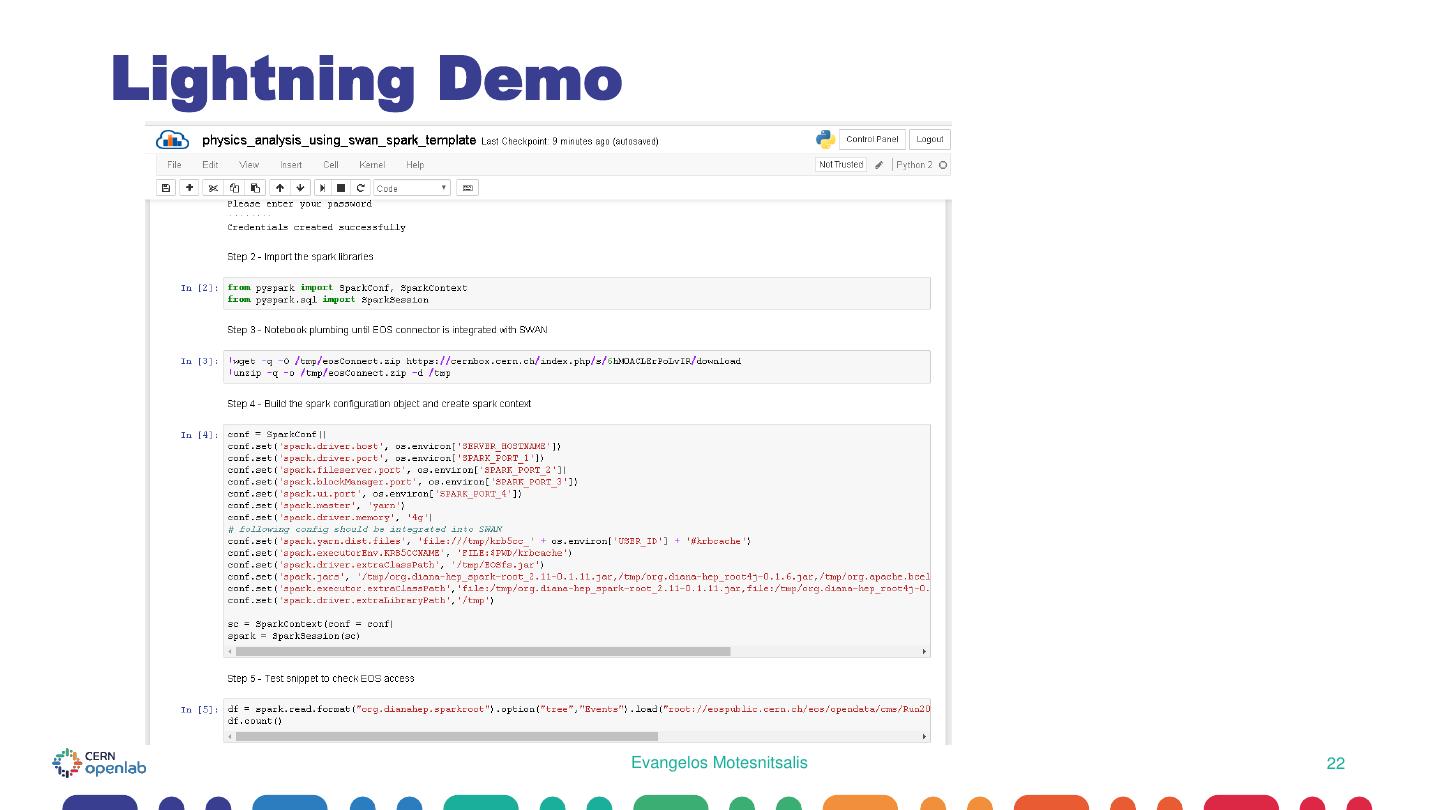
22 .Lightning Demo Evangelos Motesnitsalis 22
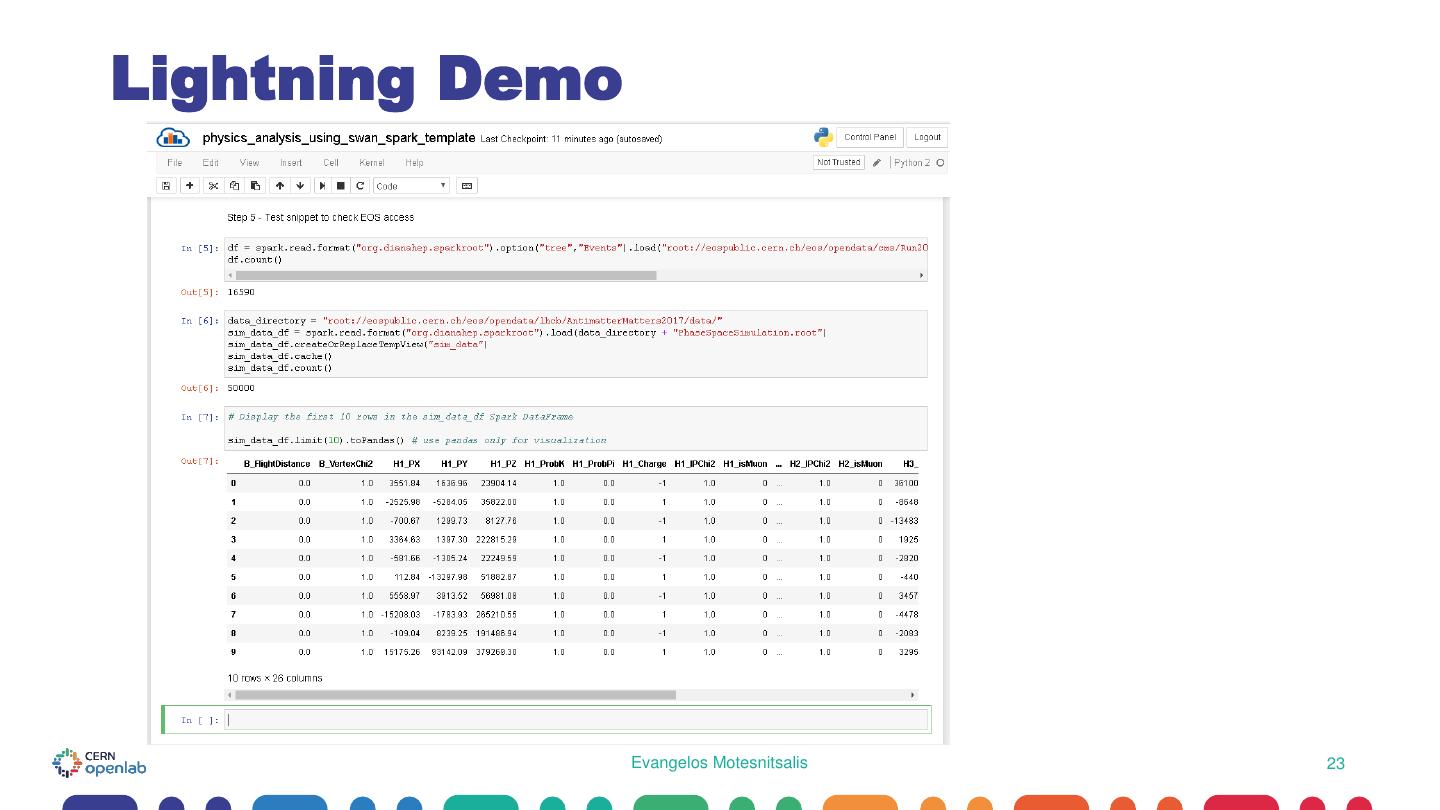
23 .Lightning Demo Evangelos Motesnitsalis 23
24 .Future steps What is next? Evangelos Motesnitsalis 24
25 . Future steps What is next? Hadoop-XrootD Connector: • Add GRID Authentication alongside with Kerberos • Introduce optimizations and tuning to decrease the performance gap between EOS and HDFS Evangelos Motesnitsalis 25
26 . Future steps What is next? Hadoop-XrootD Connector: • Add GRID Authentication alongside with Kerberos • Introduce optimizations and tuning to decrease the performance gap between EOS and HDFS spark-root: • Implement the ability to write to ROOT files • Add IO statistics support Evangelos Motesnitsalis 26
27 . Future steps What is next? Hadoop-XrootD Connector: • Add GRID Authentication alongside with Kerberos • Introduce optimizations and tuning to decrease the performance gap between EOS and HDFS spark-root: • Implement the ability to write to ROOT files • Add IO statistics support Investigate scaling behavior for larger input (goal is 1 PB) Evangelos Motesnitsalis 27
28 . Future steps What is next? Hadoop-XrootD Connector: • Add GRID Authentication alongside with Kerberos • Introduce optimizations and tuning to decrease the performance gap between EOS and HDFS spark-root: • Implement the ability to write to ROOT files • Add IO statistics support Investigate scaling behavior for larger input (goal is 1 PB) Investigate the possibility to use Spark over Openstack Evangelos Motesnitsalis 28
29 .Summary and Outlook Evangelos Motesnitsalis 29
3秒后跳转登录页面
去登陆

