




































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
A Framework for Machine Learning and Data Mining in the Cloud
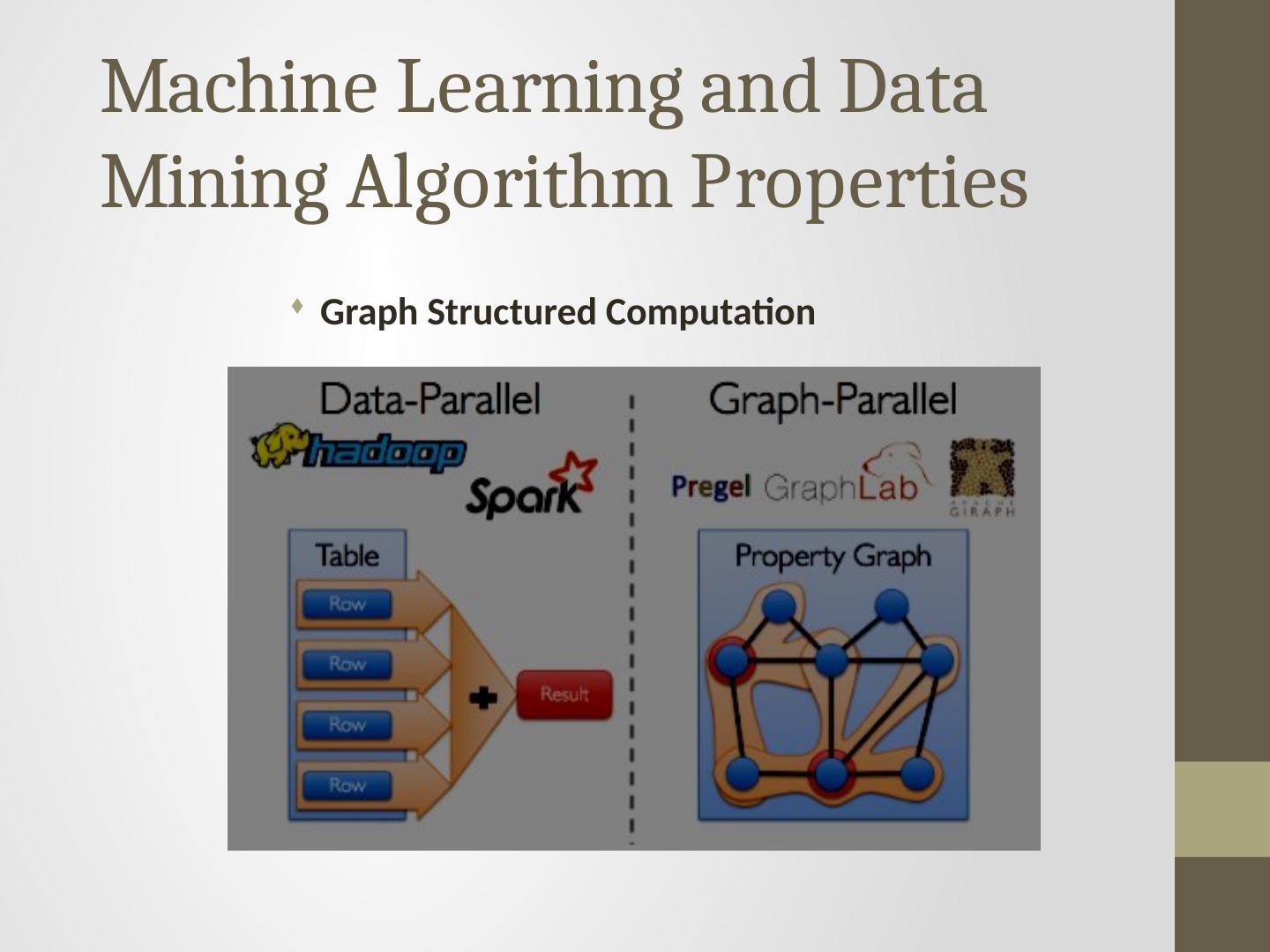
High level data parallel frameworks like MapReduce do not efficiently support many important data mining and machine learning algorithms and can lead to inefficient learning systems(Works well with independent data)
GraphLab Abstaction: expresses asynchronous, dynamic, graph parallel computation in shared memory.
展开查看详情
1 .Yucheng Low Aapo Kyrola Danny Bickson A Framework for Machine Learning and Data Mining in the Cloud Joseph Gonzalez Carlos Guestrin Joe Hellerstein
2 .2 Shift Towards Use Of Parallelism in ML ML experts repeatedly solve the same parallel design challenges: Race conditions, distributed state, communication… Resulting code is very specialized: difficult to maintain, extend, debug… GPUs Multicore Clusters Clouds Supercomputers Graduate students Avoid these problems by using high-level abstractions
3 .Abstract High level data parallel frameworks like MapReduce do not efficiently support many important data mining and machine learning algorithms and can lead to inefficient learning systems(Works well with independent data) GraphLab Abstaction : expresses asynchronous, dynamic, graph parallel computation in shared memory.
4 .Introduction Problems with distributed Machine Learning and Data Mining algorithms? How does GraphLab solves these issues? Major Contributions A summary of common properties of MLDM algorithms and the limitations of existing large-scale frameworks A modified version of the GraphLab abstraction and execution model tailored to the distributed setting
5 . Contributions .. Two substantially different approaches to implementing the new distributed execution model Chromatic Engine Locking Engine Fault tolerance through two snapshotting schemes. Implementations of three state-of-the-art machine learning algorithms on-top of distributed GraphLab . An extensive evaluation of Distributed GraphLab using a 512 processor (64 node) EC2 cluster, including comparisons to Hadoop , Pregel , and MPI implementations.
6 .Machine Learning and Data Mining Algorithm Properties Graph Structured Computation
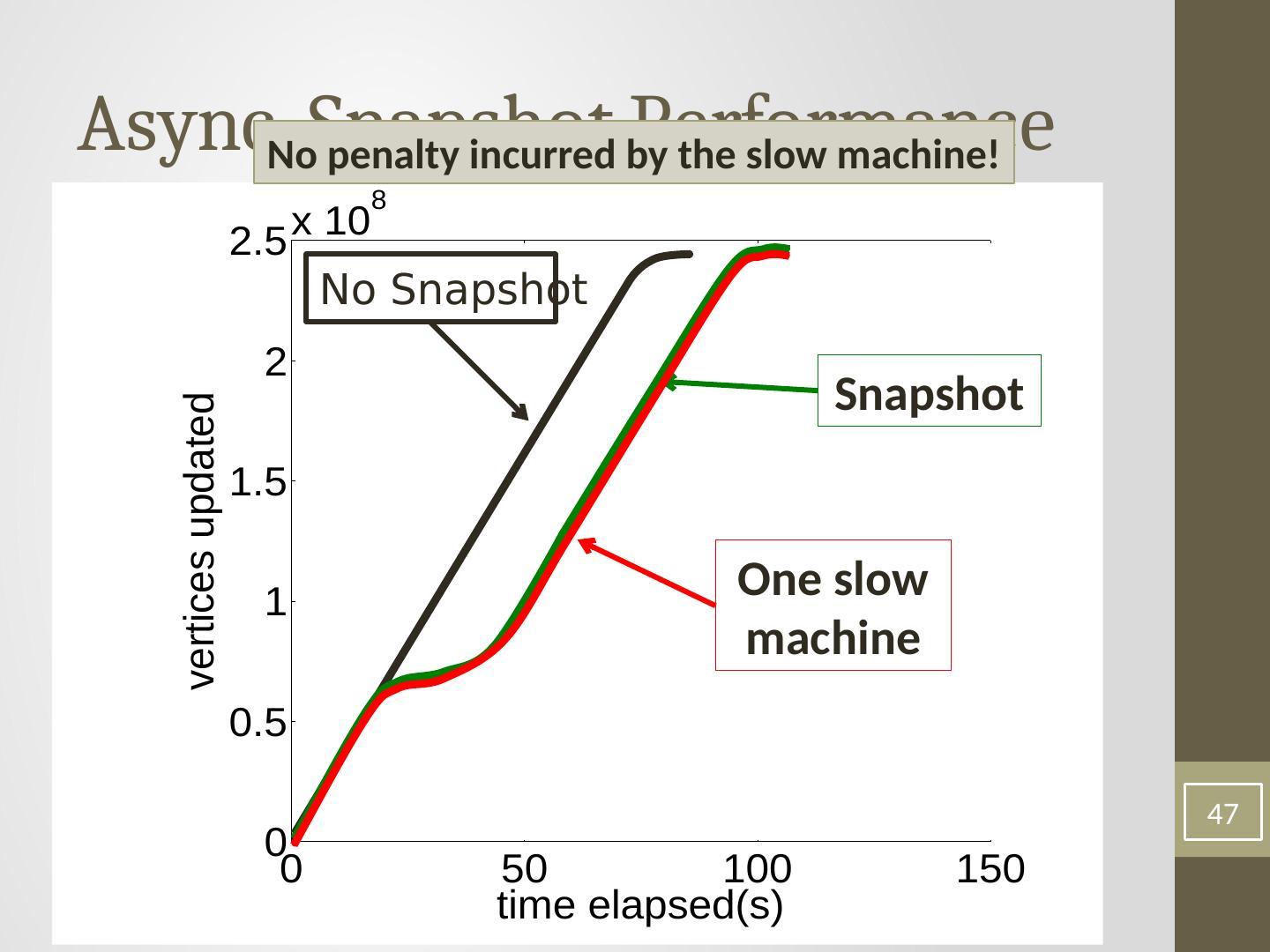
7 .Machine Learning and Data Mining Algorithm Properties Asynchronous Iterative Computation: synchronous systems update all parameters simultaneously (in parallel) using parameter values from the previous time step as input Asynchronous systems update parameters using the most recent parameter values as input.
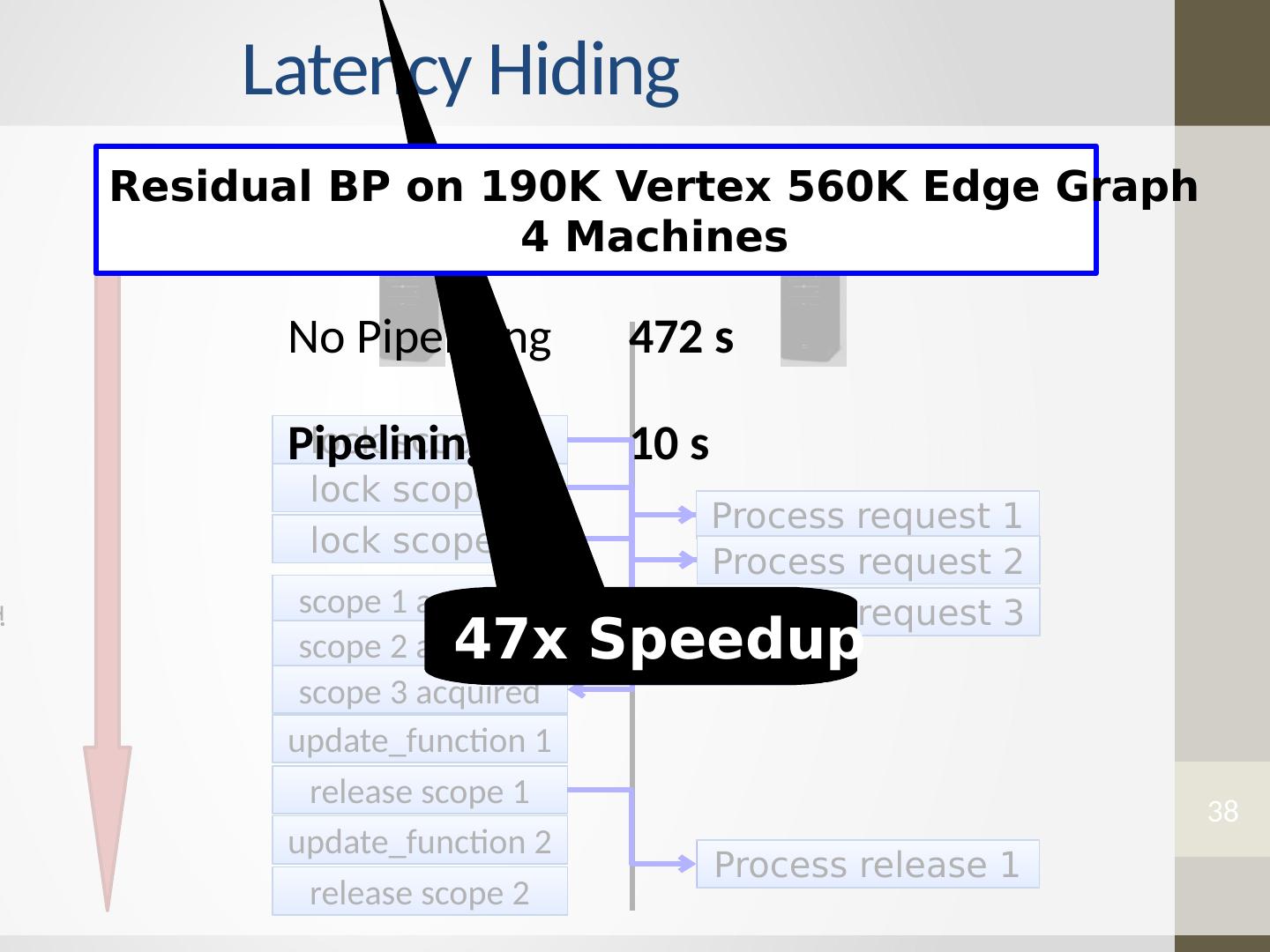
8 .Asynchronous Iterative Computation Synchronous computation incurs costly performance penalties since the runtime of each phase is determined by the slowest machine. Abstractions based on bulk data processing, such as MapReduce and Dryad were not designed for iterative computation, Spark has the iterative setting. However, these abstractions still do not support asynchronous computation. Bulk Synchronous Parallel (BSP) abstractions such as Pregel , Pic- colo , and BPGL do not naturally express asynchronicity . On the other hand, the shared memory GraphLab abstraction was designed to efficiently and naturally express the asynchronous iterative algorithms common to advanced MLDM.
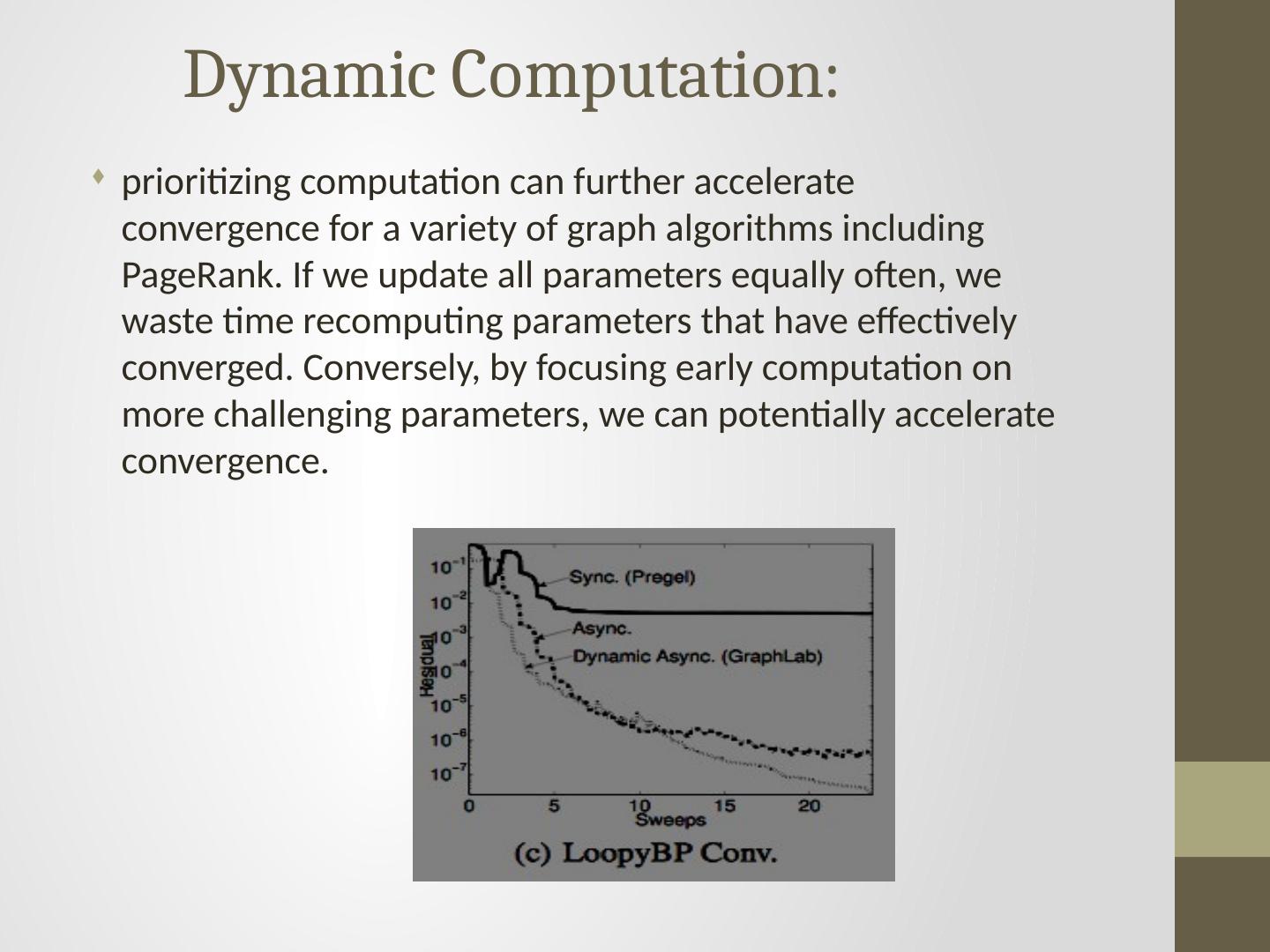
9 .Machine Learning and Data Mining Properties Dynamic Computation: In many MLDM algorithms, iterative computation converges asymmetrically.
10 . Dynamic Computation: prioritizing computation can further accelerate convergence for a variety of graph algorithms including PageRank. If we update all parameters equally often, we waste time recomputing parameters that have effectively converged. Conversely, by focusing early computation on more challenging parameters, we can potentially accelerate convergence.
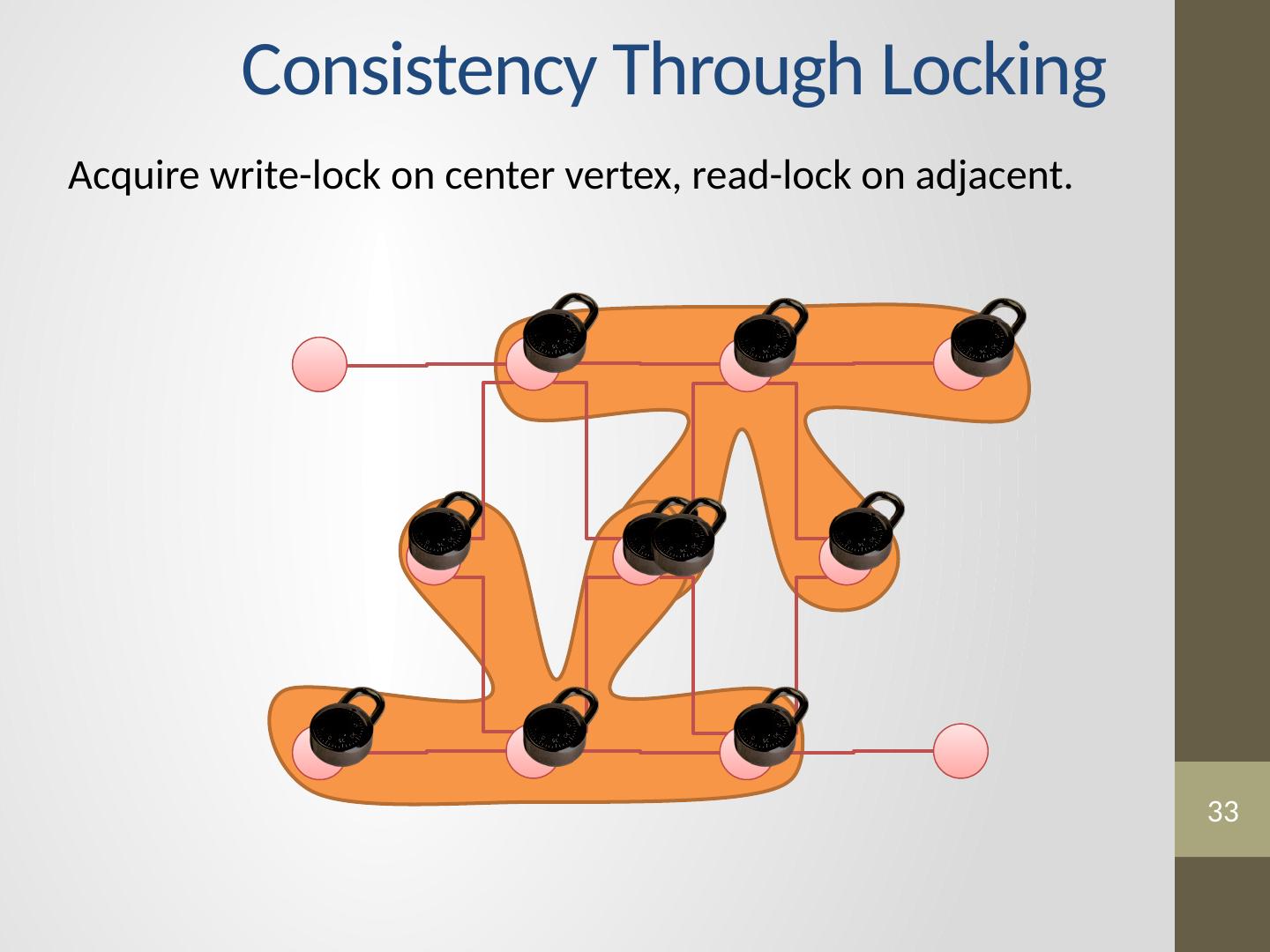
11 .Machine Learning and Data Mining Algorithm Properties Serializability : By ensuring that all parallel executions have an equivalent sequential execution, serializability eliminates many challenges associated with designing, implementing, and testing parallel MLDM algorithms. In addition, many algorithms converge faster if serializability is ensured, and some even require serializability for correctness. GraphLab supports a broad range of consistency settings, allowing a program to choose the level of consistency needed for correctness.
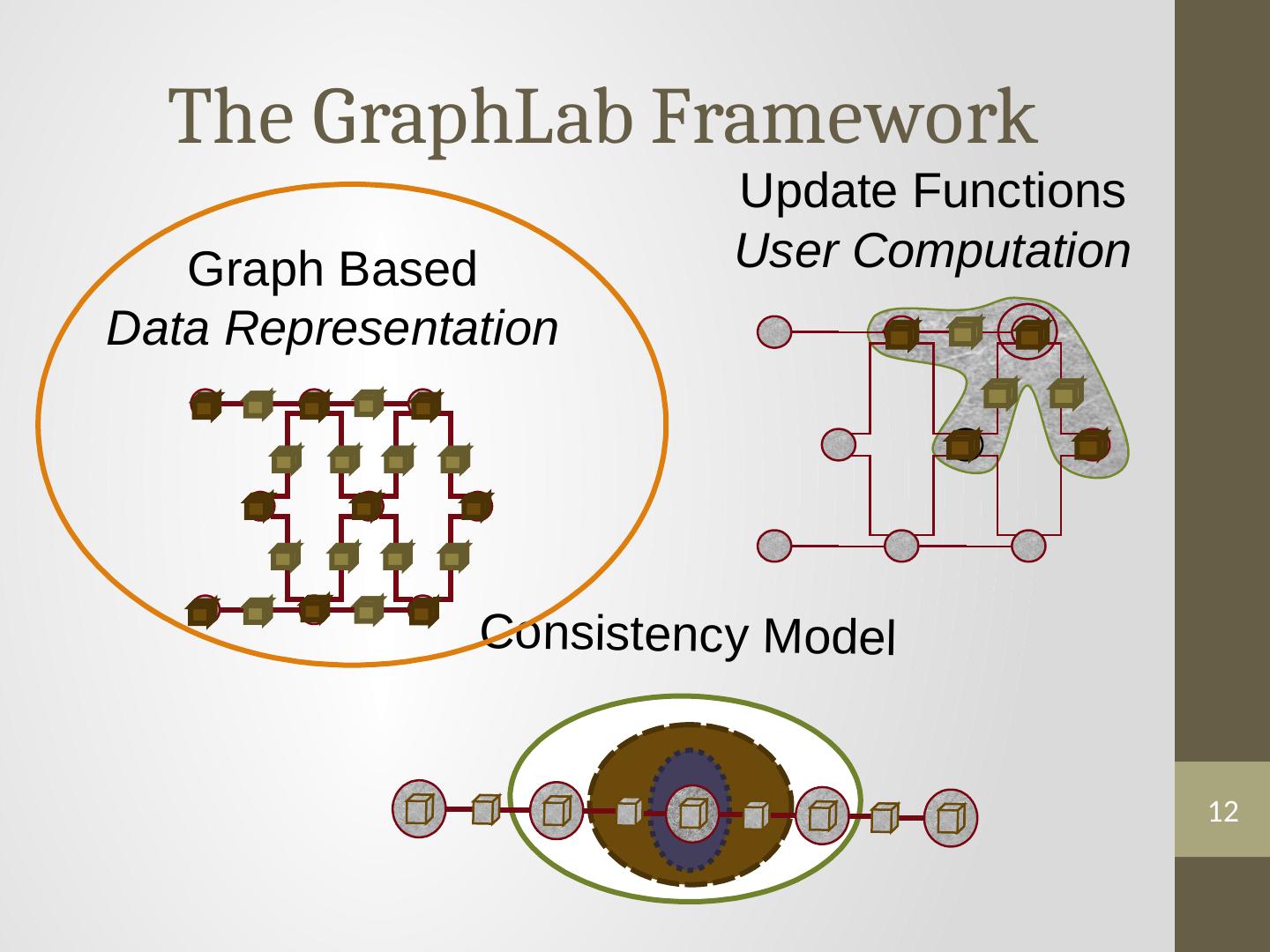
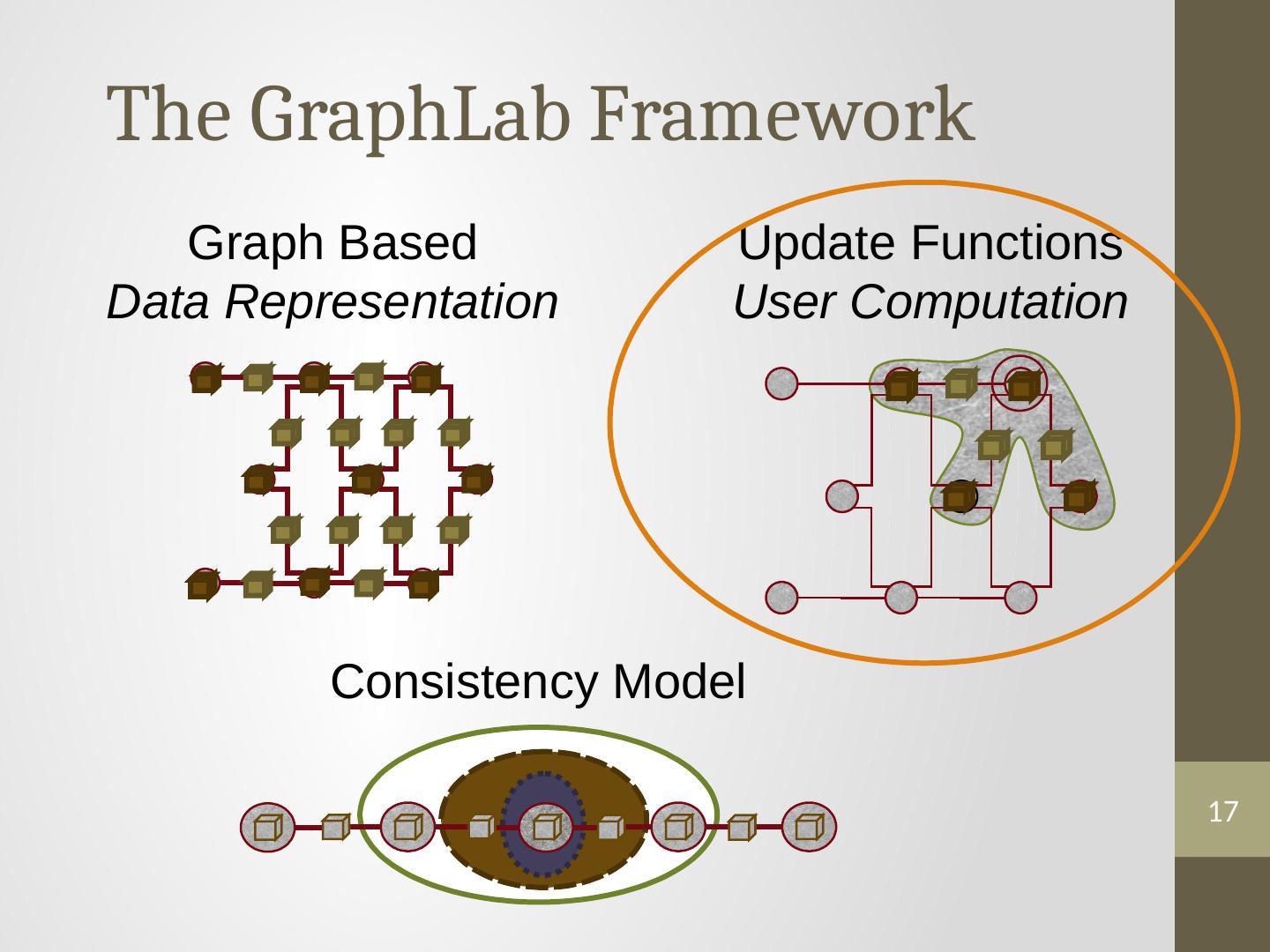
12 .12 The GraphLab Framework Consistency Model Graph Based Data Representation Update Functions User Computation
13 .Data Graph Data associated with vertices and edges Vertex Data: User profile Current interests estimates Edge Data: Relationship (friend, classmate, relative) Graph: Social Network 13
14 .Distributed Graph Partition the graph across multiple machines. 14
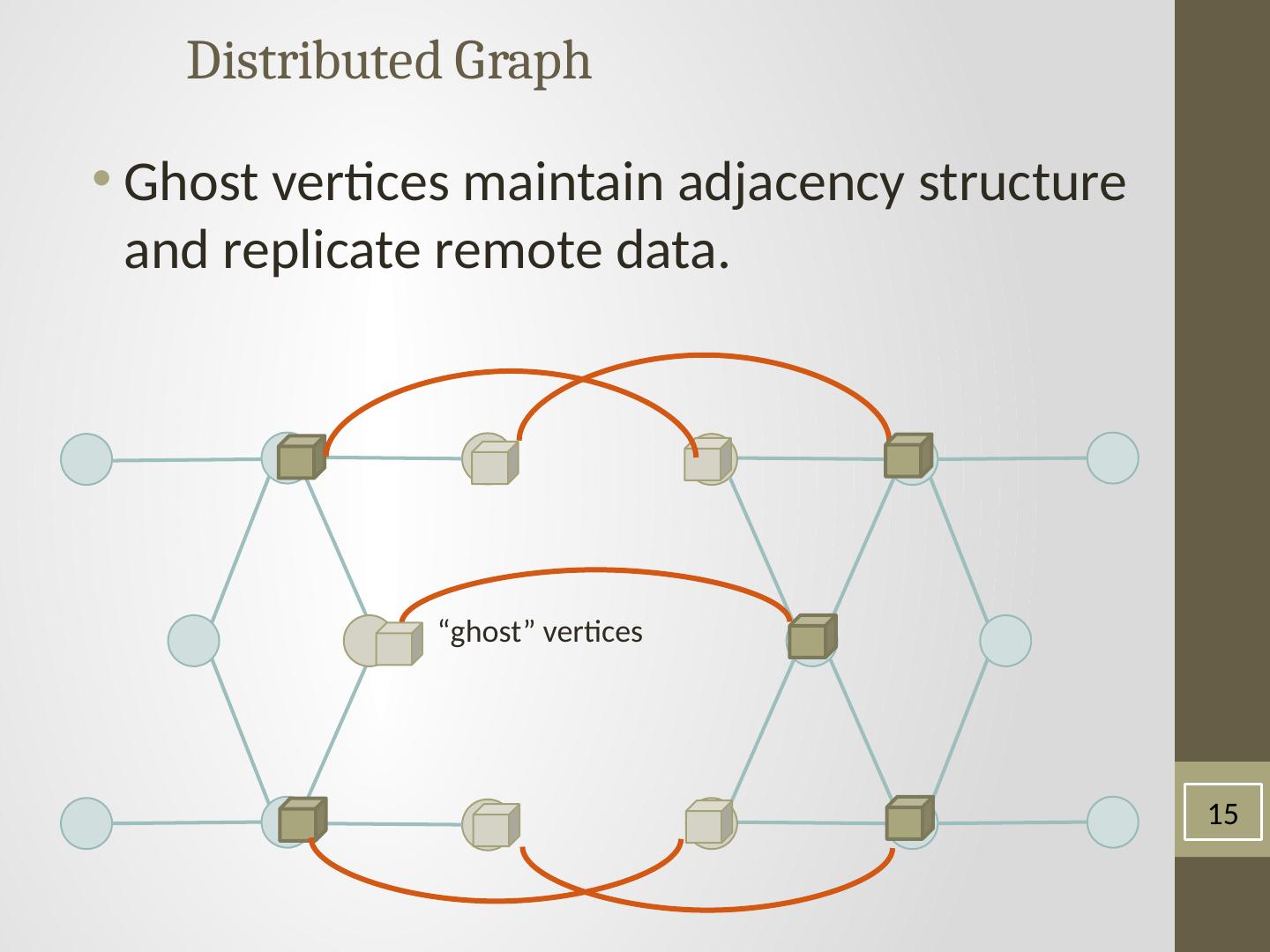
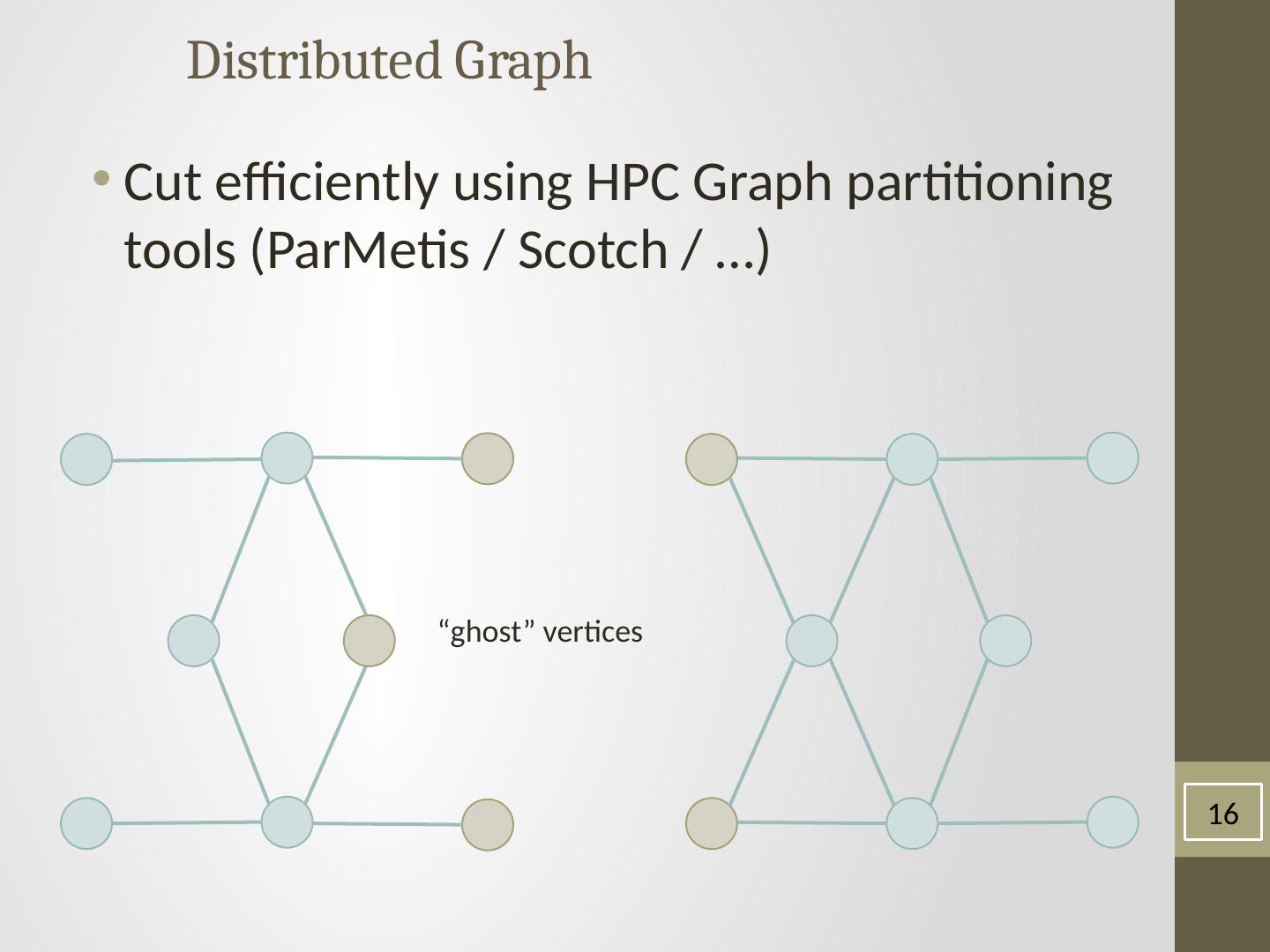
15 .Distributed Graph Ghost vertices maintain adjacency structure and replicate remote data. “ghost” vertices 15
16 .Distributed Graph Cut efficiently using HPC Graph partitioning tools ( ParMetis / Scotch / …) “ghost” vertices 16
17 .17 The GraphLab Framework Consistency Model Graph Based Data Representation Update Functions User Computation
18 .Pagerank (scope){ // Update the current vertex data // Reschedule Neighbors if needed if vertex.PageRank changes then reschedule_all_neighbors ; } Update Functions User-defined program : applied to a vertex and transforms data in scope of vertex Dynamic computation Update function applied (asynchronously) in parallel until convergence Many schedulers available to prioritize computation 18 Why Dynamic?
19 .PageRank update function Input: Vertex data R(v) from Sv Input: Edge data {w u,v : u ∈ N[v]} from Sv Input: Neighbor vertex data {R(u) : u ∈ N[v]} from Sv R old (v) ← R(v) // Save old PageRank R(v) ← α/n For each u ∈ N[v] do // Loop over neighbors R(v) ← R(v) + (1 − α) ∗ w u,v ∗ R(u) // If the PageRank changes sufficiently if |R(v) − R old (v)| > ǫ then // Schedule neighbors to be updated return {u : u ∈ N[v]} Output: Modified scope S v with new R(v)
20 .The GraphLab Execution Model Input: Data Graph G = (V, E, D) Input: Initial vertex set T = {v 1 , v 2 , ...} while T is not Empty do v ← RemoveNext(T ) (T′, S v ) ← f(v, S v ) T ← T ∪ T ′ Output: Modified Data Graph G = (V, E, D′)
21 .Serializability 21 For every parallel execution , there exists a sequential execution of update functions which produces the same result. CPU 1 CPU 2 Single CPU Parallel Sequential time
22 .22 Serializability Example Read Write Update functions one vertex apart can be run in parallel. Edge Consistency Overlapping regions are only read. Stronger / Weaker consistency levels available User-tunable consistency levels trades off parallelism & consistency
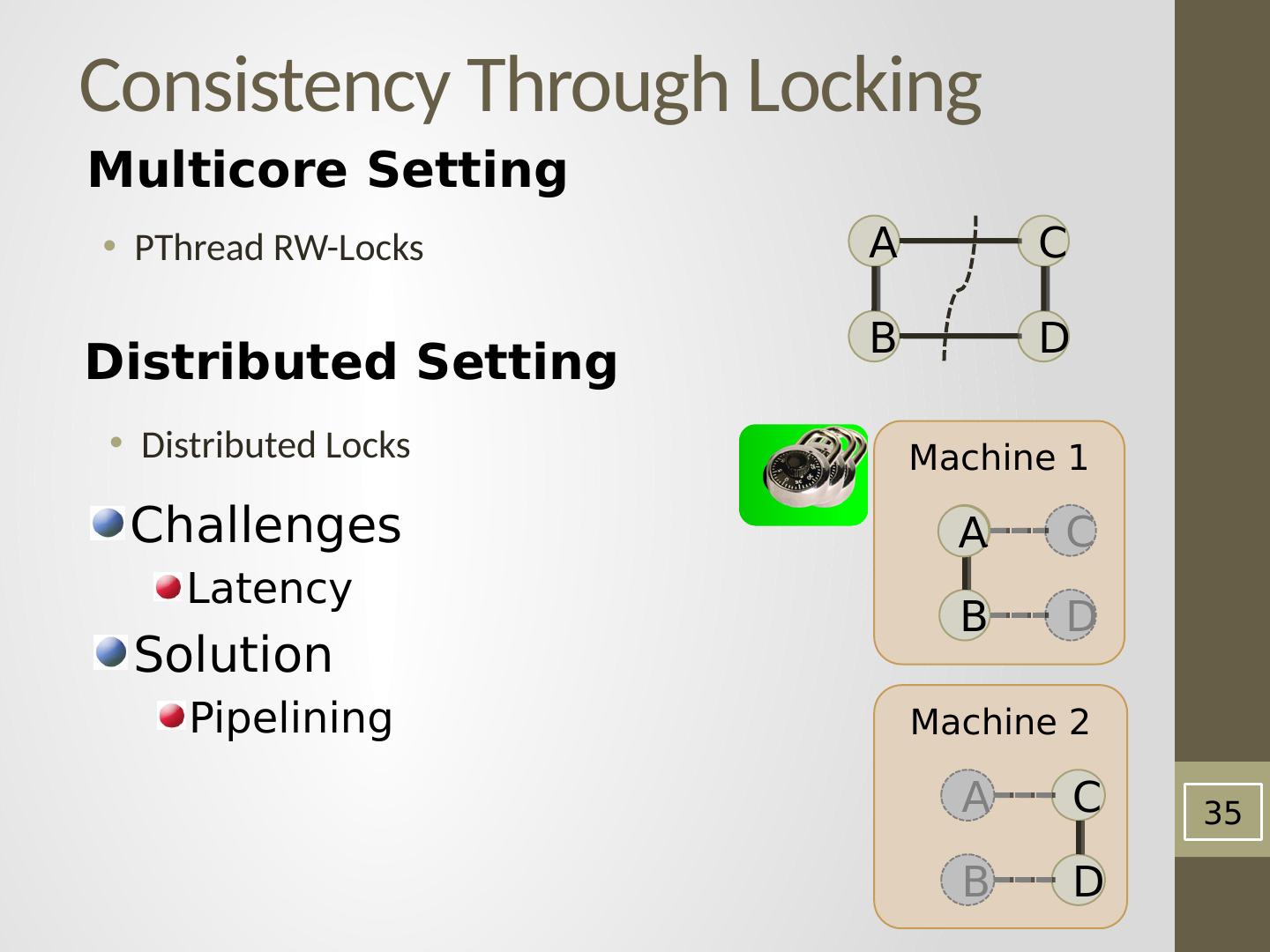
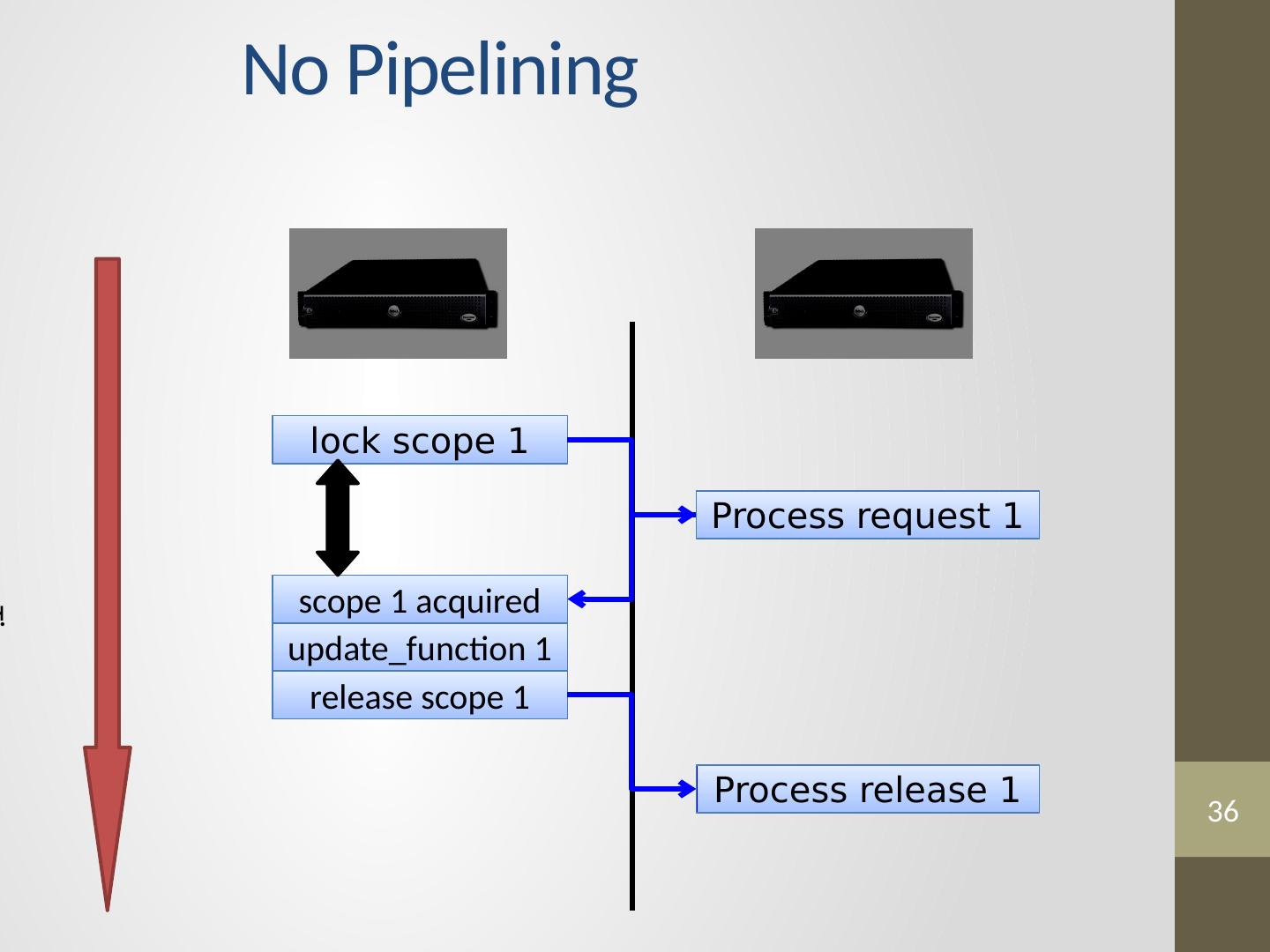
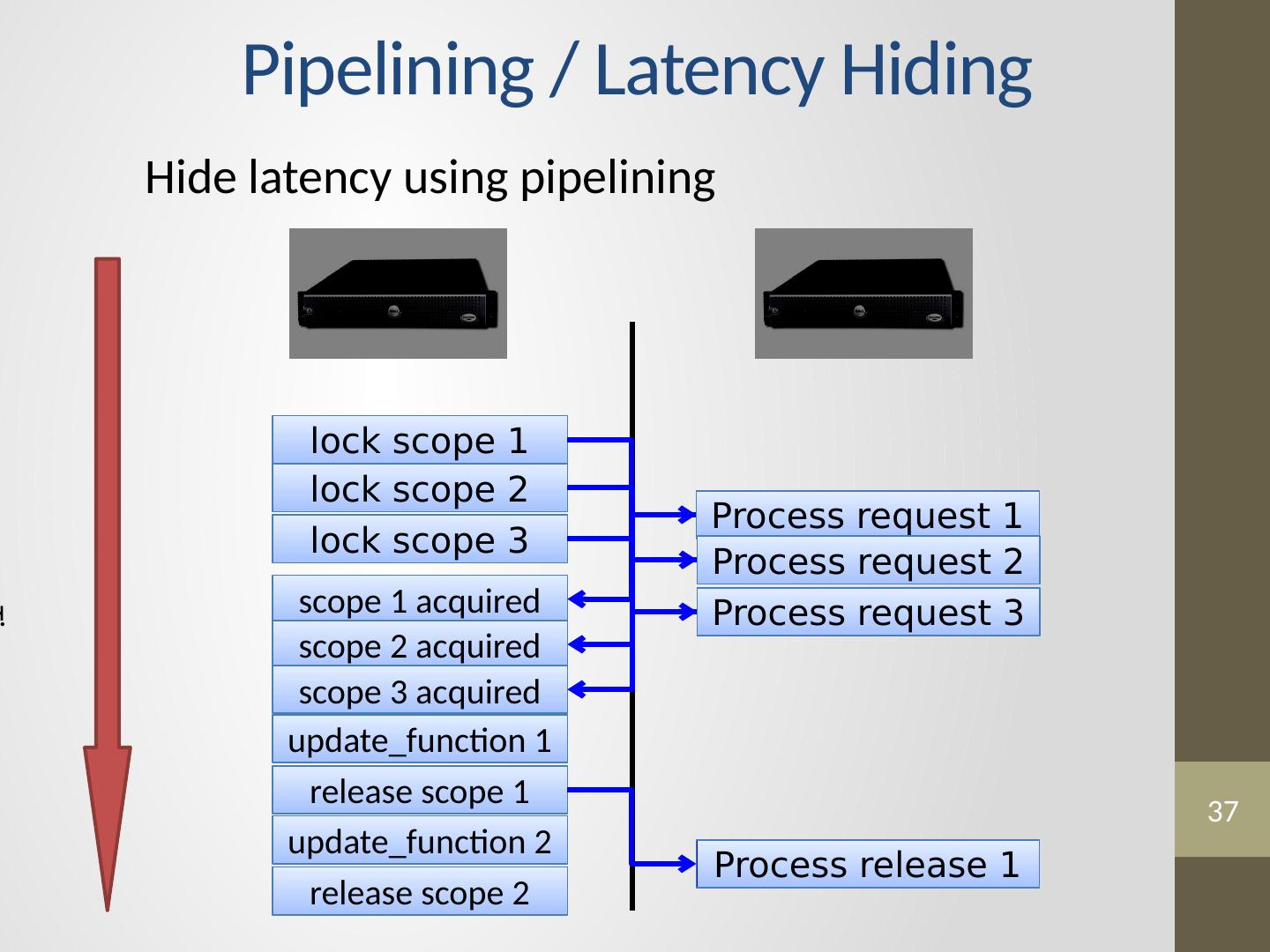
23 .Distributed Consistency Solution 1 Solution 2 Graph Coloring Distributed Locking
24 .24 Edge Consistency via Graph Coloring Vertices of the same color are all at least one vertex apart. Therefore, All vertices of the same color can be run in parallel!
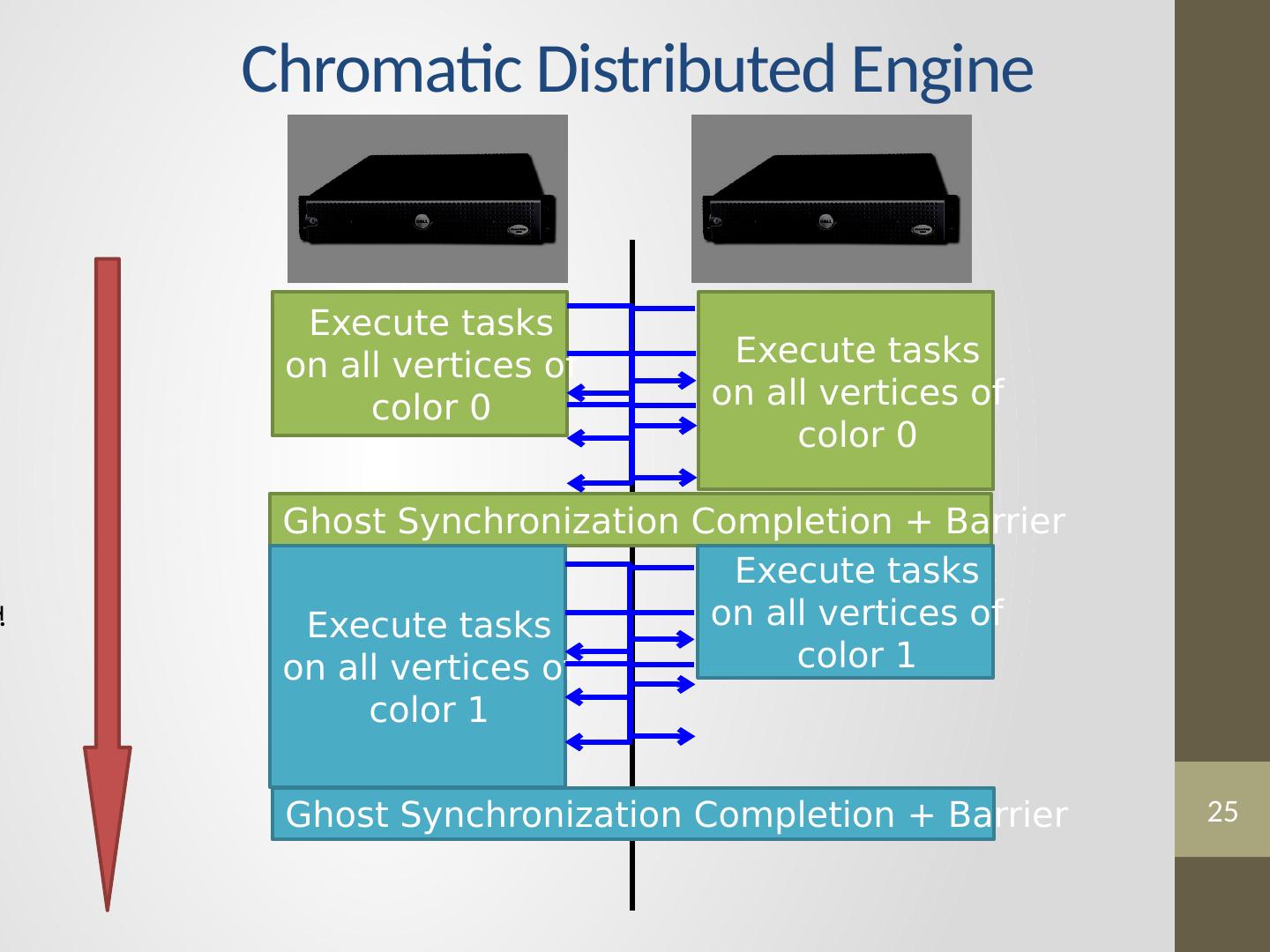
25 .25 Chromatic Distributed Engine Time Execute tasks on all vertices of color 0 Execute tasks on all vertices of color 0 Ghost Synchronization Completion + Barrier Execute tasks on all vertices of color 1 Execute tasks on all vertices of color 1 Ghost Synchronization Completion + Barrier
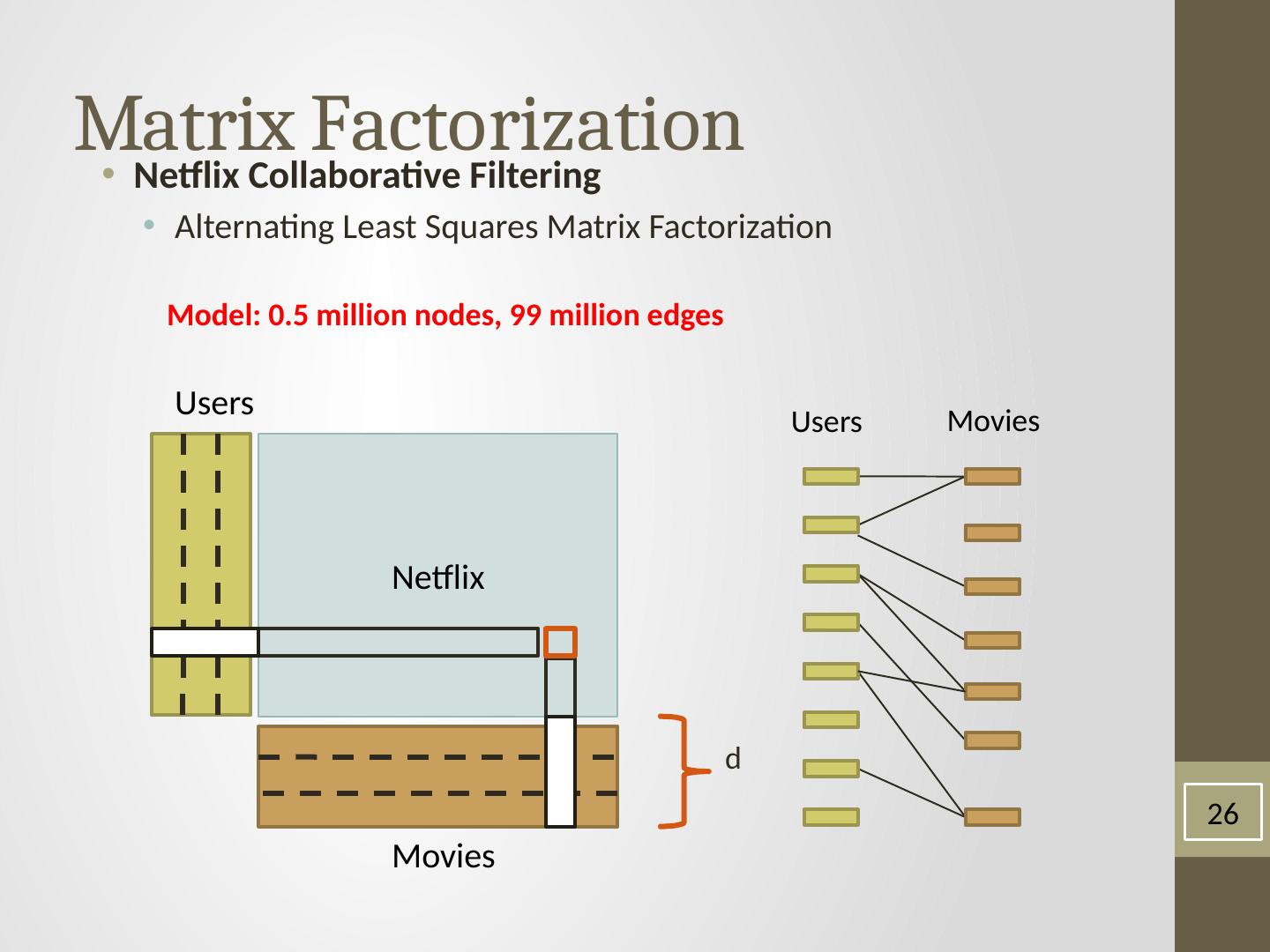
26 .Matrix Factorization Netflix Collaborative Filtering Alternating Least Squares Matrix Factorization M odel : 0.5 million nodes, 99 million edges Netflix Users Movies d 26 Users Movies
27 .27 Netflix Collaborative Filtering Ideal D=100 D=20 # machines Hadoop MPI GraphLab # machines
28 .28 The Cost of Hadoop Price Performance ratio of GraphLab and Hadoop on Amazon EC2 HPC machine on a log-log scale. Costs assume fine-grained billing.
29 .29 CoEM (Rosie Jones, 2005) Named Entity Recognition Task the cat Australia Istanbul <X> ran quickly travelled to <X> <X> is pleasant Hadoop 95 Cores 7.5 hrs Is “Cat” an animal? Is “Istanbul” a place? Vertices: 2 Million Edges: 200 Million Distributed GL 32 EC2 Nodes 80 secs GraphLab 16 Cores 30 min 0.3% of Hadoop time
3秒后跳转登录页面
去登陆

