




































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Fault-Tolerant Streaming Computation at Scale
Fault-Tolerant Streaming Computation at Scale
展开查看详情
1 .Discretized Streams: Fault-Tolerant Streaming Computation at Scale Matei Zaharia , Tathagata Das, Haoyuan Li, Scott Shenker , Ion Stoica University of California, Berkeley
2 .Stream processing and the problem Processing real time data as they arrive: Site Activity Statistics: Facebook users clicking on ads Computer Clusters Monitoring: mining real time logs Spam detection and prevention: detecting spam tweets before it’s too late Problems: Scalability to 100s of nodes: Fault tolerance ? stragglers? Generic enough to model a wide variety of systems ?
3 .Goals Scalability to 100s of nodes Minimal cost beyond base processing (little over head) Second-scale latency Second-scale recovery from faults and stragglers
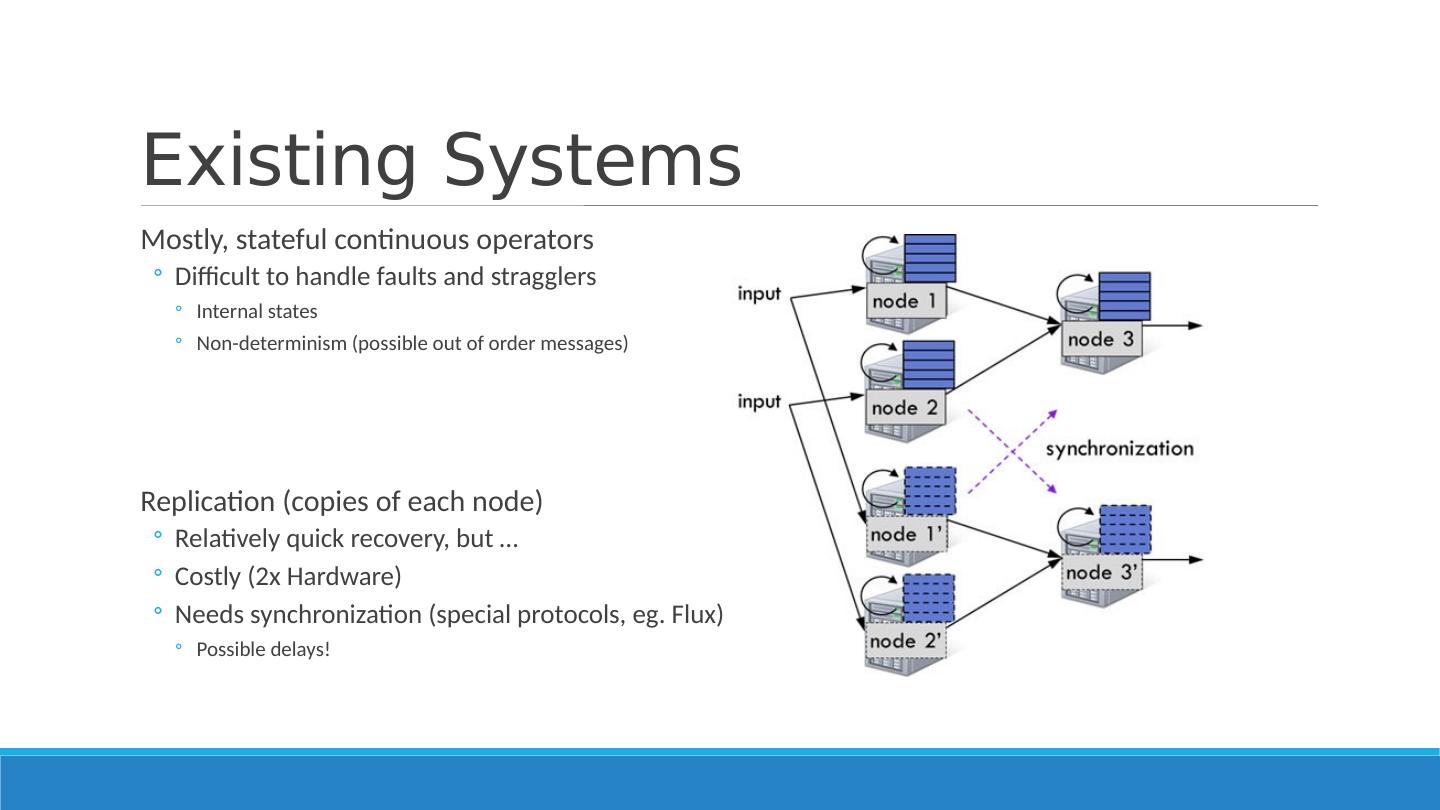
4 .Existing Systems Mostly, stateful continuous operators Difficult to handle faults and stragglers Internal states Non-determinism (possible out of order messages) Replication (copies of each node) Relatively quick recovery, but … Costly (2x Hardware) Needs synchronization (special protocols, eg . Flux) Possible delays!
5 .Upstream backup (buffer messages to replay) Buffer out-messages up to some checkpoint to be replayed Upon a node failure, a stand-by node steps in Parents replay buffered messages to the step-in node so that it reaches the desired state Incurs system delay! (waiting till the step-in node to get in state to start processing new data) Storm*, MapReduce Online, Time Stream
6 .Stragglers? Neither handles stragglers Replicas would be delayed (synchronization !) Upstream-backup would treat stragglers as failures Recovery mechanism kicks-in again, incurring more delay!
7 .Discretized Streams (D-Streams) Computations structured in a set of short, stateless, and deterministic tasks Finer-granularity dependencies Allows parallel recovery and speculation State stored in-memory as Resilient Distributed Datasets (RDDs) Unification with batch processing
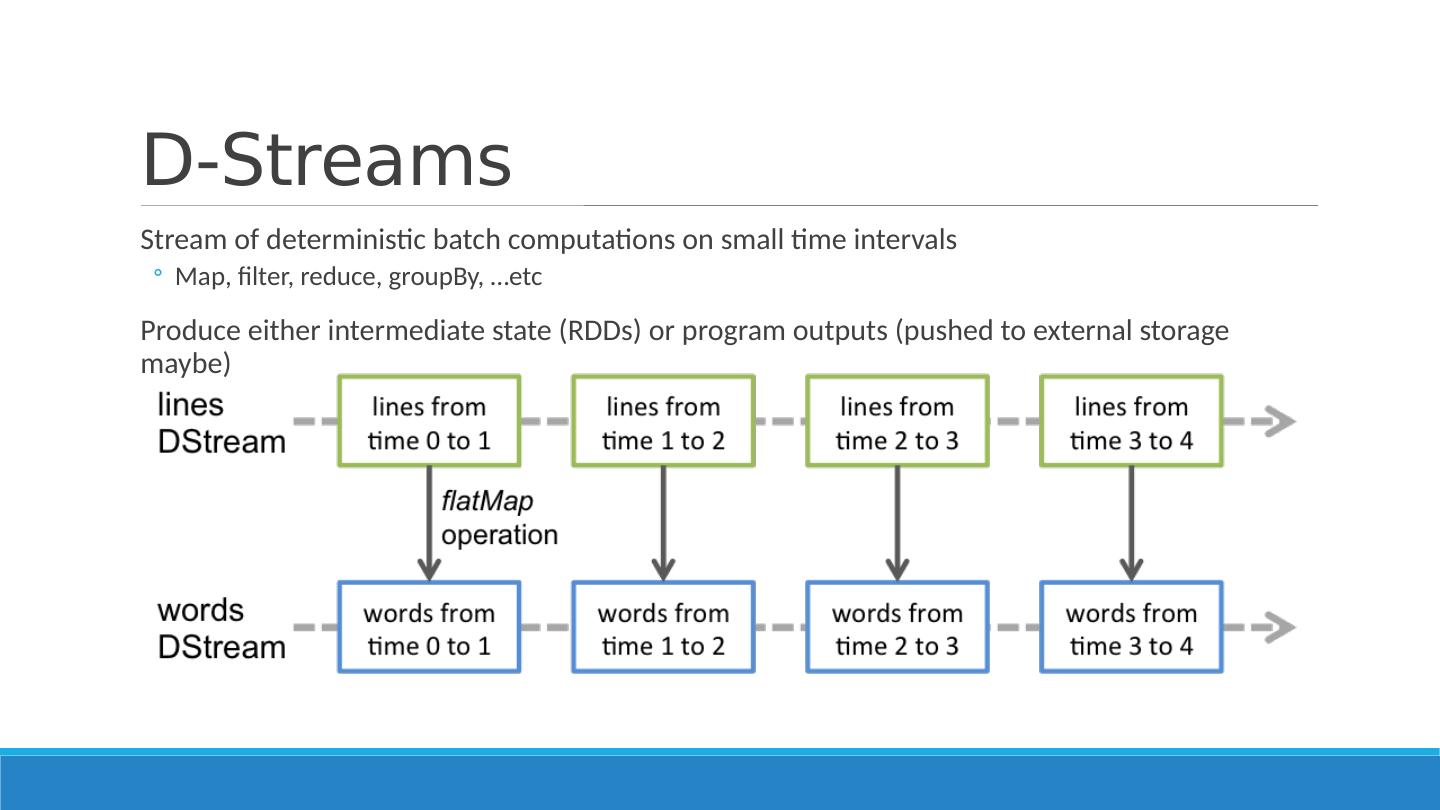
8 .D-Streams Stream of deterministic batch computations on small time intervals Map, filter, reduce, groupBy , … etc Produce either intermediate state (RDDs) or program outputs (pushed to external storage maybe)
9 .RDDs Immutable (read-only) dataset Data partitioned between workers Keeps the lineage of how the RDD was computed Eg ., by doing a map on another RDD (a dependency) Avoids replication by recomputing lost partitions from dependencies using linage Usually in-memory, but RDD partitions data can be persisted to disk
10 .Example pageViews = readStream ( “http://... ”, “1s”) ones = pageViews.map ( event => (event.url, 1 ) ) counts = ones.runningReduce ( (a, b) => a + b)
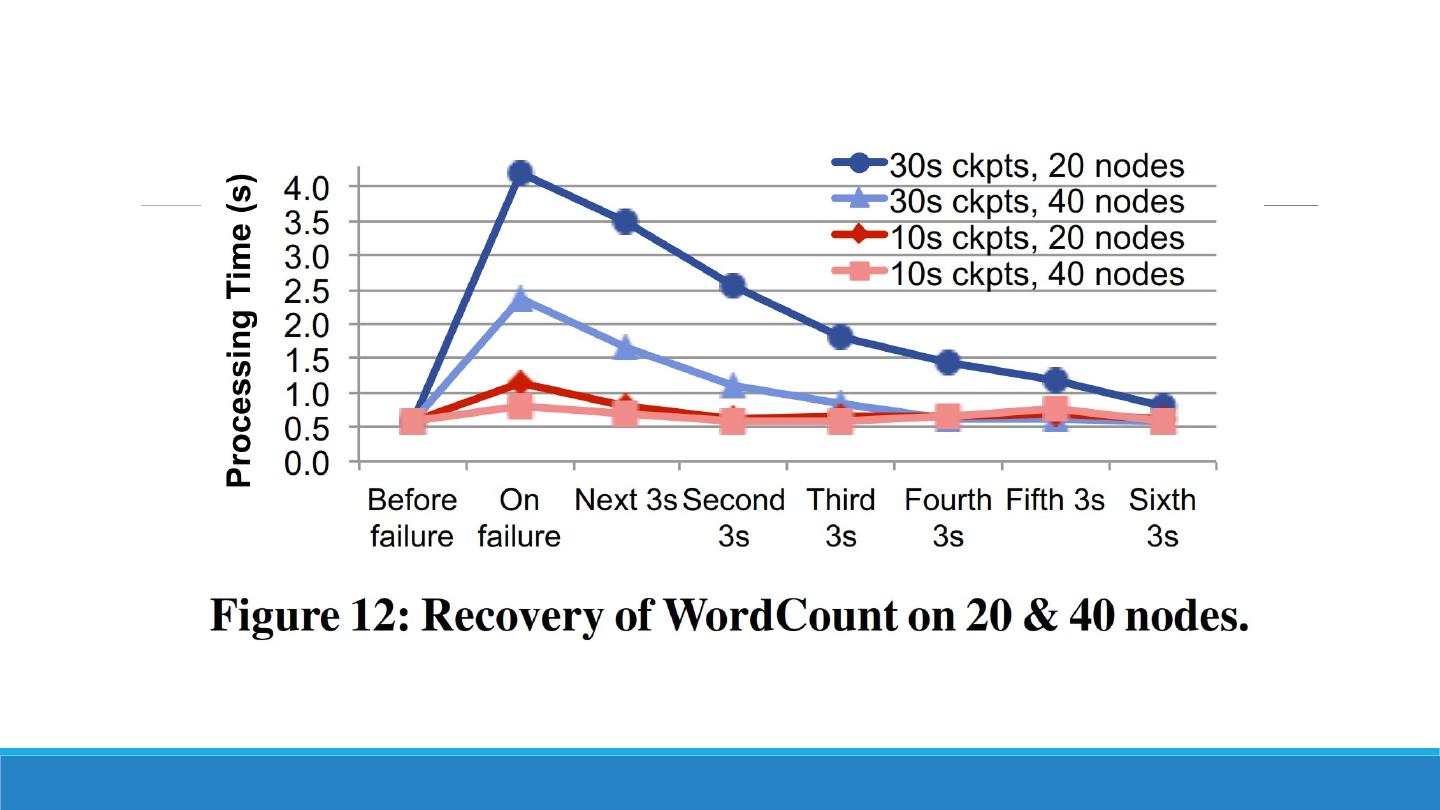
11 .RDDs cont’d Periodic checkpoints System will replicate every, say, tenth RDD Prevents infinite recomputations Recovery is often fast: parallel recomputation of lost partitions on separate nodes Parallel in respect to partitions, and time-intervals Computing different partitions of different timer-intervals in the same time More parallelism than upstream backup even when having more continuous operators per node
12 .Timing ? Assumes data arriving between [t, t+1) are actually [t, t+1) records Late records (according to embedded timestamp)? Two possible solutions: System can wait for slack time before starting processing [t, t+1) batch would wait till, say, t+5 before it packages the RDD and starts processing so it can catch late [t, t+1) messages that are arriving between [t+1, t+5) Output is delayed (here by 4 time units) Application level updates Compute for [t, t+1) and output its result catch any late [t, t+1) record, arriving up till, say, t+5 Aggregate, reduce and output an updated value for [t, t+1) based on the records caught in [t, t+5)
13 .D-Streams API Connect to streams: External streams ( eg . listening on a port) Loading periodically from a storage system ( eg . HDFS) D-Streams support: Transformations: create a new D-Stream from one or more D-Streams Map, reduce, groupBy , join … etc Output operations: write data to external systems save, foreachRDD
14 .D-Stream API cont’d Windowing Group records from a sliding window into one RDD words.window (“5s”) // “words” is the D-Stream of words as they are arriving A D-Stream of 5-second intervals, each is an RDD having the words that arrived in that time period partitioned over workers, ie ., words in [0,5), [1,6), [2,7) .. etc DStream of data window length sliding interval
15 .D-Stream API cont’d Incremental Aggregation Computing an aggregate (max, count .. etc ) over a sliding window Eg ., pairs.reduceByWindow (“5s”, _+_ ) //”pairs” is the (word,1) D-Stream Computes aggregate per interval, aggregates by the last 5 seconds Function has to be associative
16 .D-Stream API cont’d Incremental Aggregation Associatve and invertible Efficient Eg , pairs.reduceByWindow (“5s”, _ + _ , _ - _ )
17 .D-Stream API cont’d State tracking (Key, Event) -> (Key, State) Initialize : create state from event Update: ( State,Event ) -> NewState Timeout: drop old states eg .: Sessions = events.track ( (key, ev ) => 1, (key, state, ev ) => ev == Exit? null : 1, “30s”) //( ClientID , 1) for each active session // .count()
18 .D-Streams Consistency? No chance of out of sync outputs Microbatched temporal data and clear states (determinism) It’s all RDDs Can play well with offline data loaded into RDDs Perform ad-hoc queries Attach console shell, perform queries on available RDDs Query the state without the need to output! (debugging)
19 .Summary Aspect D-Streams Continuous processing Systems Latency 0.5-2s 1-100ms unless micro-batched for consistency Consistency Records processed atomically with the interval they arrive in May wait short of time to sync operators before proceeding Late Records Slack time or application level correction Slack time or out of order processing Fault Recovery Fast parallel recovery Replication or serial recovery on one node Straggler Recovery Possible via speculative execution Typically not handled Mixing with batching Simple unification through RDDs API Some DBs do, but not in message queueing systems
20 .System Architecture Implemented into Spark Streaming, based on modified Spark processing engine A master : Tracks D-Stream lineage graph and schedules tasks to compute new RDD partitions Workers: receive data, store the partitions of input and computed RDDs, and execute tasks A Client Library: used to send data into the system
21 .Application Execution Defining one or more stream inputs Ensure that data is replicated across two worker nodes before acknowledging source If a worker fails, unacknowledged data is sent to another worker (by source) Block store on each worker manages the data, tracked by the master, so that every node can find dependency partitions A uniqueID for each block, any node has a particular block ID can serve it (if multiple nodes compute it) Dropped in LRU fashion Nodes have their clocks synchronized via NTP Each node sends master a list of block IDs it has Let the tasks begin, master (no further synchronization needed – determinism!) Tasks carried out as their parents finish
22 .Execution level optimization Operators that can be grouped get pipelined into a single task Map, map, filter .. etc (narrow-dependencies) Tasks placed based on data locality Controls partitioning of RDDs As local as possible across interval for reused data
23 .Optimization for Stream Processing Network Communication Now uses async IO to let tasks with remote input, such as reduce, fetch them faster Timestep Pipelining Allow running overlapping timestep tasks tasks to utilize all nodes Task Scheduling Multiple optimizations, eg ., hand-tuning the size of control messages to be able to launch parallel jobs of hundreds of tasks every few hundred milliseconds. Storage Layer Async checkpointing of RDDs, zero-copy when possible. Lineage cutoff Forget lineage after an RDD has been checkpointed .
24 .Optimization cont’d Master Recovery Mitigate single point of failure These optimizations also benefited Spark batch operations and showed 2x improvement
25 .Memory Management Least Recently Used dropping of partitions Data spilled to disk if no enough memory Configurable maximum history timeout System will forget timed-out blocks (think garbage collection) History t imeout > checkpoint interval In many applications, memory use is not onerous State within computation is much smaller than the input data
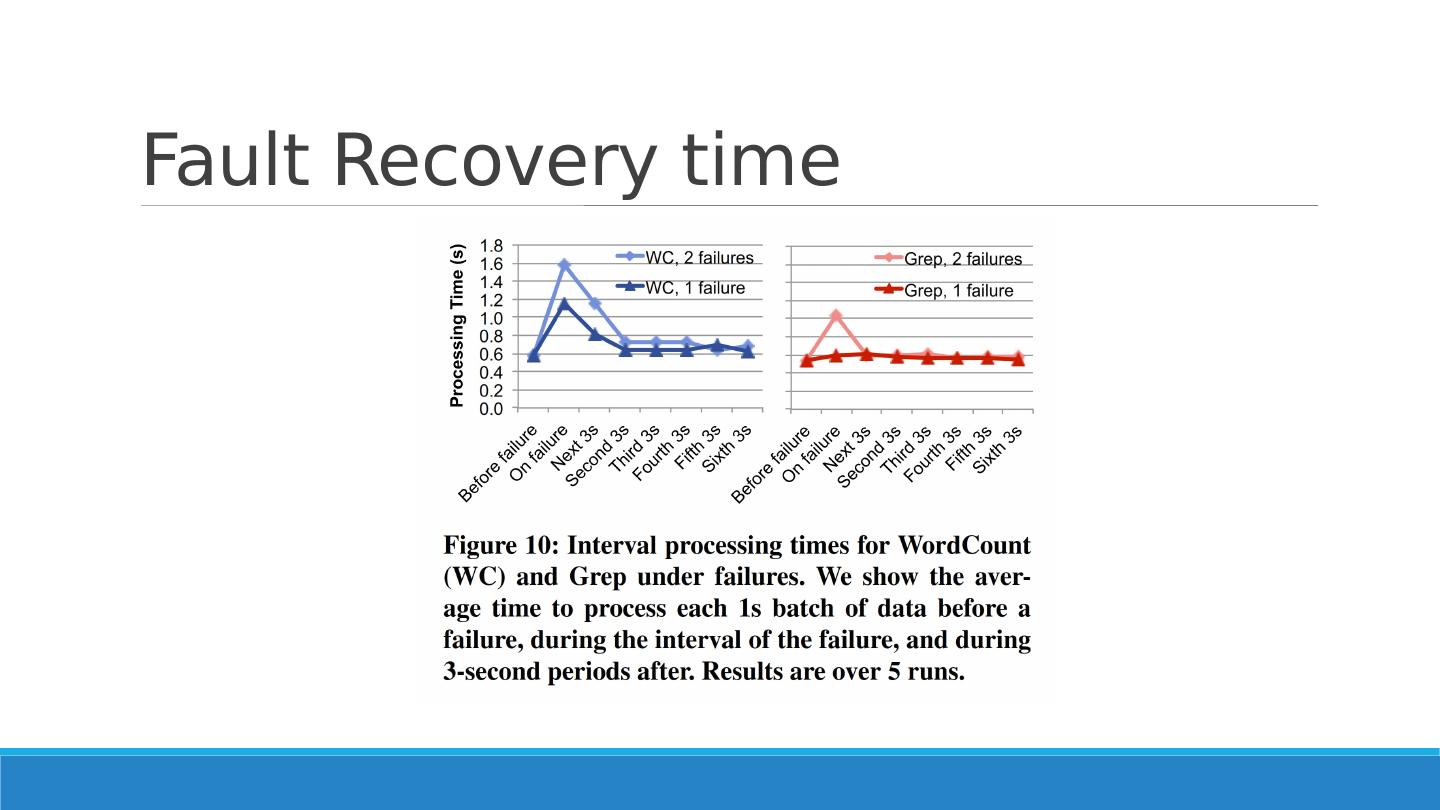
26 .Fault Recovery Deterministic nature of D-Streams allows parallel recovery RDDs are immutable State is fully explicit Fine-granularity dependencies Regular checkpoints helps speed up recomputations Parallel Recovery A node fails -> different partitions in different RDDs are lost Master identifies lost partitions and sends out tasks to nodes to recompute time according to lineage and dependencies The whole cluster partakes in recovery Parallel both in partitions in each timestep and across timesteps (if dependency allows)
27 .Parallel Recovery 1 min since last checkpoint
28 .Handling Stragglers Detection : eg ., 1.4x slower than the median task in its job stage Run speculative backup copies of slow tasks recompute straggled partitions on other nodes, in parallel Produces same results (determinism)
29 .Master Recovery Writing the state of computation reliably when starting each time step Graph of the user D-Streams and Scala function objects representing user code Time of the last checkpoint IDs of RDDs since the checkpoint Having workers connect to a new master and report their RDD partitions No problem if an RDD is computed twice (no difference) Fine to lose some running tasks while a new master loads up, can be recomputed Idempotent output operators; not to overwrite what has been outputted
3秒后跳转登录页面
去登陆

