














































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Dimensionality Reduction
Dimensionality Reduction
展开查看详情
1 .Dimensionality Reduction Shannon Quinn (with thanks to William Cohen of Carnegie Mellon University, and J. Leskovec , A. Rajaraman , and J. Ullman of Stanford University)
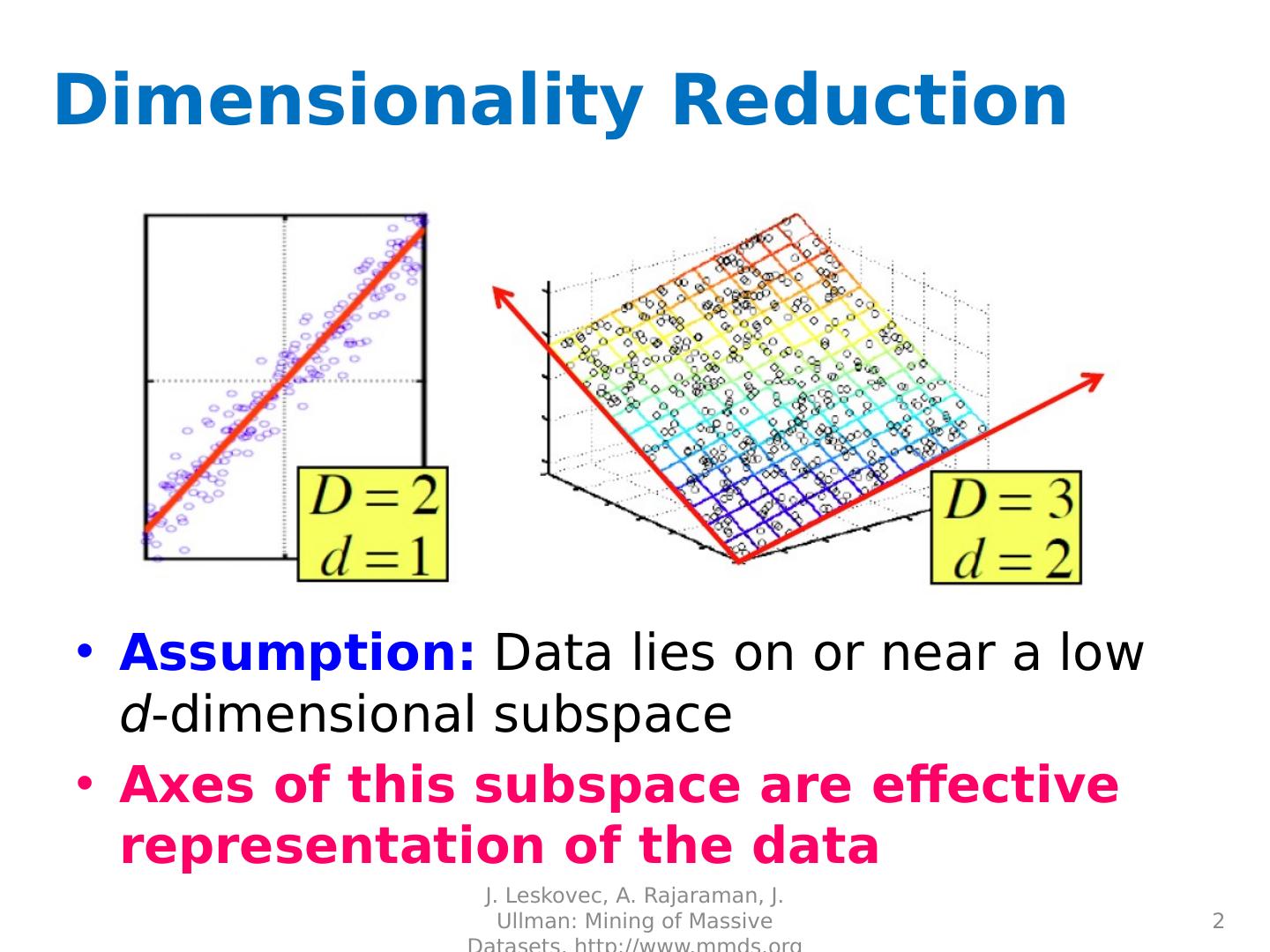
2 .Dimensionality Reduction Assumption: Data lies on or near a low d -dimensional subspace Axes of this subspace are effective representation of the data J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 2
3 .Rank of a Matrix Q: What is rank of a matrix A ? A : Number of linearly independent columns of A For example: Matrix A = has rank r=2 Why? The first two rows are linearly independent, so the rank is at least 2, but all three rows are linearly dependent (the first is equal to the sum of the second and third) so the rank must be less than 3 . Why do we care about low rank? We can write A as two “basis” vectors: [1 2 1] [-2 -3 1] And new coordinates of : [1 0] [0 1] [1 1] J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 3
4 .Rank is “Dimensionality” Cloud of points 3D space: Think of point positions as a matrix: We can rewrite coordinates more efficiently! Old basis vectors: [1 0 0] [0 1 0] [0 0 1] New basis vectors: [1 2 1] [-2 -3 1] Then A has new coordinates: [1 0]. B : [0 1], C : [1 1] Notice: We reduced the number of coordinates! 1 row per point: A B C A J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 4
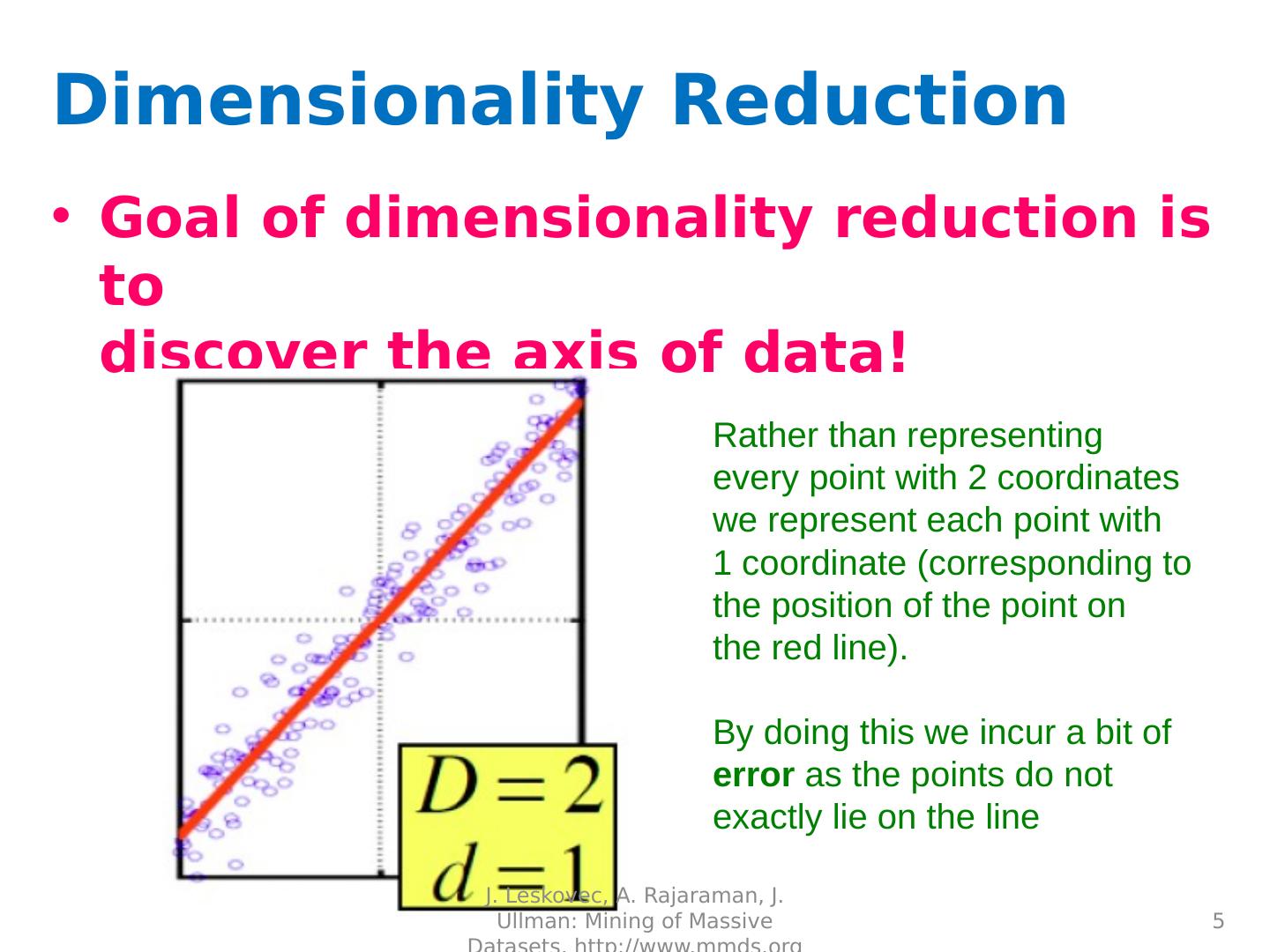
5 .Dimensionality Reduction Goal of dimensionality reduction is to discover the axis of data! Rather than representing every point with 2 coordinates we represent each point with 1 coordinate (corresponding to the position of the point on the red line). By doing this we incur a bit of error as the points do not exactly lie on the line J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 5
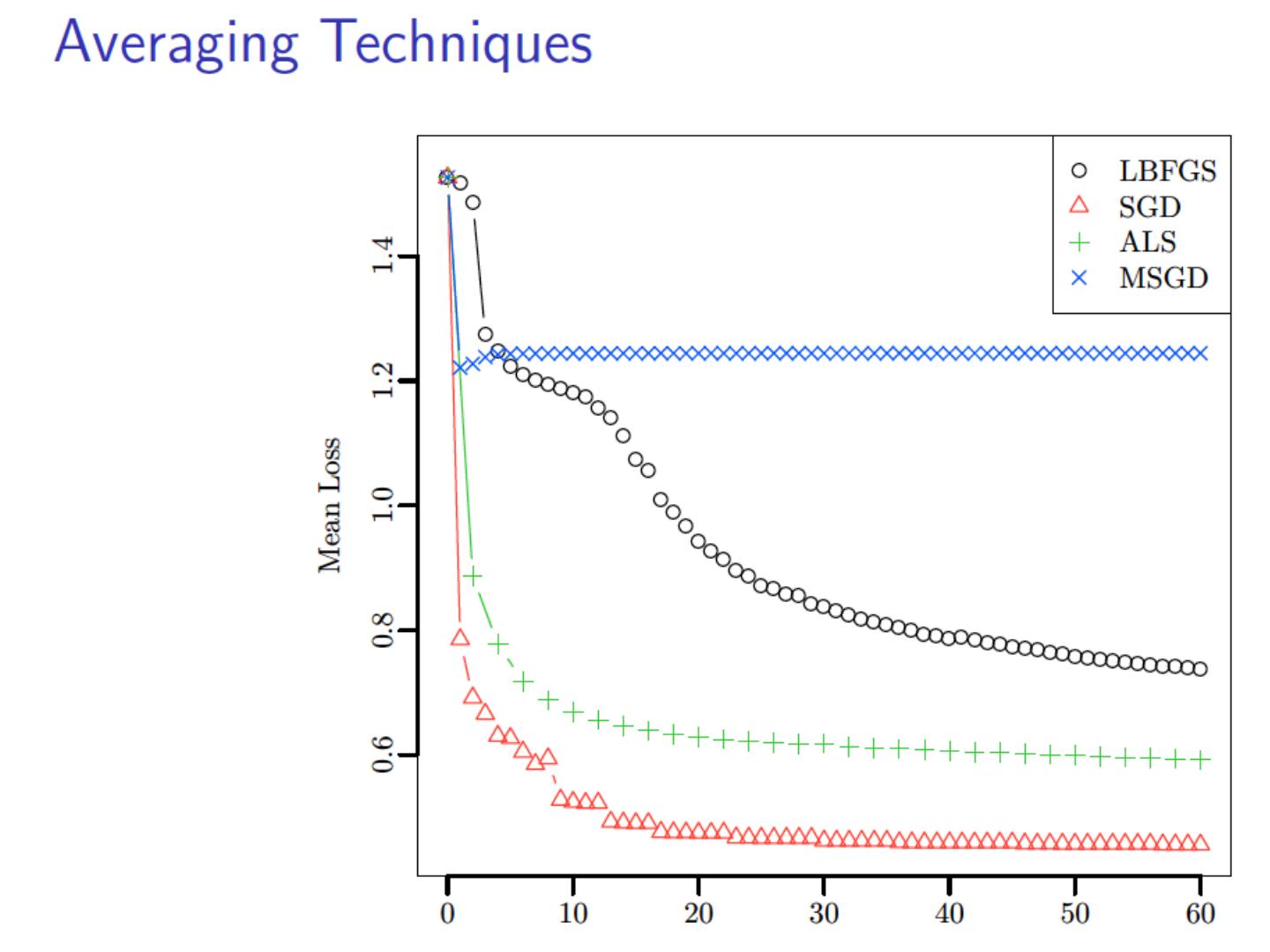
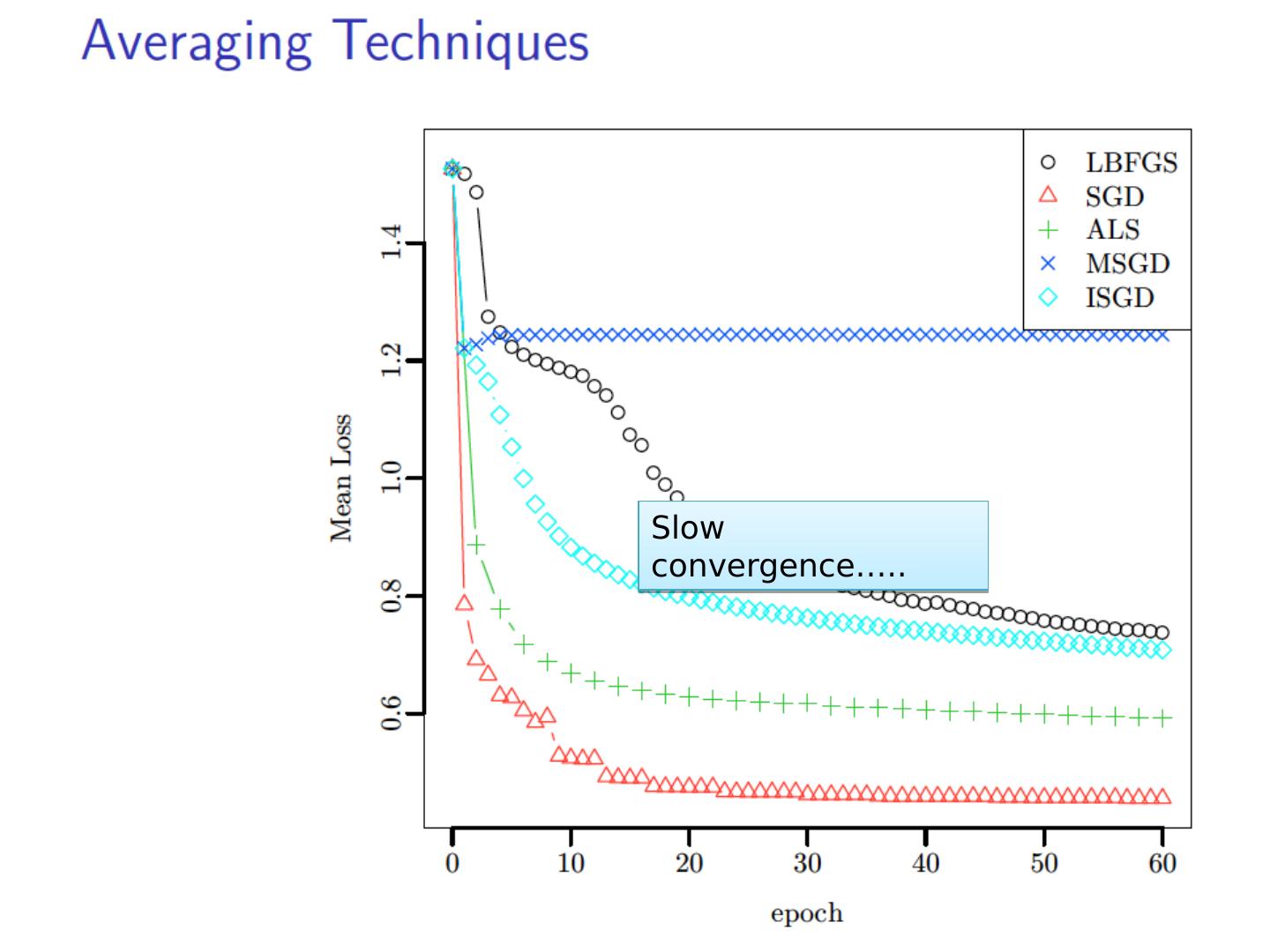
6 .Why Reduce Dimensions? Why reduce dimensions? Discover hidden correlations/topics Words that occur commonly together Remove redundant and noisy features Not all words are useful Interpretation and visualization Easier storage and processing of the data J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 6
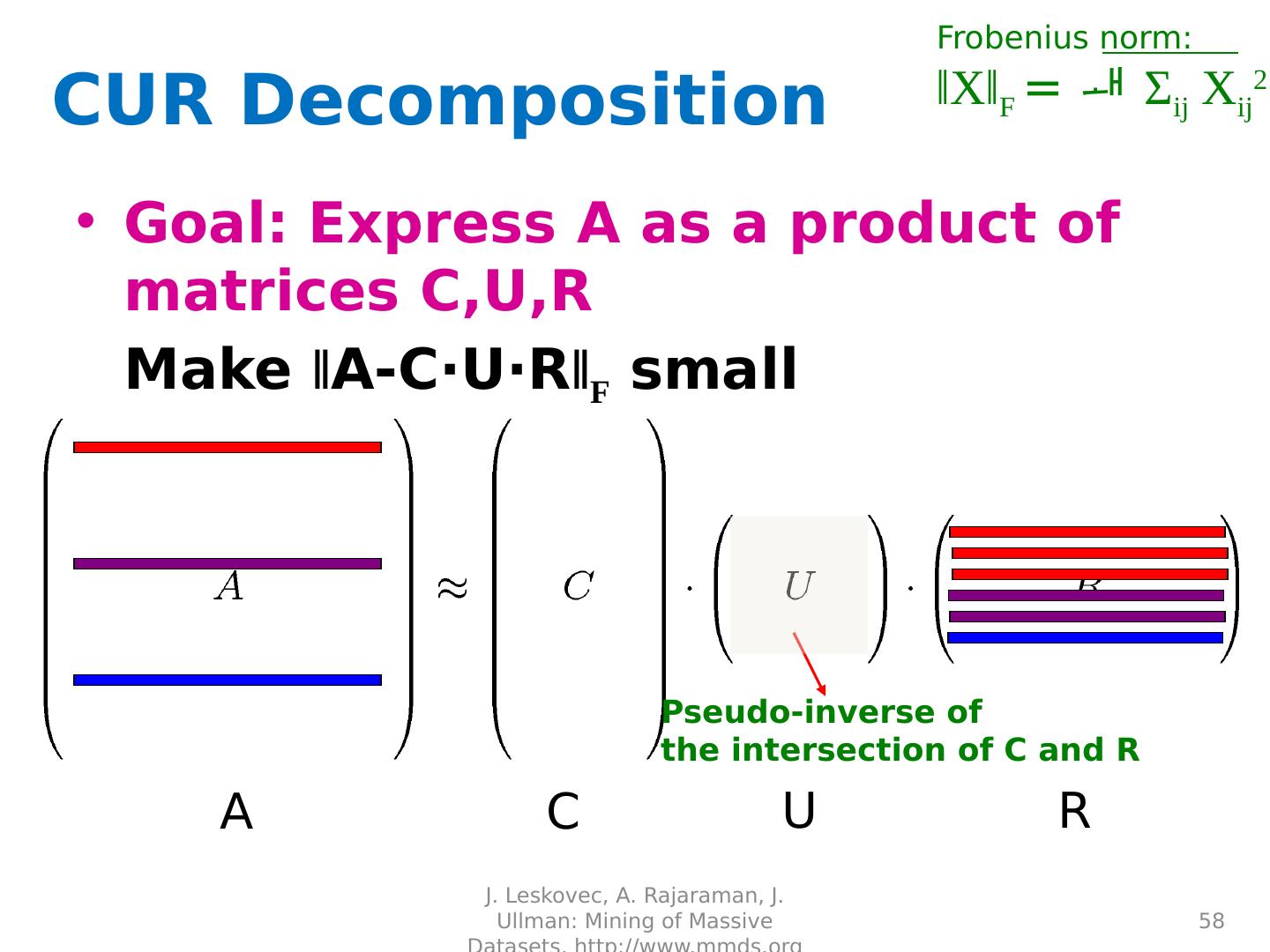
7 .J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 7 SVD - Definition A [m x n] = U [m x r] [ r x r] ( V [n x r] ) T A : Input data matrix m x n matrix (e.g ., m documents, n terms) U : Left singular vectors m x r matrix ( m documents, r concepts) : Singular values r x r diagonal matrix ( strength of each ‘concept’) ( r : rank of the matrix A ) V : Right singular vectors n x r matrix ( n terms, r concepts)
8 .SVD 8 A m n m n U V T J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org T
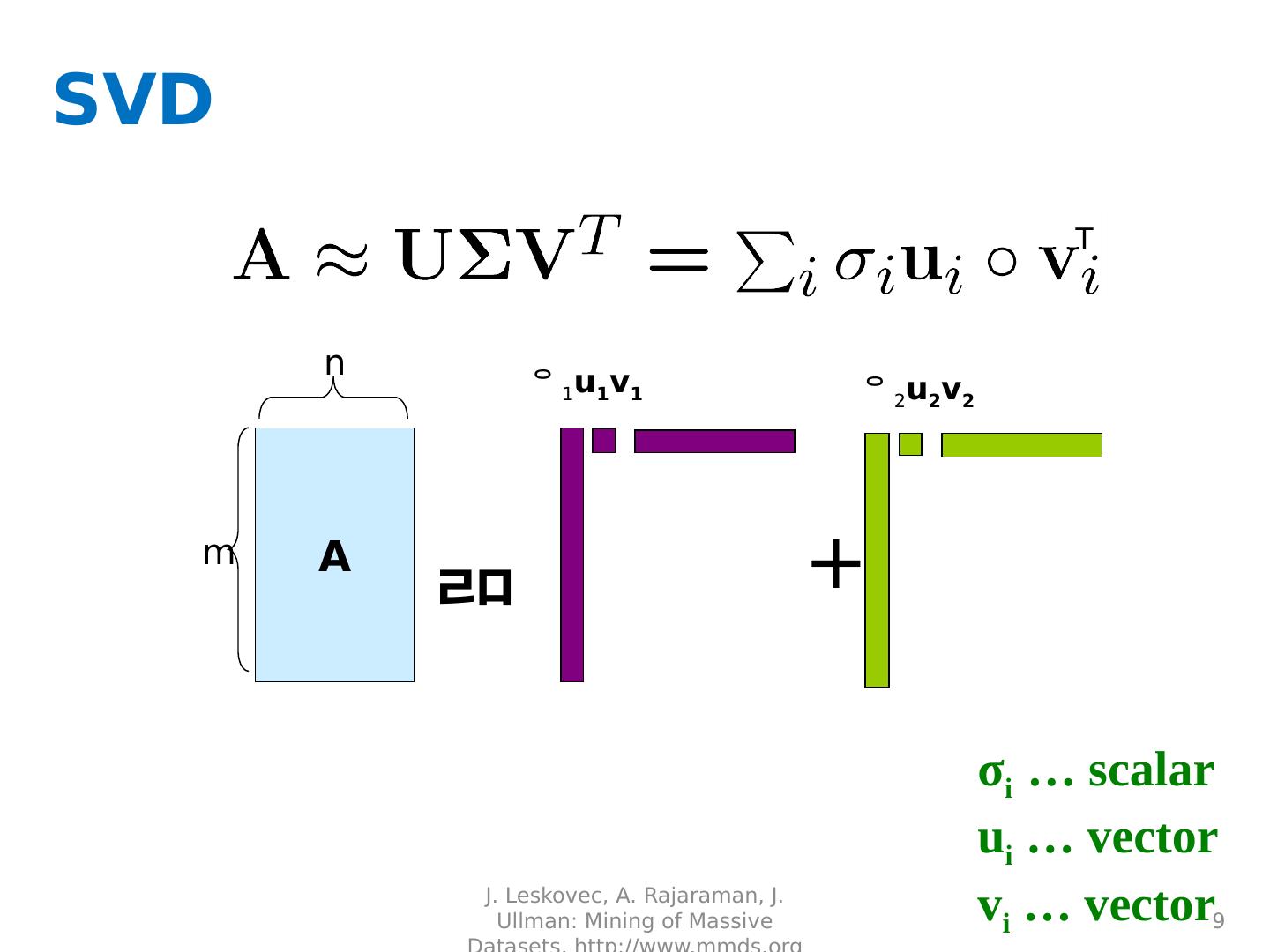
9 .SVD 9 A m n + 1 u 1 v 1 2 u 2 v 2 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org σ i … scalar u i … vector v i … vector T
10 .SVD - Properties It is always possible to decompose a real matrix A into A = U V T , where U, , V : unique U , V : column orthonormal U T U = I ; V T V = I ( I : identity matrix) (Columns are orthogonal unit vectors) : diagonal Entries ( singular values ) are positive , and sorted in decreasing order ( σ 1 σ 2 ... 0 ) J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 10 Nice proof of uniqueness: http ://www.mpi-inf.mpg.de/~bast/ir-seminar-ws04/lecture2.pdf
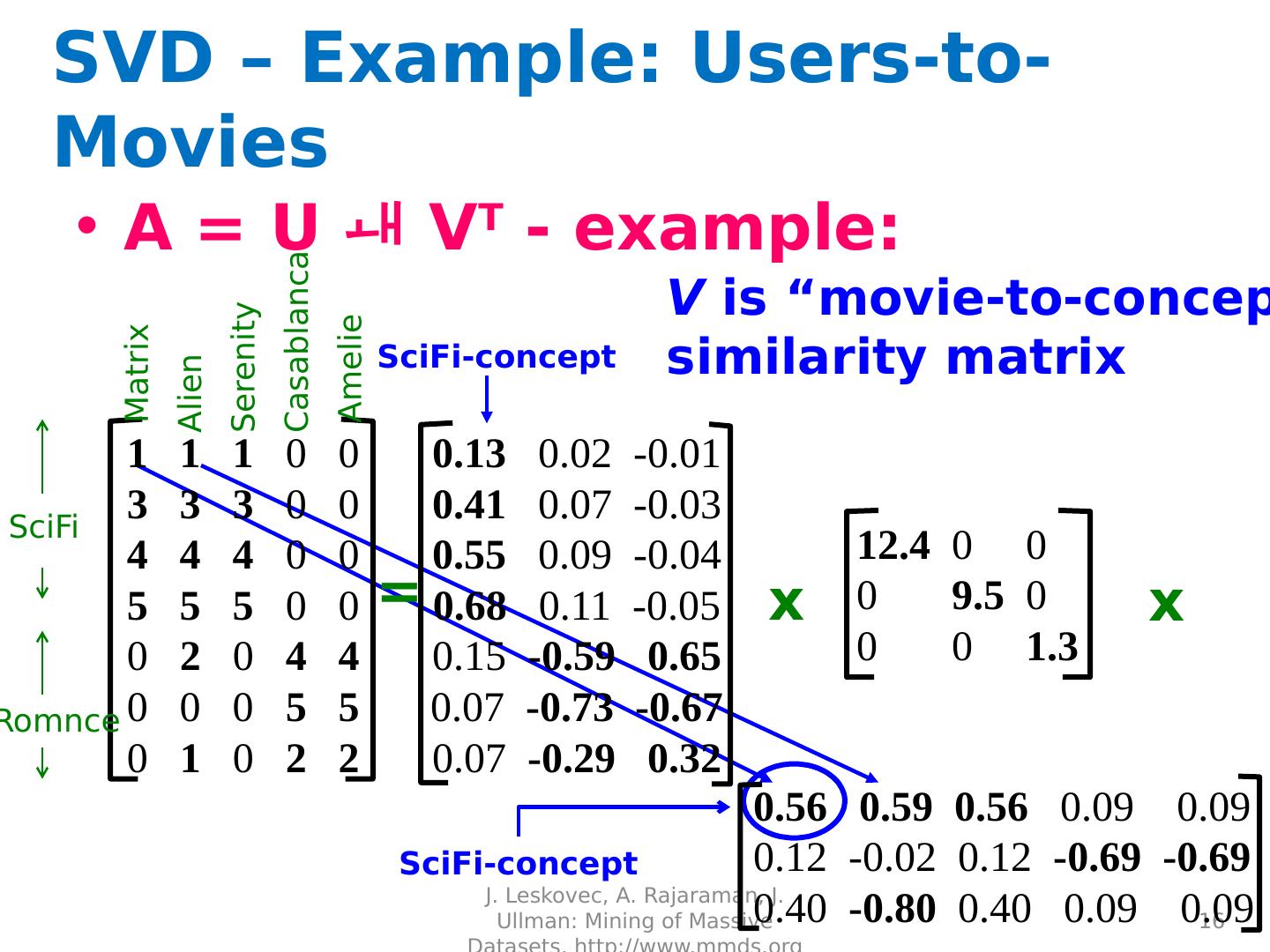
11 .SVD – Example: Users-to-Movies A = U V T - example: Users to Movies J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 11 = SciFi Romance Matrix Alien Serenity Casablanca Amelie 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2 m n U V T “Concepts” AKA Latent dimensions AKA Latent factors
12 .SVD – Example: Users-to-Movies A = U V T - example: Users to Movies J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 12 = SciFi Romnce x x Matrix Alien Serenity Casablanca Amelie 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2 0.13 0.02 -0.01 0.41 0.07 -0.03 0.55 0.09 -0.04 0.68 0.11 -0.05 0.15 -0.59 0.65 0.07 -0.73 -0.67 0.07 -0.29 0.32 12.4 0 0 0 9.5 0 0 0 1.3 0.56 0.59 0.56 0.09 0.09 0.12 -0.02 0.12 -0.69 - 0.69 0.40 -0.80 0.40 0.09 0.09
13 .SVD – Example: Users-to-Movies A = U V T - example: Users to Movies J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 13 SciFi -concept Romance-concept = SciFi Romnce x x Matrix Alien Serenity Casablanca Amelie 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2 0.13 0.02 -0.01 0.41 0.07 -0.03 0.55 0.09 -0.04 0.68 0.11 -0.05 0.15 -0.59 0.65 0.07 -0.73 -0.67 0.07 -0.29 0.32 12.4 0 0 0 9.5 0 0 0 1.3 0.56 0.59 0.56 0.09 0.09 0.12 -0.02 0.12 -0.69 - 0.69 0.40 -0.80 0.40 0.09 0.09
14 .SVD – Example: Users-to-Movies A = U V T - example: J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 14 Romance-concept U is “user-to-concept” similarity matrix SciFi -concept = SciFi Romnce x x Matrix Alien Serenity Casablanca Amelie 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2 0.13 0.02 -0.01 0.41 0.07 -0.03 0.55 0.09 -0.04 0.68 0.11 -0.05 0.15 -0.59 0.65 0.07 -0.73 -0.67 0.07 -0.29 0.32 12.4 0 0 0 9.5 0 0 0 1.3 0.56 0.59 0.56 0.09 0.09 0.12 -0.02 0.12 -0.69 - 0.69 0.40 -0.80 0.40 0.09 0.09
15 .SVD – Example: Users-to-Movies A = U V T - example: J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 15 SciFi Romnce SciFi -concept “strength” of the SciFi -concept = SciFi Romnce x x Matrix Alien Serenity Casablanca Amelie 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2 0.13 0.02 -0.01 0.41 0.07 -0.03 0.55 0.09 -0.04 0.68 0.11 -0.05 0.15 -0.59 0.65 0.07 -0.73 -0.67 0.07 -0.29 0.32 12.4 0 0 0 9.5 0 0 0 1.3 0.56 0.59 0.56 0.09 0.09 0.12 -0.02 0.12 -0.69 - 0.69 0.40 -0.80 0.40 0.09 0.09
16 .SVD – Example: Users-to-Movies A = U V T - example: J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 16 SciFi -concept V is “movie-to-concept” similarity matrix SciFi -concept = SciFi Romnce x x Matrix Alien Serenity Casablanca Amelie 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2 0.13 0.02 -0.01 0.41 0.07 -0.03 0.55 0.09 -0.04 0.68 0.11 -0.05 0.15 -0.59 0.65 0.07 -0.73 -0.67 0.07 -0.29 0.32 12.4 0 0 0 9.5 0 0 0 1.3 0.56 0.59 0.56 0.09 0.09 0.12 -0.02 0.12 -0.69 - 0.69 0.40 -0.80 0.40 0.09 0.09
17 .J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 17 SVD - Interpretation #1 ‘ movies ’, ‘ users ’ and ‘ concepts ’: U : user-to-concept similarity matrix V : movie-to-concept similarity matrix : its diagonal elements: ‘ strength’ of each concept
18 .SVD - Interpretation #2 More details Q: How exactly is dim. reduction done? A: Set smallest singular values to zero J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 18 = x x 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2 0.13 0.02 -0.01 0.41 0.07 -0.03 0.55 0.09 -0.04 0.68 0.11 -0.05 0.15 -0.59 0.65 0.07 -0.73 -0.67 0.07 -0.29 0.32 12.4 0 0 0 9.5 0 0 0 1.3 0.56 0.59 0.56 0.09 0.09 0.12 -0.02 0.12 -0.69 - 0.69 0.40 -0.80 0.40 0.09 0.09
19 .SVD - Interpretation #2 More details Q: How exactly is dim. reduction done? A: Set smallest singular values to zero J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 19 x x 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2 0.13 0.02 -0.01 0.41 0.07 -0.03 0.55 0.09 -0.04 0.68 0.11 -0.05 0.15 -0.59 0.65 0.07 -0.73 -0.67 0.07 -0.29 0.32 12.4 0 0 0 9.5 0 0 0 1.3 0.56 0.59 0.56 0.09 0.09 0.12 -0.02 0.12 -0.69 - 0.69 0.40 -0.80 0.40 0.09 0.09
20 .SVD - Interpretation #2 More details Q: How exactly is dim. reduction done? A: Set smallest singular values to zero J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 20 x x 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2 0.13 0.02 -0.01 0.41 0.07 -0.03 0.55 0.09 -0.04 0.68 0.11 -0.05 0.15 -0.59 0.65 0.07 -0.73 -0.67 0.07 -0.29 0.32 12.4 0 0 0 9.5 0 0 0 1.3 0.56 0.59 0.56 0.09 0.09 0.12 -0.02 0.12 -0.69 - 0.69 0.40 -0.80 0.40 0.09 0.09
21 .SVD - Interpretation #2 More details Q: How exactly is dim. reduction done? A: Set smallest singular values to zero J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 21 x x 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2 0.13 0.02 0.41 0.07 0.55 0.09 0.68 0.11 0.15 - 0.59 0.07 - 0.73 0.07 - 0.29 12.4 0 0 9.5 0.56 0.59 0.56 0.09 0.09 0.12 -0.02 0.12 -0.69 -0.69
22 .SVD - Interpretation #2 More details Q: How exactly is dim. reduction done? A: Set smallest singular values to zero J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 22 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2 0.92 0.95 0.92 0.01 0.01 2.91 3.01 2.91 - 0.01 -0.01 3.90 4.04 3.90 0.01 0.01 4.82 5.00 4.82 0.03 0.03 0.70 0.53 0.70 4.11 4.11 -0.69 1.34 -0.69 4.78 4.78 0.32 0.23 0.32 2.01 2.01 Frobenius norm: ǁ M ǁ F = Σ ij M ij 2 ǁ A-B ǁ F = Σ ij ( A ij -B ij ) 2 is “small”
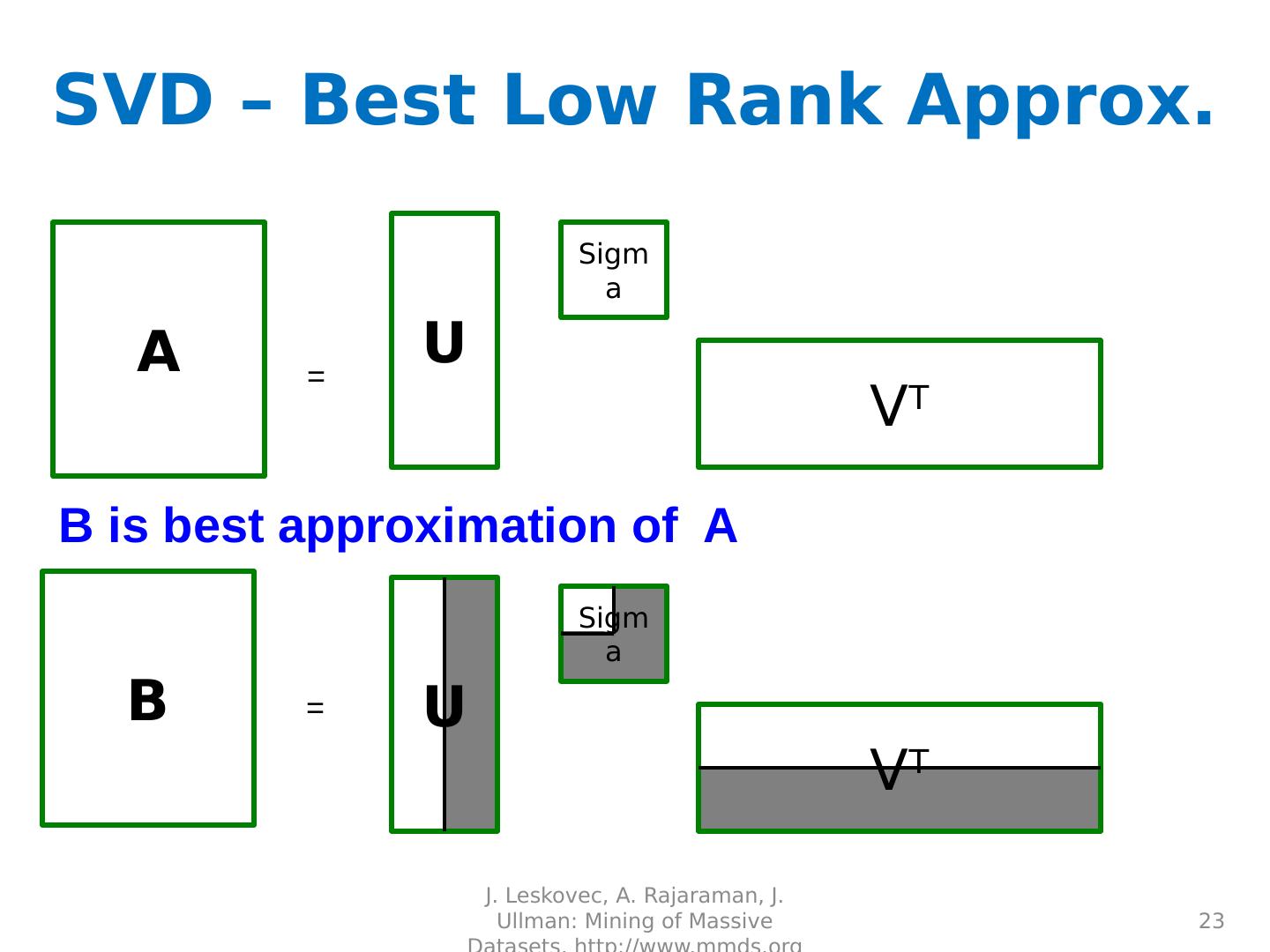
23 .SVD – Best Low Rank Approx. J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 23 A U Sigma V T = B U Sigma V T = B is best approximation of A
24 .J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 24 SVD - Interpretation #2 Equivalent : ‘spectral decomposition’ of the matrix: = x x u 1 u 2 σ 1 σ 2 v 1 v 2 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2
25 .SVD - Interpretation #2 Equivalent : ‘spectral decomposition’ of the matrix J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 25 = u 1 σ 1 v T 1 u 2 σ 2 v T 2 + +... n m n x 1 1 x m k terms Assume : σ 1 σ 2 σ 3 ... 0 Why is setting small σ i to 0 the right thing to do? Vectors u i and v i are unit length, so σ i scales them. So, zeroing small σ i introduces less error. 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2
26 .J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 26 SVD - Interpretation #2 Q: How many σ s to keep? A: Rule-of-a thumb: keep 80-90% of ‘energy’ = u 1 σ 1 v T 1 u 2 σ 2 v T 2 + +... n m Assume : σ 1 σ 2 σ 3 ... 1 1 1 0 0 3 3 3 0 0 4 4 4 0 0 5 5 5 0 0 0 2 0 4 4 0 0 0 5 5 0 1 0 2 2
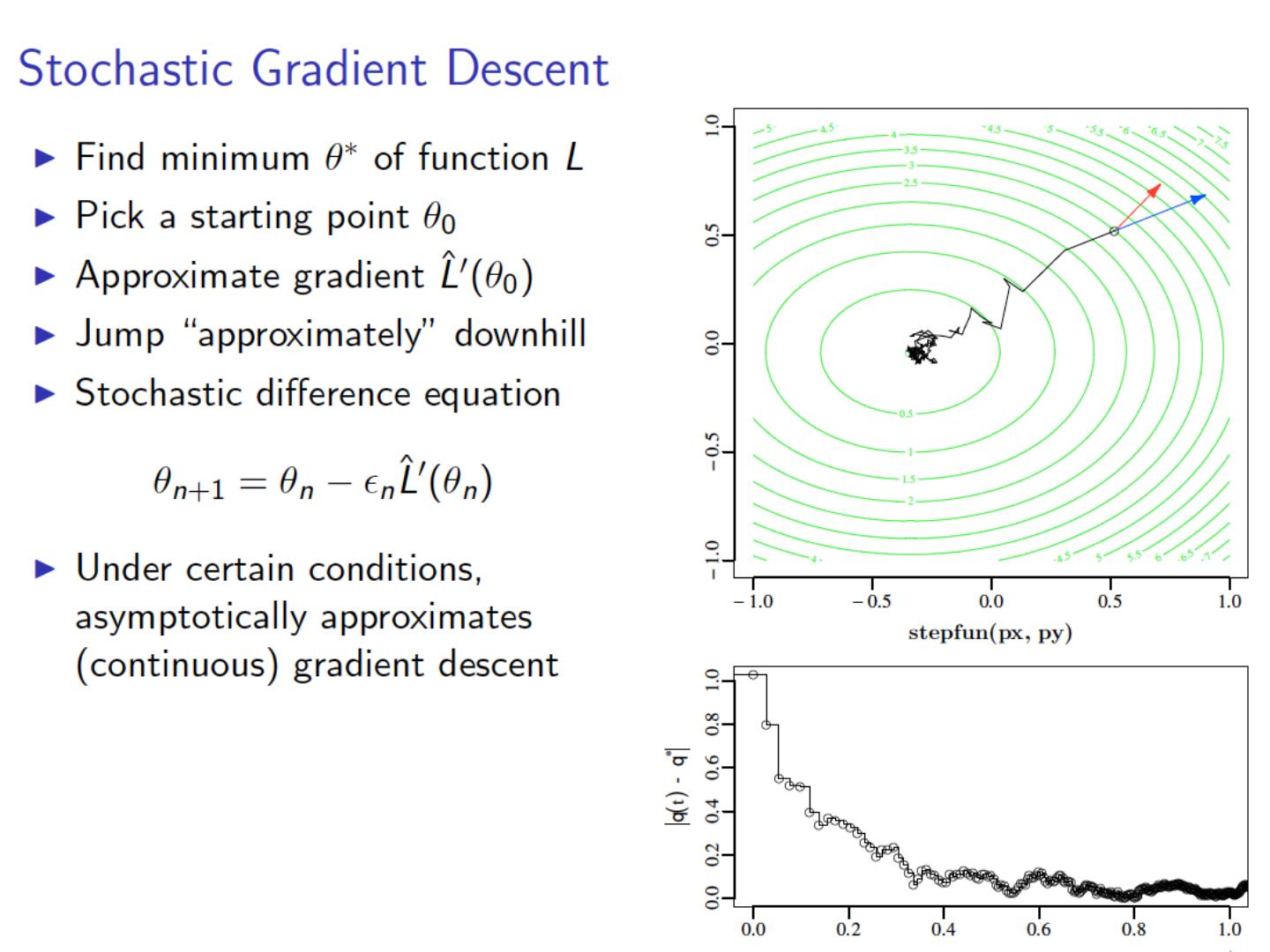
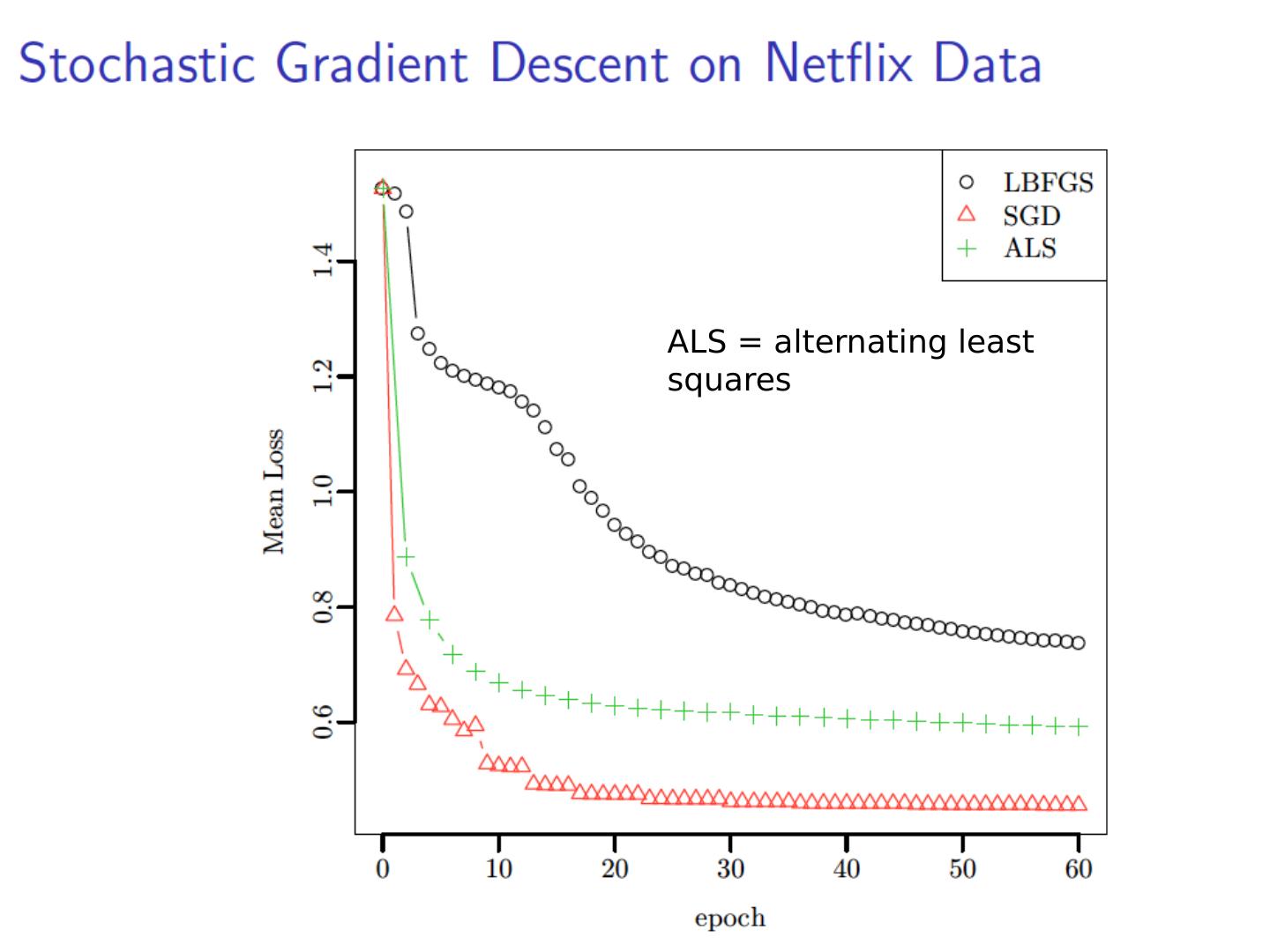
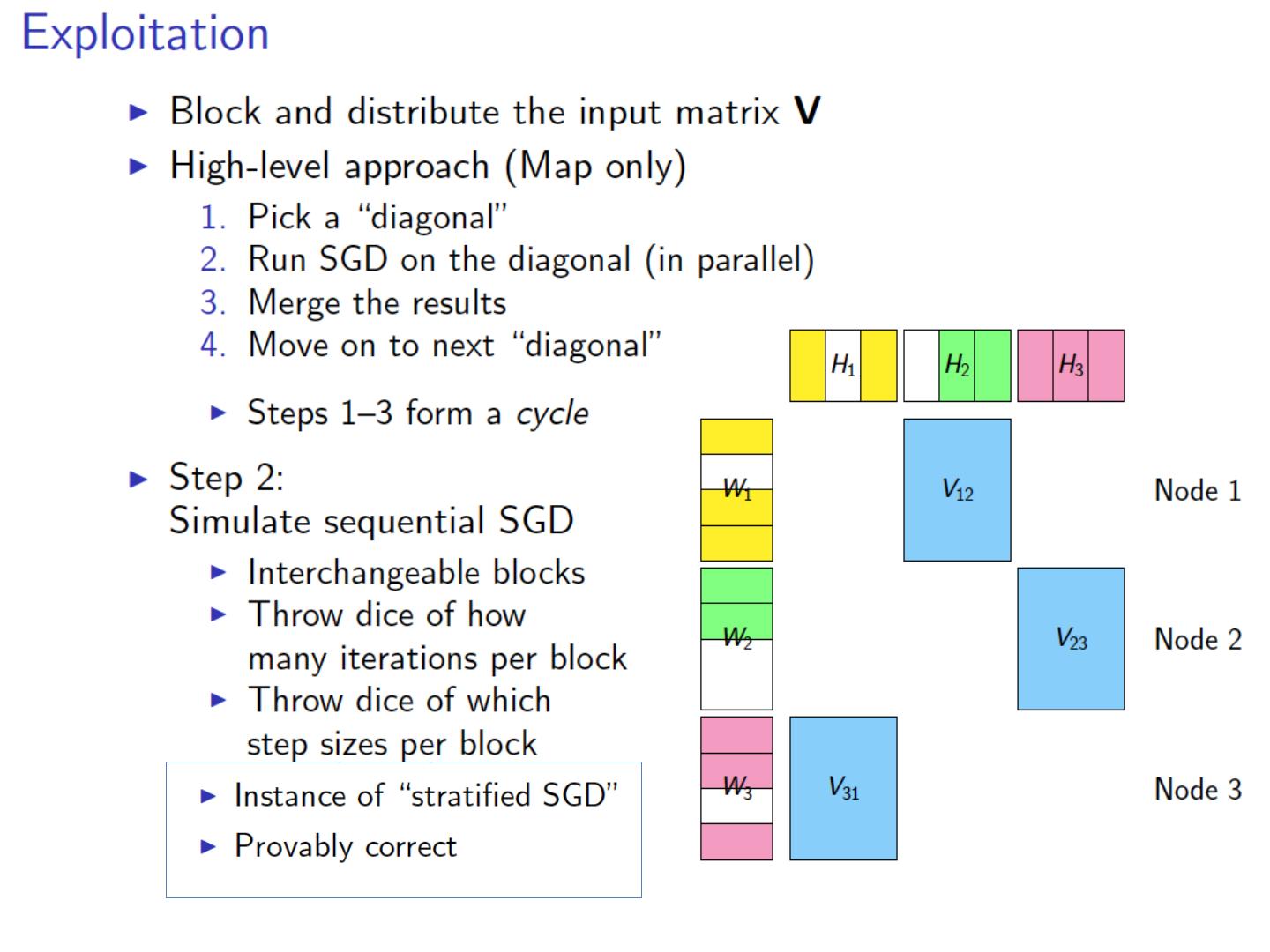
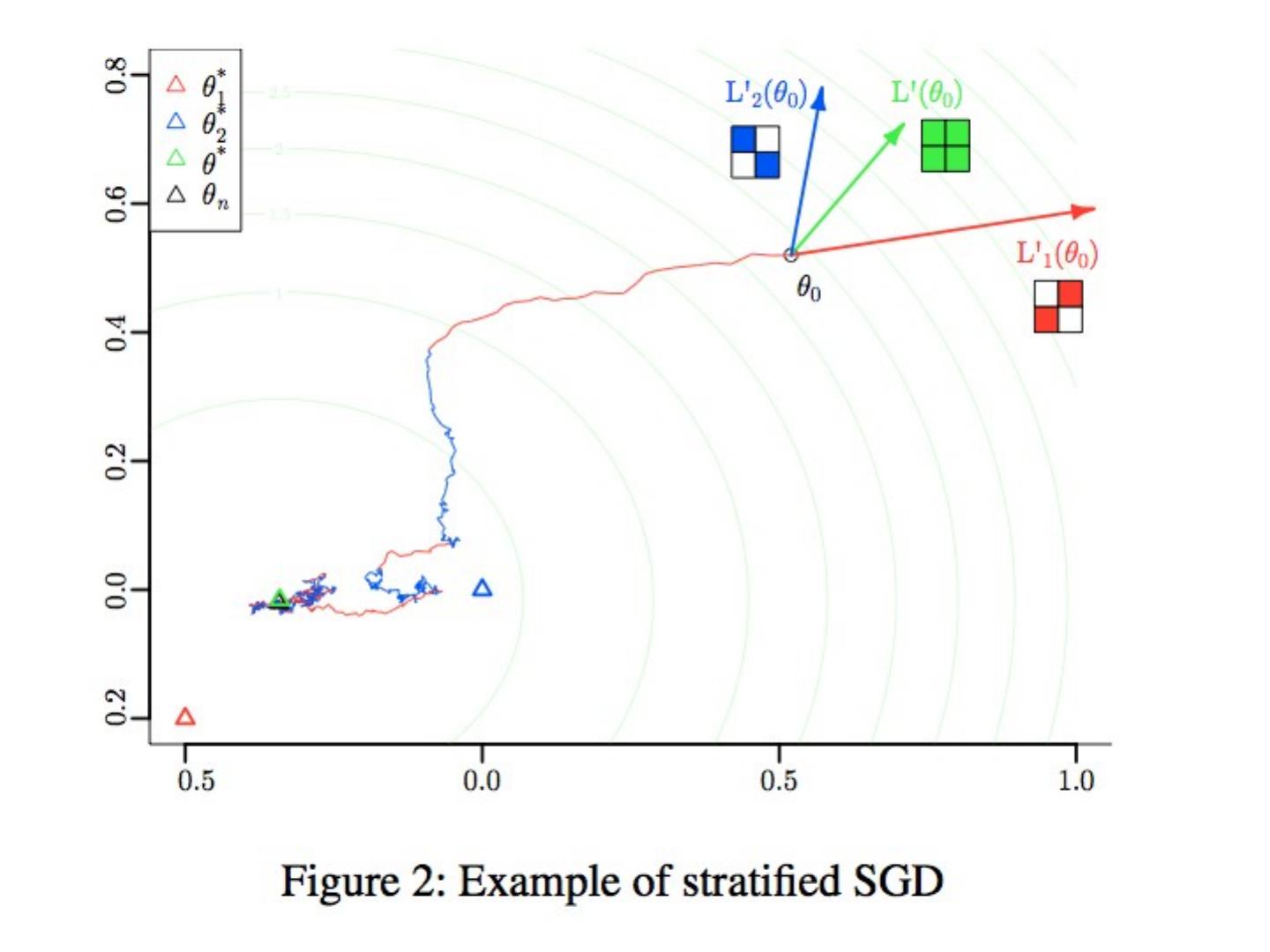
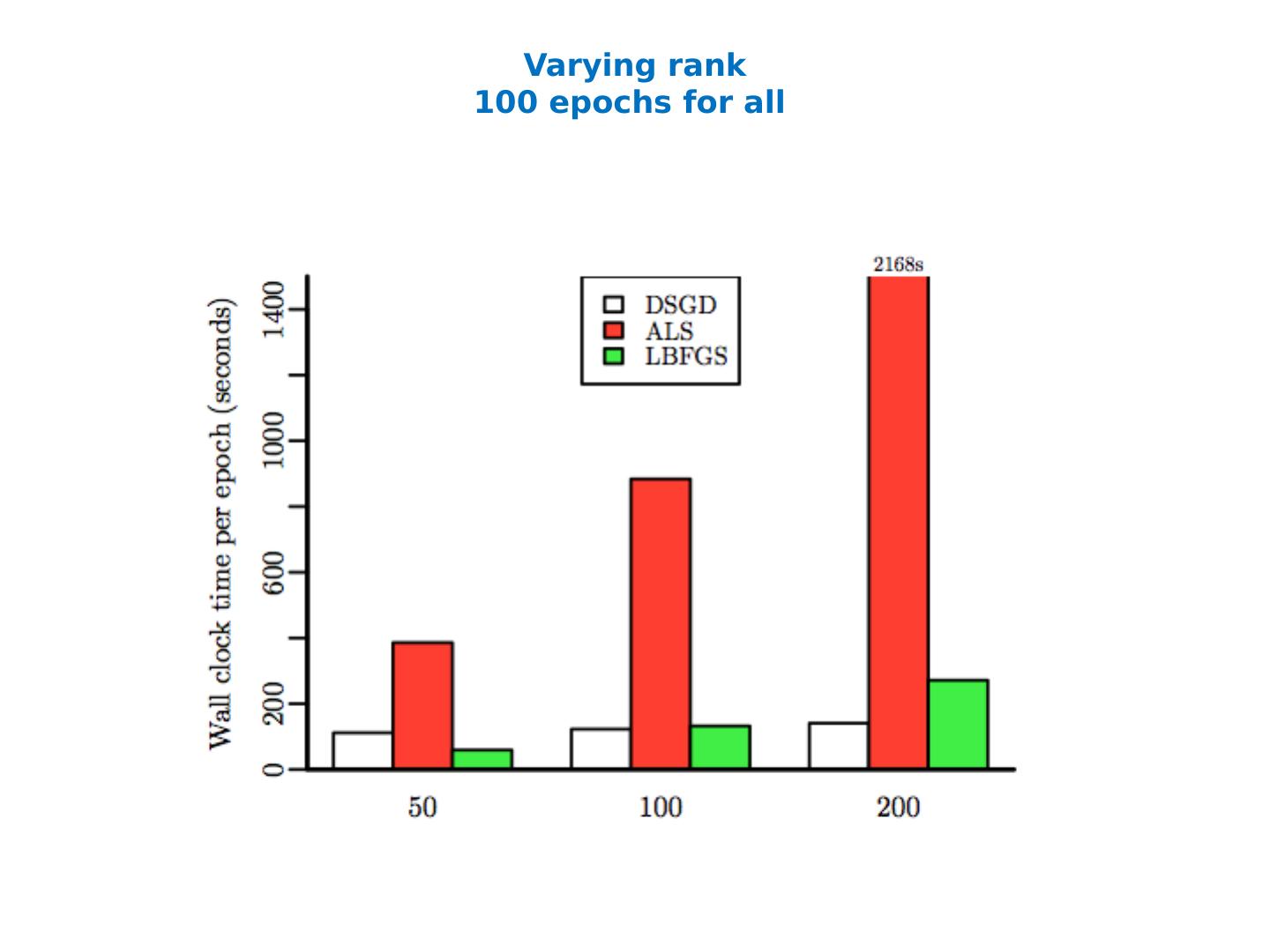
27 .Computing SVD (especially in a MapReduce setting…) Stochastic Gradient Descent (today) Stochastic SVD (not today) Other methods (not today)
28 .talk pilfered from ….. KDD 2011
29 .f or image denoising
3秒后跳转登录页面
去登陆

