









































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Key-value/NoSQL Storage
It’s a dictionary datastructure.
Insert, lookup, and delete by key
E.g., hash table, binary tree
But distributed.
Sound familiar? Remember Distributed Hash tables (DHT) in P2P systems?
It’s not surprising that key-value stores reuse many techniques from DHTs.
展开查看详情
1 .CS 525 Advanced Distributed Systems Spring 2017 Indranil Gupta (Indy) Lecture 6 Key-value/ NoSQL Storage Feb 2, 2017 All slides © IG 1
2 .The Key-value Abstraction (Business) Key Value ( twitter.com ) tweet id information about tweet ( amazon.com ) item number information about it ( kayak.com ) Flight number information about flight, e.g., availability ( yourbank.com ) Account number information about it
3 .The Key-value Abstraction (2) It’s a dictionary datastructure . Insert, lookup, and delete by key E.g., hash table, binary tree But distributed. Sound familiar? Remember Distributed Hash tables (DHT) in P2P systems? It’s not surprising that key-value stores reuse many techniques from DHTs.
4 .Isn’t that just a database? Yes, sort of Relational Database Management Systems (RDBMSs) have been around for ages MySQL is the most popular among them Data stored in tables Schema-based, i.e., structured tables Each row (data item) in a table has a primary key that is unique within that table Queried using SQL (Structured Query Language) Supports joins
5 .Relational Database Example Example SQL queries SELECT zipcode FROM users WHERE name = “ Bob ” 2. SELECT url FROM blog WHERE id = 3 SELECT users.zipcode , blog.num_posts FROM users JOIN blog ON users.blog_url = blog.url user_id name zipcode blog_url blog_id 101 Alice 12345 alice.net 1 422 Charlie 45783 charlie.com 3 555 Bob 99910 bob.blogspot.com 2 users table Primary keys id url last_updated num_posts 1 alice.net 5/2/14 332 2 bob.blogspot.com 4/2/13 10003 3 charlie.com 6/15/14 7 blog table Foreign keys
6 .Mismatch with today’s workloads Data: Large and unstructured Lots of random reads and writes Sometimes write-heavy Foreign keys rarely needed Joins infrequent
7 .Needs of Today’s Workloads Speed Avoid Single point of Failure ( SPoF ) Low TCO (Total cost of operation) Fewer system administrators Incremental Scalability Scale out, not up What?
8 .Scale out, not Scale up Scale up = grow your cluster capacity by replacing with more powerful machines Traditional approach Not cost-effective, as you’re buying above the sweet spot on the price curve And you need to replace machines often Scale out = incrementally grow your cluster capacity by adding more COTS machines (Components Off the Shelf) Cheaper Over a long duration, phase in a few newer (faster) machines as you phase out a few older machines Used by most companies who run datacenters and clouds today
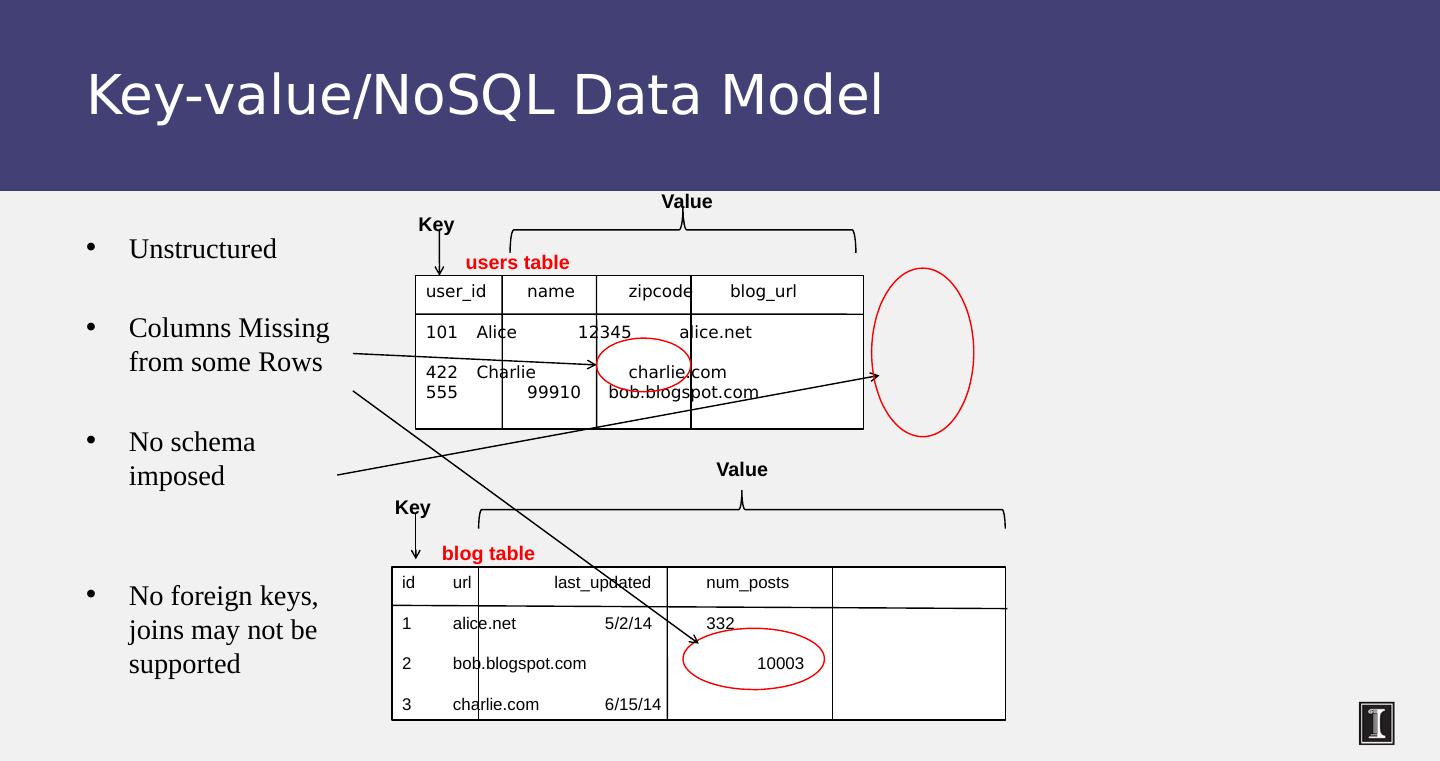
9 .Key-value/NoSQL Data Model NoSQL = “Not Only SQL” Necessary API operations: get(key) and put(key, value) And some extended operations, e.g., “CQL” in Cassandra key-value store Tables “Column families” in Cassandra, “ Table ” in HBase , “ Collection ” in MongoDB Like RDBMS tables, but … May be unstructured: May not have schemas Some columns may be missing from some rows Don’t always support joins or have foreign keys Can have index tables, just like RDBMSs
10 .Key-value/ NoSQL Data Model Unstructured Columns Missing from some Rows No schema imposed No foreign keys, joins may not be supported user_id name zipcode blog_url 101 Alice 12345 alice.net 422 Charlie charlie.com 555 99910 bob.blogspot.com users table id url last_updated num_posts 1 alice.net 5/2/14 332 2 bob.blogspot.com 10003 3 charlie.com 6/15/14 blog table Key Value Key Value
11 .Column-Oriented Storage NoSQL systems often use column-oriented storage RDBMSs store an entire row together (on disk or at a server) NoSQL systems typically store a column together (or a group of columns ). Entries within a column are indexed and easy to locate, given a key (and vice-versa) Why useful? Range searches within a column are fast since you don’t need to fetch the entire database E.g., Get me all the blog_ids from the blog table that were updated within the past month Search in the the last_updated column, fetch corresponding blog_id column Don’t need to fetch the other columns
12 .Next Design of a real key-value store, Cassandra.
13 .Cassandra A distributed key-value store Intended to run in a datacenter (and also across DCs) Originally designed at Facebook Open-sourced later, today an Apache project Some of the companies that use Cassandra in their production clusters IBM, Adobe, HP, eBay, Ericsson, Symantec Twitter, Spotify PBS Kids Netflix: uses Cassandra to keep track of your current position in the video you’re watching
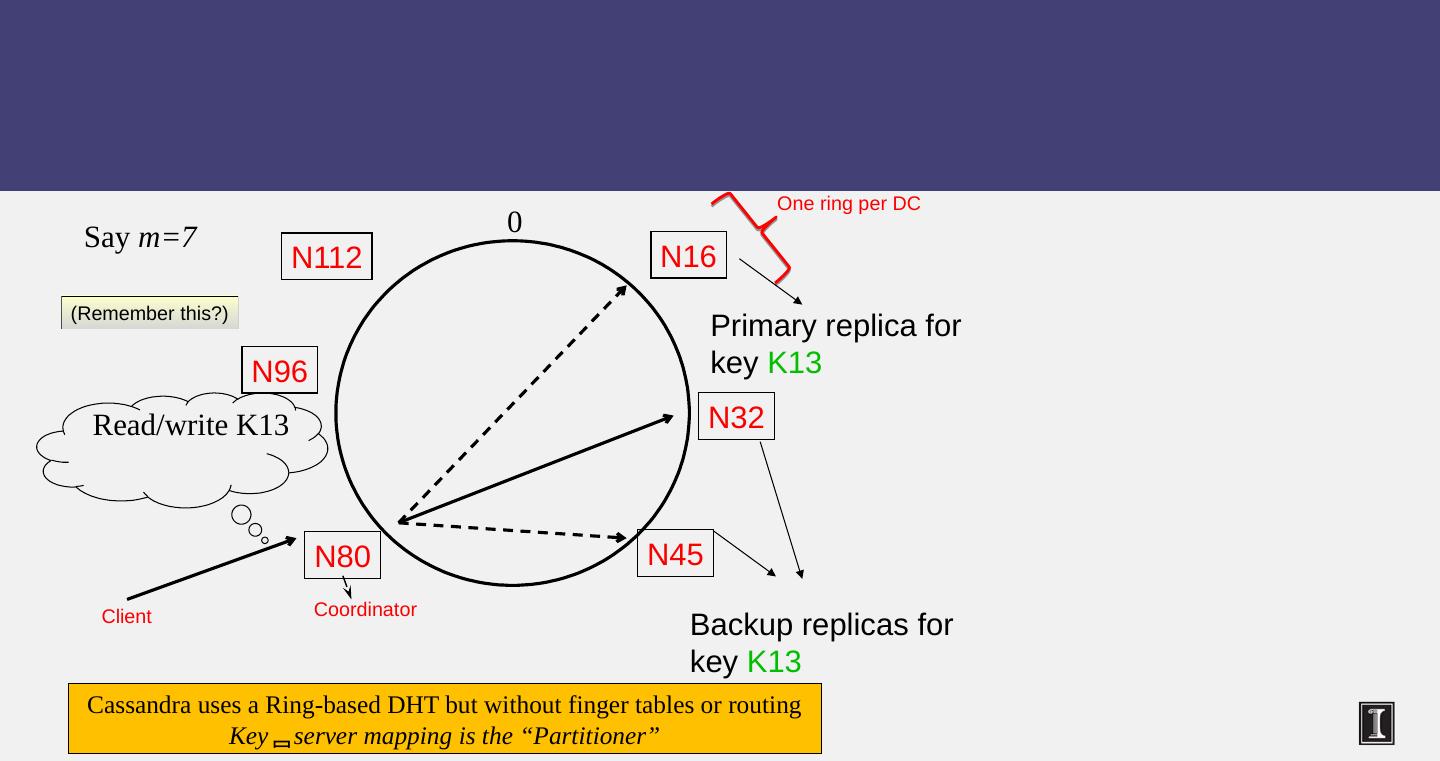
14 .Let’s go Inside Cassandra: Key -> Server Mapping How do you decide which server(s) a key-value resides on?
15 .N80 0 Say m=7 N32 N45 Backup replicas for key K13 Cassandra uses a Ring-based DHT but without finger tables or routing Key server mapping is the “ Partitioner ” N112 N96 N16 Read/write K13 Primary replica for key K13 (Remember this?) Coordinator Client One ring per DC
16 .Data Placement Strategies Replication Strategy: two options: SimpleStrategy NetworkTopologyStrategy SimpleStrategy : uses the Partitioner , of which there are two kinds RandomPartitioner : Chord-like hash partitioning ByteOrderedPartitioner : Assigns ranges of keys to servers. Easier for range queries (e.g., Get me all twitter users starting with [a-b]) NetworkTopologyStrategy : for multi-DC deployments Two replicas per DC Three replicas per DC Per DC First replica placed according to Partitioner Then go clockwise around ring until you hit a different rack
17 .Snitches Maps: IPs to racks and DCs. Configured in cassandra.yaml config file Some options: SimpleSnitch : Unaware of Topology (Rack-unaware) RackInferring : Assumes topology of network by octet of server’s IP address 101.201.202.203 = x.<DC octet>.<rack octet>.<node octet> PropertyFileSnitch : uses a config file EC2Snitch: uses EC2. EC2 Region = DC Availability zone = rack Other snitch options available
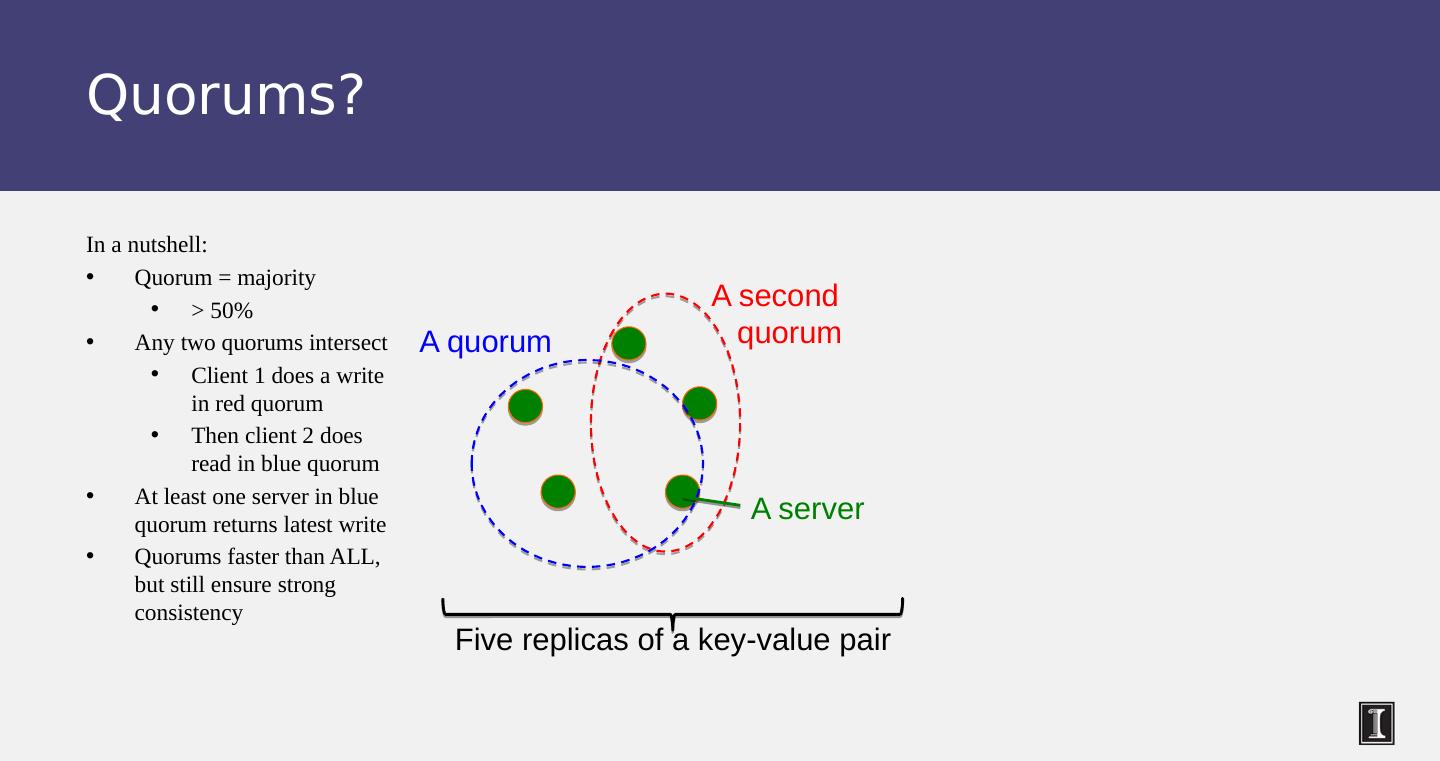
18 .Writes Need to be lock-free and fast (no reads or disk seeks) Client sends write to one coordinator node in Cassandra cluster Coordinator may be per-key, or per-client, or per-query Per-key Coordinator ensures writes for the key are serialized Coordinator uses Partitioner to send query to all replica nodes responsible for key When X replicas respond, coordinator returns an acknowledgement to the client X? We’ll see later.
19 .Writes (2) Always writable: Hinted Handoff mechanism If any replica is down, the coordinator writes to all other replicas, and keeps the write locally until down replica comes back up. When all replicas are down, the Coordinator (front end) buffers writes (for up to a few hours). One ring per datacenter Per-DC leader can be elected to coordinate with other DCs Election done via Zookeeper, which runs a Paxos (consensus) variant Paxos : elsewhere in this course
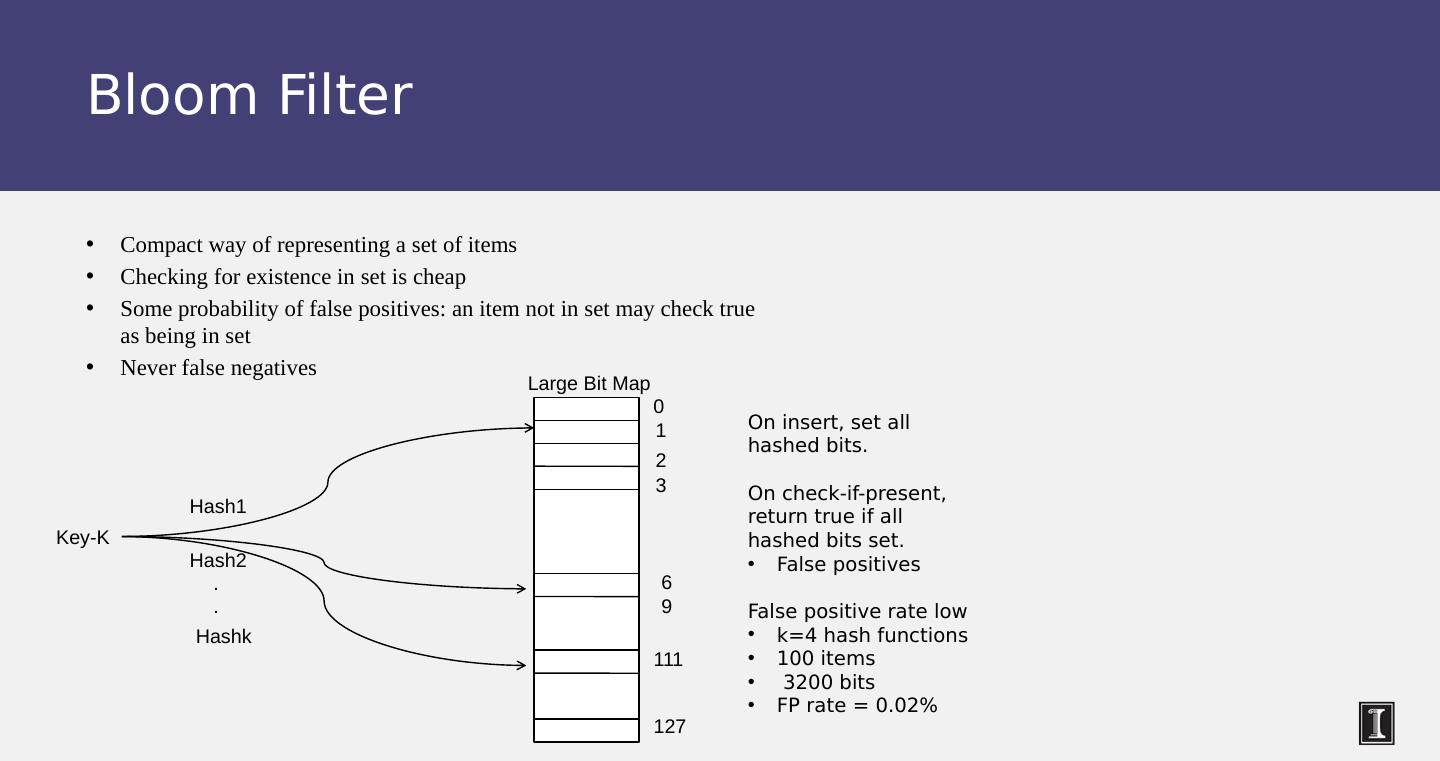
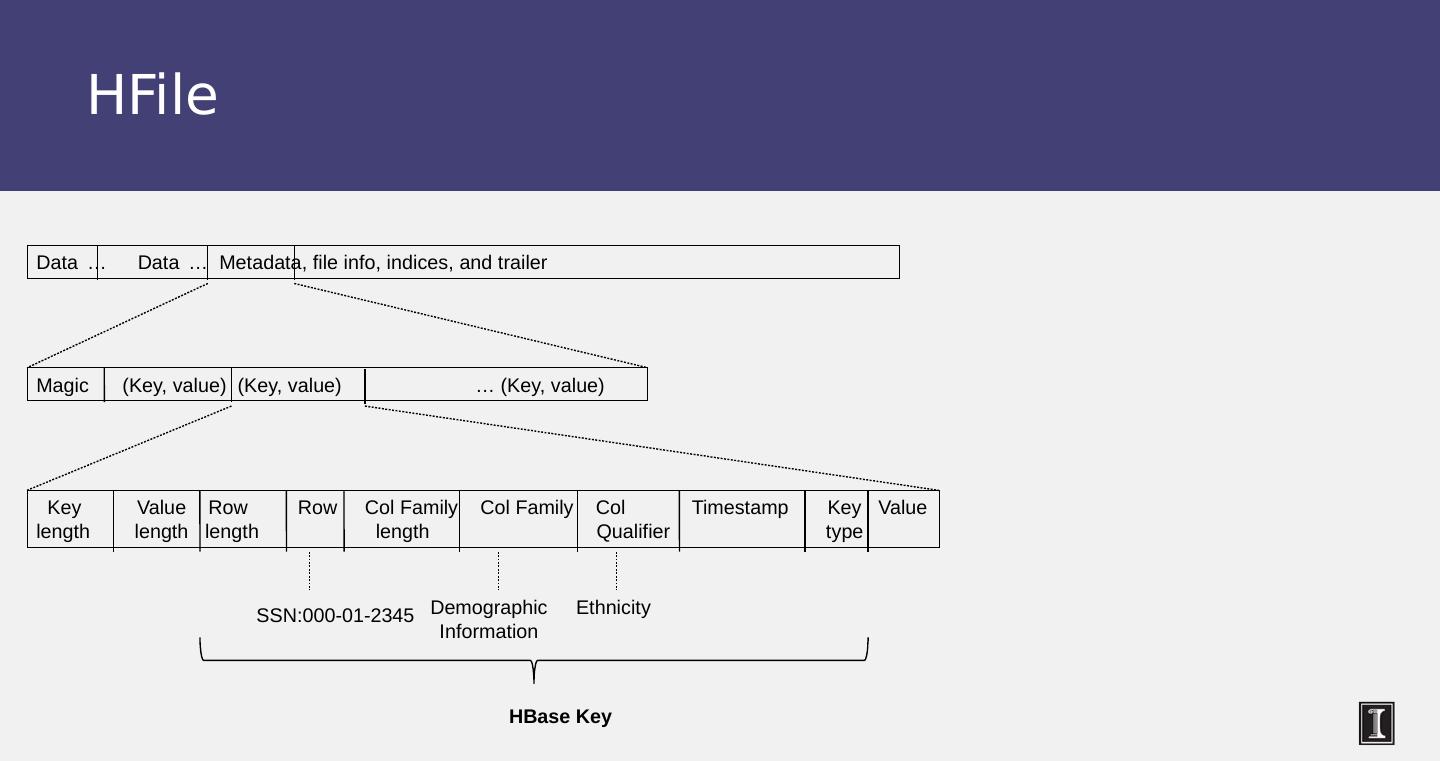
20 .Writes at a replica node On receiving a write 1. Log it in disk commit log (for failure recovery) 2. Make changes to appropriate memtables Memtable = In-memory representation of multiple key-value pairs Cache that can be searched by key Write-back cache as opposed to write-through Later, when memtable is full or old, flush to disk Data File: An SSTable (Sorted String Table) – list of key-value pairs, sorted by key Index file: An SSTable of (key, position in data sstable ) pairs And a Bloom filter (for efficient search) – next slide
21 .Bloom Filter Compact way of representing a set of items Checking for existence in set is cheap Some probability of false positives: an item not in set may check true as being in set Never false negatives Large Bit Map 0 1 2 3 69 127 111 Key-K Hash1 Hash2 Hashk On insert, set all hashed bits. On check-if-present, return true if all hashed bits set. False positives False positive rate low k=4 hash functions 100 items 3200 bits FP rate = 0.02% . .
22 .Compaction Data updates accumulate over time and SStables and logs need to be compacted The process of compaction merges SSTables , i.e., by merging updates for a key Run periodically and locally at each server
23 .Deletes Delete: don’t delete item right away Add a tombstone to the log Eventually, when compaction encounters tombstone it will delete item
24 .Reads Read: Similar to writes, except Coordinator can contact X replicas (e.g., in same rack) Coordinator sends read to replicas that have responded quickest in past When X replicas respond, coordinator returns the latest- timestamped value from among those X (X? We’ll see later.) Coordinator also fetches value from other replicas Checks consistency in the background, initiating a read repair if any two values are different This mechanism seeks to eventually bring all replicas up to date A row may be split across multiple SSTables => reads need to touch multiple SSTables => reads slower than writes (but still fast)
25 .Membership Any server in cluster could be the coordinator So every server needs to maintain a list of all the other servers that are currently in the server List needs to be updated automatically as servers join, leave, and fail
26 .Cluster Membership – Gossip-Style 1 1 10120 66 2 10103 62 3 10098 63 4 10111 65 2 4 3 Protocol: Nodes periodically gossip their membership list On receipt, the local membership list is updated, as shown If any heartbeat older than Tfail , node is marked as failed 1 10118 64 2 10110 64 3 10090 58 4 10111 65 1 10120 70 2 10110 64 3 10098 70 4 10111 65 Current time : 70 at node 2 (asynchronous clocks) Address Heartbeat Counter Time (local) Cassandra uses gossip-based cluster membership
27 .Suspicion Mechanisms in Cassandra Suspicion mechanisms to adaptively set the timeout based on underlying network and failure behavior Accrual detector: Failure Detector outputs a value (PHI) representing suspicion Apps set an appropriate threshold PHI calculation for a member Inter-arrival times for gossip messages PHI(t) = – log(CDF or Probability( t_now – t_last ))/log 10 PHI basically determines the detection timeout, but takes into account historical inter-arrival time variations for gossiped heartbeats In practice, PHI = 5 => 10-15 sec detection time
28 .Cassandra Vs. RDBMS MySQL is one of the most popular (and has been for a while) On > 50 GB data MySQL Writes 300 ms avg Reads 350 ms avg Cassandra Writes 0.12 ms avg Reads 15 ms avg Orders of magnitude faster What ’ s the catch? What did we lose?
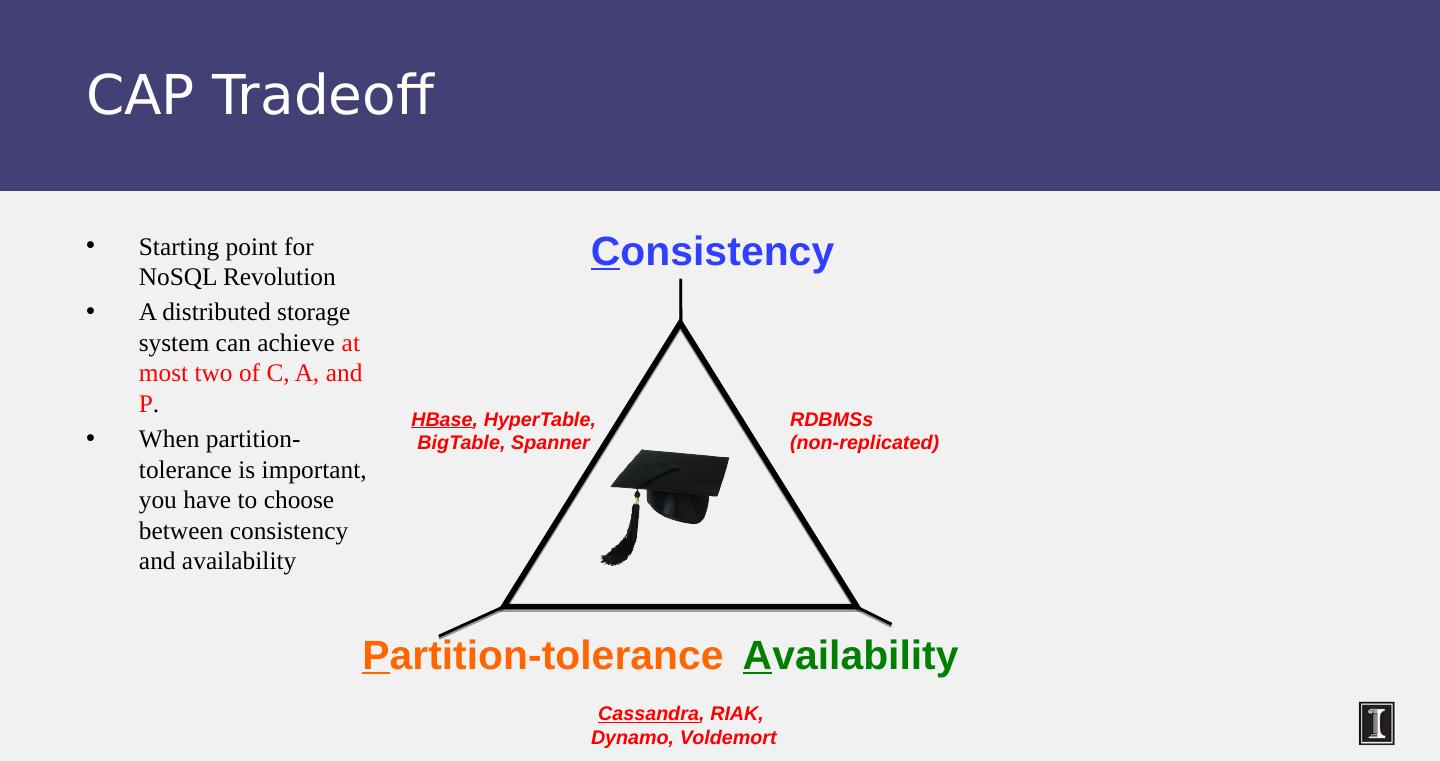
29 .Mystery of “X”: CAP Theorem Proposed by Eric Brewer (Berkeley) Subsequently proved by Gilbert and Lynch (NUS and MIT) In a distributed system you can satisfy at most 2 out of the 3 guarantees: Consistency : all nodes see same data at any time, or reads return latest written value by any client Availability : the system allows operations all the time, and operations return quickly Partition-tolerance : the system continues to work in spite of network partitions
3秒后跳转登录页面
去登陆

