


































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Cloud Computing
关于云计算的相关介绍
展开查看详情
1 . CS 525 Advanced Distributed Systems Spring 2017 Indranil Gupta (Indy) Lecture 3 Cloud Computing (Contd.) January 24, 2017 All slides © IG 1
2 . What is MapReduce? • Terms are borrowed from Functional Language (e.g., Lisp) Sum of squares: • (map square ‘(1 2 3 4)) – Output: (1 4 9 16) [processes each record sequentially and independently] • (reduce + ‘(1 4 9 16)) – (+ 16 (+ 9 (+ 4 1) ) ) – Output: 30 [processes set of all records in batches] • Let’s consider a sample application: Wordcount – You are given a huge dataset (e.g., Wikipedia dump or all of Shakespeare’s works) and asked to list the count for each of the words in each of the documents therein 2
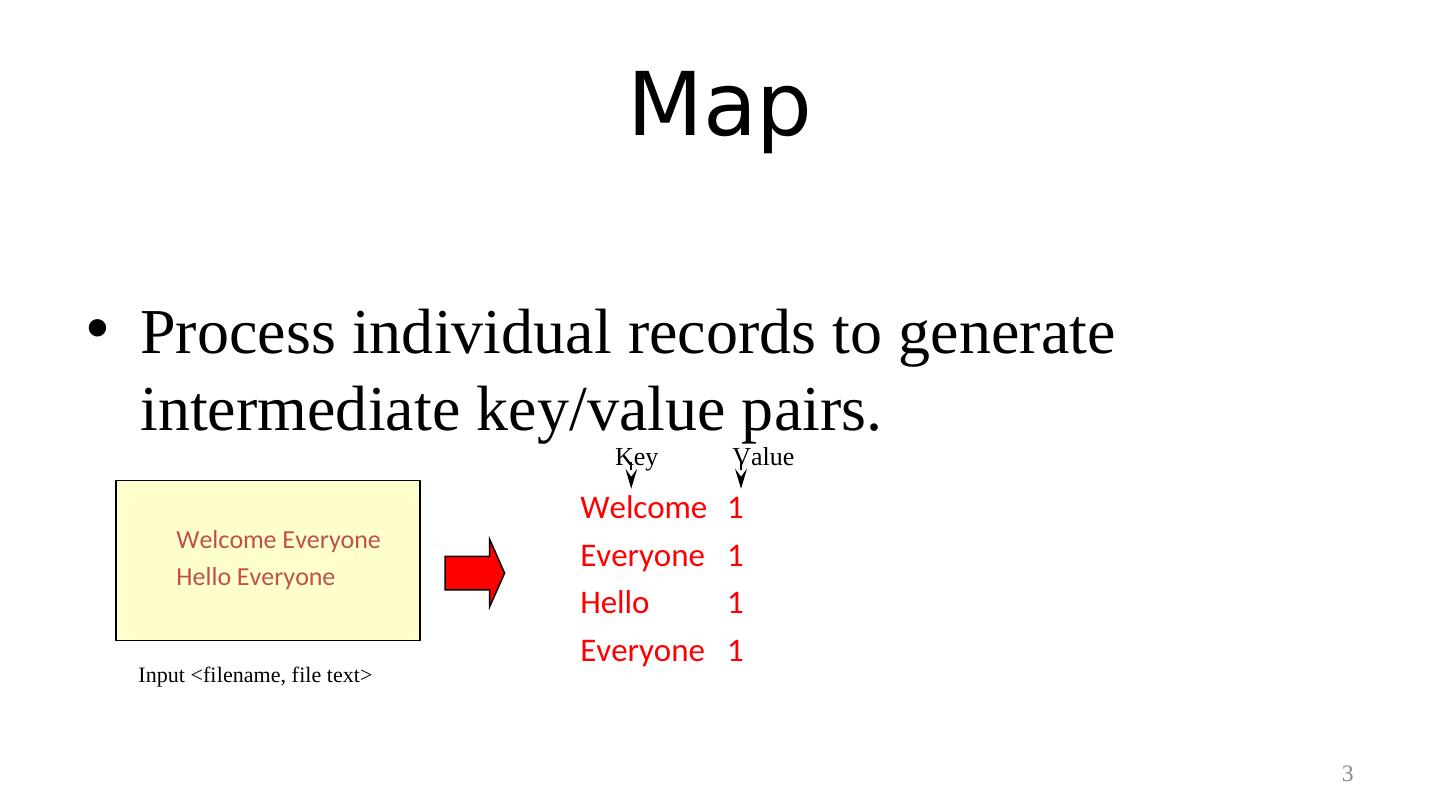
3 . Map • Process individual records to generate intermediate key/value pairs. Key Value Welcome 1 Welcome Everyone Everyone 1 Hello Everyone Hello 1 Everyone 1 Input <filename, file text> 3
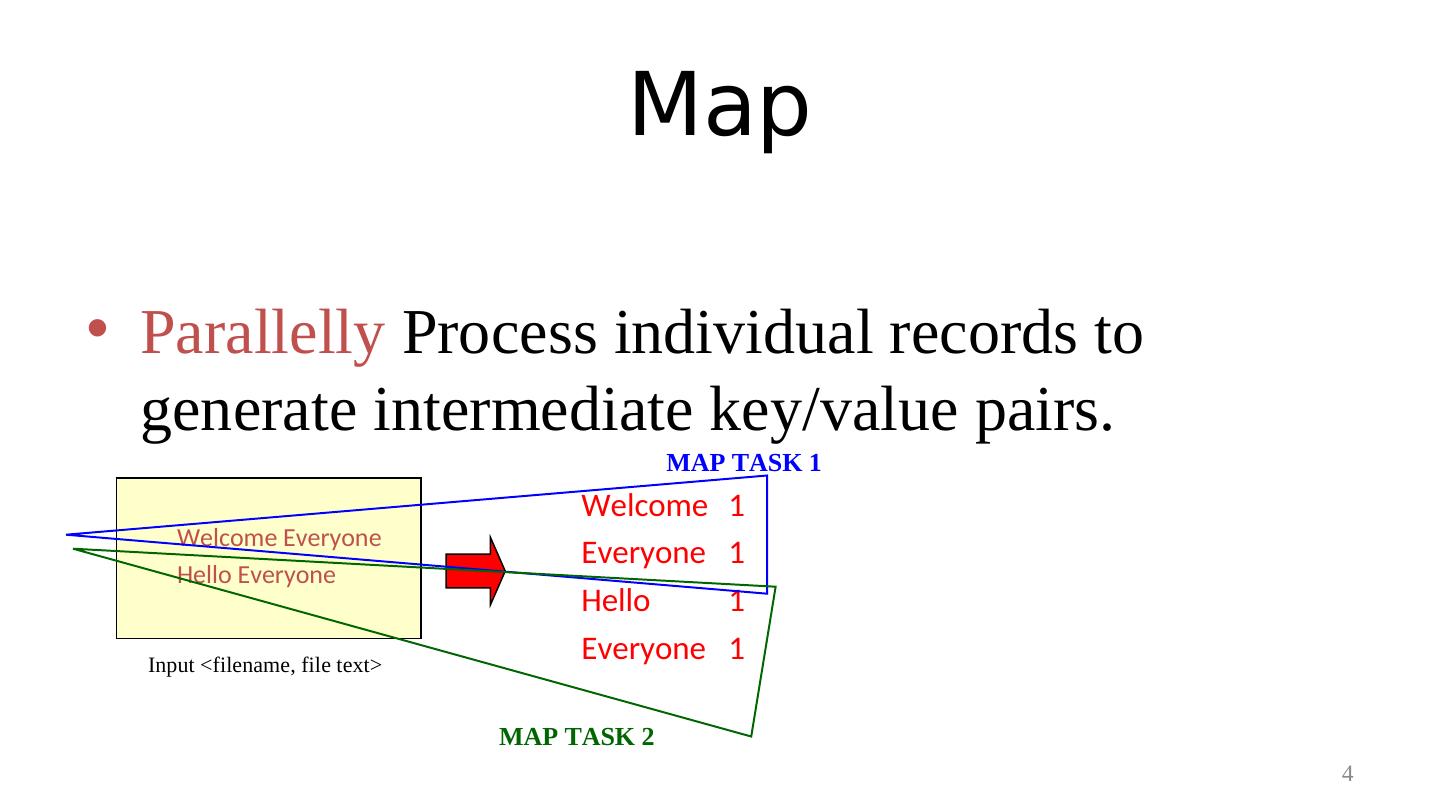
4 . Map • Parallelly Process individual records to generate intermediate key/value pairs. MAP TASK 1 Welcome 1 Welcome Everyone Everyone 1 Hello Everyone Hello 1 Input <filename, file text> Everyone 1 MAP TASK 2 4
5 . Map • Parallelly Process a large number of individual records to generate intermediate key/value pairs. Welcome 1 Welcome Everyone Everyone 1 Hello Everyone Hello 1 Why are you here Everyone 1 I am also here Why 1 They are also here Are 1 Yes, it’s THEM! You 1 The same people we were thinking of ……. Here 1 ……. Input <filename, file text> MAP TASKS 5
6 . Reduce • Reduce processes and merges all intermediate values associated per key Key Value Welcome 1 Everyone 2 Everyone 1 Hello 1 Hello 1 Welcome 1 Everyone 1 6
7 . Reduce • Each key assigned to one Reduce • Parallelly Processes and merges all intermediate values by partitioning keys Welcome 1 REDUCE Everyone 2 Everyone 1 TASK 1 Hello 1 Hello 1 REDUCE Welcome 1 Everyone 1 TASK 2 • Popular: Hash partitioning, i.e., key is assigned to reduce # = hash(key) %number of reduce servers 7
8 . Hadoop Code - Map public static class MapClass extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map( LongWritable key, Text value, /* value is a line */ OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer itr = new StringTokenizer(line); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); output.collect(word, one); } } } // Source: http://developer.yahoo.com/hadoop/tutorial/module4.html#wordcount 8
9 . Hadoop Code - Reduce public static class ReduceClass extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce( Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } // Source: http://developer.yahoo.com/hadoop/tutorial/module4.html#wordcount 9
10 . Hadoop Code - Driver // Tells Hadoop how to run your Map-Reduce job public void run (String inputPath, String outputPath) throws Exception { // The job. WordCount contains MapClass and Reduce. JobConf conf = new JobConf(WordCount.class); conf.setJobName(”mywordcount"); // The keys are words (strings) conf.setOutputKeyClass(Text.class); // The values are counts (ints) conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(MapClass.class); conf.setReducerClass(ReduceClass.class); FileInputFormat.addInputPath( conf, newPath(inputPath)); FileOutputFormat.setOutputPath( conf, new Path(outputPath)); JobClient.runJob(conf); } // Source: http://developer.yahoo.com/hadoop/tutorial/module4.html#wordcount 10
11 . Some Applications of MapReduce Distributed Grep: – Input: large set of files – Output: lines that match pattern – Map – Emits a line if it matches the supplied pattern – Reduce – Copies the intermediate data to output 11
12 . Some Applications of MapReduce (2) Reverse Web-Link Graph – Input: Web graph: tuples (a, b) where (page a page b) – Output: For each page, list of pages that link to it – Map – process web log and for each input <source, target>, it outputs <target, source> – Reduce - emits <target, list(source)> 12
13 . Some Applications of MapReduce Count of URL access frequency (3) – Input: Log of accessed URLs, e.g., from proxy server – Output: For each URL, % of total accesses for that URL – Map – Process web log and outputs <URL, 1> – Multiple Reducers - Emits <URL, URL_count> (So far, like Wordcount. But still need %) – Chain another MapReduce job after above one – Map – Processes <URL, URL_count> and outputs <1, (<URL, URL_count> )> – 1 Reducer – Does two passes over input. First sums up URL_count’s to calculate overall_count. Emits multiple <URL, URL_count/overall_count> 13
14 . Some Applications of MapReduce Map task’s output is sorted (e.g., quicksort) (4) Reduce task’s input is sorted (e.g., mergesort) Sort – Input: Series of (key, value) pairs – Output: Sorted <value>s – Map – <key, value> <value, _> (identity) – Reducer – <key, value> <key, value> (identity) – Partitioning function – partition keys across reducers based on ranges (can’t use hashing!) • Take data distribution into account to balance reducer tasks 14
15 . Programming MapReduce Externally: For user 1. Write a Map program (short), write a Reduce program (short) 2. Specify number of Maps and Reduces (parallelism level) 3. Submit job; wait for result 4. Need to know very little about parallel/distributed programming! Internally: For the Paradigm and Scheduler 1. Parallelize Map 2. Transfer data from Map to Reduce 3. Parallelize Reduce 4. Implement Storage for Map input, Map output, Reduce input, and Reduce output (Ensure that no Reduce starts before all Maps are finished. That is, ensure the barrier between the Map phase and Reduce phase) 15
16 .For the cloud: Inside MapReduce 1. Parallelize Map: easy! each map task is independent of the other! • All Map output records with same key assigned to same Reduce 2. Transfer data from Map to Reduce (“Shuffle” phase): • All Map output records with same key assigned to same Reduce task • use partitioning function, e.g., hash(key)%number of reducers 3. Parallelize Reduce: easy! each reduce task is independent of the other! 4. Implement Storage for Map input, Map output, Reduce input, and Reduce output • Map input: from distributed file system • Map output: to local disk (at Map node); uses local file system • Reduce input: from (multiple) remote disks; uses local file systems • Reduce output: to distributed file system local file system = Linux FS, etc. distributed file system = GFS (Google File System), HDFS (Hadoop Distributed File System) 16
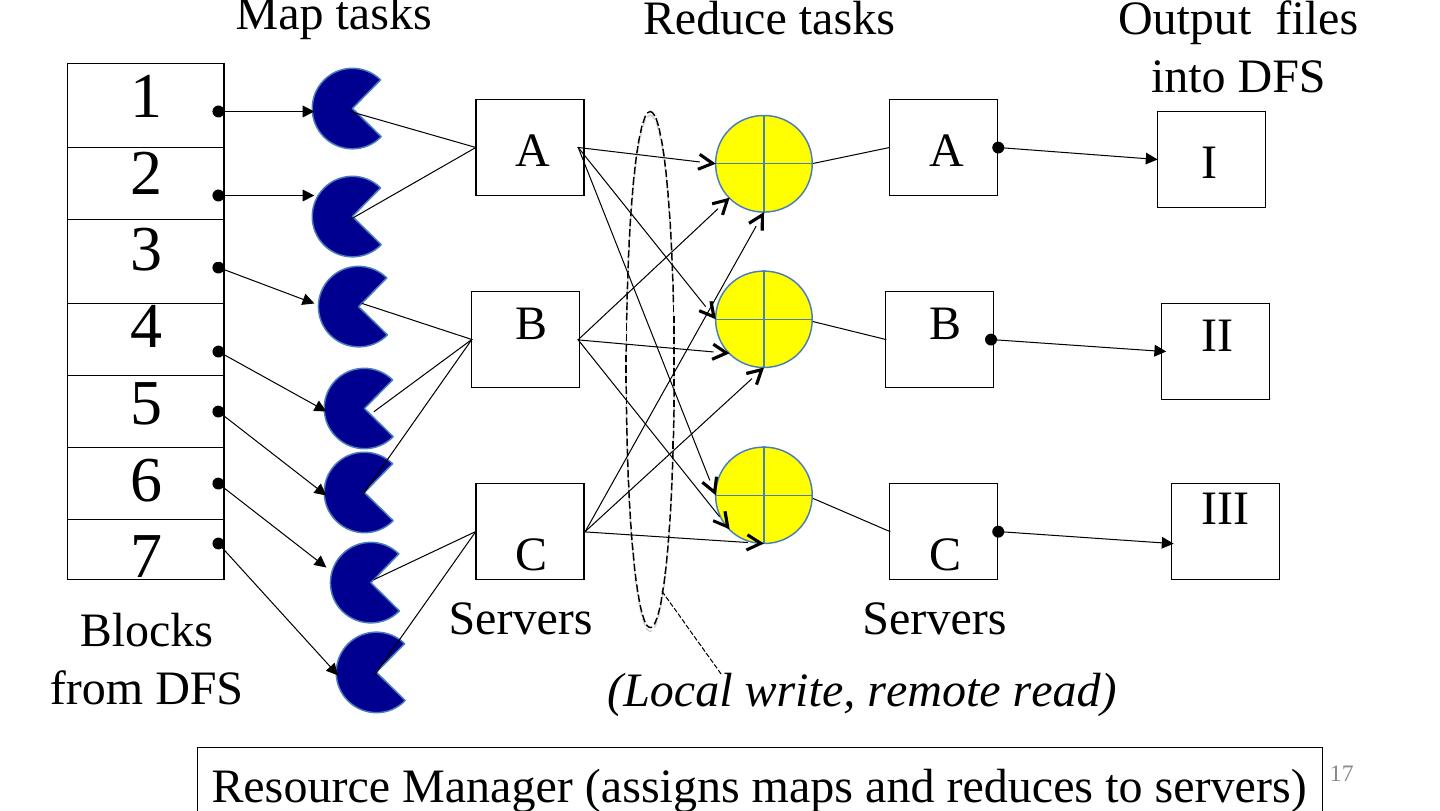
17 . Map tasks Reduce tasks Output files into DFS 1 A A I 2 3 4 B B II 5 6 III 7 C C Blocks Servers Servers from DFS (Local write, remote read) Resource Manager (assigns maps and reduces to servers) 17
18 . The YARN Scheduler • Used in Hadoop 2.x + • YARN = Yet Another Resource Negotiator • Treats each server as a collection of containers – Container = fixed CPU + fixed memory • Has 3 main components – Global Resource Manager (RM) • Scheduling – Per-server Node Manager (NM) • Daemon and server-specific functions – Per-application (job) Application Master (AM) • Container negotiation with RM and NMs • Detecting task failures of that job 18
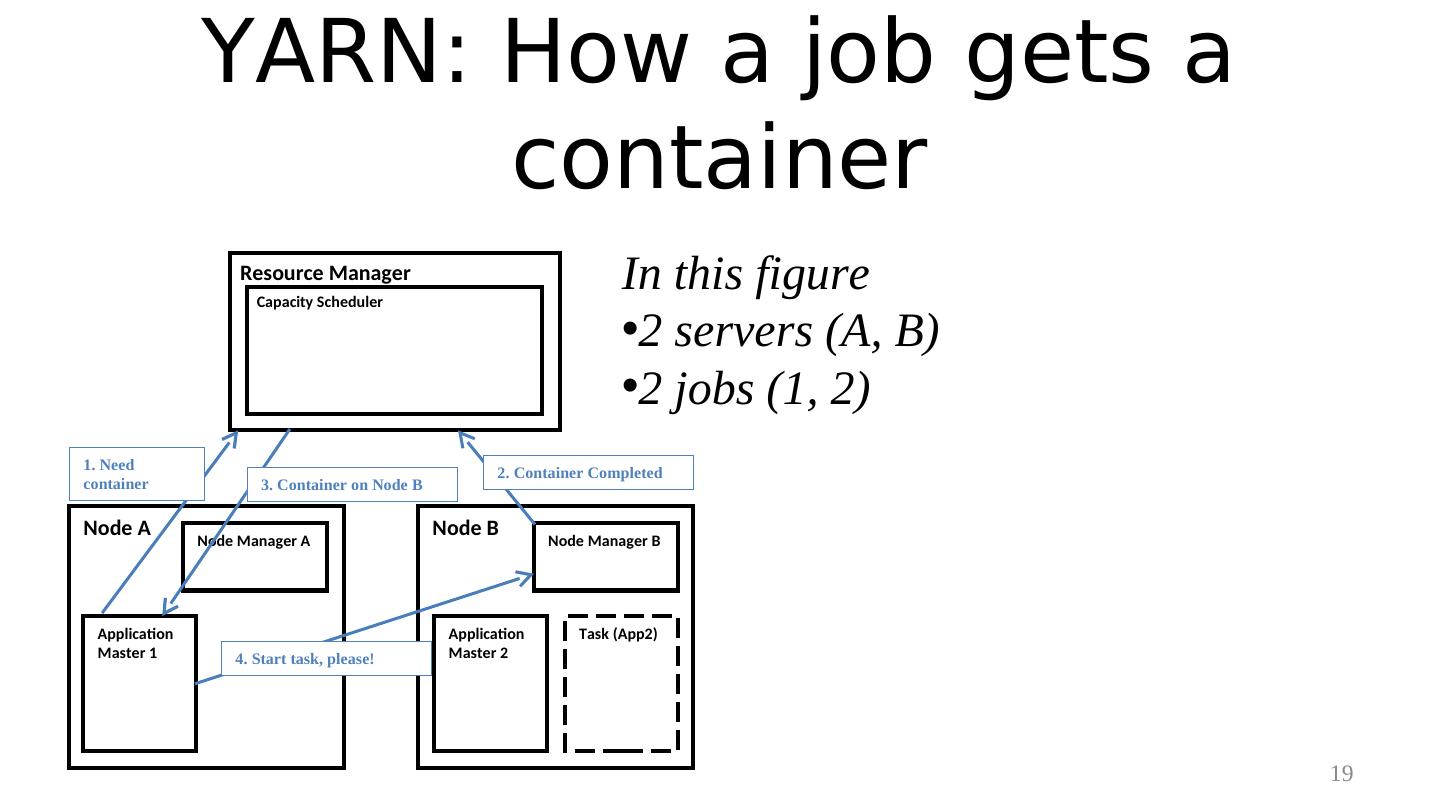
19 . YARN: How a job gets a container Resource Manager Capacity Scheduler In this figure •2 servers (A, B) •2 jobs (1, 2) 1. Need 2. Container Completed container 3. Container on Node B Node A Node Manager A Node B Node Manager B Application Application Task (App2) Master 1 4. Start task, please! Master 2 19
20 .• Server Failure Fault Tolerance – NM heartbeats to RM • If server fails, RM lets all affected AMs know, and AMs take action – NM keeps track of each task running at its server • If task fails while in-progress, mark the task as idle and restart it – AM heartbeats to RM • On failure, RM restarts AM, which then syncs up with its running tasks • RM Failure – Use old checkpoints and bring up secondary RM • Heartbeats also used to piggyback container requests – Avoids extra messages 20
21 . Slow Servers Slow tasks are called Stragglers •The slowest task slows the entire job down (why?) •Due to Bad Disk, Network Bandwidth, CPU, or Memory •Keep track of “progress” of each task (% done) •Perform proactive backup (replicated) execution of straggler task: task considered done when first replica complete. Called Speculative Execution. 21
22 . Locality • Locality – Since cloud has hierarchical topology (e.g., racks) – GFS/HDFS stores 3 replicas of each of chunks (e.g., 64 MB in size) • Maybe on different racks, e.g., 2 on a rack, 1 on a different rack – Mapreduce attempts to schedule a map task on • a machine that contains a replica of corresponding input data, or failing that, • on the same rack as a machine containing the input, or failing that, • Anywhere 22
23 . Mapreduce: Summary • Mapreduce uses parallelization + aggregation to schedule applications across clusters • Need to deal with failure • Plenty of ongoing research work in scheduling and fault-tolerance for Mapreduce and Hadoop 23
24 . 10 Challenges [Above the Clouds] (Index: Performance Data-related Scalability Logistical) • Availability of Service: Use Multiple Cloud Providers; Use Elasticity; Prevent DDOS • Data Lock-In: Standardize APIs; Enable Surge Computing • Data Confidentiality and Auditability: Deploy Encryption, VLANs, Firewalls, Geographical Data Storage • Data Transfer Bottlenecks: Data Backup/Archival; Higher BW Switches; New Cloud Topologies; FedExing Disks • Performance Unpredictability: QoS; Improved VM Support; Flash Memory; Schedule VMs • Scalable Storage: Invent Scalable Store • Bugs in Large Distributed Systems: Invent Debuggers; Real-time debugging; predictable pre- run-time debugging • Scaling Quickly: Invent Good Auto-Scalers; Snapshots for Conservation • Reputation Fate Sharing • Software Licensing: Pay-for-use licenses; Bulk use sales 24
25 . A more Bottom-Up View of Open Research Directions Myriad interesting problems that acknowledge the characteristics that make today’s cloud computing unique: massive scale + on-demand + data-intensive + new programmability + and infrastructure- and application- specific details. Monitoring: of systems&applications; single site and multi-site Storage: massive scale; global storage; for specific apps or classes Failures: what is their effect, what is their frequency, how do we achieve fault-tolerance? Scheduling: Moving tasks to data, dealing with federation Communication bottleneck: within applications, within a site Locality: within clouds, or across them Cloud Topologies: non-hierarchical, other hierarchical Security: of data, of users, of applications, confidentiality, integrity Availability of Data Seamless Scalability: of applications, of clouds, of data, of everything Geo-distributed clouds: Inter-cloud/multi-cloud computations Second Generation of Other Programming Models? Beyond MapReduce! Storm, GraphLab, Hama Pricing Models, SLAs, Fairness Green cloud computing Stream processing 25
26 . Example: Rapid Atmospheric Modeling System, ColoState U • Hurricane Georges, 17 days in Sept 1998 – “RAMS modeled the mesoscale convective complex that dropped so much rain, in good agreement with recorded data” – Used 5 km spacing instead of the usual 10 km – Ran on 256+ processors • Computation-intenstive computing (or HPC = High Performance Computing) • Can one run such a program without access to a supercomputer? 26
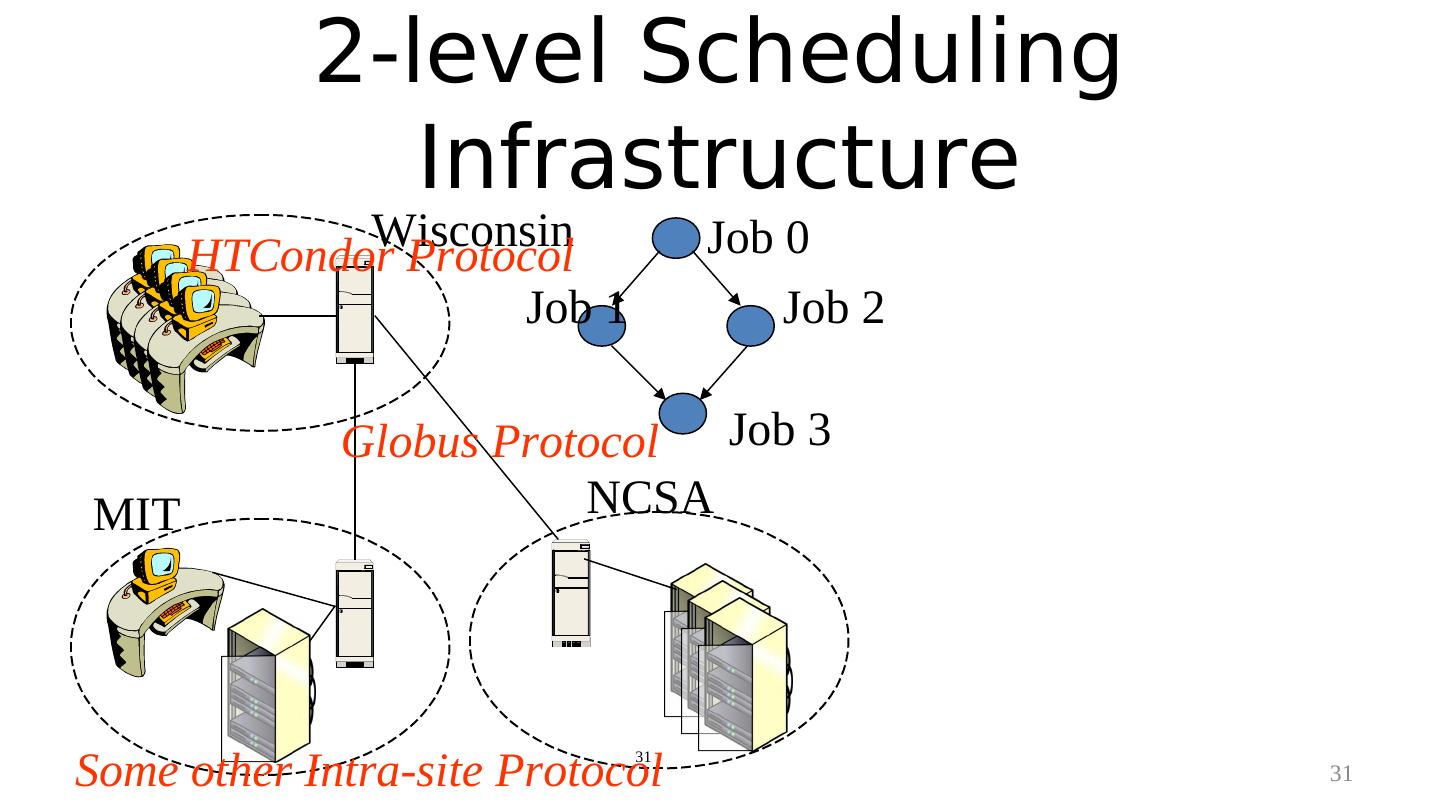
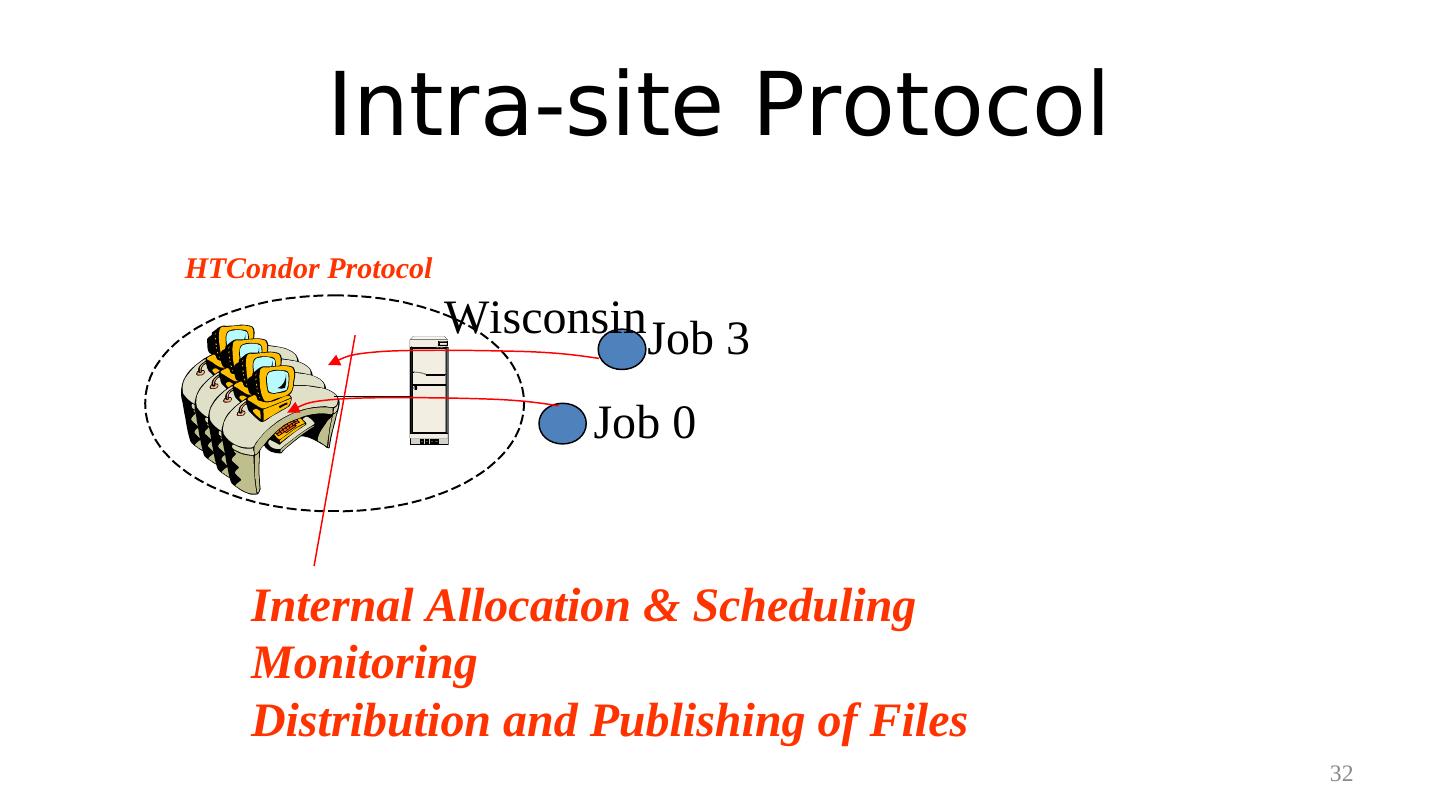
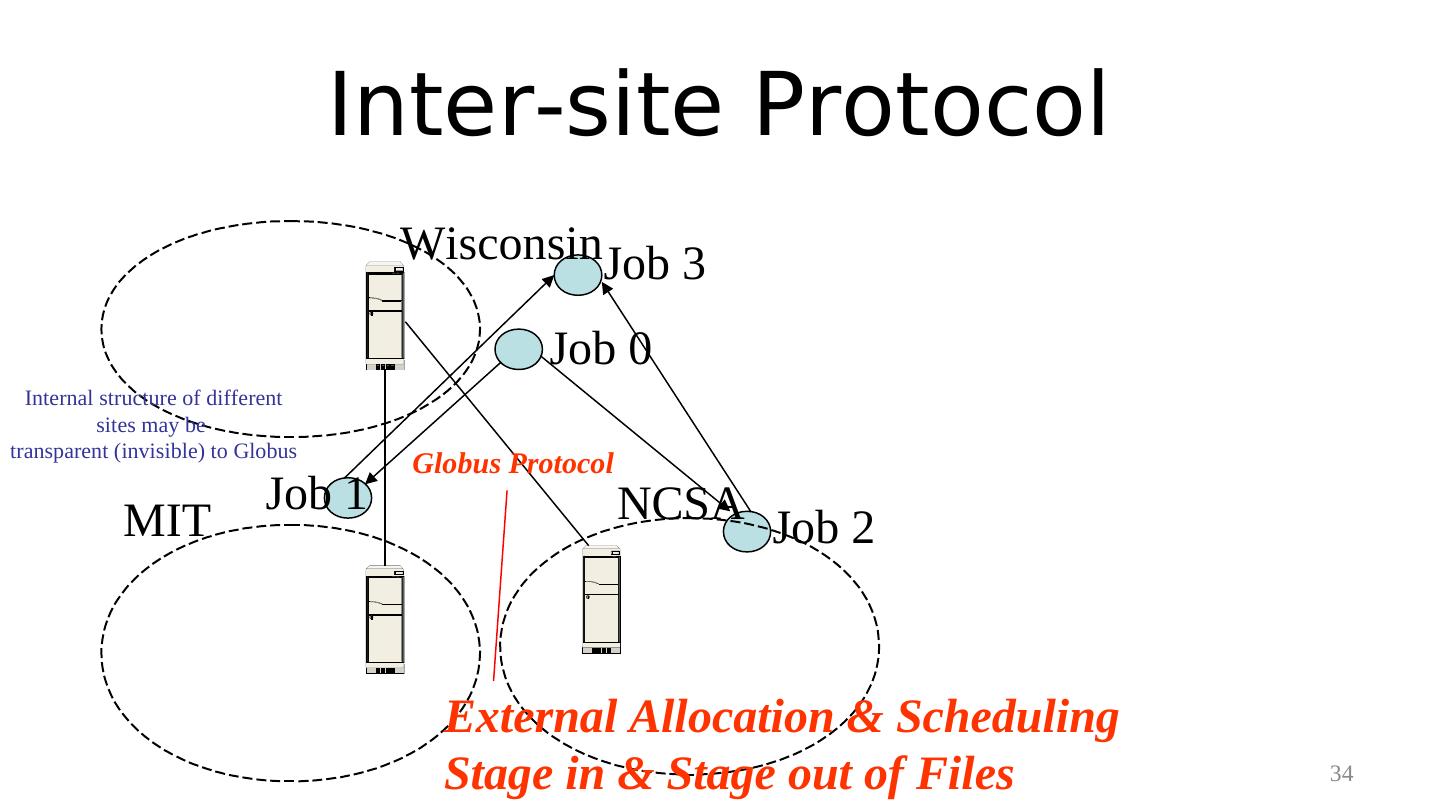
27 . Distributed Computing Resources Wisconsin MIT NCSA 27
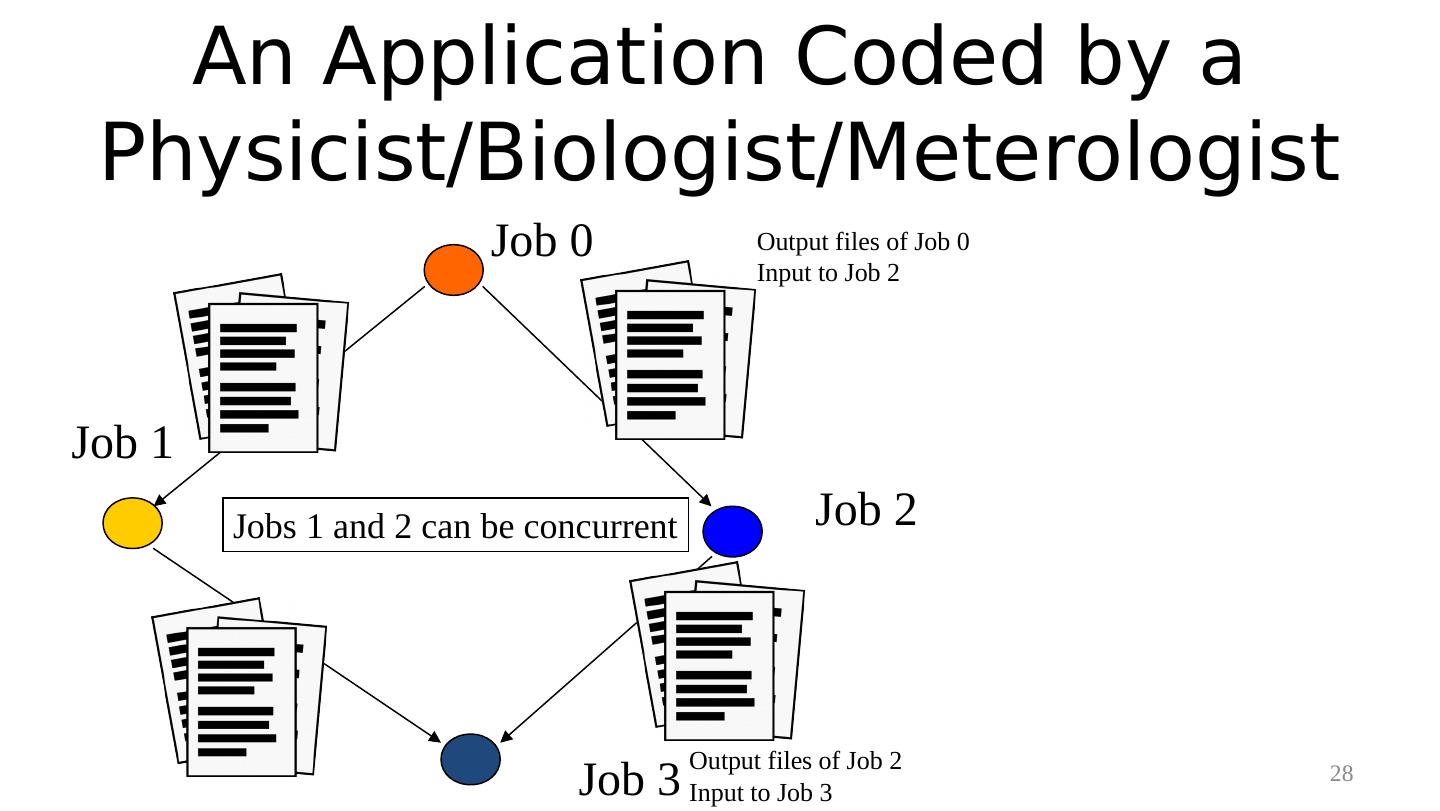
28 . An Application Coded by a Physicist/Biologist/Meterologist Job 0 Output files of Job 0 Input to Job 2 Job 1 Jobs 1 and 2 can be concurrent Job 2 Output files of Job 2 Job 3 Input to Job 3 28
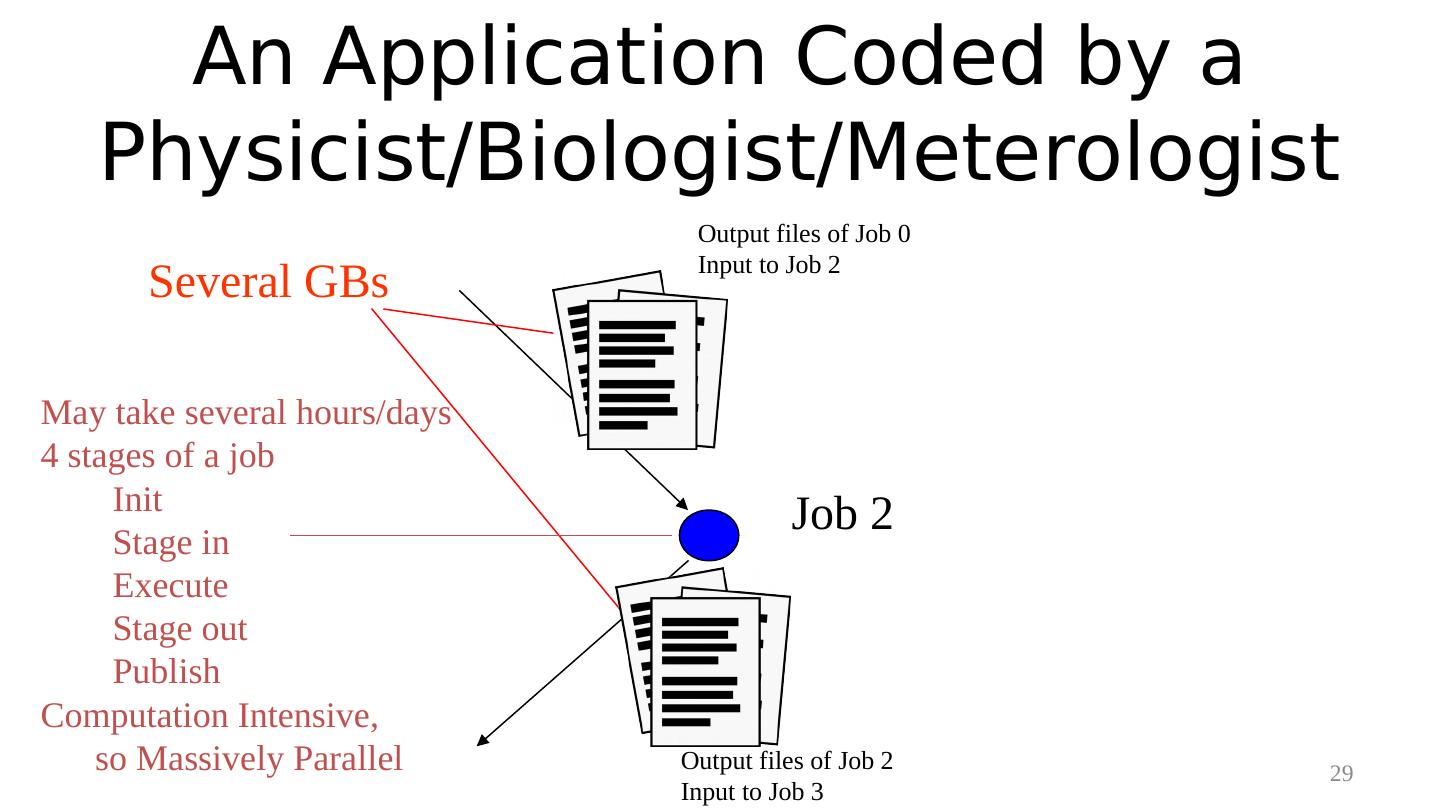
29 . An Application Coded by a Physicist/Biologist/Meterologist Output files of Job 0 Input to Job 2 Several GBs May take several hours/days 4 stages of a job Init Job 2 Stage in Execute Stage out Publish Computation Intensive, so Massively Parallel Output files of Job 2 29 Input to Job 3
3秒后跳转登录页面
去登陆

