








































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
15-MPC: Multi-Processor Computing Framework Guest Lecture
MPC: Multi-Processor Computing Framework
• Starting point: programming model used today
• Main target: transition to new programming models for Exascale
• Multi-Processor Computing (MPC)
• Multi-Processor Computing (MPC) framework
• Summary
• Unification of several parallel programming models
• Integration with other HPC components
展开查看详情
1 . MPC: Multi-Processor Computing Framework Guest Lecture Parallel Computing CIS 410/510 Department of Computer and Information Science
2 . MPC: Multi-Processor Computing Framework Patrick Carribault, Julien Jaeger and Marc Pérache JUNE 17-18, 2013 | CEA, DAM, DIFGCDV GCDV CEA, DAM, DIF, F-91297 Arpajon, France. 2
3 . Context • Starting point: programming model used today " Most used standards: MPI and/or OpenMP " Current architectures: petaflopic machines such as TERA100 " Languages: C, C++ and Fortran " Large amount of existing codes and libraries • Main target: transition to new programming models for Exascale " Provide efficient runtime to evaluate mix of programming models Unique programming model for all codes and libraries may be a non-optimal • approach " Provide smooth/incremental way to change large codes and associated libraries Avoid full rewriting before any performance results • Keep existing libraries at full current performance coupled with application • trying other programming model Example: MPI application calling OpenMP-optimized schemes/libraries • • Multi-Processor Computing (MPC) Paratools – CEA workshop| June 17-18, 2013 | PAGE 3
4 . MPC Overview • Multi-Processor Computing (MPC) framework " Runtime system and software stack for HPC " Project started in 2003 at CEA/DAM (PhD work) " Team as of May 2013 (CEA/DAM and ECR Lab) • 3 research scientists, 1 postdoc fellows, 8 PhD students, 1 apprentice, 1 engineer " Freely available at http://mpc.sourceforge.net (version 2.4.1) • Contact: marc.perache@cea.fr, patrick.carribault@cea.fr or julien.jaeger@cea.fr • Summary " Unified parallel runtime for clusters of NUMA machines • Unification of several parallel programming models " MPI, POSIX Thread, OpenMP, … • Integration with other HPC components " Parallel memory allocator, patched GCC, patched GDB, HWLOC, … Paratools – CEA workshop| June 17-18, 2013 | PAGE 4
5 .Outline Runtime Programming Optimization Models Tools Debug/Profiling Paratools – CEA workshop| June 17-18, 2013 | PAGE 5
6 . RUNTIME OPTIMIZATION 6 CEA, DAM, DIF, F-91297 Arpajon, France. CEA, DAM, DIF, F-91297 Arpajon, France. 6
7 . MPI • Goals " Smooth integration with multithreaded model " Low memory footprint " Deal with unbalanced workload • MPI 1.3 " Fully MPI 1.3 compliant • Thread-based MPI " Process virtualization " Each MPI process is a thread • Thread-level feature " From MPI2 standard " Handle up to MPI_THREAD_MULTIPLE level (max level) " Easier unification with PThread representation • Inter-process communications " Shared memory within node " TCP, InfiniBand • Tested up to 80,000 cores with various HPC codes Paratools – CEA workshop| June 17-18, 2013 | PAGE 7
8 . MPC Execution Model: Example #1 (MPI) • Application with 1 MPI task Paratools – CEA workshop| June 17-18, 2013 | PAGE 8
9 . MPI (Cont.) • Optimizations " Good integration with multithreaded models [EuroPar 08] • No spin locks: programming model fairness without any busy waiting • Scheduler-integrated polling method • Collective communications directly managed by the scheduler " Scheduler optimized for Intel Xeon Phi " Low memory footprint • Merge network buffer between MPI tasks [EuroPVM/MPI 09] • Dynamically adapt memory footprint (on going) " Deal with unbalanced workload: Collaborative polling (CP) [EuroMPI 12] " Experimental results: IMB (left-hand side) and EulerMHD 256 cores (right-hand side) CEA, DAM, DIFGCDV
10 . OpenMP • OpenMP 2.5 " OpenMP 2.5-compliant runtime integrated to MPC " Directive-lowering process done by patched GCC (C,C++,Fortran) • Generate calls to MPC ABI instead of GOMP (GCC OpenMP implementation) • Lightweight implementation " Stack-less and context-less threads (microthreads) [HiPC 08] " Dedicated scheduler (microVP) On-the-fly stack creation • " Support of oversubscribed mode Many more OpenMP threads than CPU cores • • Hybrid optimizations " Unified representation of MPI tasks and OpenMP threads [IWOMP 10] " Scheduler-integrated Multi-level polling methods " Message-buffer privatization " Parallel message reception " Large NUMA node optimization [IWOMP 12] Paratools – CEA workshop| June 17-18, 2013 | PAGE 10
11 . MPC Execution Model: Example #2 (MPI/OpenMP) • 2 MPI tasks + OpenMP parallel region w/ 4 threads (on 2 cores) Paratools – CEA workshop| June 17-18, 2013 | PAGE 11
12 . PThreads • Thread library completely in user space " Non-preemptive library " User-level threads on top of kernel threads (usually 1 per CPU core) " Automatic binding (kernel threads) + explicit migration (user threads) " MxN O(1) scheduler • Ability to map M threads on N cores (with M>>N) • Low complexity • POSIX compatibility " POSIX-thread compliant " Expose whole PThread API • Integration with other thread models: " Intel’s Thread Building Blocks (TBB) è Small patches to remove busy waiting " Unified Parallel C (UPC) " Cilk Paratools – CEA workshop| June 17-18, 2013 | PAGE 12
13 . Memory Allocation on Linux System Memory allocation " Linux uses lazy allocation " Small allocations (< 128kB) GLIBC uses buffers to avoid high frequency call to sbrk/brk " Big allocations (>= 128kB) GLIBC uses mmap system calls Malloc calls are only virtual memory reservations The real memory allocations are performed during first touch What appends during first touch: " Hardware generates an interruption " Jump to the OS " Search of the related VMA and check reason of the fault " Request a free page to NUMA free list " Reset the page content " Map the page in the VMA, update the page table " Return to the process " It was done for all 4K pages (262 144 times for 1GB) Paratools – CEA workshop| June 17-18, 2013 | PAGE 13
14 . Page fault performances " Page fault scalability evaluation Multithread based approach (1 thread per core) Process based approach (1 process per core) " 4*4 Nehalem-EP=128 cores (left hand side) and Xeon Phi (right hand side) November 9, 2014 NNSA/CEA Meeting | June 4, 2013 | PAGE 14
15 . Memory Allocation Optimization Step 1: User Space Goals " Reduce the number of system calls " Increase performance in multithreaded context with a large number of cores " Maintain data locality (NUMA-aware) Ideas " Hierarchical memory allocator " Increase memory buffer size November 9, 2014 Paratools – CEA workshop| June 17-18, 2013 | PAGE 15
16 .AMR Code + MPC on NEHALEM-EP (128: 4*4*8 cores) Paratools – CEA workshop| June 17-18, 2013 | PAGE 16
17 . Memory Allocation Optimization Step 2: Kernel Space Diagnosis " 40% of a page fault time is due to zero-page Goals " Reuse page within a process è avoid useless page cleaning " Portable for large number of memory allocators (use the mmap semantics) mmap(…MAP_ANON…) mmap(…MAP_ANON|MAP_PAGE_REUSE…) User space Process 0 Process 1 Process 2 Process 3 Local pool Local pool Local pool Kernel code Free pages November 9, 2014 Kernel space Paratools – CEA workshop| June 17-18, 2013 | PAGE 17
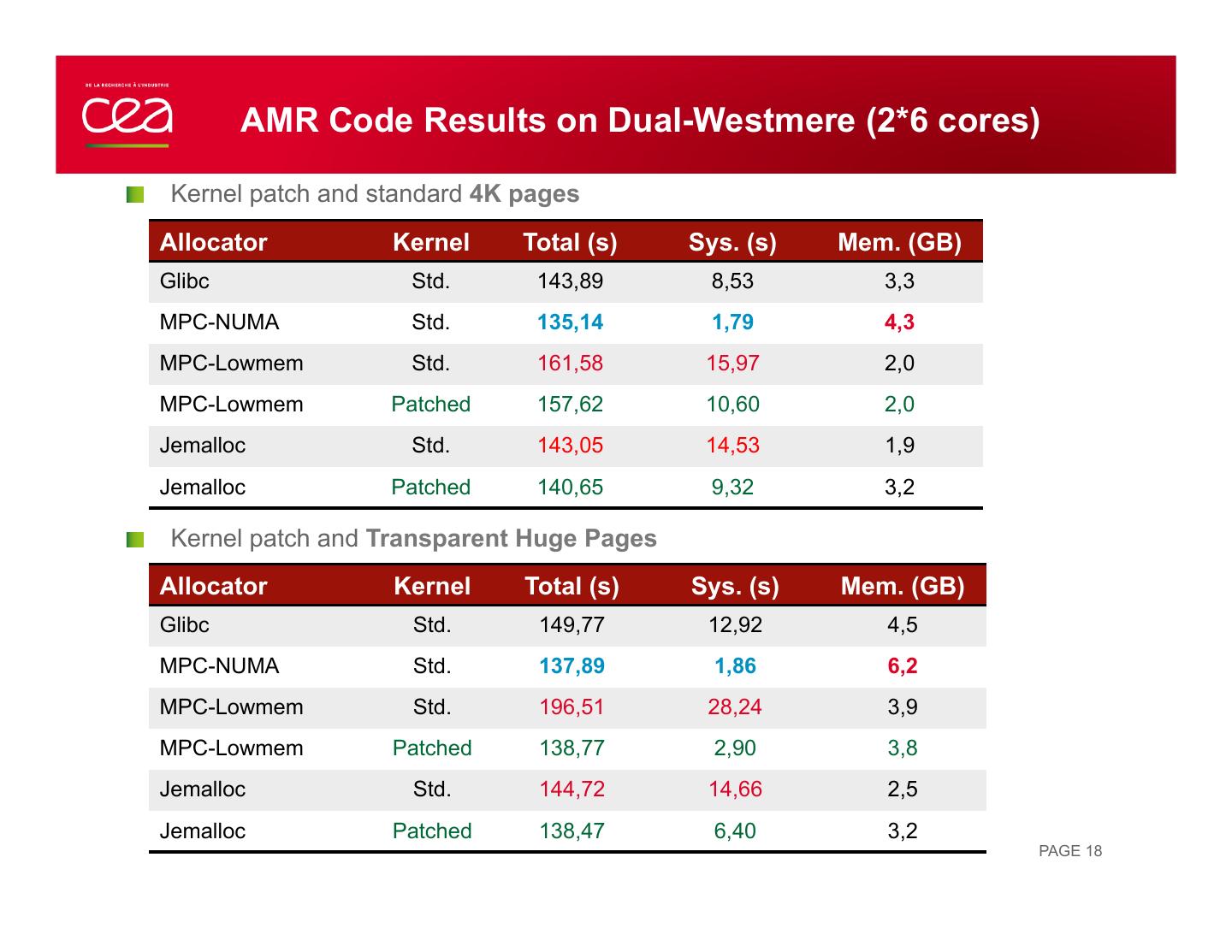
18 . AMR Code Results on Dual-Westmere (2*6 cores) " Kernel patch and standard 4K pages Allocator Kernel Total (s) Sys. (s) Mem. (GB) Glibc Std. 143,89 8,53 3,3 MPC-NUMA Std. 135,14 1,79 4,3 MPC-Lowmem Std. 161,58 15,97 2,0 MPC-Lowmem Patched 157,62 10,60 2,0 Jemalloc Std. 143,05 14,53 1,9 Jemalloc Patched 140,65 9,32 3,2 " Kernel patch and Transparent Huge Pages Allocator Kernel Total (s) Sys. (s) Mem. (GB) Glibc Std. 149,77 12,92 4,5 MPC-NUMA Std. 137,89 1,86 6,2 MPC-Lowmem Std. 196,51 28,24 3,9 MPC-Lowmem Patched 138,77 2,90 3,8 Jemalloc Std. 144,72 14,66 2,5 Jemalloc Patched 138,47 6,40 3,2 PAGE 18
19 .AMR Code Results on Dual-Westmere (2*6 cores) NNSA/CEA Meeting | June 4, 2013 | PAGE 19
20 . Conclusion on memory allocation NUMA-aware thread-aware allocator " User space: Reduce the number of system calls Keep data locality Good performances with a large number of threads Tradeoff between memory consumption and execution time User space allocator in included within the MPC framework " Kernel space: Remove useless page cleaning Portable Increase performances for standard and huge pages Useful within virtual machines " More details in: S. Valat, M. Pérache, W. Jalby. Introducing Kernel-Level Page Reuse for High Performance Computing. (To Appear in MSPC’13) November 9, 2014 Paratools – CEA workshop| June 17-18, 2013 | PAGE 20
21 . PROGRAMMING MODELS 21 CEA, DAM, DIF, F-91297 Arpajon, France. CEA, DAM, DIF, F-91297 Arpajon, France.
22 . Extended TLS [IWOMP 11] • Mixing of thread-based models require flexible data management " Design and implementation of Extended TLS (Thread-Local Storage) • Cooperation between compiler and runtime system • Compiler part (GCC) " New middle-end pass to place variables to the right extended-TLS level " Modification of backend part for code generation (link to the runtime system) • Runtime part (MPC) " Integrated to user-level thread mechanism " Copy-on-write optimization " Modified context switch to update pointer to extended TLS variables • Linker optimization (GLIBC) " Support all TLS modes " Allow Extended TLS usage without overhead Paratools – CEA workshop| June 17-18, 2013 | PAGE 22
23 . Extended TLS Application: Automatic Privatization • Global variables " Expected behavior: duplicated for each MPI task " Issue with thread-based MPI: global variables shared by MPI tasks located on the same node • Solution: Automatic privatization " Automatically convert any MPI code for thread-based MPI compliance " Duplicate each global variable • Design & Implementation " Completely transparent to the user " New option to GCC C/C++/Fortran compiler (-fmpc_privatize) " When parsing or creating a new global variable: flag it as thread-local " Generate runtime calls to access such variables (extension of TLS mechanism) " Linker optimization for reduce overhead of global variable access • On-going Intel compiler support for Xeon and MIC Paratools – CEA workshop| June 17-18, 2013 | PAGE 23
24 . HLS (Hierarchical Local Storage) [IPDPS 12] 2000 1800 " Goal: Allow to share data among MPI tasks 1600 " Require compiler support Per-node memory consumption (MB) 1400 " Allows to save memory (GBs) per node 1200 " Example of one global variable named var 1000 " Duplicated in standard MPI environment 800 " Shared with HLS directive 600 #pragma hls node(var) 400 " Updated with HLS directive 200 0 #pragma hls single(var) { ... } 256 512 736 Number of cores MPC w/ HLS MPC OpenMPI CEA | May 14-15th, 2013 | PAGE 24
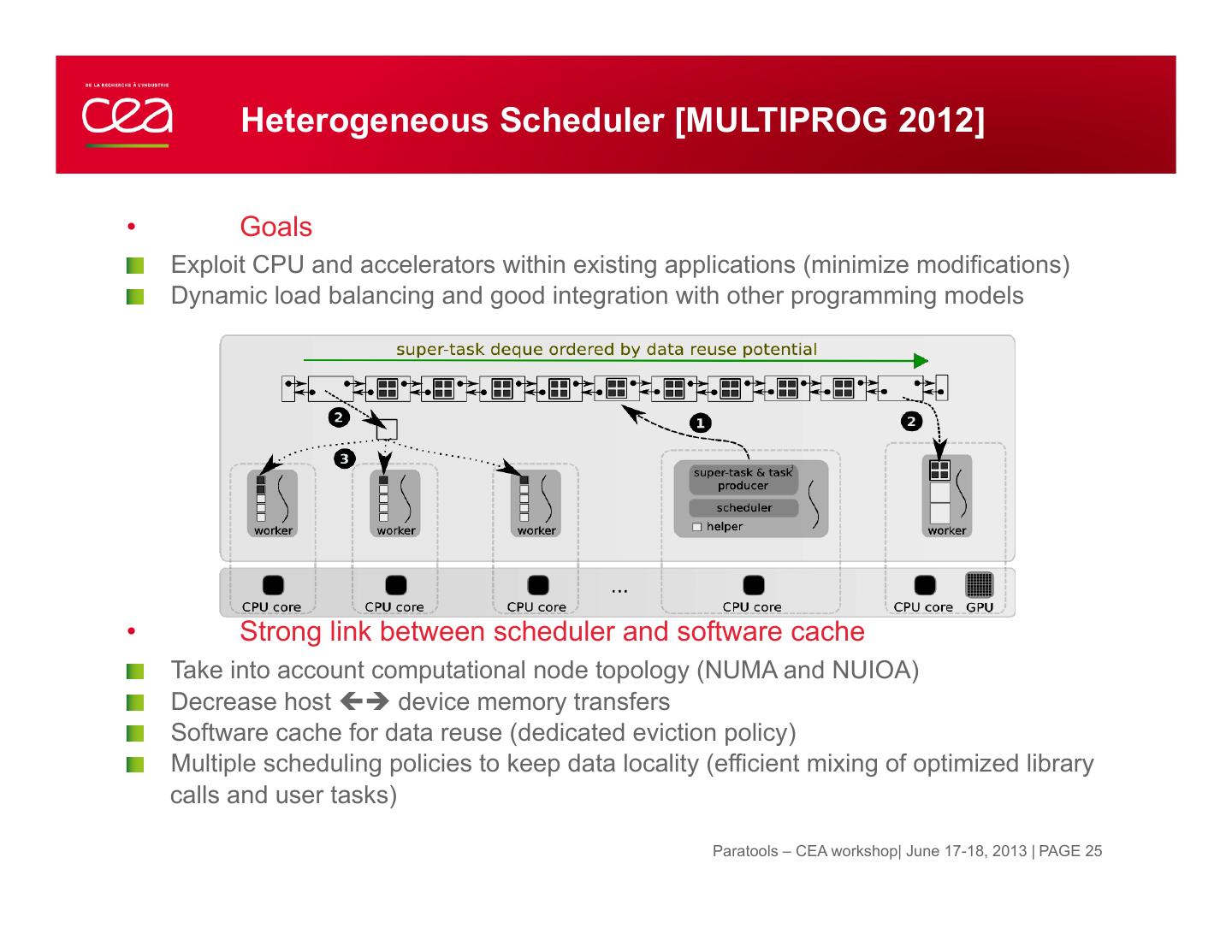
25 . Heterogeneous Scheduler [MULTIPROG 2012] • Goals " Exploit CPU and accelerators within existing applications (minimize modifications) " Dynamic load balancing and good integration with other programming models • Strong link between scheduler and software cache " Take into account computational node topology (NUMA and NUIOA) " Decrease host çè device memory transfers " Software cache for data reuse (dedicated eviction policy) " Multiple scheduling policies to keep data locality (efficient mixing of optimized library calls and user tasks) Paratools – CEA workshop| June 17-18, 2013 | PAGE 25
26 . Heterogeneous Scheduler " PN: deterministic resolution of transport equation (2D w/ MPI) " Focus on most time-consuming function (~90% of sequential execution time). 1 Large matrix-matrix multiply. 2 Small matrix-matrix multiply 3 User-defined simple tasks 4 Large matrix-matrix multiply PAGE 26
27 . Heterogeneous Scheduler PN: CPUs performance PN: Heterogeneous performance (double precision, 1536x1536 mesh, N=15, 36 iterations) (double precision, 1536x1536 mesh, N=15, 36 iterations) 974 84,29 1000 90 900 80 68,28 800 70 58,33 700 60 600 50 Time temps (s) (s) 500 Time temps(s) (s) 32,53 40 400 30 300 154,21 20 200 10 100 Final speed-up CPUs vs. heterogeneous: 0 0 2,65 x Heterogeneous GEMM DGEMM hétérogènes Sequential GEMM + tâchesDGEMM Heterogeneous ans tasks hétérogènes Séquentiel Parallel 8 Parallel (8coeurs cores) Same w/ GEMM + multiple scheduling policies tâches hétérogènes (localité forcée) Theoretical no-transfer Hétérogène performance (sans transfert) CPUs: 8-core Intel Xeon E5620 Tera-100 November Hybrid 9, 2014 Node GPU: 2 GPUs Nvidia Telsa GTX M2090 PAGE 27
28 . Emerging Programming Models • Evaluation of current and emerging models • Task-based model " Cilk • Cilk on the top of MPC • Evaluation of mix MPI + OpenMP + Cilk " OpenMP 3.X tasks • Prototype a task engine • How to mix multiple task models? • PGAS " UPC • Berkeley UPC on the top of MPC • Heterogeneous " OpenCL • Evaluation of language capabilities " OpenACC • Evaluation of an OpenACC implementation (compiler part in GCC with CUDA backend) Paratools – CEA workshop| June 17-18, 2013 | PAGE 28
29 . TOOLS: DEBUG/PROFILING 29 CEA, DAM, DIF, F-91297 Arpajon, France. CEA, DAM, DIF, F-91297 Arpajon, France. 29
3秒后跳转登录页面
去登陆

