























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
14-Parallel Performance Tools
Performance and Debugging Tools
Performance Measurement and Analysis:
– Open|SpeedShop – HPCToolkit – Vampir – Scalasca – Periscope – mpiP – Paraver – PerfExpert – TAU
Modeling and prediction
– Prophesy
– MuMMI
Debugging
– Stat
Autotuning Frameworks
– Active Harmony
展开查看详情
1 . Parallel Performance Tools Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 14 – Parallel Performance Tools
2 . Performance and Debugging Tools Performance Measurement Modeling and prediction and Analysis: – Prophesy – Open|SpeedShop – MuMMI – HPCToolkit Debugging – Vampir – Stat – Scalasca Autotuning Frameworks – Periscope – Active Harmony – mpiP – Paraver – PerfExpert – TAU Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 2
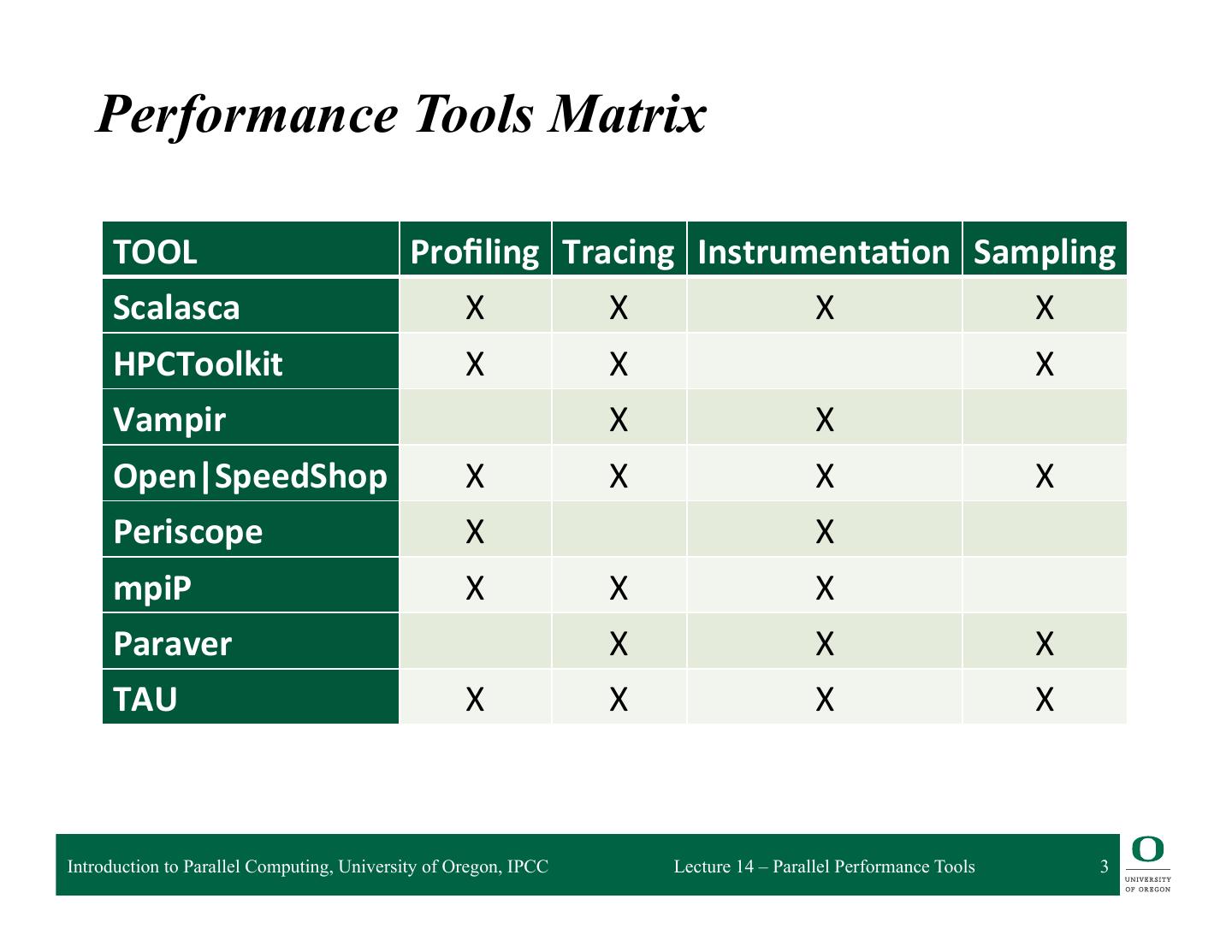
3 . Performance Tools Matrix TOOL Profiling Tracing Instrumenta5on Sampling Scalasca X X X X HPCToolkit X X X Vampir X X Open|SpeedShop X X X X Periscope X X mpiP X X X Paraver X X X TAU X X X X Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 3
4 . Open|SpeedShop Krell Institute (USA) http://www.openspeedshop.org Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 4
5 . Open|SpeedShop Tool Set q Open Source Performance Analysis Tool Framework ❍ Most common performance analysis steps all in one tool ❍ Combines tracing and sampling techniques ❍ Extensible by plugins for data collection and representation ❍ Gathers and displays several types of performance information q Flexible and Easy to use ❍ User access through: GUI, Command Line, Python Scripting, convenience scripts q Scalable Data Collection ❍ Instrumentation of unmodified application binaries ❍ New option for hierarchical online data aggregation q Supports a wide range of systems ❍ Extensively used and tested on a variety of Linux clusters ❍ Cray XT/XE/XK and Blue Gene L/P/Q support Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 5
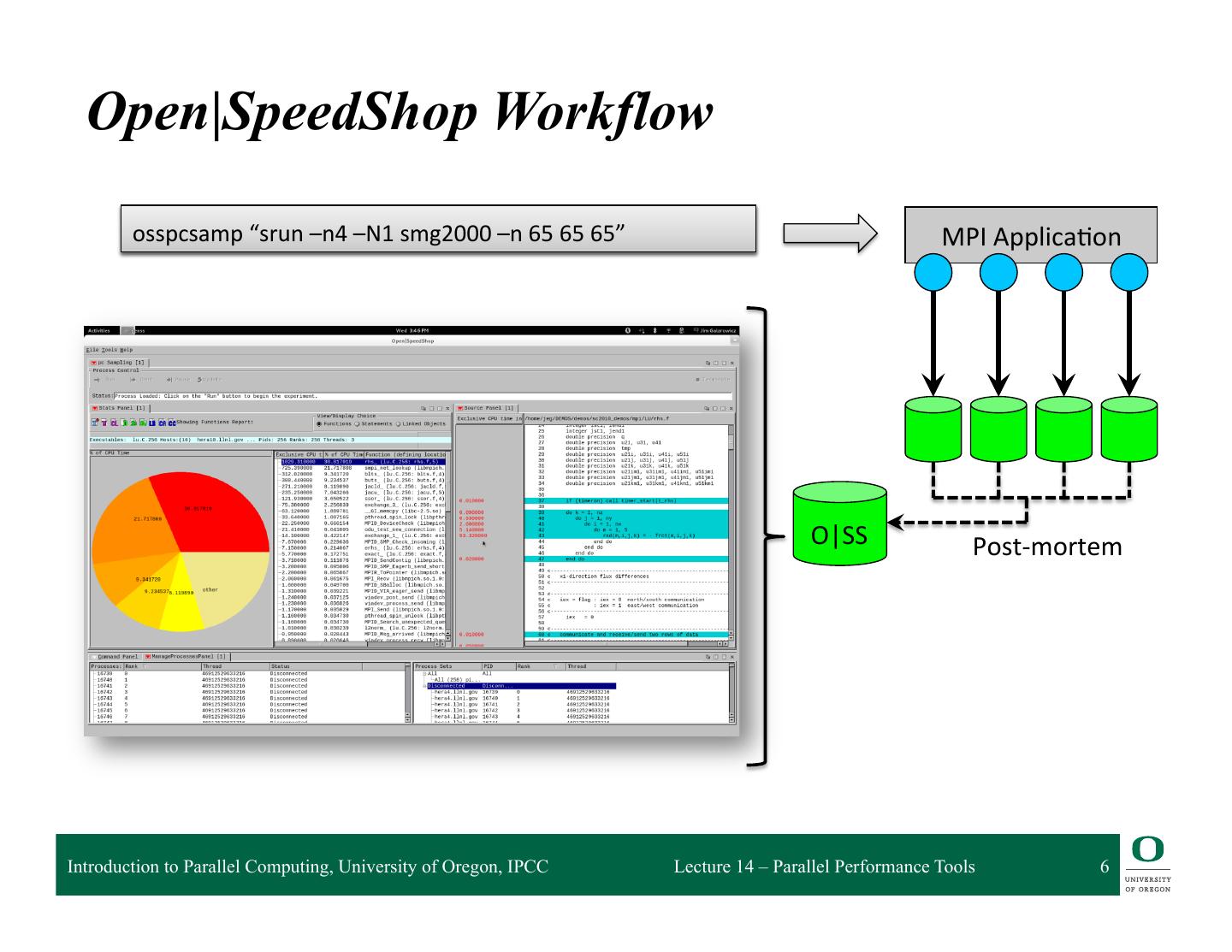
6 . Open|SpeedShop Workflow srun –n4 –N1 osspcsamp “srun smg2000 –n4 –N1 –n s6mg2000 5 65 65 –n 65 65 65” MPI Applica=on O|SS Post-‐mortem Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 6
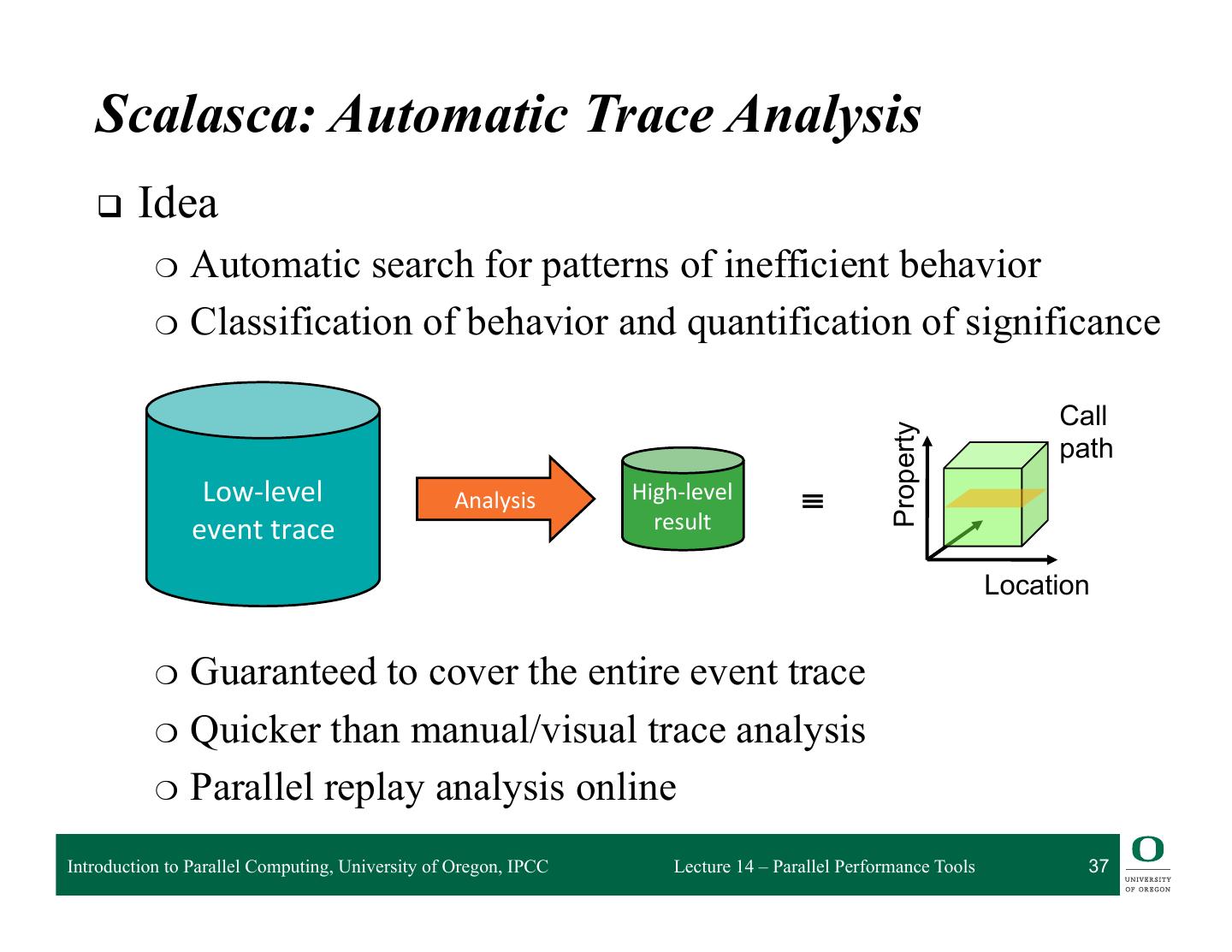
7 . Central Concept: Experiments q Users pick experiments: ❍ What to measure and from which sources? ❍ How to select, view, and analyze the resulting data? q Two main classes: ❍ Statistical Sampling ◆ periodically interrupt execution and record location ◆ useful to get an overview ◆ low and uniform overhead ❍ Event Tracing (DyninstAPI) ◆ gather and store individual application events ◆ provides detailed per event information ◆ can lead to huge data volumes q O|SS can be extended with additional experiments Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 7
8 . Performance Analysis in Parallel q How to deal with concurrency? ❍ Any experiment can be applied to parallel application ◆ Important step: aggregation or selection of data ❍ Special experiments targeting parallelism/synchronization q O|SS supports MPI and threaded codes ❍ Automatically applied to all tasks/threads ❍ Default views aggregate across all tasks/threads ❍ Data from individual tasks/threads available ❍ Thread support (incl. OpenMP) based on POSIX threads q Specific parallel experiments (e.g., MPI) ❍ Wraps MPI calls and reports ◆ MPI routine time ◆ MPI routine parameter information ❍ The mpit experiment also store function arguments and return code for each call Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 8
9 . HPCToolkit John Mellor-Crummey Rice University (USA) http://hpctoolkit.org Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 9
10 . HPCToolkit q Integrated suite of tools for measurement and analysis of program performance q Works with multilingual, fully optimized applications that are statically or dynamically linked q Sampling-based measurement methodology q Serial, multiprocess, multithread applications Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 10
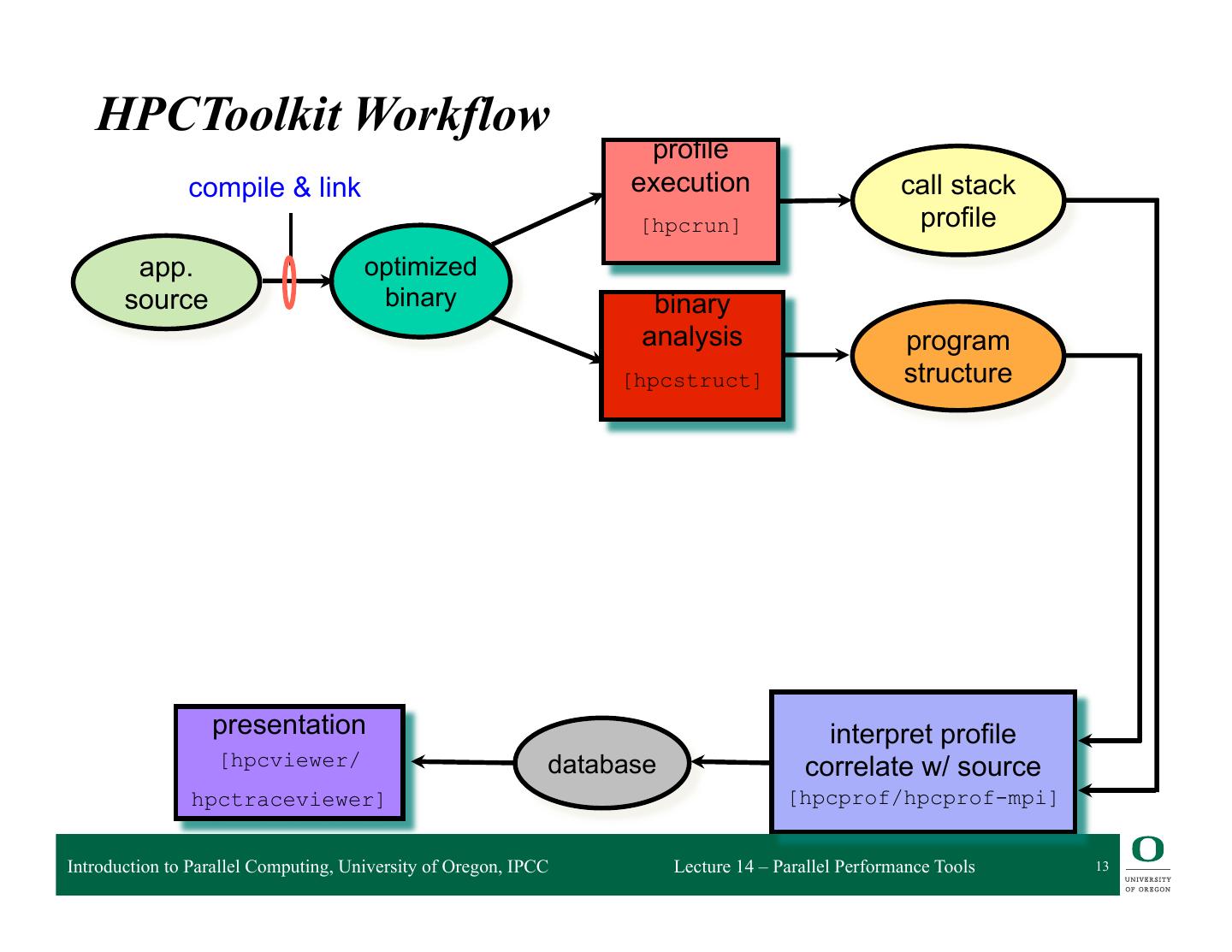
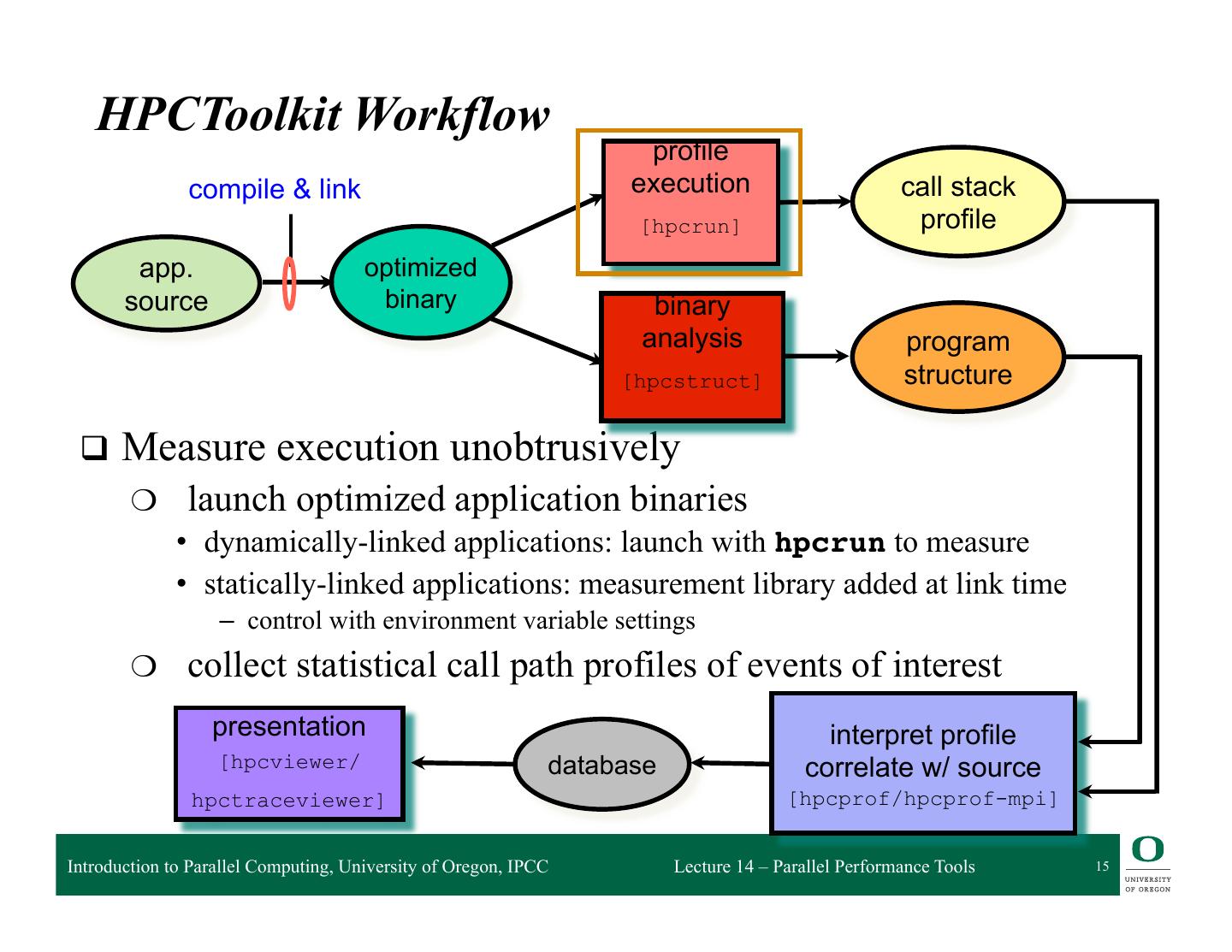
11 . HPCToolkit HPCToolkit Workflow profile compile & link call path execution profile [hpcrun] source optimized code binary binary program analysis structure [hpcstruct] • Performance Analysis through callpath sampling – Designed for low overhead – Hot path analysis – Recovery of program structure from binary presentation interpret profile [hpcviewer/ database correlate w/ source hpctraceviewer] [hpcprof/hpcprof-mpi] 8 Image by John Mellor-Crummey Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 11
12 . HPCToolkit DESIGN PRINCIPLES q Employ binary-level measurement and analysis ❍ observe fully optimized, dynamically linked executions ❍ support multi-lingual codes with external binary-only libraries q Use sampling-based measurement (avoid instrumentation) ❍ controllable overhead ❍ minimize systematic error and avoid blind spots ❍ enable data collection for large-scale parallelism q Collect and correlate multiple derived performance metrics ❍ diagnosis typically requires more than one species of metric q Associate metrics with both static and dynamic context ❍ loop nests, procedures, inlined code, calling context q Support top-down performance analysis ❍ natural approach that minimizes burden on developers Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 12
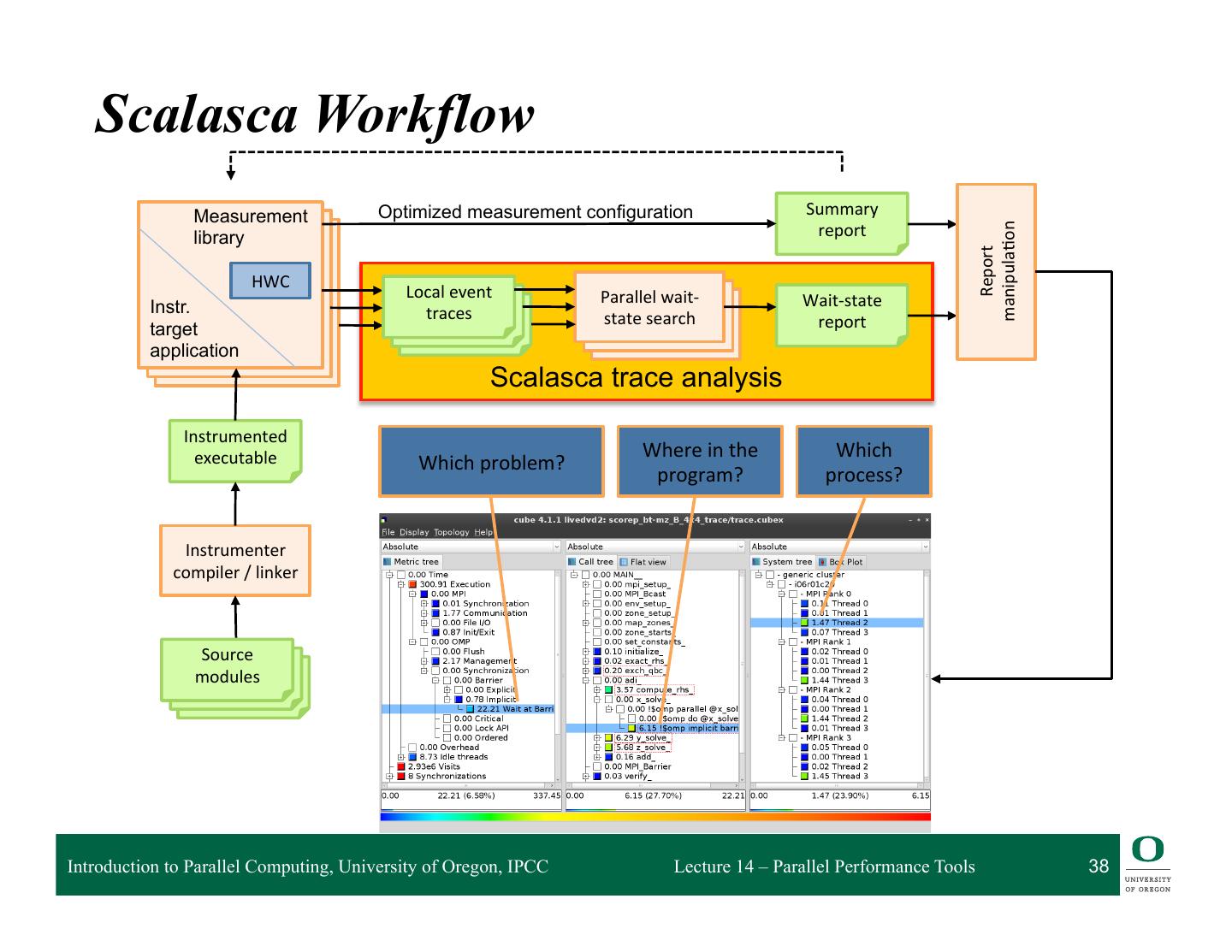
13 . HPCToolkit Workflow profile compile & link execution call stack [hpcrun] profile app. optimized source binary binary analysis program [hpcstruct] structure presentation interpret profile [hpcviewer/ database correlate w/ source hpctraceviewer] [hpcprof/hpcprof-mpi] Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 13
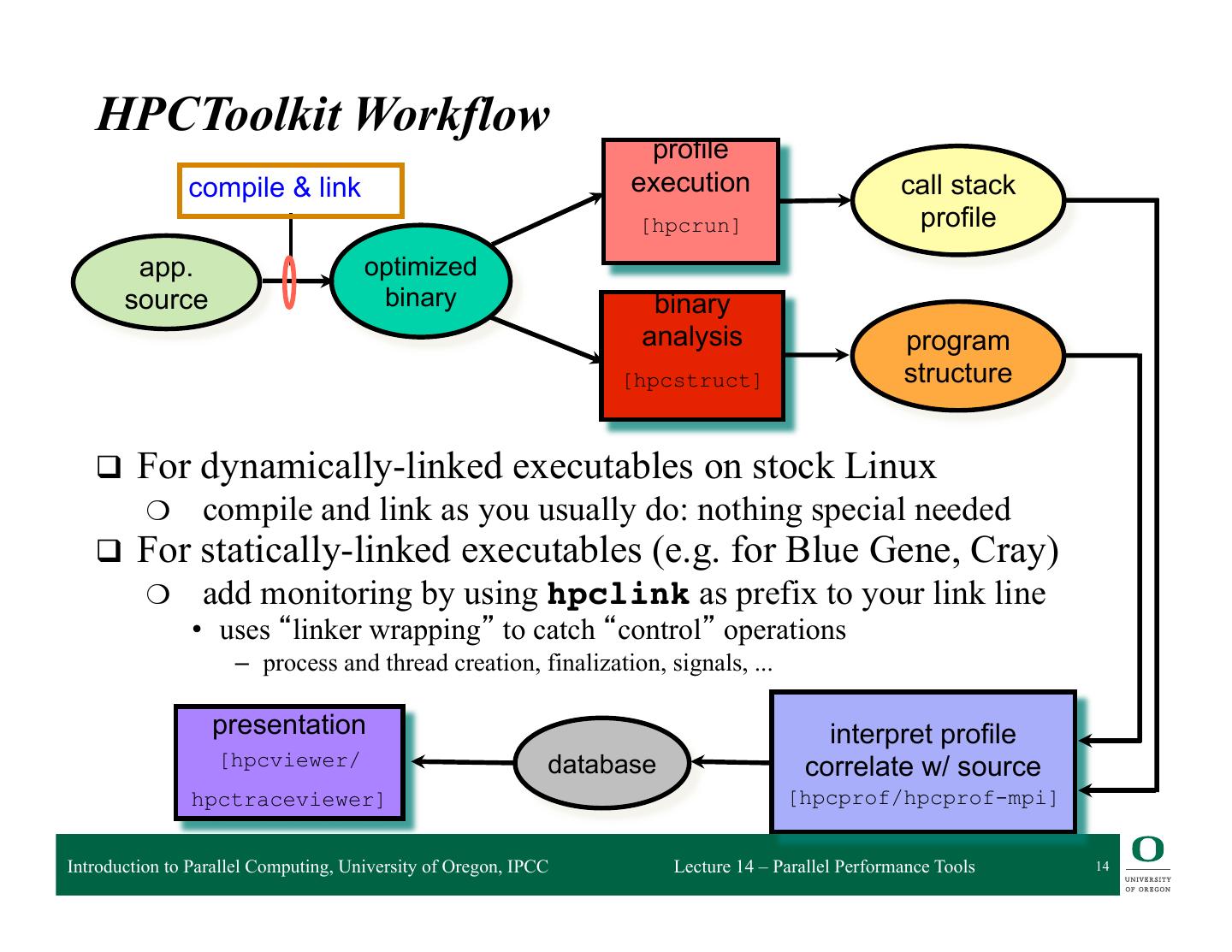
14 . HPCToolkit Workflow profile compile & link execution call stack [hpcrun] profile app. optimized source binary binary analysis program [hpcstruct] structure q For dynamically-linked executables on stock Linux ❍ compile and link as you usually do: nothing special needed q For statically-linked executables (e.g. for Blue Gene, Cray) ❍ add monitoring by using hpclink as prefix to your link line • uses “linker wrapping” to catch “control” operations – process and thread creation, finalization, signals, ... presentation interpret profile [hpcviewer/ database correlate w/ source hpctraceviewer] [hpcprof/hpcprof-mpi] Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 14
15 . HPCToolkit Workflow profile compile & link execution call stack [hpcrun] profile app. optimized source binary binary analysis program [hpcstruct] structure q Measure execution unobtrusively ❍ launch optimized application binaries • dynamically-linked applications: launch with hpcrun to measure • statically-linked applications: measurement library added at link time – control with environment variable settings ❍ collect statistical call path profiles of events of interest presentation interpret profile [hpcviewer/ database correlate w/ source hpctraceviewer] [hpcprof/hpcprof-mpi] Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 15
16 . HPCToolkit Workflow profile compile & link execution call stack [hpcrun] profile app. optimized source binary binary analysis program [hpcstruct] structure q Analyze binary with hpcstruct: recover program structure ❍ analyze machine code, line map, debugging information ❍ extract loop nesting & identify inlined procedures ❍ map transformed loops and procedures to source presentation interpret profile [hpcviewer/ database correlate w/ source hpctraceviewer] [hpcprof/hpcprof-mpi] Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 16
17 . HPCToolkit Workflow profile compile & link execution call stack [hpcrun] profile app. optimized source binary binary analysis program [hpcstruct] structure q Combine multiple profiles ❍ multiple threads; multiple processes; multiple executions q Correlate metrics to static & dynamic program structure presentation interpret profile [hpcviewer/ database correlate w/ source hpctraceviewer] [hpcprof/hpcprof-mpi] Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 17
18 . HPCToolkit Workflow profile compile & link execution call stack [hpcrun] profile app. optimized source binary binary analysis program [hpcstruct] structure q Presentation ❍ explore performance data from multiple perspectives • rank order by metrics to focus on what’s important • compute derived metrics to help gain insight – e.g. scalability losses, waste, CPI, bandwidth ❍ graph thread-level metrics for contexts ❍ explore evolution of behavior over time presentation interpret profile [hpcviewer/ database correlate w/ source hpctraceviewer] [hpcprof/hpcprof-mpi] Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 18
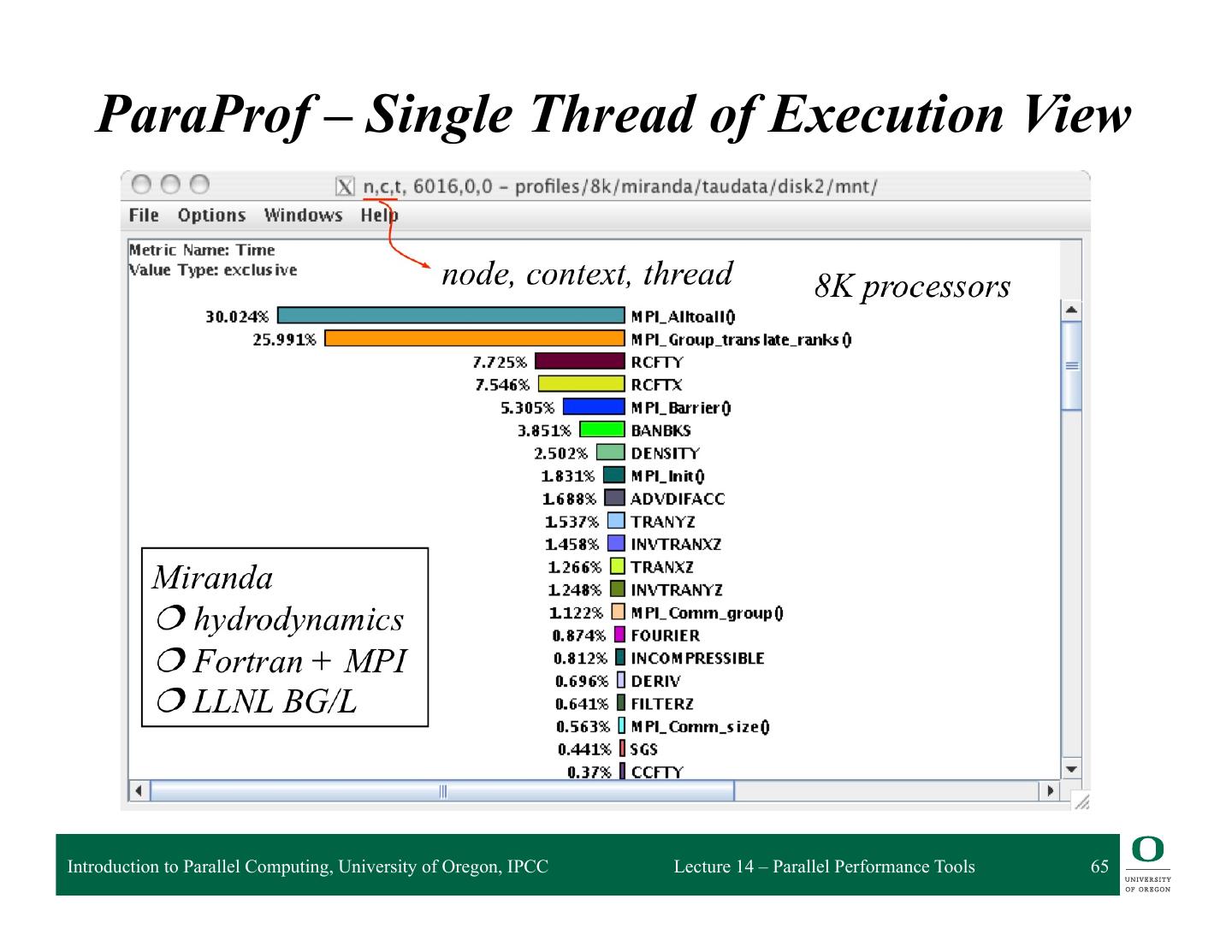
19 . Analyzing resultsResults Analyzing with hpcviewer with hpcviewer associated source code costs for • inlined procedures source pane • loops • function calls in full context view control metric display navigation pane metric pane Callpath to hotspot 24 Image by John Mellor-Crummey Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 19
20 . Vampir Wolfgang Nagel ZIH, Technische Universität Dresden (Germany) http://www.vampir.eu Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 20
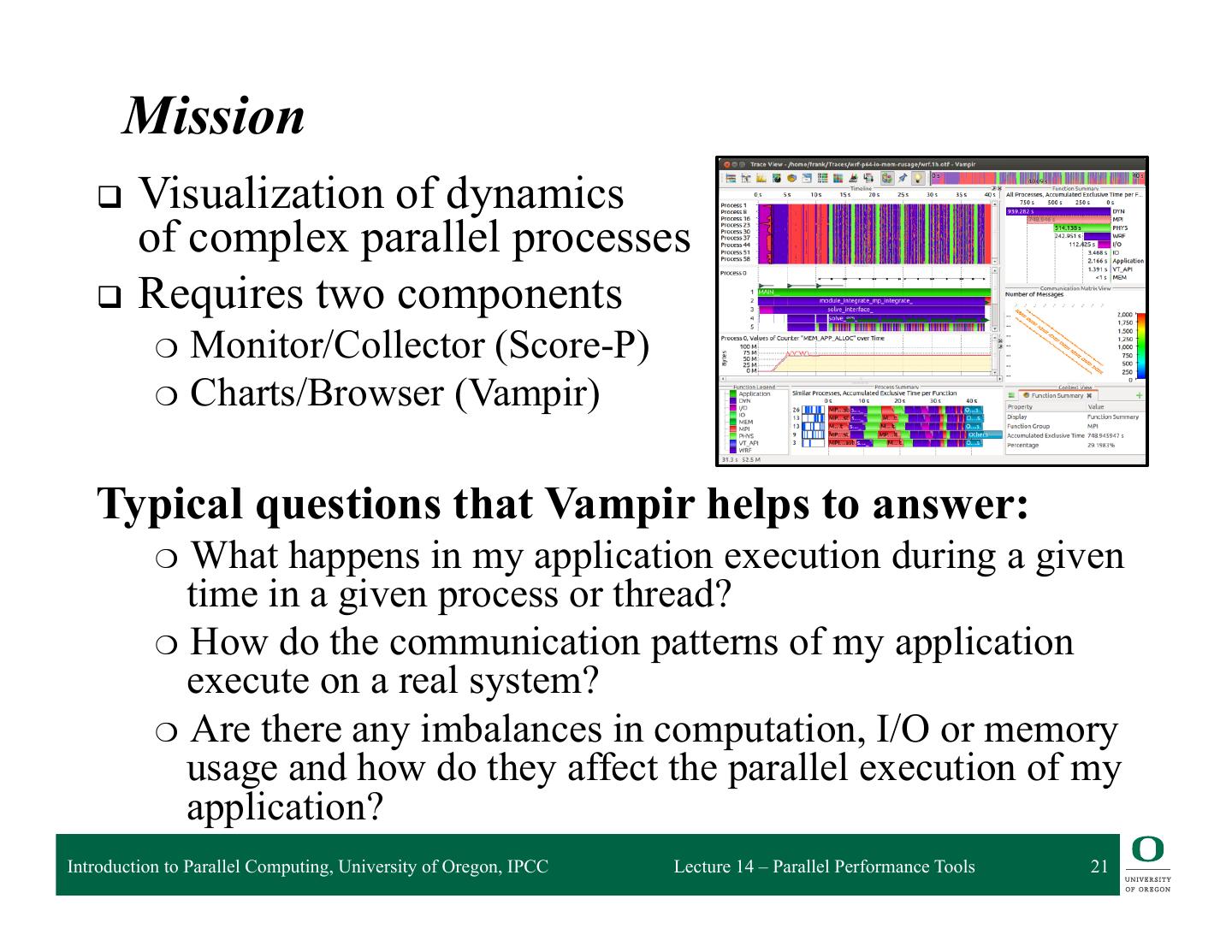
21 . Mission q Visualization of dynamics of complex parallel processes q Requires two components ❍ Monitor/Collector (Score-P) ❍ Charts/Browser (Vampir) Typical questions that Vampir helps to answer: ❍ What happens in my application execution during a given time in a given process or thread? ❍ How do the communication patterns of my application execute on a real system? ❍ Are there any imbalances in computation, I/O or memory usage and how do they affect the parallel execution of my application? Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 21
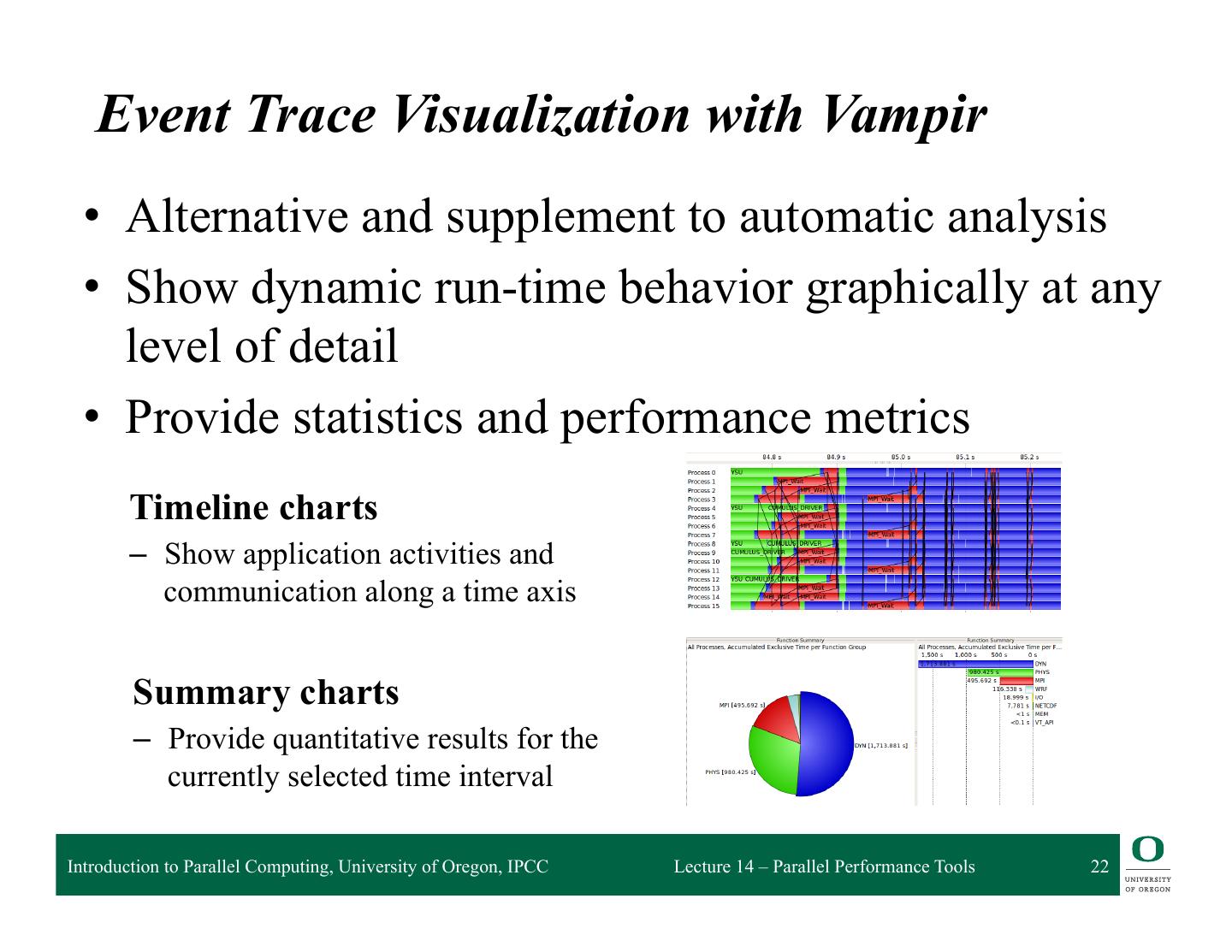
22 . Event Trace Visualization with Vampir • Alternative and supplement to automatic analysis • Show dynamic run-time behavior graphically at any level of detail • Provide statistics and performance metrics Timeline charts – Show application activities and communication along a time axis Summary charts – Provide quantitative results for the currently selected time interval Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 22
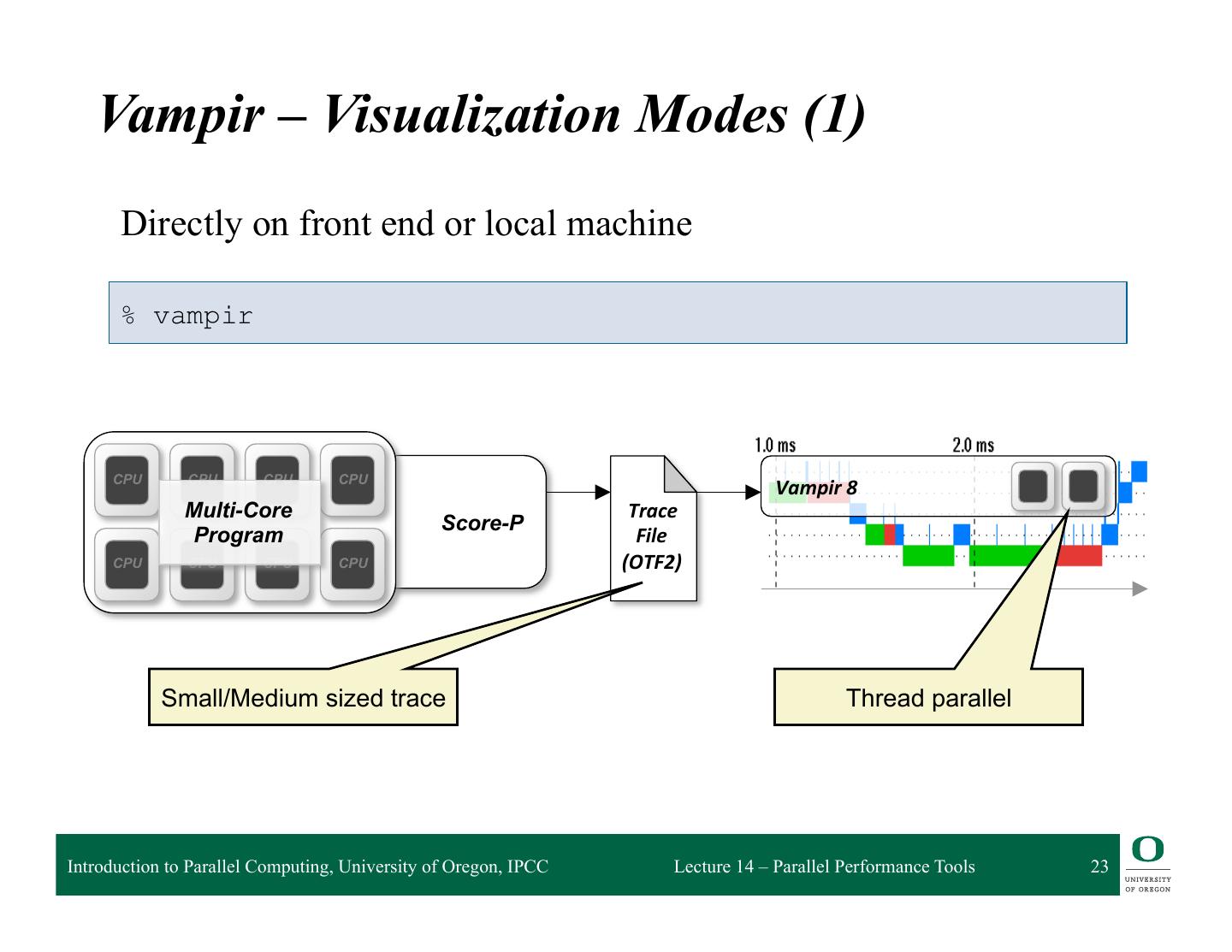
23 . Vampir – Visualization Modes (1) Directly on front end or local machine % vampir CPU CPU CPU CPU Vampir 8 Multi-Core Trace Score-P Program File CPU CPU CPU CPU (OTF2) Small/Medium sized trace Thread parallel Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 23
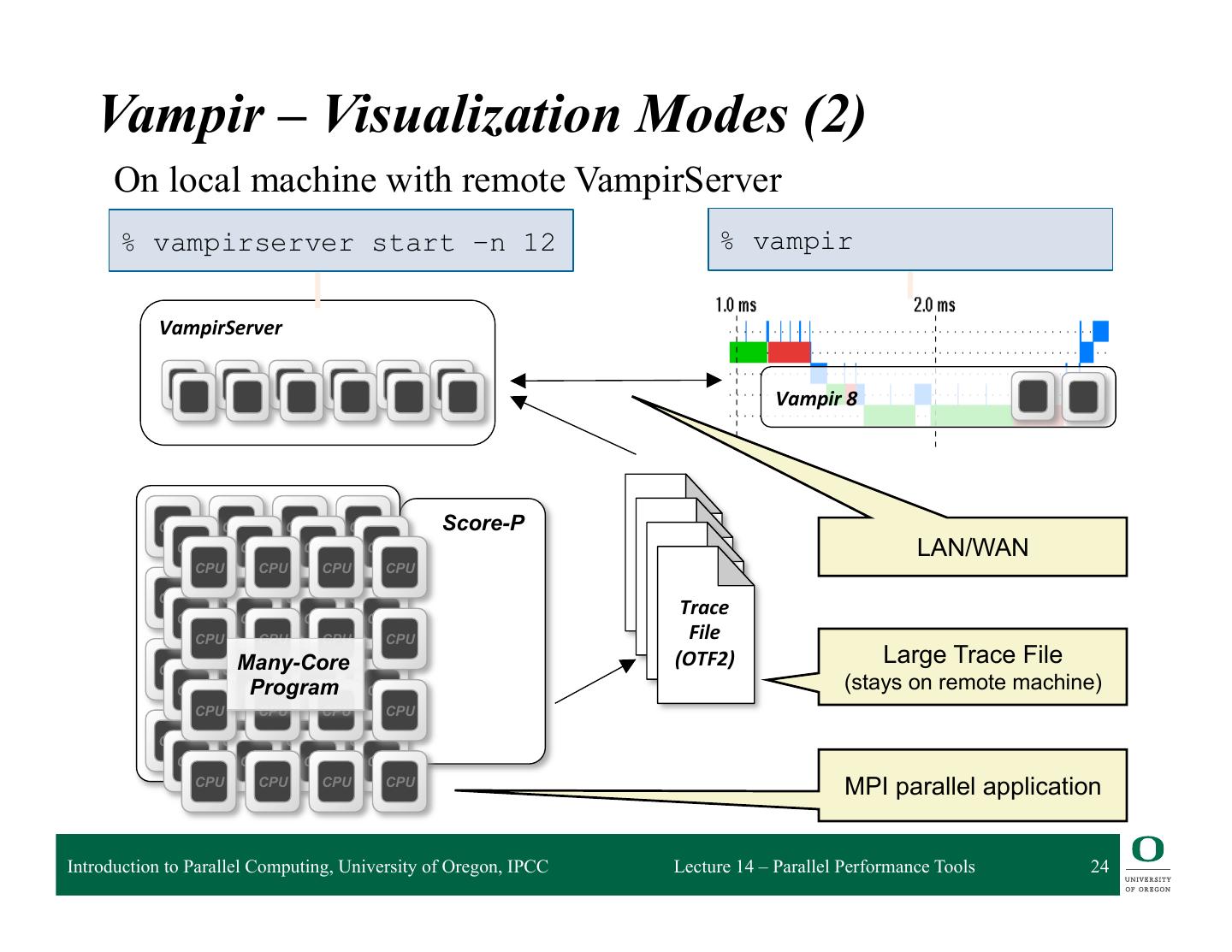
24 . Vampir – Visualization Modes (2) On local machine with remote VampirServer % vampirserver start –n 12 % vampir VampirServer Vampir 8 CPU CPU CPU CPU Score-P CPU CPU CPU CPU LAN/WAN CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU Trace CPU CPU CPU CPU File CPU Many-Core CPU CPU CPU (OTF2) Large Trace File CPU Program CPU CPU CPU (stays on remote machine) CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU MPI parallel application Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 24
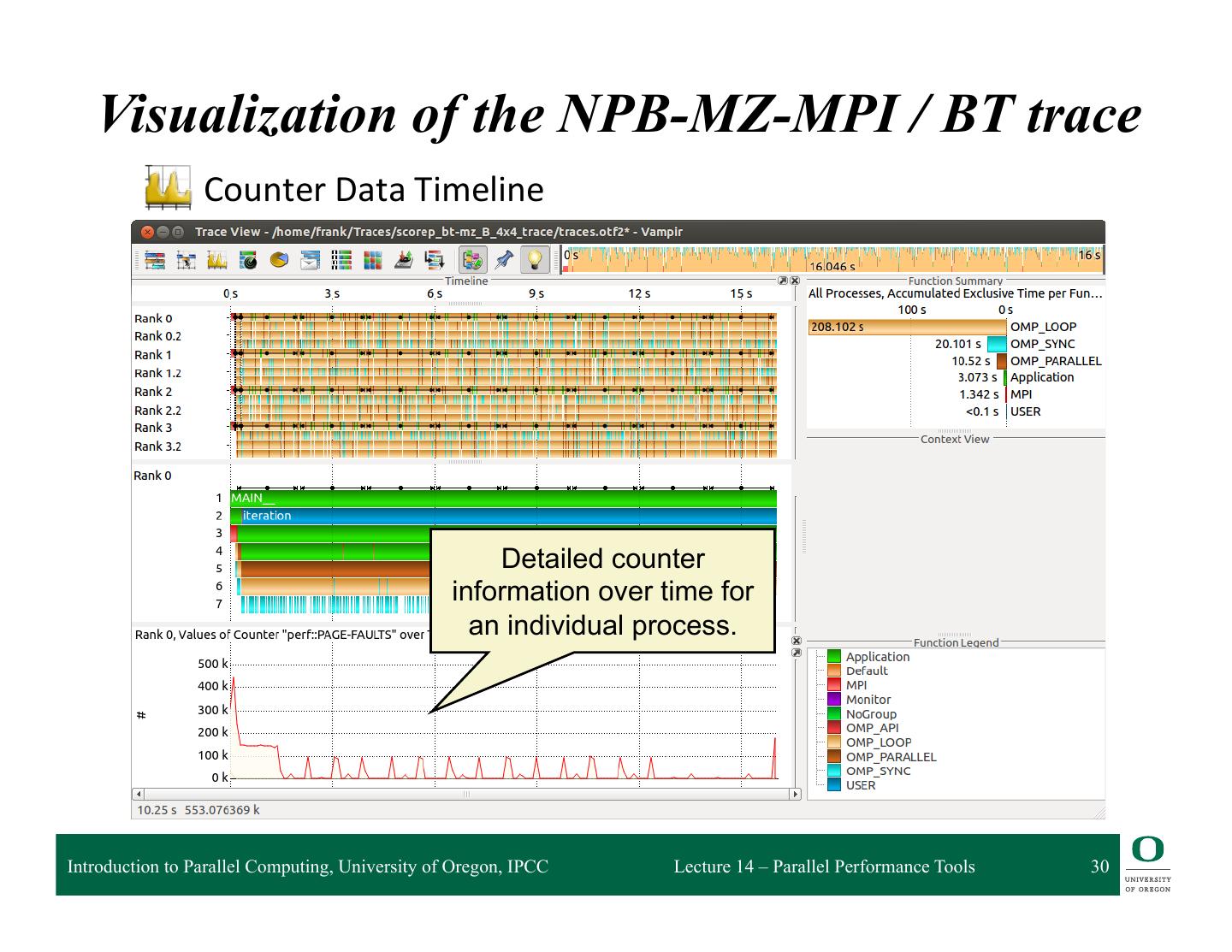
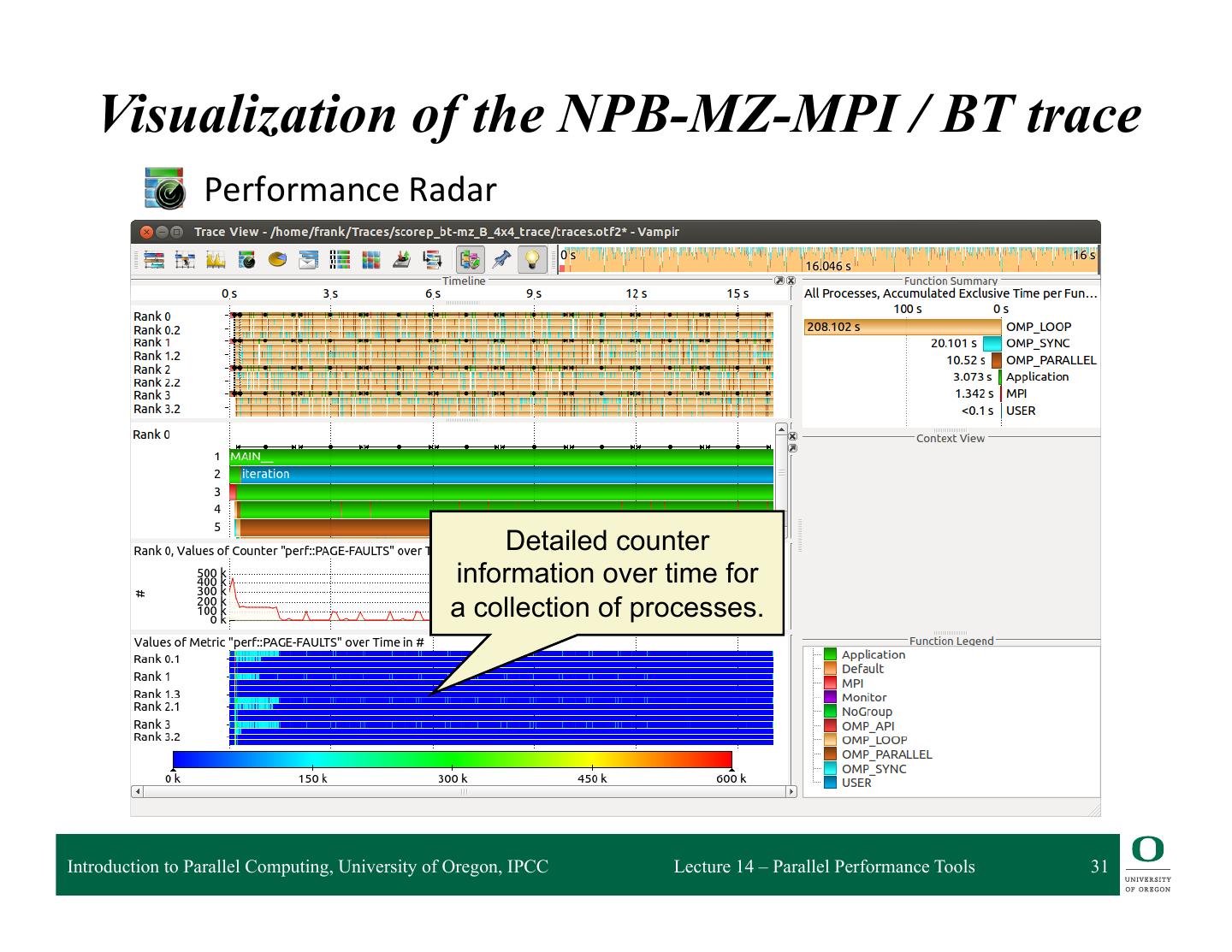
25 . Main Displays of Vampir q Timeline Charts: ❍ Master Timeline ❍ Process Timeline ❍ Counter Data Timeline ❍ Performance Radar q Summary Charts: ❍ Function Summary ❍ Message Summary ❍ Process Summary ❍ Communication Matrix View Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 25
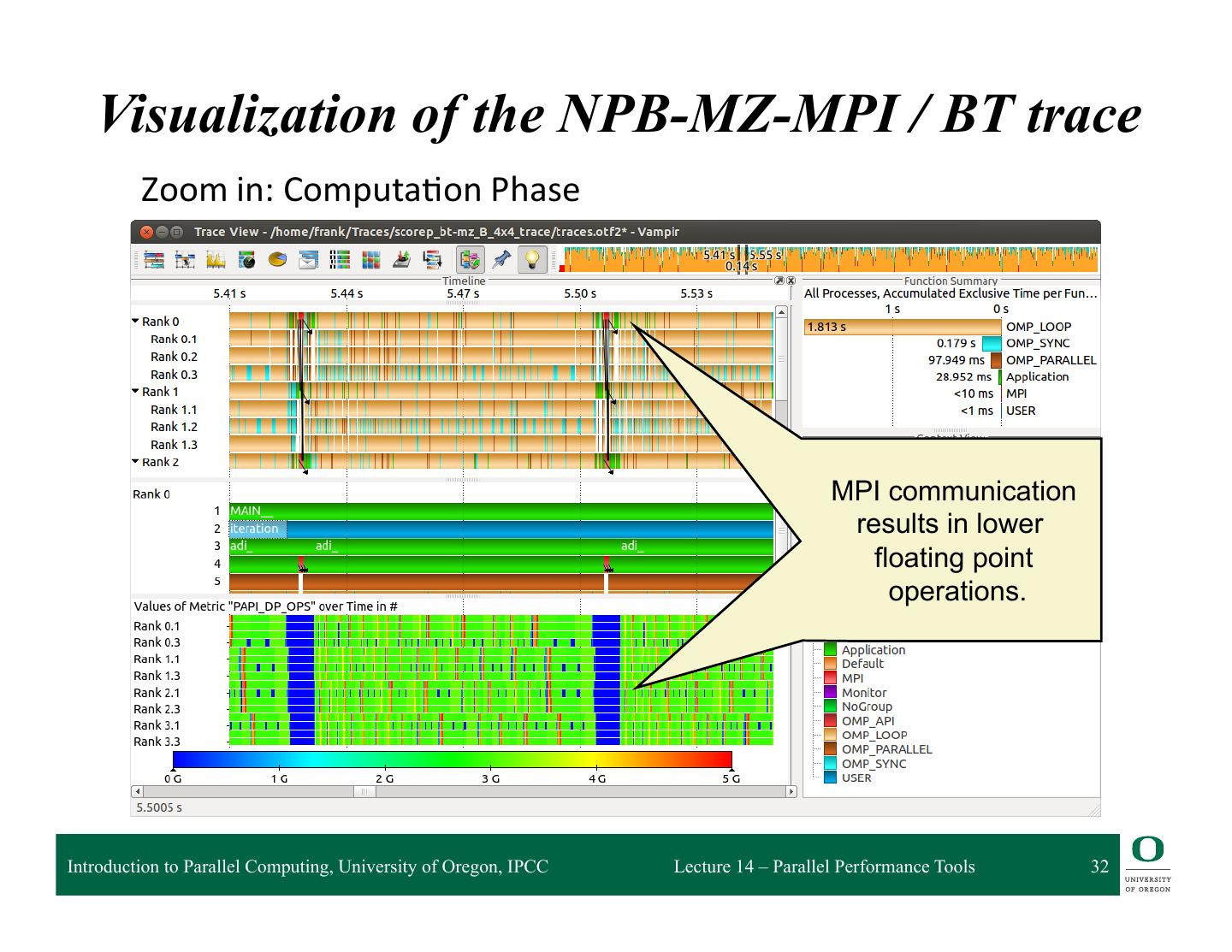
26 . Visualization of the NPB-MZ-MPI / BT trace % vampir scorep_bt-mz_B_4x4_trace Navigation Toolbar Function Summary Function Legend Master Timeline Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 26
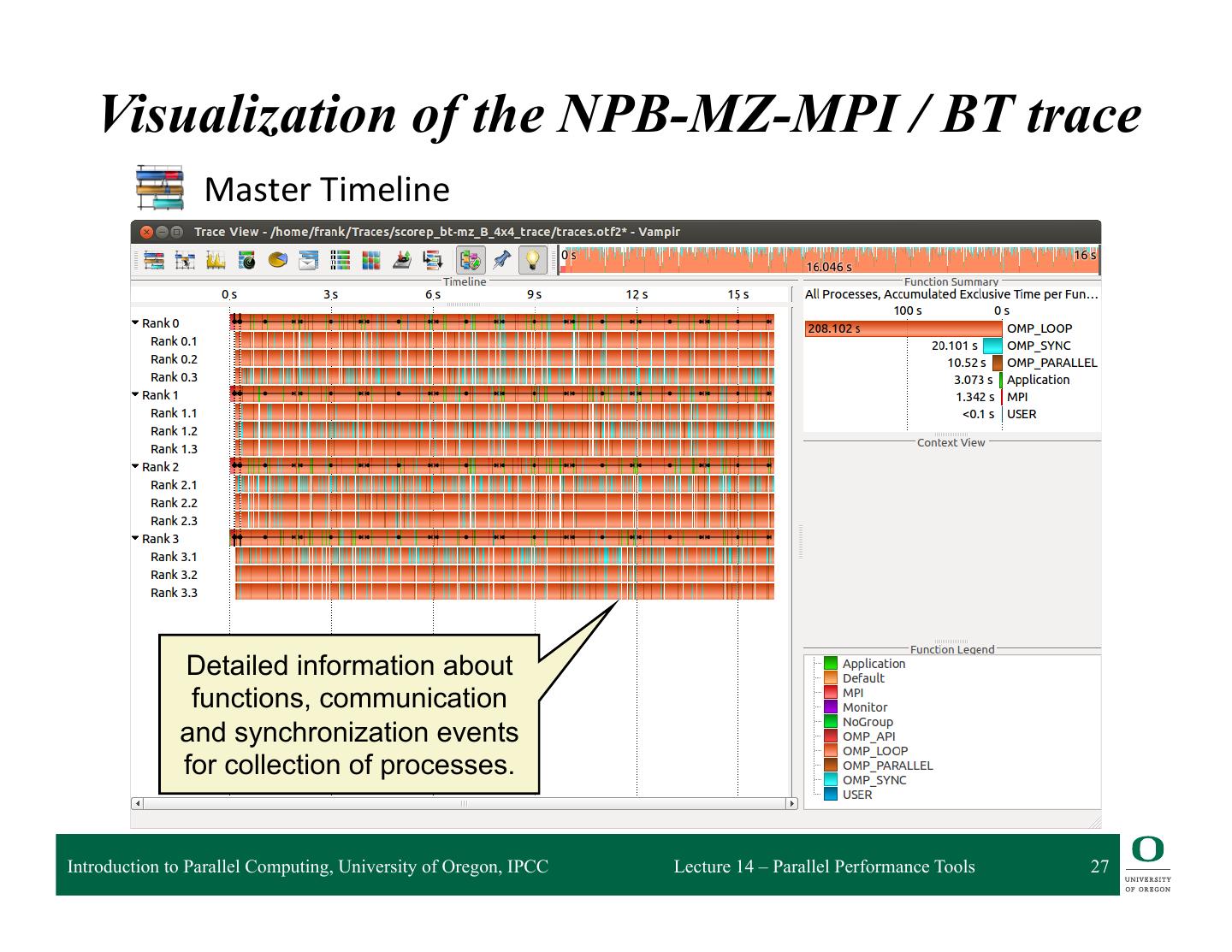
27 . Visualization of the NPB-MZ-MPI / BT trace Master Timeline Detailed information about functions, communication and synchronization events for collection of processes. Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 27
28 . Visualization of the NPB-MZ-MPI / BT trace Process Timeline Detailed information about different levels of function calls in a stacked bar chart for an individual process. Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 28
29 . Visualization of the NPB-MZ-MPI / BT trace Typical program phases Initialisation Phase Computation Phase Introduction to Parallel Computing, University of Oregon, IPCC Lecture 14 – Parallel Performance Tools 29
3秒后跳转登录页面
去登陆

