


























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
11-Parallelism on Supercomputers and the Message Passing Interface (MPI)
Outline
Quick review of hardware architectures
Running on supercomputers
Message Passing
MPI
展开查看详情
1 .Parallelism on Supercomputers and the Message Passing Interface (MPI) Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 11 –Parallelism on Supercomputers
2 . Outline q Quickreview of hardware architectures q Running on supercomputers q Message Passing q MPI Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 2
3 . Parallel Architecture Types • Uniprocessor • Shared Memory – Scalar processor Multiprocessor (SMP) processor – Shared memory address space – Bus-based memory system memory processor … processor – Vector processor bus processor vector memory memory – Interconnection network – Single Instruction Multiple processor … processor Data (SIMD) network processor … … memory memory Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 3
4 . Parallel Architecture Types (2) • Distributed Memory • Cluster of SMPs Multiprocessor – Shared memory addressing – Message passing within SMP node between nodes – Message passing between SMP memory memory nodes … M M processor processor … P … P P … P interconnec2on network network interface interconnec2on network processor processor … P … P P … P memory memory … M M – Massively Parallel Processor (MPP) – Can also be regarded as MPP if • Many, many processors processor number is large Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 4
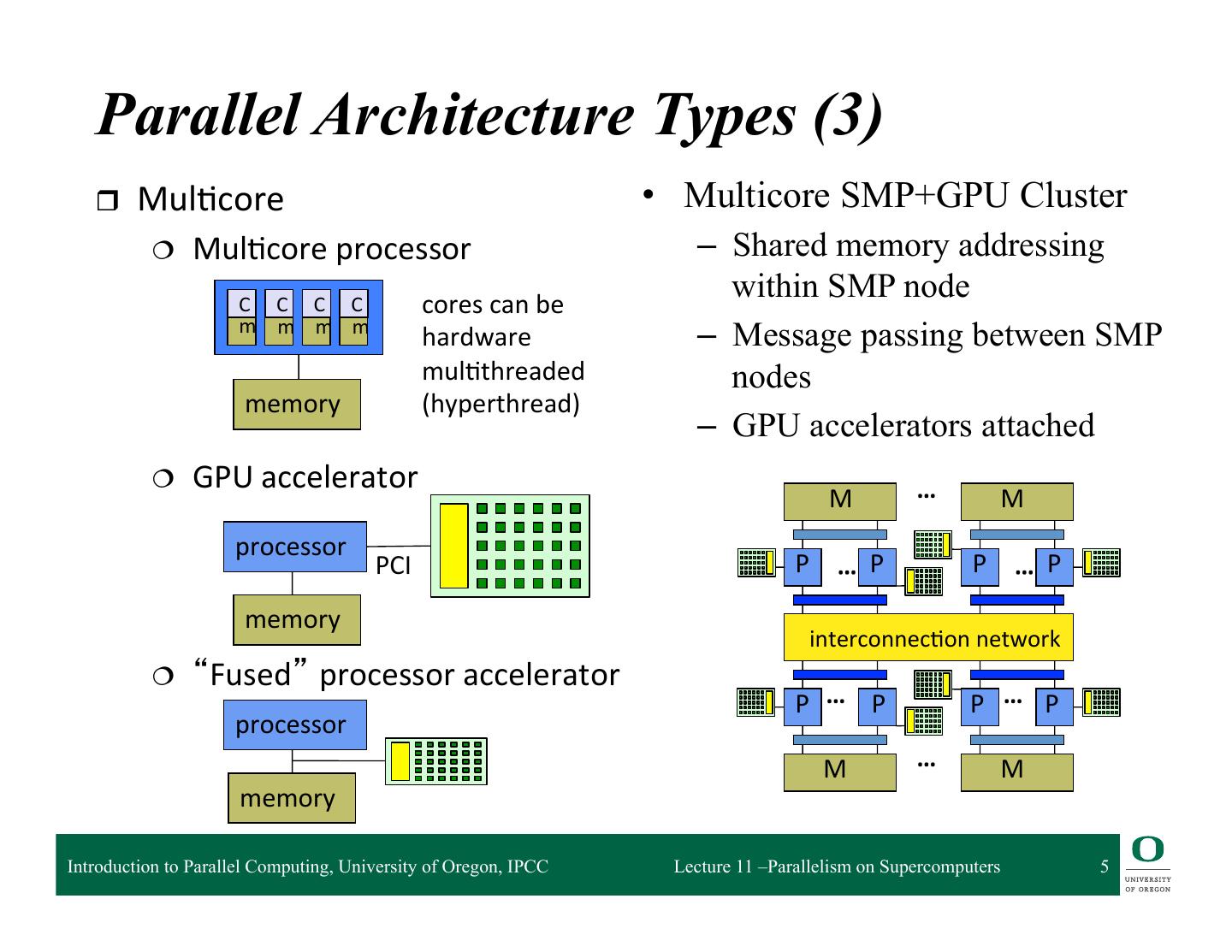
5 . Parallel Architecture Types (3) r Mul2core • Multicore SMP+GPU Cluster ¦ Mul2core processor – Shared memory addressing C C C C cores can be within SMP node m m m m hardware – Message passing between SMP mul2threaded nodes memory (hyperthread) – GPU accelerators attached ¦ GPU accelerator … M M processor PCI P … P P … P memory interconnec2on network ¦ “Fused” processor accelerator P … P P … P processor M … M memory Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 5
6 . How do you get parallelism in the hardware? q Instruction-Level Parallelism (ILP) q Data parallelism ❍ Increase amount of data to be operated on at same time q Processor parallelism ❍ Increase number of processors q Memory system parallelism ❍ Increase number of memory units ❍ Increase bandwidth to memory q Communication parallelism ❍ Increase amount of interconnection between elements ❍ Increase communication bandwidth Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 6
7 . Distributed Memory Parallelism q Each processing elements cannot access all data natively q The scale can go up considerably q Penalty for coordinating with other processing elements is now significantly higher ❍ Approaches change accordingly Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 7
8 . Scientific Simulation and Supercomputers q Why simulation? Image credit: Prabhat, LBNL ❍ Simulations are sometimes more cost effective than experiments q Why extreme scale? ❍ More compute cycles, more Climate Change memory, etc, lead for faster and/or more accurate simulations Nuclear Reactors Astrophysics Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 8
9 . How big are supercomputers? q Measured in “FLOPs” FLoating point Operations Per second ❍ 1 GigaFLOP = 1 billion FLOPs ❍ 1 TeraFLOP = 1000 GigaFLOPs ❍ 1 PetaFLOP = 1000 TeraFLOPs ◆ where we are today ❍ 1 ExaFLOP = 1000 PetaFLOPs ◆ potentially arriving in 2018 Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 9
10 . Distributed Memory Multiprocessors q Each processor has a local memory ❍ Physically separated memory address space q Processors must communicate to access non-local data ❍ Message communication (message passing) ◆ Message passing architecture ❍ Processor interconnection network q Parallel applications must be partitioned across ❍ Processors: execution units ❍ Memory: data partitioning q Scalable architecture ❍ Small incremental cost to add hardware (cost of node) Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 10
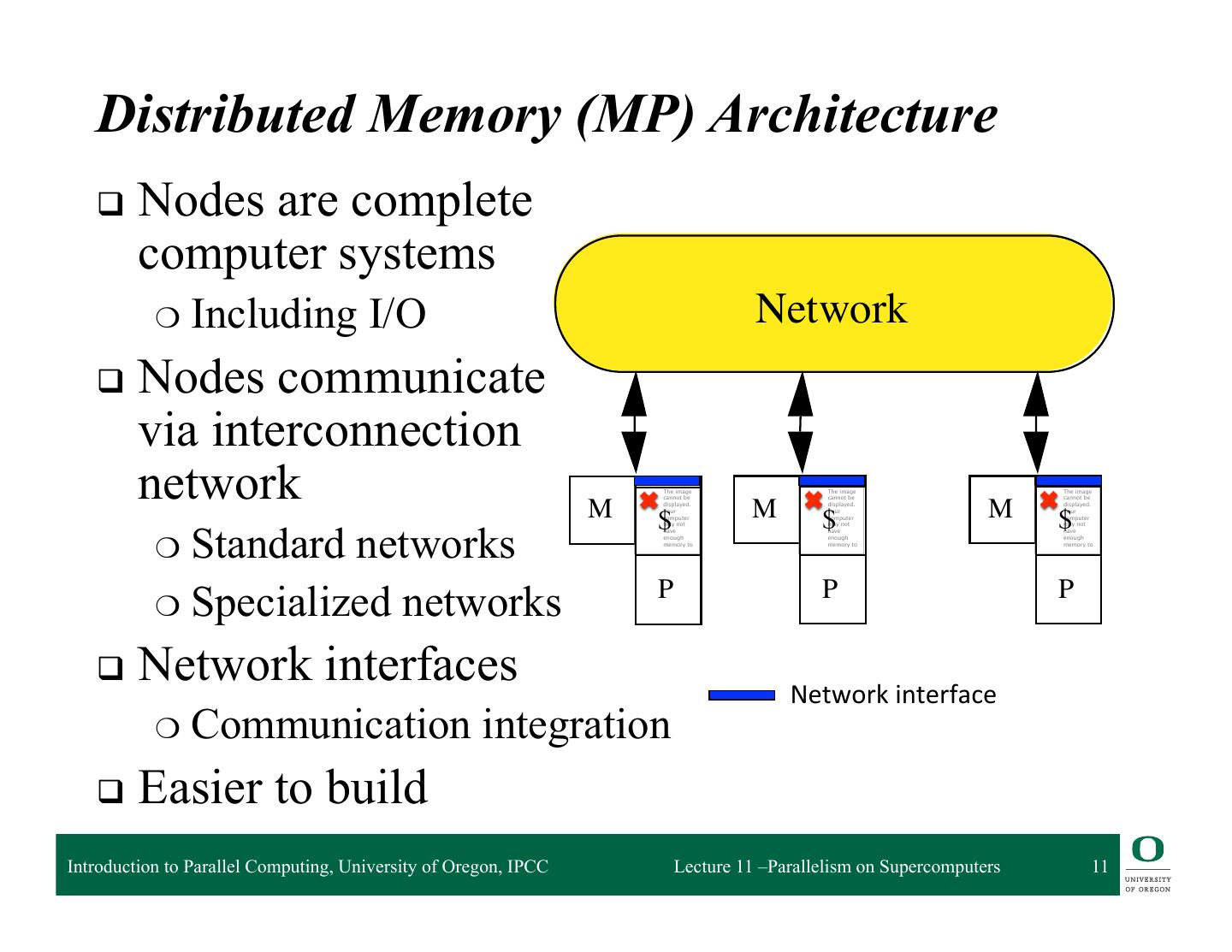
11 . Distributed Memory (MP) Architecture q Nodes are complete computer systems ❍ Including I/O Network q Nodes communicate via interconnection network M The image cannot be displayed. Your M The image cannot be displayed. Your M The image cannot be displayed. Your $ computer $computer $ computer ❍ Standard networks may not may not may not have have have enough enough enough memory to memory to memory to P P ❍ Specialized networks P q Network interfaces Network interface ❍ Communication integration q Easier to build Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 11
12 . Performance Metrics: Latency and Bandwidth q Bandwidth ❍ Need high bandwidth in communication ❍ Match limits in network, memory, and processor ❍ Network interface speed vs. network bisection bandwidth q Latency ❍ Performance affected since processor may have to wait ❍ Harder to overlap communication and computation ❍ Overhead to communicate is a problem in many machines q Latency hiding ❍ Increases programming system burden ❍ Examples: communication/computation overlaps, prefetch Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 12
13 . Advantages of Distributed Memory Architectures q The hardware can be simpler (especially versus NUMA) and is more scalable q Communication is explicit and simpler to understand q Explicit communication focuses attention on costly aspect of parallel computation q Synchronization is naturally associated with sending messages, reducing the possibility for errors introduced by incorrect synchronization q Easier to use sender-initiated communication, which may have some advantages in performance Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 13
14 . Outline q Quickreview of hardware architectures q Running on supercomputers ❍ The purpose of these slides is to give context, not to teach you how to run on supercomputers q Message Passing q MPI Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 14
15 . Running on Supercomputers q Sometimes one job runs on the entire machine, using all processors ❍ These are called “hero runs”… q Sometimes many smaller jobs are running on the machine q For most supercomputer, the processors are being used nearly continuously ❍ The processors are the “scarce resource” and jobs to run on them are “plentiful” Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 15
16 . Running on Supercomputers q You plan a “job” you want to run ❍ The job consists of a parallel binary program and an “input deck” (something that specifies input data for the program) q You submit that job to a “queue” q The job waits in the queue until it is scheduled q The scheduler allocates resources when (i) resources are available and (ii) the job is deemed “high priority” Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 16
17 . Running on Supercomputers q The scheduler runs scripts that initialize the environment ❍ Typically done with environment variables q At the end of initialization, it is possible to infer: ❍ What the desired job configuration is (i.e., how many tasks per node) ❍ What other nodes are involved ❍ How your node’s tasks relates to the overall program q The MPI library knows how to interpret all of this information and hides the details from you Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 17
18 . UO’s supercomputer: ACISS Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 18
19 . Job submission on ACISS Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 19
20 . Job submission on ACISS Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 20
21 . Outline q Quickreview of hardware architectures q Running on supercomputers q Message Passing q MPI Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 21
22 . Acknowledgements and Resources q Portions of the lectures slides were adopted from: ❍ Argonne National Laboratory, MPI tutorials. ❍ Lawrence Livermore National Laboratory, MPI tutorials ❍ See online tutorial links in course webpage q W. Gropp, E. Lusk, and A. Skjellum, Using MPI: Portable Parallel Programming with the Message Passing Interface, MIT Press, ISBN 0-262-57133-1, 1999. q W. Gropp, E. Lusk, and R. Thakur, Using MPI-2: Advanced Features of the Message Passing Interface, MIT Press, ISBN 0-262-57132-3, 1999. Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 22
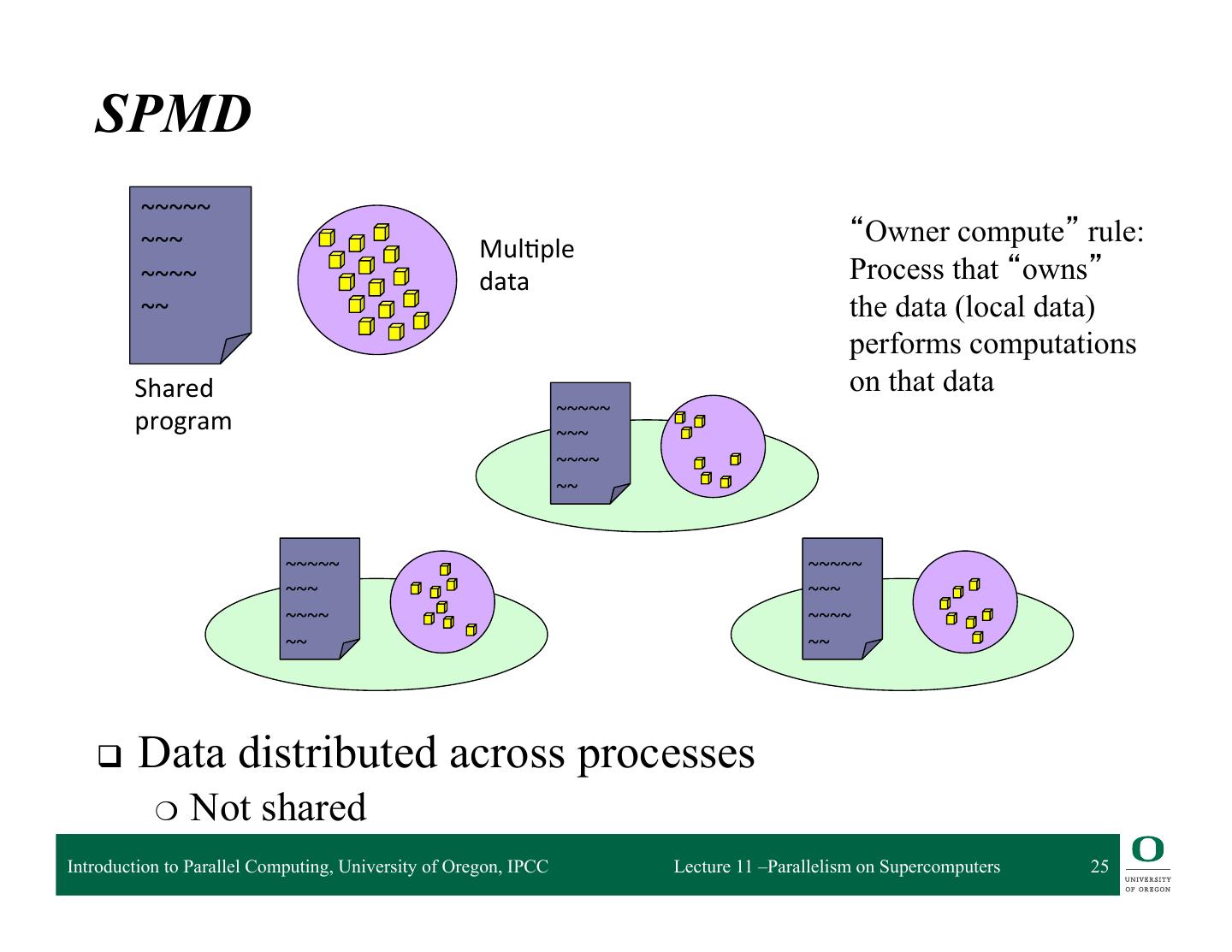
23 . Types of Parallel Computing Models q Data parallel ❍ Simultaneous execution on multiple data items ❍ Example: Single Instruction, Multiple Data (SIMD) q Task parallel ❍ Different instructions on different data (MIMD) q SPMD (Single Program, Multiple Data) ❍ Combination of data parallel and task parallel ❍ Not synchronized at individual operation level q Message passing is for MIMD/SPMD parallelism ❍ Can be used for data parallel programming Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 23
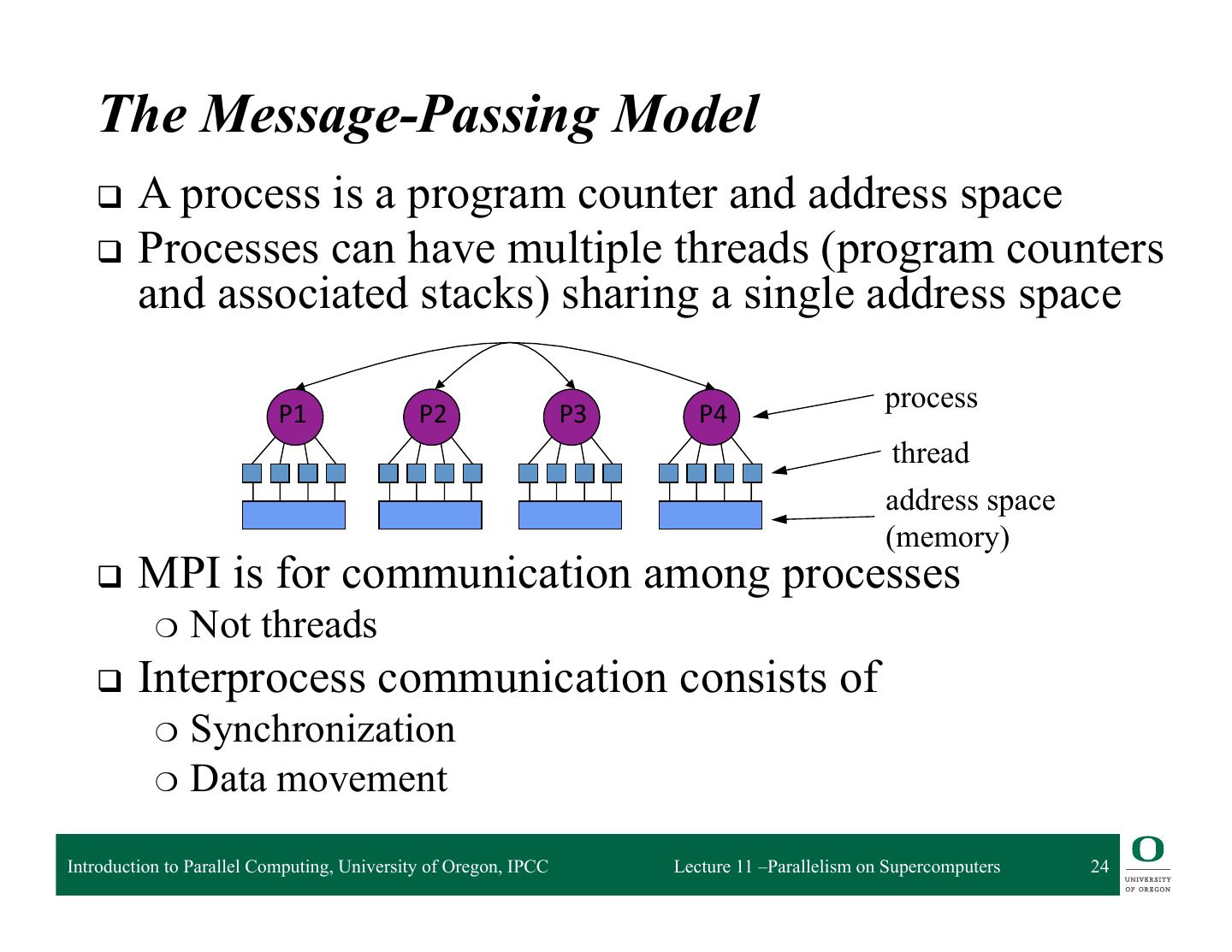
24 . The Message-Passing Model q A process is a program counter and address space q Processes can have multiple threads (program counters and associated stacks) sharing a single address space process P1 P2 P3 P4 thread address space (memory) q MPI is for communication among processes ❍ Not threads q Interprocess communication consists of ❍ Synchronization ❍ Data movement Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 24
25 . SPMD ~~~~~ ~~~ “Owner compute” rule: Mul2ple ~~~~ data Process that “owns” ~~ the data (local data) performs computations Shared on that data ~~~~~ program ~~~ ~~~~ ~~ ~~~~~ ~~~~~ ~~~ ~~~ ~~~~ ~~~~ ~~ ~~ q Data distributed across processes ❍ Not shared Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 25
26 . Message Passing Programming q Defined by communication requirements ❍ Data communication (necessary for algorithm) ❍ Control communication (necessary for dependencies) q Program behavior determined by communication patterns q Message passing infrastructure attempts to support the forms of communication most often used or desired ❍ Basic forms provide functional access ◆ Can be used most often ❍ Complex forms provide higher-level abstractions ◆ Serve as basis for extension ◆ Example: graph libraries, meshing libraries, … ❍ Extensions for greater programming power Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 26
27 . Communication Types q Two ideas for communication ❍ Cooperative operations ❍ One-sided operations Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 27
28 . Cooperative Operations for Communication q Data is cooperatively exchanged in message-passing q Explicitly sent by one process and received by another q Advantage of local control of memory ❍ Any change in the receiving process’s memory is made with the receiver’s explicit participation q Communication and synchronization are combined Process 0 Process 1 Send(data) Receive(data) time Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 28
29 . One-Sided Operations for Communication q One-sided operations between processes ❍ Include remote memory reads and writes q Only one process needs to explicitly participate ❍ There is still agreement implicit in the SPMD program q Advantages? ❍ Communication and synchronization are decoupled Process 0 Process 1 Put(data) (memory) (memory)! Get(data) time Introduction to Parallel Computing, University of Oregon, IPCC Lecture 11 –Parallelism on Supercomputers 29
3秒后跳转登录页面
去登陆

