







































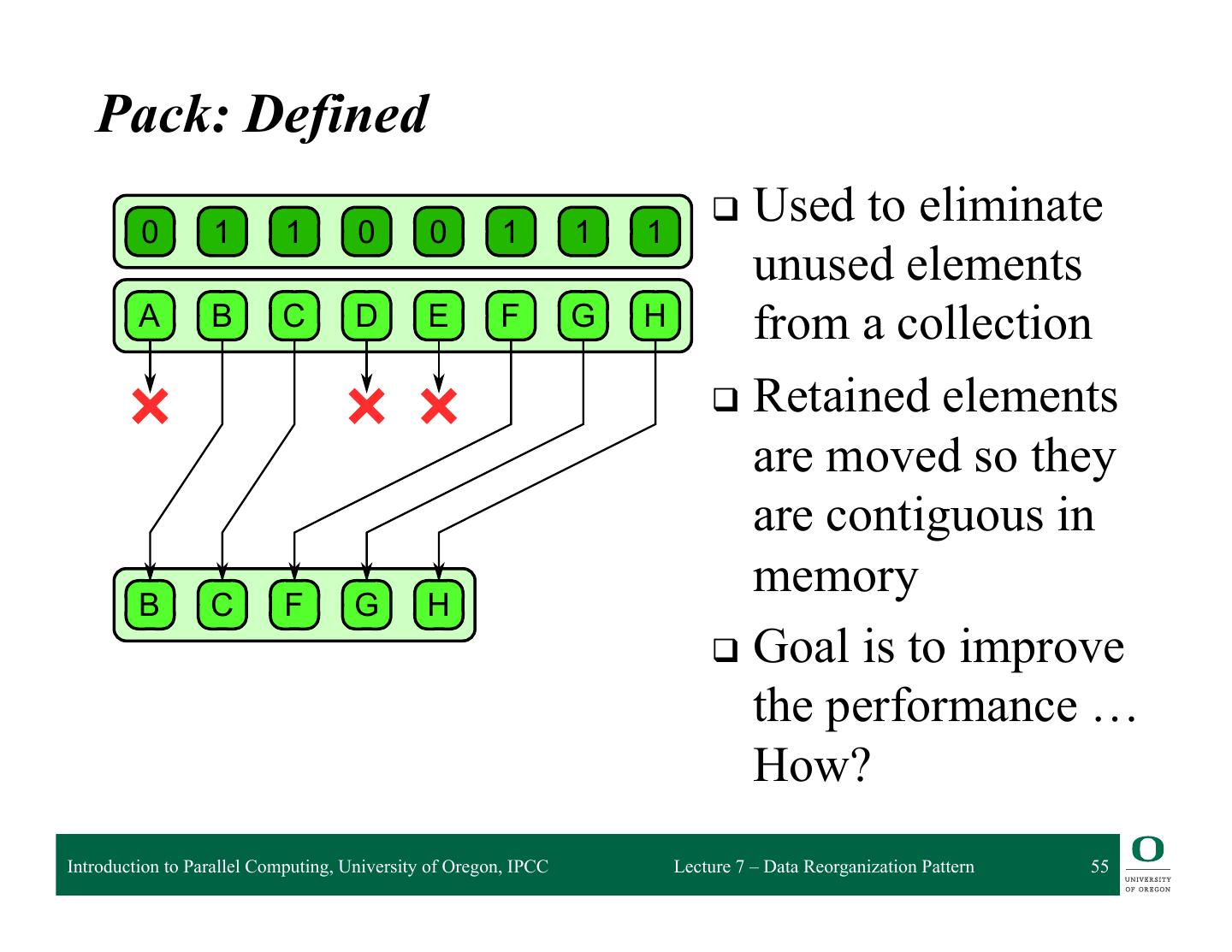
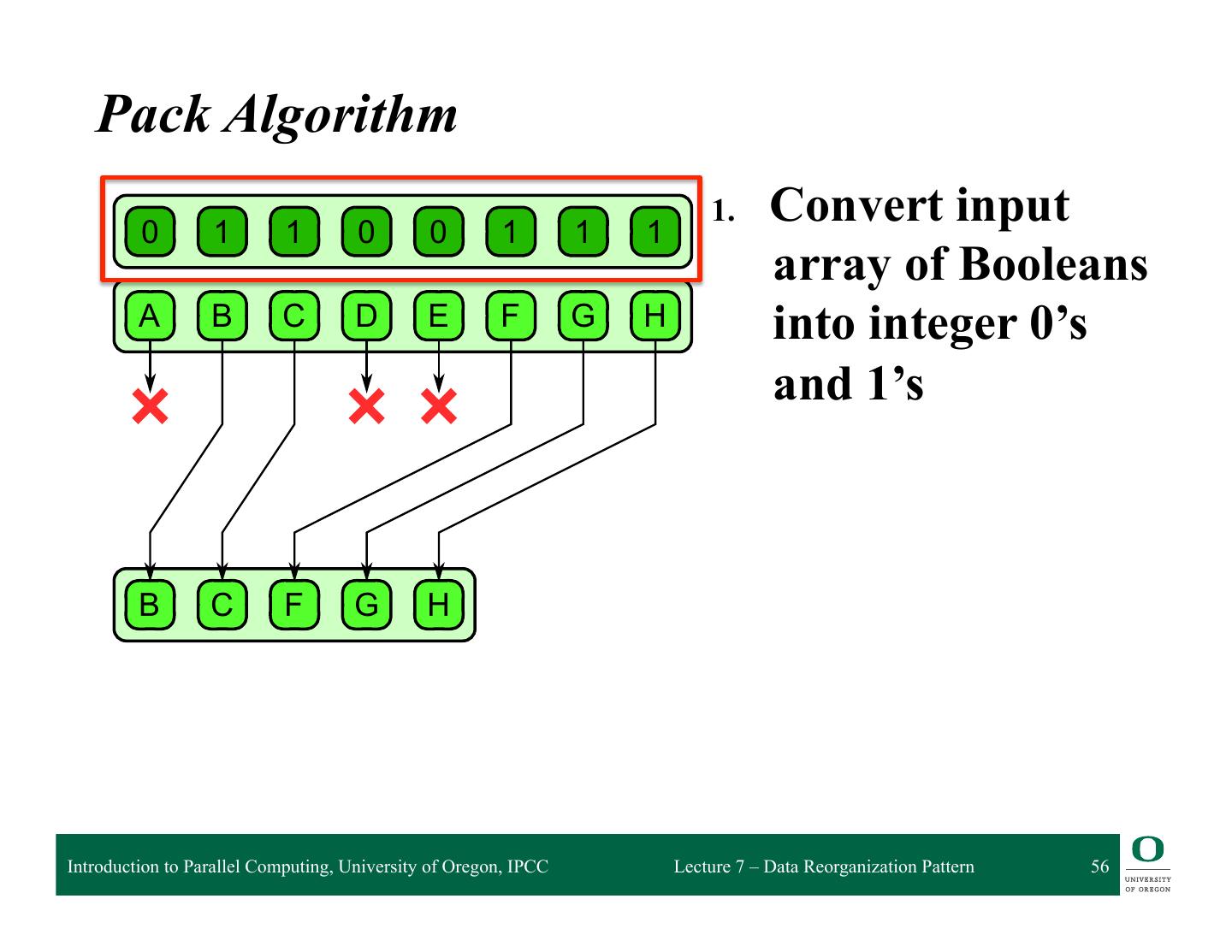
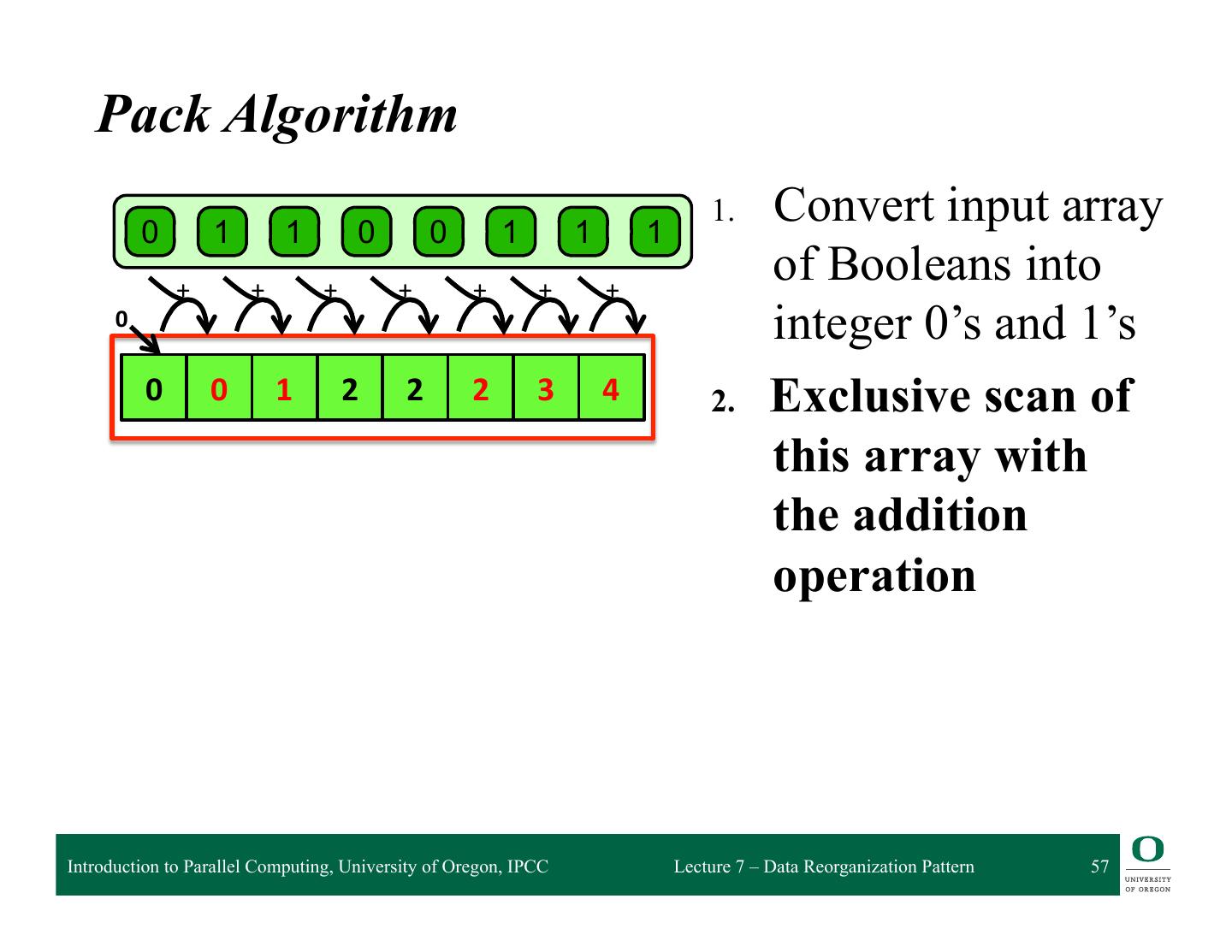
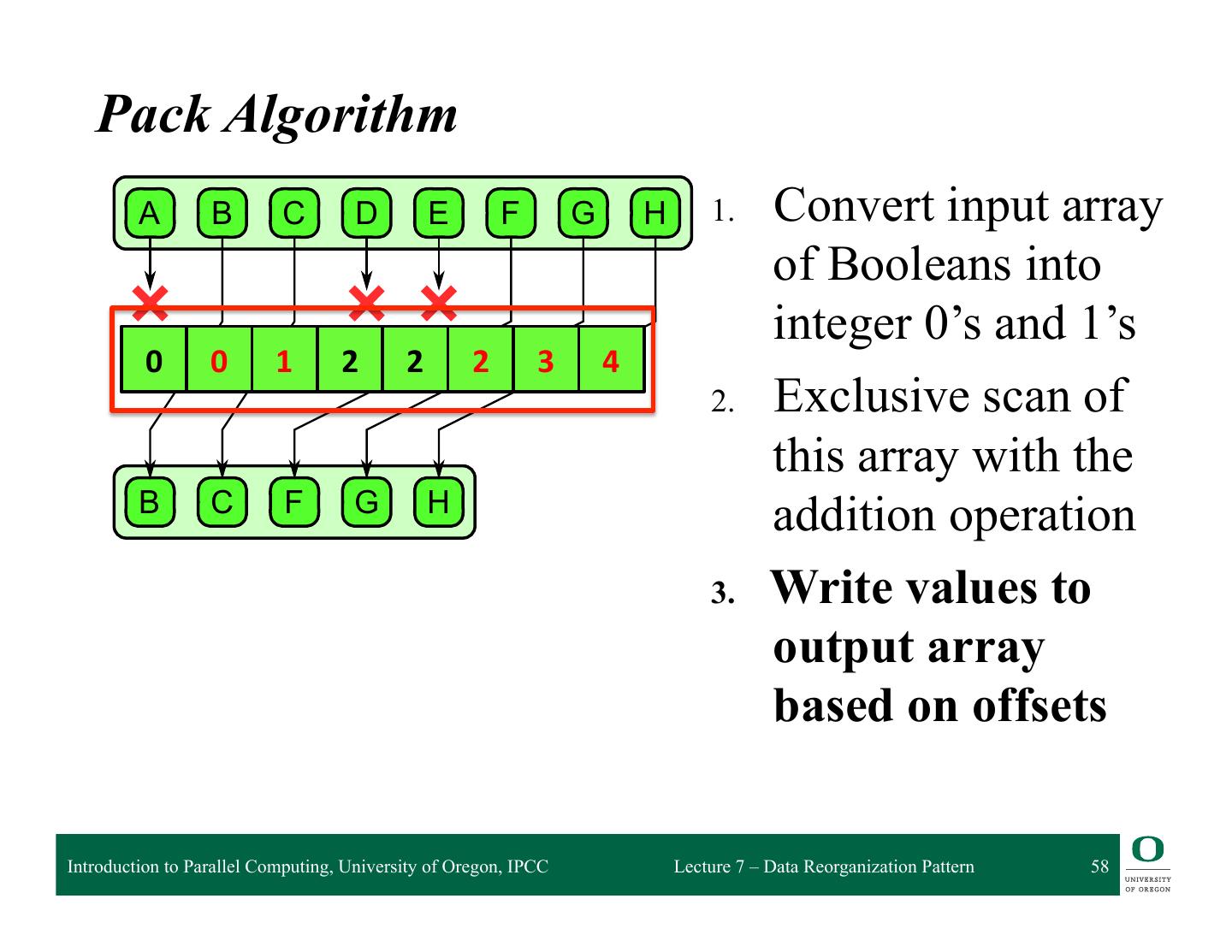




















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
7-Data Reorganization Pattern
Outline
Gather Pattern
❍ Shifts, Zip, Unzip
Scatter Pattern
❍ Collision Rules: atomic, permutation, merge, priority
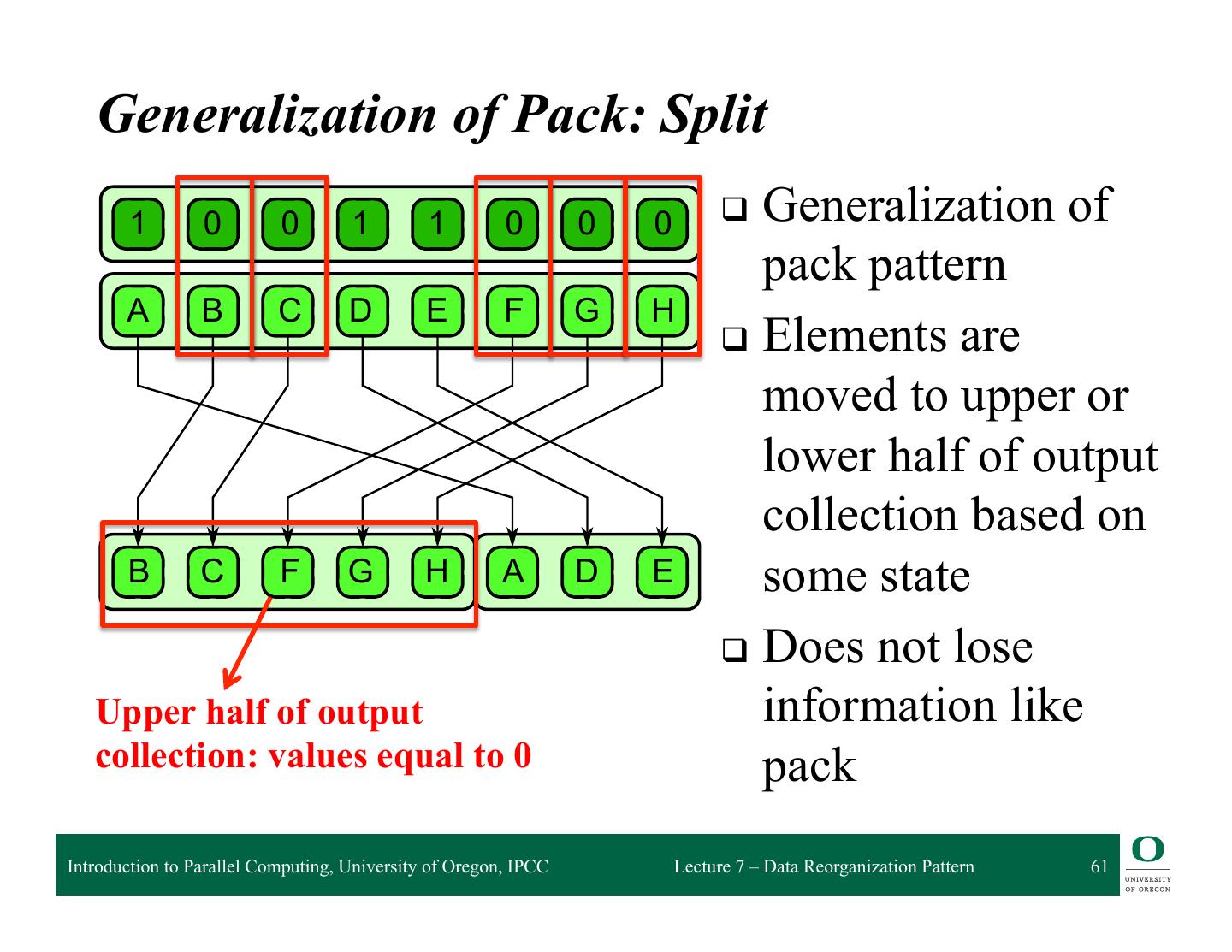
Pack Pattern
❍ Split, Unsplit, Bin
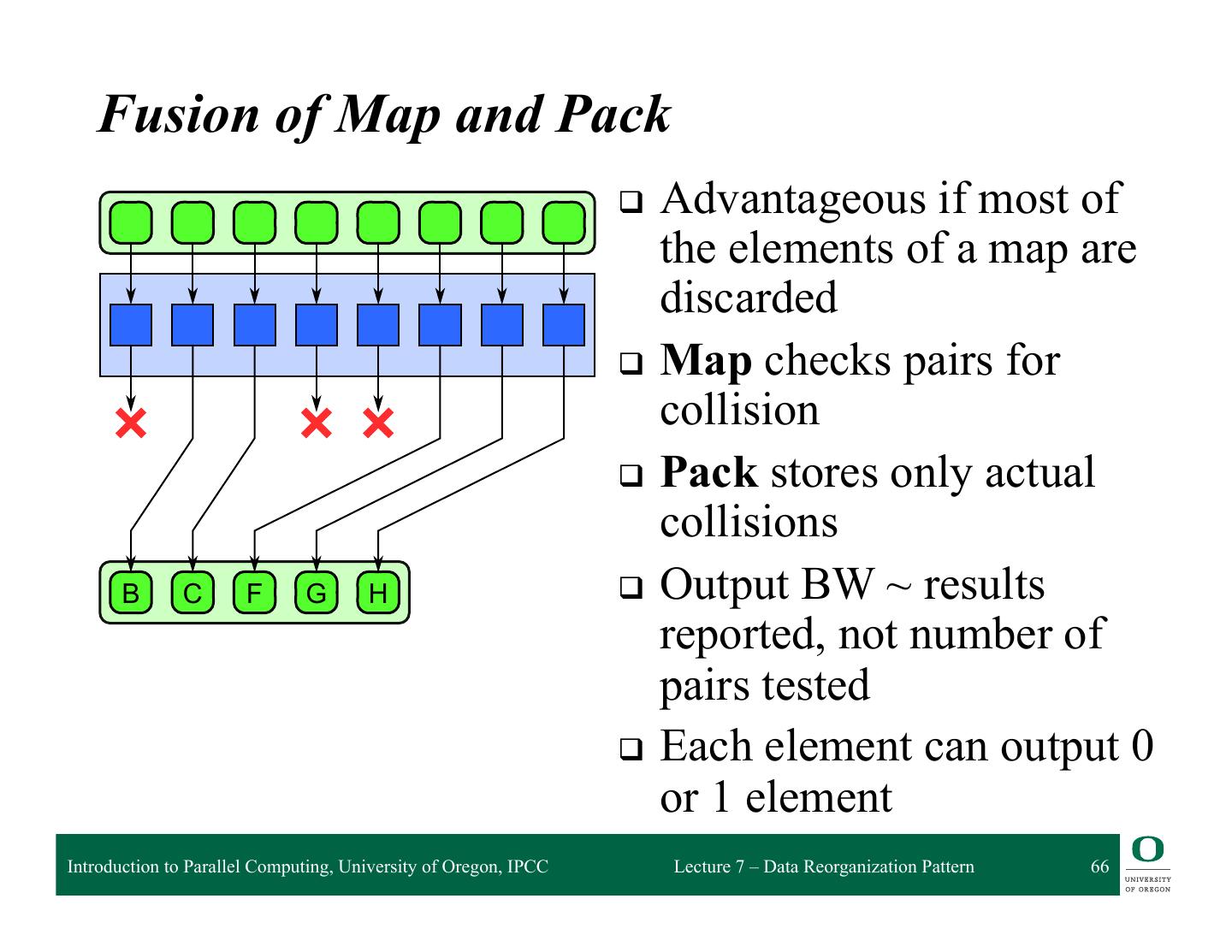
❍ Fusing Map and Pack
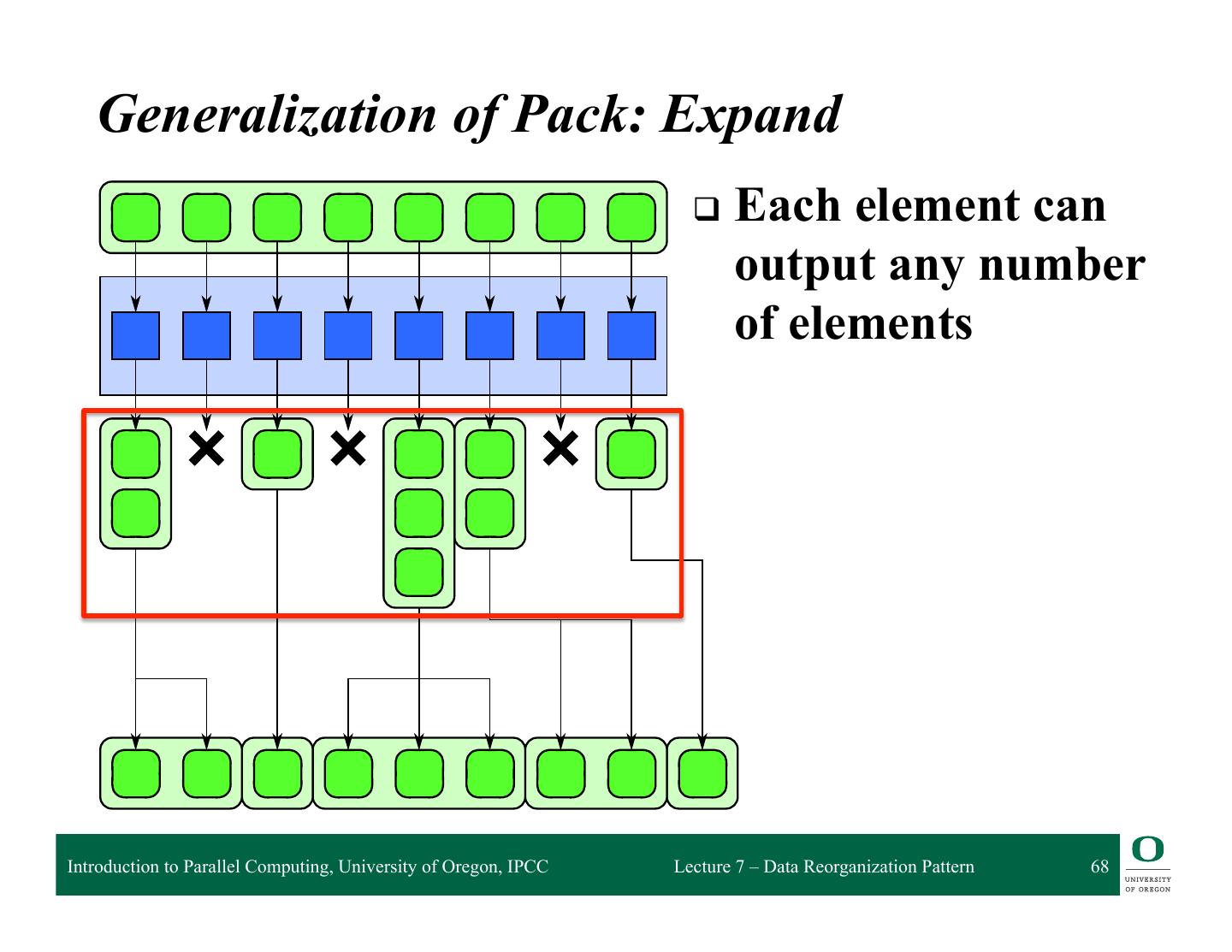
❍ Expand
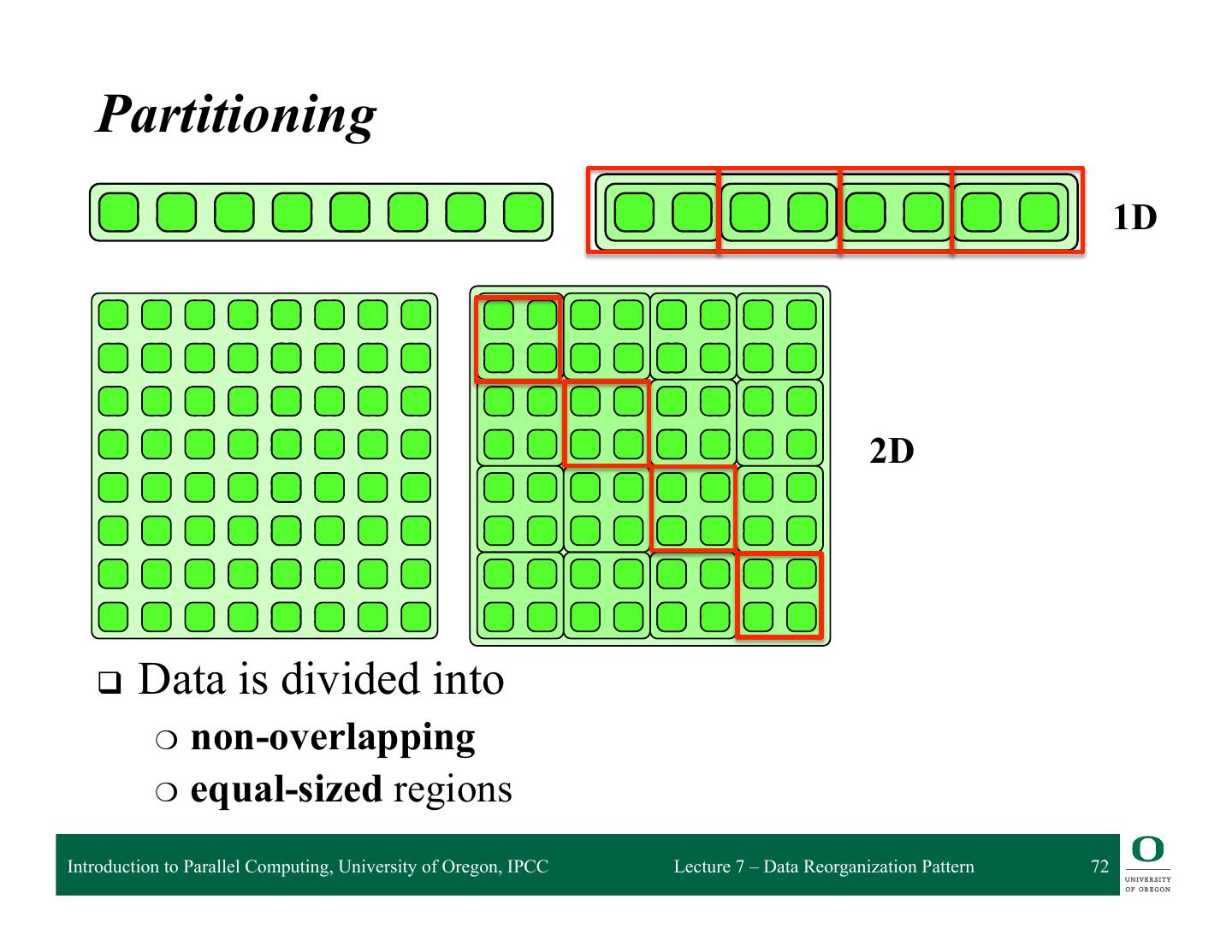
Partitioning Data
AoS vs. SoA
Example Implementation: AoS vs. SoA
展开查看详情
1 . Data Reorganization Pattern Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 7 – Data Reorganization Pattern
2 . Outline q Gather Pattern ❍ Shifts, Zip, Unzip q Scatter Pattern ❍ Collision Rules: atomic, permutation, merge, priority q Pack Pattern ❍ Split, Unsplit, Bin ❍ Fusing Map and Pack ❍ Expand q Partitioning Data q AoS vs. SoA q Example Implementation: AoS vs. SoA Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 2
3 . Data Movement q Performance is often more limited by data movement than by computation ❍ Transferring data across memory layers is costly ◆ locality is important to minimize data access times ◆ data organization and layout can impact this ❍ Transferring data across networks can take many cycles ◆ attempting to minimize the # messages and overhead is important ❍ Data movement also costs more in power q For “data intensive” application, it is a good idea to design the data movement first ❍ Design the computation around the data movements ❍ Applications such as search and sorting are all about data movement and reorganization Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 3
4 . Parallel Data Reorganization q Remember we are looking to do things in parallel q How to be faster than the sequential algorithm? q Similar consistency issues arise as when dealing with computation parallelism q Here we are concerned more with parallel data movement and management issues q Might involve the creation of additional data structures (e.g., for holding intermediate data) Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 4
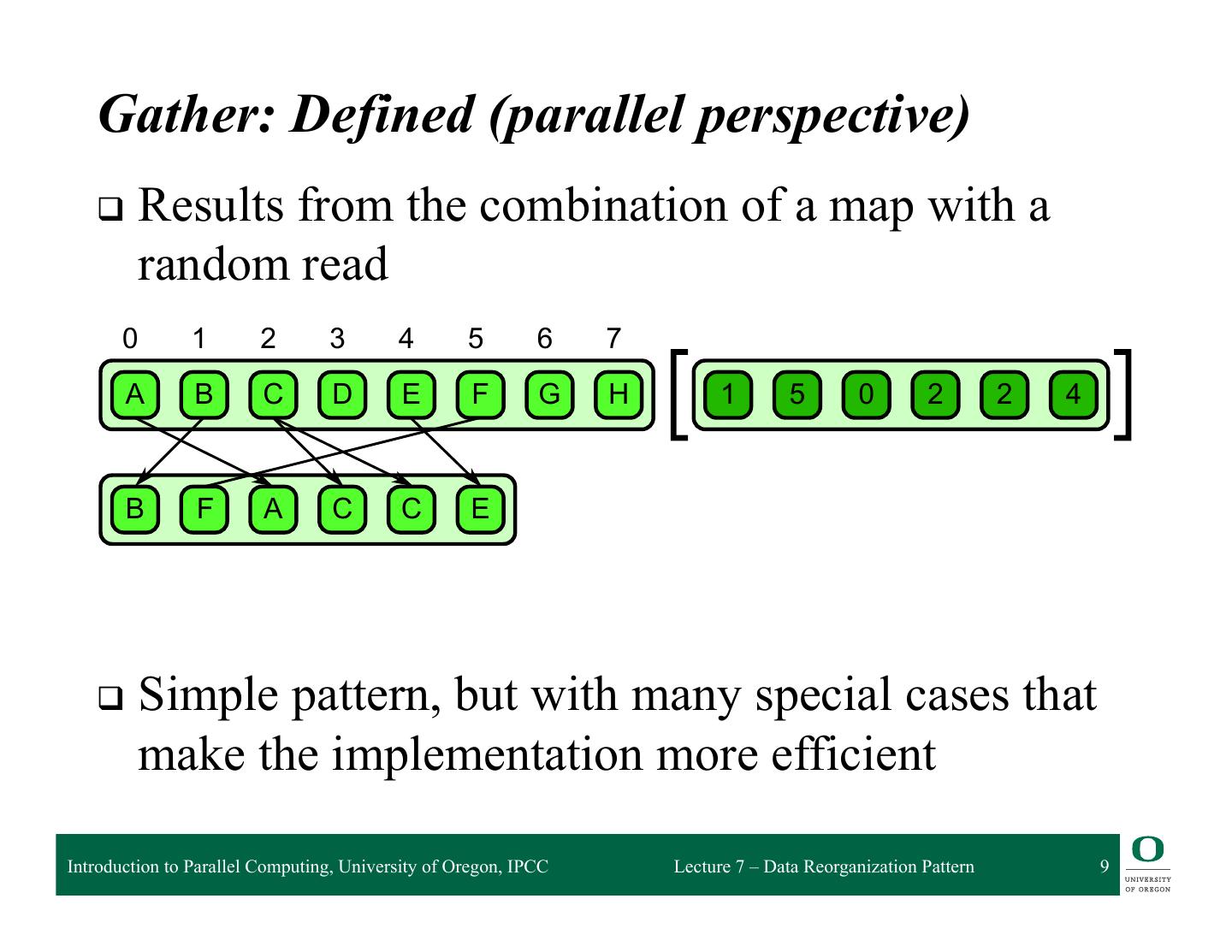
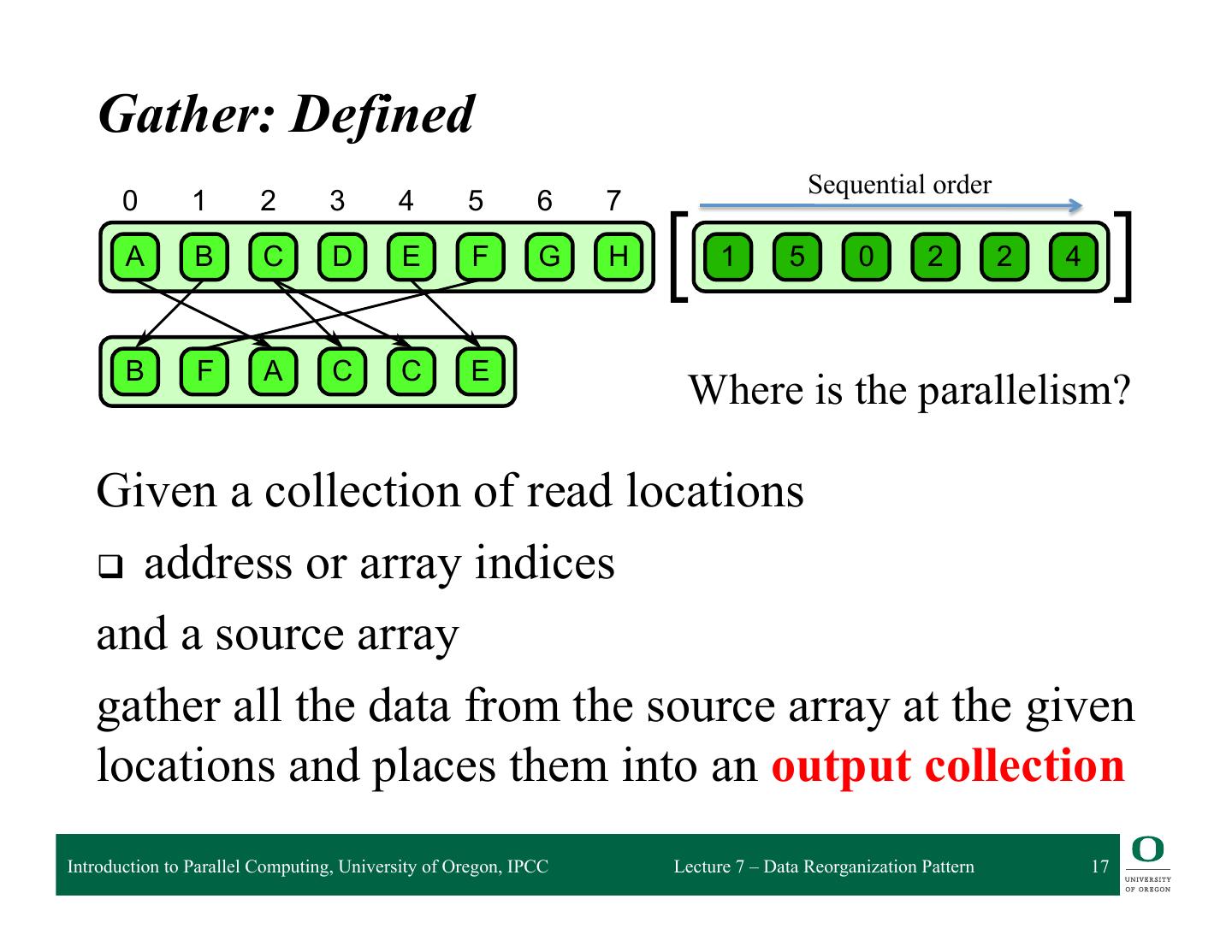
5 . Gather Pattern q Gather pattern creates a (source) collection of data by reading from another (input) data collection ❍ Given a collection of (ordered) indices ❍ Read data from the source collection at each index ❍ Write data to the output collection in index order q Transfers from source collection to output collection ❍ Element type of output collection is the same as the source ❍ Shape of the output collection is that of the index collection ◆ same dimensionality q Can be considered a combination of map and random serial read operations ❍ Essentially does a number of random reads in parallel Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 5
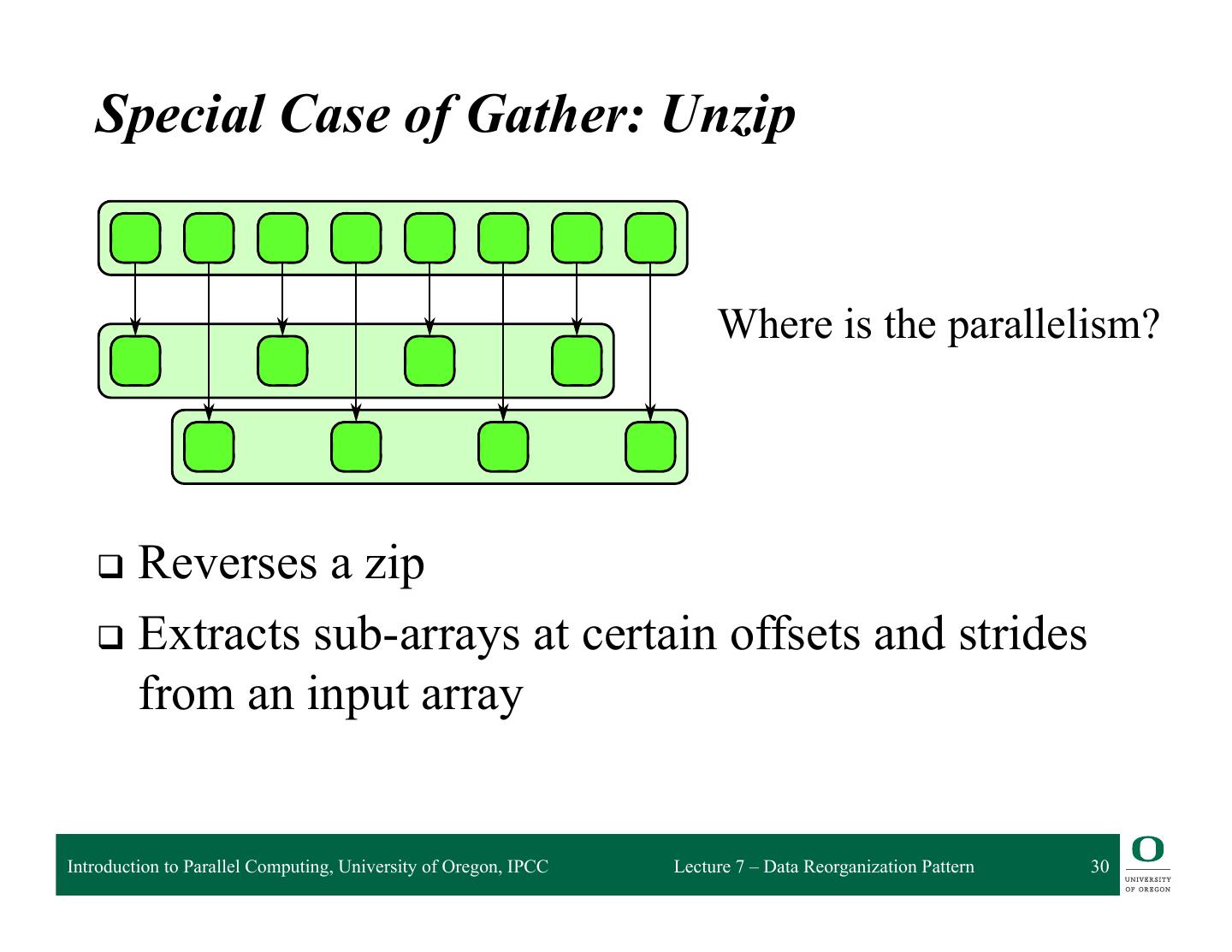
6 . The general gather pattern is simple but there are many special cases which can be implement more efficiently, especially on machines with vector instructions. Important special cases include sh and zip, which are diagrammed in Figures 6.2 and 6.3. The inverse of zip, unzip, is also useful. Gather: Serial Implementation 1 template<typename Data, typename Idx> 2 void gather( 3 size_t n, // number of elements in data collection 4 size_t m, // number of elements in index collection 5 Data a[], // input data collection (n elements ) 6 Data A[], // output data collection (m elements) 7 Idx idx[] // input index collection (m elements) 8 ) { 9 for (size_t i = 0; i < m; ++i) { 10 size_t j = idx[i]; // get ith index 11 assert(0 <= j && j < n); // check array bounds 12 A[i] = a[j]; // perform random read 13 } 14 } Serial implementation of gather in pseudocode LISTING 6.1 Serial implementation of gather in pseudocode. This definition also includes bounds checking (assert) durin debugging as an optional but useful feature. Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 6
7 . The general gather pattern is simple but there are many special cases which can be implement more efficiently, especially on machines with vector instructions. Important special cases include sh and zip, which are diagrammed in Figures 6.2 and 6.3. The inverse of zip, unzip, is also useful. Gather: Serial Implementation 1 template<typename Data, typename Idx> 2 void gather( 3 size_t n, // number of elements in data collection 4 size_t m, // number of elements in index collection 5 Data a[], // input data collection (n elements ) 6 Data A[], // output data collection (m elements) 7 Idx idx[] // input index collection (m elements) 8 ) { 9 for (size_t i = 0; i < m; ++i) { 10 size_t j = idx[i]; // get ith index 11 assert(0 <= j && j < n); // check array bounds 12 A[i] = a[j]; // perform random read 13 } 14 } Serial implementation of gather in pseudocode LISTING 6.1 Serial implementation of gather in pseudocode. This definition also includes bounds checking (assert) durin Do you debugging see as an opportunities optional but useful feature. for parallelism? Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 7
8 . The general gather pattern is simple but there are many special cases which can be implement more efficiently, especially on machines with vector instructions. Important special cases include sh and zip, which are diagrammed in Figures 6.2 and 6.3. The inverse of zip, unzip, is also useful. Gather: Serial Implementation 1 template<typename Data, typename Idx> 2 void gather( 3 size_t n, // number of elements in data collection 4 size_t m, // number of elements in index collection 5 Data a[], // input data collection (n elements ) 6 Data A[], // output data collection (m elements) Idx idx[] // input index collection (m elements) 7 8 ) { Parallelize over 9 10 for (size_t i = 0; i < m; ++i) { size_t j = idx[i]; // get ith index for loop to 11 12 assert(0 <= j && j < n); // check array bounds A[i] = a[j]; // perform random read perform random 13 14 } } read Serial implementation of gather in pseudocode LISTING 6.1 Serial implementation of gather in pseudocode. This definition also includes bounds checking (assert) durin Are there debugging anybutconflicts as an optional useful feature. that arise? Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 8
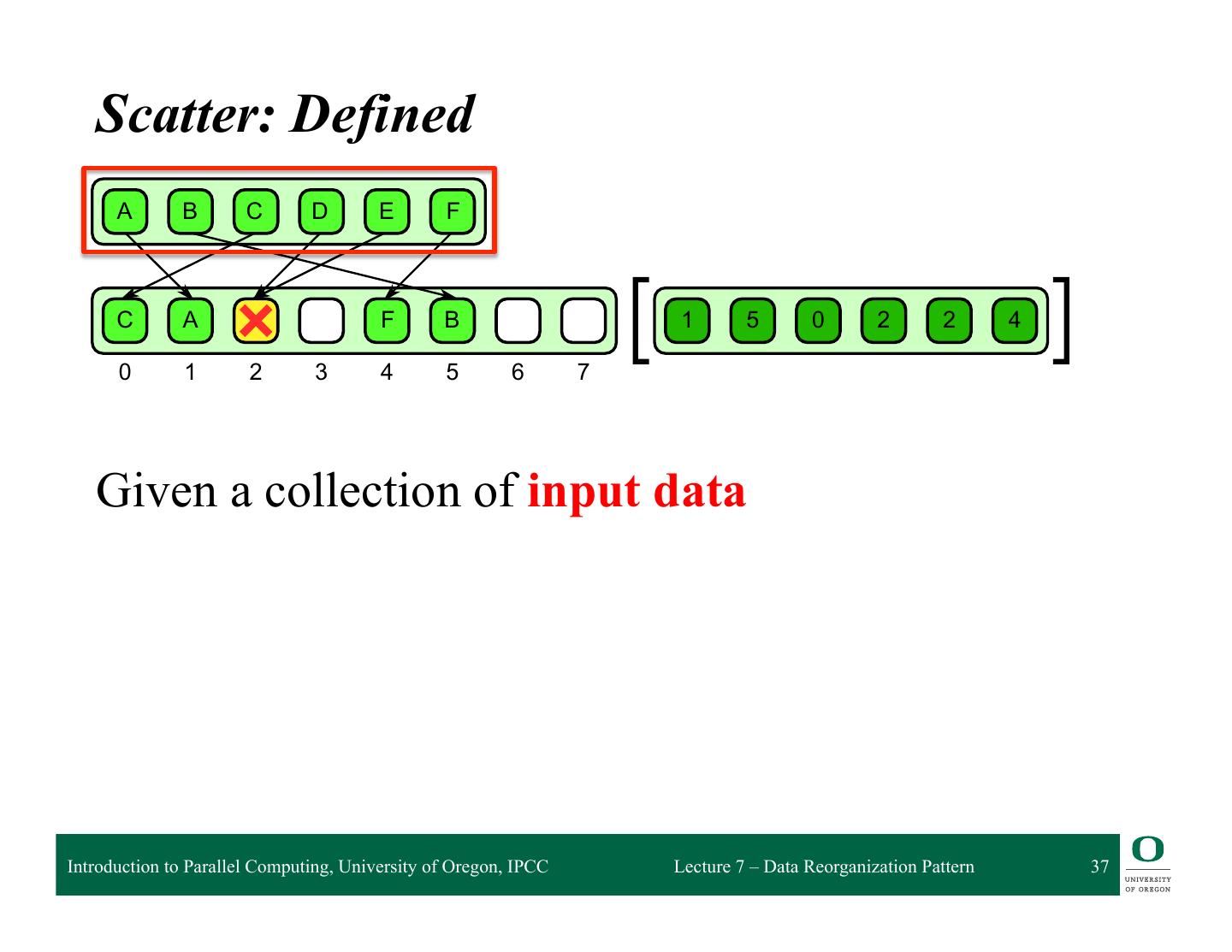
9 .mal publication. McCool — e9780124159938 — 2012/6/6 — 23:09 — Page 181 — #181 Gather: Defined (parallel perspective) 6.1 Gather q Results from the combination of a map with a random read 0 1 2 3 4 5 6 7 A B C D E F G H 1 5 0 2 2 4 B F A C C E 6.1 attern. A collection of data is read from an input collection given a collection of indices. This is q Simple nt to a map combined pattern, with a randombut with read in themany specialfunction. map’s elemental cases that make the implementation more efficient Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 9
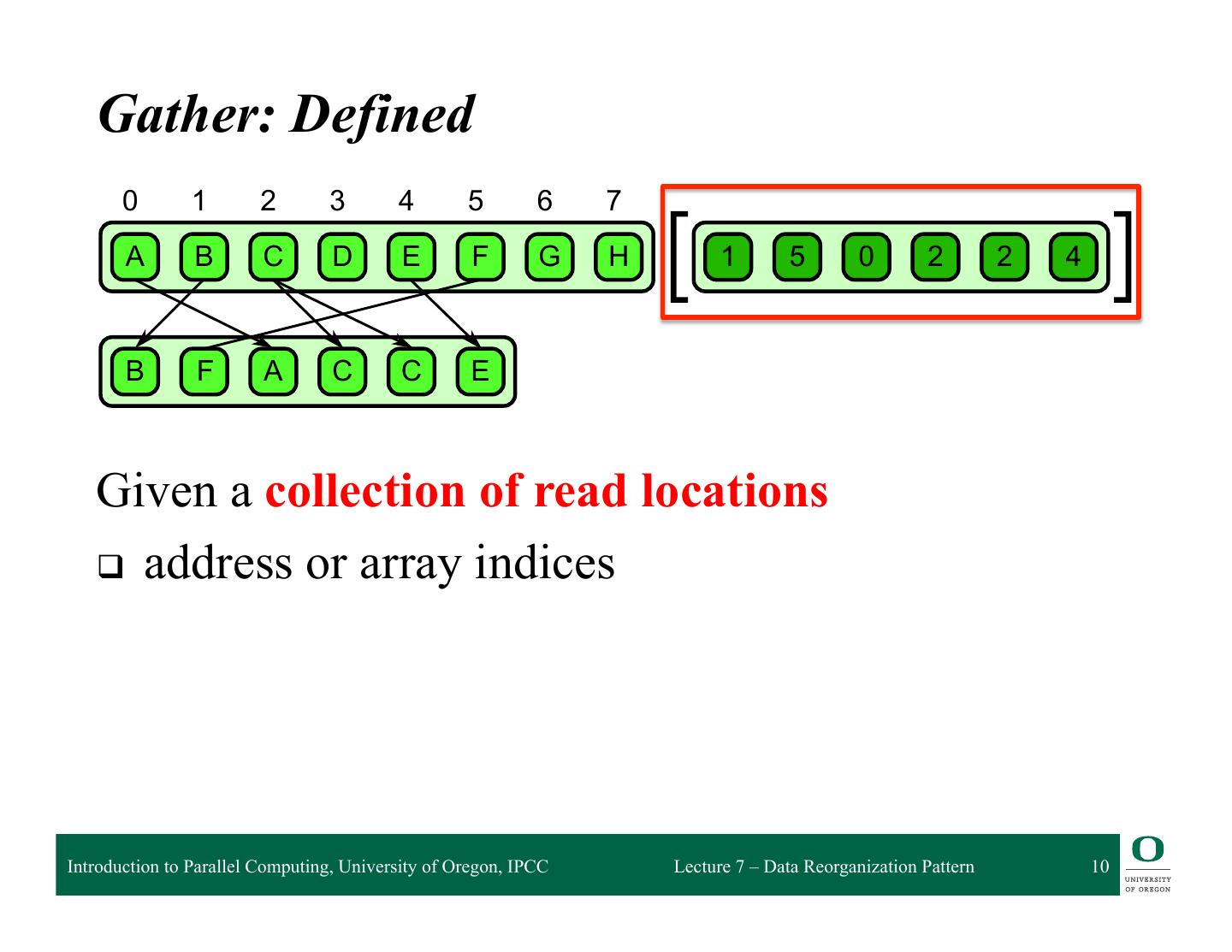
10 . 6.1 Gather Gather: Defined 0 1 2 3 4 5 6 7 A B C D E F G H 1 5 0 2 2 4 B F A C C E 6.1 Given a collection of read locations attern. A collection of data is read from an input collection given a collection of indices. This is q address nt to a map combined withor aarray randomindices read in the map’s elemental function. Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 10
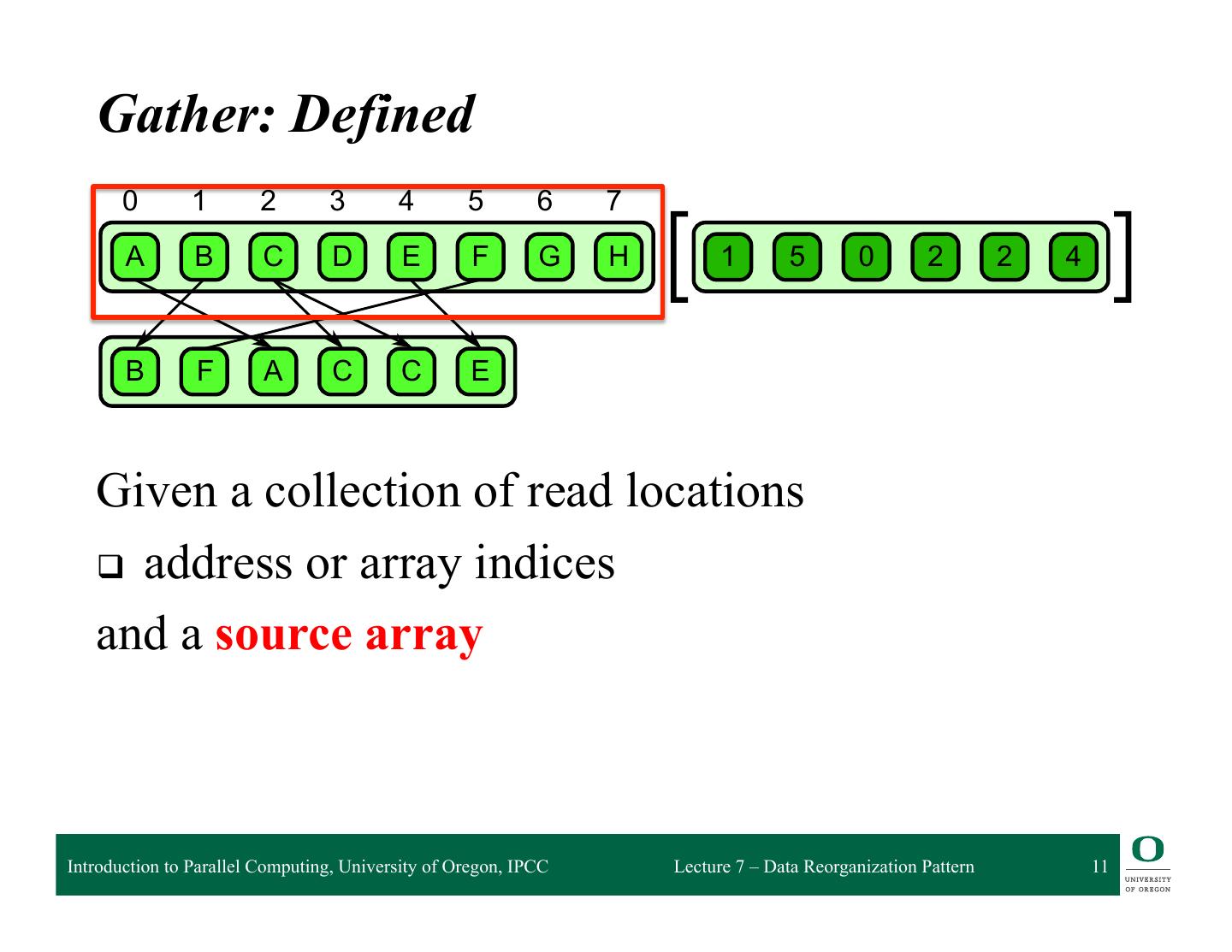
11 . 6.1 Gather Gather: Defined 0 1 2 3 4 5 6 7 A B C D E F G H 1 5 0 2 2 4 B F A C C E 6.1 Given a collection of read locations attern. A collection of data is read from an input collection given a collection of indices. This is q address nt to a map combined withor aarray randomindices read in the map’s elemental function. and a source array Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 11
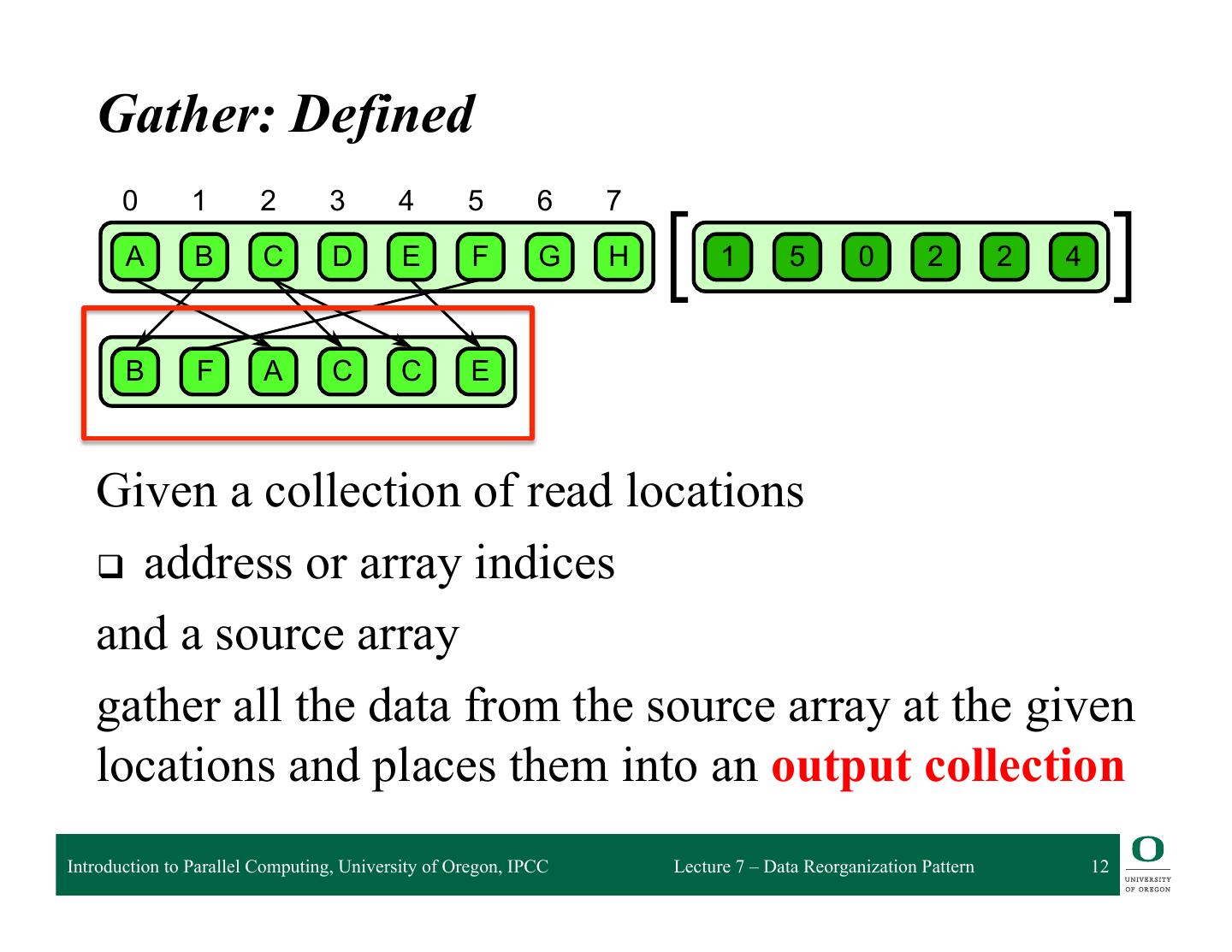
12 . 6.1 Gather Gather: Defined 0 1 2 3 4 5 6 7 A B C D E F G H 1 5 0 2 2 4 B F A C C E 6.1 Given a collection of read locations attern. A collection of data is read from an input collection given a collection of indices. This is q address nt to a map combined withor aarray randomindices read in the map’s elemental function. and a source array gather all the data from the source array at the given locations and places them into an output collection Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 12
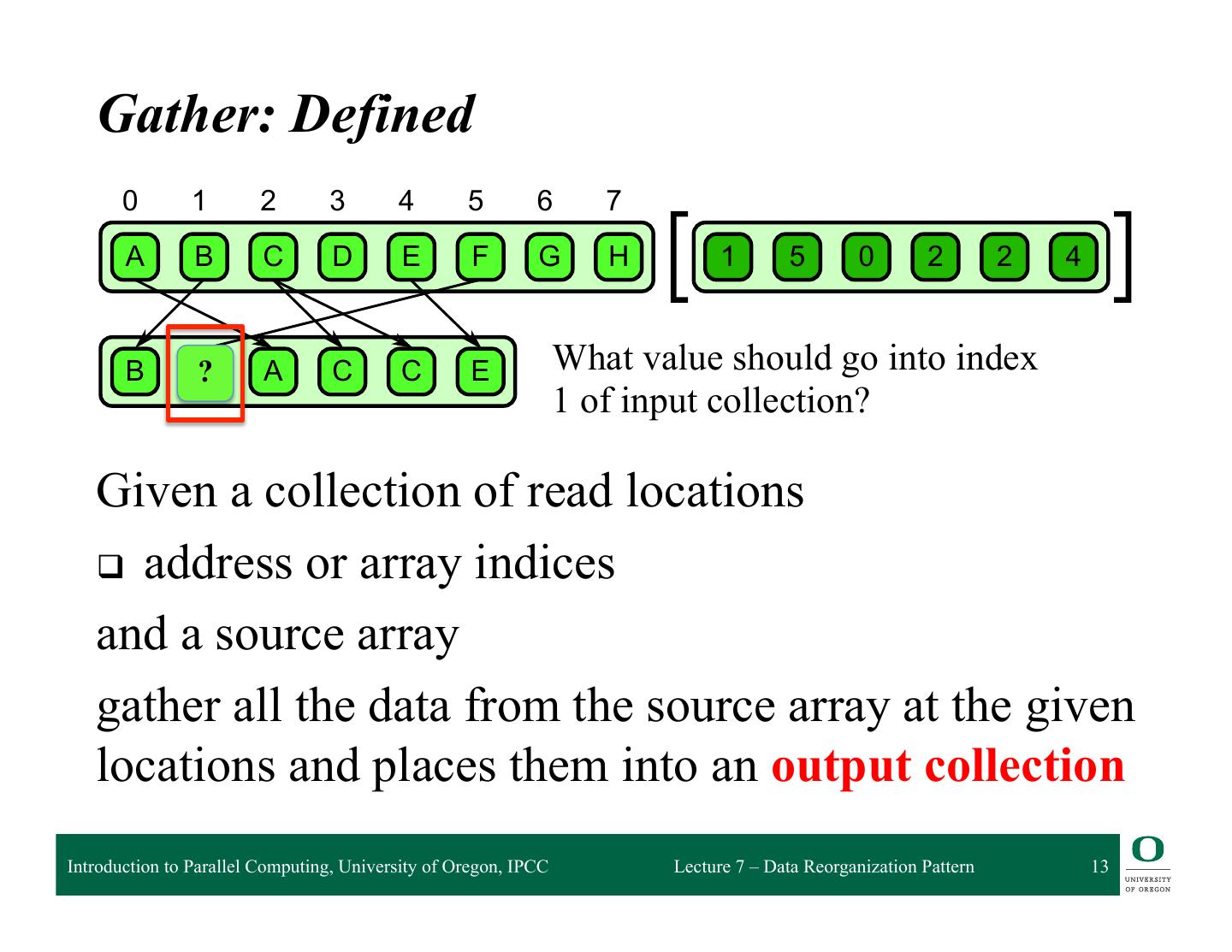
13 . 6.1 Gather Gather: Defined 0 1 2 3 4 5 6 7 A B C D E F G H 1 5 0 2 2 4 B ? F A C C E What value should go into index 1 of input collection? 6.1 Given a collection of read locations attern. A collection of data is read from an input collection given a collection of indices. This is q address nt to a map combined withor aarray randomindices read in the map’s elemental function. and a source array gather all the data from the source array at the given locations and places them into an output collection Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 13
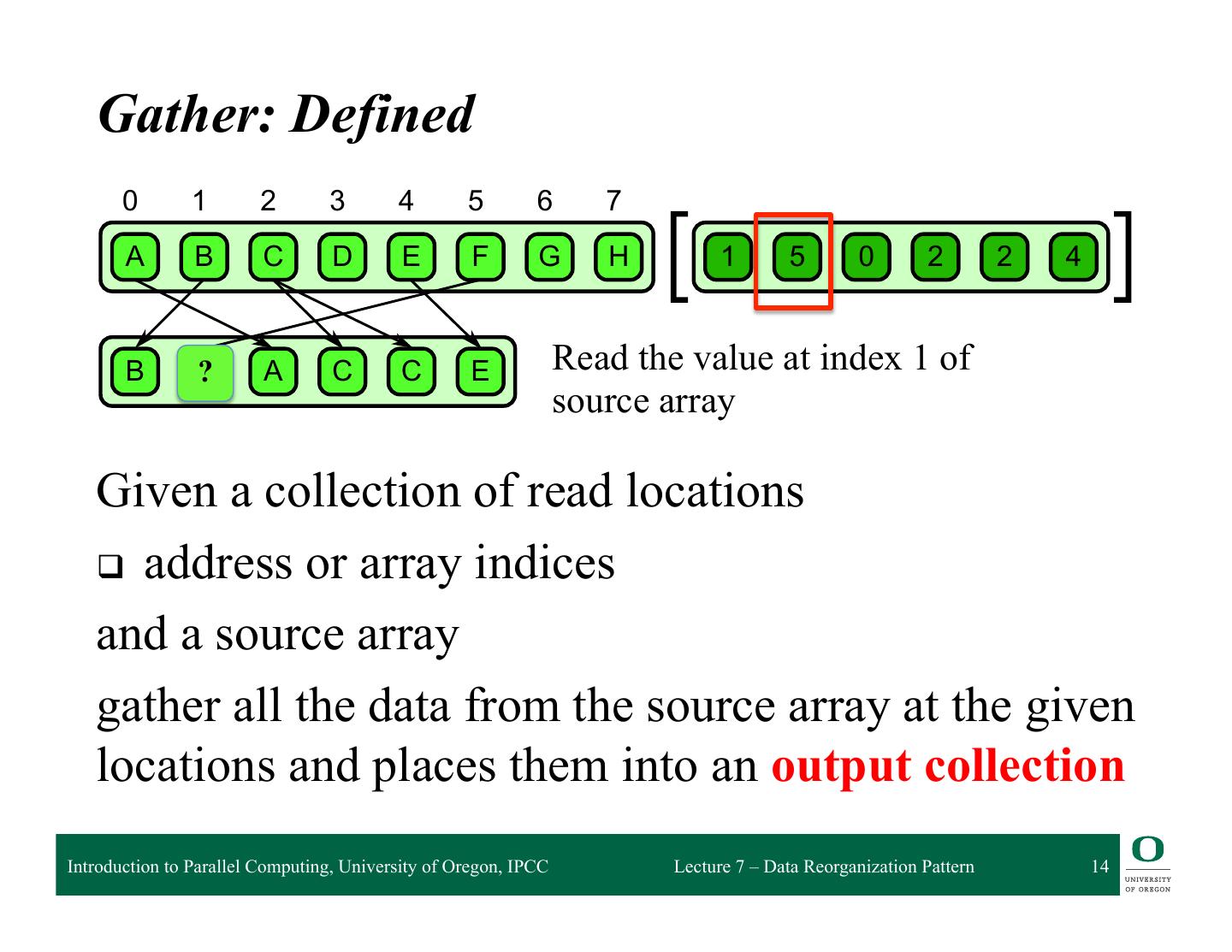
14 . 6.1 Gather Gather: Defined 0 1 2 3 4 5 6 7 A B C D E F G H 1 5 0 2 2 4 B ? F A C C E Read the value at index 1 of source array 6.1 Given a collection of read locations attern. A collection of data is read from an input collection given a collection of indices. This is q address nt to a map combined withor aarray randomindices read in the map’s elemental function. and a source array gather all the data from the source array at the given locations and places them into an output collection Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 14
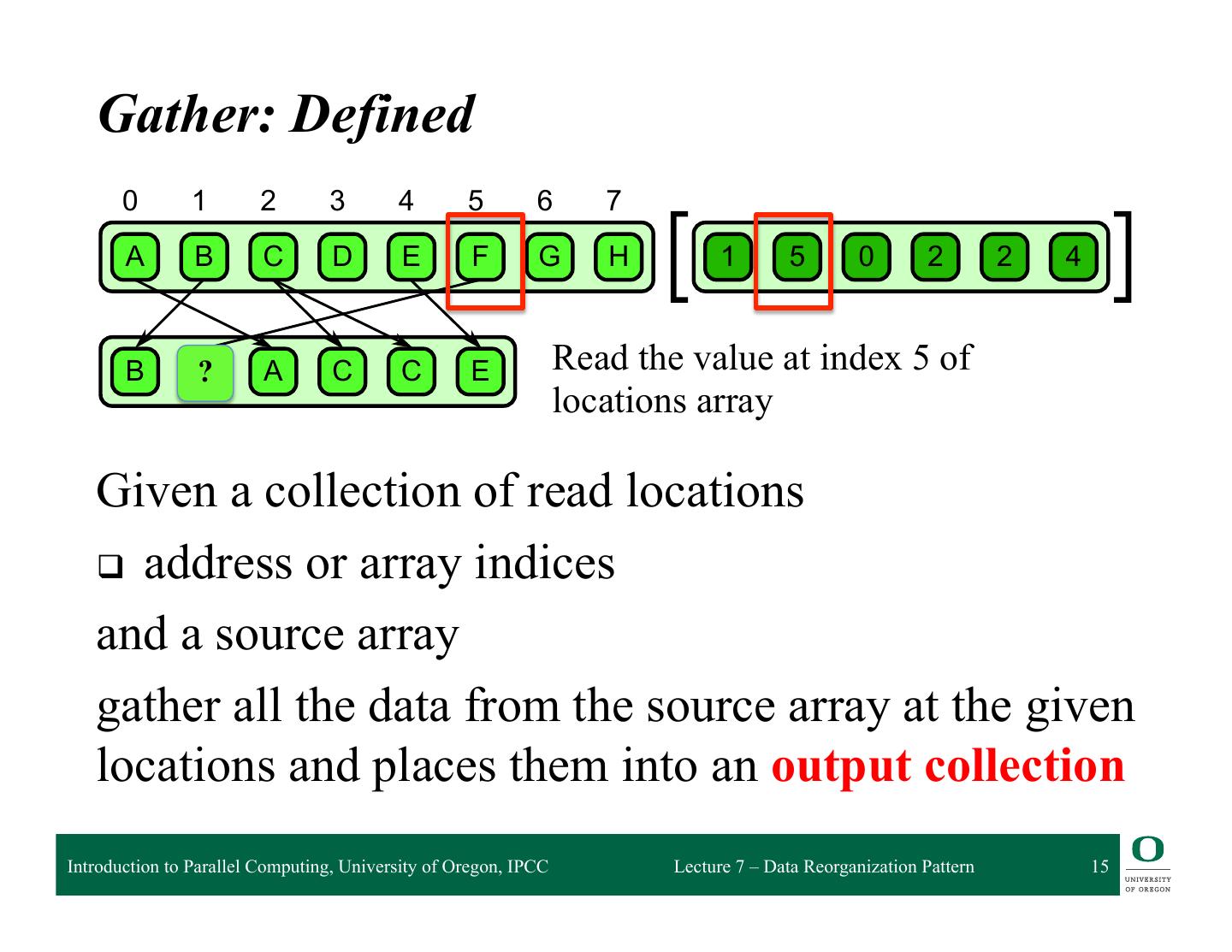
15 . 6.1 Gather Gather: Defined 0 1 2 3 4 5 6 7 A B C D E F G H 1 5 0 2 2 4 B ? F A C C E Read the value at index 5 of locations array 6.1 Given a collection of read locations attern. A collection of data is read from an input collection given a collection of indices. This is q address nt to a map combined withor aarray randomindices read in the map’s elemental function. and a source array gather all the data from the source array at the given locations and places them into an output collection Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 15
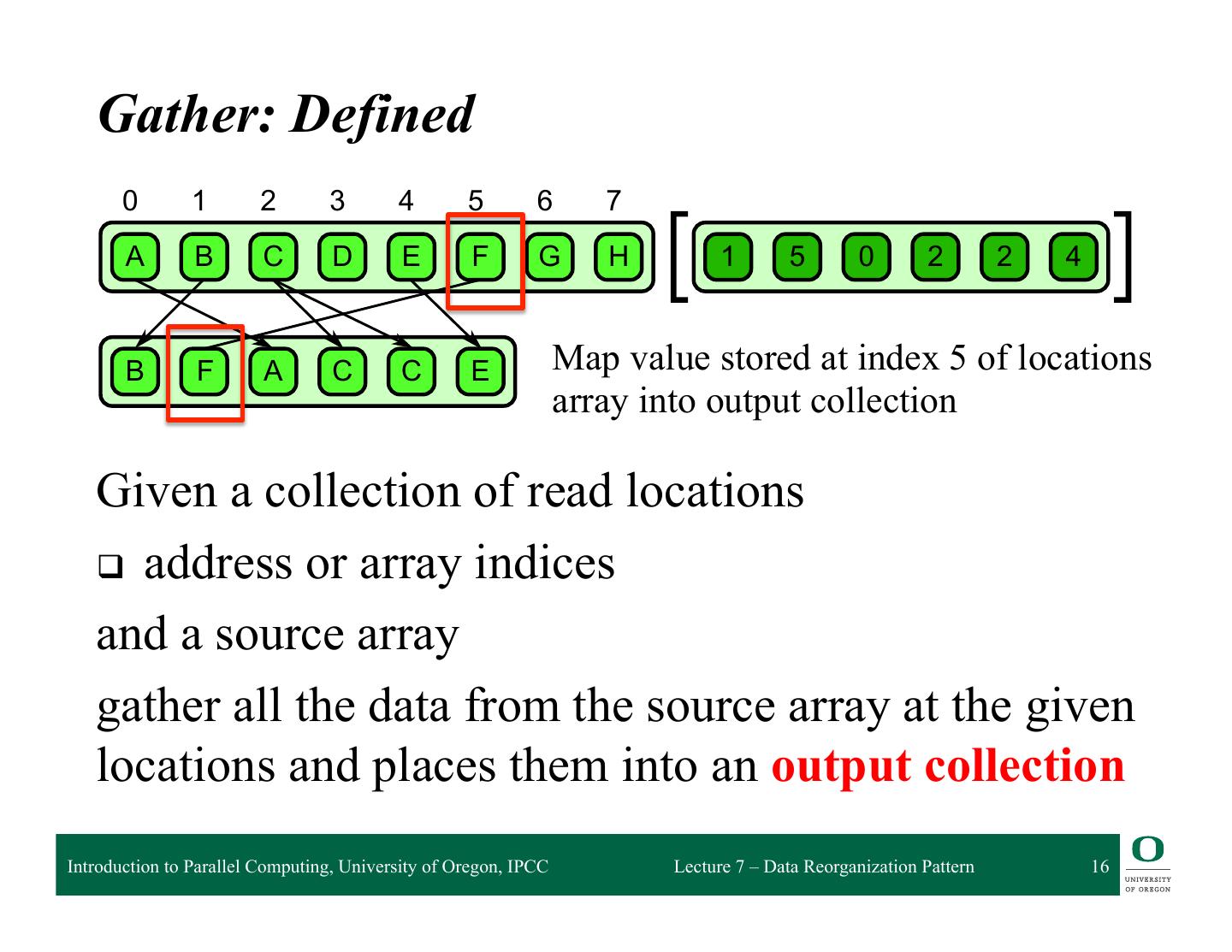
16 . 6.1 Gather Gather: Defined 0 1 2 3 4 5 6 7 A B C D E F G H 1 5 0 2 2 4 B F A C C E Map value stored at index 5 of locations array into output collection 6.1 Given a collection of read locations attern. A collection of data is read from an input collection given a collection of indices. This is q address nt to a map combined withor aarray randomindices read in the map’s elemental function. and a source array gather all the data from the source array at the given locations and places them into an output collection Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 16
17 . 6.1 Gather Gather: Defined Sequential order 0 1 2 3 4 5 6 7 A B C D E F G H 1 5 0 2 2 4 B F A C C E Where is the parallelism? 6.1 Given a collection of read locations attern. A collection of data is read from an input collection given a collection of indices. This is q address nt to a map combined withor aarray randomindices read in the map’s elemental function. and a source array gather all the data from the source array at the given locations and places them into an output collection Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 17
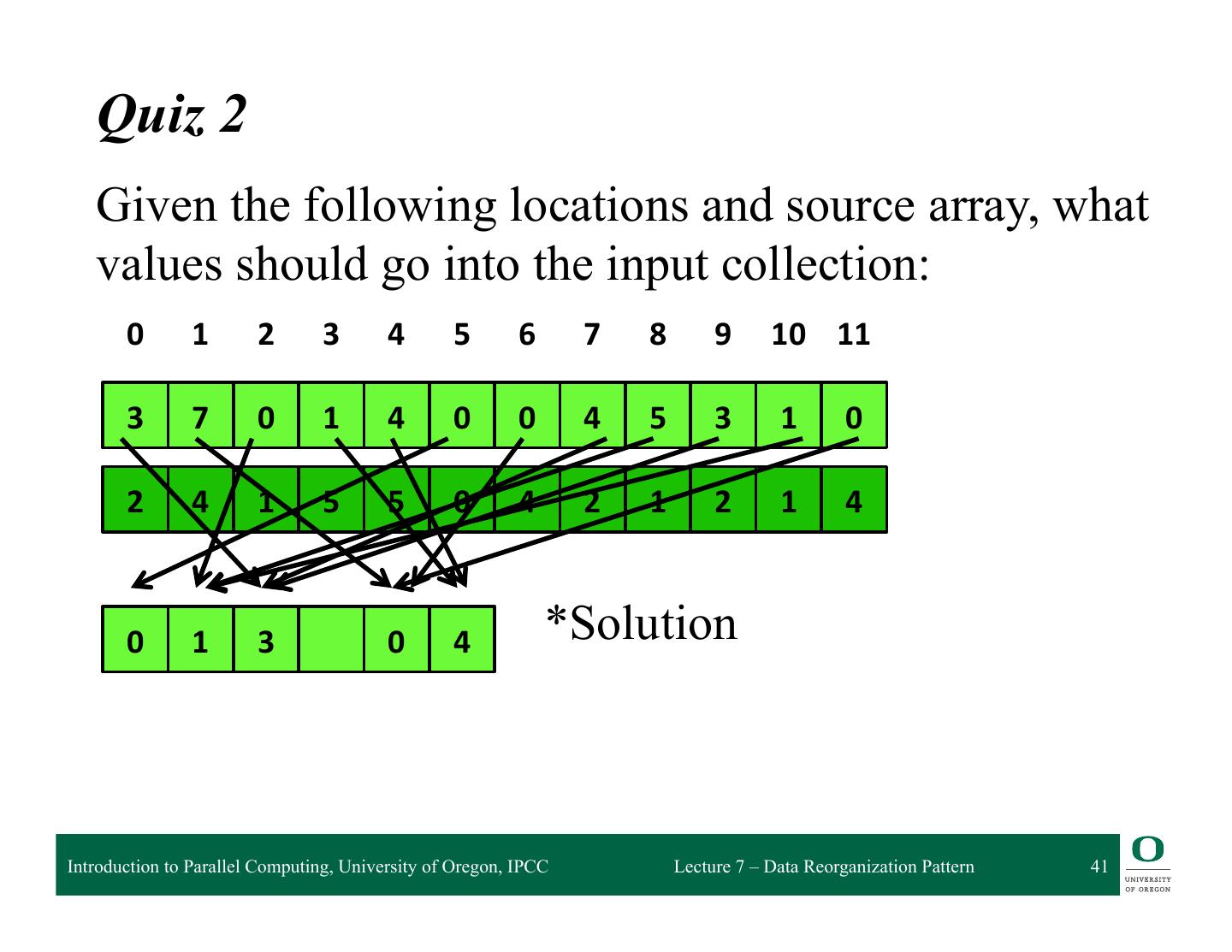
18 . Quiz 1 Given the following locations and source array, use a gather to determine what values should go into the output collection: 0 1 2 3 4 5 6 7 8 9 10 11 3 7 0 1 4 0 0 4 5 3 1 0 1 9 6 9 3 ? ? ? ? ? Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 18
19 . Quiz 1 Given the following locations and source array, use a gather to determine what values should go into the output collection: 0 1 2 3 4 5 6 7 8 9 10 11 3 7 0 1 4 0 0 4 5 3 1 0 1 9 6 9 3 7 3 0 3 1 Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 19
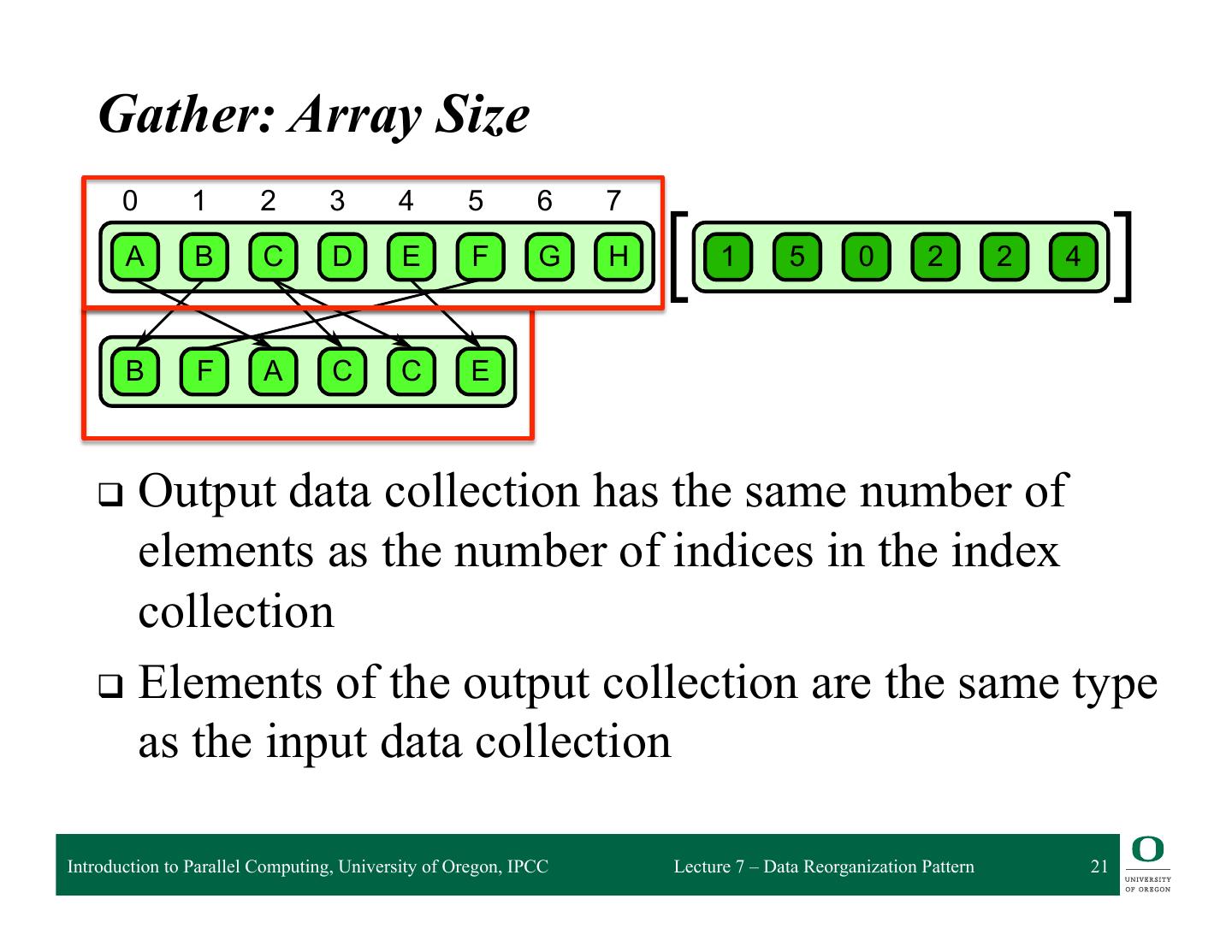
20 . 6.1 Gather Gather: Array Size 0 1 2 3 4 5 6 7 A B C D E F G H 1 5 0 2 2 4 B F A C C E 6.1 q Output data collection has the same number of attern. A collection of data is read from an input collection given a collection of indices. This is nt to a mapelements combined with asa random the number ofmap’s read in the indices in function. elemental the index collection ❍ Same dimensionality Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 20
21 . 6.1 Gather Gather: Array Size 0 1 2 3 4 5 6 7 A B C D E F G H 1 5 0 2 2 4 B F A C C E 6.1 q Output data collection has the same number of attern. A collection of data is read from an input collection given a collection of indices. This is nt to a mapelements combined with asa random the number ofmap’s read in the indices in function. elemental the index collection q Elements of the output collection are the same type as the input data collection Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 21
22 . Outline q Gather Pattern ❍ Shifts, Zip, Unzip q Scatter Pattern ❍ Collision Rules: atomic, permutation, merge, priority q Pack Pattern ❍ Split, Unsplit, Bin ❍ Fusing Map and Pack ❍ Expand q Partitioning Data q AoS vs. SoA q Example Implementation: AoS vs. SoA Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 22
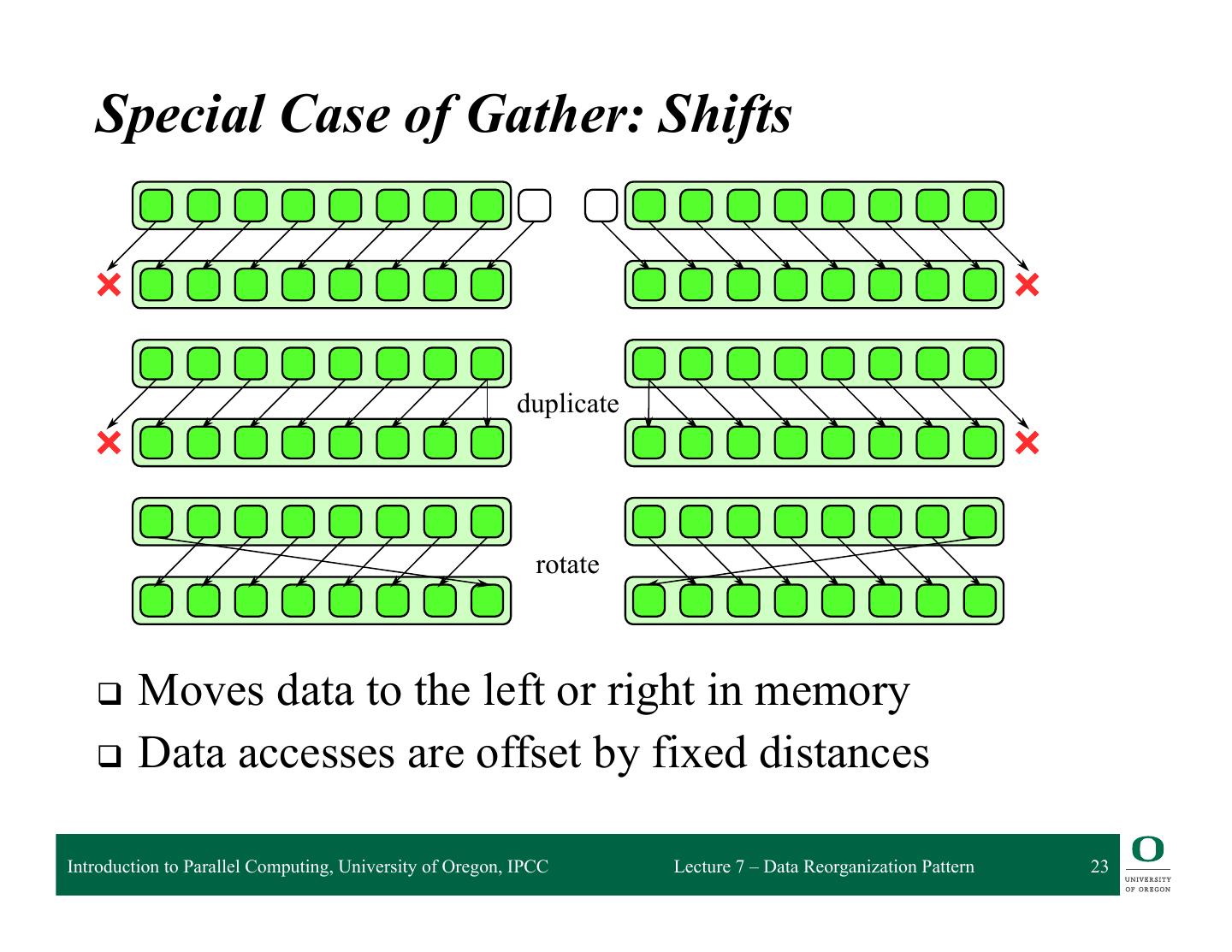
23 .FIGURE 6.1 Gather pattern. A collection of data is read from an input collection given a collection of indices. This is Special Case of Gather: Shifts equivalent to a map combined with a random read in the map’s elemental function. duplicate rotate FIGURE 6.2 Moves data to the left or right in memory q special cases of gather. There are variants based on how boundary conditions are treated. Shifts are Boundaries can be duplicated, rotated, reflected, a default value can be used, or most generally some arbitrary Data accesses are offset by fixed distances q can be used. Unlike a general gather, however, shifts can be efficiently implemented using vector function instructions since in the interior, the data access pattern is regular. Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 23
24 . More about Shifts q Regular data movement q Variants from how boundary conditions handled ❍ Requires “out of bounds” data at edge of the array ❍ Options: default value, duplicate, rotate q Shifts can be handled efficiently with vector instructions because of regularity ❍ Shift multiple data elements at the same time q Shifts can also take advantage of good data locality Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 24
25 . Table of Contents q Gather Pattern ❍ Shifts, Zip, Unzip q Scatter Pattern ❍ Collision Rules: atomic, permutation, merge, priority q Pack Pattern ❍ Split, Unsplit, Bin ❍ Fusing Map and Pack ❍ Expand q Partitioning Data q AoS vs. SoA q Example Implementation: AoS vs. SoA Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 25
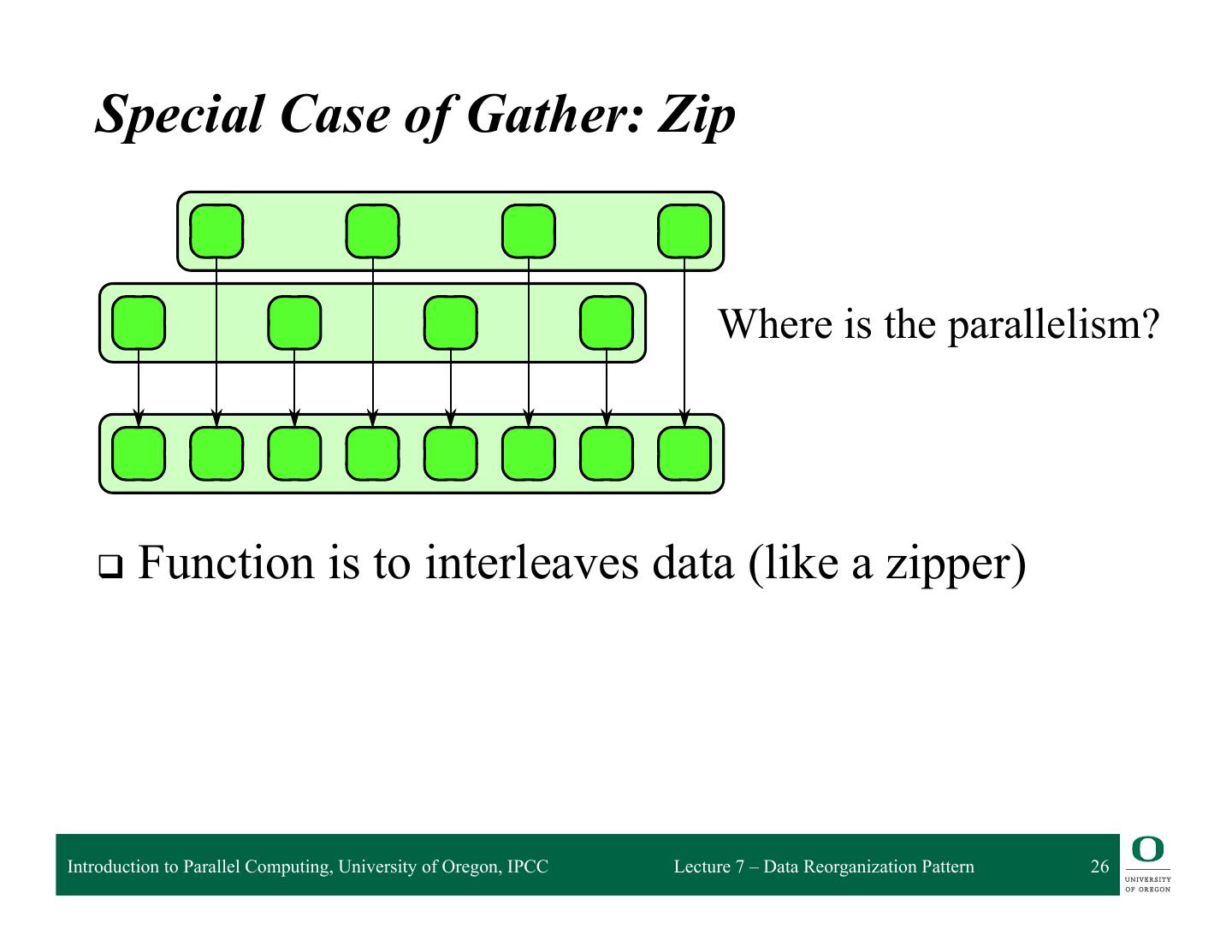
26 .Boundaries can be duplicated, rotated, reflected, a default value can be used, or most genera function can be used. Unlike a general gather, however, shifts can be efficiently implemented instructions since in the interior, the data access pattern is regular. Special Case of Gather: Zip Where is the parallelism? FIGURE 6.3 q Function is to interleaves data (like a zipper) Zip and unzip (special cases of gather). These operations can be used to convert between arr (AoS) and structure of arrays (SoA) data layouts. Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 26
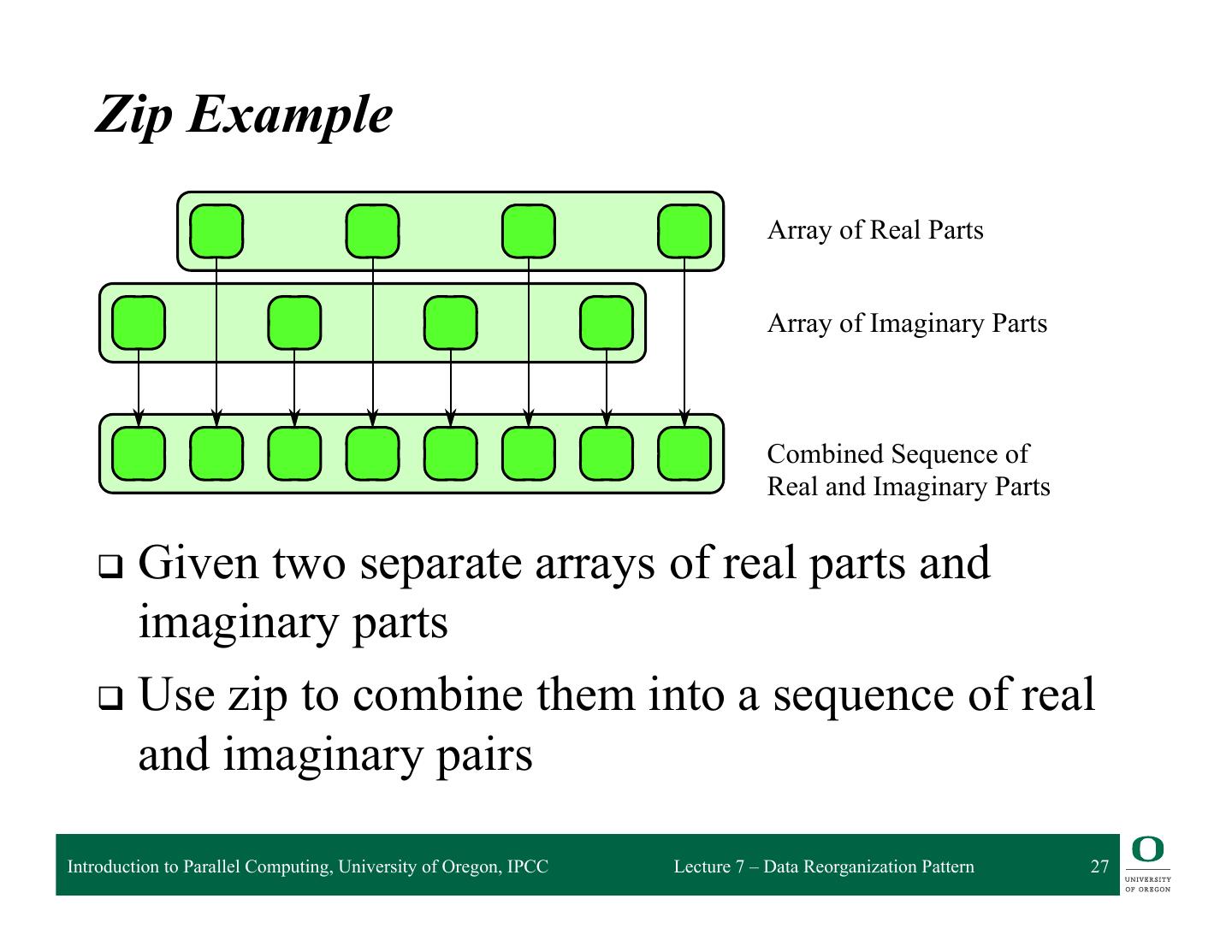
27 .Boundaries can be duplicated, rotated, reflected, a default value can be used, or most genera function can be used. Unlike a general gather, however, shifts can be efficiently implemented instructions since in the interior, the data access pattern is regular. Zip Example Array of Real Parts Array of Imaginary Parts Combined Sequence of Real and Imaginary Parts FIGURE 6.3 q Given two separate arrays of real parts and Zip and unzip (special cases of gather). These operations can be used to convert between arr imaginary (AoS) and parts structure of arrays (SoA) data layouts. q Use zip to combine them into a sequence of real and imaginary pairs Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 27
28 . More about Zip q Can be generalized to more elements q Can zip data of unlike types Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 28
29 . Table of Contents q Gather Pattern ❍ Shifts, Zip, Unzip q Scatter Pattern ❍ Collision Rules: atomic, permutation, merge, priority q Pack Pattern ❍ Split, Unsplit, Bin ❍ Fusing Map and Pack ❍ Expand q Partitioning Data q AoS vs. SoA q Example Implementation: AoS vs. SoA Introduction to Parallel Computing, University of Oregon, IPCC Lecture 7 – Data Reorganization Pattern 29
3秒后跳转登录页面
去登陆

