














- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
12 Resource Allocation and Scheduling #2
Resource Allocation and Scheduling #2
Composing Parallel Software Efficiently with Lithe
Dominant Resource Fairness: Fair Allocation of Multiple Resource Types
展开查看详情
1 . Today’s Papers EECS 262a • Composing Parallel Software Efficiently with Lithe Heidi Pan, Benjamin Hindman, Krste Asanovic. Appears in Conference Advanced Topics in Computer Systems on Programming Languages Design and Implementation (PLDI), 2010 Lecture 13 • Dominant Resource Fairness: Fair Allocation of Multiple Resources Types, A. Ghodsi, M. Zaharia, B. Hindman, A. Konwinski, S. Shenker, and I. Stoica, Usenix NSDI 2011, Boston, MA, March 2011 Resource allocation: Lithe/DRF October 2nd, 2018 • Thoughts? John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs262 10/02/2018 cs262a-F18 Lecture-12 2 The Future is Parallel Software Composability is Essential Challenge: How to build many different large parallel apps that run well? Can’t rely solely on compiler/hardware: limited parallelism & energy efficiency App 1 App 2 App Can’t rely solely on hand-tuning: limited programmer productivity BLAS BLAS MKL Goto BLAS BLAS code reuse modularity same library implementation, different apps same app, different library implementations Composability is key to building large, complex apps. 10/02/2018 cs262a-F18 Lecture-12 3 10/02/2018 cs262a-F18 Lecture-12 4
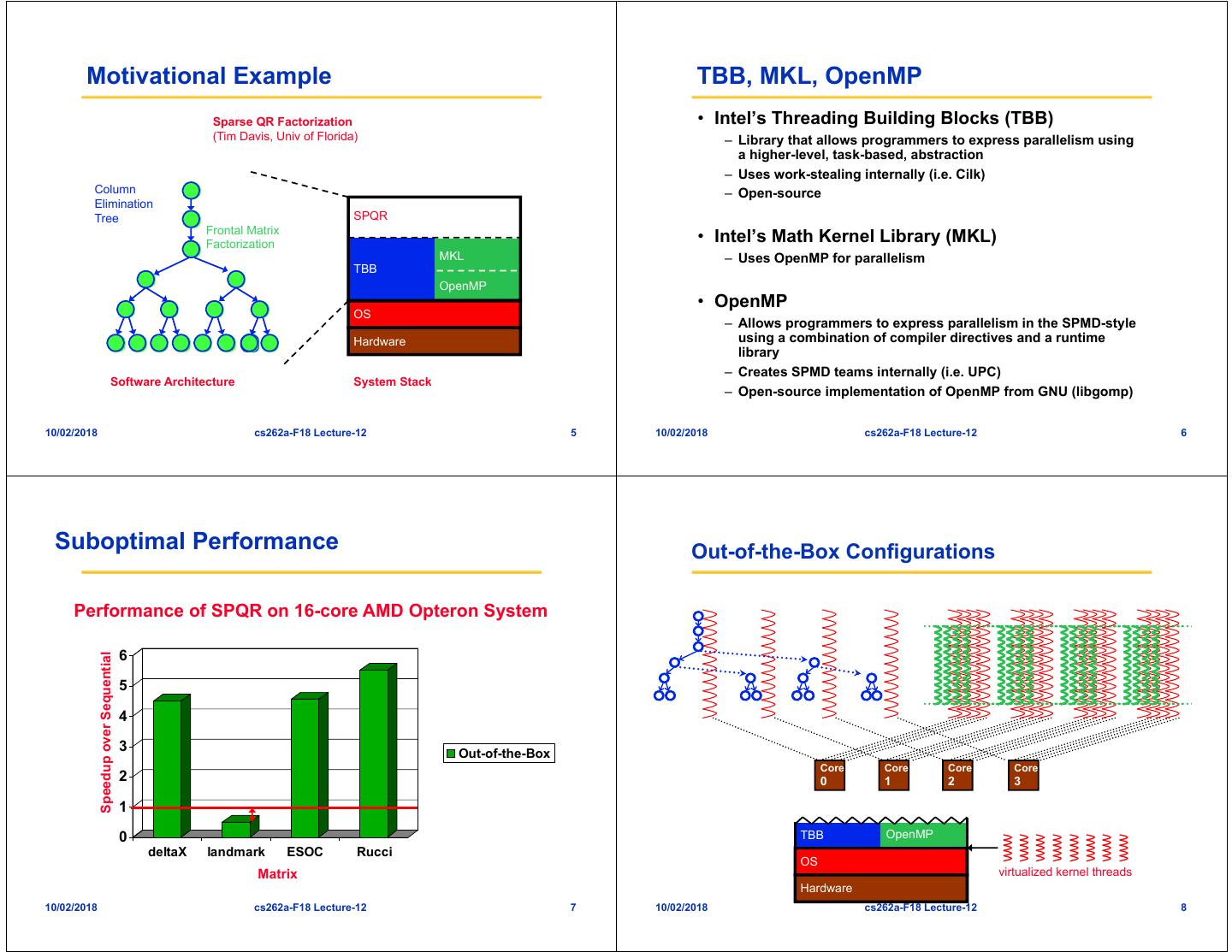
2 . Motivational Example TBB, MKL, OpenMP Sparse QR Factorization • Intel’s Threading Building Blocks (TBB) (Tim Davis, Univ of Florida) – Library that allows programmers to express parallelism using a higher-level, task-based, abstraction – Uses work-stealing internally (i.e. Cilk) Column – Open-source Elimination Tree SPQR Frontal Matrix Factorization • Intel’s Math Kernel Library (MKL) MKL – Uses OpenMP for parallelism TBB OpenMP • OpenMP OS – Allows programmers to express parallelism in the SPMD-style Hardware using a combination of compiler directives and a runtime library – Creates SPMD teams internally (i.e. UPC) Software Architecture System Stack – Open-source implementation of OpenMP from GNU (libgomp) 10/02/2018 cs262a-F18 Lecture-12 5 10/02/2018 cs262a-F18 Lecture-12 6 Suboptimal Performance Out-of-the-Box Configurations Performance of SPQR on 16-core AMD Opteron System 6 Speedup over Sequential 5 4 3 Out-of-the-Box Core Core Core Core 2 0 1 2 3 1 0 TBB OpenMP deltaX landmark ESOC Rucci OS Matrix virtualized kernel threads Hardware 10/02/2018 cs262a-F18 Lecture-12 7 10/02/2018 cs262a-F18 Lecture-12 8
3 . Providing Performance Isolation “Tuning” the Code Using Intel MKL with Threaded Applications http://www.intel.com/support/performancetools/libraries/mkl/sb/CS-017177.htm Performance of SPQR on 16-core AMD Opteron System 6 Speedup over Sequential 5 4 3 Out-of-the-Box Serial MKL 2 1 0 deltaX landmark ESOC Rucci Matrix 10/02/2018 cs262a-F18 Lecture-12 9 10/02/2018 cs262a-F18 Lecture-12 10 Partition Resources “Tuning” the Code (continued) Performance of SPQR on 16-core AMD Opteron System 6 Speedup over Sequential 5 Core Core Core Core 4 0 1 2 3 Out-of-the-Box 3 Serial MKL 2 Tuned TBB OpenMP OS 1 Hardware 0 deltaX landmark ESOC Rucci Tim Davis’ “tuned” SPQR by manually partitioning the resources. Matrix 10/02/2018 cs262a-F18 Lecture-12 11 10/02/2018 cs262a-F18 Lecture-12 12
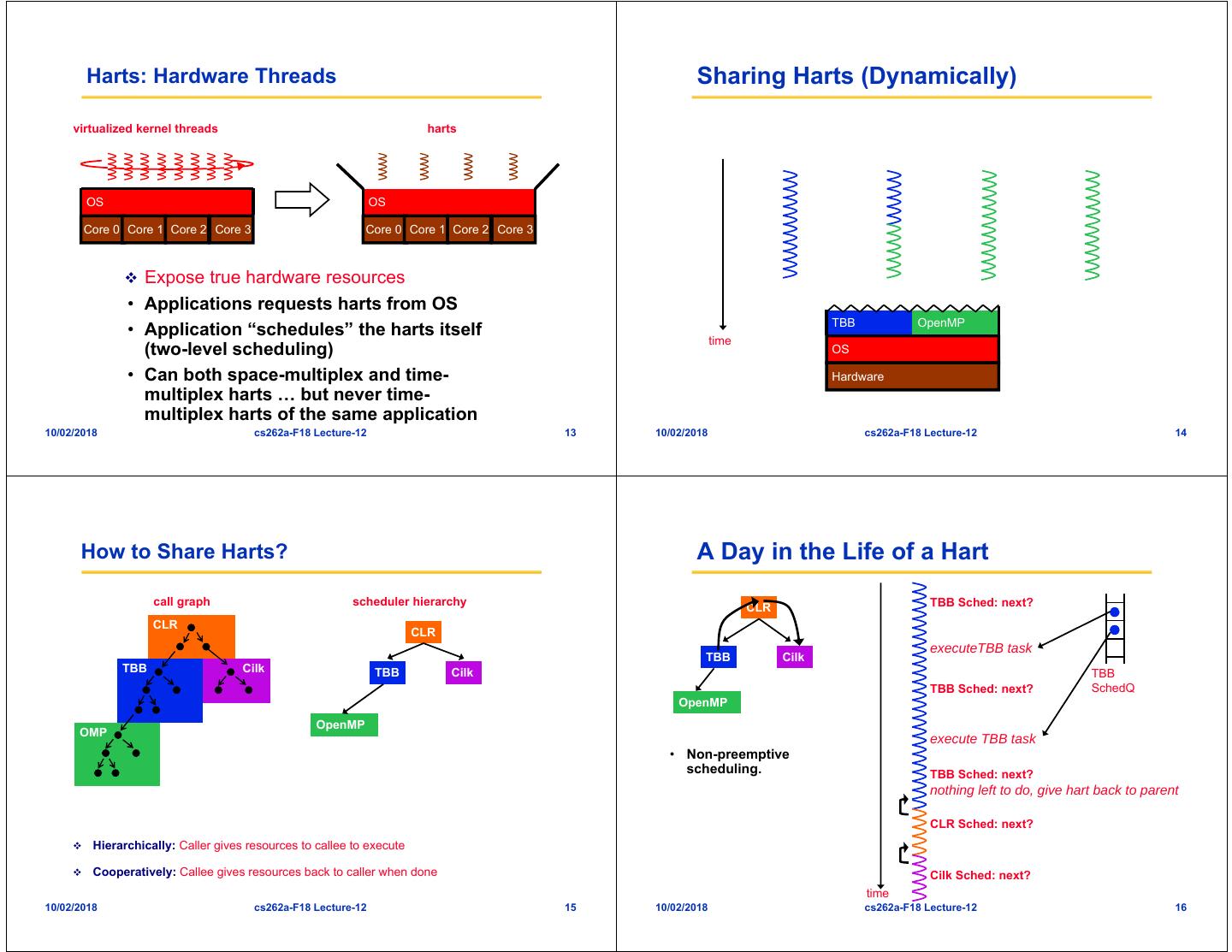
4 . Harts: Hardware Threads Sharing Harts (Dynamically) virtualized kernel threads harts OS OS Core 0 Core 1 Core 2 Core 3 Core 0 Core 1 Core 2 Core 3 Expose true hardware resources • Applications requests harts from OS TBB OpenMP • Application “schedules” the harts itself time (two-level scheduling) OS • Can both space-multiplex and time- Hardware multiplex harts … but never time- multiplex harts of the same application 10/02/2018 cs262a-F18 Lecture-12 13 10/02/2018 cs262a-F18 Lecture-12 14 How to Share Harts? A Day in the Life of a Hart call graph scheduler hierarchy TBB Sched: next? CLR CLR CLR executeTBB task TBB Cilk TBB Cilk TBB Cilk TBB TBB Sched: next? SchedQ OpenMP OpenMP OMP execute TBB task • Non-preemptive scheduling. TBB Sched: next? nothing left to do, give hart back to parent CLR Sched: next? Hierarchically: Caller gives resources to callee to execute Cooperatively: Callee gives resources back to caller when done Cilk Sched: next? time 10/02/2018 cs262a-F18 Lecture-12 15 10/02/2018 cs262a-F18 Lecture-12 16
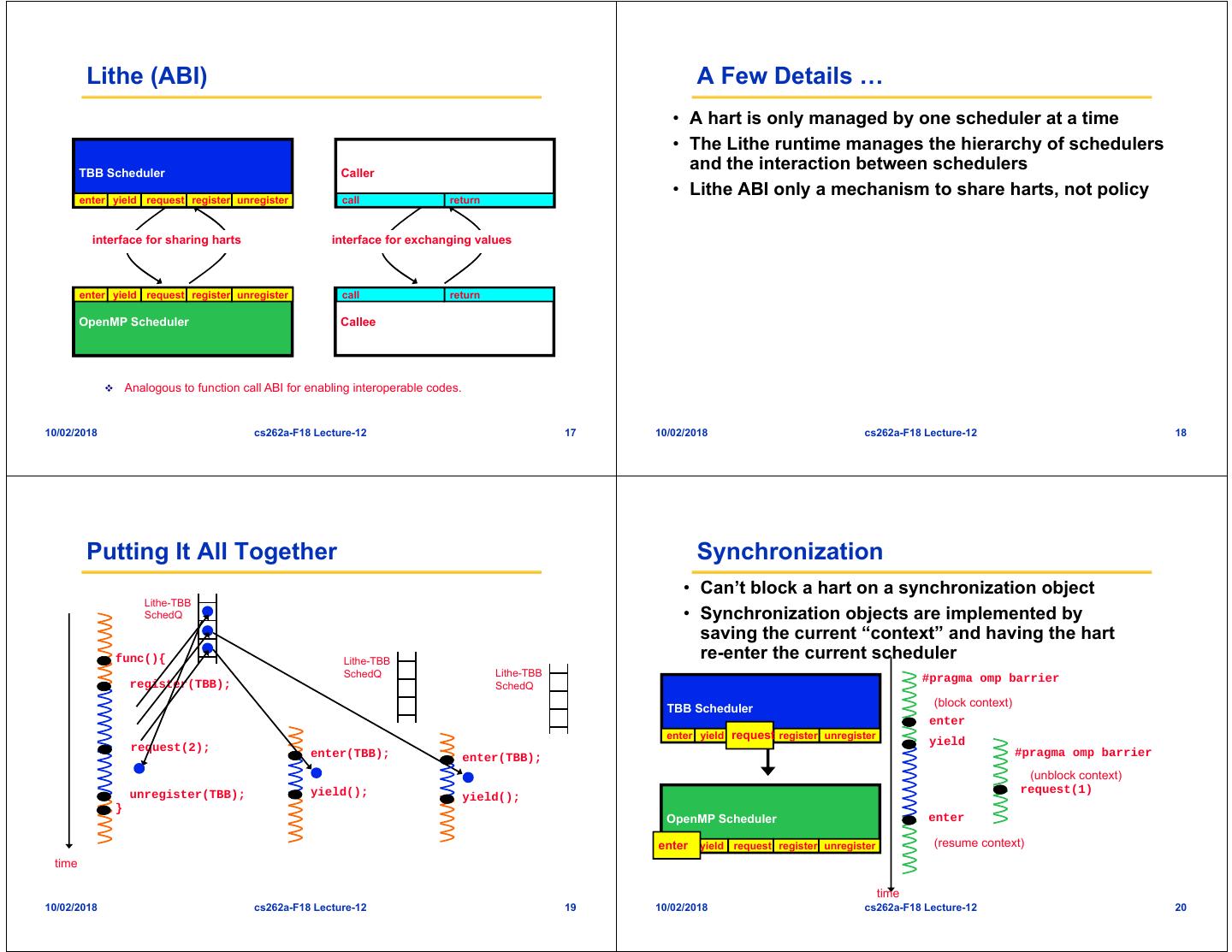
5 . Lithe (ABI) A Few Details … • A hart is only managed by one scheduler at a time • The Lithe runtime manages the hierarchy of schedulers Parent Cilk TBB Scheduler Scheduler Scheduler Caller and the interaction between schedulers enter yield request register unregister call return • Lithe ABI only a mechanism to share harts, not policy interface for sharing harts interface for exchanging values enter yield request register unregister call return Child TBB OpenMP Scheduler Scheduler Scheduler Callee Analogous to function call ABI for enabling interoperable codes. 10/02/2018 cs262a-F18 Lecture-12 17 10/02/2018 cs262a-F18 Lecture-12 18 Putting It All Together Synchronization • Can’t block a hart on a synchronization object Lithe-TBB SchedQ • Synchronization objects are implemented by saving the current “context” and having the hart func(){ Lithe-TBB re-enter the current scheduler SchedQ Lithe-TBB #pragma omp barrier register(TBB); SchedQ TBB Scheduler (block context) enter enter yield request request register unregister request(2); yield enter(TBB); enter(TBB); #pragma omp barrier (unblock context) unregister(TBB); yield(); request(1) yield(); } OpenMP Scheduler enter enter enter yield request register unregister (resume context) time time 10/02/2018 cs262a-F18 Lecture-12 19 10/02/2018 cs262a-F18 Lecture-12 20
6 . Lithe Contexts Lithe-compliant Schedulers • Includes notion of a stack • TBB • Includes context-local storage – Worker model – ~180 lines added, ~5 removed, ~70 modified (~1,500 / ~8,000 • There is a special transition context for each hart total) that allows it to transition between schedulers easily (i.e. on an enter, yield) • OpenMP – Team model – ~220 lines added, ~35 removed, ~150 modified (~1,000 / ~6,000 total) 10/02/2018 cs262a-F18 Lecture-12 21 10/02/2018 cs262a-F18 Lecture-12 22 Overheads? Flickr Application Server • TBB – Example micro-benchmarks that Intel includes with releases • GraphicsMagick parallelized using OpenMP • Server component parallelized using threads (or libprocess processes) • Spectrum of possible implementations: – Process one image upload at a time, pass all resources to OpenMP (via GraphicsMagick) + Easy implementation - Can’t overlap communication with computation, some network links are slow, images are different sizes, diminishing returns on resize operations • OpenMP – Process as many images as possible at a time, run GraphicsMagick – NAS benchmarks (conjugate gradient, LU solver, and sequentially multigrid) + Also easy implementation - Really bad latency when low-load on server, 32 core machine underwhelmed – All points in between … + Account for changing load, different image sizes, different link bandwidth/latency - Hard to program 10/02/2018 cs262a-F18 Lecture-12 23 10/02/2018 cs262a-F18 Lecture-12 24
7 . Flickr-Like App Server Case Study: Sparse QR Factorization • Different matrix sizes App Server Graphics • deltaX creates ~30,000 OpenMP schedulers Magick Libprocess • … OpenMPLithe (Lithe) • Rucci creates ~180,000 OpenMP schedulers • Platform: Dual-socket 2.66 GHz Tradeoff between throughput saturation point and latency. Intel Xeon (Clovertown) with 4 cores per socket (8 total cores) 25 10/02/2018 cs262a-F18 Lecture-12 25 10/02/2018 cs262a-F18 Lecture-12 26 Case Study: Sparse QR Factorization Case Study: Sparse QR Factorization ESOC Rucci deltaX landmark Tuned: 70.8 Tuned: 360.0 Tuned: 14.5 Tuned: 2.5 Out-of-the-box: 111.8 Out-of-the-box: 576.9 Out-of-the-box: 26.8 Out-of-the-box: 4.1 Sequential: 172.1 Sequential: 970.5 Sequential: 37.9 Sequential: 3.4 Lithe: 66.7 Lithe: 354.7 Lithe: 13.6 Lithe: 2.3 10/02/2018 cs262a-F18 Lecture-12 27 10/02/2018 cs262a-F18 Lecture-12 28
8 . Is this a good paper? Break • What were the authors’ goals? • What about the evaluation/metrics? • Did they convince you that this was a good system/approach? • Were there any red-flags? • What mistakes did they make? • Does the system/approach meet the “Test of Time” challenge? • How would you review this paper today? 10/02/2018 cs262a-F18 Lecture-12 29 10/02/2018 cs262a-F18 Lecture-12 30 CPU 100% What is Fair Sharing? 33% Why is Fair Sharing Useful? • n users want to share a resource (e.g., CPU) 50% 33% – Solution: • Weighted Fair Sharing / Proportional Shares Allocate each 1/n of the shared resource 33% 100% 0% – User 1 gets weight 2, user 2 weight 1 100% 66 20% • Generalized by max-min fairness • Priorities 50% % – Handles if a user wants less than its fair share 40 – Give user 1 weight 1000, user 2 weight 1 50% % 33 – E.g. user 1 wants no more than 20% % 0% 40 • Revervations CPU % • Generalized by weighted max-min fairness 0% – Ensure user 1 gets 10% of a resource 100% 10 100% % – Give weights to users according to importance – Give user 1 weight 10, sum weights ≤ 100 33% 50 – User 1 gets weight 1, user 2 weight 2 50% % 50% • Isolation Policy 66% 40 – Users cannot affect others beyond their fair share % 0% CPU 0% 10/02/2018 cs262a-F18 Lecture-12 31 10/02/2018 cs262a-F18 Lecture-12 32
9 . Properties of Max-Min Fairness Why Care about Fairness? • Share guarantee – Each user can get at least 1/n of the resource • Desirable properties of max-min fairness – But will get less if her demand is less – Isolation policy: A user gets her fair share irrespective of the demands of other users • Strategy-proof – Flexibility separates mechanism from policy: – Users are not better off by asking for more than they need Proportional sharing, priority, reservation,... – Users have no reason to lie • Many schedulers use max-min fairness – Datacenters: Hadoop’s fair sched, capacity, Quincy – OS: rr, prop sharing, lottery, linux cfs, ... • Max-min fairness is the only “reasonable” – Networking: wfq, wf2q, sfq, drr, csfq, ... mechanism with these two properties 10/02/2018 cs262a-F18 Lecture-12 33 10/02/2018 cs262a-F18 Lecture-12 34 When is Max-Min Fairness not Enough? Heterogeneous Resource Demands • Need to schedule multiple, heterogeneous resources – Example: Task scheduling in datacenters Some tasks are » Tasks consume more than just CPU – CPU, memory, disk, and I/O CPU-intensive • What are today’s datacenter task demands? Most task need ~ Some tasks are <2 CPU, 2 GB memory-intensive RAM> 2000-node Hadoop Cluster at Facebook (Oct 2010) 10/02/2018 cs262a-F18 Lecture-12 35 10/02/2018 cs262a-F18 Lecture-12 36
10 . Problem 100% Single resource example 50 % – 1 resource: CPU 50% Problem definition – User 1 wants <1 CPU> per task – User 2 wants <3 CPU> per task 50 % How to fairly share multiple resources when users 0% have heterogeneous demands on them? CPU 100% Multi-resource example – 2 resources: CPUs & memory – User 1 wants <1 CPU, 4 GB> per task – User 2 wants <3 CPU, 1 GB> per task 50% ? – ? What is a fair allocation? 0% CPU mem 10/02/2018 cs262a-F18 Lecture-12 37 10/02/2018 cs262a-F18 Lecture-12 38 Model What is Fair? • Goal: define a fair allocation of multiple cluster • Users have tasks according to a demand vector resources between multiple users – e.g. <2, 3, 1> user’s tasks need 2 R1, 3 R2, 1 R3 • Example: suppose we have: – Not needed in practice, can simply measure actual consumption – 30 CPUs and 30 GB RAM – Two users with equal shares • Resources given in multiples of demand vectors – User 1 needs <1 CPU, 1 GB RAM> per task – User 2 needs <1 CPU, 3 GB RAM> per task • Assume divisible resources • What is a fair allocation? 10/02/2018 cs262a-F18 Lecture-12 39 10/02/2018 cs262a-F18 Lecture-12 40
11 . First Try: Asset Fairness Lessons from Asset Fairness “You shouldn’t do worse than if you ran a smaller, • Asset Fairness private cluster equal in size to your fair share” – Equalize each user’s sum of resource shares User 1 User 2 Thus, given N users, each user should get ≥ 1/N of Problem her dominating resource (i.e., the resource that she • Cluster with 70 CPUs, 70 GB RAM 100% User 1 has < 50% of both CPUs and RAM consumes most of) – U1 needs <2 CPU, 2 GB RAM> per task 43% 43% – needs U2 in Better off <1 CPU, a separate 2 GBwith cluster RAM> per 50% of task the 50% resources 57% • Asset fairness yields 28% – U1: 15 tasks: 30 CPUs, 30 GB (∑=60) 0% – U2: 20 tasks: 20 CPUs, 40 GB (∑=60) CPU RAM 10/02/2018 cs262a-F18 Lecture-12 41 10/02/2018 cs262a-F18 Lecture-12 42 Desirable Fair Sharing Properties Cheating the Scheduler • Many desirable properties • Some users will game the system to get more resources – Share Guarantee – Strategy proofness – Envy-freeness DRF focuses on • Real-life examples – Pareto efficiency these properties – A cloud provider had quotas on map and reduce slots – Single-resource fairness Some users found out that the map-quota was low – Bottleneck fairness » Users implemented maps in the reduce slots! – Population monotonicity – Resource monotonicity – A search company provided dedicated machines to users that could ensure certain level of utilization (e.g. 80%) » Users used busy-loops to inflate utilization 10/02/2018 cs262a-F18 Lecture-12 43 10/02/2018 cs262a-F18 Lecture-12 44
12 . Two Important Properties Challenge • Strategy-proofness – A user should not be able to increase her allocation by lying about • A fair sharing policy that provides her demand vector – Strategy-proofness – Intuition: – Share guarantee » Users are incentivized to make truthful resource requirements • Max-min fairness for a single resource had these properties • Envy-freeness – Generalize max-min fairness to multiple resources – No user would ever strictly prefer another user’s lot in an allocation – Intuition: » Don’t want to trade places with any other user 10/02/2018 cs262a-F18 Lecture-12 45 10/02/2018 cs262a-F18 Lecture-12 46 Dominant Resource Fairness Dominant Resource Fairness (2) • A user’s dominant resource is the resource she has • Apply max-min fairness to dominant shares the biggest share of • Equalize the dominant share of the users – Example: Total resources: <10 CPU, 4 GB> – Example: User 1’s allocation: <2 CPU, 1 GB> Total resources: <9 CPU, 18 GB> Dominant resource is memory as 1/4 > 2/10 (1/5) User 1 demand: <1 CPU, 4 GB> dominant res: mem User 2 demand: <3 CPU, 1 GB> dominant res: CPU • A user’s dominant share is the fraction of the 100% 3 CPUs 12 GB User 1 dominant resource she is allocated User 2 – User 1’s dominant share is 25% (1/4) 66% 50% 66% 6 CPUs 2 GB 0% CPU mem (9 total) (18 total) 10/02/2018 cs262a-F18 Lecture-12 47 10/02/2018 cs262a-F18 Lecture-12 48
13 . DRF is Fair Online DRF Scheduler • DRF is strategy-proof • DRF satisfies the share guarantee Whenever there are available resources and tasks to run: • DRF allocations are envy-free Schedule a task to the user with smallest dominant share See DRF paper for proofs • O(log n) time per decision using binary heaps • Need to determine demand vectors 10/02/2018 cs262a-F18 Lecture-12 49 10/02/2018 cs262a-F18 Lecture-12 50 Alternative: Use an Economic Model Determining Demand Vectors • Approach • They can be measured – Set prices for each good – Look at actual resource consumption of a user – Let users buy what they want • They can be provided the by user • How do we determine the right prices for different goods? – What is done today • Let the market determine the prices • In both cases, strategy-proofness incentivizes user to consume resources wisely • Competitive Equilibrium from Equal Incomes (CEEI) – Give each user 1/n of every resource – Let users trade in a perfectly competitive market • Not strategy-proof! 10/02/2018 cs262a-F18 Lecture-12 51 10/02/2018 cs262a-F18 Lecture-12 52
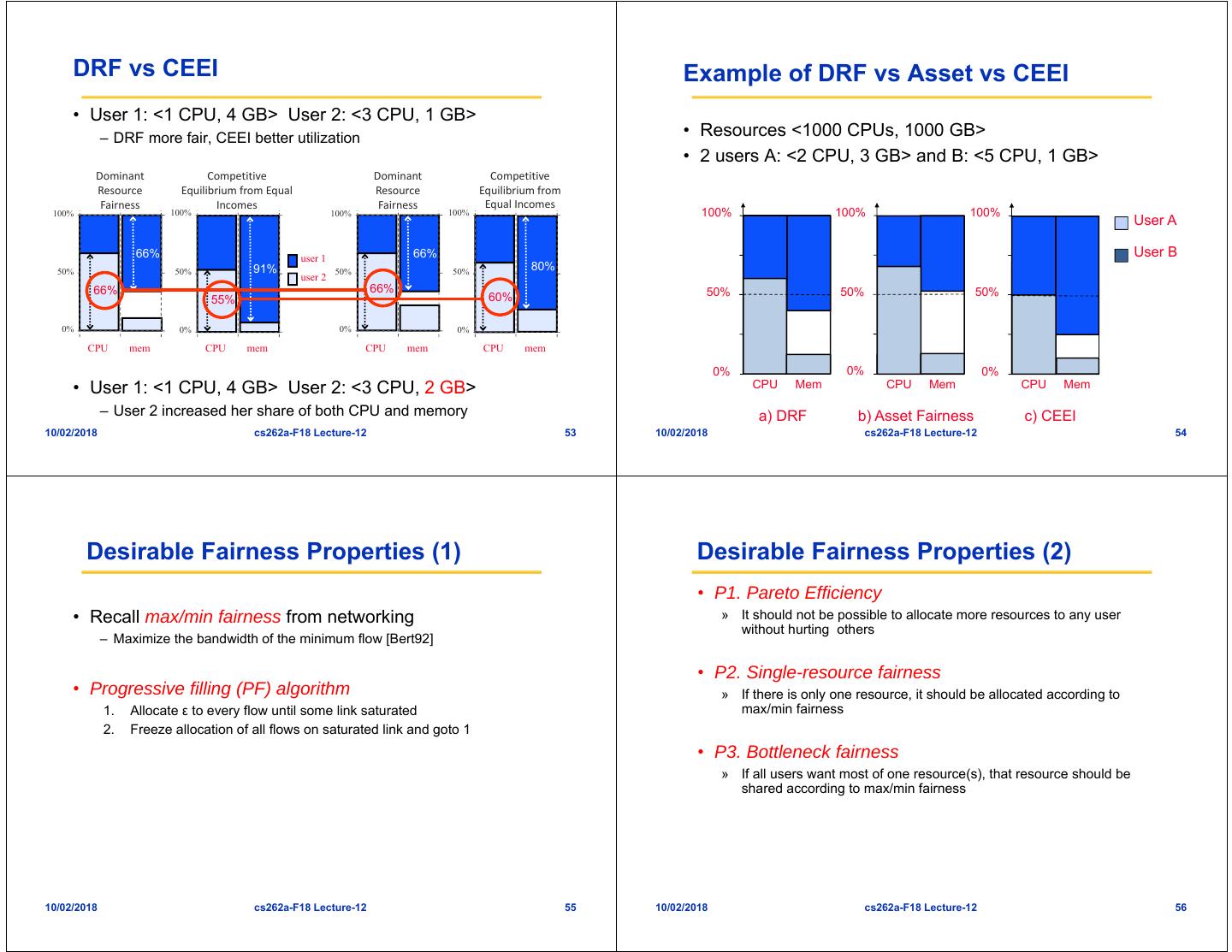
14 . DRF vs CEEI Example of DRF vs Asset vs CEEI • User 1: <1 CPU, 4 GB> User 2: <3 CPU, 1 GB> – DRF more fair, CEEI better utilization • Resources <1000 CPUs, 1000 GB> • 2 users A: <2 CPU, 3 GB> and B: <5 CPU, 1 GB> Dominant Competitive Dominant Competitive Resource Equilibrium from Equal Resource Equilibrium from Fairness Incomes Fairness Equal Incomes 100% 100% 100% 100% 100% 100% 100% User A 66% user 1 66% User B 50% 50% 91% 50% 50% 80% user 2 66% 66% 50% 50% 50% 55% 60% 0% 0% 0% 0% CPU mem CPU mem CPU mem CPU mem 0% 0% 0% • User 1: <1 CPU, 4 GB> User 2: <3 CPU, 2 GB> CPU Mem CPU Mem CPU Mem – User 2 increased her share of both CPU and memory a) DRF b) Asset Fairness c) CEEI 10/02/2018 cs262a-F18 Lecture-12 53 10/02/2018 cs262a-F18 Lecture-12 54 Desirable Fairness Properties (1) Desirable Fairness Properties (2) • P1. Pareto Efficiency • Recall max/min fairness from networking » It should not be possible to allocate more resources to any user without hurting others – Maximize the bandwidth of the minimum flow [Bert92] • P2. Single-resource fairness • Progressive filling (PF) algorithm » If there is only one resource, it should be allocated according to 1. Allocate ε to every flow until some link saturated max/min fairness 2. Freeze allocation of all flows on saturated link and goto 1 • P3. Bottleneck fairness » If all users want most of one resource(s), that resource should be shared according to max/min fairness 10/02/2018 cs262a-F18 Lecture-12 55 10/02/2018 cs262a-F18 Lecture-12 56
15 . Desirable Fairness Properties (3) Desirable Fairness Properties (4) • P4. Population Monotonicity • Assume positive demands (Dij > 0 for all i and j) – If a user leaves and relinquishes her resources, no other user’s allocation should get hurt • DRF will allocate same dominant share to all users – Can happen each time a job finishes – As soon as PF saturates a resource, allocation frozen • CEEI violates population monotonicity • DRF satisfies population monotonicity – Assuming positive demands – Intuitively DRF gives the same dominant share to all users, so all users would be hurt contradicting Pareto efficiency 10/02/2018 cs262a-F18 Lecture-12 57 10/02/2018 cs262a-F18 Lecture-12 58 Properties of Policies Evaluation Methodology Property Asset CEEI DRF • Micro-experiments on EC2 Share guarantee ✔ ✔ – Evaluate DRF’s dynamic behavior when demands Strategy-proofness ✔ ✔ change Pareto efficiency ✔ ✔ ✔ – Compare DRF with current Hadoop scheduler Envy-freeness ✔ ✔ ✔ Single resource fairness ✔ ✔ ✔ • Macro-benchmark through simulations Bottleneck res. fairness ✔ ✔ Population monotonicity ✔ ✔ – Simulate Facebook trace with DRF and current Hadoop scheduler Resource monotonicity 10/02/2018 cs262a-F18 Lecture-12 59 10/02/2018 cs262a-F18 Lecture-12 60
16 . DRF Inside Mesos on EC2 Fairness in Today’s Datacenters Dominant resource Dominant resource is CPU is memory User 1’s Shares • Hadoop Fair Scheduler/capacity/Quincy – Each machine consists of k slots (e.g. k=14) <1 CPU, 10 GB> – Run at most one task per slot <2 CPU, 4 GB> – Give jobs ”equal” number of slots, i.e., apply max-min fairness to slot-count Dominant resource is CPU User 2’s Shares • This is what DRF paper compares against <1 CPU, 1 GB> <1 CPU, 3 GB> Dominant shares are equalized Dominant Shares Share guarantee: Share guarantee: ~70% dominant 61 ~50% dominant 10/02/2018 share cs262a-F18 Lecture-12 share 61 10/02/2018 cs262a-F18 Lecture-12 62 Experiment: DRF vs Slots Experiment: DRF vs Slots Number of Type 1 Jobs Finished Completion Time of Type 1 Jobs Job completion Thrashing time Thrashing finished Jobs Number of Type 2 Jobs Finished Completion Time of Type 2 Jobs Job completion Low utilization hurts Low utilization performance Thrashing Thrashing time finished Jobs Type 1 jobs <2 CPU, 2 GB> Type 2 jobs <1 CPU, 0.5GB> 10/02/2018 cs262a-F18 Lecture-12 63 10/02/2018 Type 1 job <2 CPU, 2 GB> Lecture-12 cs262a-F18 Type 2 job <1 CPU, 0.5GB> 64
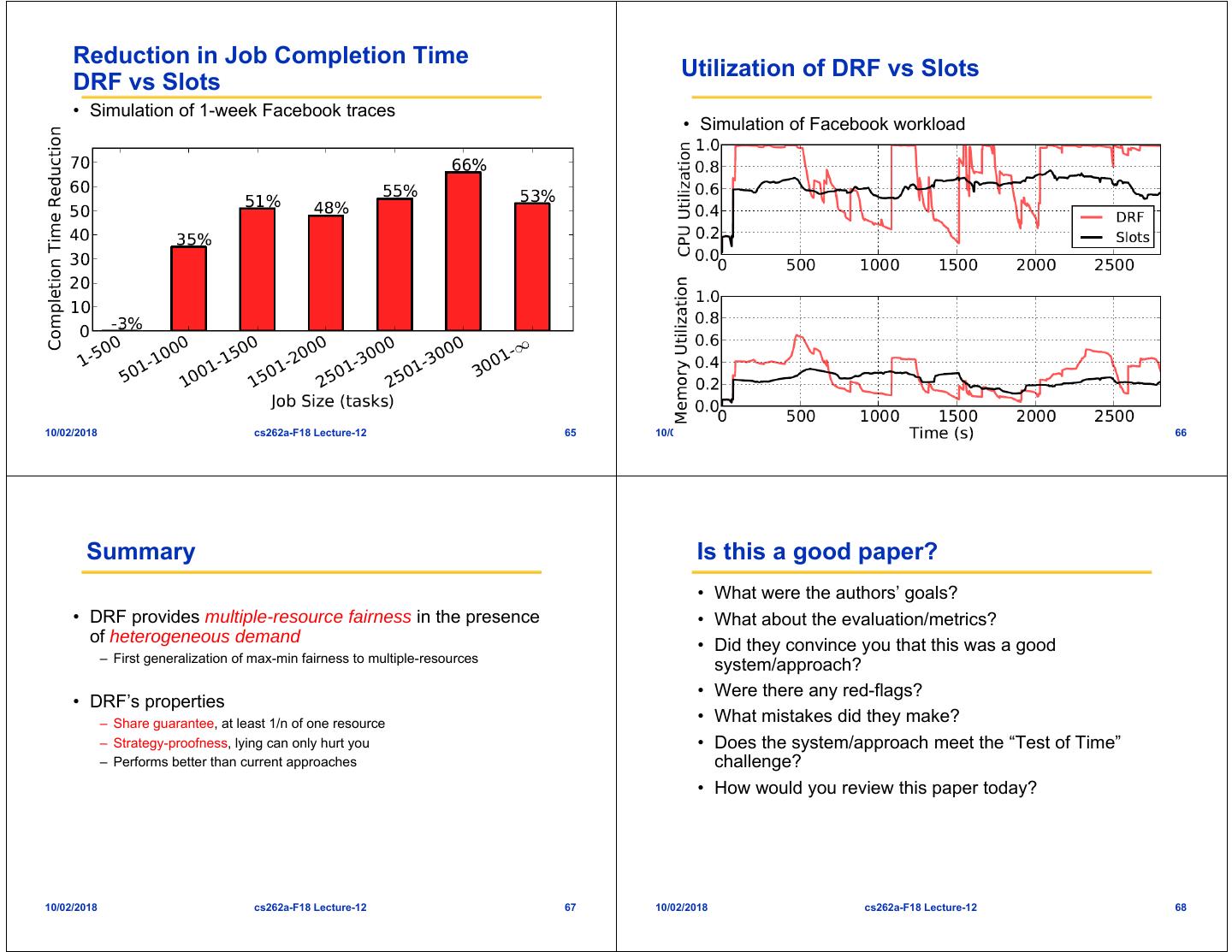
17 . Reduction in Job Completion Time Utilization of DRF vs Slots DRF vs Slots • Simulation of 1-week Facebook traces • Simulation of Facebook workload alig@cs.berkeley.edu 66 10/02/2018 cs262a-F18 Lecture-12 65 10/02/2018 cs262a-F18 Lecture-12 66 Summary Is this a good paper? • What were the authors’ goals? • DRF provides multiple-resource fairness in the presence • What about the evaluation/metrics? of heterogeneous demand • Did they convince you that this was a good – First generalization of max-min fairness to multiple-resources system/approach? • Were there any red-flags? • DRF’s properties – Share guarantee, at least 1/n of one resource • What mistakes did they make? – Strategy-proofness, lying can only hurt you • Does the system/approach meet the “Test of Time” – Performs better than current approaches challenge? • How would you review this paper today? 10/02/2018 cs262a-F18 Lecture-12 67 10/02/2018 cs262a-F18 Lecture-12 68
3秒后跳转登录页面
去登陆

