














- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
02 Introduction to Databases, System R
Introduction to Databases, System R
End-To-End Arguments in System Design
A History and Evaluation of System R [Annotated version]
展开查看详情
1 . Today’s Papers EECS 262a • End-To-End Arguments in System Design J. H. Saltzer, D. P. Reed, D. D. Clark. Appears in ACM Transactions on Advanced Topics in Computer Systems Computer Systems,Vol 2, No. 4, November 1984, pp 277-288. Lecture 2 • A History and Evaluation of System R Donald D. Chamberlin, Morton A. Astrahan, Michael W. Blasgen, James N. Gray, W. Frank King, Bruce G. Lindsay, Raymond Lorie, James W. Mehl, Thomas G. Price, Franco Putzolu, Patricia Griffiths End-to-End / System R Selinger, Mario Schkolnick, Donald R. Slutz, Irving L. Traiger, Bradford W. Wade and Robert A. Yost. Appears in Communications of the ACM, August 28th, 2018 Vol 24, No. 10, October 1981, pp 632-646 John Kubiatowicz • Both papers represented significant (controversial) Electrical Engineering and Computer Sciences paradigm shifts University of California, Berkeley • Changing the design elements http://www.eecs.berkeley.edu/~kubitron/cs262 – E2E: Where to place functionality – System R: Data independence from physical representation • Contrasting top-down vs. bottom-up views 8/28/2018 cs262a-F18h Lecture-02 2 The Internet Hourglass Implications of Hourglass Single Internet-layer module (IP): SMTP HTTP DNS NTP Applications • Allows arbitrary networks to interoperate – Any network technology that supports IP can exchange packets TCP UDP Transport • Allows applications to function on all networks – Applications that can run on IP can use any network Waist IP • Supports simultaneous innovations above and below IP Data Link – But changing IP itself, i.e., IPv6, very involved (IPng proposed in 9/93) Ethernet SONET 802.11 Physical Copper Fiber Radio The Hourglass Model There is just one network-layer protocol, IP. The “narrow waist” facilitates interoperability. 8/28/2018 cs262a-F18h Lecture-02 3 8/28/2018 cs262a-F18h Lecture-02 4
2 . Drawbacks of Layering Placing Network Functionality • Layer N may duplicate layer N-1 functionality • Hugely influential paper: “End-to-End Arguments in – E.g., error recovery to retransmit lost data System Design” by Saltzer, Reed, and Clark (‘84) • Layers may need same information – E.g., timestamps, maximum transmission unit size • “Sacred Text” of the Internet • Layering can hurt performance – Endless disputes about what it means – E.g., hiding details about what is really going on – Everyone cites it as supporting their position • Some layers are not always cleanly separated – Inter-layer dependencies for performance reasons – Some dependencies in standards (header checksums) • Headers start to get really big – Sometimes header bytes >> actual content 8/28/2018 cs262a-F18h Lecture-02 5 8/28/2018 cs262a-F18h Lecture-02 6 Basic Observation Example: Reliable File Transfer • Some types of network functionality can only be correctly implemented end-to-end Host A Host B – Reliability, security, etc Appl. Appl. • Because of this, end hosts: OS OS OK – Can satisfy the requirement without network’s help – Will/must do so, since can’t rely on network’s help • Solution 1: make each step reliable, and then • Therefore don’t go out of your way to implement concatenate them them in the network • Solution 2: end-to-end check and try again if necessary 8/28/2018 cs262a-F18h Lecture-02 7 8/28/2018 cs262a-F18h Lecture-02 8
3 . Discussion End-to-End Principle • Solution 1 is incomplete Implementing this functionality in the network: – What happens if memory is corrupted? • Doesn’t reduce host implementation complexity – Receiver has to do the check anyway! • Does increase network complexity • Probably imposes delay and overhead on all • Solution 2 is complete applications, even if they don’t need functionality – Full functionality can be entirely implemented at application layer with no need for reliability from lower layers • However, implementing in network can enhance performance in some cases • Is there any need to implement reliability at lower layers? – E.g., very lossy links such as wireless – Well, it could be more efficient or more problematic • It may also help mitigate denial of service and/or privacy 8/28/2018 cs262a-F18h Lecture-02 9 8/28/2018 cs262a-F18h Lecture-02 10 Conservative Interpretation of E2E Moderate Interpretation • Don’t implement a function at the lower levels of the system • Think twice before implementing functionality in the unless it can be completely implemented at this level network • Unless you can relieve the burden from hosts, don’t bother • If hosts can implement functionality correctly, implement it in a lower layer only as a performance enhancement • But do so only if it does not impose burden on applications that do not require that functionality • This is the interpretation I use 8/28/2018 cs262a-F18h Lecture-02 11 8/28/2018 cs262a-F18h Lecture-02 12
4 . Research Example Live Video Streaming over Cellular • Goal: Flexible networking protocols in support of H.263+ Encoder H.263+ Decoder error resilient video codecs Packetization De-Packetization RTP RTP Socket Interface Socket Interface • Target domain: Live video streaming over 2G GSM UDP / UDPLite UDP / UDPLite cellular network IP IP PPP / PPPLite PPP / PPPLite • Environment: Low-bit rate video codecs that are Radio Link Protocol Radio Link Protocol highly tolerant of errors in the byte stream – H.263++: Motion vectors, prediction, error/loss concealment GSM PSTN Network Mobile Host GSM Fixed Host • What is the role of reliability in the network? Unix BSDi 3.0 Basestation Unix BSDi 3.0 8/28/2018 cs262a-F18h Lecture-02 13 8/28/2018 cs262a-F18h Lecture-02 14 Wireless Video Streaming Need Variable Degrees of Reliability • GSM Radio Link Protocol: reliable data delivery on radio link • Protect headers (need for routing/delivery), not data! – Issue: reliability versus delay – do you need reliability when you have an error tolerant video codec? • Solution #2: – UDP Lite (Larzon, Degemark, and Pink) • Solution #1: turn off reliability in RLP and PPP » Flexible checksum only protects packet headers and allows – Fewer video packets delivered! apps to receive corrupted data – UDP checksums caused “damaged” packets to be dropped – RLP Lite / PPP Lite (new protocols) » Same as UDP Lite, but for radio link / link layer • Simulation/experiments: UDP Lite/RLP Lite/PPP Lite – Collected 4480 min of wireless video traces, (~4 min per video) – Bad channel conditions (signal strength ~2-3), BLER ~ 1.5% – Used simulation to repeat experiments • Results – Less E2E delay, constant jitter, higher throughput, lower packet loss … than UDP (with or without RLP) 8/28/2018 cs262a-F18h Lecture-02 15 8/28/2018 cs262a-F18h Lecture-02 16
5 . End to End Delay Packet Loss Mean & Min/Max Mean & Min/Max 2.5 3% 2.0 E n d -to -E n d D elay (s) 1.726 P a c k e t L o s s (% ) 1.5 2% 2.09% 1.0 1% 1.05% 0.5 0.511 0.377 0.0 0.00% UDP, RLP UDP, RLP Lite* UDP Lite, RLP Lite* 0% UDP, RLP UDP, RLP Lite* UDP Lite, RLP Lite* 8/28/2018 cs262a-F18h Lecture-02 17 8/28/2018 cs262a-F18h Lecture-02 18 Summary Is this a good paper? • What were the authors’ goals? • E2E argument encourages us to keep IP simple • What about the evaluation/metrics? • Did they convince you that this was a good • If higher layer can implement functionality correctly, system/approach? implement it in a lower layer only if • Were there any red-flags? – it improves the performance significantly for application that need that functionality, and • What mistakes did they make? – it does not impose burden on applications that do not require that • Does the system/approach meet the “Test of Time” functionality challenge? • Principle is broadly applicable to other systems domains • How would you review this paper today? – Storage, architecture, … 8/28/2018 cs262a-F18h Lecture-02 19 8/28/2018 cs262a-F18h Lecture-02 20
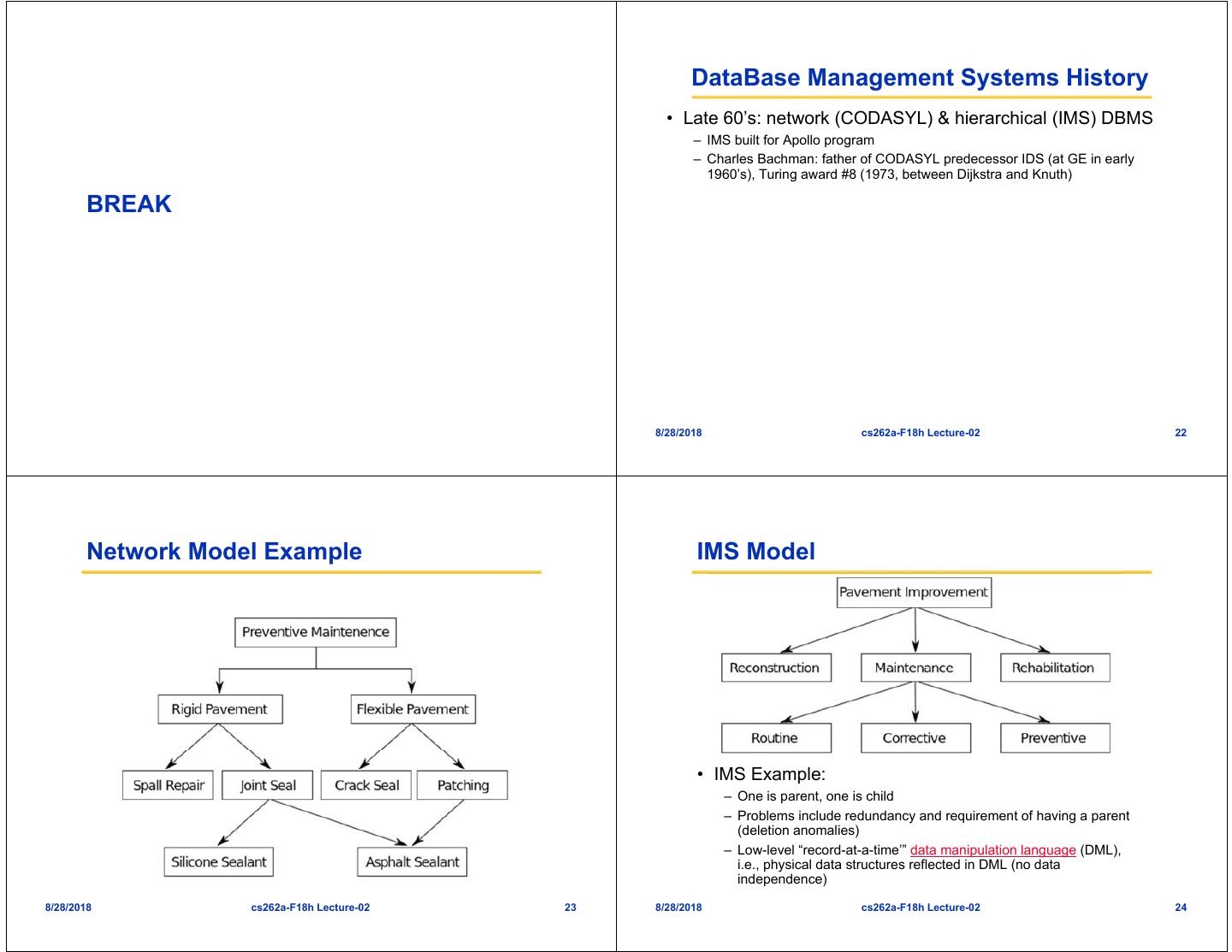
6 . DataBase Management Systems History • Late 60’s: network (CODASYL) & hierarchical (IMS) DBMS – IMS built for Apollo program – Charles Bachman: father of CODASYL predecessor IDS (at GE in early 1960’s), Turing award #8 (1973, between Dijkstra and Knuth) BREAK 8/28/2018 cs262a-F18h Lecture-02 22 Network Model Example IMS Model • IMS Example: – One is parent, one is child – Problems include redundancy and requirement of having a parent (deletion anomalies) – Low-level “record-at-a-time’” data manipulation language (DML), i.e., physical data structures reflected in DML (no data independence) 8/28/2018 cs262a-F18h Lecture-02 23 8/28/2018 cs262a-F18h Lecture-02 24
7 . 1970: Edgar Codd’s Paper Data Independence – both logical and physical • The most influential paper in DB research – Set-at-a-time DML with the key idea of “data independence” • What physical tricks could you play under the – Allows for schema and physical storage structures to change under the covers? Think about modern HW! covers – Papadimitriou: “as clear a paradigm shift as we can hope to find in computer science” • “Hellerstein’s Inequality”: – Edgar F. Codd: Turing award #18 (1981, between Hoare and Cook) – Need data independence when dapp/dt << denvironment/dt – Other scenarios where this holds? – This is an early, powerful instance of two themes: levels of indirection and adaptivity 8/28/2018 cs262a-F18h Lecture-02 25 8/28/2018 cs262a-F18h Lecture-02 26 “Modern” DBMS Prototypes Ingres : UCB 1974-77 • An early and pioneering “pickup team’”, including • Mid 70’s: Stonebraker & Wong – Wholesale adoption of Codd’s vision in 2 full-function (sort of) prototypes – Ancestors of essentially all today’s commercial systems • Begat Ingres Corp (CA), CA-Universe, Britton-Lee, Sybase, MS SQL Server, Wang’s PACE, Tandem Non-Stop SQL • Ingres and System R 8/28/2018 cs262a-F18h Lecture-02 27 8/28/2018 cs262a-F18h Lecture-02 28
8 . System R : IBM San Jose (now Almaden) Discussion • 15 PhDs • System R arguably got more stuff “right”, though there was lots of information passing between both groups • Begat IBM's SQL/DS & DB2, Oracle, HP’s Allbase, Tandem Non-Stop SQL • Both were viable starting points, proved practicality of relational approach – Direct example of theory --> practice! • Jim Gray: Turing Award #22 (1998, between – ACM Software Systems award #6 shared by both Englebart and Brooks) – Stated goal of both systems was to take Codd’s theory and turn it into a workable system as fast as CODASYL but much easier to use and maintain • Lots of Berkeley folks on the System R team – Interestingly, Stonebraker received ACM SIGMOD Innovations Award – Including Gray (1st CS PhD @ Berkeley), Bruce Lindsay, Irv #1 (1991), Gray #2 (1992), whereas Gray got the Turing first. Traiger, Paul McJones, Mike Blasgen, Mario Schkolnick, Bob Selinger , Bob Yost. See http://www.mcjones.org/System_R/SQL_Reunion_95/sqlr95- Prehisto.html#Index71. 8/28/2018 cs262a-F18h Lecture-02 29 8/28/2018 cs262a-F18h Lecture-02 30 Commercial RDBMS The Rise of SQL • Early 80’s: commercialization of relational systems • Mid 80’s: SQL becomes “intergalactic standard” – Ellison’s Oracle beats IBM to market by reading white papers – DB2 becomes IBM’s flagship product – IBM releases multiple RDBMSs, settles down to DB2 – IMS “sunseted” – Gray (System R), Jerry Held (Ingres) and others join Tandem (Non-Stop SQL) – Kapali Eswaran starts EsVal, which begets HP Allbase and Cullinet – Relational Technology Inc (Ingres Corp), Britton-Lee/Sybase, Wang PACE grow out of Ingres group – CA releases CA-Universe, a commercialization of Ingres – Informix started by Cal alum Roger Sippl (no pedigree to research) – Teradata started by some Cal Tech alums, based on proprietary networking technology (no pedigree to software research, though see parallel DBMS discussion later in semester!) 8/28/2018 cs262a-F18h Lecture-02 31 8/28/2018 cs262a-F18h Lecture-02 32
9 . Today Database View of Applications • Network & hierarchical are legacy systems (though • Big, complex record-keeping applications like SAP and commonly in use!) PeopleSoft, which run over a DBMS – IMS still widely used in banking, airline reservations, etc. (remains • “Enterprise applications” to keep businesses humming a major IBM cash cow) – ERP: Enterprise Resource Planning (SAP, Baan, PeopleSoft, Oracle, IBM, • Relational market commoditized etc.) – Microsoft, Oracle and IBM fighting over bulk of market – CRM: Customer Relationship Management (E.phiphany, Siebel, Oracle, – NCR Teradata, Sybase, HP Nonstop and a few others vying to IBM, Salesforce, etc.) survive on the fringes – SCM: Supply Chain Management (Trilogy, i2, Oracle, IBM, etc.) – OpenSource coming of age, including MySQL, PostgreSQL, Ingres – Human Resources, Direct Marketing, Call Center, Sales Force Automation, (reborn) Help Desk, Catalog Management, etc. – BerkeleyDB is an embedded transactional store that is widely used • Typically client-server (a Sybase “invention”) with a form- as well, but now owned by Oracle based API – XML and object-oriented features have pervaded the relational products as both interfaces and data types, further complicating the – Focus on resource management secondary to focus on data management “purity” of Codd’s vision • Traditionally, a main job of a DBMS is to make these kinds of apps easy to write 8/28/2018 cs262a-F18h Lecture-02 33 8/28/2018 cs262a-F18h Lecture-02 34 Relational System Architecture Relational System Architecture • RDMBS are BIG, hard to modularize pieces of software • Basic modules: – Many macro and micro scale system design decisions – parser – We’ll focus on macro design issues today (micro in future lectures) – query rewrite • Disk management choices: – optimizer – file per relation – query executor – big file in file system – access methods – raw device – buffer manager – lock manager • Process Model: – log/recovery manager – process per user – server – multi-server • Hardware Model: – shared nothing – shared memory – shared disk 8/28/2018 cs262a-F18h Lecture-02 35 8/28/2018 cs262a-F18h Lecture-02 36
10 . Notes on System R Some important points of discussion • Some “systems chestnuts” seen in this paper: • Flexibility of storage mechanisms: – Expect to throw out the 1st version of the system – Domains/inversions vs. heap-files/indexes – Expose internals via standard external interfaces whenever possible (e.g. catalogs as tables, the /proc filesystem, etc.) – Optimize the fast path • Use of TID-lists common in modern DBMS so be – Interpretation vs. compilation vs. intermediate “opcode” doctrinaire? What about Data Independence? representations – One answer: you have to get transactions right for each “access – Component failure as a common case to consider method” – Problems arising from interactions between replicated functionality (in this case, scheduling) 8/28/2018 cs262a-F18h Lecture-02 37 8/28/2018 cs262a-F18h Lecture-02 38 Some important points of discussion Some important points of discussion • System R was often CPU bound (though that’s a coarse- • Access control via views: a deep application of data grained assertion -- really means NOT disk-bound) independence?! – This is common today in well-provisioned DBMSs as well. Why? • Transactional contribution of System R (both • DBMSs are not monolithic designs, really conceptual and implementation) as important as – The RSS stuff does intertwine locking and logging into disk access, relational model, and in fact should be decoupled indexing and buffer management. But RDS/RSS boundary is clean, and from relational model. RDS is decomposable. 8/28/2018 cs262a-F18h Lecture-02 39 8/28/2018 cs262a-F18h Lecture-02 40
11 . The “Convoy Problem” Convoy Problem (Con’t) • A classic cross-level scheduling interaction • Last issue is DBMS uses a FCFS wait queue for lock – We will see this again! – For a high-traffic DB lock, DB processes will request it on average every T timesteps • Poorly explained in the paper, three big issues – If the OS preempts a DB process holding that high-traffic DB lock, the • Two interactions between OS and DB scheduling: queue behind the lock grows to include almost all DB processes – #1: OS can preempt a database “process” even when that process – Moreover, the queue is too long to be drained in T timesteps, so it’s is holding a high-traffic DB lock “stable” -- every DB process queues back up before the queue drains, and they burn up their quanta pointlessly waiting in line, after which they – #2: DB processes sitting in DB lock queues use up their OS are sent to sleep scheduling quanta while waiting (poorly explained in text), then are removed from the “multiprogramming set” and go to “sleep” – and – Hence each DB process is awake for only one grant of the lock and the an expensive OS dispatch is required to run them again subsequent T timesteps of useful work, after which they queue for the lock again, waste their quanta in the queue, and are put back to sleep • The result is that the useful work per OS waking period is about T timesteps, which is shorter than the overhead of scheduling – hence the system is thrashing 8/28/2018 cs262a-F18h Lecture-02 41 8/28/2018 cs262a-F18h Lecture-02 42 “Solution” System R and INGRES • Attacks the only issue that can be handled without • The prototypes that all current systems are based on interacting with the OS: #3 the FCFS DB lock queue • Basic architecture is the same, and many of the – Paper’s explanation is confusing ideas remain in today’s systems: • Point is to always allow any one of the DB processes – Optimizer remains, largely unchanged currently in the “multiprogramming set” to – RSS/RDS divide remains in many systems immediately get the lock without burning a quantum – SQL, cursors, duplicates, NULLs, etc. waiting on the lock » the pros and cons of duplicates. Alternatives? – Hence no quanta are wasted on waiting, so each process spends » pros and cons of NULLs. Alternatives? almost all of its allotted quanta on “real work” » grouping and aggregation – Technically, this is not “fair”, however, it is “efficient”! – updatable single-table views • Note that the proposed policy achieves this without – begin/end xact at user level, savepoints and restore, catalogs as needing to know which processes are in the OS’ relations, flexible security (GRANT/REVOKE), integrity constraints multiprogramming set – triggers (!!), clustering, compiled queries, B-trees – Nest-loop & sort-merge join, all joins 2-way – dual logs to support log failure 8/28/2018 cs262a-F18h Lecture-02 43 8/28/2018 cs262a-F18h Lecture-02 44
12 . Stuff they got wrong: OS and DBMS: Philosophical Similarities • Shadow paging • UNIX paper: “The most important job of UNIX is to provide a file system” – UNIX and System R are both “information management” systems! • Predicate locking – both also provide programming APIs for code • Both providing what they think are crucial APIs for • SQL language applications – Duplicate semantics – Subqueries vs. joins – Outer join • Rejected hashing 8/28/2018 cs262a-F18h Lecture-02 45 8/28/2018 cs262a-F18h Lecture-02 46 Difference in Focus Achilles’ Heel • Bottom-Up (elegance of system) vs. Top-Down (elegance • Achilles' heel of RDBMSs: a closed box of semantics) – Cannot leverage technology without going through the full SQL stack – main goal of UNIX: provide a small elegant set of mechanisms, and have – One solution: make the system extensible, convince the world to programmers (i.e. C programmers) build on top of it. download code into the DBMS » They are proud that “No large ‘access method’ routines are required – Another solution: componentize the system (hard? RSS is hard to bust to insulate the programmer from system calls”. OS viewed its role up, due to transaction semantics) as presenting hardware to computer programmers. » No native locking mechanisms! • Achilles' heel of OSes: hard to decide on the "right" – main goal of System R and Ingres: provide a complete system that level of abstraction insulated programmers (i.e. SQL + scripting) from the system – As we'll read, many UNIX abstractions (e.g. virtual memory) hide too » Guarantee clearly defined semantics of data and queries. After all, much detail, messing up semantics. On the other hand, too low a level DBMS views its role as managing data for application programmers. can cause too much programmer burden, and messes up the elegance of the system • Affects where the complexity goes! – One solution: make the system extensible, convince the fancy apps to – to the system, or the end-programmer? download code into the OS – question: which is better? in what environments? – Another solution: componentize the system (hard, due to protection – follow-on question: are internet systems more like enterprise apps issues) (traditionally built on DBMSs) or scientific/end-user apps (traditionally built over OSes and files)? Why? 8/28/2018 cs262a-F18h Lecture-02 47 8/28/2018 cs262a-F18h Lecture-02 48
13 . Communities Is this a good paper? • Traditionally separate communities, despite • What were the authors’ goals? subsequently clear need to integrate • What about the evaluation/metrics? – UNIX paper: "We take the view that locks are neither necessary nor sufficient, in our environment, to prevent interference between • Did they convince you that this was a good users of the same file. They are unnecessary because we are not system/approach? faced with large, single-file data bases maintained by independent processes." • Were there any red-flags? – System R: "has illustrated the feasibility of compiling a very high- • What mistakes did they make? level data sublanguage, SQL, into machine-level code". • Does the system/approach meet the “Test of Time” challenge? • How would you review this paper today? 8/28/2018 cs262a-F18h Lecture-02 49 8/28/2018 cs262a-F18h Lecture-02 50 Summary • Main goal of this class is to work from both of these directions, cull the lessons from each, and ask how to use these lessons today both within and OUTSIDE the context of these historically separate systems. 8/28/2018 cs262a-F18h Lecture-02 51
3秒后跳转登录页面
去登陆

