
















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
17 Distributed Storage #1
Distributed Storage #1
Dynamo: Amazon's Highly Available Key-value Store
Pond: the OceanStore Prototype
展开查看详情
1 . Reprise: Stability under churn (Tapestry) EECS 262a Advanced Topics in Computer Systems Lecture 17 P2P Storage: Dynamo/Pond October 18th, 2018 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs262 (May 2003: 1.5 TB over 4 hours) DOLR Model generalizes to many simultaneous apps 10/18/2018 cs262a-F18 Lecture-17 2 Churn (Optional Bamboo paper last time) A Simple lookup Test Chord is a “scalable protocol for • Start up 1,000 DHT nodes on ModelNet network lookup in a dynamic peer-to-peer – Emulates a 10,000-node, AS-level topology system with frequent node arrivals and departures” – Unlike simulations, models cross traffic and packet loss -- Stoica et al., 2001 – Unlike PlanetLab, gives reproducible results • Churn nodes at some rate – Poisson arrival of new nodes – Random node departs on every new arrival – Exponentially distributed session times Authors Systems Observed Session Time • Each node does 1 lookup every 10 seconds SGG02 Gnutella, Napster 50% < 60 minutes – Log results, process them after test CLL02 Gnutella, Napster 31% < 10 minutes SW02 FastTrack 50% < 1 minute BSV03 Overnet 50% < 60 minutes GDS03 Kazaa 50% < 2.4 minutes 10/18/2018 cs262a-F18 Lecture-17 3 10/18/2018 cs262a-F18 Lecture-17 4
2 . Early Test Results Handling Churn in a DHT • Tapestry had trouble under this level of stress • Forget about comparing different impls. – Worked great in simulations, but not as well on more realistic – Too many differing factors network – Hard to isolate effects of any one feature – Despite sharing almost all code between the two! • Implement all relevant features in one DHT • Problem was not limited to Tapestry consider Chord: – Using Bamboo (similar to Pastry) • Isolate important issues in handling churn 1. Recovering from failures 2. Routing around suspected failures 3. Proximity neighbor selection 10/18/2018 cs262a-F18 Lecture-17 5 10/18/2018 cs262a-F18 Lecture-17 6 Reactive Recovery: The obvious technique The Problem With Reactive Recovery • For correctness, maintain leaf set during churn • Under churn, many pings and change messages – Also routing table, but not needed for correctness – If bandwidth limited, interfere with each other • The Basics – Lots of dropped pings looks like a failure – Ping new nodes before adding them • Respond to failure by sending more messages – Periodically ping neighbors – Probability of drop goes up – Remove nodes that don’t respond – We have a positive feedback cycle (squelch) • Simple algorithm • Can break cycle two ways – After every change in leaf set, send to all neighbors 1. Limit probability of “false suspicions of failure” – Called reactive recovery 2. Recovery periodically 10/18/2018 cs262a-F18 Lecture-17 7 10/18/2018 cs262a-F18 Lecture-17 8
3 . Periodic Recovery Conclusions/Recommendations • Periodically send whole leaf • Avoid positive feedback cycles in recovery set to a random member – Beware of “false suspicions of failure” – Breaks feedback loop – Recover periodically rather than reactively – Converges in O(log N) • Route around potential failures early • Back off period on message – Don’t wait to conclude definite failure loss – TCP-style timeouts quickest for recursive routing – Makes a negative feedback cycle (damping) – Virtual-coordinate-based timeouts not prohibitive • PNS can be cheap and effective – Only need simple random sampling 10/18/2018 cs262a-F18 Lecture-17 9 10/18/2018 cs262a-F18 Lecture-17 10 Today’s Papers The “Traditional” approaches to storage • Dynamo: Amazon’s Highly Available Key-value Store, Giuseppe DeCandia, • Relational Database systems Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash – Clustered - Traditional Enterprise RDBMS provide the ability to Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall and cluster and replicate data over multiple servers – providing reliability Werner Vogels. Appears in Proceedings of the Symposium on Operating » Oracle, Microsoft SQL Server and even MySQL have traditionally Systems Design and Implementation (OSDI), 2007 powered enterprise and online data clouds • Pond: the OceanStore Prototype, Sean Rhea, Patrick Eaton, Dennis Geels, – Highly Available – Provide Synchronization (“Always Consistent”), Load-Balancing and High-Availability features to provide nearly 100% Hakim Weatherspoon, Ben Zhao, and John Kubiatowicz. Appears in Service Uptime Proceedings of the 2nd USENIX Conference on File and Storage – Structured Querying – Allow for complex data models and structured Technologies (FAST), 2003 querying – It is possible to off-load much of data processing and manipulation to the back-end database • However, Traditional RDBMS clouds are: EXPENSIVE! To maintain, license and store large amounts of data • Thoughts? – The service guarantees of traditional enterprise relational databases like Oracle, put high overheads on the cloud – Complex data models make the cloud more expensive to maintain, update and keep synchronized – Load distribution often requires expensive networking equipment – To maintain the “elasticity” of the cloud, often requires expensive upgrades to the network 10/18/2018 cs262a-F18 Lecture-17 11 10/18/2018 cs262a-F18 Lecture-17 12
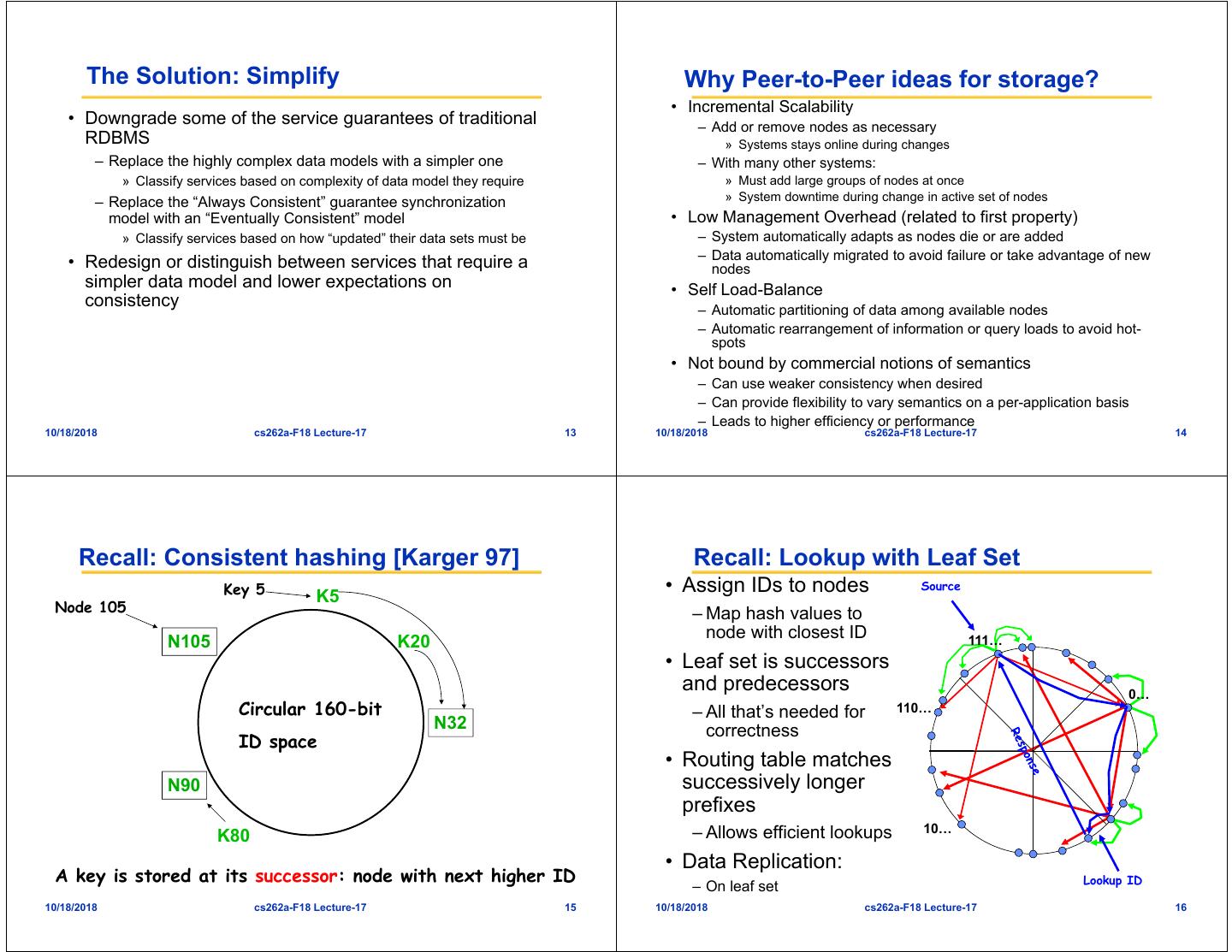
4 . The Solution: Simplify Why Peer-to-Peer ideas for storage? • Incremental Scalability • Downgrade some of the service guarantees of traditional – Add or remove nodes as necessary RDBMS » Systems stays online during changes – Replace the highly complex data models with a simpler one – With many other systems: » Classify services based on complexity of data model they require » Must add large groups of nodes at once – Replace the “Always Consistent” guarantee synchronization » System downtime during change in active set of nodes model with an “Eventually Consistent” model • Low Management Overhead (related to first property) » Classify services based on how “updated” their data sets must be – System automatically adapts as nodes die or are added – Data automatically migrated to avoid failure or take advantage of new • Redesign or distinguish between services that require a nodes simpler data model and lower expectations on • Self Load-Balance consistency – Automatic partitioning of data among available nodes – Automatic rearrangement of information or query loads to avoid hot- spots • Not bound by commercial notions of semantics – Can use weaker consistency when desired – Can provide flexibility to vary semantics on a per-application basis – Leads to higher efficiency or performance 10/18/2018 cs262a-F18 Lecture-17 13 10/18/2018 cs262a-F18 Lecture-17 14 Recall: Consistent hashing [Karger 97] Recall: Lookup with Leaf Set Key 5 K5 • Assign IDs to nodes Source Node 105 – Map hash values to node with closest ID N105 K20 111… • Leaf set is successors and predecessors 0… Circular 160-bit – All that’s needed for 110… N32 correctness ID space • Routing table matches N90 successively longer prefixes – Allows efficient lookups 10… K80 • Data Replication: A key is stored at its successor: node with next higher ID Lookup ID – On leaf set 10/18/2018 cs262a-F18 Lecture-17 15 10/18/2018 cs262a-F18 Lecture-17 16
5 . Advantages/Disadvantages of Consistent Hashing Dynamo Goals • Advantages: • Scale – adding systems to network causes minimal – Automatically adapts data partitioning as node membership changes impact – Node given random key value automatically “knows” how to participate in routing and data management • Symmetry – No special roles, all features in all nodes – Random key assignment gives approximation to load balance • Decentralization – No Master node(s) • Disadvantages – Uneven distribution of key storage natural consequence of random node • Highly Available – Focus on end user experience names Leads to uneven query load • SPEED – A system can only be as fast as the lowest level – Key management can be expensive when nodes transiently fail » Assuming that we immediately respond to node failure, must transfer state to • Service Level Agreements – System can be adapted to new node set an application’s specific needs, allows flexibility » Then when node returns, must transfer state back » Can be a significant cost if transient failure common • Disadvantages of “Scalable” routing algorithms – More than one hop to find data O(log N) or worse – Number of hops unpredictable and almost always > 1 » Node failure, randomness, etc 10/18/2018 cs262a-F18 Lecture-17 17 10/18/2018 cs262a-F18 Lecture-17 18 Dynamo Assumptions Service Level Agreements (SLA) • Query Model – Simple interface exposed to application level • Application can deliver its – Get(), Put() functionality in a bounded time: – No Delete() – Every dependency in the platform – No transactions, no complex queries needs to deliver its functionality • Atomicity, Consistency, Isolation, Durability with even tighter bounds. – Operations either succeed or fail, no middle ground • Example: service guaranteeing – System will be eventually consistent, no sacrifice of availability to that it will provide a response assure consistency – Conflicts can occur while updates propagate through system within 300ms for 99.9% of its – System can still function while entire sections of network are down requests for a peak client load • Efficiency – Measure system by the 99.9th percentile of 500 requests per second – Important with millions of users, 0.1% can be in the 10,000s • Contrast to services which • Non Hostile Environment focus on mean response time – No need to authenticate query, no malicious queries – Behind web services, not in front of them Service-oriented architecture of Amazon’s platform 10/18/2018 cs262a-F18 Lecture-17 19 10/18/2018 cs262a-F18 Lecture-17 20
6 . Partitioning and Routing Algorithm Advantages of using virtual nodes • Consistent hashing: – the output range of a hash function • If a node becomes unavailable the is treated as a fixed circular space load handled by this node is evenly or “ring”. dispersed across the remaining • Virtual Nodes: available nodes. • When a node becomes available – Each physical node can be responsible again, the newly available node for more than one virtual node accepts a roughly equivalent – Used for load balancing amount of load from each of the • Routing: “zero-hop” other available nodes. – Every node knows about every other node • The number of virtual nodes that a node is responsible can decided – Queries can be routed directly to the root node for given key based on its capacity, accounting – Also – every node has sufficient information to route query to all nodes for heterogeneity in the physical that store information about that key infrastructure. 10/18/2018 cs262a-F18 Lecture-17 21 10/18/2018 cs262a-F18 Lecture-17 22 Replication Data Versioning • Each data item is replicated • A put() call may return to its caller before the update has at N hosts. been applied at all the replicas • “preference list”: The list of • A get() call may return many versions of the same object. nodes responsible for storing • Challenge: an object having distinct version sub-histories, which a particular key the system will need to reconcile in the future. – Successive nodes not guaranteed to be on different physical nodes • Solution: uses vector clocks in order to capture causality between different versions of the same object. – Thus preference list includes physically distinct nodes • Replicas synchronized via anti-entropy protocol – Use of Merkle tree for each unique range – Nodes exchange root of trees for shared key range 10/18/2018 cs262a-F18 Lecture-17 23 10/18/2018 cs262a-F18 Lecture-17 24
7 . Vector Clock Vector clock example • A vector clock is a list of (node, counter) pairs. • Every version of every object is associated with one vector clock. • If the counters on the first object’s clock are less-than-or- equal to all of the nodes in the second clock, then the first is an ancestor of the second and can be forgotten. 10/18/2018 cs262a-F18 Lecture-17 25 10/18/2018 cs262a-F18 Lecture-17 26 Conflicts (multiversion data) Execution of get () and put () operations • Client must resolve conflicts • Route its request through a generic load balancer that will – Only resolve conflicts on reads select a node based on load information – Different resolution options: » Use vector clocks to decide based on history – Simple idea, keeps functionality within Dynamo » Use timestamps to pick latest version • Use a partition-aware client library that routes requests – Examples given in paper: directly to the appropriate coordinator nodes » For shopping cart, simply merge different versions – Requires client to participate in protocol » For customer’s session information, use latest version – Stale versions returned on reads are updated (“read repair”) – Much higher performance • Vary N, R, W to match requirements of applications – High performance reads: R=1, W=N – Fast writes with possible inconsistency: W=1 – Common configuration: N=3, R=2, W=2 • When do branches occur? – Branches uncommon: 0.0006% of requests saw > 1 version over 24 hours – Divergence occurs because of high write rate (more coordinators), not necessarily because of failure 10/18/2018 cs262a-F18 Lecture-17 27 10/18/2018 cs262a-F18 Lecture-17 28
8 . Sloppy Quorum Hinted handoff • R/W is the minimum number of nodes that must participate in a successful read/write operation. • Assume N = 3. When B is • Setting R + W > N yields a quorum-like system. temporarily down or • In this model, the latency of a get (or put) operation is unreachable during a dictated by the slowest of the R (or W) replicas. For this write, send replica to E reason, R and W are usually configured to be less than N, • E is hinted that the to provide better latency. replica belongs to B and it will deliver to B when B is recovered. • Again: “always writeable” 10/18/2018 cs262a-F18 Lecture-17 29 10/18/2018 cs262a-F18 Lecture-17 30 Summary of techniques used in Implementation Dynamo and their advantages • Java – Event-triggered framework similar to SEDA Problem Technique Advantage • Local persistence component allows for different storage Partitioning Consistent Hashing Incremental Scalability engines to be plugged in: Vector clocks with reconciliation Version size is decoupled from High Availability for writes – Berkeley Database (BDB) Transactional Data Store: object of tens during reads update rates. of kilobytes Handling temporary failures Sloppy Quorum and hinted handoff Provides high availability and – MySQL: object of > tens of kilobytes durability guarantee when some of the replicas are not available. – BDB Java Edition, etc. Recovering from permanent Synchronizes divergent replicas in Anti-entropy using Merkle trees failures the background. Preserves symmetry and avoids having a centralized registry for Gossip-based membership protocol storing membership and node Membership and failure detection and failure detection. liveness information. 10/18/2018 cs262a-F18 Lecture-17 31 10/18/2018 cs262a-F18 Lecture-17 32
9 . Evaluation Evaluation: Relaxed durabilityperformance 10/18/2018 cs262a-F18 Lecture-17 33 10/18/2018 cs262a-F18 Lecture-17 34 Is this a good paper? • What were the authors’ goals? • What about the evaluation/metrics? • Did they convince you that this was a good system/approach? • Were there any red-flags? • What mistakes did they make? • Does the system/approach meet the “Test of Time” challenge? • How would you review this paper today? BREAK 10/18/2018 cs262a-F18 Lecture-17 35 10/18/2018 cs262a-F18 Lecture-17 36
10 . OceanStore Vision: Utility Infrastructure What are the advantages of a utility? • For Clients: Canadian – Outsourcing of Responsibility OceanStore » Someone else worries about quality of service Sprint – Better Reliability » Utility can muster greater resources toward durability AT&T » System not disabled by local outages » Utility can focus resources (manpower) at security-vulnerable aspects Pac IBM of system – Better data mobility Bell » Starting with secure network modelsharing IBM • For Utility Provider: – Economies of scale » Dynamically redistribute resources between clients • Data service provided by storage federation » Focused manpower can serve many clients simultaneously • Cross-administrative domain • Contractual Quality of Service (“someone to sue”) 10/18/2018 cs262a-F18 Lecture-17 37 10/18/2018 cs262a-F18 Lecture-17 38 Key Observation: Want Automatic Maintenance OceanStore Assumptions • Can’t possibly manage billions of servers by hand! • Untrusted Infrastructure: Peer-to-peer • System should automatically: – The OceanStore is comprised of untrusted components – Adapt to failure – Individual hardware has finite lifetimes – Exclude malicious elements – All data encrypted within the infrastructure – Repair itself • Mostly Well-Connected: – Incorporate new elements – Data producers and consumers are connected to a high-bandwidth network most of the time • System should be secure and private – Exploit multicast for quicker consistency when possible – Encryption, authentication • Promiscuous Caching: • System should preserve data over the long term (accessible – Data may be cached anywhere, anytime for 100s of years): – Geographic distribution of information Quality-of-Service – New servers added/Old servers removed • Responsible Party: – Continuous Repair Data survives for long term – Some organization (i.e. service provider) guarantees that your data is consistent and durable – Not trusted with content of data, merely its integrity 10/18/2018 cs262a-F18 Lecture-17 39 10/18/2018 cs262a-F18 Lecture-17 40
11 . Recall: Routing to Objects (Tapestry) OceanStore Data Model • Versioned Objects – Every update generates a new version – Can always go back in time (Time Travel) GUID1 • Each Version is Read-Only – Can have permanent name – Much easier to repair • An Object is a signed mapping between permanent name DOLR and latest version – Write access control/integrity involves managing these mappings versions GUID2 GUID1 Comet Analogy updates 10/18/2018 cs262a-F18 Lecture-17 41 10/18/2018 cs262a-F18 Lecture-17 42 Self-Verifying Objects Two Types of OceanStore Data AGUID = hash{name+keys} • Active Data: “Floating Replicas” VGUIDi VGUIDi + 1 Data backpointe – Per object virtual server M M B- r – Interaction with other replicas for consistency Tree copy on write – May appear and disappear like bubbles Indirect • Archival Data: OceanStore’s Stable Store Blocks – m-of-n coding: Like hologram copy on write » Data coded into n fragments, any m of which are sufficient to reconstruct Data (e.g m=16, n=64) d1 d2 d3 d4 Block d'8 d'9 s d5 d6 d7 d8 d9 » Coding overhead is proportional to nm (e.g 4) – Fragments are cryptographically self-verifying Heartbeat: {AGUID,VGUID, Timestamp}signed • Most data in the OceanStore is archival! Heartbeats + Updates Read-Only Data 10/18/2018 cs262a-F18 Lecture-17 43 10/18/2018 cs262a-F18 Lecture-17 44
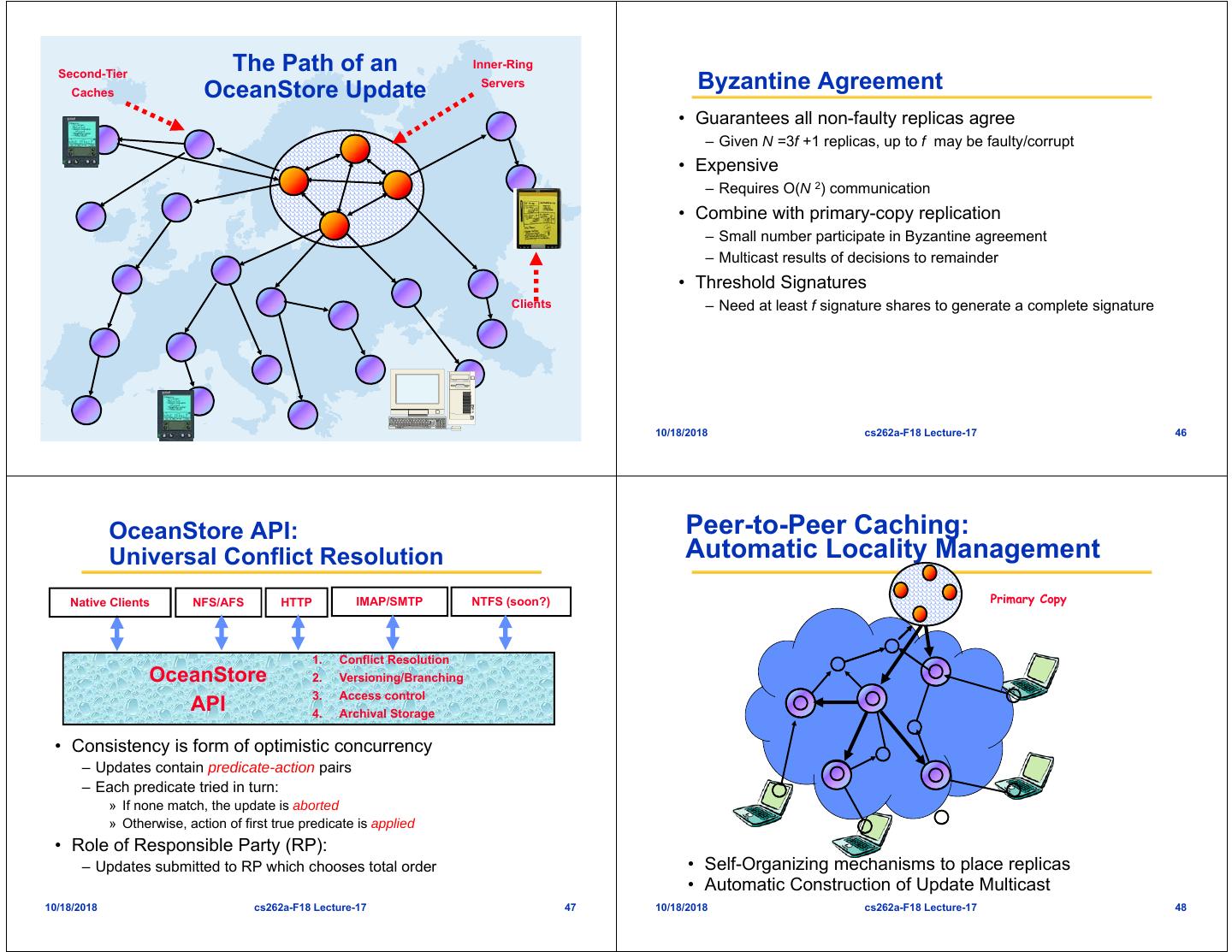
12 . Second-Tier The Path of an Inner-Ring Caches OceanStore Update Servers Byzantine Agreement • Guarantees all non-faulty replicas agree – Given N =3f +1 replicas, up to f may be faulty/corrupt • Expensive – Requires O(N 2) communication • Combine with primary-copy replication – Small number participate in Byzantine agreement – Multicast results of decisions to remainder • Threshold Signatures Clients – Need at least f signature shares to generate a complete signature 10/18/2018 cs262a-F18 Lecture-17 45 10/18/2018 cs262a-F18 Lecture-17 46 OceanStore API: Peer-to-Peer Caching: Universal Conflict Resolution Automatic Locality Management Native Clients NFS/AFS HTTP IMAP/SMTP NTFS (soon?) Primary Copy 1. Conflict Resolution OceanStore 2. Versioning/Branching 3. Access control API 4. Archival Storage • Consistency is form of optimistic concurrency – Updates contain predicate-action pairs – Each predicate tried in turn: » If none match, the update is aborted » Otherwise, action of first true predicate is applied • Role of Responsible Party (RP): – Updates submitted to RP which chooses total order • Self-Organizing mechanisms to place replicas • Automatic Construction of Update Multicast 10/18/2018 cs262a-F18 Lecture-17 47 10/18/2018 cs262a-F18 Lecture-17 48
13 . Archival Dissemination Aside: Why erasure coding? of Fragments High Durability/overhead ratio! Fraction Blocks Lost Per Year (FBLPY) Archival Servers Archival Servers • Exploit law of large numbers for durability! • 6 month repair, FBLPY: – Replication: 0.03 – Fragmentation: 10-35 10/18/2018 cs262a-F18 Lecture-17 49 10/18/2018 cs262a-F18 Lecture-17 50 Extreme Durability Differing Degrees of Responsibility • Exploiting Infrastructure for Repair • Inner-ring provides quality of service – DOLR permits efficient heartbeat mechanism to notice: » Servers going away for a while – Handles of live data and write access control » Or, going away forever! – Focus utility resources on this vital service – Continuous sweep through data also possible – Compromised servers must be detected quickly – Erasure Code provides Flexibility in Timing • Caching service can be provided by anyone • Data transferred from physical medium to physical medium – Data encrypted and self-verifying – No “tapes decaying in basement” – Pay for service “Caching Kiosks”? – Information becomes fully Virtualized • Archival Storage and Repair • Thermodynamic Analogy: Use of Energy (supplied by – Read-only data: easier to authenticate and repair servers) to Suppress Entropy – Tradeoff redundancy for responsiveness • Could be provided by different companies! 10/18/2018 cs262a-F18 Lecture-17 51 10/18/2018 cs262a-F18 Lecture-17 52
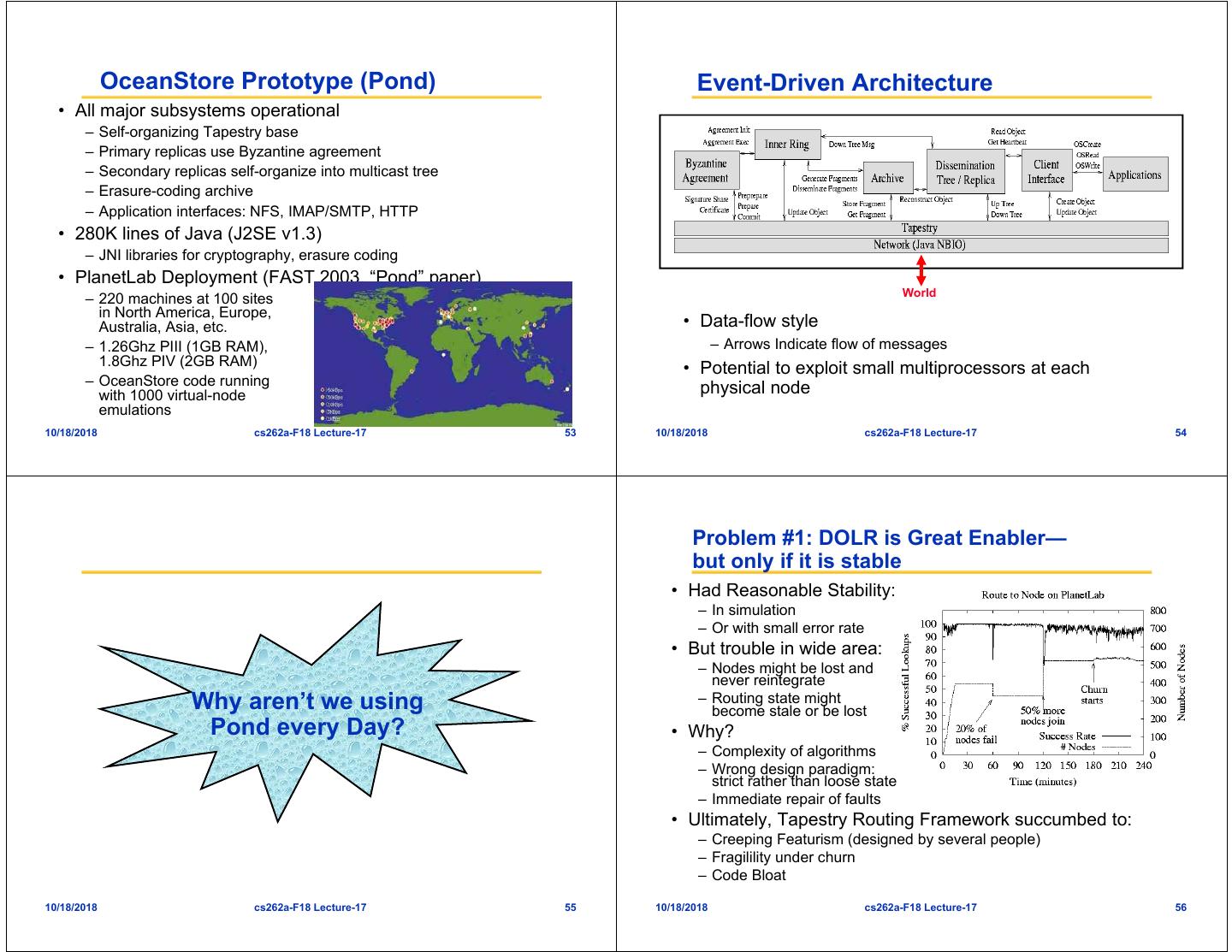
14 . OceanStore Prototype (Pond) Event-Driven Architecture • All major subsystems operational – Self-organizing Tapestry base – Primary replicas use Byzantine agreement – Secondary replicas self-organize into multicast tree – Erasure-coding archive – Application interfaces: NFS, IMAP/SMTP, HTTP • 280K lines of Java (J2SE v1.3) – JNI libraries for cryptography, erasure coding • PlanetLab Deployment (FAST 2003, “Pond” paper) World – 220 machines at 100 sites in North America, Europe, Australia, Asia, etc. • Data-flow style – 1.26Ghz PIII (1GB RAM), – Arrows Indicate flow of messages 1.8Ghz PIV (2GB RAM) • Potential to exploit small multiprocessors at each – OceanStore code running physical node with 1000 virtual-node emulations 10/18/2018 cs262a-F18 Lecture-17 53 10/18/2018 cs262a-F18 Lecture-17 54 Problem #1: DOLR is Great Enabler— but only if it is stable • Had Reasonable Stability: – In simulation – Or with small error rate • But trouble in wide area: – Nodes might be lost and never reintegrate Why aren’t we using – Routing state might become stale or be lost Pond every Day? • Why? – Complexity of algorithms – Wrong design paradigm: strict rather than loose state – Immediate repair of faults • Ultimately, Tapestry Routing Framework succumbed to: – Creeping Featurism (designed by several people) – Fragilility under churn – Code Bloat 10/18/2018 cs262a-F18 Lecture-17 55 10/18/2018 cs262a-F18 Lecture-17 56
15 . Answer: Bamboo! Problem #2: Pond Write Latency • Simple, Stable, Targeting Failure • Byzantine algorithm adapted from Castro & Liskov • Rethinking of design of Tapestry: – Gives fault tolerance, security against compromise – Separation of correctness from performance – Fast version uses symmetric cryptography – Periodic recovery instead of reactive recovery – Network understanding • Pond uses threshold signatures instead (e.g. timeout calculation) – Signature proves that f +1 primary replicas agreed – Simpler Node Integration – Can be shared among secondary replicas (smaller amount of state) – Can also change primaries w/o changing public key • Extensive testing under Churn and partition • Big plus for maintenance costs – Results good for all time once signed • Bamboo is so stable that it is part of the OpenHash – Replace faulty/compromised servers transparently public DHT infrastructure. • In wide use by many researchers 10/18/2018 cs262a-F18 Lecture-17 57 10/18/2018 cs262a-F18 Lecture-17 58 Closer Look: Write Cost Problem #3: Efficiency • Small writes 4 kB 2 MB • No resource aggregation – Signature dominates Phase write write – Small blocks spread widely – Every block of every file on different set of servers – Threshold sigs. slow! Validate 0.3 0.4 – Not uniquely OceanStore issue! – Takes 70+ ms to sign • Answer: Two-Level Naming – Compare to 5 ms Serialize 6.1 26.6 – Place data in larger chunks (‘extents’) for regular sigs. Apply 1.5 113.0 – Individual access of blocks by name within extents • Large writes Archive 4.5 566.9 get( E1,R1 ) – Encoding dominates Sign Result 77.8 75.8 – Archive cost per byte – Signature cost per write (times in milliseconds) • Answer: Reduction in overheads V2 R2 I3 B6 B5 V1 R1 I2 B4 B3 I1 B2 B1 – More Powerful Hardware at Core E1 E0 – Cryptographic Hardware » Would greatly reduce write cost – Bonus: Secure Log good interface for secure archive » Possible use of ECC or other signature method – Antiquity: New Prototype for archival storage – Offloading of Archival Encoding – Similarity to SSTable use in BigTable? 10/18/2018 cs262a-F18 Lecture-17 59 10/18/2018 cs262a-F18 Lecture-17 60
16 . Problem #4: Complexity Other Issues/Ongoing Work at Time: • Several of the mechanisms were complex • Archival Repair Expensive if done incorrectly: – Small blocks consume excessive storage and – Ideas were simple, but implementation was complex network bandwidth – Data format combination of live and archival features – Transient failures consume unnecessary repair bandwidth – Byzantine Agreement hard to get right – Solutions: collect blocks into extents and use threshold repair • Ideal layering not obvious at beginning of project: • Resource Management Issues – Many Applications Features placed into Tapestry – Denial of Service/Over Utilization of Storage serious threat – Components not autonomous, i.e. able to be tied in at any – Solution: Exciting new work on fair allocation moment and restored at any moment • Inner Ring provides incomplete solution: • Top-down design lost during thinking and – Complexity with Byzantine agreement algorithm is a problem experimentation – Working on better Distributed key generation – Better Access control + secure hardware + simpler Byzantine • Everywhere: reactive recovery of state Algorithm? – Original Philosophy: Get it right once, then repair • Handling of low-bandwidth links and Partial Disconnection – Much Better: keep working toward ideal – Improved efficiency of data storage (but assume never make it) – Scheduling of links – Resources are never unbounded • Better Replica placement through game theory? 10/18/2018 cs262a-F18 Lecture-17 61 10/18/2018 cs262a-F18 Lecture-17 62 Bamboo OpenDHT • PL deployment running for several months • Put/get via RPC over TCP Follow-on Work 10/18/2018 cs262a-F18 Lecture-17 63 10/18/2018 cs262a-F18 Lecture-17 64
17 . Antiquity Architecture: OceanStore Archive Antiquity Universal Secure Middleware • Secure Log: • Data Source App Replicated – Can only modify at one point – log head. – Creator of data Service V1 R1 I2 B4 B3 I1 B2 B1 » Makes consistency easier • Client V1 R1 I2 B4 B3 I1 B2 B1 – Self-verifying – Direct user of system » Every entry securely points to previous forming Merkle chain » “Middleware” » Prevents substitution attacks » End-user, Server, – Random read access – can still read efficiently Replicated service • Simple and secure primitive for storage – append()’s to log Storage System – Log identified by cryptographic key pair – Signs requests V1 R1 I2 B4 B3 I1 B2 B1 – Only owner of private key can modify log – Thin interface, only append() • Storage Servers – Store log replicas on disk • Amenable to secure, durable implementation – Dynamic Byzantine quorums – Byzantine quorum of storage servers App » Can survive failures at O(n) cost instead of O(n2) cost » Consistency and durability – Efficiency through aggregation • Administrator Server » Use of Extents and Two-Level naming App – Selects storage servers • Prototype operational on PlanetLab 10/18/2018 cs262a-F18 Lecture-17 65 10/18/2018 cs262a-F18 Lecture-17 66 Is this a good paper? • What were the authors’ goals? • What about the evaluation/metrics? • Did they convince you that this was a good system/approach? • Were there any red-flags? • What mistakes did they make? • Does the system/approach meet the “Test of Time” challenge? • How would you review this paper today? 10/18/2018 cs262a-F18 Lecture-17 67
3秒后跳转登录页面
去登陆

