









- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
16 Chord/Tapestry
Peer To Peer Networks
Chord: A Scalable Peer-to-peer Lookup Protocol for Internet Applications
Tapestry: A Resilient Global-scale Overlay for Service Deployment
展开查看详情
1 . Today’s Papers • Chord: A Scalable Peer‐to‐peer Lookup Protocol for Internet Applications, Ion EECS 262a Stoica, Robert Morris, David Liben‐Nowell, David R. Karger, M. Frans Kaashoek, Frank Dabek, Hari Balakrishnan, Appears in Proceedings of the IEEE/ACM Advanced Topics in Computer Systems Transactions on Networking, Vol. 11, No. 1, pp. 17‐32, February 2003 Lecture 16 • Tapestry: A Resilient Global‐scale Overlay for Service Deployment, Ben Y. Zhao, Ling Huang, Jeremy Stribling, Sean C. Rhea, Anthony D. Joseph, and John D. Kubiatowicz. Appears in IEEE Journal on Selected Areas in Communications, Vol 22, No. 1, January 2004 Chord/Tapestry October 16th, 2018 • Today: Peer‐to‐Peer Networks John Kubiatowicz Electrical Engineering and Computer Sciences • Thoughts? University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs262 10/16/2018 cs262a‐F18 Lecture‐16 2 Peer‐to‐Peer: Fully equivalent components Research Community View of Peer‐to‐Peer • Old View: – A bunch of flakey high‐school students stealing music • New View: – A philosophy of systems design at extreme scale – Probabilistic design when it is appropriate • Peer‐to‐Peer has many interacting components – New techniques aimed at unreliable components – View system as a set of equivalent nodes – A rethinking (and recasting) of distributed algorithms » “All nodes are created equal” – Any structure on system must be self‐organizing – Use of Physical, Biological, and Game‐Theoretic techniques to achieve guarantees » Not based on physical characteristics, location, or ownership 10/16/2018 cs262a‐F18 Lecture‐16 3 10/16/2018 cs262a‐F18 Lecture‐16 4
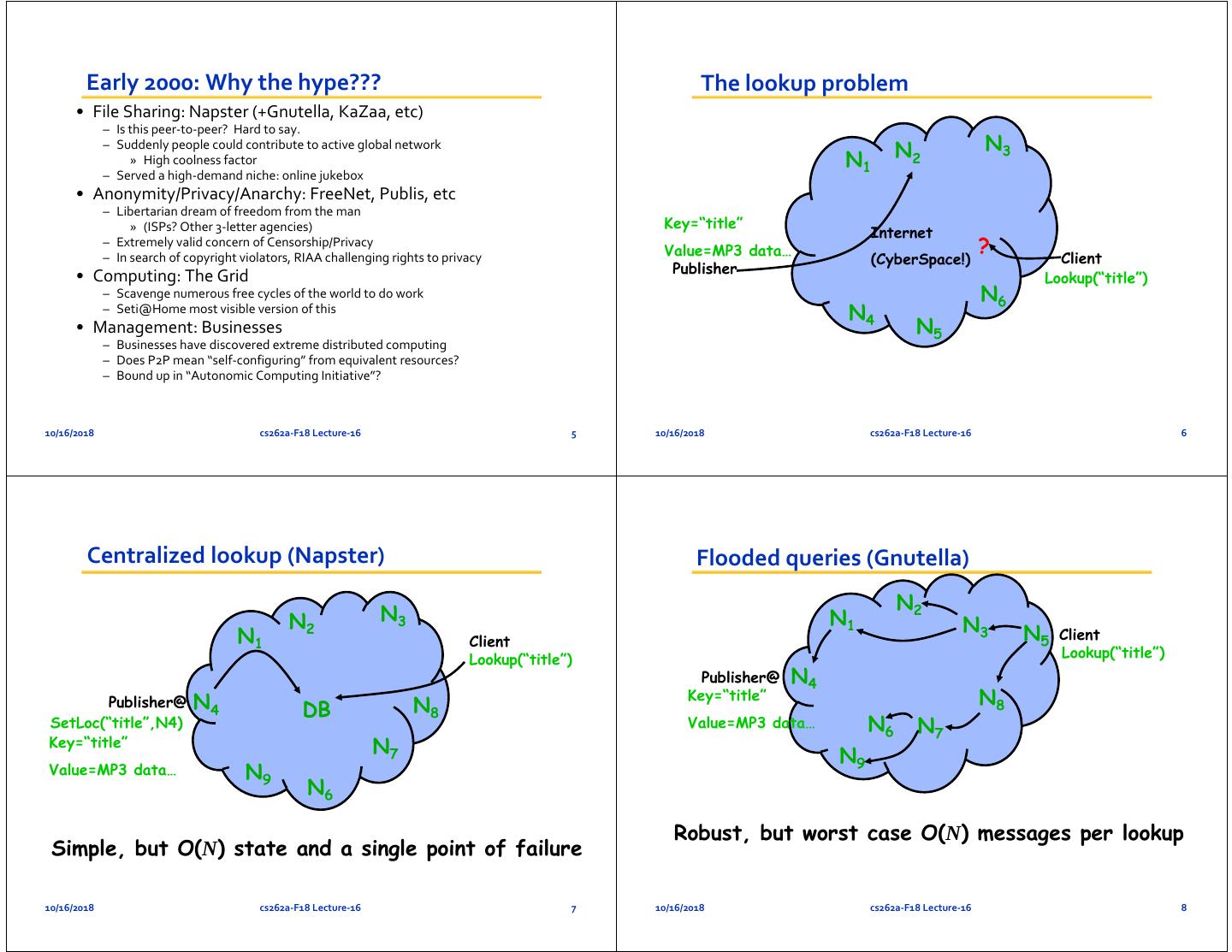
2 . Early 2000: Why the hype??? The lookup problem • File Sharing: Napster (+Gnutella, KaZaa, etc) – Is this peer‐to‐peer? Hard to say. – Suddenly people could contribute to active global network N2 N3 » High coolness factor N1 – Served a high‐demand niche: online jukebox • Anonymity/Privacy/Anarchy: FreeNet, Publis, etc – Libertarian dream of freedom from the man » (ISPs? Other 3‐letter agencies) Key=“title” Internet – Extremely valid concern of Censorship/Privacy Value=MP3 data… ? Client – In search of copyright violators, RIAA challenging rights to privacy (CyberSpace!) Publisher • Computing: The Grid Lookup(“title”) – Scavenge numerous free cycles of the world to do work N6 – Seti@Home most visible version of this N4 • Management: Businesses N5 – Businesses have discovered extreme distributed computing – Does P2P mean “self‐configuring” from equivalent resources? – Bound up in “Autonomic Computing Initiative”? 10/16/2018 cs262a‐F18 Lecture‐16 5 10/16/2018 cs262a‐F18 Lecture‐16 6 Centralized lookup (Napster) Flooded queries (Gnutella) N2 N2 N3 N1 N3 N5 N1 Client Client Lookup(“title”) Lookup(“title”) Publisher@ N4 Publisher@ N4 N8 Key=“title” N8 DB SetLoc(“title”,N4) Value=MP3 data… N6 N7 Key=“title” N7 N9 Value=MP3 data… N9 N6 Robust, but worst case O(N) messages per lookup Simple, but O(N) state and a single point of failure 10/16/2018 cs262a‐F18 Lecture‐16 7 10/16/2018 cs262a‐F18 Lecture‐16 8
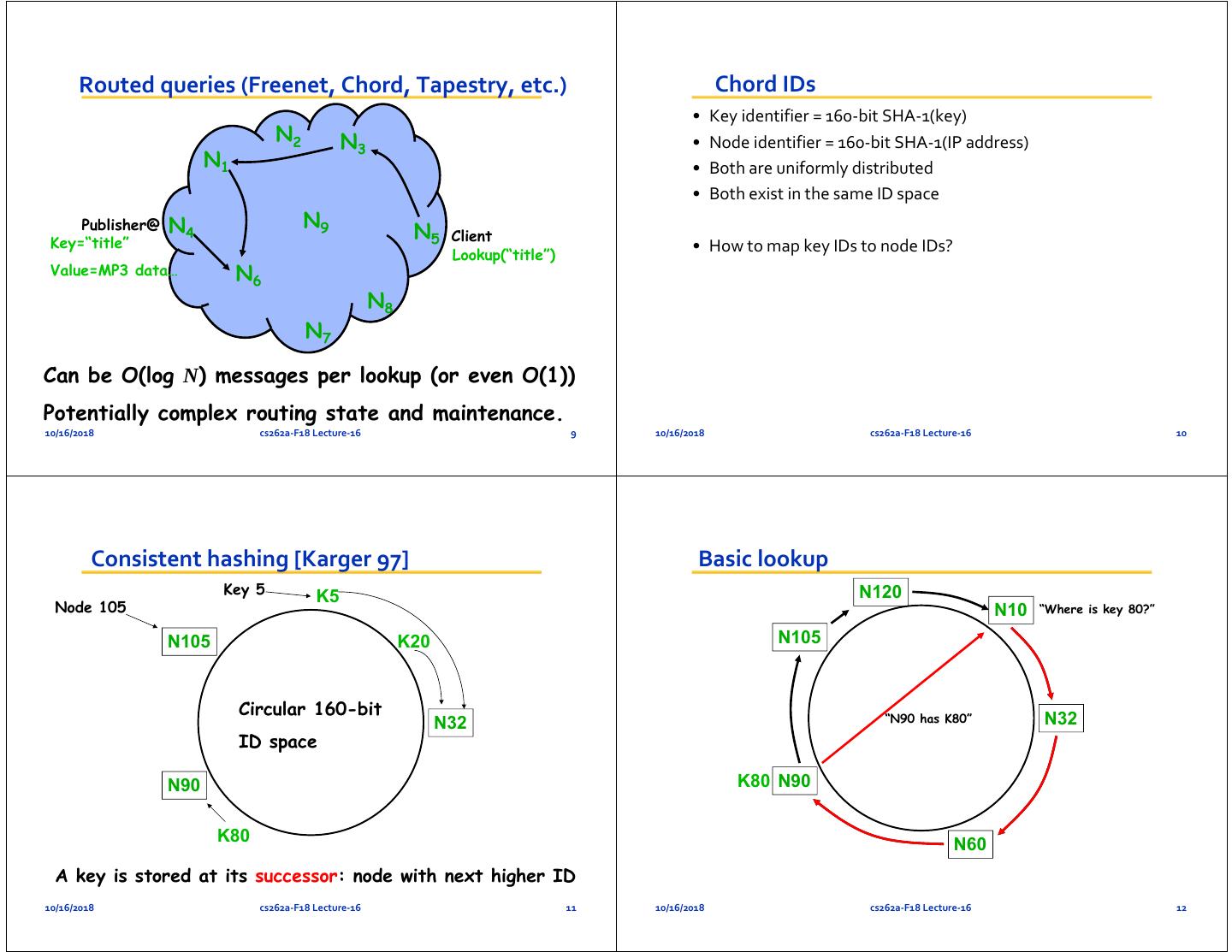
3 . Routed queries (Freenet, Chord, Tapestry, etc.) Chord IDs • Key identifier = 160‐bit SHA‐1(key) N2 N3 • Node identifier = 160‐bit SHA‐1(IP address) N1 • Both are uniformly distributed • Both exist in the same ID space Publisher@ N4 N9 Key=“title” N5 Client Lookup(“title”) • How to map key IDs to node IDs? Value=MP3 data… N6 N8 N7 Can be O(log N) messages per lookup (or even O(1)) Potentially complex routing state and maintenance. 10/16/2018 cs262a‐F18 Lecture‐16 9 10/16/2018 cs262a‐F18 Lecture‐16 10 Consistent hashing [Karger 97] Basic lookup Key 5 N120 K5 Node 105 N10 “Where is key 80?” N105 K20 N105 Circular 160-bit “N90 has K80” N32 N32 ID space N90 K80 N90 K80 N60 A key is stored at its successor: node with next higher ID 10/16/2018 cs262a‐F18 Lecture‐16 11 10/16/2018 cs262a‐F18 Lecture‐16 12
4 . Simple lookup algorithm “Finger table” allows log(N)‐time lookups Lookup(my‐id, key‐id) n = my successor ½ ¼ if my‐id < n < key‐id call Lookup(id) on node n // next hop 1/8 else return my successor // done 1/16 1/32 1/64 1/128 • Correctness depends only on successors N80 10/16/2018 cs262a‐F18 Lecture‐16 13 10/16/2018 cs262a‐F18 Lecture‐16 14 Finger i points to successor of n+2i Lookup with fingers N120 Lookup(my‐id, key‐id) 112 ¼ ½ look in local finger table for highest node n s.t. my‐id < n < key‐id if n exists 1/8 call Lookup(id) on node n // next hop 1/16 1/32 else 1/64 1/128 return my successor // done N80 10/16/2018 cs262a‐F18 Lecture‐16 15 10/16/2018 cs262a‐F18 Lecture‐16 16
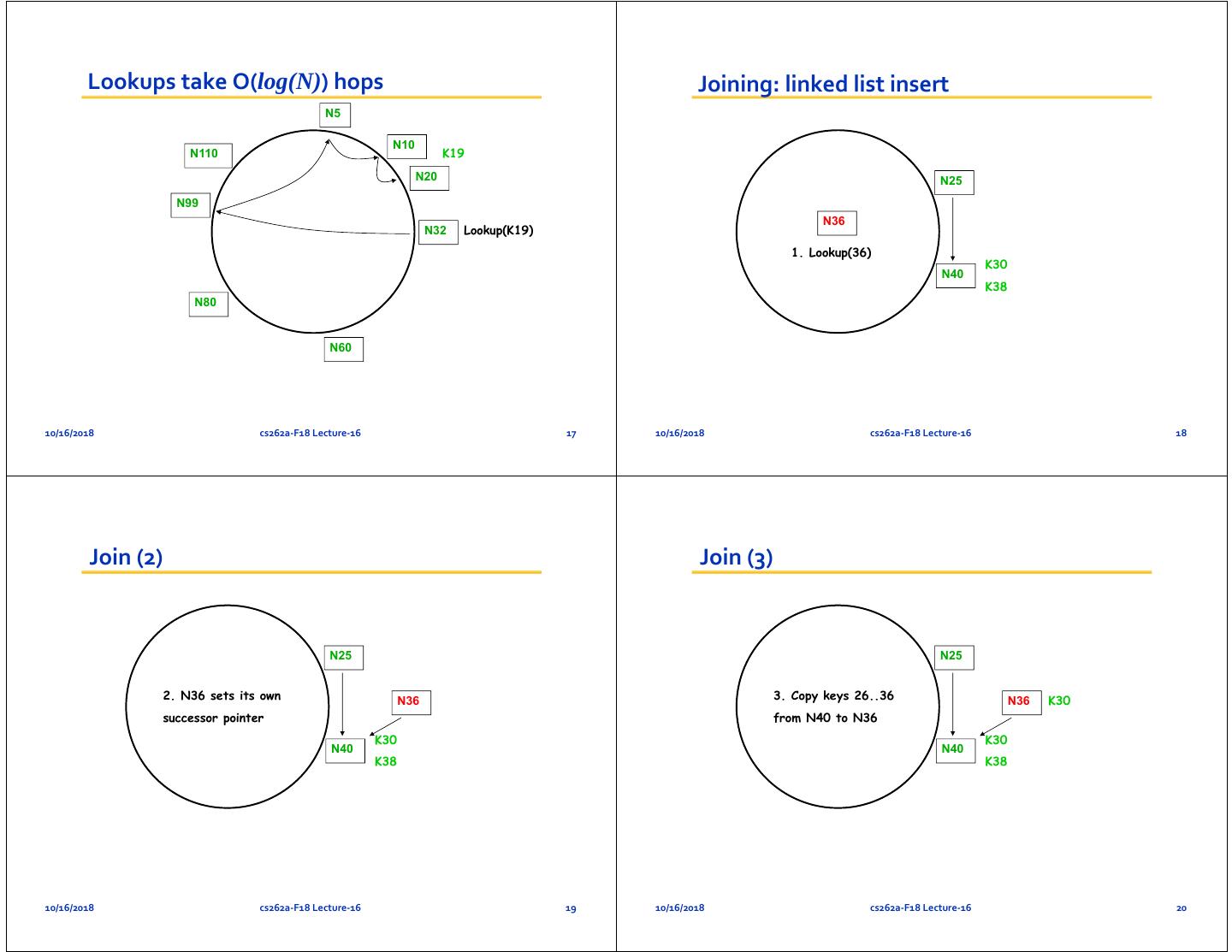
5 . Lookups take O(log(N)) hops Joining: linked list insert N5 N10 N110 K19 N20 N25 N99 N36 N32 Lookup(K19) 1. Lookup(36) K30 N40 K38 N80 N60 10/16/2018 cs262a‐F18 Lecture‐16 17 10/16/2018 cs262a‐F18 Lecture‐16 18 Join (2) Join (3) N25 N25 2. N36 sets its own N36 3. Copy keys 26..36 N36 K30 successor pointer from N40 to N36 K30 K30 N40 N40 K38 K38 10/16/2018 cs262a‐F18 Lecture‐16 19 10/16/2018 cs262a‐F18 Lecture‐16 20
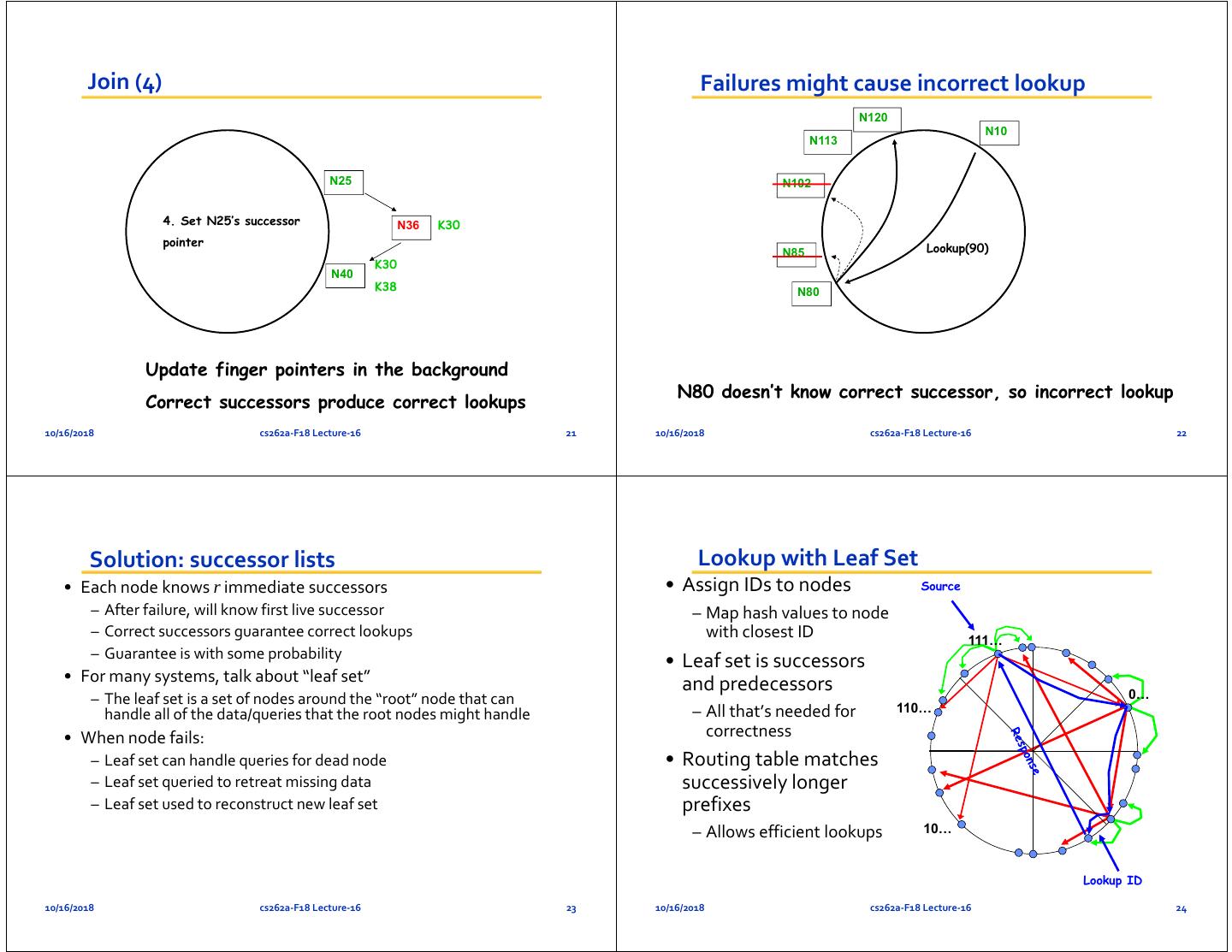
6 . Join (4) Failures might cause incorrect lookup N120 N10 N113 N25 N102 4. Set N25’s successor N36 K30 pointer Lookup(90) N85 K30 N40 K38 N80 Update finger pointers in the background N80 doesn’t know correct successor, so incorrect lookup Correct successors produce correct lookups 10/16/2018 cs262a‐F18 Lecture‐16 21 10/16/2018 cs262a‐F18 Lecture‐16 22 Solution: successor lists Lookup with Leaf Set • Each node knows r immediate successors • Assign IDs to nodes Source – After failure, will know first live successor – Map hash values to node – Correct successors guarantee correct lookups with closest ID 111… – Guarantee is with some probability • Leaf set is successors • For many systems, talk about “leaf set” and predecessors – The leaf set is a set of nodes around the “root” node that can 0… – All that’s needed for 110… handle all of the data/queries that the root nodes might handle • When node fails: correctness – Leaf set can handle queries for dead node • Routing table matches – Leaf set queried to retreat missing data successively longer – Leaf set used to reconstruct new leaf set prefixes – Allows efficient lookups 10… Lookup ID 10/16/2018 cs262a‐F18 Lecture‐16 23 10/16/2018 cs262a‐F18 Lecture‐16 24
7 . Decentralized Object Location Is this a good paper? and Routing: (DOLR) • What were the authors’ goals? • The core of Tapestry • What about the evaluation/metrics? • Routes messages to endpoints • Did they convince you that this was a good system/approach? – Both Nodes and Objects • Were there any red‐flags? • Virtualizes resources – objects are known by name, not location • What mistakes did they make? • Does the system/approach meet the “Test of Time” challenge? • How would you review this paper today? 10/16/2018 cs262a‐F18 Lecture‐16 25 10/16/2018 cs262a‐F18 Lecture‐16 26 Routing to Data, not endpoints! Decentralized Object Location and Routing DOLR Identifiers • ID Space for both nodes and endpoints (objects) : 160‐bit values with a globally defined radix (e.g. hexadecimal to give 40‐digit IDs) • Each node is randomly assigned a nodeID GUID1 • Each endpoint is assigned a Globally Unique IDentifier (GUID) from the same ID space • Typically done using SHA‐1 DOLR • Applications can also have IDs (application specific), which are used to select an appropriate process on each node for delivery GUID2 GUID1 10/16/2018 cs262a‐F18 Lecture‐16 27 10/16/2018 cs262a‐F18 Lecture‐16 28
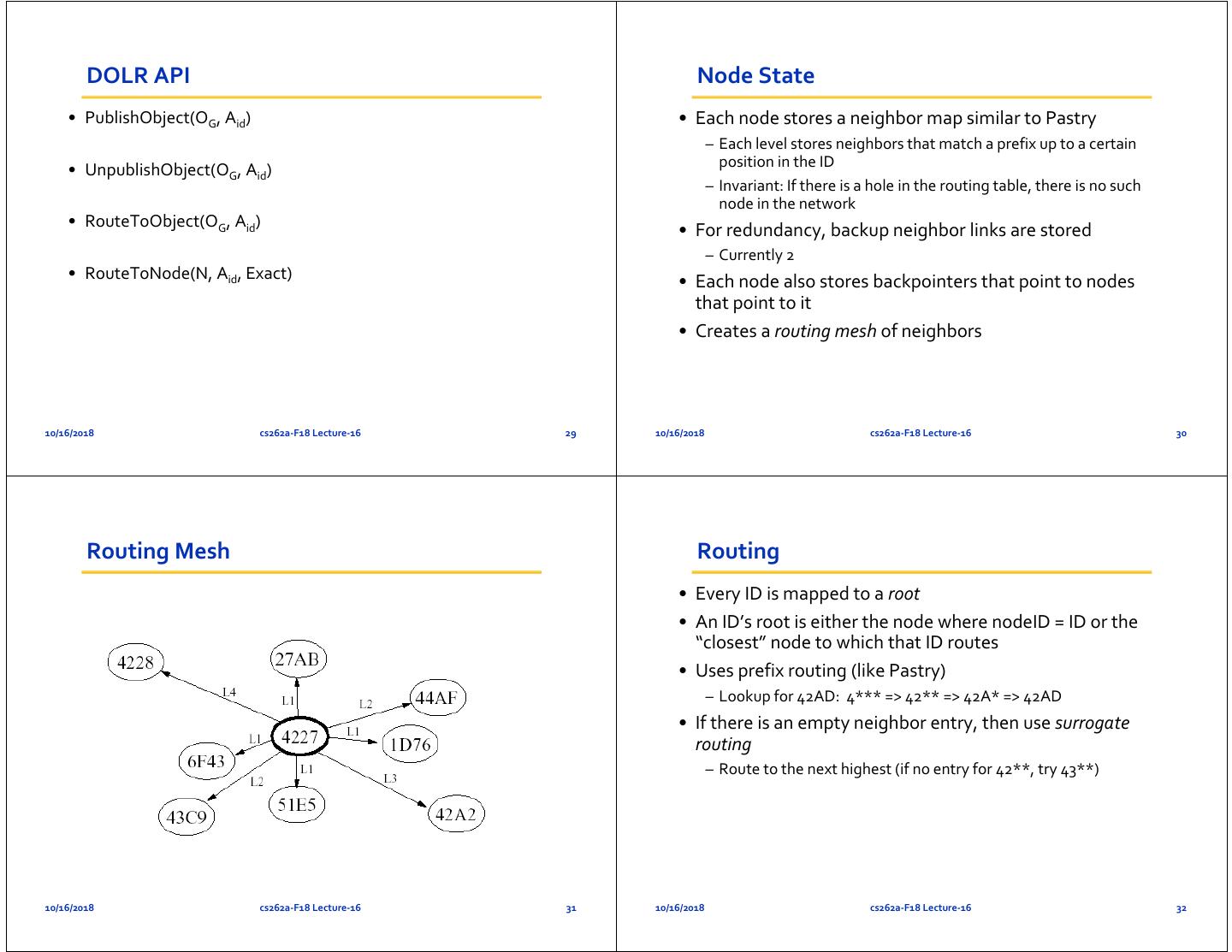
8 . DOLR API Node State • PublishObject(OG, Aid) • Each node stores a neighbor map similar to Pastry – Each level stores neighbors that match a prefix up to a certain • UnpublishObject(OG, Aid) position in the ID – Invariant: If there is a hole in the routing table, there is no such node in the network • RouteToObject(OG, Aid) • For redundancy, backup neighbor links are stored – Currently 2 • RouteToNode(N, Aid, Exact) • Each node also stores backpointers that point to nodes that point to it • Creates a routing mesh of neighbors 10/16/2018 cs262a‐F18 Lecture‐16 29 10/16/2018 cs262a‐F18 Lecture‐16 30 Routing Mesh Routing • Every ID is mapped to a root • An ID’s root is either the node where nodeID = ID or the “closest” node to which that ID routes • Uses prefix routing (like Pastry) – Lookup for 42AD: 4*** => 42** => 42A* => 42AD • If there is an empty neighbor entry, then use surrogate routing – Route to the next highest (if no entry for 42**, try 43**) 10/16/2018 cs262a‐F18 Lecture‐16 31 10/16/2018 cs262a‐F18 Lecture‐16 32
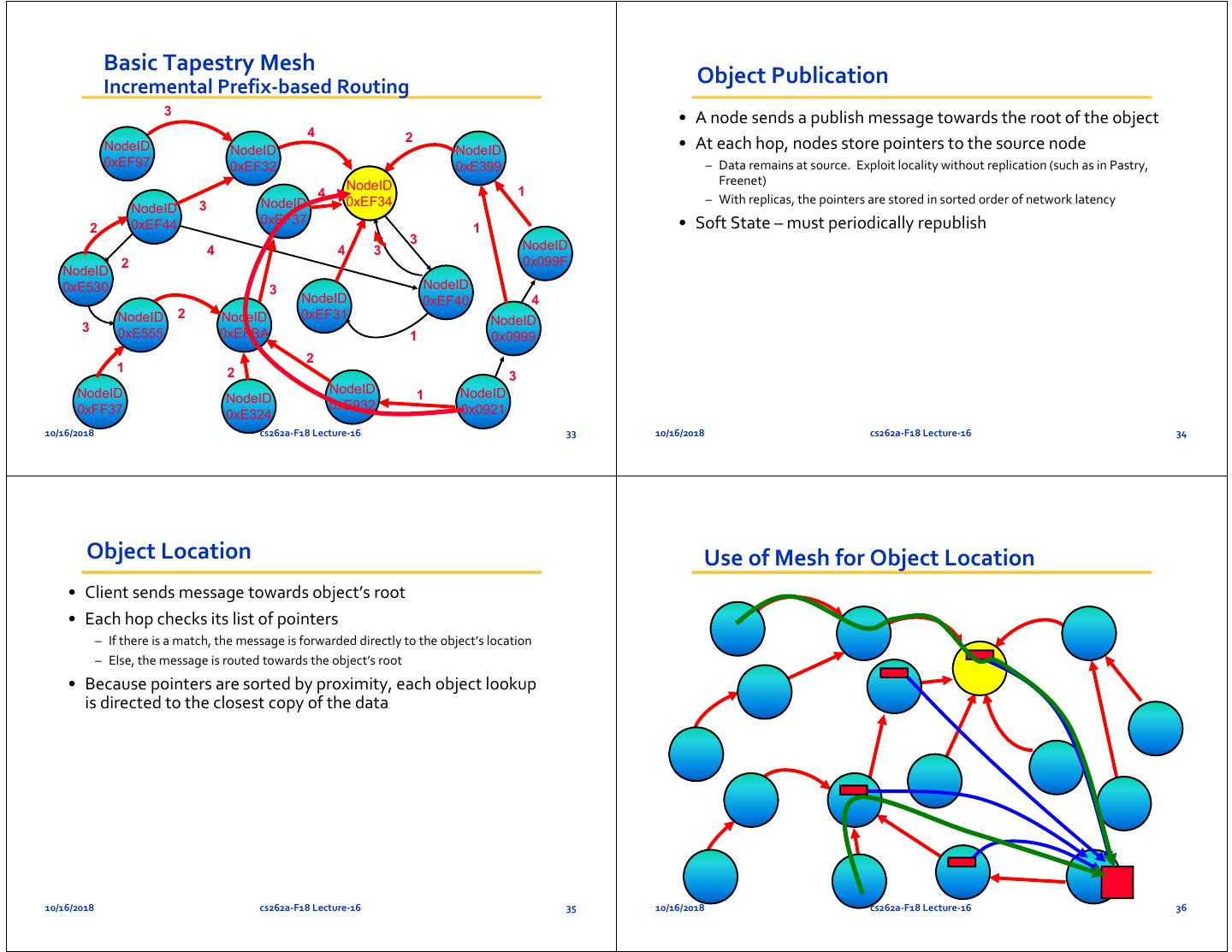
9 . Basic Tapestry Mesh Incremental Prefix‐based Routing Object Publication 3 • A node sends a publish message towards the root of the object 4 2 NodeID NodeID NodeID • At each hop, nodes store pointers to the source node 0xEF97 0xEF32 0xE399 – Data remains at source. Exploit locality without replication (such as in Pastry, NodeID Freenet) 4 1 3 NodeID 0xEF34 – With replicas, the pointers are stored in sorted order of network latency NodeID 0xEF44 0xEF37 • Soft State – must periodically republish 2 1 3 NodeID 4 4 3 2 0x099F NodeID 0xE530 3 NodeID NodeID 0xEF40 4 NodeID 2 NodeID 0xEF31 NodeID 3 0xE555 0xEFBA 1 0x0999 2 1 2 3 NodeID NodeID 1 NodeID NodeID 0xFF37 0xE932 0x0921 0xE324 10/16/2018 cs262a‐F18 Lecture‐16 33 10/16/2018 cs262a‐F18 Lecture‐16 34 Object Location Use of Mesh for Object Location • Client sends message towards object’s root • Each hop checks its list of pointers – If there is a match, the message is forwarded directly to the object’s location – Else, the message is routed towards the object’s root • Because pointers are sorted by proximity, each object lookup is directed to the closest copy of the data 10/16/2018 cs262a‐F18 Lecture‐16 35 10/16/2018 cs262a‐F18 Lecture‐16 36
10 . Node Insertions Node Deletions • A insertion for new node N must accomplish the following: • Voluntary – All nodes that have null entries for N need to be alerted of N’s presence – Backpointer nodes are notified, which fix their routing tables and » Acknowledged muliticast from the “root” node of N’s ID to visit all nodes republish objects with the common prefix – N may become the new root for some objects. Move those pointers • Involuntary during the muliticast – Periodic heartbeats: detection of failed link initiates mesh repair – N must build its routing table (to clean up routing tables) » All nodes contacted during muliticast contact N and become its neighbor – Soft state publishing: object pointers go away if not republished set (to clean up object pointers) » Iterative nearest neighbor search based on neighbor set – Nodes near N might want to use N in their routing tables as an • Discussion Point: Node insertions/deletions + heartbeats optimization + soft state republishing = network overhead. Is it » Also done during iterative search acceptable? What are the tradeoffs? 10/16/2018 cs262a‐F18 Lecture‐16 37 10/16/2018 cs262a‐F18 Lecture‐16 38 Tapestry Architecture Experimental Results (I) • 3 environments – Local cluster, PlanetLab, Simulator OceanStore, etc • Micro‐benchmarks on local cluster – Message processing overhead deliver(), » Proportional to processor speed ‐ Can utilize Moore’s Law forward(), route(), etc. – Message throughput » Optimal size is 4KB Tier 0/1: Routing, Object Location Connection Mgmt TCP, UDP • Prototype implemented using Java 10/16/2018 cs262a‐F18 Lecture‐16 39 10/16/2018 cs262a‐F18 Lecture‐16 40
11 . Experimental Results (II) Object Location with Tapestry • Routing/Object location tests – Routing overhead (PlanetLab) » About twice as long to route through overlay vs IP – Object location/optimization (PlanetLab/Simulator) » Object pointers significantly help routing to close objects • Network Dynamics – Node insertion overhead (PlanetLab) » Sublinear latency to stabilization » O(LogN) bandwidth consumption • RDP (Relative Delay Penalty) – Node failures, joins, churn (PlanetLab/Simulator) – Under 2 in the wide area » Brief dip in lookup success rate followed by quick return to near 100% success rate – More trouble in local area – (why?) » Churn lookup rate near 100% • Optimizations: – More pointers (in neighbors, etc) – Detect wide‐area links and make sure that pointers on exit nodes to wide area 10/16/2018 cs262a‐F18 Lecture‐16 41 10/16/2018 cs262a‐F18 Lecture‐16 42 Possibilities for DOLR? Stability under extreme circumstances • Original Tapestry – Could be used to route to data or endpoints with locality (not routing to IP addresses) – Self adapting to changes in underlying system • Pastry – Similarities to Tapestry, now in nth generation release – Need to build locality layer for true DOLR • Bamboo – Similar to Pastry – very stable under churn • Other peer‐to‐peer options – Coral: nice stable system with course‐grained locality – Chord: very simple system with locality optimizations (May 2003: 1.5 TB over 4 hours) DOLR Model generalizes to many simultaneous apps 10/16/2018 cs262a‐F18 Lecture‐16 43 10/16/2018 cs262a‐F18 Lecture‐16 44
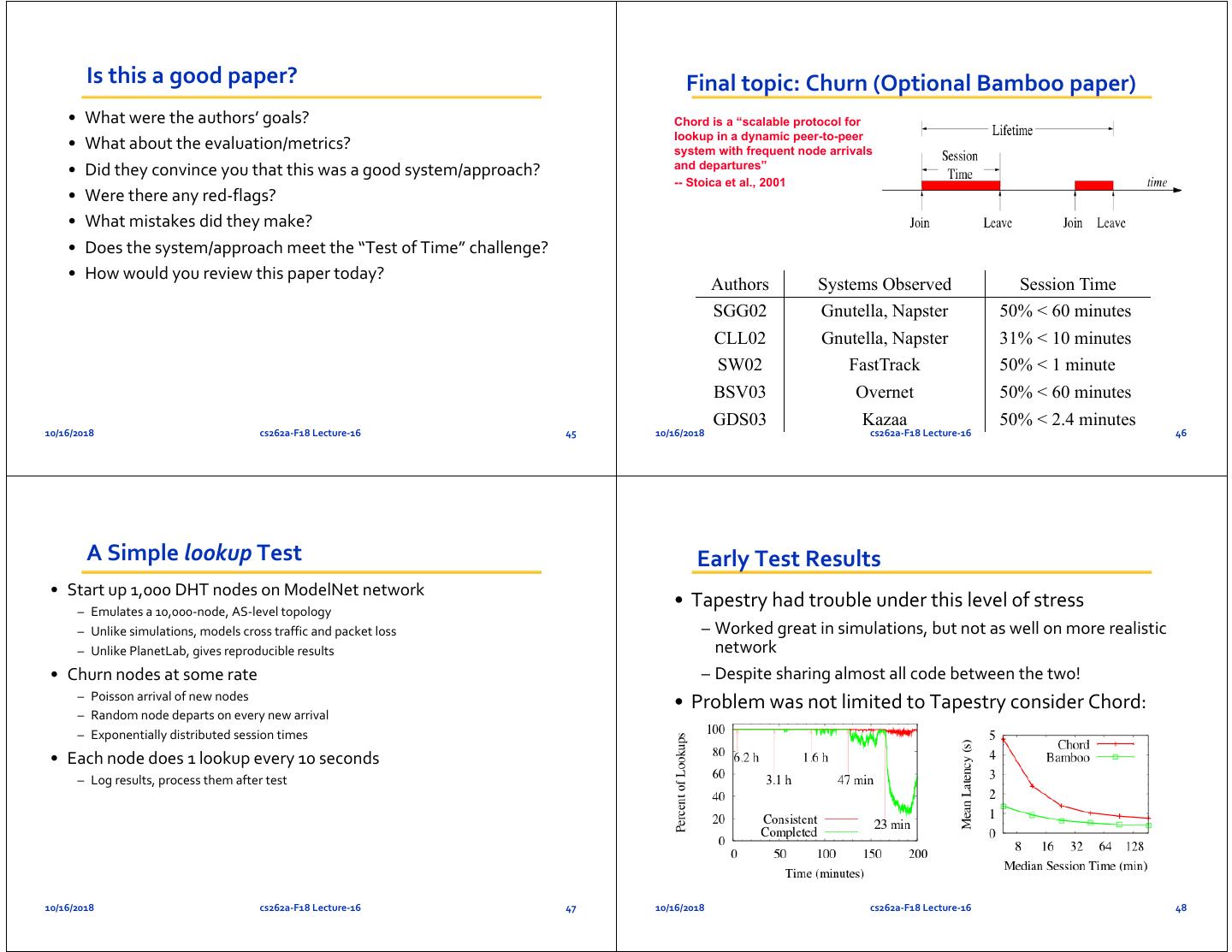
12 . Is this a good paper? Final topic: Churn (Optional Bamboo paper) • What were the authors’ goals? Chord is a “scalable protocol for lookup in a dynamic peer-to-peer • What about the evaluation/metrics? system with frequent node arrivals • Did they convince you that this was a good system/approach? and departures” -- Stoica et al., 2001 • Were there any red‐flags? • What mistakes did they make? • Does the system/approach meet the “Test of Time” challenge? • How would you review this paper today? Authors Systems Observed Session Time SGG02 Gnutella, Napster 50% < 60 minutes CLL02 Gnutella, Napster 31% < 10 minutes SW02 FastTrack 50% < 1 minute BSV03 Overnet 50% < 60 minutes GDS03 Kazaa 50% < 2.4 minutes 10/16/2018 cs262a‐F18 Lecture‐16 45 10/16/2018 cs262a‐F18 Lecture‐16 46 A Simple lookup Test Early Test Results • Start up 1,000 DHT nodes on ModelNet network – Emulates a 10,000‐node, AS‐level topology • Tapestry had trouble under this level of stress – Unlike simulations, models cross traffic and packet loss – Worked great in simulations, but not as well on more realistic – Unlike PlanetLab, gives reproducible results network • Churn nodes at some rate – Despite sharing almost all code between the two! – Poisson arrival of new nodes • Problem was not limited to Tapestry consider Chord: – Random node departs on every new arrival – Exponentially distributed session times • Each node does 1 lookup every 10 seconds – Log results, process them after test 10/16/2018 cs262a‐F18 Lecture‐16 47 10/16/2018 cs262a‐F18 Lecture‐16 48
13 . Handling Churn in a DHT Reactive Recovery: The obvious technique • Forget about comparing different impls. • For correctness, maintain leaf set during churn – Too many differing factors – Also routing table, but not needed for correctness – Hard to isolate effects of any one feature • The Basics • Implement all relevant features in one DHT – Ping new nodes before adding them – Using Bamboo (similar to Pastry) – Periodically ping neighbors • Isolate important issues in handling churn – Remove nodes that don’t respond 1. Recovering from failures • Simple algorithm 2. Routing around suspected failures – After every change in leaf set, send to all neighbors 3. Proximity neighbor selection – Called reactive recovery 10/16/2018 cs262a‐F18 Lecture‐16 49 10/16/2018 cs262a‐F18 Lecture‐16 50 The Problem With Reactive Recovery Periodic Recovery • Periodically send whole leaf • Under churn, many pings and change messages set to a random member – If bandwidth limited, interfere with each other – Breaks feedback loop – Lots of dropped pings looks like a failure – Converges in O(log N) • Respond to failure by sending more messages • Back off period on message – Probability of drop goes up loss – We have a positive feedback cycle (squelch) – Makes a negative feedback cycle • Can break cycle two ways (damping) 1. Limit probability of “false suspicions of failure” 2. Recovery periodically 10/16/2018 cs262a‐F18 Lecture‐16 51 10/16/2018 cs262a‐F18 Lecture‐16 52
14 . Conclusions/Recommendations • Avoid positive feedback cycles in recovery – Beware of “false suspicions of failure” – Recover periodically rather than reactively • Route around potential failures early – Don’t wait to conclude definite failure – TCP‐style timeouts quickest for recursive routing – Virtual‐coordinate‐based timeouts not prohibitive • PNS can be cheap and effective – Only need simple random sampling 10/16/2018 cs262a‐F18 Lecture‐16 53
3秒后跳转登录页面
去登陆

