










- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
22 C-Store/DB-Cracking
Column Stores
C-Store: A Column-oriented DBMS
Database Cracking
展开查看详情
1 . Today’s Papers EECS 262a • C-Store: A Column-oriented DBMS* Mike Stonebraker, Daniel J. Abadi, Adam Batkin, Xuedong Chen, Mitch Advanced Topics in Computer Systems Cherniack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Lecture 22 Elizabeth O’Neil, Pat O’Neil, Alex Rasin, Nga Tran, Stan Zdonik. Appears in Proceedings of the ACM Conference on Very Large Databases(VLDB), 2005 • Database Cracking+ C-Store / DB Cracking Stratos Idreos, Martin L. Kersten, and Stefan Manegold. Appears in the November 8th, 2018 3rd Biennial Conference on Innovative Data Systems Research (CIDR), January 7-10, 2007 John Kubiatowicz • Wednesday: Comparison of PDBMS, CS, MR Electrical Engineering and Computer Sciences University of California, Berkeley • Thoughts? http://www.eecs.berkeley.edu/~kubitron/cs262 *Some slides based on slides from Jianlin Feng, School of Software, Sun Yat-Sen University +Some slides based on slides from Stratos Idreos, CWI Amsterdam, The Netherlands 11/08/2018 cs262a-F18 Lecture-22 2 Relational Data: Logical View C-Store: A Column-oriented DBMS • Physical layout: Row store or Column store Name Age Department Salary Record 1 Bob 25 Math 10K Bill 27 EECS 50K Column Column Column Jill 24 Biology 80K Record 2 1 2 3 Record 3 Relation or Tables 11/08/2018 cs262a-F18 Lecture-22 3 11/08/2018 cs262a-F18 Lecture-22 4
2 . Row Stores Row Store: Columns Stored Together Data Rid = (i,N) • On-Line Transaction Processing (OLTP) Page i – ATM, POS in supermarkets Rid = (i,2) Rid = (i,1) • Characteristics of OLTP applications: – Transactions that involve small numbers of records (or tuples) – Frequent updates (including queries) – Many users – Fast response times 20 16 24 N Pointer N ... 2 1 # slots to start Slot • OLTP needs a write-optimized row store of free Array SLOT DIRECTORY – Insert and delete a record in one physical write space Record id = <page id, slot #> • Easy to add new record, but might read unnecessary data (wasted memory and I/O bandwidth) 11/08/2018 cs262a-F18 Lecture-22 5 11/08/2018 cs262a-F18 Lecture-22 6 Current DBMS Gold Standard OLAP and Data Warehouses • Store columns from one record contiguously on disk • On-Line Analytical Processing (OLAP) – Flexible reporting for Business Intelligence • Use B-tree indexing • Characteristics of OLAP applications – Transactions that involve large numbers of records • Use small (e.g. 4K) disk blocks – Frequent Ad-hoc queries and infrequent updates – A few decision-making users – Fast response times • Align fields on byte or word boundaries • Data Warehouses facilitate reporting and analysis – Read-Mostly • Conventional (row-oriented) query optimizer and executor (technology from 1979) • Other read-mostly applications – Customer Relationship Management (Siebel, Oracle) • Aries-style transactions – Catalog Search in E-Commerce (Amazon.com, Bestbuy.com) 11/08/2018 cs262a-F18 Lecture-22 7 11/08/2018 cs262a-F18 Lecture-22 8
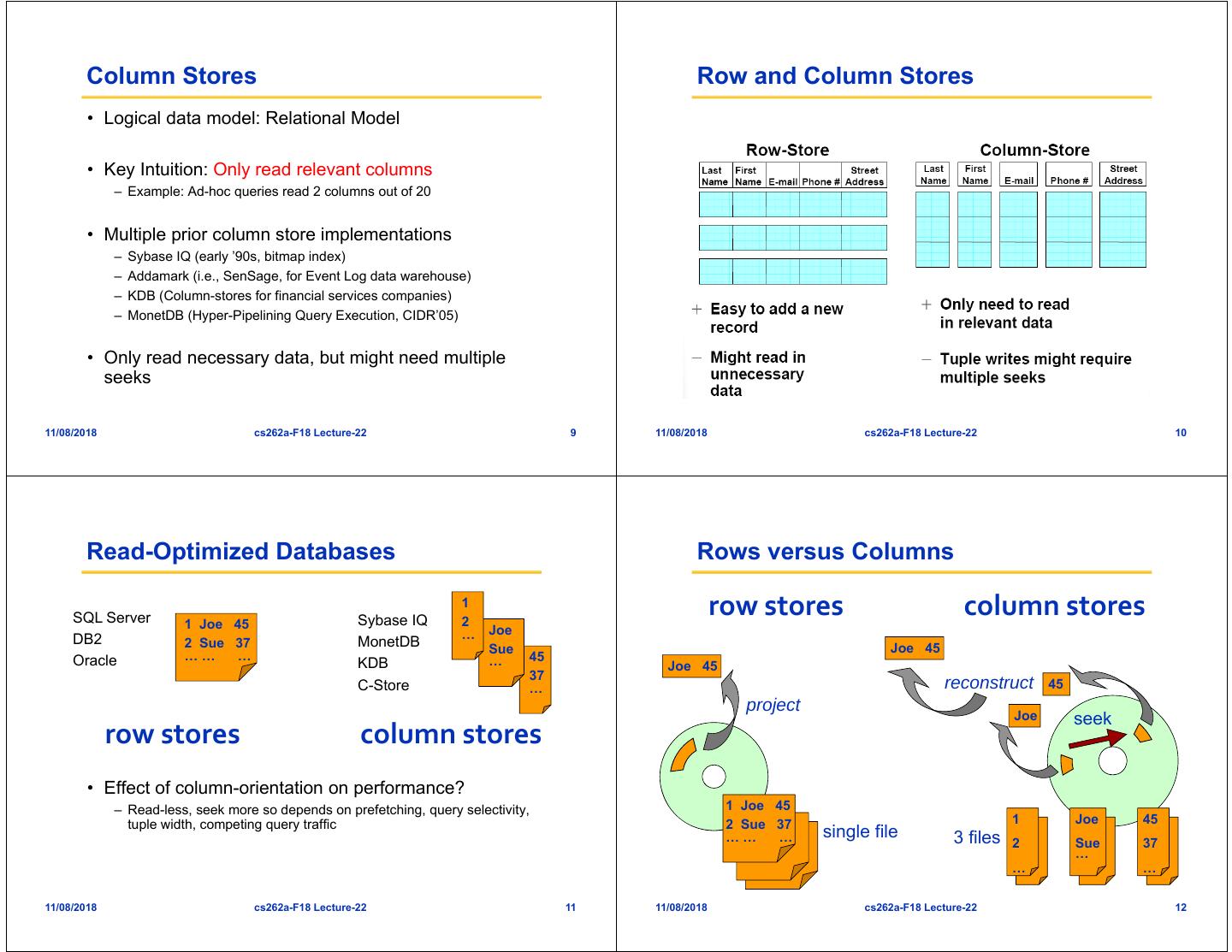
3 . Column Stores Row and Column Stores • Logical data model: Relational Model • Key Intuition: Only read relevant columns – Example: Ad-hoc queries read 2 columns out of 20 • Multiple prior column store implementations – Sybase IQ (early ’90s, bitmap index) – Addamark (i.e., SenSage, for Event Log data warehouse) – KDB (Column-stores for financial services companies) – MonetDB (Hyper-Pipelining Query Execution, CIDR’05) • Only read necessary data, but might need multiple seeks 11/08/2018 cs262a-F18 Lecture-22 9 11/08/2018 cs262a-F18 Lecture-22 10 Read-Optimized Databases Rows versus Columns SQL Server 1 Joe 45 Sybase IQ 1 2 row stores column stores DB2 … Joe 2 Sue 37 MonetDB Sue Joe 45 Oracle …… … … 45 KDB Joe 45 37 C-Store … reconstruct 45 project Joe seek row stores column stores • Effect of column-orientation on performance? – Read-less, seek more so depends on prefetching, query selectivity, 1 Joe 45 tuple width, competing query traffic 2 Sue 37 1 Joe 45 …… … single file 3 files 2 Sue 37 … … … 11/08/2018 cs262a-F18 Lecture-22 11 11/08/2018 cs262a-F18 Lecture-22 12
4 . C-Store Technical Ideas Architecture of Vertica C-Store • Column Store with some “novel” ideas (below) • Only materialized views on each relation (perhaps many) Writeable Store (WS) • Active data compression Tuple Mover Read-optimized Store (RS) • Column-oriented query Read-optimized Store (RS) Read-optimized Store (RS) executor and optimizer Read-optimized Store (RS) • Shared-nothing architecture • Replication-based concurrency control and recovery 11/08/2018 cs262a-F18 Lecture-22 13 11/08/2018 cs262a-F18 Lecture-22 14 Basic Concepts Example C-Store Projection • A logical table is physically represented as a set of • LINEITEM(shipdate, quantity, retflag, projections suppkey | shipdate, quantity, retflag) – First sorted by shipdate • Each projection consists of a set of columns – Second sorted by quantity – Columns are stored separately, along with a common sort order defined by SORT KEY – Third sorted by retflag • Each column appears in at least one projection • Sorting increases locality of data – Favors compression techniques such as Run- • A column can have different sort orders if it is stored Length Encoding (see Elephant paper) in multiple projections 11/08/2018 cs262a-F18 Lecture-22 15 11/08/2018 cs262a-F18 Lecture-22 16
5 . C-Store Operators Example: Join over Two Columns • Selection – Produce bitmaps that can be efficiently combined • Mask – Materialize a set of values from a column and a bitmap • Permute – Reorder a column using a join index • Projection – Free operation! – Two columns in the same order can be concatenated for free • Join – Produces positions rather than values 11/08/2018 cs262a-F18 Lecture-22 17 11/08/2018 cs262a-F18 Lecture-22 18 Column Store has High Compressibility Compression Methods • Each attribute is stored in a separate column … ‘low’ … … 00 … – Related values are compressible (versus values of separate attributes) • Dictionary … ‘high’ … … 10 … … ‘low’ … … 00 … … ‘normal’ … … 01 … • Compression benefits – Reduces the data sizes • Bit-pack – Improves disk (and memory) I/O performance by: – Pack several attributes inside a 4-byte word » reducing seek times (related data stored nearer together) – Use as many bits as max-value » reducing transfer times (less data to read/write) » increasing buffer hit rate (buffer can hold larger fraction of data) • Delta – Base value per page – Arithmetic differences • No Run-Length Encoding (unlike Elephant paper) 11/08/2018 cs262a-F18 Lecture-22 19 11/08/2018 cs262a-F18 Lecture-22 20
6 . C-Store Use of Snapshot Isolation Other Ideas • Snapshot Isolation for Fast OLAP/Data Warehousing • K-safety: Can handle up to K-1 failures – Allows very fast transactions without locks – Every piece of data replicated K times – Can read large consistent snapshot of database – Different projections sorted in different ways • Divide into RS and WS stores • Join Tables – Read Store is Optimized for Fast Read-Only Transactions – Construct original tuples given covering projects – Write Store is Optimized for Transactional Updates – Vertica gave up on Join Tables – too expensive, require super-projections • Low Water Mark (LWM) – Represents earliest epoch at which read-only transactions can run – RS contains tuples added before LWM • High Water Mark (HWM) – Represents latest epoch at which read-only transactions can run 11/08/2018 cs262a-F18 Lecture-22 21 11/08/2018 cs262a-F18 Lecture-22 22 Evaluation? Summary • Columns outperform rows in listed workloads – Reasons: » Column representation avoids reads of unused attributes » Query operators operate on compressed representation, mitigating storage barrier problem » Avoids memory-bandwidth bottleneck in rows • Storing overlapping projections, rather than the • Series of 7 queries against C-Store vs two commercial DBMS whole table allows storage of multiple orderings of a – C-Store faster In all cases, sometimes significantly column as appropriate • Why so much faster? • Better compression of data allows more orderings in – Column Representation – avoid extra reads the same space – Overlapping projections – multiple orderings of column as appropriate • Results from other papers: – Better data compression – Prefetching is key to columns outperforming rows – Query operators operating on compressed data – Systems with competing traffic favor columns 11/08/2018 cs262a-F18 Lecture-22 23 11/08/2018 cs262a-F18 Lecture-22 24
7 . Is this a good paper? • What were the authors’ goals? • What about the evaluation/metrics? • Did they convince you that this was a good system/approach? • Were there any red-flags? BREAK • What mistakes did they make? • Does the system/approach meet the “Test of Time” challenge? • How would you review this paper today? 11/08/2018 cs262a-F18 Lecture-22 25 DB Physical Organization Problem Timeline • Many DBMS perform well and efficiently only • Sample workload after being tuned by a DBA • Analyze performance • DBA decides: – Which indexes to build? • Prepare estimated physical design – On which data parts? – and when to build them? • Queries Very complex and time consuming process! What about: • Dynamic, changing workloads? • Very Large Databases? 11/08/2018 cs262a-F18 Lecture-22 27 11/08/2018 cs262a-F18 Lecture-22 28
8 . Database Cracking Database Cracking • Solve challenges of dynamic environments: • No monitoring – Remove all tuning and physical design steps, but still get • No preparation similar performance as a fully tuned system • No external tools • How? • No full indexes • No human involvement • Design new auto-tuning kernels – DBA with cracking (operators, plans, structures, etc.) • Continuous on-the-fly physical reorganization – Partial, incremental, adaptive indexing • Designed for modern column-stores 11/08/2018 cs262a-F18 Lecture-22 29 11/08/2018 cs262a-F18 Lecture-22 30 Cracking Example Cracking Design • Each query is treated as an advice on how data should be stored • The first time a range query is posed on an attribute – Triggers physical re‐organization of the database A, a cracking DBMS makes a copy of column A, Column A called the cracker column of A 13 • A cracker column is continuously physically re- 16 organized based on queries that need to touch 4 attribute such as the result is in a contiguous space Q1: select * from R 9 where R.A > 10 2 • For each cracker column, there is a cracker index 12 and R.A < 14 7 1 19 3 14 11 8 6 11/08/2018 cs262a-F18 Lecture-22 31 11/08/2018 cs262a-F18 Lecture-22 32
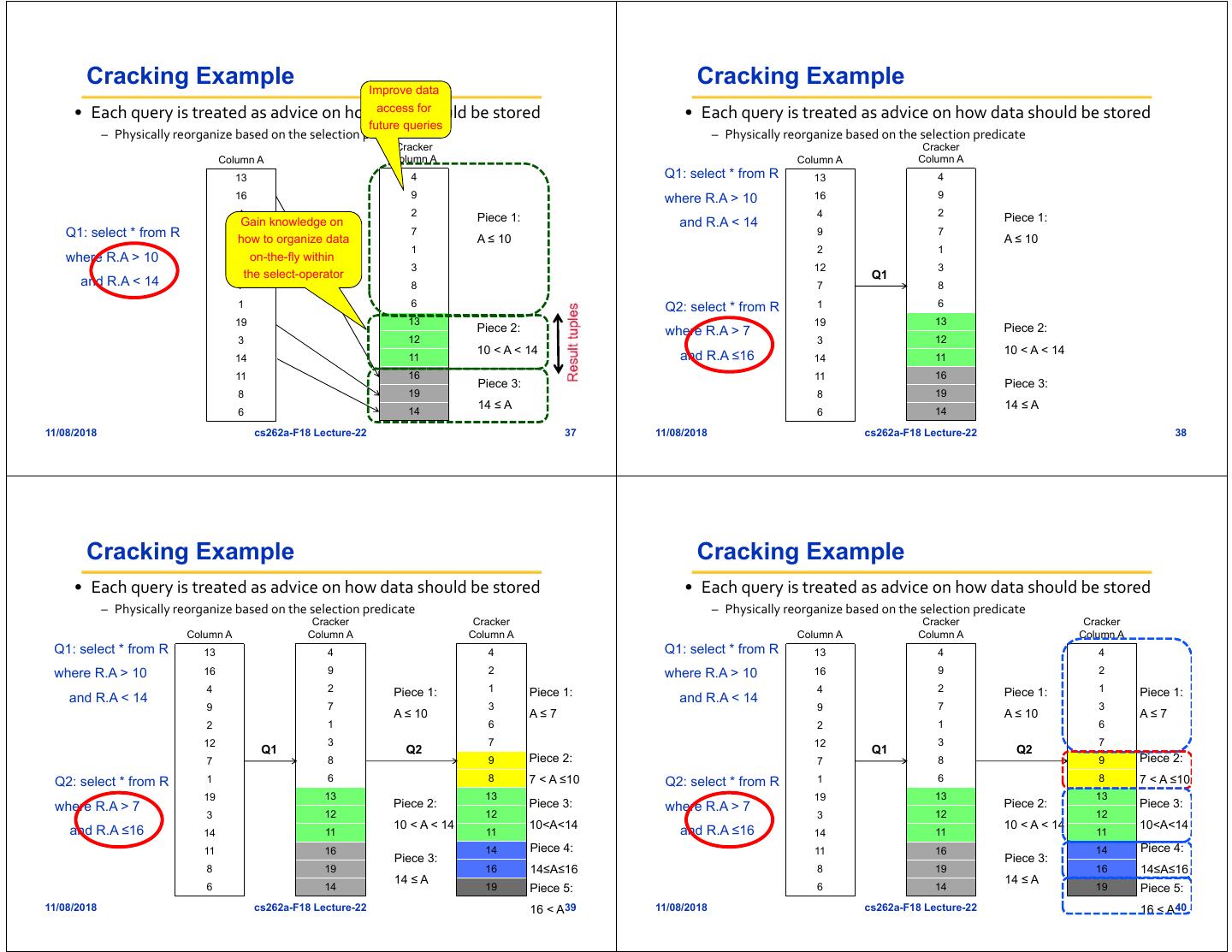
9 . Cracking Algorithms Cracker Select Operator • Two types of cracking algorithms based on select’s • Traditional select operator where clause – Scans the column where X < # where # < X < # – Returns a new column that contains the qualifying values Split a piece into Split a piece into two new pieces three new pieces • The cracker select operator – Searches the cracker index – Physically re-organizes the pieces found – Updates the cracker index – Returns a slice of the cracker column as the result • More steps but faster because analyzes less data 11/08/2018 cs262a-F18 Lecture-22 33 11/08/2018 cs262a-F18 Lecture-22 34 Cracking Example Cracking Example • Each query is treated as advice on how data should be stored • Each query is treated as advice on how data should be stored – Physically reorganize based on the selection predicate – Physically reorganize based on the selection predicate Cracker Cracker Column A Column A Column A Column A 13 4 13 4 16 9 16 9 4 2 Piece 1: 4 2 Piece 1: Q1: select * from R 9 7 A ≤ 10 Q1: select * from R 9 7 A ≤ 10 2 1 2 1 where R.A > 10 where R.A > 10 12 3 12 3 and R.A < 14 7 8 and R.A < 14 7 8 1 6 1 6 19 13 19 13 Piece 2: Piece 2: 3 12 3 12 10 < A < 14 10 < A < 14 14 11 14 11 11 16 11 16 Piece 3: Piece 3: 8 19 8 19 14 ≤ A 14 ≤ A 6 14 6 14 11/08/2018 cs262a-F18 Lecture-22 35 11/08/2018 cs262a-F18 Lecture-22 36
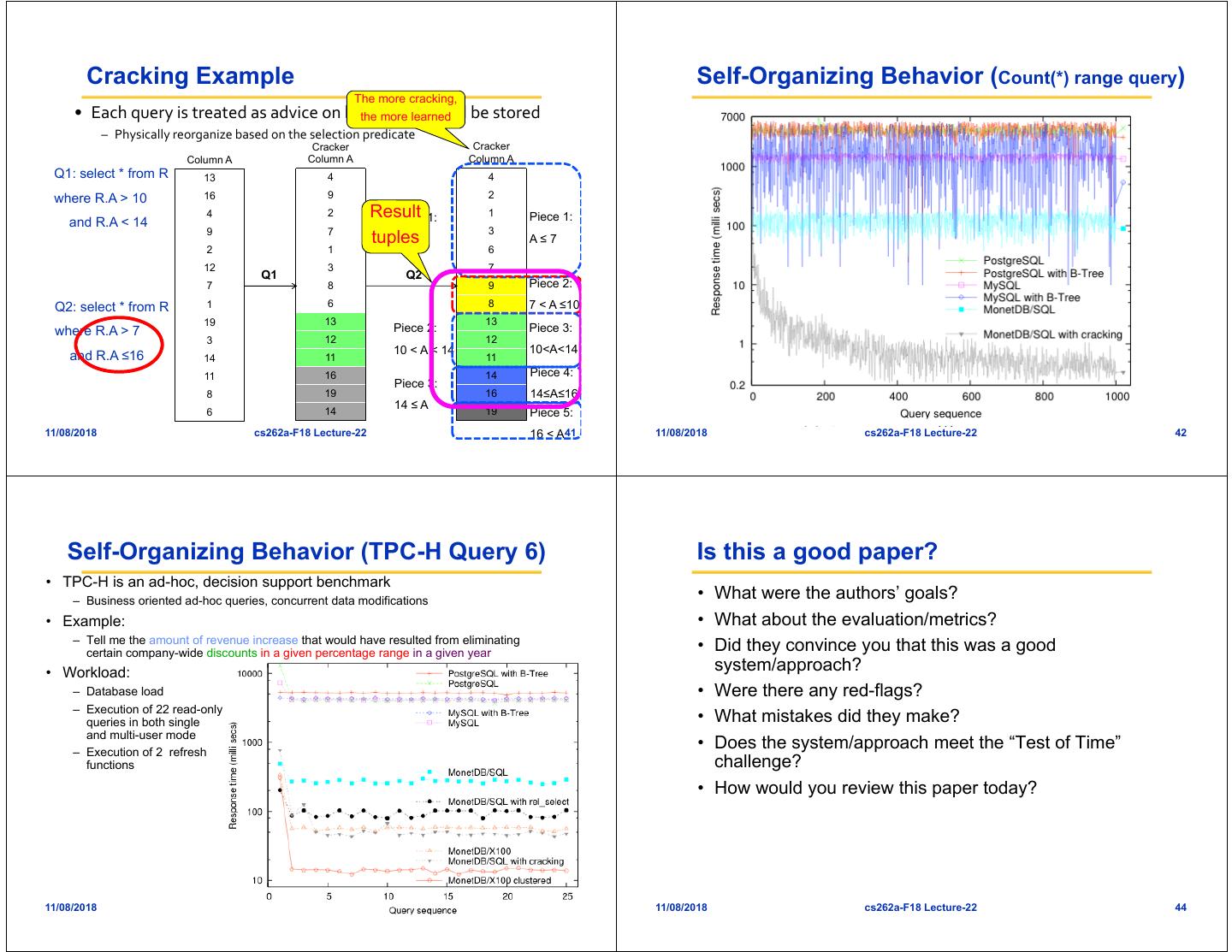
10 . Cracking Example Improve data Cracking Example access for • Each query is treated as advice on how data should be stored • Each query is treated as advice on how data should be stored future queries – Physically reorganize based on the selection predicate – Physically reorganize based on the selection predicate Cracker Cracker Column A Column A Column A Column A 13 4 Q1: select * from R 13 4 16 9 where R.A > 10 16 9 4 2 Piece 1: 4 2 Piece 1: Gain knowledge on and R.A < 14 Q1: select * from R 9 how to organize data 7 A ≤ 10 9 7 A ≤ 10 2 1 2 1 where R.A > 10 on-the-fly within 12 3 12 3 the select-operator Q1 and R.A < 14 7 8 7 8 1 6 Q2: select * from R 1 6 19 13 19 13 Piece 2: where R.A > 7 Piece 2: 3 12 3 12 10 < A < 14 10 < A < 14 14 11 and R.A ≤16 14 11 11 16 11 16 Piece 3: Piece 3: 8 19 8 19 14 ≤ A 14 ≤ A 6 14 6 14 11/08/2018 cs262a-F18 Lecture-22 37 11/08/2018 cs262a-F18 Lecture-22 38 Cracking Example Cracking Example • Each query is treated as advice on how data should be stored • Each query is treated as advice on how data should be stored – Physically reorganize based on the selection predicate – Physically reorganize based on the selection predicate Cracker Cracker Cracker Cracker Column A Column A Column A Column A Column A Column A Q1: select * from R 13 4 4 Q1: select * from R 13 4 4 where R.A > 10 16 9 2 where R.A > 10 16 9 2 4 2 Piece 1: 1 Piece 1: 4 2 Piece 1: 1 Piece 1: and R.A < 14 and R.A < 14 9 7 3 9 7 3 A ≤ 10 A≤7 A ≤ 10 A≤7 2 1 6 2 1 6 12 3 7 12 3 7 Q1 Q2 Q1 Q2 7 8 9 Piece 2: 7 8 9 Piece 2: Q2: select * from R 1 6 8 7 < A ≤10 Q2: select * from R 1 6 8 7 < A ≤10 19 13 13 19 13 13 where R.A > 7 Piece 2: Piece 3: where R.A > 7 Piece 2: Piece 3: 3 12 12 3 12 12 10 < A < 14 10<A<14 10 < A < 14 10<A<14 and R.A ≤16 14 11 11 and R.A ≤16 14 11 11 11 16 14 Piece 4: 11 16 14 Piece 4: Piece 3: Piece 3: 8 19 16 14≤A≤16 8 19 16 14≤A≤16 14 ≤ A 14 ≤ A 6 14 19 Piece 5: 6 14 19 Piece 5: 11/08/2018 cs262a-F18 Lecture-22 16 < A39 11/08/2018 cs262a-F18 Lecture-22 16 < A40
11 . Cracking Example Self-Organizing Behavior (Count(*) range query) The more cracking, • Each query is treated as advice on how data should be stored the more learned – Physically reorganize based on the selection predicate Cracker Cracker Column A Column A Column A Q1: select * from R 13 4 4 where R.A > 10 16 9 2 4 2 Result Piece 1: 1 Piece 1: and R.A < 14 9 7 3 tuples A ≤ 10 A≤7 2 1 6 12 3 7 Q1 Q2 7 8 9 Piece 2: Q2: select * from R 1 6 8 7 < A ≤10 19 13 13 where R.A > 7 Piece 2: Piece 3: 3 12 12 10 < A < 14 10<A<14 and R.A ≤16 14 11 11 11 16 14 Piece 4: Piece 3: 8 19 16 14≤A≤16 14 ≤ A 6 14 19 Piece 5: 11/08/2018 cs262a-F18 Lecture-22 16 < A41 11/08/2018 cs262a-F18 Lecture-22 42 Self-Organizing Behavior (TPC-H Query 6) Is this a good paper? • TPC-H is an ad-hoc, decision support benchmark – Business oriented ad-hoc queries, concurrent data modifications • What were the authors’ goals? • Example: • What about the evaluation/metrics? – Tell me the amount of revenue increase that would have resulted from eliminating certain company-wide discounts in a given percentage range in a given year • Did they convince you that this was a good • Workload: system/approach? – Database load • Were there any red-flags? – Execution of 22 read-only queries in both single • What mistakes did they make? and multi-user mode – Execution of 2 refresh • Does the system/approach meet the “Test of Time” functions challenge? • How would you review this paper today? 11/08/2018 cs262a-F18 Lecture-22 43 11/08/2018 cs262a-F18 Lecture-22 44
3秒后跳转登录页面
去登陆

