














- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Squeeze-and-Excitation Networks
The central building block of convolutional neural networks (CNNs) is the convolution operator, which enables networks to construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer. A broad range of prior research has investigated the spatial component of this relationship, seeking to strengthen the representational power of a CNN by enhancing the quality of spatial encodings throughout its feature hierarchy. In this work, we focus instead on the channel relationship and propose a novel architectural unit, which we term the “Squeeze-and-Excitation” (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We show that these blocks can be stacked together to form SENet architectures that generalise extremely effectively across different datasets. We further demonstrate that SE blocks bring significant improvements in performance for existing state-of-the-art CNNs at minimal additional computational cost. Squeeze-and-Excitation Networks formed the foundation of our ILSVRC 2017 classification submission which won first place and reduced the top- 5 error to 2.251% , surpassing the winning entry of 2016 by a relative improvement of ∼25% . Models and code are available at https://github.com/hujie-frank/SENet.
展开查看详情
1 . 1 Squeeze-and-Excitation Networks Jie Hu[0000−0002−5150−1003] Li Shen[0000−0002−2283−4976] Samuel Albanie[0000−0001−9736−5134] Gang Sun[0000−0001−6913−6799] Enhua Wu[0000−0002−2174−1428] Abstract—The central building block of convolutional neural networks (CNNs) is the convolution operator, which enables networks to construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer. A broad range of prior research has investigated the spatial component of this relationship, seeking to strengthen the representational power of a CNN by enhancing the quality of spatial encodings throughout its feature hierarchy. In this work, we focus instead on the channel relationship and propose a novel architectural unit, which we term the “Squeeze-and-Excitation” (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We show that these blocks can be stacked together to form SENet architectures that generalise extremely effectively across different datasets. We further demonstrate arXiv:1709.01507v3 [cs.CV] 25 Oct 2018 that SE blocks bring significant improvements in performance for existing state-of-the-art CNNs at minimal additional computational cost. Squeeze-and-Excitation Networks formed the foundation of our ILSVRC 2017 classification submission which won first place and reduced the top-5 error to 2.251%, surpassing the winning entry of 2016 by a relative improvement of ∼25%. Models and code are available at https://github.com/hujie-frank/SENet. Index Terms—Squeeze-and-Excitation, Image classification, Convolutional Neural Network. ✦ 1 I NTRODUCTION C ONVOLUTIONAL neural networks (CNNs) have proven to be useful models for tackling a wide range of visual tasks [1]–[4]. At each convolutional layer in the of representations produced by a network by explicitly modelling the interdependencies between the channels of its convolutional features. To this end, we propose a mecha- network, a collection of filters expresses neighbourhood nism that allows the network to perform feature recalibration, spatial connectivity patterns along input channels—fusing through which it can learn to use global information to spatial and channel-wise information together within local selectively emphasise informative features and suppress less receptive fields. By interleaving a series of convolutional useful ones. layers with non-linear activation functions and downsam- The structure of the SE building block is depicted in pling operators, CNNs are able to produce robust represen- Fig. 1. For any given transformation Ftr : X → U, tations that capture hierarchical patterns and attain global X ∈ RH ×W ×C , U ∈ RH×W ×C , (e.g. a convolution), we theoretical receptive fields. Recent research has shown that can construct a corresponding SE block to perform feature these representations can be strengthened by integrating recalibration. The features U are first passed through a learning mechanisms into the network that help capture squeeze operation, which produces a channel descriptor by spatial correlations between features. One such approach, aggregating feature maps across their spatial dimensions popularised by the Inception family of architectures [5], [6], (H × W ). The function of this descriptor is to produce incorporates multi-scale processes into network modules to an embedding of the global distribution of channel-wise achieve improved performance. Further work has sought to feature responses, allowing information from the global better model spatial dependencies [7], [8] and incorporate receptive field of the network to be used by all its layers. The spatial attention into the structure of the network [9]. aggregation is followed by an excitation operation, which In this paper, we investigate a different aspect of network takes the form of a simple self-gating mechanism that takes design - the relationship between channels. We introduce the embedding as input and produces a collection of per- a new architectural unit, which we term the Squeeze-and- channel modulation weights. These weights are applied to Excitation (SE) block, with the goal of improving the quality the feature maps U to generate the output of the SE block which can be fed directly into subsequent layers of the network. • Jie Hu and Enhua Wu are with the State Key Laboratory of Computer Science, Institute of Software, Chinese Academy of Sciences, Beijing, It is possible to construct an SE network (SENet) by 100190, China. simply stacking a collection of SE blocks. Moreover, these They are also with the University of Chinese Academy of Sciences, Beijing, SE blocks can also be used as a drop-in replacement for 100049, China. Jie Hu is also with Momenta and Enhua Wu is also with the University the original block at a range of depths in the network of Macau. architecture (Sec. 6.4). While the template for the building E-mail: hujie@ios.ac.cn ehwu@umac.mo block is generic, the role it performs at different depths • Gang Sun is with LIAMA-NLPR at the CAS Institute of Automation and differs throughout the network. In earlier layers, it excites Momenta. E-mail: sungang@momenta.ai informative features in a class-agnostic manner, strengthen- • Li Shen and Samuel Albanie are with the Visual Geometry Group at the ing the shared low-level representations. In later layers, the University of Oxford. SE blocks become increasingly specialised, and respond to E-mail: {lishen,albanie}@robots.ox.ac.uk different inputs in a highly class-specific manner (Sec. 7.2).
2 . 2 Fig. 1. A Squeeze-and-Excitation block. As a consequence, the benefits of the feature recalibration be achieved with multi-branch convolutions [5], [6], [20], performed by SE blocks can be accumulated through the [21], which can be viewed as a natural extension of the network. grouping operator. In prior work, cross-channel correlations The design and development of new CNN architectures are typically mapped as new combinations of features, ei- is a difficult engineering task, typically requiring the se- ther independently of spatial structure [22], [23] or jointly lection of many new hyperparameters and layer configura- by using standard convolutional filters [24] with 1 × 1 tions. By contrast, the structure of the SE block is simple and convolutions. Much of this research has concentrated on the can be used directly in existing state-of-the-art architectures objective of reducing model and computational complexity, by replacing components with their SE counterparts, where reflecting an assumption that channel relationships can be the performance can be effectively enhanced. SE blocks are formulated as a composition of instance-agnostic functions also computationally lightweight and impose only a slight with local receptive fields. In contrast, we claim that provid- increase in model complexity and computational burden. ing the unit with a mechanism to explicitly model dynamic, To provide evidence for these claims, in Sec. 4 we de- non-linear dependencies between channels using global in- velop several SENets and conduct an extensive evaluation formation can ease the learning process, and significantly on the ImageNet 2012 dataset [10]. We also present results enhance the representational power of the network. beyond ImageNet that indicate that the benefits of our Algorithmic Architecture Search. Alongside the works approach are not restricted to a specific dataset or task. described above, there is also a rich history of research By making use of SENets, we ranked first in the ILSVRC that aims to forgo manual architecture design and instead 2017 classification competition. Our best model ensemble seeks to learn the structure of the network automatically. achieves a 2.251% top-5 error on the test set1 . This repre- Much of the early work in this domain was conducted in sents roughly a 25% relative improvement when compared the neuro-evolution community, which established methods to the winner entry of the previous year (top-5 error of for searching across network topologies with evolutionary 2.991%). methods [25], [26]. While often computationally demand- ing, evolutionary search has had notable successes which 2 R ELATED W ORK include finding good memory cells for sequence models Deeper architectures. VGGNets [11] and Inception mod- [27], [28] and learning sophisticated architectures for large- els [5] showed that increasing the depth of a network could scale image classification [29]–[31]. With the goal of reduc- significantly increase the quality of representations that ing the computational burden of these methods, efficient it was capable of learning. By regulating the distribution alternatives to this approach have been proposed based on of the inputs to each layer, Batch Normalization (BN) [6] Lamarckian inheritance [32] and differentiable architecture added stability to the learning process in deep networks search [33]. and produced smoother optimisation surfaces [12]. Building By formulating architecture search as hyperparameter on these works, ResNets demonstrated that it was pos- optimisation, random search [34] and other more sophis- sible to learn considerably deeper and stronger networks ticated model-based optimisation techniques [35], [36] can through the use of identity-based skip connections [13], [14]. also be used to tackle the problem. Topology selection Highway networks [15] introduced a gating mechanism to as a path through a fabric of possible designs [37] and regulate the flow of information along shortcut connections. direct architecture prediction [38], [39] have been proposed Following these works, there have been further reformula- as additional viable architecture search tools. Particularly tions of the connections between network layers [16], [17], strong results have been achieved with techniques from which show promising improvements to the learning and reinforcement learning [40]–[44]. SE blocks can be used as representational properties of deep networks. atomic building blocks for these search algorithms, and An alternative, but closely related line of research has were demonstrated to be highly effective in this capacity focused on methods to improve the functional form of in concurrent work [45]. the computational elements contained within a network. Grouped convolutions have proven to be a popular ap- Attention and gating mechanisms. Attention can be in- proach for increasing the cardinality of learned transforma- terpreted as a means of biasing the allocation of available tions [18], [19]. More flexible compositions of operators can computational resources towards the most informative com- ponents of a signal [46]–[51]. Attention mechanisms have 1. http://image-net.org/challenges/LSVRC/2017/results demonstrated their utility across many tasks including se-
3 . 3 quence learning [52], [53], localisation and understanding in channel-wise statistics. Formally, a statistic z ∈ RC is gener- images [9], [54], image captioning [55], [56] and lip reading ated by shrinking U through its spatial dimensions H × W , [57]. In these applications, it can be incorporated as an oper- such that the c-th element of z is calculated by: ator following one or more layers representing higher-level H W 1 abstractions for adaptation between modalities. Concurrent zc = Fsq (uc ) = uc (i, j). (2) work provides an interesting study into the combined use of H ×W i=1 j=1 spatial and channel attention around convolutional [58] and Discussion. The output of the transformation U can be bottleneck units [59]. Wang et al. [60] introduced a powerful interpreted as a collection of the local descriptors whose trunk-and-mask attention mechanism based on hourglass statistics are expressive for the whole image. Exploiting modules [8] that is inserted between the intermediate stages such information is prevalent in prior feature engineering of deep residual networks. By contrast, our proposed SE work [61]–[63]. We opt for the simplest aggregation tech- block comprises a lightweight gating mechanism which nique, global average pooling, noting that more sophisti- focuses on enhancing the representational power of the cated strategies could be employed here as well. network by modelling channel-wise relationships in a com- putationally efficient manner. 3.2 Excitation: Adaptive Recalibration To make use of the information aggregated in the squeeze 3 S QUEEZE - AND -E XCITATION B LOCKS operation, we follow it with a second operation which aims to fully capture channel-wise dependencies. To fulfil this The Squeeze-and-Excitation block is a computational unit objective, the function must meet two criteria: first, it must which can be constructed for any given transformation be flexible (in particular, it must be capable of learning U = Ftr (X), X ∈ RH ×W ×C , U ∈ RH×W ×C . For sim- a nonlinear interaction between channels) and second, it plicity, in the notation that follows we take Ftr to be a must learn a non-mutually-exclusive relationship since we convolutional operator. Let V = [v1 , v2 , . . . , vC ] denote would like to ensure that multiple channels are allowed to the learned set of filter kernels, where vc refers to the be emphasised (rather than enforcing a one-hot activation). parameters of the c-th filter. We can then write the outputs To meet these criteria, we opt to employ a simple gating of Ftr as U = [u1 , u2 , . . . , uC ], where mechanism with a sigmoid activation: C s = Fex (z, W) = σ(g(z, W)) = σ(W2 δ(W1 z)), (3) uc = vc ∗ X = vcs ∗ xs . (1) C s=1 where δ refers to the ReLU [64] function, W1 ∈ R ×C and r C W2 ∈ RC× r . To limit model complexity and aid general- Here ∗ denotes convolution, vc = [vc1 , vc2 , . . . , vcC ], X = isation, we parameterise the gating mechanism by forming [x1 , x2 , . . . , xC ] (to simplify the notation, bias terms are a bottleneck with two fully connected (FC) layers around omitted) and vcs is a 2D spatial kernel representing a single the non-linearity, i.e. a dimensionality-reduction layer with channel of vc that acts on the corresponding channel of X. parameters W1 and reduction ratio r (this parameter choice Since the output is produced by a summation through all is discussed in Sec. 6.1), a ReLU and then a dimensionality- channels, channel dependencies are implicitly embedded in increasing layer with parameters W2 . The final output of vc , but are entangled with the local spatial correlation cap- the block is obtained by rescaling the transformation output tured by the filters. As a consequence, the channel relation- U with the activations: ships modelled by convolution are inherently local. Since our goal is to ensure that the network is able to increase xc = Fscale (uc , sc ) = sc · uc , (4) its sensitivity to informative features so that they can be exploited by subsequent transformations most effectively, where X = [x1 , x2 , . . . , xC ] and Fscale (uc , sc ) refers to we would like to provide it with access to global infor- channel-wise multiplication between the scalar sc and the mation. We propose to achieve this by explicitly modelling feature map uc ∈ RH×W . channel interdependencies to recalibrate filter responses in Discussion. The excitation operator maps the input- two steps, squeeze and excitation, before they are fed into the specific descriptor z to a set of channel specific weights. next transformation, described next. A diagram illustrating In this regard, SE blocks intrinsically introduce dynamics the structure of an SE block is shown in Fig. 1. conditioned on the input, helping to boost feature discrim- inability. 3.1 Squeeze: Global Information Embedding 3.3 Instantiations In order to tackle the issue of exploiting channel depen- The SE block can be integrated into standard architectures dencies, we first consider the signal to each channel in the such as VGGNet [11] by insertion after the non-linearity output features. Each of the learned filters operates with following each convolution. Moreover, the flexibility of the a local receptive field and consequently each unit of the SE block means that it can be directly applied to transforma- transformation output U is unable to exploit contextual tions beyond standard convolutions. To illustrate this point, information outside of this region. we develop SENets by incorporating SE blocks into several To mitigate this problem, we propose to squeeze global examples of more complex architectures, described next. spatial information into a channel descriptor. This is We first consider the construction of SE blocks for Incep- achieved by using global average pooling to generate tion networks [5]. Here, we simply take the transformation
4 . 4 4 M ODEL AND C OMPUTATIONAL C OMPLEXITY X X For the proposed SE block design to be of practical use, it Inception Inception must offer a good trade-off between improved performance 𝐻×W×C X and increased model complexity. We set the reduction ratio Global pooling r (introduced in Sec. 3.2) to 16 in all experiments, except Inception Module 1×1×C FC C where stated otherwise (an ablation study of this design 1×1× 𝑟 decision is provided in Sec. 6.1). To illustrate the compu- ReLU C 1×1× 𝑟 tational burden associated with the module, we consider FC a comparison between ResNet-50 and SE-ResNet-50 as an 1×1×C example. ResNet-50 requires ∼3.86 GFLOPs in a single Sigmoid 1×1×C forward pass for a 224 × 224 pixel input image. Each SE block makes use of a global average pooling operation in Scale 𝐻×W×C the squeeze phase and two small fully connected layers in X the excitation phase, followed by an inexpensive channel- SE-Inception Module wise scaling operation. In aggregate, SE-ResNet-50 requires ∼3.87 GFLOPs, corresponding to a 0.26% relative increase Fig. 2. The schema of the original Inception module (left) and the SE- Inception module (right). over the original ResNet-50. In exchange for this slight addi- tional computational burden, the accuracy of SE-ResNet-50 surpasses that of ResNet-50 and indeed, approaches that of a deeper ResNet-101 network requiring ∼7.58 GFLOPs X X (Table 2). Residual Residual In practical terms, a single pass forwards and backwards 𝐻×W×C through ResNet-50 takes 190 ms, compared to 209 ms for + Global pooling 1×1×C SE-ResNet-50 with a training minibatch of 256 images (both X timings are performed on a server with 8 NVIDIA Titan X FC C 1×1× GPUs). We suggest that this represents a reasonable runtime ResNet Module 𝑟 ReLU 1×1× C overhead, which may be further reduced as global pooling 𝑟 and small inner-product operations receive further opti- FC 1×1×C misation in popular GPU libraries. Due to its importance Sigmoid for embedded device applications, we further benchmark 1×1×C CPU inference time for each model: for a 224 × 224 pixel Scale 𝐻×W×C input image, ResNet-50 takes 164 ms in comparison to 167 + 𝐻×W×C ms for SE-ResNet-50. We believe that the small additional X computational cost incurred by the SE block is justified by SE-ResNet Module its contribution to model performance. We next consider the additional parameters introduced Fig. 3. The schema of the original Residual module (left) and the SE- ResNet module (right). by the proposed SE block. These additional parameters result solely from the two fully-connected layers of the gating mechanism and therefore constitute a small fraction of the total network capacity. Concretely, the total number of Ftr to be an entire Inception module (see Fig. 2) and by mak- additional parameters introduced by the proposed approach ing this change for each such module in the architecture, we is given by: S obtain an SE-Inception network. SE blocks can also be used 2 Ns · Cs 2 , (5) directly with residual networks (Fig. 3 depicts the schema r s=1 of an SE-ResNet module). Here, the SE block transformation where r denotes the reduction ratio, S refers to the number Ftr is taken to be the non-identity branch of a residual of stages (a stage refers to the collection of blocks operating module. Squeeze and Excitation both act before summation on feature maps of a common spatial dimension), Cs de- with the identity branch. Further variants that integrate SE notes the dimension of the output channels and Ns denotes blocks with ResNeXt [19], Inception-ResNet [21], MobileNet the number of repeated blocks for stage s. SE-ResNet-50 [65] and ShuffleNet [66] can be constructed by following introduces ∼2.5 million additional parameters beyond the similar schemes (Sec. 5.1). For concrete examples of SENet ∼25 million parameters required by ResNet-50, correspond- architectures, a detailed description of SE-ResNet-50 and ing to a ∼10% increase. In practice, the majority of these SE-ResNeXt-50 is given in Table 1. parameters come from the final stage of the network, where One consequence of the flexible nature of the SE block the excitation operation is performed across the greatest is that there are several viable ways in which it could number of channels. However, we found that this compara- be integrated into these architectures. Therefore, to assess tively costly final stage of SE blocks could be removed at sensitivity to the integration strategy used to incorporate SE only a small cost in performance (<0.1% top-5 error on blocks into a network architecture, we also provide ablation ImageNet) reducing the relative parameter increase to ∼4%, experiments exploring different designs for block inclusion which may prove useful in cases where parameter usage is in Sec. 6.5. a key consideration (see Sec. 7.2 for further discussion).
5 . 5 TABLE 1 (Left) ResNet-50. (Middle) SE-ResNet-50. (Right) SE-ResNeXt-50 with a 32×4d template. The shapes and operations with specific parameter settings of a residual building block are listed inside the brackets and the number of stacked blocks in a stage is presented outside. The inner brackets following by fc indicates the output dimension of the two fully connected layers in an SE module. Output size ResNet-50 SE-ResNet-50 SE-ResNeXt-50 (32 × 4d) 112 × 112 conv, 7 × 7, 64, stride 2 max pool, 3× 3, stride 2 56 × 56 conv, 1 × 1, 64 conv, 1 × 1, 128 conv, 1 × 1, 64 conv, 3 × 3, 64 conv, 3 × 3, 128 C = 32 conv, 3 × 3, 64 × 3 conv, 1 × 1, 256 × 3 ×3 conv, 1 × 1, 256 conv, 1 × 1, 256 f c, [16, 256] f c, [16, 256] conv, 1 × 1, 128 conv, 1 × 1, 256 conv, 1 × 1, 128 conv, 3 × 3, 128 conv, 3 × 3, 256 C = 32 28 × 28 conv, 3 × 3, 128 × 4 conv, 1 × 1, 512 × 4 ×4 conv, 1 × 1, 512 conv, 1 × 1, 512 f c, [32, 512] f c, [32, 512] conv, 1 × 1, 256 conv, 1 × 1, 512 conv, 1 × 1, 256 conv, 3 × 3, 256 conv, 3 × 3, 512 conv, 3 × 3, 256 × 6 C = 32 14 × 14 conv, 1 × 1, 1024 × 6 conv, 1 × 1, 1024 ×6 conv, 1 × 1, 1024 f c, [64, 1024] f c, [64, 1024] conv, 1 × 1, 512 conv, 1 × 1, 1024 conv, 1 × 1, 512 conv, 3 × 3, 512 conv, 3 × 3, 1024 C = 32 7×7 conv, 3 × 3, 512 × 3 conv, 1 × 1, 2048 × 3 ×3 conv, 1 × 1, 2048 conv, 1 × 1, 2048 f c, [128, 2048] f c, [128, 2048] 1×1 global average pool, 1000-d f c, softmax TABLE 2 Single-crop error rates (%) on the ImageNet validation set and complexity comparisons. The original column refers to the results reported in the original papers. To enable a fair comparison, we re-train the baseline models and report the scores in the re-implementation column. The SENet column refers to the corresponding architectures in which SE blocks have been added. The numbers in brackets denote the performance improvement over the re-implemented baselines. † indicates that the model has been evaluated on the non-blacklisted subset of the validation set (this is discussed in more detail in [21]), which may slightly improve results. VGG-16 and SE-VGG-16 are trained with batch normalization. original re-implementation SENet top-1 err. top-5 err. top-1 err. top-5 err. GFLOPs top-1 err. top-5 err. GFLOPs ResNet-50 [13] 24.7 7.8 24.80 7.48 3.86 23.29(1.51) 6.62(0.86) 3.87 ResNet-101 [13] 23.6 7.1 23.17 6.52 7.58 22.38(0.79) 6.07(0.45) 7.60 ResNet-152 [13] 23.0 6.7 22.42 6.34 11.30 21.57(0.85) 5.73(0.61) 11.32 ResNeXt-50 [19] 22.2 - 22.11 5.90 4.24 21.10(1.01) 5.49(0.41) 4.25 ResNeXt-101 [19] 21.2 5.6 21.18 5.57 7.99 20.70(0.48) 5.01(0.56) 8.00 VGG-16 [11] - - 27.02 8.81 15.47 25.22(1.80) 7.70(1.11) 15.48 BN-Inception [6] 25.2 7.82 25.38 7.89 2.03 24.23(1.15) 7.14(0.75) 2.04 Inception-ResNet-v2 [21] 19.9† 4.9† 20.37 5.21 11.75 19.80(0.57) 4.79(0.42) 11.76 TABLE 3 Single-crop error rates (%) on the ImageNet validation set and complexity comparisons. MobileNet refers to “1.0 MobileNet-224” in [65] and ShuffleNet refers to “ShuffleNet 1 × (g = 3)” in [66]. The numbers in brackets denote the performance improvement over the re-implementation. original re-implementation SENet top-1 err. top-5 err. top-1 err. top-5 err. MFLOPs Params top-1 err. top-5 err. MFLOPs Params MobileNet [65] 29.4 - 29.1 10.1 569 4.2M 25.3(3.8) 7.9(2.2) 572 4.7M ShuffleNet [66] 32.6 - 32.6 12.5 140 1.8M 31.0(1.6) 11.1(1.4) 142 2.4M 5 E XPERIMENTS data augmentation with random cropping [5] to a size of In this section, we conduct experiments to investigate the 224 × 224 pixels (or 299 × 299 for Inception-ResNet-v2 [21] effectiveness of SE blocks across a range of tasks, datasets and SE-Inception-ResNet-v2) and perform random horizon- and model architectures. tal flipping. Each input image is normalised through mean RGB-channel subtraction. We adopt the data balancing strat- 5.1 Image Classification egy described in [67] for minibatch sampling. All models are trained on our distributed learning system ROCS which To evaluate the influence of SE blocks, we first perform is designed to handle efficient parallel training of large experiments on the ImageNet 2012 dataset [10] which networks. Optimisation is performed using synchronous comprises 1.28 million training images and 50K validation SGD with momentum 0.9 and a minibatch size of 1024. images from 1000 different classes. We train networks on The initial learning rate is set to 0.6 and decreased by a the training set and report the top-1 and top-5 error on the factor of 10 every 30 epochs. All models are trained for 100 validation set. epochs from scratch, using the weight initialisation strategy Each original network architecture and its correspond- described in [68]. ing SE counterpart are trained with identical optimisa- tion schemes. We follow standard practices and perform When evaluating the models we apply centre-cropping
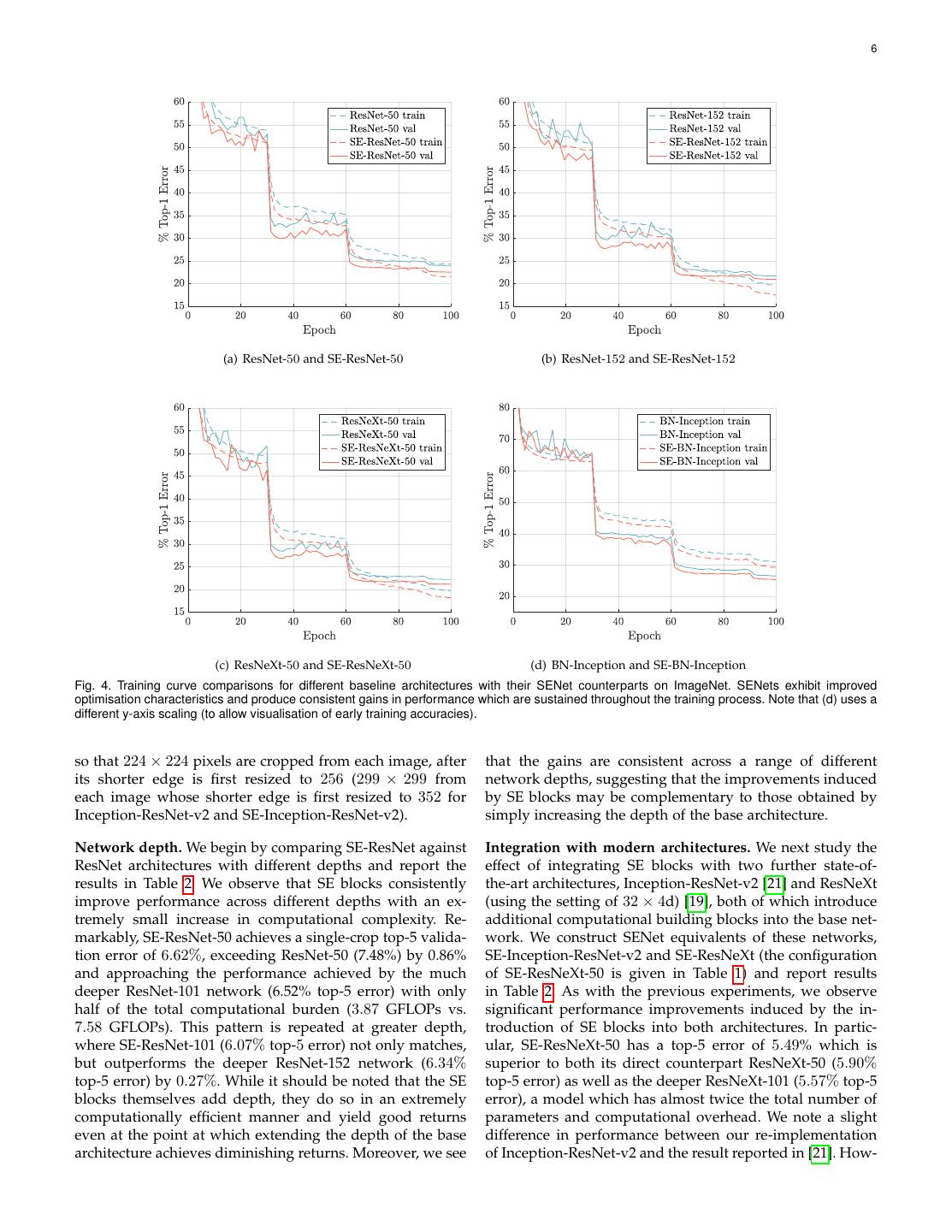
6 . 6 (a) ResNet-50 and SE-ResNet-50 (b) ResNet-152 and SE-ResNet-152 (c) ResNeXt-50 and SE-ResNeXt-50 (d) BN-Inception and SE-BN-Inception Fig. 4. Training curve comparisons for different baseline architectures with their SENet counterparts on ImageNet. SENets exhibit improved optimisation characteristics and produce consistent gains in performance which are sustained throughout the training process. Note that (d) uses a different y-axis scaling (to allow visualisation of early training accuracies). so that 224 × 224 pixels are cropped from each image, after that the gains are consistent across a range of different its shorter edge is first resized to 256 (299 × 299 from network depths, suggesting that the improvements induced each image whose shorter edge is first resized to 352 for by SE blocks may be complementary to those obtained by Inception-ResNet-v2 and SE-Inception-ResNet-v2). simply increasing the depth of the base architecture. Network depth. We begin by comparing SE-ResNet against Integration with modern architectures. We next study the ResNet architectures with different depths and report the effect of integrating SE blocks with two further state-of- results in Table 2. We observe that SE blocks consistently the-art architectures, Inception-ResNet-v2 [21] and ResNeXt improve performance across different depths with an ex- (using the setting of 32 × 4d) [19], both of which introduce tremely small increase in computational complexity. Re- additional computational building blocks into the base net- markably, SE-ResNet-50 achieves a single-crop top-5 valida- work. We construct SENet equivalents of these networks, tion error of 6.62%, exceeding ResNet-50 (7.48%) by 0.86% SE-Inception-ResNet-v2 and SE-ResNeXt (the configuration and approaching the performance achieved by the much of SE-ResNeXt-50 is given in Table 1) and report results deeper ResNet-101 network (6.52% top-5 error) with only in Table 2. As with the previous experiments, we observe half of the total computational burden (3.87 GFLOPs vs. significant performance improvements induced by the in- 7.58 GFLOPs). This pattern is repeated at greater depth, troduction of SE blocks into both architectures. In partic- where SE-ResNet-101 (6.07% top-5 error) not only matches, ular, SE-ResNeXt-50 has a top-5 error of 5.49% which is but outperforms the deeper ResNet-152 network (6.34% superior to both its direct counterpart ResNeXt-50 (5.90% top-5 error) by 0.27%. While it should be noted that the SE top-5 error) as well as the deeper ResNeXt-101 (5.57% top-5 blocks themselves add depth, they do so in an extremely error), a model which has almost twice the total number of computationally efficient manner and yield good returns parameters and computational overhead. We note a slight even at the point at which extending the depth of the base difference in performance between our re-implementation architecture achieves diminishing returns. Moreover, we see of Inception-ResNet-v2 and the result reported in [21]. How-
7 . 7 TABLE 4 TABLE 6 Classification error (%) on CIFAR-10. Single-crop error rates (%) on Places365 validation set. original SENet top-1 err. top-5 err. ResNet-110 [14] 6.37 5.21 Places-365-CNN [72] 41.07 11.48 ResNet-164 [14] 5.46 4.39 ResNet-152 (ours) 41.15 11.61 WRN-16-8 [69] 4.27 3.88 SE-ResNet-152 40.37 11.01 Shake-Shake 26 2x96d [70] + Cutout [71] 2.56 2.12 TABLE 7 TABLE 5 Faster R-CNN object detection results on MS COCO 40k validation set Classification error (%) on CIFAR-100. using different trunk architectures. original SENet AP@IoU=0.5 AP ResNet-110 [14] 26.88 23.85 ResNet-50 45.2 25.1 ResNet-164 [14] 24.33 21.31 SE-ResNet-50 46.8 26.4 WRN-16-8 [69] 20.43 19.14 ResNet-101 48.4 27.2 Shake-Even 29 2x4x64d [70] + Cutout [71] 15.85 15.41 SE-ResNet-101 49.2 27.9 ever, we observe a similar trend with regard to the effect of integration of SE blocks into these networks follows the SE blocks, finding that SE-Inception-ResNet-v2 (4.79% top-5 same approach that was described in Sec. 3.3. Each baseline error) outperforms our reimplemented Inception-ResNet-v2 and its SENet counterpart are trained with a standard data baseline (5.21% top-5 error) by 0.42% (a relative improve- augmentation strategy [24], [74]. During training, images ment of 8.1%) as well as the reported result in [21]. The are randomly horizontally flipped and zero-padded on each training curves for the baseline architectures ResNet-50, side with four pixels before taking a random 32 × 32 crop. ResNet-152, ResNeXt-50 and BN-Inception, and their re- Mean and standard deviation normalisation is also applied. spective SE counterparts are depicted in Fig. 4. We observe The setting of the training strategy and other hyperparam- that SE blocks yield a steady improvement throughout the eters (e.g. minibatch size, initial learning rate, number of optimisation procedure. Moreover, this trend is consistent epochs, weight decay) match those suggested by the authors across each of the families of state-of-the-art architectures of each model. We report the performance of each baseline considered as baselines. and its SENet counterpart on CIFAR-10 in Table 4 and per- We also assess the effect of SE blocks when operating formance on CIFAR-100 in Table 5. We observe that in every on non-residual networks by conducting experiments with comparison SENets outperform the baseline architectures, the VGG-16 [11] and BN-Inception architecture [6]. To fa- suggesting that the benefits of SE blocks are not confined to cilitate the training of VGG-16 from scratch, we add Batch the ImageNet dataset. Normalization layers after each convolution. As with the previous models, we use identical training schemes for both 5.2 Scene Classification VGG-16 and SE-VGG-16. The results of the comparison are We next conduct experiments on the Places365-Challenge shown in Table 2. Similarly to the results reported for the dataset [75] for scene classification. This dataset comprises residual baseline architectures, we observe that SE blocks 8 million training images and 36, 500 validation images bring improvements in performance. across 365 categories. Relative to classification, the task of Mobile setting. Finally, we consider two representative scene understanding offers an alternative assessment of a architectures from the class of mobile-optimised networks, model’s ability to generalise well and handle abstraction. MobileNet [65] and ShuffleNet [66]. For these experiments, This is because it often requires the model to handle more we used a minibatch size of 256 and a weight decay of complex data associations and to be robust to a greater level 4 × 10−5 . We trained the models across 8 GPUs using SGD of appearance variation. with momentum (set to 0.9) and an initial learning rate We opted to use ResNet-152 as a strong baseline to of 0.1 which was reduced by a factor of 10 each time the assess the effectiveness of SE blocks and carefully follow validation loss plateaued (rather than using a fixed-length the training and evaluation protocols described in [72]. In schedule). The total training process required ∼ 400 epochs these experiments, all models are trained from scratch. We (we found that this approach enabled us to reproduce the report the results in Table 6, comparing also with prior baseline performance of [66]). The results reported in Table 3 work. We observe that SE-ResNet-152 (11.01% top-5 error) show that SE blocks consistently improve the accuracy by a achieves a lower validation error than ResNet-152 (11.61% large margin at a minimal increase in computational cost. top-5 error), providing evidence that SE blocks can also yield improvements for scene classification. This SENet surpasses Additional datasets. We next investigate whether the bene- the previous state-of-the-art model Places-365-CNN [72] fits of SE blocks generalise to datasets beyond ImageNet. We which has a top-5 error of 11.48% on this task. perform experiments with several popular baseline archi- tectures and techniques (ResNet-110 [14], ResNet-164 [14], WideResNet-16-8 [69], Shake-Shake [70] and Cutout [71]) on 5.3 Object Detection on COCO the CIFAR-10 and CIFAR-100 datasets [73]. These comprise We further assess the generalisation of SE blocks on the a collection of 50k training and 10k test 32 × 32 pixel RGB task of object detection using the COCO dataset [76] which images, labelled with 10 and 100 classes respectively. The comprises 80k training images and 40k validation images,
8 . 8 TABLE 8 TABLE 10 Single-crop error rates (%) of state-of-the-art CNNs on ImageNet Single-crop error rates (%) on ImageNet validation set and parameter validation set with crop sizes 224 × 224 and 320 × 320 / 299 × 299. sizes for SE-ResNet-50 at different reduction ratios r. Here, original refers to ResNet-50. 224 × 224 320 × 320 / 299 × 299 Ratio r top-1 err. top-5 err. Params top-1 top-5 top-1 top-5 4 22.25 6.09 35.7M err. err. err. err. 8 22.26 5.99 30.7M ResNet-152 [13] 23.0 6.7 21.3 5.5 16 22.28 6.03 28.1M ResNet-200 [14] 21.7 5.8 20.1 4.8 Inception-v3 [20] - - 21.2 5.6 32 22.72 6.20 26.9M Inception-v4 [21] - - 20.0 5.0 original 23.30 6.55 25.6M Inception-ResNet-v2 [21] - - 19.9 4.9 ResNeXt-101 (64 × 4d) [19] 20.4 5.3 19.1 4.4 DenseNet-264 [17] 22.15 6.12 - - Attention-92 [60] - - 19.5 4.8 in Appendix). We compare this model with prior work on PyramidNet-200 [77] 20.1 5.4 19.2 4.7 the ImageNet validation set in Table 8 using standard crop DPN-131 [16] 19.93 5.12 18.55 4.16 sizes (224 × 224 and 320 × 320). We observe that SENet-154 SENet-154 18.68 4.47 17.28 3.79 achieves a top-1 error of 18.68% and a top-5 error of 4.47% using a 224 × 224 centre crop evaluation, which represents the strongest reported result. TABLE 9 Comparison (%) with state-of-the-art CNNs on ImageNet validation set Following the challenge there has been a great deal of using larger crop sizes/additional training data. † This model was further progress on the ImageNet benchmark. For compar- trained with a crop size of 320 × 320. ‡This model builds on the result ison, we include the strongest results that we are currently by [31] by introducing a new form of data augmentation. aware of among the both published and unpublished lit- extra crop top-1 top-5 erature in Table 9. The best performance using only Im- data size err. err. Very Deep PolyNet [78] - 331 18.71 4.25 ageNet data was recently reported by [79]. This method NASNet-A (6 @ 4032) [42] - 331 17.3 3.8 uses reinforcement learning to develop new polices for PNASNet-5 (N=4,F=216) [35] - 331 17.1 3.8 data augmentation during training to improve the perfor- AmoebaNet-C [31] - 331 16.9 3.7 mance of the architecture proposed by [31]. The best overall SENet-154† - 320 16.88 3.58 performance was reported by [80] using a ResNeXt-101 AmoebaNet-C‡ [79] - 331 16.46 3.52 32×48d architecture. This was achieved by pretraining their ResNeXt-101 32 × 48d [80] 224 14.6 2.4 model on approximately one billion weakly labelled images and finetuning on ImageNet. The improvements yielded by more sophisticated data augmentation [79] and extensive following the splits used in [13]. We use the Faster R-CNN pretraining [80] may be complementary to our proposed [4] detection framework as the basis for evaluating our changes to the network architecture. models and follow the basic implementation described in [13]. Our goal is to evaluate the effect of replacing the trunk architecture (ResNet) in the object detector with SE-ResNet, 6 A BLATION S TUDY so that any changes in performance can be attributed In this section we conduct ablation experiments to gain to better representations. Table 7 reports the validation a better understanding of the relative importance of com- set performance of the object detector using ResNet-50, ponents in the SE block design. All ablation experiments ResNet-101 and their SE counterparts as trunk architectures. are performed on the ImageNet dataset on a single ma- SE-ResNet-50 outperforms ResNet-50 by 1.3% (a relative chine (with 8 GPUs). ResNet-50 is used as the backbone 5.2% improvement) on COCO’s standard AP metric and by architecture. The data augmentation strategy follows the 1.6% on AP@IoU=0.5. SE blocks also bring improvements approach described in Sec. 5.1. To allow us to study the on the deeper ResNet-101 architecture achieving a 0.7% upper limit of performance for each variant, the learning improvement (or 2.6% relative improvement) on the AP rate is initialised to 0.1 and training continues until the metric. validation loss plateaus (rather than continuing for a fixed number of epochs). The learning rate is then reduced by a In summary, this set of experiments demonstrate that the factor of 10 and then this process is repeated (three times in improvements induced by SE blocks can be realised across total). a broad range of architectures, tasks and datasets. 6.1 Reduction ratio 5.4 ILSVRC 2017 Classification Competition The reduction ratio r introduced in Eqn. 5 is a hyperpa- SENets formed the foundation of our submission to the rameter which allows us to vary the capacity and compu- ILSVRC competition where we achieved first place. Our tational cost of the SE blocks in the network. To investigate winning entry comprised a small ensemble of SENets that the trade-off between performance and computational cost employed a standard multi-scale and multi-crop fusion mediated by this hyperparameter, we conduct experiments strategy to obtain a top-5 error of 2.251% on the test set. with SE-ResNet-50 for a range of different r values. The As part of this submission, we constructed an additional comparison in Table 10 shows that performance does not model, SENet-154, by integrating SE blocks with a modified improve monotonically with increased capacity, suggesting ResNeXt [19] (the details of the architecture are provided that with enough weights the SE block is able to overfit
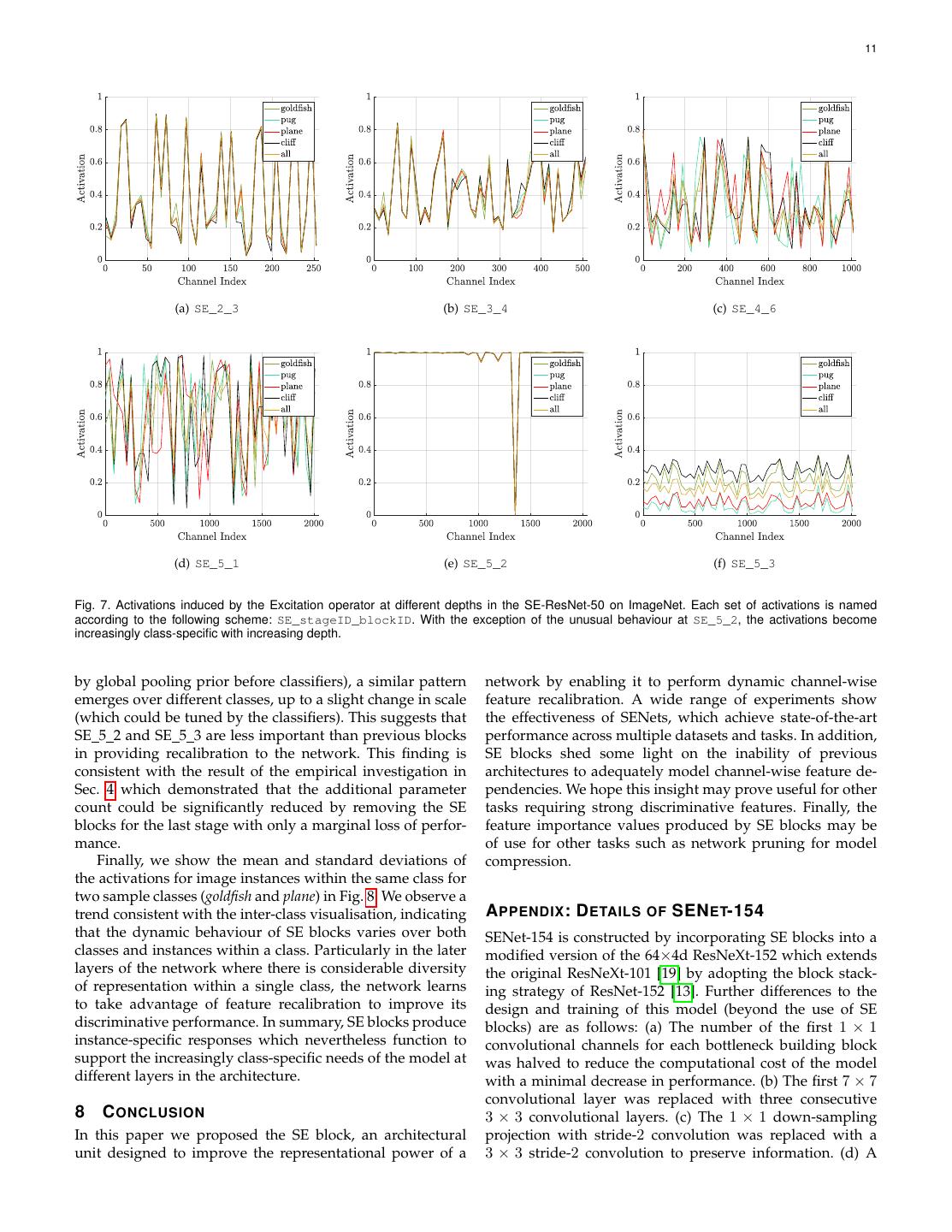
9 . 9 TABLE 11 TABLE 14 Effect of using different squeeze operators in SE-ResNet-50 on Effect of different SE block integration strategies with ResNet-50 on ImageNet (%). ImageNet (%). Squeeze top-1 err. top-5 err. Design top-1 err. top-5 err. Max 22.57 6.09 SE 22.28 6.03 Avg 22.28 6.03 SE-PRE 22.23 6.00 SE-POST 22.78 6.35 SE-Identity 22.20 6.15 TABLE 12 Effect of using different non-linearities for the excitation operator in SE-ResNet-50 on ImageNet (%). TABLE 15 Excitation top-1 err. top-5 err. Effect of integrating SE blocks at the 3x3 convolutional layer of each ReLU 23.47 6.98 residual branch in ResNet-50 on ImageNet (%). Tanh 23.00 6.38 Design top-1 err. top-5 err. GFLOPs Params Sigmoid 22.28 6.03 SE 22.28 6.03 3.87 28.1M SE 3×3 22.48 6.02 3.86 25.8M to the channel interdependencies of the training set. We found that setting r = 16 achieved a good balance between stage 2, stage 3 and stage 4, and report the results in Ta- accuracy and complexity and consequently, we used this ble 13. We observe that SE blocks bring performance benefits value for all experiments reported in this work. when introduced at each of these stages of the architecture. Moreover, the gains induced by SE blocks at different stages are complementary, in the sense that they can be combined 6.2 Squeeze Operator effectively to further bolster network performance. We examine the significance of using global average pooling as opposed to global max pooling as our choice of squeeze 6.5 Integration strategy operator (since this worked well, we did not consider more sophisticated alternatives). The results are reported in Ta- Finally, we perform an ablation study to assess the influence ble 11. While both max and average pooling are effective, of the location of the SE block when integrating it into exist- average pooling achieves slightly better performance, jus- ing architectures. In addition to the proposed SE design, we tifying its selection as the basis of the squeeze operation. consider three variants: (1) SE-PRE block, in which the SE However, we note that the performance of SE blocks is fairly block is moved before the residual unit; (2) SE-POST block, robust to the choice of specific aggregation operator. in which the SE unit is moved after the summation with the identity branch and (3) SE-Identity block, in which the SE unit is placed on the identity connection in parallel to the 6.3 Excitation Operator residual unit. These variants are illustrated in Figure 5 and We next assess the choice of non-linearity for the excitation the performance of each variant is reported in Table 14. We mechanism. We consider two further options: ReLU and observe that the SE-PRE, SE-Identity and proposed SE block tanh, and experiment with replacing the sigmoid with these each perform similarly well, while usage of the SE-POST alternative non-linearities. The results are reported in Ta- block leads to a drop in performance. This experiment ble 12. We see that exchanging the sigmoid for tanh slightly suggests that the performance improvements produced by worsens performance, while using ReLU is dramatically SE units are fairly robust to their location, provided that worse and in fact causes the performance of SE-ResNet-50 they are applied prior to branch aggregation. to drop below that of the ResNet-50 baseline. This suggests In the experiments above, each SE block was placed that for the SE block to be effective, careful construction of outside the structure of a residual unit. We also construct the excitation operator is important. a variant of the design which moves the SE block inside the residual unit, placing it directly after the 3 × 3 convo- lutional layer. Since the 3 × 3 convolutional layer possesses 6.4 Different stages fewer channels, the number of parameters introduced by the We explore the influence of SE blocks at different stages by corresponding SE block is also reduced. The comparison in integrating SE blocks into ResNet-50, one stage at a time. Table 15 shows that the SE 3×3 variant achieves comparable Specifically, we add SE blocks to the intermediate stages: classification accuracy with fewer parameters than the stan- dard SE block. Although it is beyond the scope of this work, we anticipate that further efficiency gains will be achievable TABLE 13 Effect of integrating SE blocks with ResNet-50 at different stages on by tailoring SE block usage for specific architectures. ImageNet (%). Stage top-1 err. top-5 err. GFLOPs Params 7 R OLE OF SE BLOCKS ResNet-50 23.30 6.55 3.86 25.6M Although the proposed SE block has been shown to improve SE Stage 2 23.03 6.48 3.86 25.6M SE Stage 3 23.04 6.32 3.86 25.7M network performance on multiple visual tasks, we would SE Stage 4 22.68 6.22 3.86 26.4M also like to understand the role of the squeeze operation and SE All 22.28 6.03 3.87 28.1M how the excitation mechanism operates in practice. Unfortu- nately, a rigorous theoretical analysis of the representations
10 . 10 Residual SE Residual SE Residual SE Residual Residual SE (a) Residual block (b) Standard SE block (c) SE-PRE block (d) SE-POST block (e) SE-Identity block Fig. 5. SE block integration designs explored in the ablation study. TABLE 16 Effect of Squeeze operator on ImageNet (%). top-1 err. top-5 err. GFLOPs Params ResNet-50 23.30 6.55 3.86 25.6M NoSqueeze 22.93 6.39 4.27 28.1M SE 22.28 6.03 3.87 28.1M (a) goldfish (b) pug (c) plane (d) cliff Fig. 6. Sample images from the four classes of ImageNet used in the experiments described in Sec. 7.2. learned by deep neural networks remains challenging. We therefore take an empirical approach to examining the role input images at various depths in the network. In particular, played by the SE block with the goal of attaining at least a we would like to understand how excitations vary across primitive understanding of its practical function. images of different classes, and across images within a class. We first consider the distribution of excitations for dif- 7.1 Effect of Squeeze ferent classes. Specifically, we sample four classes from the To assess whether the global embedding produced by the ImageNet dataset that exhibit semantic and appearance di- squeeze operation plays an important role in performance, versity, namely goldfish, pug, plane and cliff (example images we experiment with a variant of the SE block that adds an from these classes are shown in Figure 6). We then draw equal number of parameters, but does not perform global fifty samples for each class from the validation set and average pooling. Specifically, we remove the pooling op- compute the average activations for fifty uniformly sampled eration and replace the two FC layers with corresponding channels in the last SE block of each stage (immediately 1 × 1 convolutions with identical channel dimensions in prior to downsampling) and plot their distribution in Fig. 7. the excitation operator, namely NoSqueeze, where the ex- For reference, we also plot the distribution of the mean citation output maintains the spatial dimensions as input. activations across all of the 1000 classes. In contrast to the SE block, these point-wise convolutions We make the following three observations about the can only remap the channels as a function of the output role of the excitation operation. First, the distribution across of a local operator. While in practice, the later layers of a different classes is very similar at the earlier layers of the deep network will typically possess a (theoretical) global network, e.g. SE 2 3. This suggests that the importance of receptive field, global embeddings are no longer directly feature channels is likely to be shared by different classes accessible throughout the network in the NoSqueeze variant. in the early stages. The second observation is that at greater The accuracy and computational complexity of the both depth, the value of each channel becomes much more class- models are compared to a standard ResNet-50 model in specific as different classes exhibit different preferences to Table 16. We observe that the use of global information has the discriminative value of features, e.g. SE 4 6 and SE 5 1. a significant influence on the model performance, underlin- These observations are consistent with findings in previous ing the importance of the squeeze operation. Moreover, in work [81], [82], namely that earlier layer features are typi- comparison to the NoSqueeze design, the SE block allows cally more general (e.g. class agnostic in the context of the this global information to be used in a computationally classification task) while later layer features exhibit greater parsimonious manner. levels of specificity [83]. Next, we observe a somewhat different phenomena in the last stage of the network. SE 5 2 exhibits an interesting 7.2 Role of Excitation tendency towards a saturated state in which most of the To provide a clearer picture of the function of the excitation activations are close to one and the remainder is close to operator in SE blocks, in this section we study example zero. At the point at which all activations take the value one, activations from the SE-ResNet-50 model and examine their an SE block reduces to the identity operator. At the end of distribution with respect to different classes and different the network in the SE 5 3 (which is immediately followed
11 . 11 (a) SE_2_3 (b) SE_3_4 (c) SE_4_6 (d) SE_5_1 (e) SE_5_2 (f) SE_5_3 Fig. 7. Activations induced by the Excitation operator at different depths in the SE-ResNet-50 on ImageNet. Each set of activations is named according to the following scheme: SE_stageID_blockID. With the exception of the unusual behaviour at SE_5_2, the activations become increasingly class-specific with increasing depth. by global pooling prior before classifiers), a similar pattern network by enabling it to perform dynamic channel-wise emerges over different classes, up to a slight change in scale feature recalibration. A wide range of experiments show (which could be tuned by the classifiers). This suggests that the effectiveness of SENets, which achieve state-of-the-art SE 5 2 and SE 5 3 are less important than previous blocks performance across multiple datasets and tasks. In addition, in providing recalibration to the network. This finding is SE blocks shed some light on the inability of previous consistent with the result of the empirical investigation in architectures to adequately model channel-wise feature de- Sec. 4 which demonstrated that the additional parameter pendencies. We hope this insight may prove useful for other count could be significantly reduced by removing the SE tasks requiring strong discriminative features. Finally, the blocks for the last stage with only a marginal loss of perfor- feature importance values produced by SE blocks may be mance. of use for other tasks such as network pruning for model Finally, we show the mean and standard deviations of compression. the activations for image instances within the same class for two sample classes (goldfish and plane) in Fig. 8. We observe a trend consistent with the inter-class visualisation, indicating A PPENDIX : D ETAILS OF SEN ET-154 that the dynamic behaviour of SE blocks varies over both SENet-154 is constructed by incorporating SE blocks into a classes and instances within a class. Particularly in the later modified version of the 64×4d ResNeXt-152 which extends layers of the network where there is considerable diversity the original ResNeXt-101 [19] by adopting the block stack- of representation within a single class, the network learns ing strategy of ResNet-152 [13]. Further differences to the to take advantage of feature recalibration to improve its design and training of this model (beyond the use of SE discriminative performance. In summary, SE blocks produce blocks) are as follows: (a) The number of the first 1 × 1 instance-specific responses which nevertheless function to convolutional channels for each bottleneck building block support the increasingly class-specific needs of the model at was halved to reduce the computational cost of the model different layers in the architecture. with a minimal decrease in performance. (b) The first 7 × 7 convolutional layer was replaced with three consecutive 8 C ONCLUSION 3 × 3 convolutional layers. (c) The 1 × 1 down-sampling In this paper we proposed the SE block, an architectural projection with stride-2 convolution was replaced with a unit designed to improve the representational power of a 3 × 3 stride-2 convolution to preserve information. (d) A
12 . 12 (a) SE_2_3 (b) SE_3_4 (c) SE_4_6 (d) SE_5_1 (e) SE_5_2 (f) SE_5_3 Fig. 8. Activations induced by Excitation in the different modules of SE-ResNet-50 on image samples from the goldfish and plane classes of ImageNet. The module is named “SE_stageID_blockID”. dropout layer (with a dropout ratio of 0.2) was inserted [4] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards before the classification layer to reduce overfitting. (e) Label- real-time object detection with region proposal networks,” in NIPS, 2015. smoothing regularisation (as introduced in [20]) was used [5] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, during training. (f) The parameters of all BN layers were D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with frozen for the last few training epochs to ensure consistency convolutions,” in CVPR, 2015. between training and testing. (g) Training was performed [6] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep with 8 servers (64 GPUs) in parallel to enable large batch network training by reducing internal covariate shift,” in ICML, 2015. sizes (2048). The initial learning rate was set to 1.0. [7] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick, “Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks,” in CVPR, 2016. ACKNOWLEDGMENTS [8] A. Newell, K. Yang, and J. Deng, “Stacked hourglass networks for human pose estimation,” in ECCV, 2016. The authors would like to thank Chao Li and Guangyuan [9] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu, Wang from Momenta for their contributions in the training “Spatial transformer networks,” in NIPS, 2015. [10] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, system optimisation and experiments on CIFAR dataset. We Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and would also like to thank Andrew Zisserman, Aravindh Ma- L. Fei-Fei, “ImageNet large scale visual recognition challenge,” hendran and Andrea Vedaldi for many helpful discussions. IJCV, 2015. S.A is supported by EPSRC AIMS CDT EP/L015897/1. The [11] K. Simonyan and A. Zisserman, “Very deep convolutional net- works for large-scale image recognition,” in ICLR, 2015. work is supported in part by National Natural Science Foun- [12] S. Santurkar, D. Tsipras, A. Ilyas, and A. Madry, “How does dation of China with Nos. 61632003, 61672502, 61620106003 batch normalization help optimization? (no, it is not about internal and 61331018. covariate shift),” in NIPS, 2018. [13] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016. R EFERENCES [14] K. He, X. Zhang, S. Ren, and J. Sun, “Identity mappings in deep residual networks,” in ECCV, 2016. [1] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classifi- [15] R. K. Srivastava, K. Greff, and J. Schmidhuber, “Training very deep cation with deep convolutional neural networks,” in NIPS, 2012. networks,” in NIPS, 2015. [2] A. Toshev and C. Szegedy, “DeepPose: Human pose estimation [16] Y. Chen, J. Li, H. Xiao, X. Jin, S. Yan, and J. Feng, “Dual path via deep neural networks,” in CVPR, 2014. networks,” in NIPS, 2017. [3] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional net- [17] G. Huang, Z. Liu, K. Q. Weinberger, and L. Maaten, “Densely works for semantic segmentation,” in CVPR, 2015. connected convolutional networks,” in CVPR, 2017.
13 . 13 [18] Y. Ioannou, D. Robertson, R. Cipolla, and A. Criminisi, “Deep [49] H. Larochelle and G. E. Hinton, “Learning to combine foveal roots: Improving CNN efficiency with hierarchical filter groups,” glimpses with a third-order boltzmann machine,” in NIPS, 2010. in CVPR, 2017. [50] V. Mnih, N. Heess, A. Graves, and K. Kavukcuoglu, “Recurrent [19] S. Xie, R. Girshick, P. Doll´ar, Z. Tu, and K. He, “Aggregated models of visual attention,” in NIPS, 2014. residual transformations for deep neural networks,” in CVPR, [51] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. 2017. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” [20] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Re- in NIPS, 2017. thinking the inception architecture for computer vision,” in CVPR, [52] T. Bluche, “Joint line segmentation and transcription for end-to- 2016. end handwritten paragraph recognition,” in NIPS, 2016. [21] C. Szegedy, S. Ioffe, V. Vanhoucke, and A. Alemi, “Inception- [53] A. Miech, I. Laptev, and J. Sivic, “Learnable pooling with context v4, inception-resnet and the impact of residual connections on gating for video classification,” arXiv:1706.06905, 2017. learning,” in ICLR Workshop, 2016. [54] C. Cao, X. Liu, Y. Yang, Y. Yu, J. Wang, Z. Wang, Y. Huang, L. Wang, [22] M. Jaderberg, A. Vedaldi, and A. Zisserman, “Speeding up con- C. Huang, W. Xu, D. Ramanan, and T. S. Huang, “Look and volutional neural networks with low rank expansions,” in BMVC, think twice: Capturing top-down visual attention with feedback 2014. convolutional neural networks,” in ICCV, 2015. [23] F. Chollet, “Xception: Deep learning with depthwise separable [55] K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, convolutions,” in CVPR, 2017. R. Zemel, and Y. Bengio, “Show, attend and tell: Neural image [24] M. Lin, Q. Chen, and S. Yan, “Network in network,” in ICLR, 2014. caption generation with visual attention,” in ICML, 2015. [25] G. F. Miller, P. M. Todd, and S. U. Hegde, “Designing neural [56] L. Chen, H. Zhang, J. Xiao, L. Nie, J. Shao, W. Liu, and T. Chua, networks using genetic algorithms.” in ICGA, 1989. “SCA-CNN: Spatial and channel-wise attention in convolutional [26] K. O. Stanley and R. Miikkulainen, “Evolving neural networks networks for image captioning,” in CVPR, 2017. through augmenting topologies,” Evolutionary computation, 2002. [57] J. S. Chung, A. Senior, O. Vinyals, and A. Zisserman, “Lip reading [27] J. Bayer, D. Wierstra, J. Togelius, and J. Schmidhuber, “Evolving sentences in the wild,” in CVPR, 2017. memory cell structures for sequence learning,” in ICANN, 2009. [58] S. Woo, J. Park, J.-Y. Lee, and I. S. Kweon, “CBAM: Convolutional [28] R. Jozefowicz, W. Zaremba, and I. Sutskever, “An empirical explo- block attention module,” in ECCV, 2018. ration of recurrent network architectures,” in ICML, 2015. [59] J. Park, S. Woo, J.-Y. Lee, and I. S. Kweon, “BAM: Bottleneck [29] L. Xie and A. L. Yuille, “Genetic CNN,” in ICCV, 2017. attention module,” in BMVC, 2018. [30] E. Real, S. Moore, A. Selle, S. Saxena, Y. L. Suematsu, J. Tan, Q. Le, [60] F. Wang, M. Jiang, C. Qian, S. Yang, C. Li, H. Zhang, X. Wang, and and A. Kurakin, “Large-scale evolution of image classifiers,” in X. Tang, “Residual attention network for image classification,” in ICML, 2017. CVPR, 2017. [61] J. Yang, K. Yu, Y. Gong, and T. Huang, “Linear spatial pyramid [31] E. Real, A. Aggarwal, Y. Huang, and Q. V. Le, “Regularized matching using sparse coding for image classification,” in CVPR, evolution for image classifier architecture search,” arXiv preprint 2009. arXiv:1802.01548, 2018. [62] J. Sanchez, F. Perronnin, T. Mensink, and J. Verbeek, “Image [32] T. Elsken, J. H. Metzen, and F. Hutter, “Efficient multi-objective classification with the fisher vector: Theory and practice,” IJCV, neural architecture search via lamarckian evolution,” arXiv 2013. preprint arXiv:1804.09081, 2018. [63] L. Shen, G. Sun, Q. Huang, S. Wang, Z. Lin, and E. Wu, “Multi- [33] H. Liu, K. Simonyan, and Y. Yang, “DARTS: Differentiable archi- level discriminative dictionary learning with application to large tecture search,” arXiv preprint arXiv:1806.09055, 2018. scale image classification,” IEEE TIP, 2015. [34] J. Bergstra and Y. Bengio, “Random search for hyper-parameter [64] V. Nair and G. E. Hinton, “Rectified linear units improve restricted optimization,” JMLR, 2012. boltzmann machines,” in ICML, 2010. [35] C. Liu, B. Zoph, J. Shlens, W. Hua, L.-J. Li, L. Fei-Fei, A. Yuille, [65] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, J. Huang, and K. Murphy, “Progressive neural architecture T. Weyand, M. Andreetto, and H. Adam, “MobileNets: Efficient search,” in ECCV, 2018. convolutional neural networks for mobile vision applications,” [36] R. Negrinho and G. Gordon, “Deeparchitect: Automatically arXiv:1704.04861, 2017. designing and training deep architectures,” arXiv preprint [66] X. Zhang, X. Zhou, M. Lin, and J. Sun, “ShuffleNet: An extremely arXiv:1704.08792, 2017. efficient convolutional neural network for mobile devices,” in [37] S. Saxena and J. Verbeek, “Convolutional neural fabrics,” in NIPS, CVPR, 2018. 2016. [67] L. Shen, Z. Lin, and Q. Huang, “Relay backpropagation for effec- [38] A. Brock, T. Lim, J. M. Ritchie, and N. Weston, “SMASH: one-shot tive learning of deep convolutional neural networks,” in ECCV, model architecture search through hypernetworks,” in ICLR, 2018. 2016. [39] B. Baker, O. Gupta, R. Raskar, and N. Naik, “Accelerating neural [68] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: architecture search using performance prediction,” in ICLR Work- Surpassing human-level performance on ImageNet classification,” shop, 2018. in ICCV, 2015. [40] B. Baker, O. Gupta, N. Naik, and R. Raskar, “Designing neural [69] S. Zagoruyko and N. Komodakis, “Wide residual networks,” in network architectures using reinforcement learning,” in ICLR, BMVC, 2016. 2017. [70] X. Gastaldi, “Shake-shake regularization,” arXiv preprint [41] B. Zoph and Q. V. Le, “Neural architecture search with reinforce- arXiv:1705.07485, 2017. ment learning,” in ICLR, 2017. [71] T. DeVries and G. W. Taylor, “Improved regularization of [42] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, “Learning transfer- convolutional neural networks with cutout,” arXiv preprint able architectures for scalable image recognition,” in CVPR, 2018. arXiv:1708.04552, 2017. [43] H. Liu, K. Simonyan, O. Vinyals, C. Fernando, and [72] L. Shen, Z. Lin, G. Sun, and J. Hu, “Places401 and places365 mod- K. Kavukcuoglu, “Hierarchical representations for efficient els,” https://github.com/lishen-shirley/Places2-CNNs, 2016. architecture search,” in ICLR, 2018. [73] A. Krizhevsky and G. Hinton, “Learning multiple layers of fea- [44] H. Pham, M. Y. Guan, B. Zoph, Q. V. Le, and J. Dean, “Efficient tures from tiny images,” Citeseer, Tech. Rep., 2009. neural architecture search via parameter sharing,” in ICML, 2018. [74] G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Q. Weinberger, “Deep [45] M. Tan, B. Chen, R. Pang, V. Vasudevan, and Q. V. Le, “Mnas- networks with stochastic depth,” in ECCV, 2016. net: Platform-aware neural architecture search for mobile,” arXiv [75] B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, preprint arXiv:1807.11626, 2018. “Places: A 10 million image database for scene recognition,” IEEE [46] B. A. Olshausen, C. H. Anderson, and D. C. V. Essen, “A neurobio- TPAMI, 2017. logical model of visual attention and invariant pattern recognition [76] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, based on dynamic routing of information,” Journal of Neuroscience, P. Doll´ar, and C. L. Zitnick, “Microsoft COCO: Common objects in 1993. context,” in ECCV, 2014. [47] L. Itti, C. Koch, and E. Niebur, “A model of saliency-based visual [77] D. Han, J. Kim, and J. Kim, “Deep pyramidal residual networks,” attention for rapid scene analysis,” IEEE TPAMI, 1998. in CVPR, 2017. [48] L. Itti and C. Koch, “Computational modelling of visual attention,” [78] X. Zhang, Z. Li, C. C. Loy, and D. Lin, “Polynet: A pursuit of Nature reviews neuroscience, 2001. structural diversity in very deep networks,” in CVPR, 2017.
14 . 14 [79] E. D. Cubuk, B. Zoph, D. Mane, V. Vasudevan, and Q. V. Le, Enhua Wu completed his BSc study in 1970 “Autoaugment: Learning augmentation policies from data,” arXiv from Tsinghua University, Beijing and stayed preprint arXiv:1805.09501, 2018. in the same university for teaching until 1980. [80] D. Mahajan, R. Girshick, V. Ramanathan, K. He, M. Paluri, Y. Li, He received his PhD degree from University of A. Bharambe, and L. van der Maaten, “Exploring the limits of Manchester, UK in 1984, followed by working at weakly supervised pretraining,” in ECCV, 2018. the State Key Lab. of Computer Science, Insti- [81] H. Lee, R. Grosse, R. Ranganath, and A. Y. Ng, “Convolutional tute of Software, Chinese Academy of Sciences deep belief networks for scalable unsupervised learning of hierar- since 1985, and at the same time invited as a chical representations,” in ICML, 2009. full professor of University of Macau since 1997. [82] J. Yosinski, J. Clune, Y. Bengio, and H. Lipson, “How transferable He has been invited to chair various conferences are features in deep neural networks?” in NIPS, 2014. including recently the PC chair of ACM VRST15, [83] A. S. Morcos, D. G. Barrett, N. C. Rabinowitz, and M. Botvinick, honorary chair of SIGGRAPH Asia16 & ACM VRCAI16, Co-chair of “On the importance of single directions for generalization,” in CASA18 and ACM VRCAI18. He was the Editor-in-Chief of the Chinese ICLR, 2018. Journal of CAD & Graphics between 2004-2010, and an Associate Editor-in-Chief of the Journal of Computer Science and Technology since 1995. He has been also in long years served as an associate editor for TVC, CAVW, Visual Informatics, IJIG, IJSI. He is a member of IEEE & ACM, and a fellow of the China Computer Federation (CCF). His research interests include realistic image synthesis, physically based simulation and virtual reality. Jie Hu is currently a PhD student at the Insti- tute of Software, Chinese Academy of Sciences & University of Chinese Academy of Sciences. He received his MS degree in software engi- neering from Peking University, China, in 2018. His research interests include computer vision and pattern recognition, with a focus on image recognition. Li Shen is a postdoctoral researcher in the Vi- sual Geometry Group at the University of Oxford. Her research interests are in computer vision and deep learning, particularly in image recog- nition and network architectures. Samuel Albanie is a researcher in the Visual Geometry Group at the University of Oxford. Gang Sun is a postdoctoral researcher in LIAMA-NLPR at CAS Institute of Automation, Beijing. He is also working as R&D director at Momenta. His research interests are computer vision, deep learning and distributed computing.
3秒后跳转登录页面
去登陆

