


















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Neural Random-Access Machines
In this paper, we propose and investigate a new neural network architecture called Neural Random Access Machine. It can manipulate and dereference pointers to an external variable-size random-access memory. The model is trained from pure input-output examples using backpropagation. We evaluate the new model on a number of simple algorithmic tasks whose solutions require pointer manipulation and dereferencing. Our results show that the proposed model can learn to solve algorithmic tasks of such type and is capable of operating on simple data structures like linked-lists and binary trees. For easier tasks, the learned solutions generalize to sequences of arbitrary length. Moreover, memory access during inference can be done in a constant time under some assumptions.
展开查看详情
1 . Published as a conference paper at ICLR 2016 N EURAL R ANDOM -ACCESS M ACHINES Karol Kurach∗ & Marcin Andrychowicz∗ & Ilya Sutskever Google {kkurach,marcina,ilyasu}@google.com A BSTRACT In this paper, we propose and investigate a new neural network architecture called Neural Random Access Machine. It can manipulate and dereference pointers to arXiv:1511.06392v3 [cs.LG] 9 Feb 2016 an external variable-size random-access memory. The model is trained from pure input-output examples using backpropagation. We evaluate the new model on a number of simple algorithmic tasks whose so- lutions require pointer manipulation and dereferencing. Our results show that the proposed model can learn to solve algorithmic tasks of such type and is capable of operating on simple data structures like linked-lists and binary trees. For easier tasks, the learned solutions generalize to sequences of arbitrary length. More- over, memory access during inference can be done in a constant time under some assumptions. 1 I NTRODUCTION Deep learning is successful for two reasons. First, deep neural networks are able to represent the “right” kind of functions; second, deep neural networks are trainable. Deep neural networks can be potentially improved if they get deeper and have fewer parameters, while maintaining train- ability. By doing so, we move closer towards a practical implementation of Solomonoff induc- tion (Solomonoff, 1964). The first model that we know of that attempted to train extremely deep networks with a large memory and few parameters is the Neural Turing Machine (NTM) (Graves et al., 2014) — a computationally universal deep neural network that is trainable with backprop- agation. Other models with this property include variants of Stack-Augmented recurrent neural networks (Joulin & Mikolov, 2015; Grefenstette et al., 2015), and the Grid-LSTM (Kalchbrenner et al., 2015)—of which the Grid-LSTM has achieved the greatest success on both synthetic and real tasks. The key characteristic of these models is that their depth, the size of their short term memory, and their number of parameters are no longer confounded and can be altered independently — which stands in contrast to models like the LSTM (Hochreiter & Schmidhuber, 1997), whose number of parameters grows quadratically with the size of their short term memory. A fundamental operation of modern computers is pointer manipulation and dereferencing. In this work, we investigate a model class that we name the Neural Random-Access Machine (NRAM), which is a neural network that has, as primitive operations, the ability to manipulate, store in mem- ory, and dereference pointers into its working memory. By providing our model with dereferencing as a primitive, it becomes possible to train models on problems whose solutions require pointer manipulation and chasing. Although all computationally universal neural networks are equivalent, which means that the NRAM model does not have a representational advantage over other models if they are given a sufficient number of computational steps, in practice, the number of timesteps that a given model has is highly limited, as extremely deep models are very difficult to train. As a result, the model’s core primitives have a strong effect on the set of functions that can be feasibly learned in practice, similarly to the way in which the choice of a programming language strongly affects the functions that can be implemented with an extremely small amount of code. Finally, the usefulness of computationally-universal neural networks depends entirely on the ability of backpropagation to find good settings of their parameters. Indeed, it is trivial to define the “op- timal” hypothesis class (Solomonoff, 1964), but the problem of finding the best (or even a good) ∗ Equal contribution. 1
2 .Published as a conference paper at ICLR 2016 function in that class is intractable. Our work puts the backpropagation algorithm to another test, where the model is extremely deep and intricate. In our experiments, we evaluate our model on several algorithmic problems whose solutions required pointer manipulation and chasing. These problems include algorithms on a linked-list and a binary tree. While we were able to achieve encouraging results on these problems, we found that standard optimization algorithms struggle with these extremely deep and nonlinear models. We believe that advances in optimization methods will likely lead to better results. 2 R ELATED WORK There has been a significant interest in the problem of learning algorithms in the past few years. The most relevant recent paper is Neural Turing Machines (NTMs) (Graves et al., 2014). It was the first paper to explicitly suggest the notion that it is worth training a computationally universal neural network, and achieved encouraging results. A follow-up model that had the goal of learning algorithms was the Stack-Augmented Recurrent Neural Network (Joulin & Mikolov, 2015) This work demonstrated that the Stack-Augmented RNN can generalize to long problem instances from short problem instances. A related model is the Reinforcement Learning Neural Turing Machine (Zaremba & Sutskever, 2015), which attempted to use reinforcement learning techniques to train a discrete-continuous hybrid model. The memory network (Weston et al., 2014) is an early model that attempted to explicitly separate the memory from computation in a neural network model. The followup work of Sukhbaatar et al. (2015) combined the memory network with the soft attention mechanism, which allowed it to be trained with less supervision. The Grid-LSTM (Kalchbrenner et al., 2015) is a highly interesting extension of LSTM, which allows to use LSTM cells for both deep and sequential computation. It achieves excellent results on both synthetic, algorithmic problems and on real tasks, such as language modelling, machine translation, and object recognition. The Pointer Network (Vinyals et al., 2015) is somewhat different from the above models in that it does not have a writable memory — it is more similar to the attention model of Bahdanau et al. (2014) in this regard. Despite not having a memory, this model was able to solve a number of diffi- cult algorithmic problems that include the convex hull and the approximate 2D travelling salesman problem (TSP). Finally, it is important to mention the attention model of Bahdanau et al. (2014). Although this work is not explicitly aimed at learning algorithms, it is by far the most practical model that has an “algorithmic bent”. Indeed, this model has proven to be highly versatile, and variants of this model have achieved state-of-the-art results on machine translation (Luong et al., 2015), speech recognition (Chan et al., 2015), and syntactic parsing (Vinyals et al., 2014), without the use of almost any domain-specific tuning. 3 M ODEL In this section we describe the NRAM model. We start with a description of the simplified version of our model which does not use an external memory and then explain how to augment it with a variable-size random-access memory. The core part of the model is a neural controller, which acts as a “processor”. The controller can be a feedforward neural network or an LSTM, and it is the only trainable part of the model. The model contains R registers, each of which holds an integer value. To make our model trainable with gradient descent, we made it fully differentiable. Hence, each register represents an integer value with a distribution over the set {0, 1, . . . , M − 1}, for some constant M . We do not assume that these distributions have any special form — they are simply stored as vectors p ∈ RM satisfying pi ≥ 0 and i pi = 1. The controller does not have direct access to the registers; it can interact with them using a number of prespecified modules (gates), such as integer addition or equality test. 2
3 .Published as a conference paper at ICLR 2016 Let’s denote the modules m1 , m2 , . . . , mQ , where each module is a function: mi : {0, 1, . . . , M − 1} × {0, 1, . . . , M − 1} → {0, 1, . . . , M − 1}. On a high level, the model performs a sequence of timesteps, each of which consists of the following substeps: 1. The controller gets some inputs depending on the values of the registers (the controller’s inputs are described in Sec. 3.1). 2. The controller updates its internal state (if the controller is an LSTM). 3. The controller outputs the description of a “fuzzy circuit” with inputs r1 , . . . , rR , gates m1 , . . . , mQ and R outputs. 4. The values of the registers are overwritten with the outputs of the circuit. More precisely, each circuit is created as follows. The inputs for the module mi are chosen by the controller from the set {r1 , . . . , rR , o1 , . . . , oi−1 }, where: • rj is the value stored in the j-th register at the current timestep, and • oj is the output of the module mj at the current timestep. Hence, for each 1 ≤ i ≤ Q the controller chooses weighted averages of the values {r1 , . . . , rR , o1 , . . . , oi−1 } which are given as inputs to the module. Therefore, oi = mi (r1 , . . . , rR , o1 , . . . , oi−1 )T softmax(ai ), (r1 , . . . , rR , o1 , . . . , oi−1 )T softmax(bi ) , (1) where the vectors ai , bi ∈ RR+i−1 are produced by the controller (Fig. 1). outputs of previous registers modules ·, · r1 ... rR o1 . . . oi−1 mi oi ·, · ai s-m LSTM bi s-m Figure 1: The execution of the module mi . Gates s-m represent the softmax function and ·, · denotes inner product. See Eq. 1 for details. Recall that the variables rj represent probability distributions and therefore the inputs to mi , be- ing weighted averages of probability distributions, are also probability distributions. Thus, as the modules mi are originally defined for integer inputs and outputs, we must extend their domain to probability distributions as inputs, which can be done in a natural way (and make their output also be a probability distribution): ∀0≤c<M P (mi (A, B) = c) = P(A = a)P(B = b)[mi (a, b) = c]. (2) 0≤a,b<M After the modules have produced their outputs, the controller decides which of the values {r1 , . . . , rR , o1 , . . . , oQ } should be stored in the registers. In detail, the controller outputs the vec- tors ci ∈ RR+Q for 1 ≤ i ≤ R and the values of the registers are updated (simultaneously) using the formula: ri := (r1 , . . . , rR , o1 , . . . , oQ )T softmax(ci ). (3) 3
4 .Published as a conference paper at ICLR 2016 3.1 C ONTROLLER ’ S INPUTS Recall that at the beginning of each timestep the controller receives some inputs, and it is an im- portant design decision to decide where should these inputs come from. A naive approach is to use the values of the registers as inputs to the controller. However, the values of the registers are probability distributions and are stored as vectors p ∈ RM . If the entire distributions were given as inputs to the controller then the number of the model’s parameters would depend on M . This would be undesirable because, as will be explained in the next section, the value M is linked to the size of an external random-access memory tape and hence it would prevent the model from generalizing to different memory sizes. Hence, for each 1 ≤ i ≤ R the controller receives, as input, only one scalar from each register, namely P(ri = 0) — the probability that the value in the register is equal 0. This solution has an additional advantage, namely it limits the amount of information available to the controller and forces it to rely on the modules instead of trying to solve the problem on its own. Notice that this information is sufficient to get the exact value of ri if ri ∈ {0, 1}, which is the case whenever ri is an output of a ,,boolean” module, e.g. the inequality test module mi (a, b) = [a < b]. 3.2 M EMORY TAPE One could use the model described so far for learning sequence-to-sequence transformations by initializing the registers with the input sequence, and training the model to produce the desired output sequence in its registers after a given number of timesteps. The disadvantage of such model is that it would be completely unable to generalize to longer sequences, because the length of the sequence that the model can process is equal to the number of its registers, which is constant. Therefore, we extend the model with a variable-size memory tape, which consists of M memory cells, each of which stores a distribution over the set {0, 1, . . . , M −1}. Notice that each distribution stored in a memory cell or a register can be interpreted as a fuzzy address in the memory and used as a fuzzy pointer. We will hence identify integers in the set {0, 1, . . . , M − 1} with pointers to the memory. Therefore, the value in each memory cell may be interpreted as an integer or as a pointer. The exact state of the memory can be described by a matrix M ∈ RM M , where the value Mi,j is the probability that the i-th cell holds the value j. The model interacts with the memory tape solely using two special modules: • READ module: this module takes as the input a pointer1 and returns the value stored under the given address in the memory. This operation is extended to fuzzy pointers similarly to Eq. 2. More precisely, if p is a vector representing the probability distribution of the input (i.e. pi is the probability that the input pointer points to the i-th cell) then the module returns the value MT p. • WRITE module: this module takes as the input a pointer p and a value a and stores the value a under the address p in the memory. The fuzzy form of the operation can be effectively expressed using matrix operations 2 . The full architecture of the NRAM model is presented on Fig. 2 3.3 I NPUTS AND OUTPUTS HANDLING The memory tape also serves as an input-output channel — the model’s memory is initialized with the input sequence and the model is expected to produce the output in the memory. Moreover, we use a novel way of deciding how many timesteps should be executed. After each timestep we let the controller decide whether it would like to continue the execution or finish it, in which case the current state of the memory is treated as the output. 1 Formally each module takes two arguments. In this case the second argument is simply ignored. 2 The exact formula is M := (J − p)J T · M + paT , where J denotes a (column) vector consisting of M ones and · denotes coordinate-wise multiplication. 4
5 .Published as a conference paper at ICLR 2016 binarized LSTM finish? registers r1 m1 m3 r1 r2 r2 r3 r3 r4 m2 r4 memory tape Figure 2: One timestep of the NRAM architecture with R = 4 registers. The LSTM controller gets the ,,binarized” values r1 , r2 , . . . stored in the registers as inputs and outputs the description of the circuit in the grey box and the probability of finishing the execution in the current timestep (See Sec. 3.3 for more detail). The weights of the solid thin connections are outputted by the controller. The weights of the solid thick connections are trainable parameters of the model. Some of the modules (i.e. READ and WRITE) may interact with the memory tape (dashed connections). More precisely, after the timestep t the controller outputs a scalar ft ∈ [0, 1]3 , which denotes the willingness to finish the execution in the current timestep. Therefore, the probability that the exe- t−1 cution has not been finished before the timestep t is equal i=1 (1 − fi ), and the probability that t−1 the output is produced exactly at the timestep t is equal pt = ft · i=1 (1 − fi ). There is also some maximal allowed number of timesteps T , which is a hyperparameter. The model is forced to T −1 produce output in the last step if it has not done it yet, i.e. pT = 1 − i=1 pi regardless of the value fT . (t) Let M(t) ∈ RM M denote the memory matrix after the timestep t, i.e. Mi,j is the probability that the i-th memory cell holds the value j after the timestep t. For an input-output pair (x, y), where x, y ∈ {0, 1, . . . , M − 1}M we define the loss of the model as the expected negative log-likelihood T M (t) of producing the correct output, i.e., − t=1 pt · i=1 log(Mi,yi ) assuming that the memory was initialized with the sequence x4 . Moreover, for all problems we consider the output sequence is shorter than the memory. Therefore, we compute the loss only over memory cells, which should contain the output. 3.4 D ISCRETIZATION Computing the outputs of modules, represented as probability distributions, is a computationally costly operation. For example, computing the output of the READ module takes Θ(M 2 ) time as it requires the multiplication of the matrix M ∈ RM M and the vector p ∈ R . M One may however suspect (and we empirically verify this claim in Sec. 4) that the NRAM model naturally learns solutions in which the distributions of intermediate values have very low entropy. The argument for this hypothesis is that fuzziness in the intermediate values would probably prop- agate to the output and cause a higher value of the cost function. To test this hypothesis we trained the model and then used its discretized version during interference. In the discretized version every module gets as inputs the values from modules (or registers), which are the most probable to produce 3 In fact, the controller outputs a scalar xi and fi = sigmoid(xi ). 4 M T (t) One could also use the negative log-likelihood of the expected output, i.e. − i=1 log t=1 pt · Mi,yi as the loss function. 5
6 .Published as a conference paper at ICLR 2016 the given input accordingly to the distribution outputted by the controller. More precisely, it corre- sponds to replacing the function softmax in equations (1,3) with the function returning the vector containing 1 on the position of the maximum value in the input and zeros on all other positions. Notice that in the discretized NRAM model each register and memory cell stores an integer from the set {0, 1, . . . , M − 1} and therefore all modules may be executed efficiently (assuming that the functions represented by the modules can be efficiently computed). In case of a feedforward controller and a small (e.g. ≤ 20) number of registers the interference can be accelerated even further. Recall that the only inputs to the controller are binarized values of the register. Therefore, instead of executing the controller one may simple precompute the (discretized) controller’s output for each configuration of the registers’ binarized values. Such algorithm would enjoy an extremely efficient implementation in machine code. 4 E XPERIMENTS 4.1 T RAINING PROCEDURE The NRAM model is fully differentiable and we trained it using the Adam optimization algorithm (Kingma & Ba, 2014) with the negative log-likelihood cost function. Notice that we do not use any additional supervised data (such as memory access traces) beyond pure input-output examples. We used multilayer perceptrons (MLPs) with two hidden layers or LSTMs with a hidden layer between input and LSTM cells as controllers. The number of hidden units in each layer was equal. The ReLu nonlinearity (Nair & Hinton, 2010) was used in all experiments. Below are some important techniques that we used in the training: Curriculum learning As noticed in several papers (Bengio et al., 2009; Zaremba & Sutskever, 2014), curriculum learning is crucial for training deep networks on very complicated problems. We followed the curriculum learning schedule from Zaremba & Sutskever (2014) without any modifi- cations. The details can be found in Appendix B. Gradient clipping Notice that the depth of the unfolded execution is roughly a product of the number of timesteps and the number of modules. Even for moderately small experiments (e.g. 14 modules and 20 timesteps) this value easily exceeds a few hundreds. In networks of such depth, the gradients can often “explode” (Bengio et al., 1994), what makes training by backpropagation much harder. We noticed that the gradients w.r.t. the intermediate values inside the backpropagation were so large, that they sometimes led to an overflow in single-precision floating-point arithmetic. Therefore, we clipped the gradients w.r.t. the activations, within the execution of the backpropaga- tion algorithm. More precisely, each coordinate is separately cropped into the range [−C1 , C1 ] for some constant C1 . Before updating parameters, we also globally rescale the whole gradient vector, so that its L2 norm is not bigger than some constant value C2 . Noise We added random Gaussian noise to the computed gradients after the backpropagation step. The variance of this noise decays exponentially during the training. The details can be found in Neelakantan et al. (2015). Enforcing Distribution Constraints For very deep networks, a small error in one place can prop- agate to a huge error in some other place. This was the case with our pointers: they are probability distributions over memory cells and they should sum up to 1. However, after a number of operations are applied, they can accumulate error as a result of inaccurate floating-point arithmetic. We have a special layer which is responsible for rescaling all values (multiplying by the inverse of their sum), to make sure they always represent a probability distribution. We add this layer to our model in a few critical places (eg. after the softmax operation)5 . 5 We do not however backpropagate through these renormalizing operations, i.e. during the backward pass we simply assume that they are identities. 6
7 .Published as a conference paper at ICLR 2016 Entropy While searching for a solution, the network can fix the pointer distribution on some particular value. This is advantageous at the end of training, because ideally we would like to be able to discretize the model. However, if this happens at the begin of the training, it could force the network to stay in a local minimum, with a small chance of moving the probability mass to some other value. To address this problem, we encourage the network to explore the space of solutions by adding an ”entropy bonus”, that decreases over time. More precisely, for every distribution outputted by the controller, we subtract from the cost function the entropy of the distribution multiplied by some coefficient, which decreases exponentially during the training. Limiting the values of logarithms There are two places in our model where the logarithms are computed — in the cost function and in the entropy computation. Inputs to whose logarithms can be very small numbers, which may cause very big values of the cost function or even overflows in floating-point arithmetic. To prevent this phenomenon we use log(max(x, )) instead of log(x) for some small hyperparameter whenever a logarithm is computed. 4.2 TASKS We now describe the tasks used in our experiments. For every task, the input is given to the network in the memory tape, and the network’s goal is to modify the memory according to the task’s specifi- cation. We allow the network to modify the original input. The final error for a test case is computed as mc , where c is the number of correctly written cells, and m represents the total number of cells that should be modified. Due to limited space, we describe the tasks only briefly here. The detailed memory layout of inputs and outputs can be found in the Appendix A. 1. Access Given a value k and an array A, return A[k]. 2. Increment Given an array, increment all its elements by 1. 3. Copy Given an array and a pointer to the destination, copy all elements from the array to the given location. 4. Reverse Given an array and a pointer to the destination, copy all elements from the array in reversed order. 5. Swap Given two pointers p, q and an array A, swap elements A[p] and A[q]. 6. Permutation Given two arrays of n elements: P (contains a permutation of numbers 1, . . . , n) and A (contains random elements), permutate A according to P . 7. ListK Given a pointer to the head of a linked list and a number k, find the value of the k-th element on the list. 8. ListSearch Given a pointer to the head of a linked list and a value v to find return a pointer to the first node on the list with the value v. 9. Merge Given pointers to 2 sorted arrays A and B, merge them. 10. WalkBST Given a pointer to the root of a Binary Search Tree, and a path to be traversed (sequence of left/right steps), return the element at the end of the path. 4.3 M ODULES In all of our experiments we used the same sequence of 14 modules: READ (described in Sec. 3.2), ZERO(a, b) = 0, ONE(a, b) = 1, TWO(a, b) = 2, INC(a, b) = (a+1) mod M , ADD(a, b) = (a+b) mod M , SUB(a, b) = (a − b) mod M , DEC(a, b) = (a − 1) mod M , LESS-THAN(a, b) = [a < b], LESS-OR-EQUAL-THAN(a, b) = [a ≤ b], EQUALITY-TEST(a, b) = [a = b], MIN(a, b) = min(a, b), MAX(a, b) = max(a, b), WRITE (described in Sec. 3.2). We also considered settings in which the module sequence is repeated many times, e.g. there are 28 modules, where modules number 1. and 15. are READ, modules number 2. and 16. are ZERO and so on. The number of repetitions is a hyperparameter. 7
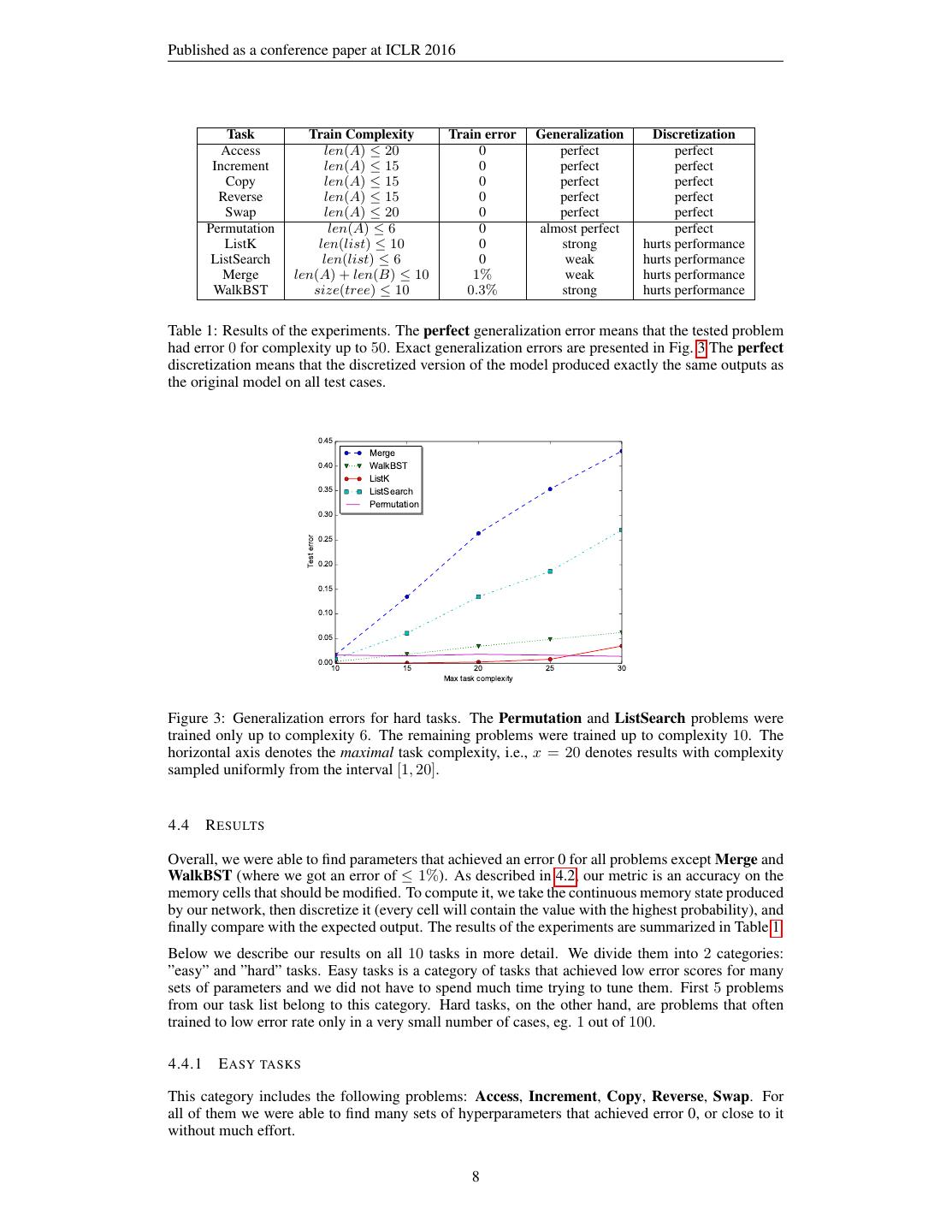
8 .Published as a conference paper at ICLR 2016 Task Train Complexity Train error Generalization Discretization Access len(A) ≤ 20 0 perfect perfect Increment len(A) ≤ 15 0 perfect perfect Copy len(A) ≤ 15 0 perfect perfect Reverse len(A) ≤ 15 0 perfect perfect Swap len(A) ≤ 20 0 perfect perfect Permutation len(A) ≤ 6 0 almost perfect perfect ListK len(list) ≤ 10 0 strong hurts performance ListSearch len(list) ≤ 6 0 weak hurts performance Merge len(A) + len(B) ≤ 10 1% weak hurts performance WalkBST size(tree) ≤ 10 0.3% strong hurts performance Table 1: Results of the experiments. The perfect generalization error means that the tested problem had error 0 for complexity up to 50. Exact generalization errors are presented in Fig. 3 The perfect discretization means that the discretized version of the model produced exactly the same outputs as the original model on all test cases. 0.45 Merge 0.40 WalkBST ListK 0.35 ListSearch Permutation 0.30 0.25 Test error 0.20 0.15 0.10 0.05 0.00 10 15 20 25 30 Max task complexity Figure 3: Generalization errors for hard tasks. The Permutation and ListSearch problems were trained only up to complexity 6. The remaining problems were trained up to complexity 10. The horizontal axis denotes the maximal task complexity, i.e., x = 20 denotes results with complexity sampled uniformly from the interval [1, 20]. 4.4 R ESULTS Overall, we were able to find parameters that achieved an error 0 for all problems except Merge and WalkBST (where we got an error of ≤ 1%). As described in 4.2, our metric is an accuracy on the memory cells that should be modified. To compute it, we take the continuous memory state produced by our network, then discretize it (every cell will contain the value with the highest probability), and finally compare with the expected output. The results of the experiments are summarized in Table 1. Below we describe our results on all 10 tasks in more detail. We divide them into 2 categories: ”easy” and ”hard” tasks. Easy tasks is a category of tasks that achieved low error scores for many sets of parameters and we did not have to spend much time trying to tune them. First 5 problems from our task list belong to this category. Hard tasks, on the other hand, are problems that often trained to low error rate only in a very small number of cases, eg. 1 out of 100. 4.4.1 E ASY TASKS This category includes the following problems: Access, Increment, Copy, Reverse, Swap. For all of them we were able to find many sets of hyperparameters that achieved error 0, or close to it without much effort. 8
9 .Published as a conference paper at ICLR 2016 Step 0 1 2 3 4 5 6 7 8 9 10 11 r1 r2 r3 r4 READ WRITE 1 6 2 10 6 8 9 0 0 0 0 0 0 0 0 0 0 p:0 p:0 a:6 2 6 2 10 6 8 9 0 0 0 0 0 0 0 5 0 1 p:1 p:6 a:2 3 6 2 10 6 8 9 2 0 0 0 0 0 0 5 1 1 p:1 p:6 a:2 4 6 2 10 6 8 9 2 0 0 0 0 0 0 5 1 2 p:2 p:7 a:10 5 6 2 10 6 8 9 2 10 0 0 0 0 0 5 2 2 p:2 p:7 a:10 6 6 2 10 6 8 9 2 10 0 0 0 0 0 5 2 3 p:3 p:8 a:6 7 6 2 10 6 8 9 2 10 6 0 0 0 0 5 3 3 p:3 p:8 a:6 8 6 2 10 6 8 9 2 10 6 0 0 0 0 5 3 4 p:4 p:9 a:8 9 6 2 10 6 8 9 2 10 6 8 0 0 0 5 4 4 p:4 p:9 a:8 10 6 2 10 6 8 9 2 10 6 8 0 0 0 5 4 5 p:5 p:10 a:9 11 6 2 10 6 8 9 2 10 6 8 9 0 0 5 5 5 p:5 p:10 a:9 Table 2: State of memory and registers for the Copy problem at the start of every timestep. We also show the arguments given to the READ and WRITE functions in each timestep. The argument “p:” represents the source/destination address and “a:” represents the value to be written (for WRITE). The value 6 at position 0 in the memory is the pointer to the destination array. It is followed by 5 values (gray columns) that should be copied. We also tested how those solutions generalize to longer input sequences. To do this, for every problem we selected a model that achieved error 0 during the training, and tested it on inputs with lengths up to 506 . To perform these tests we also increased the memory size and the number of allowed timesteps. In all cases the model solved the problem perfectly, what shows that it generalizes not only to longer input sequences, but also to different memory sizes and numbers of allowed timesteps. Moreover, the discretized version of the model (see Sec. 3.4 for details) also solves all the problems perfectly. These results show that the NRAM model naturally learns “algorithmic” solutions, which generalize well. We were also interested if the found solutions generalize to sequences of arbitrary length. It is eas- iest to verify in the case of a discretized model with a feedforward controller. That is because then circuits outputted by the controller depend solely on the values of registers, which are integers. We manually analysed circuits for problems Copy and Increment and verified that found solutions gen- eralize to inputs of arbitrary length, assuming that the number of allowed timesteps is appropriate. 4.4.2 H ARD TASKS r3 ' This category includes: Permutation, ListK, ListSearch, Merge and WalkBST. For all of r4 p read a them we had to perform an extensive random p write search to find a good set of hyperparameters. add Usually, most of the parameter combinations were stuck on the starting curriculum level with r2 r2 ' a high error of 50% − 70%. For the first 3 tasks we managed to train the network to achieve er- ror 0. For WalkBST and Merge the training er- r3 inc min r4 ' rors were 0.3% and 1% respectively. For train- ing those problems we had to introduce addi- r1 r1 ' tional techniques described in Sec. 4.1. For Permutation, ListK and WalkBST our model generalizes very well and achieves low error rates on inputs at least twice longer than Figure 4: The circuit generated at every timestep the ones seen during the training. The exact ≥ 2. The values of the pointer (p) for READ, generalization errors are shown in Fig. 3. WRITE and the value to be written (a) for WRITE are presented in Table 2. The modules whose out- The only hard problem on which our model puts are not used were removed from the picture. discretizes well is Permutation — on this task 6 Unfortunately we could not test for lengths longer than 50 due to the memory restrictions. 9
10 .Published as a conference paper at ICLR 2016 the discretized version of the model produces exactly the same outputs as the original model on all cases tested. For the remaining four problems the discretized version of the models perform very poorly (error rates ≥ 70%). We believe that better results may be obtained by using some techniques encouraging discretization during the training 7 . We noticed that the training procedure is very unstable and the error often raises from a few percents to e.g. 70% in just one epoch. Moreover, even if we use the best found set of hyperparameters, the percent of random seeds that converges to error 0 was usually equal about 11%. We observed that the percent of converging seeds is much lower if we do not add noise to the gradient — in this case only about 1% of seeds converge. 4.5 C OMPARISON TO EXISTING MODELS A comparison to other models is challenging because we are the first to consider problems with pointers. The NTM can solve tasks like Copy or Reverse, but it suffers from the inability to naturally store a pointer to a fixed location in the memory. This makes it unlikely that it could solve tasks such as ListK, ListSearch or WalkBST since the pointers used in these tasks refer to absolute positions. What distinguishes our model from most of the previous attempts (including NTMs, Memory Net- works, Pointer Networks) is the lack of content-based addressing. It was a deliberate design deci- sion, since this kind of addressing inherently slows down the memory access. In contrast, our model — if discretized — can access the memory in a constant time. The NRAM is also the first model that we are aware of employing a differentiable mechanism for deciding when to finish the computation. 4.6 E XEMPLARY EXECUTION We present one example execution of our model for the problem Copy. For the example, we use a very small model with 12 memory cells, 4 registers and the standard set of 14 modules. The controller for this model is a feedforward network, and we run it for 11 timesteps. Table 2 contains, for every timestep, the state of the memory and registers at the begin of the timestep. The model can execute different circuits at different timesteps. In particular, we observed that the first circuit is slightly different from the rest, since it needs to handle the initialization. Starting from the second step all generated circuits are the same. We present this circuit in Fig. 4. The register r2 is constant and keeps the offset between the destination array and the source array (6 − 1 = 5 in this case). The register r3 is responsible for incrementing the pointer in the source array. Its value is copied to r4 8 , the register used by the READ module. For the WRITE module, it also uses r4 which is shifted by r2 . The register r1 is unused. This solution generalizes to sequences of arbitrary length. 5 C ONCLUSIONS In this paper we presented the Neural Random-Access Machine, which can learn to solve problems that require explicit manipulation and dereferencing of pointers. We showed that this model can learn to solve a number of algorithmic problems and generalize well to inputs longer than ones seen during the training. In particular, for some problems it generalizes to inputs of arbitrary length. However, we noticed that the optimization problem resulting from the backpropagating through the execution trace of the program is very challenging for standard optimization techniques. It seems likely that a method that can search in an easier “abstract” space would be more effective at solving such problems. 7 One could for example add at later stages of training a penalty proportional to the entropy of the interme- diate values of registers/memory. 8 In our case r3 < r2 , so the MIN module always outputs the value r3 + 1. It is not satisfied in the last timestep, but then the array is already copied. 10
11 .Published as a conference paper at ICLR 2016 R EFERENCES Bahdanau, Dzmitry, Cho, Kyunghyun, and Bengio, Yoshua. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014. Bengio, Yoshua, Simard, Patrice, and Frasconi, Paolo. Learning long-term dependencies with gra- dient descent is difficult. Neural Networks, IEEE Transactions on, 5(2):157–166, 1994. Bengio, Yoshua, Louradour, J´erˆome, Collobert, Ronan, and Weston, Jason. Curriculum learning. In Proceedings of the 26th annual international conference on machine learning, pp. 41–48. ACM, 2009. Chan, William, Jaitly, Navdeep, Le, Quoc V, and Vinyals, Oriol. Listen, attend and spell. arXiv preprint arXiv:1508.01211, 2015. Graves, Alex, Wayne, Greg, and Danihelka, Ivo. Neural turing machines. arXiv preprint arXiv:1410.5401, 2014. Grefenstette, Edward, Hermann, Karl Moritz, Suleyman, Mustafa, and Blunsom, Phil. Learning to transduce with unbounded memory. arXiv preprint arXiv:1506.02516, 2015. Hochreiter, Sepp and Schmidhuber, J¨urgen. Long short-term memory. Neural computation, 9(8): 1735–1780, 1997. Joulin, Armand and Mikolov, Tomas. Inferring algorithmic patterns with stack-augmented recurrent nets. arXiv preprint arXiv:1503.01007, 2015. Kalchbrenner, Nal, Danihelka, Ivo, and Graves, Alex. Grid long short-term memory. arXiv preprint arXiv:1507.01526, 2015. Kingma, Diederik and Ba, Jimmy. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. Luong, Minh-Thang, Pham, Hieu, and Manning, Christopher D. Effective approaches to attention- based neural machine translation. arXiv preprint arXiv:1508.04025, 2015. Nair, Vinod and Hinton, Geoffrey E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), pp. 807– 814, 2010. Neelakantan, Arvind, Vilnis, Luke, Le, Quoc V, Sutskever, Ilya, Kaiser, Lukasz, Kurach, Karol, and Martens, James. Adding gradient noise improves learning for very deep networks. arXiv preprint arXiv:1511.06807, 2015. Solomonoff, Ray J. A formal theory of inductive inference. part i. Information and control, 7(1): 1–22, 1964. Sukhbaatar, Sainbayar, Szlam, Arthur, Weston, Jason, and Fergus, Rob. End-to-end memory net- works. arXiv preprint arXiv:1503.08895, 2015. Vinyals, Oriol, Kaiser, Lukasz, Koo, Terry, Petrov, Slav, Sutskever, Ilya, and Hinton, Geoffrey. Grammar as a foreign language. arXiv preprint arXiv:1412.7449, 2014. Vinyals, Oriol, Fortunato, Meire, and Jaitly, Navdeep. Pointer networks. arXiv preprint arXiv:1506.03134, 2015. Weston, Jason, Chopra, Sumit, and Bordes, Antoine. Memory networks. arXiv preprint arXiv:1410.3916, 2014. Zaremba, Wojciech and Sutskever, Ilya. Learning to execute. arXiv preprint arXiv:1410.4615, 2014. Zaremba, Wojciech and Sutskever, Ilya. Reinforcement learning neural turing machines. arXiv preprint arXiv:1505.00521, 2015. 11
12 .Published as a conference paper at ICLR 2016 A D ETAILED TASKS DESCRIPTIONS In this section we describe in details the memory layout of inputs and outputs for the tasks used in our experiments. In all descriptions below, big letters represent arrays and small letters represents pointers. N U LL denotes the value 0 and is used to mark the end of an array or a missing next element in a list or a binary tree. 1. Access Given a value k and an array A, return A[k]. Input is given as k, A[0], .., A[n − 1], N U LL and the network should replace the first memory cell with A[k]. 2. Increment Given an array A, increment all its elements by 1. Input is given as A[0], ..., A[n − 1], N U LL and the expected output is A[0] + 1, ..., A[n − 1] + 1. 3. Copy Given an array and a pointer to the destination, copy all elements from the array to the given location. Input is given as p, A[0], ..., A[n−1] where p points to one element after A[n − 1]. The expected output is A[0], ..., A[n − 1] at positions p, ..., p + n − 1 respectively. 4. Reverse Given an array and a pointer to the destination, copy all elements from the array in reversed order. Input is given as p, A[0], ..., A[n − 1] where p points one element after A[n − 1]. The expected output is A[n − 1], ..., A[0] at positions p, ..., p + n − 1 respectively. 5. Swap Given two pointers p, q and an array A, swap elements A[p] and A[q]. Input is given as p, q, A[0], .., A[p], ..., A[q], ..., A[n − 1], 0. The expected modified array A is: A[0], ..., A[q], ..., A[p], ..., A[n − 1]. 6. Permutation Given two arrays of n elements: P (contains a permutation of numbers 0, . . . , n − 1) and A (contains random elements), permutate A according to P . Input is given as a, P [0], ..., P [n − 1], A[0], ..., A[n − 1], where a is a pointer to the array A. The expected output is A[P [0]], ..., A[P [n − 1]], which should override the array P . 7. ListK Given a pointer to the head of a linked list and a number k, find the value of the k-th element on the list. List nodes are represented as two adjacent memory cells: a pointer to the next node and a value. Elements are in random locations in the memory, so that the network needs to follow the pointers to find the correct element. Input is given as: head, k, out, ... where head is a pointer to the first node on the list, k indicates how many hops are needed and out is a cell where the output should be put. 8. ListSearch Given a pointer to the head of a linked list and a value v to find return a pointer to the first node on the list with the value v. The list is placed in memory in the same way as in the task ListK. We fill empty memory with “trash” values to prevent the network from “cheating” and just iterating over the whole memory. 9. Merge Given pointers to 2 sorted arrays A and B, and the pointer to the output o, merge the two arrays into one sorted array. The input is given as: a, b, o, A[0], .., A[n − 1], G, B[0], ..., B[m − 1], G, where G is a special guardian value, a and b point to the first elements of arrays A and B respectively, and o points to the address after the second G. The n + m element should be written in correct order starting from position o. 10. WalkBST Given a pointer to the root of a Binary Search Tree, and a path to be traversed, return the element at the end of the path. The BST nodes are represented as tripes (v, l, r), where v is the value, and l, r are pointers to the left/right child. The triples are placed randomly in the memory. Input is given as root, out, d1 , d2 , ..., dk , N U LL, ..., where root points to the root node and out is a slot for the output. The sequence d1 ...dk , di ∈ {0, 1} represents the path to be traversed: di = 0 means that the network should go to the left child, di = 1 represents going to the right child. 12
13 .Published as a conference paper at ICLR 2016 B D ETAILS OF CURRICULUM TRAINING As noticed in several papers (Bengio et al., 2009; Zaremba & Sutskever, 2014), curriculum learning is crucial for training deep networks on very complicated problems. We followed the curriculum learning schedule from Zaremba & Sutskever (2014) without any modifications. For each of the tasks we have manually defined a sequence of subtasks with increasing difficulty, where the difficulty is usually measured by the length of the input sequence. During training the input-output examples are sampled from a distribution that is determined by the current difficulty level D. The level is increased (up to some maximal value) whenever the error rate of the model goes below some threshold. Moreover, we ensure that successive increases of D are separated by some number of batches. In more detail, to generate an input-output example we first sample a difficulty d from a distribution determined by the current level D and then draw the example with the difficulty d. The procedure for sampling d is the following: • with probability 10%: pick d uniformly at random from the set of all possible difficulties; • with probability 25%: pick d uniformly from [1, D + e], where e is a sample from a geo- metric distribution with a success probability 1/2; • with probability 65%: set d = D + e, where e is sampled as above. Notice that the above procedure guarantees that every difficulty d can be picked regardless of the current level D, which has been shown to increase performance Zaremba & Sutskever (2014). 13
14 .Published as a conference paper at ICLR 2016 C E XAMPLE C IRCUITS Below are presented example circuits generated during training for all simple tasks (except Copy which was presented in the paper). For modules READ and WRITE, the value of the first argument (pointer to the address to be read/written) is marked as p. For WRITE, the value to be written is marked as a and the value returned by this module is always 0. For modules LESS-THAN and LESS-OR-EQUAL-THAN the first parameter is marked as x and the second one as y. Other modules either have only one parameter or the order of parameters is not important. For all tasks below (except Increment), the circuit generated at timestep 1 is different than circuits generated at steps ≥ 2, which are the same. This is because the first circuit needs to handle the initialization. We present only the ”main” circuits generated for timesteps ≥ 2. C.1 ACCESS 0 y x lt min inc p read write r2 ' p a r1 r1 ' Figure 5: The circuit generated at every timestep ≥ 2 for the task Access. Step 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 r1 r2 1 3 1 12 4 7 12 1 13 8 2 1 3 11 11 12 0 0 0 2 3 1 12 4 7 12 1 13 8 2 1 3 11 11 12 0 3 0 3 4 1 12 4 7 12 1 13 8 2 1 3 11 11 12 0 3 0 Table 3: Memory for task Access. Only the first memory cell is modified. 14
15 .Published as a conference paper at ICLR 2016 C.2 I NCREMENT p write r3 ' a r5 p r4 ' read inc max r5 ' r2 ' 1 add min r1 ' Figure 6: The circuit generated at every timestep for the task Increment. Step 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 r1 r2 r3 r4 r5 1 1 11 3 8 1 2 9 8 5 3 0 0 0 0 0 0 0 0 0 0 0 2 2 11 3 8 1 2 9 8 5 3 0 0 0 0 0 0 1 2 2 2 1 3 2 12 3 8 1 2 9 8 5 3 0 0 0 0 0 0 2 12 12 12 2 4 2 12 4 8 1 2 9 8 5 3 0 0 0 0 0 0 3 4 4 4 3 5 2 12 4 9 1 2 9 8 5 3 0 0 0 0 0 0 4 9 9 9 4 6 2 12 4 9 2 2 9 8 5 3 0 0 0 0 0 0 5 2 2 2 5 7 2 12 4 9 2 3 9 8 5 3 0 0 0 0 0 0 6 3 3 3 6 8 2 12 4 9 2 3 10 8 5 3 0 0 0 0 0 0 7 10 10 10 7 9 2 12 4 9 2 3 10 9 5 3 0 0 0 0 0 0 8 9 9 9 8 10 2 12 4 9 2 3 10 9 6 3 0 0 0 0 0 0 9 6 6 6 9 11 2 12 4 9 2 3 10 9 6 4 0 0 0 0 0 0 10 4 4 4 10 Table 4: Memory for task Increment. 15
16 .Published as a conference paper at ICLR 2016 C.3 R EVERSE r4 r2 ' x y le r4 ' 1 r1 ' r1 add sub dec p r3 inc r3 ' p write a read min max Figure 7: The circuit generated at every timestep ≥ 2 for the task Reverse. Step 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 r1 r2 r3 r4 1 8 8 1 3 5 1 1 2 0 0 0 0 0 0 0 0 0 0 0 0 2 8 8 1 3 5 1 1 2 0 0 0 0 0 0 0 0 8 0 1 1 3 8 8 1 3 5 1 1 2 0 0 0 0 0 0 8 0 8 1 2 1 4 8 8 1 3 5 1 1 2 0 0 0 0 0 1 8 0 8 1 3 1 5 8 8 1 3 5 1 1 2 0 0 0 0 3 1 8 0 8 1 4 1 6 8 8 1 3 5 1 1 2 0 0 0 5 3 1 8 0 8 1 5 1 7 8 8 1 3 5 1 1 2 0 0 1 5 3 1 8 0 8 1 6 1 8 8 8 1 3 5 1 1 2 0 1 1 5 3 1 8 0 8 1 7 1 9 8 8 1 3 5 1 1 2 2 1 1 5 3 1 8 0 8 1 8 1 10 8 8 1 3 5 1 1 2 2 1 1 5 3 1 8 0 8 1 9 1 Table 5: Memory for task Reverse. 16
17 .Published as a conference paper at ICLR 2016 C.4 S WAP For swap we observed that 2 different circuits are generated, one for even timesteps, one for odd timesteps. r2 ' p read max read a p write r1 ' r1 p max a write add p r2 Figure 8: The circuit generated at every even timestep for the task Swap. max a r1 p a read write r1 ' write p p r2 x sub lt y eq add 2 1 sub y x le r2 ' inc x lt y 0 Figure 9: The circuit generated at every odd timestep ≥ 3 for the task Swap. Step 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 r1 r2 1 4 13 6 10 5 4 6 3 7 1 1 11 13 12 0 0 0 0 2 5 13 6 10 5 4 6 3 7 1 1 11 13 12 0 0 1 4 3 5 13 6 10 12 4 6 3 7 1 1 11 13 12 0 0 0 13 4 5 13 6 10 12 4 6 3 7 1 1 11 13 5 0 0 5 1 Table 6: Memory for task Swap. 17
3秒后跳转登录页面
去登陆

