











- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Mask R-CNN
We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps. Moreover,Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework. We show top results in all three tracks of the COCO suite of challenges, including instance segmentation, boundingbox object detection, and person keypoint detection. Without bells and whistles, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners. We hope our simple and effective approach will serve as a solid baseline and help ease future research in instance-level recognition. Code has been made available at: https://github.com/facebookresearch/Detectron.
展开查看详情
1 . Mask R-CNN Kaiming He Georgia Gkioxari Piotr Doll´ar Ross Girshick Facebook AI Research (FAIR) Abstract arXiv:1703.06870v3 [cs.CV] 24 Jan 2018 We present a conceptually simple, flexible, and general class box framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously RoIAlign generating a high-quality segmentation mask for each in- conv conv stance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recogni- tion. Mask R-CNN is simple to train and adds only a small Figure 1. The Mask R-CNN framework for instance segmentation. overhead to Faster R-CNN, running at 5 fps. Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., al- lowing us to estimate human poses in the same framework. segmentation, where the goal is to classify each pixel into We show top results in all three tracks of the COCO suite a fixed set of categories without differentiating object in- of challenges, including instance segmentation, bounding- stances.1 Given this, one might expect a complex method box object detection, and person keypoint detection. With- is required to achieve good results. However, we show that out bells and whistles, Mask R-CNN outperforms all ex- a surprisingly simple, flexible, and fast system can surpass isting, single-model entries on every task, including the prior state-of-the-art instance segmentation results. COCO 2016 challenge winners. We hope our simple and Our method, called Mask R-CNN, extends Faster R-CNN effective approach will serve as a solid baseline and help [36] by adding a branch for predicting segmentation masks ease future research in instance-level recognition. Code on each Region of Interest (RoI), in parallel with the ex- has been made available at: https://github.com/ isting branch for classification and bounding box regres- facebookresearch/Detectron. sion (Figure 1). The mask branch is a small FCN applied to each RoI, predicting a segmentation mask in a pixel-to- pixel manner. Mask R-CNN is simple to implement and 1. Introduction train given the Faster R-CNN framework, which facilitates a wide range of flexible architecture designs. Additionally, The vision community has rapidly improved object de- the mask branch only adds a small computational overhead, tection and semantic segmentation results over a short pe- enabling a fast system and rapid experimentation. riod of time. In large part, these advances have been driven In principle Mask R-CNN is an intuitive extension of by powerful baseline systems, such as the Fast/Faster R- Faster R-CNN, yet constructing the mask branch properly CNN [12, 36] and Fully Convolutional Network (FCN) [30] is critical for good results. Most importantly, Faster R- frameworks for object detection and semantic segmenta- CNN was not designed for pixel-to-pixel alignment be- tion, respectively. These methods are conceptually intuitive tween network inputs and outputs. This is most evident in and offer flexibility and robustness, together with fast train- how RoIPool [18, 12], the de facto core operation for at- ing and inference time. Our goal in this work is to develop a tending to instances, performs coarse spatial quantization comparably enabling framework for instance segmentation. for feature extraction. To fix the misalignment, we pro- Instance segmentation is challenging because it requires pose a simple, quantization-free layer, called RoIAlign, that the correct detection of all objects in an image while also faithfully preserves exact spatial locations. Despite being precisely segmenting each instance. It therefore combines 1 Following common terminology, we use object detection to denote elements from the classical computer vision tasks of ob- detection via bounding boxes, not masks, and semantic segmentation to ject detection, where the goal is to classify individual ob- denote per-pixel classification without differentiating instances. Yet we jects and localize each using a bounding box, and semantic note that instance segmentation is both semantic and a form of detection. 1
2 . umbrella.98 bus.99 umbrella.98 person1.00 person1.00 person1.00 backpack1.00 person1.00 person.99 handbag.96 person.99 person1.00 person1.00 person1.00 person1.00 person1.00 person.95 person.98 person1.00 person1.00 person1.00 person.94 person1.00 person1.00 person.89 person1.00 sheep.99 backpack.99 sheep.99 sheep.86 backpack.93 sheep.82 sheep.96 sheep.96 sheep.93 sheep.91 sheep.95 sheep.96 sheep1.00 sheep1.00 sheep.99 sheep1.00 sheep.99 sheep.96 sheep.99 person.99 bottle.99 dining table.96 bottle.99 bottle.99 person.99person1.00 person1.00 traffic light.96 tv.99 chair.98 chair.99 chair.90 dining table.99 chair.96 wine glass.97 chair.86 bottle.99wine glass.93 chair.99 bowl.85 wine glass1.00 elephant1.00 wine glass.99 wine glass1.00 person1.00 chair.96 chair.99 fork.95 person1.00 traffic light.95 bowl.81 person1.00 traffic light.92 traffic light.84 person1.00 person.85 person.96 truck1.00 person.99 motorcycle1.00 person.96person1.00 person.83 person1.00 motorcycle1.00 person.98 person.99person.91 person.90 person.87 car.99 car.92 person.99 person.92 car.99 car.93 car1.00 motorcycle.95 knife.83 person.96 Figure 2. Mask R-CNN results on the COCO test set. These results are based on ResNet-101 [19], achieving a mask AP of 35.7 and running at 5 fps. Masks are shown in color, and bounding box, category, and confidences are also shown. a seemingly minor change, RoIAlign has a large impact: it 2. Related Work improves mask accuracy by relative 10% to 50%, showing bigger gains under stricter localization metrics. Second, we R-CNN: The Region-based CNN (R-CNN) approach [13] found it essential to decouple mask and class prediction: we to bounding-box object detection is to attend to a manage- predict a binary mask for each class independently, without able number of candidate object regions [42, 20] and evalu- ate convolutional networks [25, 24] independently on each competition among classes, and rely on the network’s RoI classification branch to predict the category. In contrast, RoI. R-CNN was extended [18, 12] to allow attending to FCNs usually perform per-pixel multi-class categorization, RoIs on feature maps using RoIPool, leading to fast speed which couples segmentation and classification, and based and better accuracy. Faster R-CNN [36] advanced this on our experiments works poorly for instance segmentation. stream by learning the attention mechanism with a Region Proposal Network (RPN). Faster R-CNN is flexible and ro- Without bells and whistles, Mask R-CNN surpasses all bust to many follow-up improvements (e.g., [38, 27, 21]), previous state-of-the-art single-model results on the COCO and is the current leading framework in several benchmarks. instance segmentation task [28], including the heavily- engineered entries from the 2016 competition winner. As Instance Segmentation: Driven by the effectiveness of R- a by-product, our method also excels on the COCO object CNN, many approaches to instance segmentation are based detection task. In ablation experiments, we evaluate multi- on segment proposals. Earlier methods [13, 15, 16, 9] re- ple basic instantiations, which allows us to demonstrate its sorted to bottom-up segments [42, 2]. DeepMask [33] and robustness and analyze the effects of core factors. following works [34, 8] learn to propose segment candi- dates, which are then classified by Fast R-CNN. In these Our models can run at about 200ms per frame on a GPU, methods, segmentation precedes recognition, which is slow and training on COCO takes one to two days on a single and less accurate. Likewise, Dai et al. [10] proposed a com- 8-GPU machine. We believe the fast train and test speeds, plex multiple-stage cascade that predicts segment proposals together with the framework’s flexibility and accuracy, will from bounding-box proposals, followed by classification. benefit and ease future research on instance segmentation. Instead, our method is based on parallel prediction of masks Finally, we showcase the generality of our framework and class labels, which is simpler and more flexible. via the task of human pose estimation on the COCO key- Most recently, Li et al. [26] combined the segment pro- point dataset [28]. By viewing each keypoint as a one-hot posal system in [8] and object detection system in [11] for binary mask, with minimal modification Mask R-CNN can “fully convolutional instance segmentation” (FCIS). The be applied to detect instance-specific poses. Mask R-CNN common idea in [8, 11, 26] is to predict a set of position- surpasses the winner of the 2016 COCO keypoint compe- sensitive output channels fully convolutionally. These tition, and at the same time runs at 5 fps. Mask R-CNN, channels simultaneously address object classes, boxes, and therefore, can be seen more broadly as a flexible framework masks, making the system fast. But FCIS exhibits system- for instance-level recognition and can be readily extended atic errors on overlapping instances and creates spurious to more complex tasks. edges (Figure 6), showing that it is challenged by the fun- We have released code to facilitate future research. damental difficulties of segmenting instances. 2
3 . Another family of solutions [23, 4, 3, 29] to instance seg- Figure 3. RoIAlign: The dashed grid rep- resents a feature map, the solid lines an RoI mentation are driven by the success of semantic segmen- (with 2×2 bins in this example), and the dots tation. Starting from per-pixel classification results (e.g., the 4 sampling points in each bin. RoIAlign FCN outputs), these methods attempt to cut the pixels of computes the value of each sampling point the same category into different instances. In contrast to the by bilinear interpolation from the nearby grid points on the feature map. No quantization is segmentation-first strategy of these methods, Mask R-CNN performed on any coordinates involved in the is based on an instance-first strategy. We expect a deeper in- RoI, its bins, or the sampling points. corporation of both strategies will be studied in the future. class label used to select the output mask. This decouples 3. Mask R-CNN mask and class prediction. This is different from common practice when applying FCNs [30] to semantic segmenta- Mask R-CNN is conceptually simple: Faster R-CNN has tion, which typically uses a per-pixel softmax and a multino- two outputs for each candidate object, a class label and a mial cross-entropy loss. In that case, masks across classes bounding-box offset; to this we add a third branch that out- compete; in our case, with a per-pixel sigmoid and a binary puts the object mask. Mask R-CNN is thus a natural and in- loss, they do not. We show by experiments that this formu- tuitive idea. But the additional mask output is distinct from lation is key for good instance segmentation results. the class and box outputs, requiring extraction of much finer Mask Representation: A mask encodes an input object’s spatial layout of an object. Next, we introduce the key ele- spatial layout. Thus, unlike class labels or box offsets ments of Mask R-CNN, including pixel-to-pixel alignment, that are inevitably collapsed into short output vectors by which is the main missing piece of Fast/Faster R-CNN. fully-connected (fc) layers, extracting the spatial structure Faster R-CNN: We begin by briefly reviewing the Faster of masks can be addressed naturally by the pixel-to-pixel R-CNN detector [36]. Faster R-CNN consists of two stages. correspondence provided by convolutions. The first stage, called a Region Proposal Network (RPN), Specifically, we predict an m × m mask from each RoI proposes candidate object bounding boxes. The second using an FCN [30]. This allows each layer in the mask stage, which is in essence Fast R-CNN [12], extracts fea- branch to maintain the explicit m × m object spatial lay- tures using RoIPool from each candidate box and performs out without collapsing it into a vector representation that classification and bounding-box regression. The features lacks spatial dimensions. Unlike previous methods that re- used by both stages can be shared for faster inference. We sort to fc layers for mask prediction [33, 34, 10], our fully refer readers to [21] for latest, comprehensive comparisons convolutional representation requires fewer parameters, and between Faster R-CNN and other frameworks. is more accurate as demonstrated by experiments. Mask R-CNN: Mask R-CNN adopts the same two-stage This pixel-to-pixel behavior requires our RoI features, procedure, with an identical first stage (which is RPN). In which themselves are small feature maps, to be well aligned the second stage, in parallel to predicting the class and box to faithfully preserve the explicit per-pixel spatial corre- offset, Mask R-CNN also outputs a binary mask for each spondence. This motivated us to develop the following RoI. This is in contrast to most recent systems, where clas- RoIAlign layer that plays a key role in mask prediction. sification depends on mask predictions (e.g. [33, 10, 26]). RoIAlign: RoIPool [12] is a standard operation for extract- Our approach follows the spirit of Fast R-CNN [12] that ing a small feature map (e.g., 7×7) from each RoI. RoIPool applies bounding-box classification and regression in par- first quantizes a floating-number RoI to the discrete granu- allel (which turned out to largely simplify the multi-stage larity of the feature map, this quantized RoI is then subdi- pipeline of original R-CNN [13]). vided into spatial bins which are themselves quantized, and Formally, during training, we define a multi-task loss on finally feature values covered by each bin are aggregated each sampled RoI as L = Lcls + Lbox + Lmask . The clas- (usually by max pooling). Quantization is performed, e.g., sification loss Lcls and bounding-box loss Lbox are identi- on a continuous coordinate x by computing [x/16], where cal as those defined in [12]. The mask branch has a Km2 - 16 is a feature map stride and [·] is rounding; likewise, quan- dimensional output for each RoI, which encodes K binary tization is performed when dividing into bins (e.g., 7×7). masks of resolution m × m, one for each of the K classes. These quantizations introduce misalignments between the To this we apply a per-pixel sigmoid, and define Lmask as RoI and the extracted features. While this may not impact the average binary cross-entropy loss. For an RoI associated classification, which is robust to small translations, it has a with ground-truth class k, Lmask is only defined on the k-th large negative effect on predicting pixel-accurate masks. mask (other mask outputs do not contribute to the loss). To address this, we propose an RoIAlign layer that re- Our definition of Lmask allows the network to generate moves the harsh quantization of RoIPool, properly aligning masks for every class without competition among classes; the extracted features with the input. Our proposed change we rely on the dedicated classification branch to predict the is simple: we avoid any quantization of the RoI boundaries 3
4 . Faster R-CNN Faster R-CNN or bins (i.e., we use x/16 instead of [x/16]). We use bi- w/ ResNet [19] w/ FPN [27] class class linear interpolation [22] to compute the exact values of the 7×7 7×7 ave 7×7 RoI ×1024 res5 ×2048 2048 RoI ×256 1024 1024 box box input features at four regularly sampled locations in each RoI bin, and aggregate the result (using max or average), 14×14 14×14 14×14 14×14 28×28 28×28 see Figure 3 for details. We note that the results are not sen- ×256 ×80 RoI ×256 ×4 ×256 ×256 ×80 sitive to the exact sampling locations, or how many points mask mask are sampled, as long as no quantization is performed. Figure 4. Head Architecture: We extend two existing Faster R- RoIAlign leads to large improvements as we show in CNN heads [19, 27]. Left/Right panels show the heads for the §4.2. We also compare to the RoIWarp operation proposed ResNet C4 and FPN backbones, from [19] and [27], respectively, in [10]. Unlike RoIAlign, RoIWarp overlooked the align- to which a mask branch is added. Numbers denote spatial resolu- ment issue and was implemented in [10] as quantizing RoI tion and channels. Arrows denote either conv, deconv, or fc layers just like RoIPool. So even though RoIWarp also adopts as can be inferred from context (conv preserves spatial dimension bilinear resampling motivated by [22], it performs on par while deconv increases it). All convs are 3×3, except the output conv which is 1×1, deconvs are 2×2 with stride 2, and we use with RoIPool as shown by experiments (more details in Ta- ReLU [31] in hidden layers. Left: ‘res5’ denotes ResNet’s fifth ble 2c), demonstrating the crucial role of alignment. stage, which for simplicity we altered so that the first conv oper- Network Architecture: To demonstrate the generality of ates on a 7×7 RoI with stride 1 (instead of 14×14 / stride 2 as in our approach, we instantiate Mask R-CNN with multiple [19]). Right: ‘×4’ denotes a stack of four consecutive convs. architectures. For clarity, we differentiate between: (i) the convolutional backbone architecture used for feature ex- 3.1. Implementation Details traction over an entire image, and (ii) the network head We set hyper-parameters following existing Fast/Faster for bounding-box recognition (classification and regression) R-CNN work [12, 36, 27]. Although these decisions were and mask prediction that is applied separately to each RoI. made for object detection in original papers [12, 36, 27], we We denote the backbone architecture using the nomen- found our instance segmentation system is robust to them. clature network-depth-features. We evaluate ResNet [19] and ResNeXt [45] networks of depth 50 or 101 layers. The Training: As in Fast R-CNN, an RoI is considered positive original implementation of Faster R-CNN with ResNets if it has IoU with a ground-truth box of at least 0.5 and [19] extracted features from the final convolutional layer negative otherwise. The mask loss Lmask is defined only on of the 4-th stage, which we call C4. This backbone with positive RoIs. The mask target is the intersection between ResNet-50, for example, is denoted by ResNet-50-C4. This an RoI and its associated ground-truth mask. is a common choice used in [19, 10, 21, 39]. We adopt image-centric training [12]. Images are resized We also explore another more effective backbone re- such that their scale (shorter edge) is 800 pixels [27]. Each cently proposed by Lin et al. [27], called a Feature Pyra- mini-batch has 2 images per GPU and each image has N mid Network (FPN). FPN uses a top-down architecture with sampled RoIs, with a ratio of 1:3 of positive to negatives lateral connections to build an in-network feature pyramid [12]. N is 64 for the C4 backbone (as in [12, 36]) and 512 from a single-scale input. Faster R-CNN with an FPN back- for FPN (as in [27]). We train on 8 GPUs (so effective mini- bone extracts RoI features from different levels of the fea- batch size is 16) for 160k iterations, with a learning rate of ture pyramid according to their scale, but otherwise the 0.02 which is decreased by 10 at the 120k iteration. We rest of the approach is similar to vanilla ResNet. Using a use a weight decay of 0.0001 and momentum of 0.9. With ResNet-FPN backbone for feature extraction with Mask R- ResNeXt [45], we train with 1 image per GPU and the same CNN gives excellent gains in both accuracy and speed. For number of iterations, with a starting learning rate of 0.01. further details on FPN, we refer readers to [27]. The RPN anchors span 5 scales and 3 aspect ratios, fol- For the network head we closely follow architectures lowing [27]. For convenient ablation, RPN is trained sep- presented in previous work to which we add a fully con- arately and does not share features with Mask R-CNN, un- volutional mask prediction branch. Specifically, we ex- less specified. For every entry in this paper, RPN and Mask tend the Faster R-CNN box heads from the ResNet [19] R-CNN have the same backbones and so they are shareable. and FPN [27] papers. Details are shown in Figure 4. The Inference: At test time, the proposal number is 300 for the head on the ResNet-C4 backbone includes the 5-th stage of C4 backbone (as in [36]) and 1000 for FPN (as in [27]). We ResNet (namely, the 9-layer ‘res5’ [19]), which is compute- run the box prediction branch on these proposals, followed intensive. For FPN, the backbone already includes res5 and by non-maximum suppression [14]. The mask branch is thus allows for a more efficient head that uses fewer filters. then applied to the highest scoring 100 detection boxes. Al- We note that our mask branches have a straightforward though this differs from the parallel computation used in structure. More complex designs have the potential to im- training, it speeds up inference and improves accuracy (due prove performance but are not the focus of this work. to the use of fewer, more accurate RoIs). The mask branch 4
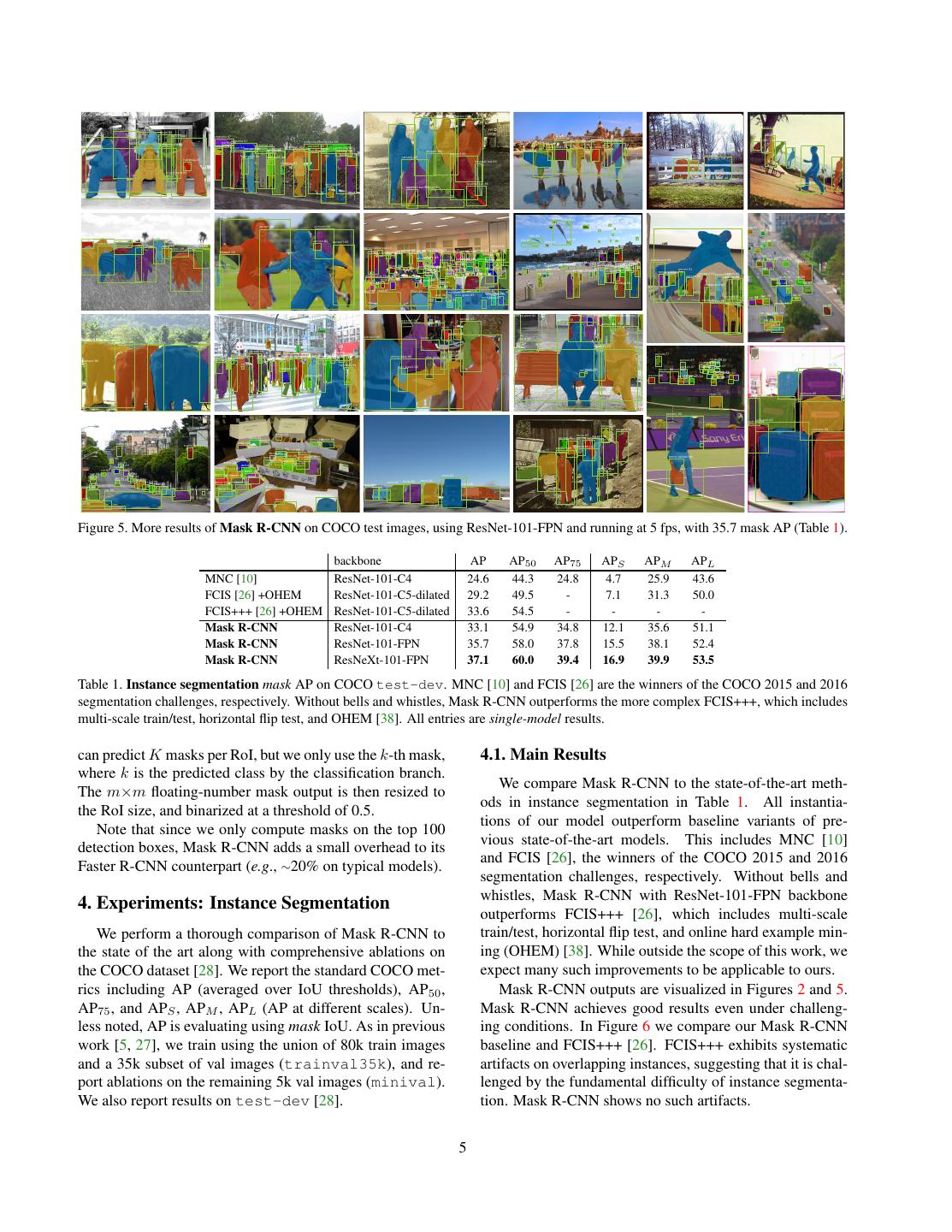
5 . person1.00 person1.00 person1.00 person1.00 person.93 person1.00 person.99 person.99 person.95 person1.00 person1.00 umbrella.97 person1.00 person1.00 person.98 person.98 person.93 umbrella.97 person1.00 surfboard1.00 person1.00 person.99 umbrella.96 umbrella.99 person1.00 skateboard.91 person.91 person1.00 bench.76 umbrella1.00 person1.00 person1.00 person.99 person.98 umbrella.89 umbrella1.00 surfboard1.00 surfboard.98 surfboard1.00 person.74 person1.00 person.89person1.00person1.00 person1.00umbrella.98 person1.00 handbag.97 surfboard1.00 person.95 person.80 person1.00 person1.00 backpack.98 person1.00 horse1.00 person.99 backpack.95 backpack.96 person1.00 horse1.00 horse1.00 handbag.81 baseball bat.99 handbag.85 skateboard.83 baseball bat.85 skateboard.82 bicycle.93 baseball bat.98dog1.00 person.99 kite.72 kite.89 kite.81 kite1.00 kite.99 kite.98 person.99 person1.00 kite.89 person1.00 kite.73 car.87 car.93 kite.88 kite.82 kite.98 zebra1.00 zebra.90 zebra.99 zebra.96 kite.97 kite.84 kite.86 kite.88 kite.95 car.95 zebra.74 person.82 person1.00 car.95 zebra.99 zebra.96 zebra.76 kite.99 zebra.99 car.97 zebra.88 zebra1.00 person.87 kite.95 kite.84 car.99 zebra1.00 person.95person.72 person.99 person.92 person.94 person.95 person.88 person.97 person.99 frisbee1.00 person.97 person.77person.97 person.98 person.82 person.89 person.97 person.83 kite.93 person.99 person.86 person.81 person.77 car.78 person.88 person.98 traffic light.73 person.94 person.88 person.96 person.96person.99person.86 person.99 person.80 skateboard.99 car.98 truck.88 car.93 person.87person.71 person.78 person.98 bus1.00 person.77 person.98 person.98 person.89 person.99 person.80 person.91 chair.96 person.94 person.72 person1.00 person.99 person.81 person.84 chair.98 chair.78 dining cup.93 cup.79 table.81 person.95 person.82 person.72 person1.00 chair.85 dining table.96 dining table.75 person.94 person.99 person1.00 car1.00 chair.89 person.99 person.96 person1.00 person.98 motorcycle.72 person1.00 person.91 cup.75 cup.71 person1.00 person1.00 person1.00 person.99 chair.99 chair.99 chair.98 chair.95 person1.00 person.99 person1.00person1.00 person.99 dining table.78 person.98 person.80 person1.00 wine glass.80 chair.92 car.95truck.86 car.98 chair.95 cup.83 wine glass.80 cup.71 cup.98 chair.85 handbag.80 bus1.00 car.93 skateboard.98 car.97 diningchair.83 table.91 chair.87 chair.97 chair.94 wine glass.91 wine cup.96 wine glass.93 wineglass.94 glass.94 car.99 car.82 wine glass.83 person1.00 car.99 car.99 cup.91 couch.82 person.99 person.90 person.99 car.98 car.96 car.91car.94 potted plant.92 backpack.88 person.86person1.00 handbag.91 person.76 person1.00 person.78 person.98 person.78 person.88 person1.00 car.98 person1.00 person.98 car.78 traffic light.87 tv.98 tv.84 person1.00 traffic light.99 person1.00 bottle.97 elephant1.00 bird.93 elephant1.00 elephant1.00 elephant.97 traffic light.71 bench.97 handbag.73 stop sign.88 person.99 wine glass.99 person1.00 person.98 person.97 person.95 person.77 person.92 person.74 person.99 person.73 person1.00 person.95 person1.00 person.98 person1.00 person.99 person.95 person.99 person.95 dining table.95 person1.00 person.80 wine glass1.00 person.87 person.98 person1.00 person.95 person1.00 person.99 chair.93 elephant.99 person.87 chair.81 tie.85 chair.99chair.97 chair.99 handbag.88 wine glass1.00 person.97 chair.81 suitcase1.00 chair.93 chair.94 chair.92 handbag.88 cell clock.73 phone.77 person.81 person.90 suitcase.98 chair.83 chair.81 chair.98 chair.91 chair.80 handbag.99 person.96 person.71 person.99 person.94 chair.71 person.98 chair.73 suitcase.93 suitcase.96 suitcase.72 person1.00 suitcase1.00 suitcase.88 person.98 person1.00 suitcase.99 donut.86 horse.97 person.96 donut.95 person.96 person.97 person.98 horse.99 donut.89 donut.89donut.89 sports ball.99 traffic light.99 donut.90 traffic light1.00 person1.00 donut.93donut.99 person1.00 horse.77 donut.86 donut.96 donut.95 donut.98 donut.81 tennis racket1.00 car.95 donut.89 donut1.00 donut1.00 donut.96donut.98 car.81 donut.99 donut.98 car.89 donut.98 cow.93 car.98 donut.89 donut.97 person.99 car.97 car.91 donut.95 car.96 car.94 donut.94 car.97 car.94 donut.98 donut1.00 truck.92 person.87 car.95 bicycle.86 car.97 truck.96 car1.00 donut.95 donut.99 truck.97 truck.99 car.96 car.98 car.97 car.99 truck.99 truck.93 bus.90 person.99 car.95 car.97 donut.90 bus.99 car1.00 parking meter.98 donut.96 car.99 donut1.00 car.97 donut.88 car.86 Figure 5. More results of Mask R-CNN on COCO test images, using ResNet-101-FPN and running at 5 fps, with 35.7 mask AP (Table 1). backbone AP AP50 AP75 APS APM APL MNC [10] ResNet-101-C4 24.6 44.3 24.8 4.7 25.9 43.6 FCIS [26] +OHEM ResNet-101-C5-dilated 29.2 49.5 - 7.1 31.3 50.0 FCIS+++ [26] +OHEM ResNet-101-C5-dilated 33.6 54.5 - - - - Mask R-CNN ResNet-101-C4 33.1 54.9 34.8 12.1 35.6 51.1 Mask R-CNN ResNet-101-FPN 35.7 58.0 37.8 15.5 38.1 52.4 Mask R-CNN ResNeXt-101-FPN 37.1 60.0 39.4 16.9 39.9 53.5 Table 1. Instance segmentation mask AP on COCO test-dev. MNC [10] and FCIS [26] are the winners of the COCO 2015 and 2016 segmentation challenges, respectively. Without bells and whistles, Mask R-CNN outperforms the more complex FCIS+++, which includes multi-scale train/test, horizontal flip test, and OHEM [38]. All entries are single-model results. can predict K masks per RoI, but we only use the k-th mask, 4.1. Main Results where k is the predicted class by the classification branch. We compare Mask R-CNN to the state-of-the-art meth- The m×m floating-number mask output is then resized to ods in instance segmentation in Table 1. All instantia- the RoI size, and binarized at a threshold of 0.5. tions of our model outperform baseline variants of pre- Note that since we only compute masks on the top 100 vious state-of-the-art models. This includes MNC [10] detection boxes, Mask R-CNN adds a small overhead to its and FCIS [26], the winners of the COCO 2015 and 2016 Faster R-CNN counterpart (e.g., ∼20% on typical models). segmentation challenges, respectively. Without bells and whistles, Mask R-CNN with ResNet-101-FPN backbone 4. Experiments: Instance Segmentation outperforms FCIS+++ [26], which includes multi-scale We perform a thorough comparison of Mask R-CNN to train/test, horizontal flip test, and online hard example min- the state of the art along with comprehensive ablations on ing (OHEM) [38]. While outside the scope of this work, we the COCO dataset [28]. We report the standard COCO met- expect many such improvements to be applicable to ours. rics including AP (averaged over IoU thresholds), AP50 , Mask R-CNN outputs are visualized in Figures 2 and 5. AP75 , and APS , APM , APL (AP at different scales). Un- Mask R-CNN achieves good results even under challeng- less noted, AP is evaluating using mask IoU. As in previous ing conditions. In Figure 6 we compare our Mask R-CNN work [5, 27], we train using the union of 80k train images baseline and FCIS+++ [26]. FCIS+++ exhibits systematic and a 35k subset of val images (trainval35k), and re- artifacts on overlapping instances, suggesting that it is chal- port ablations on the remaining 5k val images (minival). lenged by the fundamental difficulty of instance segmenta- We also report results on test-dev [28]. tion. Mask R-CNN shows no such artifacts. 5
6 .FCIS umbrella.99 umbrella1.00 person1.00 person1.00 person1.00 person1.00 person1.00 person1.00 person1.00 Mask R-CNN person1.00 person1.00 person1.00 train1.00 person1.00 person1.00 person1.00 train.99 person1.00 person1.00 person.99 person1.00 giraffe1.00 giraffe1.00 person.99 person1.00 car.99 car.93 train.80 person.95 handbag.93 tie.95 skateboard.98 tie1.00 sports ball.98 sports ball1.00 skateboard.99 Figure 6. FCIS+++ [26] (top) vs. Mask R-CNN (bottom, ResNet-101-FPN). FCIS exhibits systematic artifacts on overlapping objects. net-depth-features AP AP50 AP75 AP AP50 AP75 align? bilinear? agg. AP AP50 AP75 ResNet-50-C4 30.3 51.2 31.5 softmax 24.8 44.1 25.1 RoIPool [12] max 26.9 48.8 26.4 ResNet-101-C4 32.7 54.2 34.3 sigmoid 30.3 51.2 31.5 max 27.2 49.2 27.1 RoIWarp [10] ResNet-50-FPN 33.6 55.2 35.3 +5.5 +7.1 +6.4 ave 27.1 48.9 27.1 ResNet-101-FPN 35.4 57.3 37.5 max 30.2 51.0 31.8 RoIAlign ResNeXt-101-FPN 36.7 59.5 38.9 ave 30.3 51.2 31.5 (a) Backbone Architecture: Better back- (b) Multinomial vs. Independent Masks (c) RoIAlign (ResNet-50-C4): Mask results with various RoI bones bring expected gains: deeper networks (ResNet-50-C4): Decoupling via per- layers. Our RoIAlign layer improves AP by ∼3 points and do better, FPN outperforms C4 features, and class binary masks (sigmoid) gives large AP75 by ∼5 points. Using proper alignment is the only fac- ResNeXt improves on ResNet. gains over multinomial masks (softmax). tor that contributes to the large gap between RoI layers. AP AP50 AP75 APbb APbb 50 APbb 75 mask branch AP AP50 AP75 RoIPool 23.6 46.5 21.6 28.2 52.7 26.9 MLP fc: 1024→1024→80·282 31.5 53.7 32.8 RoIAlign 30.9 51.8 32.1 34.0 55.3 36.4 MLP fc: 1024→1024→1024→80·282 31.5 54.0 32.6 +7.3 + 5.3 +10.5 +5.8 +2.6 +9.5 FCN conv: 256→256→256→256→256→80 33.6 55.2 35.3 (d) RoIAlign (ResNet-50-C5, stride 32): Mask-level and box-level (e) Mask Branch (ResNet-50-FPN): Fully convolutional networks (FCN) vs. AP using large-stride features. Misalignments are more severe than multi-layer perceptrons (MLP, fully-connected) for mask prediction. FCNs im- with stride-16 features (Table 2c), resulting in big accuracy gaps. prove results as they take advantage of explicitly encoding spatial layout. Table 2. Ablations. We train on trainval35k, test on minival, and report mask AP unless otherwise noted. 4.2. Ablation Experiments mask per class. Interestingly, Mask R-CNN with class- agnostic masks (i.e., predicting a single m×m output re- We run a number of ablations to analyze Mask R-CNN. gardless of class) is nearly as effective: it has 29.7 mask AP Results are shown in Table 2 and discussed in detail next. vs. 30.3 for the class-specific counterpart on ResNet-50-C4. Architecture: Table 2a shows Mask R-CNN with various This further highlights the division of labor in our approach backbones. It benefits from deeper networks (50 vs. 101) which largely decouples classification and segmentation. and advanced designs including FPN and ResNeXt. We note that not all frameworks automatically benefit from RoIAlign: An evaluation of our proposed RoIAlign layer is deeper or advanced networks (see benchmarking in [21]). shown in Table 2c. For this experiment we use the ResNet- 50-C4 backbone, which has stride 16. RoIAlign improves Multinomial vs. Independent Masks: Mask R-CNN de- AP by about 3 points over RoIPool, with much of the gain couples mask and class prediction: as the existing box coming at high IoU (AP75 ). RoIAlign is insensitive to branch predicts the class label, we generate a mask for each max/average pool; we use average in the rest of the paper. class without competition among classes (by a per-pixel sig- Additionally, we compare with RoIWarp proposed in moid and a binary loss). In Table 2b, we compare this to MNC [10] that also adopt bilinear sampling. As discussed using a per-pixel softmax and a multinomial loss (as com- in §3, RoIWarp still quantizes the RoI, losing alignment monly used in FCN [30]). This alternative couples the tasks with the input. As can be seen in Table 2c, RoIWarp per- of mask and class prediction, and results in a severe loss forms on par with RoIPool and much worse than RoIAlign. in mask AP (5.5 points). This suggests that once the in- This highlights that proper alignment is key. stance has been classified as a whole (by the box branch), We also evaluate RoIAlign with a ResNet-50-C5 back- it is sufficient to predict a binary mask without concern for bone, which has an even larger stride of 32 pixels. We use the categories, which makes the model easier to train. the same head as in Figure 4 (right), as the res5 head is not Class-Specific vs. Class-Agnostic Masks: Our default in- applicable. Table 2d shows that RoIAlign improves mask stantiation predicts class-specific masks, i.e., one m×m AP by a massive 7.3 points, and mask AP75 by 10.5 points 6
7 . backbone APbb APbb 50 APbb 75 APbb S APbb M APbb L Faster R-CNN+++ [19] ResNet-101-C4 34.9 55.7 37.4 15.6 38.7 50.9 Faster R-CNN w FPN [27] ResNet-101-FPN 36.2 59.1 39.0 18.2 39.0 48.2 Faster R-CNN by G-RMI [21] Inception-ResNet-v2 [41] 34.7 55.5 36.7 13.5 38.1 52.0 Faster R-CNN w TDM [39] Inception-ResNet-v2-TDM 36.8 57.7 39.2 16.2 39.8 52.1 Faster R-CNN, RoIAlign ResNet-101-FPN 37.3 59.6 40.3 19.8 40.2 48.8 Mask R-CNN ResNet-101-FPN 38.2 60.3 41.7 20.1 41.1 50.2 Mask R-CNN ResNeXt-101-FPN 39.8 62.3 43.4 22.1 43.2 51.2 Table 3. Object detection single-model results (bounding box AP), vs. state-of-the-art on test-dev. Mask R-CNN using ResNet-101- FPN outperforms the base variants of all previous state-of-the-art models (the mask output is ignored in these experiments). The gains of Mask R-CNN over [27] come from using RoIAlign (+1.1 APbb ), multitask training (+0.9 APbb ), and ResNeXt-101 (+1.6 APbb ). (50% relative improvement). Moreover, we note that with 4.4. Timing RoIAlign, using stride-32 C5 features (30.9 AP) is more ac- Inference: We train a ResNet-101-FPN model that shares curate than using stride-16 C4 features (30.3 AP, Table 2c). features between the RPN and Mask R-CNN stages, follow- RoIAlign largely resolves the long-standing challenge of ing the 4-step training of Faster R-CNN [36]. This model using large-stride features for detection and segmentation. runs at 195ms per image on an Nvidia Tesla M40 GPU (plus Finally, RoIAlign shows a gain of 1.5 mask AP and 0.5 15ms CPU time resizing the outputs to the original resolu- box AP when used with FPN, which has finer multi-level tion), and achieves statistically the same mask AP as the strides. For keypoint detection that requires finer alignment, unshared one. We also report that the ResNet-101-C4 vari- RoIAlign shows large gains even with FPN (Table 6). ant takes ∼400ms as it has a heavier box head (Figure 4), so Mask Branch: Segmentation is a pixel-to-pixel task and we do not recommend using the C4 variant in practice. we exploit the spatial layout of masks by using an FCN. Although Mask R-CNN is fast, we note that our design In Table 2e, we compare multi-layer perceptrons (MLP) is not optimized for speed, and better speed/accuracy trade- and FCNs, using a ResNet-50-FPN backbone. Using FCNs offs could be achieved [21], e.g., by varying image sizes and gives a 2.1 mask AP gain over MLPs. We note that we proposal numbers, which is beyond the scope of this paper. choose this backbone so that the conv layers of the FCN Training: Mask R-CNN is also fast to train. Training with head are not pre-trained, for a fair comparison with MLP. ResNet-50-FPN on COCO trainval35k takes 32 hours in our synchronized 8-GPU implementation (0.72s per 16- 4.3. Bounding Box Detection Results image mini-batch), and 44 hours with ResNet-101-FPN. In We compare Mask R-CNN to the state-of-the-art COCO fact, fast prototyping can be completed in less than one day bounding-box object detection in Table 3. For this result, when training on the train set. We hope such rapid train- even though the full Mask R-CNN model is trained, only ing will remove a major hurdle in this area and encourage the classification and box outputs are used at inference (the more people to perform research on this challenging topic. mask output is ignored). Mask R-CNN using ResNet-101- FPN outperforms the base variants of all previous state-of- 5. Mask R-CNN for Human Pose Estimation the-art models, including the single-model variant of G- RMI [21], the winner of the COCO 2016 Detection Chal- Our framework can easily be extended to human pose lenge. Using ResNeXt-101-FPN, Mask R-CNN further im- estimation. We model a keypoint’s location as a one-hot proves results, with a margin of 3.0 points box AP over mask, and adopt Mask R-CNN to predict K masks, one for the best previous single model entry from [39] (which used each of K keypoint types (e.g., left shoulder, right elbow). Inception-ResNet-v2-TDM). This task helps demonstrate the flexibility of Mask R-CNN. As a further comparison, we trained a version of Mask We note that minimal domain knowledge for human pose R-CNN but without the mask branch, denoted by “Faster is exploited by our system, as the experiments are mainly to R-CNN, RoIAlign” in Table 3. This model performs better demonstrate the generality of the Mask R-CNN framework. than the model presented in [27] due to RoIAlign. On the We expect that domain knowledge (e.g., modeling struc- other hand, it is 0.9 points box AP lower than Mask R-CNN. tures [6]) will be complementary to our simple approach. This gap of Mask R-CNN on box detection is therefore due Implementation Details: We make minor modifications to solely to the benefits of multi-task training. the segmentation system when adapting it for keypoints. Lastly, we note that Mask R-CNN attains a small gap For each of the K keypoints of an instance, the training between its mask and box AP: e.g., 2.7 points between 37.1 target is a one-hot m × m binary mask where only a single (mask, Table 1) and 39.8 (box, Table 3). This indicates that pixel is labeled as foreground. During training, for each vis- our approach largely closes the gap between object detec- ible ground-truth keypoint, we minimize the cross-entropy tion and the more challenging instance segmentation task. loss over an m2 -way softmax output (which encourages a 7
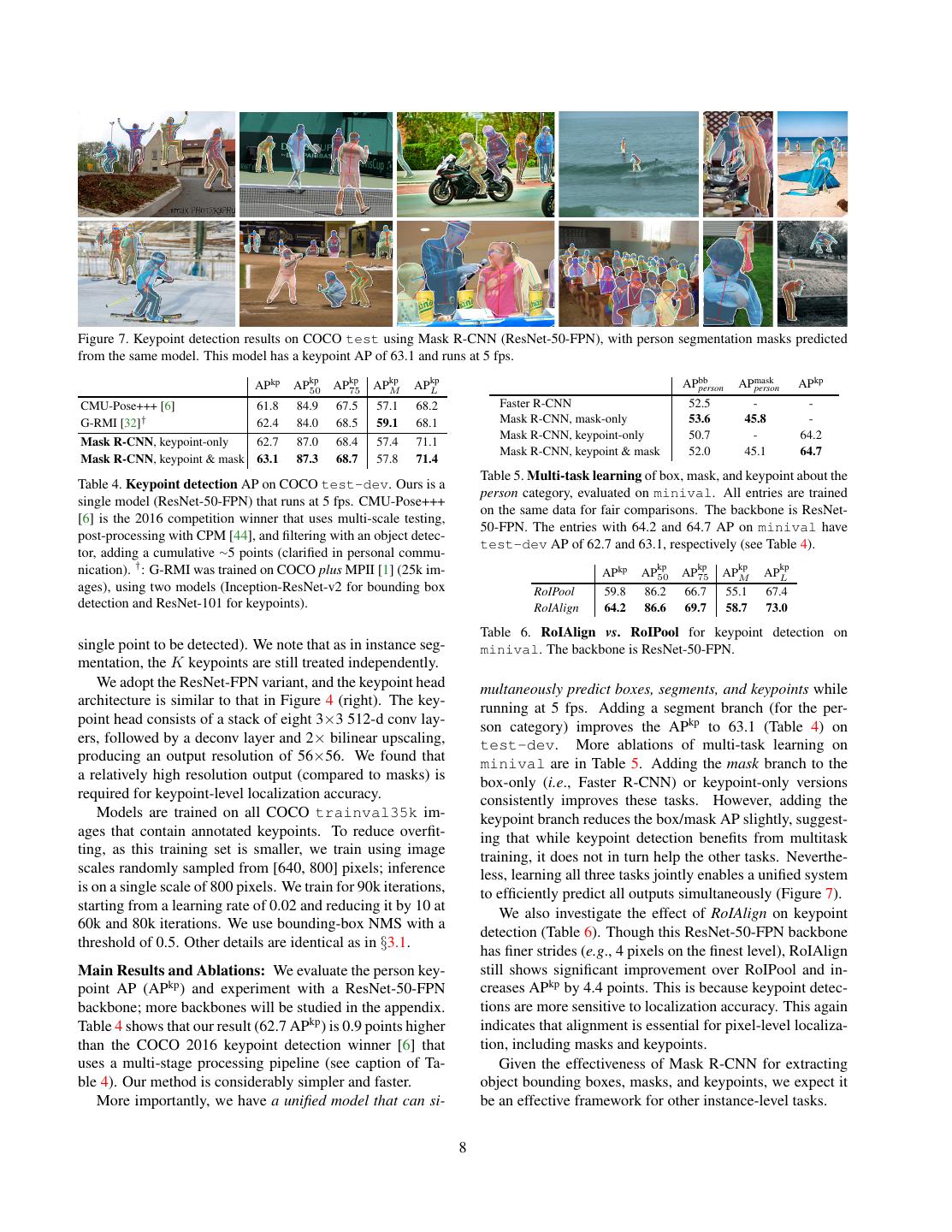
8 .Figure 7. Keypoint detection results on COCO test using Mask R-CNN (ResNet-50-FPN), with person segmentation masks predicted from the same model. This model has a keypoint AP of 63.1 and runs at 5 fps. kp kp kp kp APkp AP50 AP75 APM APL APbb person APmask person APkp CMU-Pose+++ [6] 61.8 84.9 67.5 57.1 68.2 Faster R-CNN 52.5 - - G-RMI [32]† 62.4 84.0 68.5 59.1 68.1 Mask R-CNN, mask-only 53.6 45.8 - Mask R-CNN, keypoint-only 50.7 - 64.2 Mask R-CNN, keypoint-only 62.7 87.0 68.4 57.4 71.1 Mask R-CNN, keypoint & mask 52.0 45.1 64.7 Mask R-CNN, keypoint & mask 63.1 87.3 68.7 57.8 71.4 Table 5. Multi-task learning of box, mask, and keypoint about the Table 4. Keypoint detection AP on COCO test-dev. Ours is a person category, evaluated on minival. All entries are trained single model (ResNet-50-FPN) that runs at 5 fps. CMU-Pose+++ on the same data for fair comparisons. The backbone is ResNet- [6] is the 2016 competition winner that uses multi-scale testing, 50-FPN. The entries with 64.2 and 64.7 AP on minival have post-processing with CPM [44], and filtering with an object detec- test-dev AP of 62.7 and 63.1, respectively (see Table 4). tor, adding a cumulative ∼5 points (clarified in personal commu- nication). † : G-RMI was trained on COCO plus MPII [1] (25k im- APkp kp AP50 kp AP75 APM kp APL kp ages), using two models (Inception-ResNet-v2 for bounding box RoIPool 59.8 86.2 66.7 55.1 67.4 detection and ResNet-101 for keypoints). RoIAlign 64.2 86.6 69.7 58.7 73.0 Table 6. RoIAlign vs. RoIPool for keypoint detection on single point to be detected). We note that as in instance seg- minival. The backbone is ResNet-50-FPN. mentation, the K keypoints are still treated independently. We adopt the ResNet-FPN variant, and the keypoint head multaneously predict boxes, segments, and keypoints while architecture is similar to that in Figure 4 (right). The key- running at 5 fps. Adding a segment branch (for the per- point head consists of a stack of eight 3×3 512-d conv lay- son category) improves the APkp to 63.1 (Table 4) on ers, followed by a deconv layer and 2× bilinear upscaling, test-dev. More ablations of multi-task learning on producing an output resolution of 56×56. We found that minival are in Table 5. Adding the mask branch to the a relatively high resolution output (compared to masks) is box-only (i.e., Faster R-CNN) or keypoint-only versions required for keypoint-level localization accuracy. consistently improves these tasks. However, adding the Models are trained on all COCO trainval35k im- keypoint branch reduces the box/mask AP slightly, suggest- ages that contain annotated keypoints. To reduce overfit- ing that while keypoint detection benefits from multitask ting, as this training set is smaller, we train using image training, it does not in turn help the other tasks. Neverthe- scales randomly sampled from [640, 800] pixels; inference less, learning all three tasks jointly enables a unified system is on a single scale of 800 pixels. We train for 90k iterations, to efficiently predict all outputs simultaneously (Figure 7). starting from a learning rate of 0.02 and reducing it by 10 at We also investigate the effect of RoIAlign on keypoint 60k and 80k iterations. We use bounding-box NMS with a detection (Table 6). Though this ResNet-50-FPN backbone threshold of 0.5. Other details are identical as in §3.1. has finer strides (e.g., 4 pixels on the finest level), RoIAlign Main Results and Ablations: We evaluate the person key- still shows significant improvement over RoIPool and in- point AP (APkp ) and experiment with a ResNet-50-FPN creases APkp by 4.4 points. This is because keypoint detec- backbone; more backbones will be studied in the appendix. tions are more sensitive to localization accuracy. This again Table 4 shows that our result (62.7 APkp ) is 0.9 points higher indicates that alignment is essential for pixel-level localiza- than the COCO 2016 keypoint detection winner [6] that tion, including masks and keypoints. uses a multi-stage processing pipeline (see caption of Ta- Given the effectiveness of Mask R-CNN for extracting ble 4). Our method is considerably simpler and faster. object bounding boxes, masks, and keypoints, we expect it More importantly, we have a unified model that can si- be an effective framework for other instance-level tasks. 8
9 . training data AP [val] AP AP50 person rider car truck bus train mcycle bicycle InstanceCut [23] fine + coarse 15.8 13.0 27.9 10.0 8.0 23.7 14.0 19.5 15.2 9.3 4.7 DWT [4] fine 19.8 15.6 30.0 15.1 11.7 32.9 17.1 20.4 15.0 7.9 4.9 SAIS [17] fine - 17.4 36.7 14.6 12.9 35.7 16.0 23.2 19.0 10.3 7.8 DIN [3] fine + coarse - 20.0 38.8 16.5 16.7 25.7 20.6 30.0 23.4 17.1 10.1 SGN [29] fine + coarse 29.2 25.0 44.9 21.8 20.1 39.4 24.8 33.2 30.8 17.7 12.4 Mask R-CNN fine 31.5 26.2 49.9 30.5 23.7 46.9 22.8 32.2 18.6 19.1 16.0 Mask R-CNN fine + COCO 36.4 32.0 58.1 34.8 27.0 49.1 30.1 40.9 30.9 24.1 18.7 Table 7. Results on Cityscapes val (‘AP [val]’ column) and test (remaining columns) sets. Our method uses ResNet-50-FPN. Appendix A: Experiments on Cityscapes person:0.99 person:1.00 person:1.00 rider:0.59 person:0.79 person:1.00 person:1.00 person:1.00 person:1.00 person:1.00 person:0.66 person:0.59 person:1.00 bus:1.00 person:1.00 bus:0.95 person:1.00 person:1.00 truck:0.66 person:1.00 person:1.00 person:0.98 car:1.00 person:0.99 car:0.98 person:0.82 person:0.92 person:0.99person:0.67 person:1.00 person:0.99 person:0.98 person:0.73 car:0.52 car:1.00 car:0.64 person:1.00 We further report instance segmentation results on the person:0.82 car:0.81 person:0.98 person:0.94 person:0.94 person:0.98 car:0.95 car:0.68 car:1.00 car:0.68 car:0.52 person:0.82 person:0.99 car:0.98 car:0.95 car:1.00 car:0.57 person:0.63car:1.00 rider:0.68 person:0.72 person:0.93 person:0.97 person:0.99 person:0.99 person:0.86person:0.98 person:0.73 person:0.98 bicycle:0.83 car:0.99car:1.00 car:0.69car:1.00 car:1.00 car:1.00 person:0.84 person:0.98 person:0.99 person:0.72 person:0.72 car:1.00car:0.95 car:0.95 person:0.91 bicycle:0.56 Cityscapes [7] dataset. This dataset has fine annota- tions for 2975 train, 500 val, and 1525 test images. It has 20k coarse training images without instance annotations, which we do not use. All images are 2048×1024 pixels. person:1.00 car:1.00 car:1.00 car:1.00 car:1.00 car:1.00 person:1.00 person:1.00 car:1.00 car:1.00 car:1.00 person:0.82 person:1.00 person:1.00 The instance segmentation task involves 8 object categories, car:0.97 person:0.78 car:1.00 car:0.50 car:1.00 car:1.00 person:0.73 car:0.72 person:0.98 person:1.00 person:0.58 car:1.00 car:0.65 bus:0.75 person:0.85car:1.00 car:1.00 car:1.00 car:1.00 car:0.72 car:0.76 car:1.00 car:1.00 car:1.00 person:0.93 car:1.00 car:1.00 car:0.98 car:0.88 car:1.00 car:1.00 car:0.99 car:1.00 car:0.89 car:0.67 whose numbers of instances on the fine training set are: person rider car truck bus train mcycle bicycle 17.9k 1.8k 26.9k 0.5k 0.4k 0.2k 0.7k 3.7k Instance segmentation performance on this task is measured person:1.00 person:1.00 person:0.99 person:1.00 person:1.00 person:1.00person:1.00 person:1.00 person:0.92 person:1.00person:0.97 person:1.00 person:1.00 person:1.00 person:1.00 person:0.75 person:0.93 person:1.00 person:1.00 person:1.00 person:1.00 person:0.96 person:1.00 person:1.00 person:1.00 person:1.00person:1.00 person:1.00 person:1.00person:0.98 person:1.00 car:1.00 rider:0.94 person:1.00 person:0.99 person:1.00 person:1.00 by the COCO-style mask AP (averaged over IoU thresh- person:0.70 person:0.59 person:0.96 car:0.99 car:1.00 person:0.88 person:0.89 car:0.89 bicycle:0.97 bicycle:0.99 olds); AP50 (i.e., mask AP at an IoU of 0.5) is also reported. person:0.91 Implementation: We apply our Mask R-CNN models with the ResNet-FPN-50 backbone; we found the 101-layer Figure 8. Mask R-CNN results on Cityscapes test (32.0 AP). counterpart performs similarly due to the small dataset size. The bottom-right image shows a failure prediction. We train with image scale (shorter side) randomly sampled ing samples each. To partially remedy this issue, we further from [800, 1024], which reduces overfitting; inference is on report a result using COCO pre-training. To do this, we ini- a single scale of 1024 pixels. We use a mini-batch size of tialize the corresponding 7 categories in Cityscapes from a 1 image per GPU (so 8 on 8 GPUs) and train the model pre-trained COCO Mask R-CNN model (rider being ran- for 24k iterations, starting from a learning rate of 0.01 and domly initialized). We fine-tune this model for 4k iterations reducing it to 0.001 at 18k iterations. It takes ∼4 hours of in which the learning rate is reduced at 3k iterations, which training on a single 8-GPU machine under this setting. takes ∼1 hour for training given the COCO model. Results: Table 7 compares our results to the state of the The COCO pre-trained Mask R-CNN model achieves art on the val and test sets. Without using the coarse 32.0 AP on test, almost a 6 point improvement over the training set, our method achieves 26.2 AP on test, which fine-only counterpart. This indicates the important role is over 30% relative improvement over the previous best en- the amount of training data plays. It also suggests that try (DIN [3]), and is also better than the concurrent work of methods on Cityscapes might be influenced by their low- SGN’s 25.0 [29]. Both DIN and SGN use fine + coarse shot learning performance. We show that using COCO pre- data. Compared to the best entry using fine data only training is an effective strategy on this dataset. (17.4 AP), we achieve a ∼50% improvement. Finally, we observed a bias between the val and test For the person and car categories, the Cityscapes dataset AP, as is also observed from the results of [23, 4, 29]. We exhibits a large number of within-category overlapping in- found that this bias is mainly caused by the truck, bus, stances (on average 6 people and 9 cars per image). We and train categories, with the fine-only model having argue that within-category overlap is a core difficulty of in- val/test AP of 28.8/22.8, 53.5/32.2, and 33.0/18.6, re- stance segmentation. Our method shows massive improve- spectively. This suggests that there is a domain shift on ment on these two categories over the other best entries (rel- these categories, which also have little training data. COCO ative ∼40% improvement on person from 21.8 to 30.5 and pre-training helps to improve results the most on these cat- ∼20% improvement on car from 39.4 to 46.9), even though egories; however, the domain shift persists with 38.0/30.1, our method does not exploit the coarse data. 57.5/40.9, and 41.2/30.9 val/test AP, respectively. Note A main challenge of the Cityscapes dataset is training that for the person and car categories we do not see any models in a low-data regime, particularly for the categories such bias (val/test AP are within ±1 point). of truck, bus, and train, which have about 200-500 train- Example results on Cityscapes are shown in Figure 8. 9
10 . APbb APbb APbb kp kp kp kp description backbone AP AP50 AP75 50 75 description backbone APkp AP50 AP75 APM APL original baseline X-101-FPN 36.7 59.5 38.9 39.6 61.5 43.2 original baseline R-50-FPN 64.2 86.6 69.7 58.7 73.0 + updated baseline X-101-FPN 37.0 59.7 39.0 40.5 63.0 43.7 + updated baseline R-50-FPN 65.1 86.6 70.9 59.9 73.6 + e2e training X-101-FPN 37.6 60.4 39.9 41.7 64.1 45.2 + deeper R-101-FPN 66.1 87.7 71.7 60.5 75.0 + ImageNet-5k X-101-FPN 38.6 61.7 40.9 42.7 65.1 46.6 + ResNeXt X-101-FPN 67.3 88.0 73.3 62.2 75.6 + train-time augm. X-101-FPN 39.2 62.5 41.6 43.5 65.9 47.2 + data distillation [35] X-101-FPN 69.1 88.9 75.3 64.1 77.1 + deeper X-152-FPN 39.7 63.2 42.2 44.1 66.4 48.4 + test-time augm. X-101-FPN 70.4 89.3 76.8 65.8 78.1 + Non-local [43] X-152-FPN-NL 40.3 64.4 42.8 45.0 67.8 48.9 + test-time augm. X-152-FPN-NL 41.8 66.0 44.8 47.3 69.3 51.5 Table 9. Enhanced keypoint results of Mask R-CNN on COCO Table 8. Enhanced detection results of Mask R-CNN on COCO minival. Each row adds an extra component to the above row. minival. Each row adds an extra component to the above row. Here we use only keypoint annotations but no mask annotations. We denote ResNeXt model by ‘X’ for notational brevity. We denote ResNet by ‘R’ and ResNeXt by ‘X’ for brevity. Appendix B: Enhanced Results on COCO Train-time augmentation: Scale augmentation at train time further improves results. During training, we randomly As a general framework, Mask R-CNN is compat- sample a scale from [640, 800] pixels and we increase the ible with complementary techniques developed for de- number of iterations to 260k (with the learning rate reduced tection/segmentation, including improvements made to by 10 at 200k and 240k iterations). Train-time augmenta- Fast/Faster R-CNN and FCNs. In this appendix we de- tion improves mask AP by 0.6 and box AP by 0.8. scribe some techniques that improve over our original re- Model architecture: By upgrading the 101-layer sults. Thanks to its generality and flexibility, Mask R-CNN ResNeXt to its 152-layer counterpart [19], we observe an was used as the framework by the three winning teams in increase of 0.5 mask AP and 0.6 box AP. This shows a the COCO 2017 instance segmentation competition, which deeper model can still improve results on COCO. all significantly outperformed the previous state of the art. Using the recently proposed non-local (NL) model [43], we achieve 40.3 mask AP and 45.0 box AP. This result is Instance Segmentation and Object Detection without test-time augmentation, and the method runs at 3fps We report some enhanced results of Mask R-CNN in Ta- on an Nvidia Tesla P100 GPU at test time. ble 8. Overall, the improvements increase mask AP 5.1 Test-time augmentation: We combine the model results points (from 36.7 to 41.8) and box AP 7.7 points (from 39.6 evaluated using scales of [400, 1200] pixels with a step of to 47.3). Each model improvement increases both mask AP 100 and on their horizontal flips. This gives us a single- and box AP consistently, showing good generalization of model result of 41.8 mask AP and 47.3 box AP. the Mask R-CNN framework. We detail the improvements The above result is the foundation of our submission to next. These results, along with future updates, can be repro- the COCO 2017 competition (which also used an ensemble, duced by our released code at https://github.com/ not discussed here). The first three winning teams for the facebookresearch/Detectron, and can serve as instance segmentation task were all reportedly based on an higher baselines for future research. extension of the Mask R-CNN framework. Updated baseline: We start with an updated baseline Keypoint Detection with a different set of hyper-parameters. We lengthen the training to 180k iterations, in which the learning rate is re- We report enhanced results of keypoint detection in Ta- duced by 10 at 120k and 160k iterations. We also change ble 9. As an updated baseline, we extend the training sched- the NMS threshold to 0.5 (from a default value of 0.3). The ule to 130k iterations in which the learning rate is reduced updated baseline has 37.0 mask AP and 40.5 box AP. by 10 at 100k and 120k iterations. This improves APkp by End-to-end training: All previous results used stage- about 1 point. Replacing ResNet-50 with ResNet-101 and wise training, i.e., training RPN as the first stage and Mask ResNeXt-101 increases APkp to 66.1 and 67.3, respectively. R-CNN as the second. Following [37], we evaluate end- With a recent method called data distillation [35], we are to-end (‘e2e’) training that jointly trains RPN and Mask R- able to exploit the additional 120k unlabeled images pro- CNN. We adopt the ‘approximate’ version in [37] that only vided by COCO. In brief, data distillation is a self-training computes partial gradients in the RoIAlign layer by ignor- strategy that uses a model trained on labeled data to pre- ing the gradient w.r.t. RoI coordinates. Table 8 shows that dict annotations on unlabeled images, and in turn updates e2e training improves mask AP by 0.6 and box AP by 1.2. the model with these new annotations. Mask R-CNN pro- ImageNet-5k pre-training: Following [45], we experi- vides an effective framework for such a self-training strat- ment with models pre-trained on a 5k-class subset of Ima- egy. With data distillation, Mask R-CNN APkp improve by geNet (in contrast to the standard 1k-class subset). This 5× 1.8 points to 69.1. We observe that Mask R-CNN can ben- increase in pre-training data improves both mask and box 1 efit from extra data, even if that data is unlabeled. AP. As a reference, [40] used ∼250× more images (300M) By using the same test-time augmentation as used for and reported a 2-3 box AP improvement on their baselines. instance segmentation, we further boost APkp to 70.4. 10
11 .Acknowledgements: We would like to acknowledge Ilija [21] J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, Radosavovic for contributions to code release and enhanced A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama, et al. results, and the Caffe2 team for engineering support. Speed/accuracy trade-offs for modern convolutional object detectors. In CVPR, 2017. 2, 3, 4, 6, 7 References [22] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu. Spatial transformer networks. In [1] M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele. 2D NIPS, 2015. 4 human pose estimation: New benchmark and state of the art [23] A. Kirillov, E. Levinkov, B. Andres, B. Savchynskyy, and analysis. In CVPR, 2014. 8 C. Rother. Instancecut: from edges to instances with multi- [2] P. Arbel´aez, J. Pont-Tuset, J. T. Barron, F. Marques, and cut. In CVPR, 2017. 3, 9 J. Malik. Multiscale combinatorial grouping. In CVPR, [24] A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet clas- 2014. 2 sification with deep convolutional neural networks. In NIPS, [3] A. Arnab and P. H. Torr. Pixelwise instance segmentation 2012. 2 with a dynamically instantiated network. In CVPR, 2017. 3, [25] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. 9 Howard, W. Hubbard, and L. D. Jackel. Backpropagation [4] M. Bai and R. Urtasun. Deep watershed transform for in- applied to handwritten zip code recognition. Neural compu- stance segmentation. In CVPR, 2017. 3, 9 tation, 1989. 2 [5] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Inside- [26] Y. Li, H. Qi, J. Dai, X. Ji, and Y. Wei. Fully convolutional outside net: Detecting objects in context with skip pooling instance-aware semantic segmentation. In CVPR, 2017. 2, and recurrent neural networks. In CVPR, 2016. 5 3, 5, 6 [6] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh. Realtime multi- [27] T.-Y. Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and person 2d pose estimation using part affinity fields. In CVPR, S. Belongie. Feature pyramid networks for object detection. 2017. 7, 8 In CVPR, 2017. 2, 4, 5, 7 [7] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, [28] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ra- R. Benenson, U. Franke, S. Roth, and B. Schiele. The manan, P. Doll´ar, and C. L. Zitnick. Microsoft COCO: Com- Cityscapes dataset for semantic urban scene understanding. mon objects in context. In ECCV, 2014. 2, 5 In CVPR, 2016. 9 [29] S. Liu, J. Jia, S. Fidler, and R. Urtasun. SGN: Sequen- [8] J. Dai, K. He, Y. Li, S. Ren, and J. Sun. Instance-sensitive tial grouping networks for instance segmentation. In ICCV, fully convolutional networks. In ECCV, 2016. 2 2017. 3, 9 [9] J. Dai, K. He, and J. Sun. Convolutional feature masking for [30] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional joint object and stuff segmentation. In CVPR, 2015. 2 networks for semantic segmentation. In CVPR, 2015. 1, 3, 6 [31] V. Nair and G. E. Hinton. Rectified linear units improve re- [10] J. Dai, K. He, and J. Sun. Instance-aware semantic segmen- stricted boltzmann machines. In ICML, 2010. 4 tation via multi-task network cascades. In CVPR, 2016. 2, 3, [32] G. Papandreou, T. Zhu, N. Kanazawa, A. Toshev, J. Tomp- 4, 5, 6 son, C. Bregler, and K. Murphy. Towards accurate multi- [11] J. Dai, Y. Li, K. He, and J. Sun. R-FCN: Object detection via person pose estimation in the wild. In CVPR, 2017. 8 region-based fully convolutional networks. In NIPS, 2016. 2 [33] P. O. Pinheiro, R. Collobert, and P. Dollar. Learning to seg- [12] R. Girshick. Fast R-CNN. In ICCV, 2015. 1, 2, 3, 4, 6 ment object candidates. In NIPS, 2015. 2, 3 [13] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich fea- [34] P. O. Pinheiro, T.-Y. Lin, R. Collobert, and P. Doll´ar. Learn- ture hierarchies for accurate object detection and semantic ing to refine object segments. In ECCV, 2016. 2, 3 segmentation. In CVPR, 2014. 2, 3 [35] I. Radosavovic, P. Doll´ar, R. Girshick, G. Gkioxari, and [14] R. Girshick, F. Iandola, T. Darrell, and J. Malik. Deformable K. He. Data distillation: Towards omni-supervised learning. part models are convolutional neural networks. In CVPR, arXiv:1712.04440, 2017. 10 2015. 4 [36] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: To- [15] B. Hariharan, P. Arbel´aez, R. Girshick, and J. Malik. Simul- wards real-time object detection with region proposal net- taneous detection and segmentation. In ECCV. 2014. 2 works. In NIPS, 2015. 1, 2, 3, 4, 7 [16] B. Hariharan, P. Arbel´aez, R. Girshick, and J. Malik. Hyper- [37] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: To- columns for object segmentation and fine-grained localiza- wards real-time object detection with region proposal net- tion. In CVPR, 2015. 2 works. In TPAMI, 2017. 10 [17] Z. Hayder, X. He, and M. Salzmann. Shape-aware instance [38] A. Shrivastava, A. Gupta, and R. Girshick. Training region- segmentation. In CVPR, 2017. 9 based object detectors with online hard example mining. In [18] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling CVPR, 2016. 2, 5 in deep convolutional networks for visual recognition. In [39] A. Shrivastava, R. Sukthankar, J. Malik, and A. Gupta. Be- ECCV. 2014. 1, 2 yond skip connections: Top-down modulation for object de- [19] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning tection. arXiv:1612.06851, 2016. 4, 7 for image recognition. In CVPR, 2016. 2, 4, 7, 10 [40] C. Sun, A. Shrivastava, S. Singh, and A. Gupta. Revisiting [20] J. Hosang, R. Benenson, P. Doll´ar, and B. Schiele. What unreasonable effectiveness of data in deep learning era. In makes for effective detection proposals? PAMI, 2015. 2 ICCV, 2017. 10 11
12 .[41] C. Szegedy, S. Ioffe, and V. Vanhoucke. Inception-v4, inception-resnet and the impact of residual connections on learning. In ICLR Workshop, 2016. 7 [42] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition. IJCV, 2013. 2 [43] X. Wang, R. Girshick, A. Gupta, and K. He. Non-local neural networks. arXiv:1711.07971, 2017. 10 [44] S.-E. Wei, V. Ramakrishna, T. Kanade, and Y. Sheikh. Con- volutional pose machines. In CVPR, 2016. 8 [45] S. Xie, R. Girshick, P. Doll´ar, Z. Tu, and K. He. Aggregated residual transformations for deep neural networks. In CVPR, 2017. 4, 10 12
3秒后跳转登录页面
去登陆

