





















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Improved Training of Wasserstein GANs
Generative Adversarial Networks (GANs) are powerful generative models, but suffer from training instability. The recently proposed Wasserstein GAN (WGAN) makes progress toward stable training of GANs, but sometimes can still generate only poor samples or fail to converge. We find that these problems are often due to the use of weight clipping in WGAN to enforce a Lipschitz constraint on the critic, which can lead to undesired behavior. We propose an alternative to clipping weights: penalize the norm of gradient of the critic with respect to its input. Our proposed method performs better than standard WGAN and enables stable training of a wide variety of GAN architectures with almost no hyperparameter tuning, including 101-layer ResNets and language models with continuous generators. We also achieve high quality generations on CIFAR-10 and LSUN bedrooms
展开查看详情
1 . Improved Training of Wasserstein GANs Ishaan Gulrajani1∗, Faruk Ahmed1 , Martin Arjovsky2 , Vincent Dumoulin1 , Aaron Courville1,3 1 Montreal Institute for Learning Algorithms 2 Courant Institute of Mathematical Sciences CIFAR Fellow arXiv:1704.00028v3 [cs.LG] 25 Dec 2017 3 igul222@gmail.com {faruk.ahmed,vincent.dumoulin,aaron.courville}@umontreal.ca ma4371@nyu.edu Abstract Generative Adversarial Networks (GANs) are powerful generative models, but suffer from training instability. The recently proposed Wasserstein GAN (WGAN) makes progress toward stable training of GANs, but sometimes can still generate only poor samples or fail to converge. We find that these problems are often due to the use of weight clipping in WGAN to enforce a Lipschitz constraint on the critic, which can lead to undesired behavior. We propose an alternative to clipping weights: penalize the norm of gradient of the critic with respect to its input. Our proposed method performs better than standard WGAN and enables stable train- ing of a wide variety of GAN architectures with almost no hyperparameter tuning, including 101-layer ResNets and language models with continuous generators. We also achieve high quality generations on CIFAR-10 and LSUN bedrooms. † 1 Introduction Generative Adversarial Networks (GANs) [9] are a powerful class of generative models that cast generative modeling as a game between two networks: a generator network produces synthetic data given some noise source and a discriminator network discriminates between the generator’s output and true data. GANs can produce very visually appealing samples, but are often hard to train, and much of the recent work on the subject [23, 19, 2, 21] has been devoted to finding ways of stabilizing training. Despite this, consistently stable training of GANs remains an open problem. In particular, [1] provides an analysis of the convergence properties of the value function being optimized by GANs. Their proposed alternative, named Wasserstein GAN (WGAN) [2], leverages the Wasserstein distance to produce a value function which has better theoretical properties than the original. WGAN requires that the discriminator (called the critic in that work) must lie within the space of 1-Lipschitz functions, which the authors enforce through weight clipping. Our contributions are as follows: 1. On toy datasets, we demonstrate how critic weight clipping can lead to undesired behavior. 2. We propose gradient penalty (WGAN-GP), which does not suffer from the same problems. 3. We demonstrate stable training of varied GAN architectures, performance improvements over weight clipping, high-quality image generation, and a character-level GAN language model without any discrete sampling. ∗ Now at Google Brain † Code for our models is available at https://github.com/igul222/improved_wgan_training.
2 .2 Background 2.1 Generative adversarial networks The GAN training strategy is to define a game between two competing networks. The generator network maps a source of noise to the input space. The discriminator network receives either a generated sample or a true data sample and must distinguish between the two. The generator is trained to fool the discriminator. Formally, the game between the generator G and the discriminator D is the minimax objective: min max E [log(D(x))] + E [log(1 − D(x))], ˜ (1) G D x∼Pr ˜ x∼P g where Pr is the data distribution and Pg is the model distribution implicitly defined by x ˜ = G(z), z ∼ p(z) (the input z to the generator is sampled from some simple noise distribution p, such as the uniform distribution or a spherical Gaussian distribution). If the discriminator is trained to optimality before each generator parameter update, then minimiz- ing the value function amounts to minimizing the Jensen-Shannon divergence between Pr and Pg [9], but doing so often leads to vanishing gradients as the discriminator saturates. In practice, [9] advocates that the generator be instead trained to maximize Ex∼P˜ g [log(D(x))], which goes some ˜ way to circumvent this difficulty. However, even this modified loss function can misbehave in the presence of a good discriminator [1]. 2.2 Wasserstein GANs [2] argues that the divergences which GANs typically minimize are potentially not continuous with respect to the generator’s parameters, leading to training difficulty. They propose instead using the Earth-Mover (also called Wasserstein-1) distance W (q, p), which is informally defined as the minimum cost of transporting mass in order to transform the distribution q into the distribution p (where the cost is mass times transport distance). Under mild assumptions, W (q, p) is continuous everywhere and differentiable almost everywhere. The WGAN value function is constructed using the Kantorovich-Rubinstein duality [25] to obtain min max E D(x) − E ˜ D(x)) (2) G D∈D x∼Pr ˜ x∼P g where D is the set of 1-Lipschitz functions and Pg is once again the model distribution implicitly defined by x˜ = G(z), z ∼ p(z). In that case, under an optimal discriminator (called a critic in the paper, since it’s not trained to classify), minimizing the value function with respect to the generator parameters minimizes W (Pr , Pg ). The WGAN value function results in a critic function whose gradient with respect to its input is better behaved than its GAN counterpart, making optimization of the generator easier. Empirically, it was also observed that the WGAN value function appears to correlate with sample quality, which is not the case for GANs [2]. To enforce the Lipschitz constraint on the critic, [2] propose to clip the weights of the critic to lie within a compact space [−c, c]. The set of functions satisfying this constraint is a subset of the k-Lipschitz functions for some k which depends on c and the critic architecture. In the following sections, we demonstrate some of the issues with this approach and propose an alternative. 2.3 Properties of the optimal WGAN critic In order to understand why weight clipping is problematic in a WGAN critic, as well as to motivate our approach, we highlight some properties of the optimal critic in the WGAN framework. We prove these in the Appendix. 2
3 .Proposition 1. Let Pr and Pg be two distributions in X , a compact metric space. Then, there is a 1-Lipschitz function f ∗ which is the optimal solution of max f L ≤1 Ey∼Pr [f (y)] − Ex∼Pg [f (x)]. Let π be the optimal coupling between Pr and Pg , defined as the minimizer of: W (Pr , Pg ) = inf π∈Π(Pr ,Pg ) E(x,y)∼π [ x − y ] where Π(Pr , Pg ) is the set of joint distributions π(x, y) whose marginals are Pr and Pg , respectively. Then, if f ∗ is differentiable‡ , π(x = y) = 0§ , and xt = tx + (1 − t)y with 0 ≤ t ≤ 1, it holds that P(x,y)∼π ∇f ∗ (xt ) = y−xt y−xt = 1. Corollary 1. f has gradient norm 1 almost everywhere under Pr and Pg . ∗ 3 Difficulties with weight constraints We find that weight clipping in WGAN leads to optimization difficulties, and that even when op- timization succeeds the resulting critic can have a pathological value surface. We explain these problems below and demonstrate their effects; however we do not claim that each one always occurs in practice, nor that they are the only such mechanisms. Our experiments use the specific form of weight constraint from [2] (hard clipping of the magnitude of each weight), but we also tried other weight constraints (L2 norm clipping, weight normalization), as well as soft constraints (L1 and L2 weight decay) and found that they exhibit similar problems. To some extent these problems can be mitigated with batch normalization in the critic, which [2] use in all of their experiments. However even with batch normalization, we observe that very deep WGAN critics often fail to converge. Weight clipping Gradient norm (log scale) 8 Gaussians 25 Gaussians Swiss Roll 10 Weight clipping (c = 0.001) Weight clipping (c = 0.01) Weight clipping (c = 0.1) Gradient penalty 0 −0.02 −0.01 0.00 0.01 0.02 Weights Gradient penalty −10 −20 −0.50 −0.25 0.00 0.25 0.50 13 10 7 4 1 Weights Discriminator layer (a) Value surfaces of WGAN critics trained to op- (b) (left) Gradient norms of deep WGAN critics dur- timality on toy datasets using (top) weight clipping ing training on the Swiss Roll dataset either explode and (bottom) gradient penalty. Critics trained with or vanish when using weight clipping, but not when weight clipping fail to capture higher moments of the using a gradient penalty. (right) Weight clipping (top) data distribution. The ‘generator’ is held fixed at the pushes weights towards two values (the extremes of real data plus Gaussian noise. the clipping range), unlike gradient penalty (bottom). Figure 1: Gradient penalty in WGANs does not exhibit undesired behavior like weight clipping. 3.1 Capacity underuse Implementing a k-Lipshitz constraint via weight clipping biases the critic towards much simpler functions. As stated previously in Corollary 1, the optimal WGAN critic has unit gradient norm almost everywhere under Pr and Pg ; under a weight-clipping constraint, we observe that our neural network architectures which try to attain their maximum gradient norm k end up learning extremely simple functions. To demonstrate this, we train WGAN critics with weight clipping to optimality on several toy distri- butions, holding the generator distribution Pg fixed at the real distribution plus unit-variance Gaus- sian noise. We plot value surfaces of the critics in Figure 1a. We omit batch normalization in the ‡ We can actually assume much less, and talk only about directional derivatives on the direction of the line; which we show in the proof always exist. This would imply that in every point where f ∗ is differentiable (and thus we can take gradients in a neural network setting) the statement holds. § This assumption is in order to exclude the case when the matching point of sample x is x itself. It is satisfied in the case that Pr and Pg have supports that intersect in a set of measure 0, such as when they are supported by two low dimensional manifolds that don’t perfectly align [1]. 3
4 .Algorithm 1 WGAN with gradient penalty. We use default values of λ = 10, ncritic = 5, α = 0.0001, β1 = 0, β2 = 0.9. Require: The gradient penalty coefficient λ, the number of critic iterations per generator iteration ncritic , the batch size m, Adam hyperparameters α, β1 , β2 . Require: initial critic parameters w0 , initial generator parameters θ0 . 1: while θ has not converged do 2: for t = 1, ..., ncritic do 3: for i = 1, ..., m do 4: Sample real data x ∼ Pr , latent variable z ∼ p(z), a random number ∼ U [0, 1]. 5: ˜ ← Gθ (z) x 6: ˆ ← x + (1 − )x x ˜ 7: L(i) ← Dw (x) ˜ − Dw (x) + λ( ∇xˆ Dw (x) ˆ 2 − 1)2 8: end for m 9: w ← Adam(∇w m 1 (i) i=1 L , w, α, β1 , β2 ) 10: end for 11: Sample a batch of latent variables {z (i) }m i=1 ∼ p(z). m 12: θ ← Adam(∇θ m 1 i=1 −D w (G θ (z)), θ, α, β1 , β2 ) 13: end while critic. In each case, the critic trained with weight clipping ignores higher moments of the data dis- tribution and instead models very simple approximations to the optimal functions. In contrast, our approach does not suffer from this behavior. 3.2 Exploding and vanishing gradients We observe that the WGAN optimization process is difficult because of interactions between the weight constraint and the cost function, which result in either vanishing or exploding gradients without careful tuning of the clipping threshold c. To demonstrate this, we train WGAN on the Swiss Roll toy dataset, varying the clipping threshold c in [10−1 , 10−2 , 10−3 ], and plot the norm of the gradient of the critic loss with respect to successive layers of activations. Both generator and critic are 12-layer ReLU MLPs without batch normaliza- tion. Figure 1b shows that for each of these values, the gradient either grows or decays exponentially as we move farther back in the network. We find our method results in more stable gradients that neither vanish nor explode, allowing training of more complicated networks. 4 Gradient penalty We now propose an alternative way to enforce the Lipschitz constraint. A differentiable function is 1-Lipschtiz if and only if it has gradients with norm at most 1 everywhere, so we consider di- rectly constraining the gradient norm of the critic’s output with respect to its input. To circumvent tractability issues, we enforce a soft version of the constraint with a penalty on the gradient norm for random samples x ˆ ∼ Pxˆ . Our new objective is L = E [D(x)] ˜ − E [D(x)] + λ E ( ∇xˆ D(x) ˆ 2 − 1)2 . ˜ x∼P x∼Pr ˆ g x∼Pxˆ (3) Original critic loss Our gradient penalty Sampling distribution We implicitly define Pxˆ sampling uniformly along straight lines between pairs of points sampled from the data distribution Pr and the generator distribution Pg . This is motivated by the fact that the optimal critic contains straight lines with gradient norm 1 connecting coupled points from Pr and Pg (see Proposition 1). Given that enforcing the unit gradient norm constraint everywhere is intractable, enforcing it only along these straight lines seems sufficient and experimentally results in good performance. Penalty coefficient All experiments in this paper use λ = 10, which we found to work well across a variety of architectures and datasets ranging from toy tasks to large ImageNet CNNs. 4
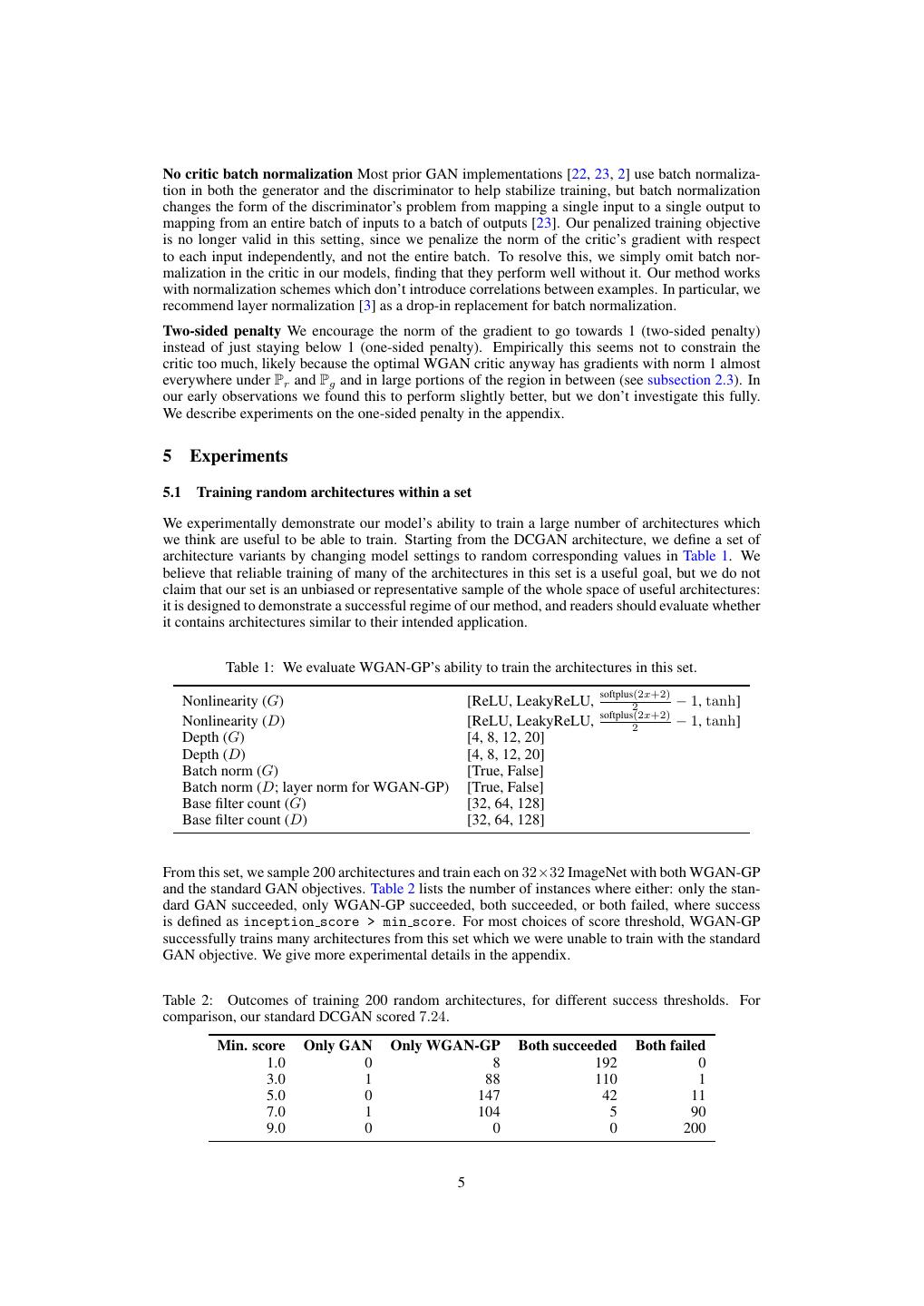
5 .No critic batch normalization Most prior GAN implementations [22, 23, 2] use batch normaliza- tion in both the generator and the discriminator to help stabilize training, but batch normalization changes the form of the discriminator’s problem from mapping a single input to a single output to mapping from an entire batch of inputs to a batch of outputs [23]. Our penalized training objective is no longer valid in this setting, since we penalize the norm of the critic’s gradient with respect to each input independently, and not the entire batch. To resolve this, we simply omit batch nor- malization in the critic in our models, finding that they perform well without it. Our method works with normalization schemes which don’t introduce correlations between examples. In particular, we recommend layer normalization [3] as a drop-in replacement for batch normalization. Two-sided penalty We encourage the norm of the gradient to go towards 1 (two-sided penalty) instead of just staying below 1 (one-sided penalty). Empirically this seems not to constrain the critic too much, likely because the optimal WGAN critic anyway has gradients with norm 1 almost everywhere under Pr and Pg and in large portions of the region in between (see subsection 2.3). In our early observations we found this to perform slightly better, but we don’t investigate this fully. We describe experiments on the one-sided penalty in the appendix. 5 Experiments 5.1 Training random architectures within a set We experimentally demonstrate our model’s ability to train a large number of architectures which we think are useful to be able to train. Starting from the DCGAN architecture, we define a set of architecture variants by changing model settings to random corresponding values in Table 1. We believe that reliable training of many of the architectures in this set is a useful goal, but we do not claim that our set is an unbiased or representative sample of the whole space of useful architectures: it is designed to demonstrate a successful regime of our method, and readers should evaluate whether it contains architectures similar to their intended application. Table 1: We evaluate WGAN-GP’s ability to train the architectures in this set. softplus(2x+2) Nonlinearity (G) [ReLU, LeakyReLU, 2 − 1, tanh] softplus(2x+2) Nonlinearity (D) [ReLU, LeakyReLU, 2 − 1, tanh] Depth (G) [4, 8, 12, 20] Depth (D) [4, 8, 12, 20] Batch norm (G) [True, False] Batch norm (D; layer norm for WGAN-GP) [True, False] Base filter count (G) [32, 64, 128] Base filter count (D) [32, 64, 128] From this set, we sample 200 architectures and train each on 32×32 ImageNet with both WGAN-GP and the standard GAN objectives. Table 2 lists the number of instances where either: only the stan- dard GAN succeeded, only WGAN-GP succeeded, both succeeded, or both failed, where success is defined as inception score > min score. For most choices of score threshold, WGAN-GP successfully trains many architectures from this set which we were unable to train with the standard GAN objective. We give more experimental details in the appendix. Table 2: Outcomes of training 200 random architectures, for different success thresholds. For comparison, our standard DCGAN scored 7.24. Min. score Only GAN Only WGAN-GP Both succeeded Both failed 1.0 0 8 192 0 3.0 1 88 110 1 5.0 0 147 42 11 7.0 1 104 5 90 9.0 0 0 0 200 5
6 . DCGAN LSGAN WGAN (clipping) WGAN-GP (ours) Baseline (G: DCGAN, D: DCGAN) G: No BN and a constant number of filters, D: DCGAN G: 4-layer 512-dim ReLU MLP, D: DCGAN No normalization in either G or D Gated multiplicative nonlinearities everywhere in G and D tanh nonlinearities everywhere in G and D 101-layer ResNet G and D Figure 2: Different GAN architectures trained with different methods. We only succeeded in train- ing every architecture with a shared set of hyperparameters using WGAN-GP. 5.2 Training varied architectures on LSUN bedrooms To demonstrate our model’s ability to train many architectures with its default settings, we train six different GAN architectures on the LSUN bedrooms dataset [31]. In addition to the baseline DC- GAN architecture from [22], we choose six architectures whose successful training we demonstrate: (1) no BN and a constant number of filters in the generator, as in [2], (2) 4-layer 512-dim ReLU MLP generator, as in [2], (3) no normalization in either the discriminator or generator (4) gated multiplicative nonlinearities, as in [24], (5) tanh nonlinearities, and (6) 101-layer ResNet generator and discriminator. Although we do not claim it is impossible without our method, to the best of our knowledge this is the first time very deep residual networks were successfully trained in a GAN setting. For each architecture, we train models using four different GAN methods: WGAN-GP, WGAN with weight clipping, DCGAN [22], and Least-Squares GAN [18]. For each objective, we used the default set of optimizer hyperparameters recommended in that work (except LSGAN, where we searched over learning rates). For WGAN-GP, we replace any batch normalization in the discriminator with layer normalization (see section 4). We train each model for 200K iterations and present samples in Figure 2. We only succeeded in training every architecture with a shared set of hyperparameters using WGAN-GP. For every other training method, some of these architectures were unstable or suffered from mode collapse. 5.3 Improved performance over weight clipping One advantage of our method over weight clipping is improved training speed and sample quality. To demonstrate this, we train WGANs with weight clipping and our gradient penalty on CIFAR- 10 [13] and plot Inception scores [23] over the course of training in Figure 3. For WGAN-GP, 6
7 . Convergence on CIFAR-10 Convergence on CIFAR-10 7 7 6 6 Inception Score Inception Score 5 5 4 4 Weight clipping Weight clipping 3 3 Gradient Penalty (RMSProp) Gradient Penalty (RMSProp) 2 Gradient Penalty (Adam) 2 Gradient Penalty (Adam) DCGAN DCGAN 1 1 0.0 0.5 1.0 1.5 2.0 0 1 2 3 4 ×105 ×105 Generator iterations Wallclock time (in seconds) Figure 3: CIFAR-10 Inception score over generator iterations (left) or wall-clock time (right) for four models: WGAN with weight clipping, WGAN-GP with RMSProp and Adam (to control for the optimizer), and DCGAN. WGAN-GP significantly outperforms weight clipping and performs comparably to DCGAN. we train one model with the same optimizer (RMSProp) and learning rate as WGAN with weight clipping, and another model with Adam and a higher learning rate. Even with the same optimizer, our method converges faster and to a better score than weight clipping. Using Adam further improves performance. We also plot the performance of DCGAN [22] and find that our method converges more slowly (in wall-clock time) than DCGAN, but its score is more stable at convergence. 5.4 Sample quality on CIFAR-10 and LSUN bedrooms For equivalent architectures, our method achieves comparable sample quality to the standard GAN objective. However the increased stability allows us to improve sample quality by exploring a wider range of architectures. To demonstrate this, we find an architecture which establishes a new state of the art Inception score on unsupervised CIFAR-10 (Table 3). When we add label information (using the method in [20]), the same architecture outperforms all other published models except for SGAN. Table 3: Inception scores on CIFAR-10. Our unsupervised model achieves state-of-the-art perfor- mance, and our conditional model outperforms all others except SGAN. Unsupervised Supervised Method Score Method Score ALI [8] (in [27]) 5.34 ± .05 SteinGAN [26] 6.35 BEGAN [4] 5.62 DCGAN (with labels, in [26]) 6.58 DCGAN [22] (in [11]) 6.16 ± .07 Improved GAN [23] 8.09 ± .07 Improved GAN (-L+HA) [23] 6.86 ± .06 AC-GAN [20] 8.25 ± .07 EGAN-Ent-VI [7] 7.07 ± .10 SGAN-no-joint [11] 8.37 ± .08 DFM [27] 7.72 ± .13 WGAN-GP ResNet (ours) 8.42 ± .10 WGAN-GP ResNet (ours) 7.86 ± .07 SGAN [11] 8.59 ± .12 We also train a deep ResNet on 128 × 128 LSUN bedrooms and show samples in Figure 4. We believe these samples are at least competitive with the best reported so far on any resolution for this dataset. 5.5 Modeling discrete data with a continuous generator To demonstrate our method’s ability to model degenerate distributions, we consider the problem of modeling a complex discrete distribution with a GAN whose generator is defined over a continuous space. As an instance of this problem, we train a character-level GAN language model on the Google Billion Word dataset [6]. Our generator is a simple 1D CNN which deterministically transforms a latent vector into a sequence of 32 one-hot character vectors through 1D convolutions. We apply a softmax nonlinearity at the output, but use no sampling step: during training, the softmax output is 7
8 .Figure 4: Samples of 128 × 128 LSUN bedrooms. We believe these samples are at least comparable to the best published results so far. passed directly into the critic (which, likewise, is a simple 1D CNN). When decoding samples, we just take the argmax of each output vector. We present samples from the model in Table 4. Our model makes frequent spelling errors (likely because it has to output each character independently) but nonetheless manages to learn quite a lot about the statistics of language. We were unable to produce comparable results with the standard GAN objective, though we do not claim that doing so is impossible. Table 4: Samples from a WGAN-GP character-level language model trained on sentences from the Billion Word dataset, truncated to 32 characters. The model learns to directly output one-hot character embeddings from a latent vector without any discrete sampling step. We were unable to achieve comparable results with the standard GAN objective and a continuous generator. Busino game camperate spent odea Solice Norkedin pring in since In the bankaway of smarling the ThiS record ( 31. ) UBS ) and Ch SingersMay , who kill that imvic It was not the annuas were plogr Keray Pents of the same Reagun D This will be us , the ect of DAN Manging include a tudancs shat " These leaded as most-worsd p2 a0 His Zuith Dudget , the Denmbern The time I paidOa South Cubry i In during the Uitational questio Dour Fraps higs it was these del Divos from The ’ noth ronkies of This year out howneed allowed lo She like Monday , of macunsuer S Kaulna Seto consficutes to repor The difference in performance between WGAN and other GANs can be explained as follows. Con- sider the simplex ∆n = {p ∈ Rn : pi ≥ 0, i pi = 1}, and the set of vertices on the simplex (or one-hot vectors) Vn = {p ∈ Rn : pi ∈ {0, 1}, i pi = 1} ⊆ ∆n . If we have a vocabulary of size n and we have a distribution Pr over sequences of size T , we have that Pr is a distribution on VnT = Vn × · · · × Vn . Since VnT is a subset of ∆Tn , we can also treat Pr as a distribution on ∆Tn (by assigning zero probability mass to all points not in VnT ). Pr is discrete (or supported on a finite number of elements, namely VnT ) on ∆Tn , but Pg can easily be a continuous distribution over ∆Tn . The KL divergences between two such distributions are infinite, 8
9 . 50 0.8 train train train 40 validation validation validation Negative critic loss Negative critic loss Negative critic loss 10 0.6 30 0.4 20 5 0.2 10 0 0.0 0 0 2 4 0.0 0.5 1.0 1.5 2.0 0.0 0.5 1.0 1.5 2.0 ×104 ×104 ×104 Generator iterations Generator iterations Generator iterations (a) (b) Figure 5: (a) The negative critic loss of our model on LSUN bedrooms converges toward a minimum as the network trains. (b) WGAN training and validation losses on a random 1000-digit subset of MNIST show overfitting when using either our method (left) or weight clipping (right). In particular, with our method, the critic overfits faster than the generator, causing the training loss to increase gradually over time even as the validation loss drops. and so the JS divergence is saturated. Although GANs do not literally minimize these divergences [16], in practice this means a discriminator might quickly learn to reject all samples that don’t lie on VnT (sequences of one-hot vectors) and give meaningless gradients to the generator. However, it is easily seen that the conditions of Theorem 1 and Corollary 1 of [2] are satisfied even on this non-standard learning scenario with X = ∆Tn . This means that W (Pr , Pg ) is still well defined, continuous everywhere and differentiable almost everywhere, and we can optimize it just like in any other continuous variable setting. The way this manifests is that in WGANs, the Lipschitz constraint forces the critic to provide a linear gradient from all ∆Tn towards towards the real points in VnT . Other attempts at language modeling with GANs [32, 14, 30, 5, 15, 10] typically use discrete models and gradient estimators [28, 12, 17]. Our approach is simpler to implement, though whether it scales beyond a toy language model is unclear. 5.6 Meaningful loss curves and detecting overfitting An important benefit of weight-clipped WGANs is that their loss correlates with sample quality and converges toward a minimum. To show that our method preserves this property, we train a WGAN-GP on the LSUN bedrooms dataset [31] and plot the negative of the critic’s loss in Figure 5a. We see that the loss converges as the generator minimizes W (Pr , Pg ). Given enough capacity and too little training data, GANs will overfit. To explore the loss curve’s behavior when the network overfits, we train large unregularized WGANs on a random 1000-image subset of MNIST and plot the negative critic loss on both the training and validation sets in Fig- ure 5b. In both WGAN and WGAN-GP, the two losses diverge, suggesting that the critic overfits and provides an inaccurate estimate of W (Pr , Pg ), at which point all bets are off regarding correla- tion with sample quality. However in WGAN-GP, the training loss gradually increases even while the validation loss drops. [29] also measure overfitting in GANs by estimating the generator’s log-likelihood. Compared to that work, our method detects overfitting in the critic (rather than the generator) and measures overfitting against the same loss that the network minimizes. 6 Conclusion In this work, we demonstrated problems with weight clipping in WGAN and introduced an alterna- tive in the form of a penalty term in the critic loss which does not exhibit the same problems. Using our method, we demonstrated strong modeling performance and stability across a variety of archi- tectures. Now that we have a more stable algorithm for training GANs, we hope our work opens the path for stronger modeling performance on large-scale image datasets and language. Another interesting direction is adapting our penalty term to the standard GAN objective function, where it might stabilize training by encouraging the discriminator to learn smoother decision boundaries. 9
10 .Acknowledgements We would like to thank Mohamed Ishmael Belghazi, L´eon Bottou, Zihang Dai, Stefan Doerr, Ian Goodfellow, Kyle Kastner, Kundan Kumar, Luke Metz, Alec Radford, Colin Raffel, Sai Rajeshwar, Aditya Ramesh, Tom Sercu, Zain Shah and Jake Zhao for insightful comments. References [1] M. Arjovsky and L. Bottou. Towards principled methods for training generative adversarial networks. 2017. [2] M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein gan. arXiv preprint arXiv:1701.07875, 2017. [3] J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016. [4] D. Berthelot, T. Schumm, and L. Metz. Began: Boundary equilibrium generative adversarial networks. arXiv preprint arXiv:1703.10717, 2017. [5] T. Che, Y. Li, R. Zhang, R. D. Hjelm, W. Li, Y. Song, and Y. Bengio. Maximum-likelihood augmented discrete generative adversarial networks. arXiv preprint arXiv:1702.07983, 2017. [6] C. Chelba, T. Mikolov, M. Schuster, Q. Ge, T. Brants, P. Koehn, and T. Robinson. One bil- lion word benchmark for measuring progress in statistical language modeling. arXiv preprint arXiv:1312.3005, 2013. [7] Z. Dai, A. Almahairi, P. Bachman, E. Hovy, and A. Courville. Calibrating energy-based gen- erative adversarial networks. arXiv preprint arXiv:1702.01691, 2017. [8] V. Dumoulin, M. I. D. Belghazi, B. Poole, A. Lamb, M. Arjovsky, O. Mastropietro, and A. Courville. Adversarially learned inference. 2017. [9] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014. [10] R. D. Hjelm, A. P. Jacob, T. Che, K. Cho, and Y. Bengio. Boundary-seeking generative adver- sarial networks. arXiv preprint arXiv:1702.08431, 2017. [11] X. Huang, Y. Li, O. Poursaeed, J. Hopcroft, and S. Belongie. Stacked generative adversarial networks. arXiv preprint arXiv:1612.04357, 2016. [12] E. Jang, S. Gu, and B. Poole. Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144, 2016. [13] A. Krizhevsky. Learning multiple layers of features from tiny images. 2009. [14] J. Li, W. Monroe, T. Shi, A. Ritter, and D. Jurafsky. Adversarial learning for neural dialogue generation. arXiv preprint arXiv:1701.06547, 2017. [15] X. Liang, Z. Hu, H. Zhang, C. Gan, and E. P. Xing. Recurrent topic-transition gan for visual paragraph generation. arXiv preprint arXiv:1703.07022, 2017. [16] S. Liu, O. Bousquet, and K. Chaudhuri. Approximation and convergence properties of gener- ative adversarial learning. arXiv preprint arXiv:1705.08991, 2017. [17] C. J. Maddison, A. Mnih, and Y. W. Teh. The concrete distribution: A continuous relaxation of discrete random variables. arXiv preprint arXiv:1611.00712, 2016. [18] X. Mao, Q. Li, H. Xie, R. Y. Lau, and Z. Wang. Least squares generative adversarial networks. arXiv preprint arXiv:1611.04076, 2016. 10
11 .[19] L. Metz, B. Poole, D. Pfau, and J. Sohl-Dickstein. Unrolled generative adversarial networks. arXiv preprint arXiv:1611.02163, 2016. [20] A. Odena, C. Olah, and J. Shlens. Conditional image synthesis with auxiliary classifier gans. arXiv preprint arXiv:1610.09585, 2016. [21] B. Poole, A. A. Alemi, J. Sohl-Dickstein, and A. Angelova. Improved generator objectives for gans. arXiv preprint arXiv:1612.02780, 2016. [22] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convo- lutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015. [23] T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, and X. Chen. Improved techniques for training gans. In Advances in Neural Information Processing Systems, pages 2226–2234, 2016. [24] A. van den Oord, N. Kalchbrenner, L. Espeholt, O. Vinyals, A. Graves, et al. Conditional image generation with pixelcnn decoders. In Advances in Neural Information Processing Systems, pages 4790–4798, 2016. [25] C. Villani. Optimal transport: old and new, volume 338. Springer Science & Business Media, 2008. [26] D. Wang and Q. Liu. Learning to draw samples: With application to amortized mle for gener- ative adversarial learning. arXiv preprint arXiv:1611.01722, 2016. [27] D. Warde-Farley and Y. Bengio. Improving generative adversarial networks with denoising feature matching. 2017. [28] R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning. Machine learning, 8(3-4):229–256, 1992. [29] Y. Wu, Y. Burda, R. Salakhutdinov, and R. Grosse. On the quantitative analysis of decoder- based generative models. arXiv preprint arXiv:1611.04273, 2016. [30] Z. Yang, W. Chen, F. Wang, and B. Xu. Improving neural machine translation with conditional sequence generative adversarial nets. arXiv preprint arXiv:1703.04887, 2017. [31] F. Yu, A. Seff, Y. Zhang, S. Song, T. Funkhouser, and J. Xiao. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365, 2015. [32] L. Yu, W. Zhang, J. Wang, and Y. Yu. Seqgan: sequence generative adversarial nets with policy gradient. arXiv preprint arXiv:1609.05473, 2016. 11
12 .A Proof of Proposition 1 Proof. Since X is a compact space, by Theorem 5.10 of [25], part (iii), we know that there is an optimal f ∗ . By Theorem 5.10 of [25], part (ii) we know that if π is an optimal coupling, P(x,y)∼π [f ∗ (y) − f ∗ (x) = y − x ] = 1 Let (x, y) be such that f ∗ (y)−f ∗ (x) = y −x . We can safely assume that x = y as well, since this happens under π with probability 1. Let ψ(t) = f ∗ (xt ) − f ∗ (x). We claim that ψ(t) = xt − x = t y−x . Let t, t ∈ [0, 1], then |ψ(t) − ψ(t )| = f ∗ (xt ) − f ∗ (xt ) ≤ xt − xt = |t − t | x − y Therefore, ψ is x − y -Lipschitz. This in turn implies ψ(1) − ψ(0) = ψ(1) − ψ(t) + ψ(t) − ψ(0) ≤ (1 − t) x − y + ψ(t) − ψ(0) ≤ (1 − t) x − y + t x − y = x−y However, |ψ(1) − ψ(0)| = |f ∗ (y) − f ∗ (x)| = y − x so the inequalities have to actually be equalities. In particular, ψ(t) − ψ(0) = t x − y , and ψ(0) = f ∗ (x) − f ∗ (x) = 0. Therefore, ψ(t) = t x − y and we finish our claim. Let y − xt v= y − xt y − ((1 − t)x − ty) = y − ((1 − t)x − ty) (1 − t)(y − x) = (1 − t) y − x y−x = y−x Now we know that f ∗ (xt ) − f ∗ (x) = ψ(t) = t x − y , so f ∗ (xt ) = f ∗ (x) + t x − y . Then, we have the partial derivative ∂ ∗ f ∗ (xt + hv) − f ∗ (xt ) f (xt ) = lim ∂v h→0 h h f ∗ x + t(y − x) + y−x (y − x) − f ∗ (xt ) = lim h→0 h ∗ ∗ f xt+ h − f (xt ) y−x = lim h→0 h h f ∗ (x) + t + y−x x − y − (f ∗ (x) + t x − y ) = lim h→0 h h = lim h→0 h =1 12
13 .If f ∗ is differentiable at xt , we know that ∇f ∗ (xt ) ≤ 1 since it is a 1-Lipschitz function. There- fore, by simple Pythagoras and using that v is a unit vector 1 ≤ ∇f ∗ (x) 2 = v, ∇f ∗ (xt ) 2 + ∇f ∗ (xt ) − v, ∇f ∗ (xt ) v 2 ∂ ∂ = | f ∗ (xt )|2 + ∇f ∗ (xt ) − v f ∗ (xt ) 2 ∂v ∂v = 1 + ∇f ∗ (xt ) − v 2 ≤1 The fact that both extremes of the inequality coincide means that it was all an equality and 1 = 1+ ∇f ∗ (xt )−v 2 so ∇f ∗ (xt )−v = 0 and therefore ∇f ∗ (xt ) = v. This shows that ∇f ∗ (xt ) = y−xt y−xt . To conclude, we showed that if (x, y) have the property that f ∗ (y) − f ∗ (x) = y − x , then ∇f ∗ (xt ) = y−x y−xt . Since this happens with probability 1 under π, we know that t y − xt P(x,y)∼π ∇f ∗ (xt ) = =1 y − xt and we finished the proof. B More details for training random architectures within a set All models were trained on 32 × 32 ImageNet for 100K generator iterations using Adam with hyperparameters as recommended in [22] (α = 0.0002, β1 = 0.5, β2 = 0.999) for the standard GAN objective and our recommended settings (α = 0.0001, β1 = 0, β2 = 0.9) for WGAN-GP. In the discriminator, if we use batch normalization (or layer normalization) we also apply a small weight decay (λ = 10−3 ), finding that this helps both algorithms slightly. Table 5: Outcomes of training 200 random architectures, for different success thresholds. For comparison, our standard DCGAN achieved a score of 7.24. Min. score Only GAN Only WGAN-GP Both succeeded Both failed 1.0 0 8 192 0 1.5 0 50 150 0 2.0 0 60 140 0 2.5 0 74 125 1 3.0 1 88 110 1 3.5 0 111 86 3 4.0 1 126 67 6 4.5 0 136 55 9 5.0 0 147 42 11 5.5 0 148 32 20 6.0 0 145 21 34 6.5 1 131 11 57 7.0 1 104 5 90 7.5 2 67 3 128 8.0 1 34 0 165 8.5 0 6 0 194 9.0 0 0 0 200 C Experiments with one-sided penalty We considered a one-sided penalty of the form λ Ex∼Pˆ ˆ x max(0, ∇xˆ D(x) ˆ 2 − 1)2 which would penalize gradients larger than 1 but not gradients smaller than 1, but we observe that the two-sided 13
14 .version seems to perform slightly better. We sample 174 architectures from the set specified in Table 1 and train each architecture with the one-sided and two-sided penalty terms. The two-sided penalty achieved a higher Inception score in 100 of the trials, compared to 77 for the one-sided penalty. We note that this result is not statistically significant at p < 0.05 and further is with respect to only one (somewhat arbitrary) metric and distribution of architectures, and it is entirely possible (likely, in fact) that there are settings where the one-sided penalty performs better, but we leave a thorough comparison for future work. Other training details are the same as in Appendix B. D Nonsmooth activation functions The gradient of our objective with respect to the discriminator’s parameters contains terms which in- volve second derivatives of the network’s activation functions. In the case of networks with ReLU or other common nonsmooth activation functions, this means the gradient is undefined at some points (albeit a measure zero set) and the gradient penalty objective might not be continuous with respect to the parameters. Gradient descent is not guaranteed to succeed in this setting, but empirically this seems not to be a problem for some common activation functions: in our random architecture and LSUN architecture experiments we find that we are able to train networks with piecewise linear ac- tivation functions (ReLU, leaky ReLU) as well as smooth activation functions. We do note that we were unable to train networks with ELU activations, whose derivative is continuous but not smooth. Replacing ELU with a very similar nonlinearity which is smooth ( softplus(2x+2) 2 − 1) fixed the issue. E Hyperparameters used for LSUN robustness experiments For each method we used the hyperparameters recommended in that method’s paper. For LSGAN, we additionally searched over learning rate (because the paper did not make a specific recommen- dation). • WGAN with gradient penalty: Adam (α = .0001, β1 = .5, β2 = .9) • WGAN with weight clipping: RMSProp (α = .00005) • DCGAN: Adam (α = .0002, β1 = .5) • LSGAN: RMSProp (α = .0001) [chosen by search over α = .001, .0002, .0001] F CIFAR-10 ResNet architecture The generator and critic are residual networks; we use pre-activation residual blocks with two 3 × 3 convolutional layers each and ReLU nonlinearity. Some residual blocks perform downsampling (in the critic) using mean pooling after the second convolution, or nearest-neighbor upsampling (in the generator) before the second convolution. We use batch normalization in the generator but not the critic. We optimize using Adam with learning rate 2 × 10−4 , decayed linearly to 0 over 100K generator iterations, and batch size 64. For further architectural details, please refer to our open-source implementation. Generator G(z) Kernel size Resample Output shape z - - 128 Linear - - 128 × 4 × 4 Residual block [ 3×3 ] × 2 Up 128 × 8 × 8 Residual block [ 3×3 ] × 2 Up 128 × 16 × 16 Residual block [ 3×3 ] × 2 Up 128 × 32 × 32 Conv, tanh 3×3 - 3 × 32 × 32 14
15 . Critic D(x) Kernel size Resample Output shape Residual block [ 3×3 ] × 2 Down 128 × 16 × 16 Residual block [ 3×3 ] × 2 Down 128 × 8 × 8 Residual block [ 3×3 ] × 2 - 128 × 8 × 8 Residual block [ 3×3 ] × 2 - 128 × 8 × 8 ReLU, mean pool - - 128 Linear - - 1 G CIFAR-10 ResNet samples Figure 6: (left) CIFAR-10 samples generated by our unsupervised model. (right) Conditional CIFAR-10 samples, from adding AC-GAN conditioning to our unconditional model. Samples from the same class are displayed in the same column. 15
16 .H More LSUN samples Method: DCGAN Method: DCGAN G: DCGAN, D: DCGAN G: No BN and const. filter count Method: DCGAN Method: DCGAN G: 4-layer 512-dim ReLU MLP No normalization in either G or D Method: DCGAN Method: DCGAN Gated multiplicative nonlinearities tanh nonlinearities 16
17 . Method: DCGAN Method: LSGAN 101-layer ResNet G and D G: DCGAN, D: DCGAN Method: LSGAN Method: LSGAN G: No BN and const. filter count G: 4-layer 512-dim ReLU MLP Method: LSGAN Method: LSGAN No normalization in either G or D Gated multiplicative nonlinearities 17
18 . Method: LSGAN Method: LSGAN tanh nonlinearities 101-layer ResNet G and D Method: WGAN with clipping Method: WGAN with clipping G: DCGAN, D: DCGAN G: No BN and const. filter count Method: WGAN with clipping Method: WGAN with clipping G: 4-layer 512-dim ReLU MLP No normalization in either G or D 18
19 . Method: WGAN with clipping Method: WGAN with clipping Gated multiplicative nonlinearities tanh nonlinearities Method: WGAN with clipping Method: WGAN-GP (ours) 101-layer ResNet G and D G: DCGAN, D: DCGAN Method: WGAN-GP (ours) Method: WGAN-GP (ours) G: No BN and const. filter count G: 4-layer 512-dim ReLU MLP 19
20 . Method: WGAN-GP (ours) Method: WGAN-GP (ours) No normalization in either G or D Gated multiplicative nonlinearities Method: WGAN-GP (ours) Method: WGAN-GP (ours) tanh nonlinearities 101-layer ResNet G and D 20
3秒后跳转登录页面
去登陆

