














- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Auto-Encoding Variational Bayes
How can we perform efficient inference and learning in directed probabilistic models, in the presence of continuous latent variables with intractable posterior distributions, and large datasets? We introduce a stochastic variational inference and learning algorithm that scales to large datasets and, under some mild differentiability conditions, even works in the intractable case. Our contributions is two-fold. First, we show that a reparameterization of the variational lower bound yields a lower bound estimator that can be straightforwardly optimized using standard stochastic gradient methods. Second, we show that for i.i.d. datasets with continuous latent variables per datapoint, posterior inference can be made especially efficient by fitting an approximate inference model (also called a recognition model) to the intractable posterior using the proposed lower bound estimator.Theoretical advantages are reflected in experimental results.
展开查看详情
1 . Auto-Encoding Variational Bayes Diederik P. Kingma Max Welling Machine Learning Group Machine Learning Group Universiteit van Amsterdam Universiteit van Amsterdam dpkingma@gmail.com welling.max@gmail.com arXiv:1312.6114v10 [stat.ML] 1 May 2014 Abstract How can we perform efficient inference and learning in directed probabilistic models, in the presence of continuous latent variables with intractable posterior distributions, and large datasets? We introduce a stochastic variational inference and learning algorithm that scales to large datasets and, under some mild differ- entiability conditions, even works in the intractable case. Our contributions is two-fold. First, we show that a reparameterization of the variational lower bound yields a lower bound estimator that can be straightforwardly optimized using stan- dard stochastic gradient methods. Second, we show that for i.i.d. datasets with continuous latent variables per datapoint, posterior inference can be made espe- cially efficient by fitting an approximate inference model (also called a recogni- tion model) to the intractable posterior using the proposed lower bound estimator. Theoretical advantages are reflected in experimental results. 1 Introduction How can we perform efficient approximate inference and learning with directed probabilistic models whose continuous latent variables and/or parameters have intractable posterior distributions? The variational Bayesian (VB) approach involves the optimization of an approximation to the intractable posterior. Unfortunately, the common mean-field approach requires analytical solutions of expecta- tions w.r.t. the approximate posterior, which are also intractable in the general case. We show how a reparameterization of the variational lower bound yields a simple differentiable unbiased estimator of the lower bound; this SGVB (Stochastic Gradient Variational Bayes) estimator can be used for ef- ficient approximate posterior inference in almost any model with continuous latent variables and/or parameters, and is straightforward to optimize using standard stochastic gradient ascent techniques. For the case of an i.i.d. dataset and continuous latent variables per datapoint, we propose the Auto- Encoding VB (AEVB) algorithm. In the AEVB algorithm we make inference and learning especially efficient by using the SGVB estimator to optimize a recognition model that allows us to perform very efficient approximate posterior inference using simple ancestral sampling, which in turn allows us to efficiently learn the model parameters, without the need of expensive iterative inference schemes (such as MCMC) per datapoint. The learned approximate posterior inference model can also be used for a host of tasks such as recognition, denoising, representation and visualization purposes. When a neural network is used for the recognition model, we arrive at the variational auto-encoder. 2 Method The strategy in this section can be used to derive a lower bound estimator (a stochastic objective function) for a variety of directed graphical models with continuous latent variables. We will restrict ourselves here to the common case where we have an i.i.d. dataset with latent variables per datapoint, and where we like to perform maximum likelihood (ML) or maximum a posteriori (MAP) inference on the (global) parameters, and variational inference on the latent variables. It is, for example, 1
2 . φ z θ x N Figure 1: The type of directed graphical model under consideration. Solid lines denote the generative model pθ (z)pθ (x|z), dashed lines denote the variational approximation qφ (z|x) to the intractable posterior pθ (z|x). The variational parameters φ are learned jointly with the generative model pa- rameters θ. straightforward to extend this scenario to the case where we also perform variational inference on the global parameters; that algorithm is put in the appendix, but experiments with that case are left to future work. Note that our method can be applied to online, non-stationary settings, e.g. streaming data, but here we assume a fixed dataset for simplicity. 2.1 Problem scenario Let us consider some dataset X = {x(i) }N i=1 consisting of N i.i.d. samples of some continuous or discrete variable x. We assume that the data are generated by some random process, involving an unobserved continuous random variable z. The process consists of two steps: (1) a value z(i) is generated from some prior distribution pθ∗ (z); (2) a value x(i) is generated from some condi- tional distribution pθ∗ (x|z). We assume that the prior pθ∗ (z) and likelihood pθ∗ (x|z) come from parametric families of distributions pθ (z) and pθ (x|z), and that their PDFs are differentiable almost everywhere w.r.t. both θ and z. Unfortunately, a lot of this process is hidden from our view: the true parameters θ ∗ as well as the values of the latent variables z(i) are unknown to us. Very importantly, we do not make the common simplifying assumptions about the marginal or pos- terior probabilities. Conversely, we are here interested in a general algorithm that even works effi- ciently in the case of: 1. Intractability: the case where the integral of the marginal likelihood pθ (x) = pθ (z)pθ (x|z) dz is intractable (so we cannot evaluate or differentiate the marginal like- lihood), where the true posterior density pθ (z|x) = pθ (x|z)pθ (z)/pθ (x) is intractable (so the EM algorithm cannot be used), and where the required integrals for any reason- able mean-field VB algorithm are also intractable. These intractabilities are quite common and appear in cases of moderately complicated likelihood functions pθ (x|z), e.g. a neural network with a nonlinear hidden layer. 2. A large dataset: we have so much data that batch optimization is too costly; we would like to make parameter updates using small minibatches or even single datapoints. Sampling- based solutions, e.g. Monte Carlo EM, would in general be too slow, since it involves a typically expensive sampling loop per datapoint. We are interested in, and propose a solution to, three related problems in the above scenario: 1. Efficient approximate ML or MAP estimation for the parameters θ. The parameters can be of interest themselves, e.g. if we are analyzing some natural process. They also allow us to mimic the hidden random process and generate artificial data that resembles the real data. 2. Efficient approximate posterior inference of the latent variable z given an observed value x for a choice of parameters θ. This is useful for coding or data representation tasks. 3. Efficient approximate marginal inference of the variable x. This allows us to perform all kinds of inference tasks where a prior over x is required. Common applications in computer vision include image denoising, inpainting and super-resolution. 2
3 .For the purpose of solving the above problems, let us introduce a recognition model qφ (z|x): an approximation to the intractable true posterior pθ (z|x). Note that in contrast with the approximate posterior in mean-field variational inference, it is not necessarily factorial and its parameters φ are not computed from some closed-form expectation. Instead, we’ll introduce a method for learning the recognition model parameters φ jointly with the generative model parameters θ. From a coding theory perspective, the unobserved variables z have an interpretation as a latent representation or code. In this paper we will therefore also refer to the recognition model qφ (z|x) as a probabilistic encoder, since given a datapoint x it produces a distribution (e.g. a Gaussian) over the possible values of the code z from which the datapoint x could have been generated. In a similar vein we will refer to pθ (x|z) as a probabilistic decoder, since given a code z it produces a distribution over the possible corresponding values of x. 2.2 The variational bound The marginal likelihood is composed of a sum over the marginal likelihoods of individual datapoints N log pθ (x(1) , · · · , x(N ) ) = i=1 log pθ (x(i) ), which can each be rewritten as: log pθ (x(i) ) = DKL (qφ (z|x(i) )||pθ (z|x(i) )) + L(θ, φ; x(i) ) (1) The first RHS term is the KL divergence of the approximate from the true posterior. Since this KL-divergence is non-negative, the second RHS term L(θ, φ; x(i) ) is called the (variational) lower bound on the marginal likelihood of datapoint i, and can be written as: log pθ (x(i) ) ≥ L(θ, φ; x(i) ) = Eqφ (z|x) [− log qφ (z|x) + log pθ (x, z)] (2) which can also be written as: L(θ, φ; x(i) ) = −DKL (qφ (z|x(i) )||pθ (z)) + Eqφ (z|x(i) ) log pθ (x(i) |z) (3) We want to differentiate and optimize the lower bound L(θ, φ; x(i) ) w.r.t. both the variational parameters φ and generative parameters θ. However, the gradient of the lower bound w.r.t. φ is a bit problematic. The usual (na¨ıve) Monte Carlo gradient estimator for this type of problem 1 L (l) is: ∇φ Eqφ (z) [f (z)] = Eqφ (z) f (z)∇qφ (z) log qφ (z) L l=1 f (z)∇qφ (z(l) ) log qφ (z ) where (l) (i) z ∼ qφ (z|x ). This gradient estimator exhibits exhibits very high variance (see e.g. [BJP12]) and is impractical for our purposes. 2.3 The SGVB estimator and AEVB algorithm In this section we introduce a practical estimator of the lower bound and its derivatives w.r.t. the parameters. We assume an approximate posterior in the form qφ (z|x), but please note that the technique can be applied to the case qφ (z), i.e. where we do not condition on x, as well. The fully variational Bayesian method for inferring a posterior over the parameters is given in the appendix. Under certain mild conditions outlined in section 2.4 for a chosen approximate posterior qφ (z|x) we can reparameterize the random variable z ∼ qφ (z|x) using a differentiable transformation gφ ( , x) of an (auxiliary) noise variable : z = gφ ( , x) with ∼ p( ) (4) See section 2.4 for general strategies for chosing such an approriate distribution p( ) and function gφ ( , x). We can now form Monte Carlo estimates of expectations of some function f (z) w.r.t. qφ (z|x) as follows: L 1 Eqφ (z|x(i) ) [f (z)] = Ep( ) f (gφ ( , x(i) )) f (gφ ( (l) , x(i) )) where (l) ∼ p( ) (5) L l=1 We apply this technique to the variational lower bound (eq. (2)), yielding our generic Stochastic Gradient Variational Bayes (SGVB) estimator LA (θ, φ; x(i) ) L(θ, φ; x(i) ): L A 1 (i) L (θ, φ; x ) = log pθ (x(i) , z(i,l) ) − log qφ (z(i,l) |x(i) ) L l=1 where z(i,l) = gφ ( (i,l) , x(i) ) and (l) ∼ p( ) (6) 3
4 .Algorithm 1 Minibatch version of the Auto-Encoding VB (AEVB) algorithm. Either of the two SGVB estimators in section 2.3 can be used. We use settings M = 100 and L = 1 in experiments. θ, φ ← Initialize parameters repeat XM ← Random minibatch of M datapoints (drawn from full dataset) ← Random samples from noise distribution p( ) g ← ∇θ,φ LM (θ, φ; XM , ) (Gradients of minibatch estimator (8)) θ, φ ← Update parameters using gradients g (e.g. SGD or Adagrad [DHS10]) until convergence of parameters (θ, φ) return θ, φ Often, the KL-divergence DKL (qφ (z|x(i) )||pθ (z)) of eq. (3) can be integrated analytically (see appendix B), such that only the expected reconstruction error Eqφ (z|x(i) ) log pθ (x(i) |z) requires estimation by sampling. The KL-divergence term can then be interpreted as regularizing φ, encour- aging the approximate posterior to be close to the prior pθ (z). This yields a second version of the SGVB estimator LB (θ, φ; x(i) ) L(θ, φ; x(i) ), corresponding to eq. (3), which typically has less variance than the generic estimator: L 1 LB (θ, φ; x(i) ) = −DKL (qφ (z|x(i) )||pθ (z)) + (log pθ (x(i) |z(i,l) )) L l=1 (i,l) (i,l) (i) (l) where z = gφ ( , x ) and ∼ p( ) (7) Given multiple datapoints from a dataset X with N datapoints, we can construct an estimator of the marginal likelihood lower bound of the full dataset, based on minibatches: M N L(θ, φ; X) LM (θ, φ; XM ) = L(θ, φ; x(i) ) (8) M i=1 where the minibatch XM = {x(i) }M i=1 is a randomly drawn sample of M datapoints from the full dataset X with N datapoints. In our experiments we found that the number of samples L per datapoint can be set to 1 as long as the minibatch size M was large enough, e.g. M = 100. Derivatives ∇θ,φ L(θ; XM ) can be taken, and the resulting gradients can be used in conjunction with stochastic optimization methods such as SGD or Adagrad [DHS10]. See algorithm 1 for a basic approach to compute the stochastic gradients. A connection with auto-encoders becomes clear when looking at the objective function given at eq. (7). The first term is (the KL divergence of the approximate posterior from the prior) acts as a regularizer, while the second term is a an expected negative reconstruction error. The function gφ (.) is chosen such that it maps a datapoint x(i) and a random noise vector (l) to a sample from the approximate posterior for that datapoint: z(i,l) = gφ ( (l) , x(i) ) where z(i,l) ∼ qφ (z|x(i) ). Subse- quently, the sample z(i,l) is then input to function log pθ (x(i) |z(i,l) ), which equals the probability density (or mass) of datapoint x(i) under the generative model, given z(i,l) . This term is a negative reconstruction error in auto-encoder parlance. 2.4 The reparameterization trick In order to solve our problem we invoked an alternative method for generating samples from qφ (z|x). The essential parameterization trick is quite simple. Let z be a continuous random vari- able, and z ∼ qφ (z|x) be some conditional distribution. It is then often possible to express the random variable z as a deterministic variable z = gφ ( , x), where is an auxiliary variable with independent marginal p( ), and gφ (.) is some vector-valued function parameterized by φ. This reparameterization is useful for our case since it can be used to rewrite an expectation w.r.t qφ (z|x) such that the Monte Carlo estimate of the expectation is differentiable w.r.t. φ. A proof is as follows. Given the deterministic mapping z = gφ ( , x) we know that qφ (z|x) i dzi = p( ) i d i . Therefore1 , qφ (z|x)f (z) dz = p( )f (z) d = p( )f (gφ ( , x)) d . It follows 1 Note that for infinitesimals we use the notational convention dz = i dzi 4
5 . 1 (l) L that a differentiable estimator can be constructed: qφ (z|x)f (z) dz L l=1 f (gφ (x, )) (l) where ∼ p( ). In section 2.3 we applied this trick to obtain a differentiable estimator of the variational lower bound. Take, for example, the univariate Gaussian case: let z ∼ p(z|x) = N (µ, σ 2 ). In this case, a valid reparameterization is z = µ + σ , where is an auxiliary noise variable ∼ N (0, 1). Therefore, L EN (z;µ,σ2 ) [f (z)] = EN ( ;0,1) [f (µ + σ )] L1 l=1 f (µ + σ (l) ) where (l) ∼ N (0, 1). For which qφ (z|x) can we choose such a differentiable transformation gφ (.) and auxiliary variable ∼ p( )? Three basic approaches are: 1. Tractable inverse CDF. In this case, let ∼ U(0, I), and let gφ ( , x) be the inverse CDF of qφ (z|x). Examples: Exponential, Cauchy, Logistic, Rayleigh, Pareto, Weibull, Reciprocal, Gompertz, Gumbel and Erlang distributions. 2. Analogous to the Gaussian example, for any ”location-scale” family of distributions we can choose the standard distribution (with location = 0, scale = 1) as the auxiliary variable , and let g(.) = location + scale · . Examples: Laplace, Elliptical, Student’s t, Logistic, Uniform, Triangular and Gaussian distributions. 3. Composition: It is often possible to express random variables as different transformations of auxiliary variables. Examples: Log-Normal (exponentiation of normally distributed variable), Gamma (a sum over exponentially distributed variables), Dirichlet (weighted sum of Gamma variates), Beta, Chi-Squared, and F distributions. When all three approaches fail, good approximations to the inverse CDF exist requiring computa- tions with time complexity comparable to the PDF (see e.g. [Dev86] for some methods). 3 Example: Variational Auto-Encoder In this section we’ll give an example where we use a neural network for the probabilistic encoder qφ (z|x) (the approximation to the posterior of the generative model pθ (x, z)) and where the param- eters φ and θ are optimized jointly with the AEVB algorithm. Let the prior over the latent variables be the centered isotropic multivariate Gaussian pθ (z) = N (z; 0, I). Note that in this case, the prior lacks parameters. We let pθ (x|z) be a multivariate Gaussian (in case of real-valued data) or Bernoulli (in case of binary data) whose distribution pa- rameters are computed from z with a MLP (a fully-connected neural network with a single hidden layer, see appendix C). Note the true posterior pθ (z|x) is in this case intractable. While there is much freedom in the form qφ (z|x), we’ll assume the true (but intractable) posterior takes on a ap- proximate Gaussian form with an approximately diagonal covariance. In this case, we can let the variational approximate posterior be a multivariate Gaussian with a diagonal covariance structure2 : log qφ (z|x(i) ) = log N (z; µ(i) , σ 2(i) I) (9) (i) (i) where the mean and s.d. of the approximate posterior, µ and σ , are outputs of the encoding MLP, i.e. nonlinear functions of datapoint x(i) and the variational parameters φ (see appendix C). As explained in section 2.4, we sample from the posterior z(i,l) ∼ qφ (z|x(i) ) using z(i,l) = gφ (x(i) , (l) ) = µ(i) + σ (i) (l) where (l) ∼ N (0, I). With we signify an element-wise product. In this model both pθ (z) (the prior) and qφ (z|x) are Gaussian; in this case, we can use the estimator of eq. (7) where the KL divergence can be computed and differentiated without estimation (see appendix B). The resulting estimator for this model and datapoint x(i) is: J L (i) 1 (i) (i) (i) 1 L(θ, φ; x ) 1+ log((σj )2 ) − (µj )2 − (σj )2 + log pθ (x(i) |z(i,l) ) 2 j=1 L l=1 where z(i,l) = µ(i) + σ (i) (l) and (l) ∼ N (0, I) (10) As explained above and in appendix C, the decoding term log pθ (x(i) |z(i,l) ) is a Bernoulli or Gaus- sian MLP, depending on the type of data we are modelling. 2 Note that this is just a (simplifying) choice, and not a limitation of our method. 5
6 .4 Related work The wake-sleep algorithm [HDFN95] is, to the best of our knowledge, the only other on-line learn- ing method in the literature that is applicable to the same general class of continuous latent variable models. Like our method, the wake-sleep algorithm employs a recognition model that approximates the true posterior. A drawback of the wake-sleep algorithm is that it requires a concurrent optimiza- tion of two objective functions, which together do not correspond to optimization of (a bound of) the marginal likelihood. An advantage of wake-sleep is that it also applies to models with discrete latent variables. Wake-Sleep has the same computational complexity as AEVB per datapoint. Stochastic variational inference [HBWP13] has recently received increasing interest. Recently, [BJP12] introduced a control variate schemes to reduce the high variance of the na¨ıve gradient estimator discussed in section 2.1, and applied to exponential family approximations of the poste- rior. In [RGB13] some general methods, i.e. a control variate scheme, were introduced for reducing the variance of the original gradient estimator. In [SK13], a similar reparameterization as in this paper was used in an efficient version of a stochastic variational inference algorithm for learning the natural parameters of exponential-family approximating distributions. The AEVB algorithm exposes a connection between directed probabilistic models (trained with a variational objective) and auto-encoders. A connection between linear auto-encoders and a certain class of generative linear-Gaussian models has long been known. In [Row98] it was shown that PCA corresponds to the maximum-likelihood (ML) solution of a special case of the linear-Gaussian model with a prior p(z) = N (0, I) and a conditional distribution p(x|z) = N (x; Wz, I), specifically the case with infinitesimally small . In relevant recent work on autoencoders [VLL+ 10] it was shown that the training criterion of un- regularized autoencoders corresponds to maximization of a lower bound (see the infomax princi- ple [Lin89]) of the mutual information between input X and latent representation Z. Maximiz- ing (w.r.t. parameters) of the mutual information is equivalent to maximizing the conditional en- tropy, which is lower bounded by the expected loglikelihood of the data under the autoencoding model [VLL+ 10], i.e. the negative reconstrution error. However, it is well known that this recon- struction criterion is in itself not sufficient for learning useful representations [BCV13]. Regular- ization techniques have been proposed to make autoencoders learn useful representations, such as denoising, contractive and sparse autoencoder variants [BCV13]. The SGVB objective contains a regularization term dictated by the variational bound (e.g. eq. (10)), lacking the usual nuisance regu- larization hyperparameter required to learn useful representations. Related are also encoder-decoder architectures such as the predictive sparse decomposition (PSD) [KRL08], from which we drew some inspiration. Also relevant are the recently introduced Generative Stochastic Networks [BTL13] where noisy auto-encoders learn the transition operator of a Markov chain that samples from the data distribution. In [SL10] a recognition model was employed for efficient learning with Deep Boltz- mann Machines. These methods are targeted at either unnormalized models (i.e. undirected models like Boltzmann machines) or limited to sparse coding models, in contrast to our proposed algorithm for learning a general class of directed probabilistic models. The recently proposed DARN method [GMW13], also learns a directed probabilistic model using an auto-encoding structure, however their method applies to binary latent variables. Even more recently, [RMW14] also make the connection between auto-encoders, directed proabilistic models and stochastic variational inference using the reparameterization trick we describe in this paper. Their work was developed independently of ours and provides an additional perspective on AEVB. 5 Experiments We trained generative models of images from the MNIST and Frey Face datasets3 and compared learning algorithms in terms of the variational lower bound, and the estimated marginal likelihood. The generative model (encoder) and variational approximation (decoder) from section 3 were used, where the described encoder and decoder have an equal number of hidden units. Since the Frey Face data are continuous, we used a decoder with Gaussian outputs, identical to the encoder, except that the means were constrained to the interval (0, 1) using a sigmoidal activation function at the 3 Available at http://www.cs.nyu.edu/˜roweis/data.html 6
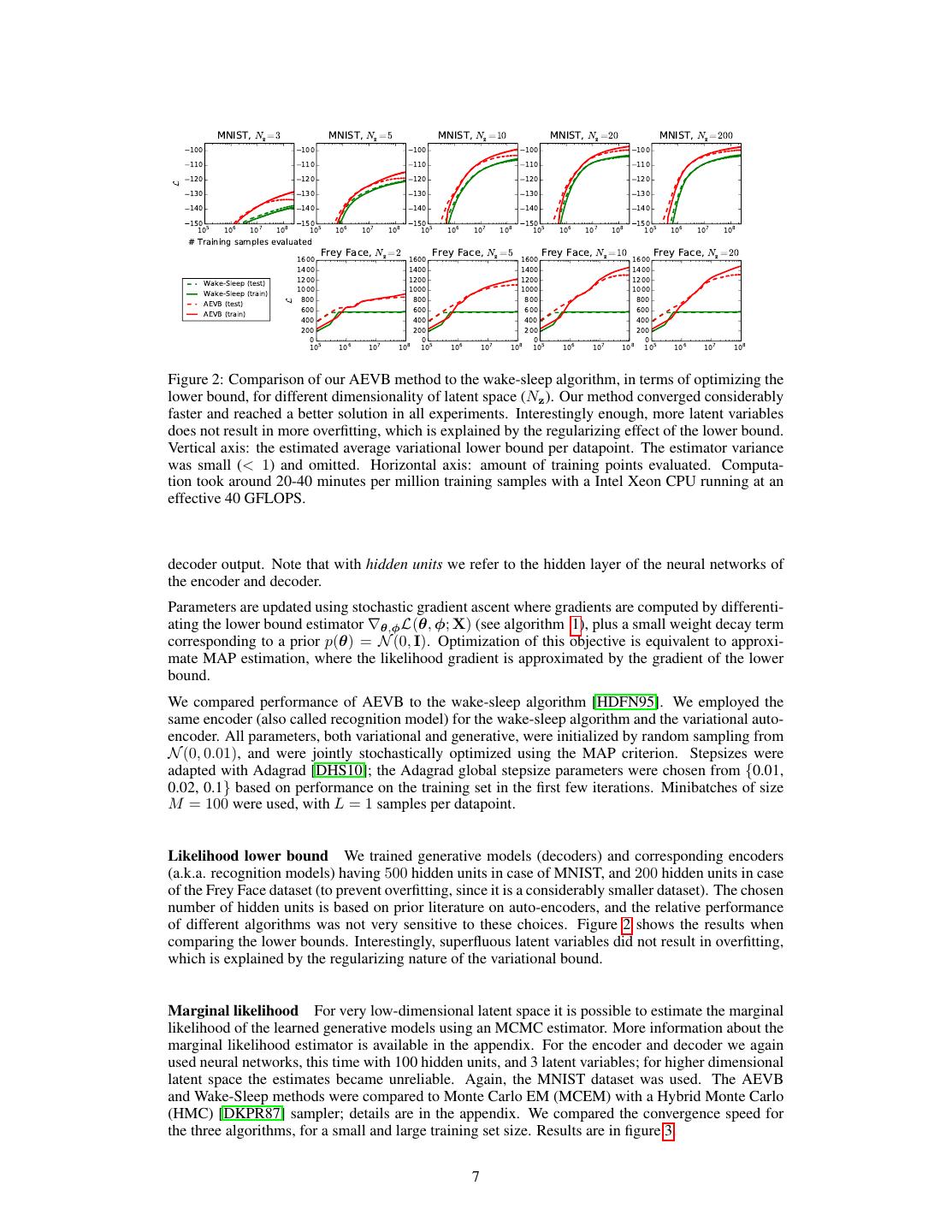
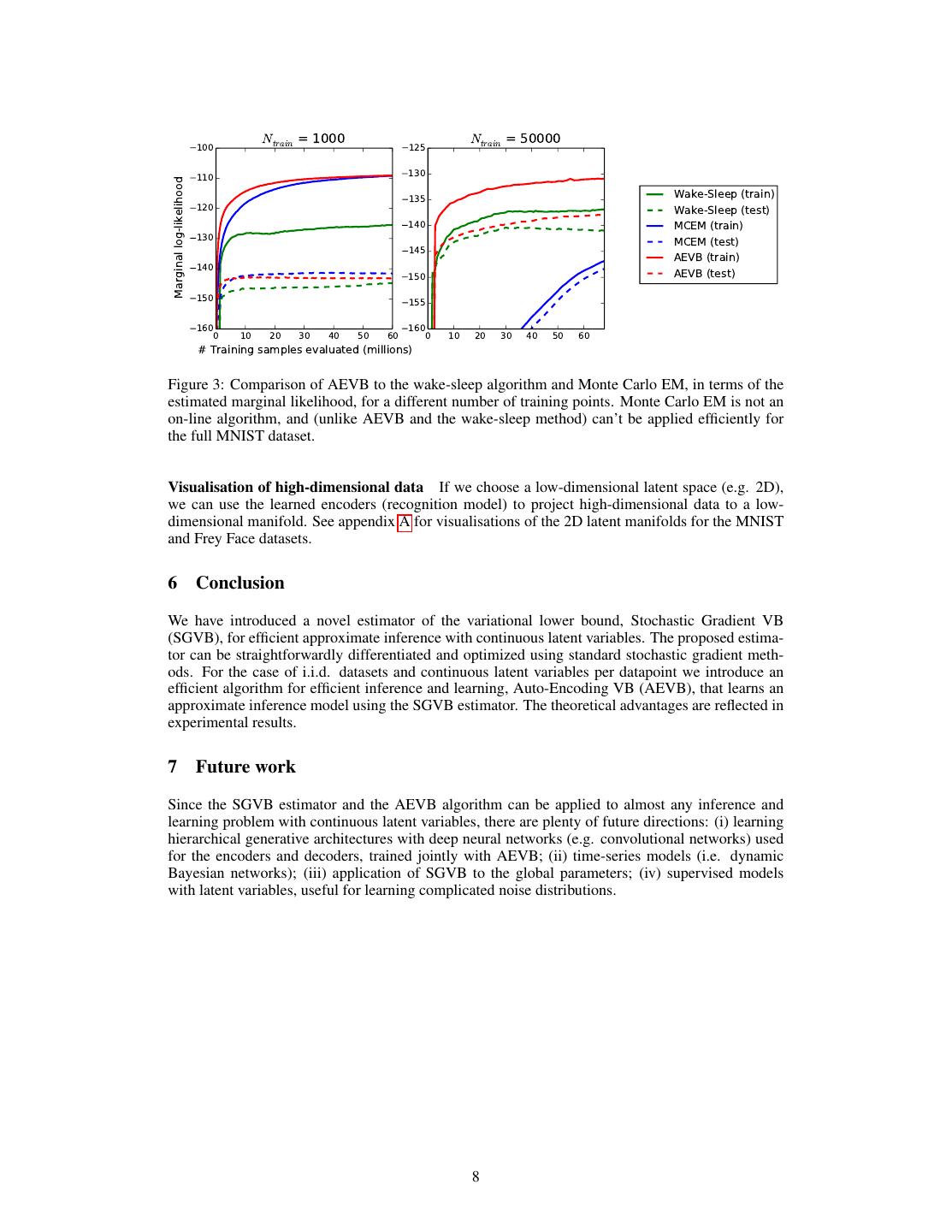
7 . MNIST, Nz =3 MNIST, Nz =5 MNIST, Nz =10 MNIST, Nz =20 MNIST, Nz =200 100 100 100 100 100 110 110 110 110 110 L 120 120 120 120 120 130 130 130 130 130 140 140 140 140 140 150 5 150 5 150 5 150 5 150 5 10 106 107 108 10 106 107 108 10 106 107 108 10 106 107 108 10 106 107 108 # Training samples evaluated 1600 Frey Face, Nz =2 1600 Frey Face, Nz =5 1600 Frey Face, Nz =10 1600 Frey Face, Nz =20 1400 1400 1400 1400 Wake-Sleep (test) 1200 1200 1200 1200 Wake-Sleep (train) 1000 1000 1000 1000 AEVB (test) 800 800 800 800 L AEVB (train) 600 600 600 600 400 400 400 400 200 200 200 200 0 0 0 0 105 106 107 108 105 106 107 108 105 106 107 108 105 106 107 108 Figure 2: Comparison of our AEVB method to the wake-sleep algorithm, in terms of optimizing the lower bound, for different dimensionality of latent space (Nz ). Our method converged considerably faster and reached a better solution in all experiments. Interestingly enough, more latent variables does not result in more overfitting, which is explained by the regularizing effect of the lower bound. Vertical axis: the estimated average variational lower bound per datapoint. The estimator variance was small (< 1) and omitted. Horizontal axis: amount of training points evaluated. Computa- tion took around 20-40 minutes per million training samples with a Intel Xeon CPU running at an effective 40 GFLOPS. decoder output. Note that with hidden units we refer to the hidden layer of the neural networks of the encoder and decoder. Parameters are updated using stochastic gradient ascent where gradients are computed by differenti- ating the lower bound estimator ∇θ,φ L(θ, φ; X) (see algorithm 1), plus a small weight decay term corresponding to a prior p(θ) = N (0, I). Optimization of this objective is equivalent to approxi- mate MAP estimation, where the likelihood gradient is approximated by the gradient of the lower bound. We compared performance of AEVB to the wake-sleep algorithm [HDFN95]. We employed the same encoder (also called recognition model) for the wake-sleep algorithm and the variational auto- encoder. All parameters, both variational and generative, were initialized by random sampling from N (0, 0.01), and were jointly stochastically optimized using the MAP criterion. Stepsizes were adapted with Adagrad [DHS10]; the Adagrad global stepsize parameters were chosen from {0.01, 0.02, 0.1} based on performance on the training set in the first few iterations. Minibatches of size M = 100 were used, with L = 1 samples per datapoint. Likelihood lower bound We trained generative models (decoders) and corresponding encoders (a.k.a. recognition models) having 500 hidden units in case of MNIST, and 200 hidden units in case of the Frey Face dataset (to prevent overfitting, since it is a considerably smaller dataset). The chosen number of hidden units is based on prior literature on auto-encoders, and the relative performance of different algorithms was not very sensitive to these choices. Figure 2 shows the results when comparing the lower bounds. Interestingly, superfluous latent variables did not result in overfitting, which is explained by the regularizing nature of the variational bound. Marginal likelihood For very low-dimensional latent space it is possible to estimate the marginal likelihood of the learned generative models using an MCMC estimator. More information about the marginal likelihood estimator is available in the appendix. For the encoder and decoder we again used neural networks, this time with 100 hidden units, and 3 latent variables; for higher dimensional latent space the estimates became unreliable. Again, the MNIST dataset was used. The AEVB and Wake-Sleep methods were compared to Monte Carlo EM (MCEM) with a Hybrid Monte Carlo (HMC) [DKPR87] sampler; details are in the appendix. We compared the convergence speed for the three algorithms, for a small and large training set size. Results are in figure 3. 7
8 . 100 Ntrain = 1000 125 Ntrain = 50000 Marginal log-likelihood 110 130 135 Wake-Sleep (train) 120 Wake-Sleep (test) 140 MCEM (train) 130 MCEM (test) 145 AEVB (train) 140 AEVB (test) 150 150 155 160 160 0 10 20 30 40 50 60 0 10 20 30 40 50 60 # Training samples evaluated (millions) Figure 3: Comparison of AEVB to the wake-sleep algorithm and Monte Carlo EM, in terms of the estimated marginal likelihood, for a different number of training points. Monte Carlo EM is not an on-line algorithm, and (unlike AEVB and the wake-sleep method) can’t be applied efficiently for the full MNIST dataset. Visualisation of high-dimensional data If we choose a low-dimensional latent space (e.g. 2D), we can use the learned encoders (recognition model) to project high-dimensional data to a low- dimensional manifold. See appendix A for visualisations of the 2D latent manifolds for the MNIST and Frey Face datasets. 6 Conclusion We have introduced a novel estimator of the variational lower bound, Stochastic Gradient VB (SGVB), for efficient approximate inference with continuous latent variables. The proposed estima- tor can be straightforwardly differentiated and optimized using standard stochastic gradient meth- ods. For the case of i.i.d. datasets and continuous latent variables per datapoint we introduce an efficient algorithm for efficient inference and learning, Auto-Encoding VB (AEVB), that learns an approximate inference model using the SGVB estimator. The theoretical advantages are reflected in experimental results. 7 Future work Since the SGVB estimator and the AEVB algorithm can be applied to almost any inference and learning problem with continuous latent variables, there are plenty of future directions: (i) learning hierarchical generative architectures with deep neural networks (e.g. convolutional networks) used for the encoders and decoders, trained jointly with AEVB; (ii) time-series models (i.e. dynamic Bayesian networks); (iii) application of SGVB to the global parameters; (iv) supervised models with latent variables, useful for learning complicated noise distributions. 8
9 .References [BCV13] Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A re- view and new perspectives. 2013. [BJP12] David M Blei, Michael I Jordan, and John W Paisley. Variational bayesian inference with stochastic search. In Proceedings of the 29th International Conference on Machine Learning (ICML-12), pages 1367–1374, 2012. [BTL13] ´ Thibodeau-Laufer. Deep generative stochastic networks train- Yoshua Bengio and Eric able by backprop. arXiv preprint arXiv:1306.1091, 2013. [Dev86] Luc Devroye. Sample-based non-uniform random variate generation. In Proceedings of the 18th conference on Winter simulation, pages 260–265. ACM, 1986. [DHS10] John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12:2121– 2159, 2010. [DKPR87] Simon Duane, Anthony D Kennedy, Brian J Pendleton, and Duncan Roweth. Hybrid monte carlo. Physics letters B, 195(2):216–222, 1987. [GMW13] Karol Gregor, Andriy Mnih, and Daan Wierstra. Deep autoregressive networks. arXiv preprint arXiv:1310.8499, 2013. [HBWP13] Matthew D Hoffman, David M Blei, Chong Wang, and John Paisley. Stochastic varia- tional inference. The Journal of Machine Learning Research, 14(1):1303–1347, 2013. [HDFN95] Geoffrey E Hinton, Peter Dayan, Brendan J Frey, and Radford M Neal. The” wake- sleep” algorithm for unsupervised neural networks. SCIENCE, pages 1158–1158, 1995. [KRL08] Koray Kavukcuoglu, Marc’Aurelio Ranzato, and Yann LeCun. Fast inference in sparse coding algorithms with applications to object recognition. Technical Report CBLL- TR-2008-12-01, Computational and Biological Learning Lab, Courant Institute, NYU, 2008. [Lin89] Ralph Linsker. An application of the principle of maximum information preservation to linear systems. Morgan Kaufmann Publishers Inc., 1989. [RGB13] Rajesh Ranganath, Sean Gerrish, and David M Blei. Black box variational inference. arXiv preprint arXiv:1401.0118, 2013. [RMW14] Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic back- propagation and variational inference in deep latent gaussian models. arXiv preprint arXiv:1401.4082, 2014. [Row98] Sam Roweis. EM algorithms for PCA and SPCA. Advances in neural information processing systems, pages 626–632, 1998. [SK13] Tim Salimans and David A Knowles. Fixed-form variational posterior approximation through stochastic linear regression. Bayesian Analysis, 8(4), 2013. [SL10] Ruslan Salakhutdinov and Hugo Larochelle. Efficient learning of deep boltzmann ma- chines. In International Conference on Artificial Intelligence and Statistics, pages 693– 700, 2010. [VLL+ 10] Pascal Vincent, Hugo Larochelle, Isabelle Lajoie, Yoshua Bengio, and Pierre-Antoine Manzagol. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. The Journal of Machine Learning Research, 9999:3371–3408, 2010. A Visualisations See figures 4 and 5 for visualisations of latent space and corresponding observed space of models learned with SGVB. 9
10 . (a) Learned Frey Face manifold (b) Learned MNIST manifold Figure 4: Visualisations of learned data manifold for generative models with two-dimensional latent space, learned with AEVB. Since the prior of the latent space is Gaussian, linearly spaced coor- dinates on the unit square were transformed through the inverse CDF of the Gaussian to produce values of the latent variables z. For each of these values z, we plotted the corresponding generative pθ (x|z) with the learned parameters θ. (a) 2-D latent space (b) 5-D latent space (c) 10-D latent space (d) 20-D latent space Figure 5: Random samples from learned generative models of MNIST for different dimensionalities of latent space. B Solution of −DKL (qφ (z)||pθ (z)), Gaussian case The variational lower bound (the objective to be maximized) contains a KL term that can often be integrated analytically. Here we give the solution when both the prior pθ (z) = N (0, I) and the posterior approximation qφ (z|x(i) ) are Gaussian. Let J be the dimensionality of z. Let µ and σ denote the variational mean and s.d. evaluated at datapoint i, and let µj and σj simply denote the j-th element of these vectors. Then: qθ (z) log p(z) dz = N (z; µ, σ 2 ) log N (z; 0, I) dz J J 1 =− log(2π) − (µ2j + σj2 ) 2 2 j=1 10
11 .And: qθ (z) log qθ (z) dz = N (z; µ, σ 2 ) log N (z; µ, σ 2 ) dz J J 1 =− log(2π) − (1 + log σj2 ) 2 2 j=1 Therefore: −DKL ((qφ (z)||pθ (z)) = qθ (z) (log pθ (z) − log qθ (z)) dz J 1 = 1 + log((σj )2 ) − (µj )2 − (σj )2 2 j=1 When using a recognition model qφ (z|x) then µ and s.d. σ are simply functions of x and the variational parameters φ, as exemplified in the text. C MLP’s as probabilistic encoders and decoders In variational auto-encoders, neural networks are used as probabilistic encoders and decoders. There are many possible choices of encoders and decoders, depending on the type of data and model. In our example we used relatively simple neural networks, namely multi-layered perceptrons (MLPs). For the encoder we used a MLP with Gaussian output, while for the decoder we used MLPs with either Gaussian or Bernoulli outputs, depending on the type of data. C.1 Bernoulli MLP as decoder In this case let pθ (x|z) be a multivariate Bernoulli whose probabilities are computed from z with a fully-connected neural network with a single hidden layer: D log p(x|z) = xi log yi + (1 − xi ) · log(1 − yi ) i=1 where y = fσ (W2 tanh(W1 z + b1 ) + b2 ) (11) where fσ (.) is the elementwise sigmoid activation function, and where θ = {W1 , W2 , b1 , b2 } are the weights and biases of the MLP. C.2 Gaussian MLP as encoder or decoder In this case let encoder or decoder be a multivariate Gaussian with a diagonal covariance structure: log p(x|z) = log N (x; µ, σ 2 I) where µ = W4 h + b4 log σ 2 = W5 h + b5 h = tanh(W3 z + b3 ) (12) where {W3 , W4 , W5 , b3 , b4 , b5 } are the weights and biases of the MLP and part of θ when used as decoder. Note that when this network is used as an encoder qφ (z|x), then z and x are swapped, and the weights and biases are variational parameters φ. D Marginal likelihood estimator We derived the following marginal likelihood estimator that produces good estimates of the marginal likelihood as long as the dimensionality of the sampled space is low (less then 5 dimensions), and sufficient samples are taken. Let pθ (x, z) = pθ (z)pθ (x|z) be the generative model we are sampling from, and for a given datapoint x(i) we would like to estimate the marginal likelihood pθ (x(i) ). The estimation process consists of three stages: 11
12 . 1. Sample L values {z(l) } from the posterior using gradient-based MCMC, e.g. Hybrid Monte Carlo, using ∇z log pθ (z|x) = ∇z log pθ (z) + ∇z log pθ (x|z). 2. Fit a density estimator q(z) to these samples {z(l) }. 3. Again, sample L new values from the posterior. Plug these samples, as well as the fitted q(z), into the following estimator: L −1 (i) 1 q(z(l) ) pθ (x ) where z(l) ∼ pθ (z|x(i) ) L l=1 pθ (z)pθ (x(i) |z(l) ) Derivation of the estimator: (i) 1 q(z) dz q(z) ppθθ (x ,z) (x(i) ,z) dz = = pθ (x(i) ) pθ (x(i) ) pθ (x(i) ) pθ (x(i) , z) q(z) = dz pθ (x(i) ) pθ (x(i) , z) q(z) = pθ (z|x(i) ) dz pθ (x(i) , z) L 1 q(z(l) ) where z(l) ∼ pθ (z|x(i) ) L l=1 pθ (z)pθ (x(i) |z(l) ) E Monte Carlo EM The Monte Carlo EM algorithm does not employ an encoder, instead it samples from the pos- terior of the latent variables using gradients of the posterior computed with ∇z log pθ (z|x) = ∇z log pθ (z) + ∇z log pθ (x|z). The Monte Carlo EM procedure consists of 10 HMC leapfrog steps with an automatically tuned stepsize such that the acceptance rate was 90%, followed by 5 weight updates steps using the acquired sample. For all algorithms the parameters were updated using the Adagrad stepsizes (with accompanying annealing schedule). The marginal likelihood was estimated with the first 1000 datapoints from the train and test sets, for each datapoint sampling 50 values from the posterior of the latent variables using Hybrid Monte Carlo with 4 leapfrog steps. F Full VB As written in the paper, it is possible to perform variational inference on both the parameters θ and the latent variables z, as opposed to just the latent variables as we did in the paper. Here, we’ll derive our estimator for that case. Let pα (θ) be some hyperprior for the parameters introduced above, parameterized by α. The marginal likelihood can be written as: log pα (X) = DKL (qφ (θ)||pα (θ|X)) + L(φ; X) (13) where the first RHS term denotes a KL divergence of the approximate from the true posterior, and where L(φ; X) denotes the variational lower bound to the marginal likelihood: L(φ; X) = qφ (θ) (log pθ (X) + log pα (θ) − log qφ (θ)) dθ (14) Note that this is a lower bound since the KL divergence is non-negative; the bound equals the true marginal when the approximate and true posteriors match exactly. The term log pθ (X) is composed N (i) of a sum over the marginal likelihoods of individual datapoints log pθ (X) = i=1 log pθ (x ), which can each be rewritten as: log pθ (x(i) ) = DKL (qφ (z|x(i) )||pθ (z|x(i) )) + L(θ, φ; x(i) ) (15) 12
13 .where again the first RHS term is the KL divergence of the approximate from the true posterior, and L(θ, φ; x) is the variational lower bound of the marginal likelihood of datapoint i: L(θ, φ; x(i) ) = qφ (z|x) log pθ (x(i) |z) + log pθ (z) − log qφ (z|x) dz (16) The expectations on the RHS of eqs (14) and (16) can obviously be written as a sum of three separate expectations, of which the second and third component can sometimes be analytically solved, e.g. when both pθ (x) and qφ (z|x) are Gaussian. For generality we will here assume that each of these expectations is intractable. Under certain mild conditions outlined in section (see paper) for chosen approximate posteriors qφ (θ) and qφ (z|x) we can reparameterize conditional samples z ∼ qφ (z|x) as z = gφ ( , x) with ∼ p( ) (17) where we choose a prior p( ) and a function gφ ( , x) such that the following holds: L(θ, φ; x(i) ) = qφ (z|x) log pθ (x(i) |z) + log pθ (z) − log qφ (z|x) dz = p( ) log pθ (x(i) |z) + log pθ (z) − log qφ (z|x) d (18) z=gφ ( ,x(i) ) The same can be done for the approximate posterior qφ (θ): θ = hφ (ζ) with ζ ∼ p(ζ) (19) where we, similarly as above, choose a prior p(ζ) and a function hφ (ζ) such that the following holds: L(φ; X) = qφ (θ) (log pθ (X) + log pα (θ) − log qφ (θ)) dθ = p(ζ) (log pθ (X) + log pα (θ) − log qφ (θ)) dζ (20) θ=hφ (ζ) For notational conciseness we introduce a shorthand notation fφ (x, z, θ): fφ (x, z, θ) = N · (log pθ (x|z) + log pθ (z) − log qφ (z|x)) + log pα (θ) − log qφ (θ) (21) Using equations (20) and (18), the Monte Carlo estimate of the variational lower bound, given datapoint x(i) , is: L 1 L(φ; X) fφ (x(l) , gφ ( (l) , x(l) ), hφ (ζ (l) )) (22) L l=1 where (l) ∼ p( ) and ζ (l) ∼ p(ζ). The estimator only depends on samples from p( ) and p(ζ) which are obviously not influenced by φ, therefore the estimator can be differentiated w.r.t. φ. The resulting stochastic gradients can be used in conjunction with stochastic optimization methods such as SGD or Adagrad [DHS10]. See algorithm 1 for a basic approach to computing stochastic gradients. F.1 Example Let the prior over the parameters and latent variables be the centered isotropic Gaussian pα (θ) = N (z; 0, I) and pθ (z) = N (z; 0, I). Note that in this case, the prior lacks parameters. Let’s also assume that the true posteriors are approximatily Gaussian with an approximately diagonal covari- ance. In this case, we can let the variational approximate posteriors be multivariate Gaussians with a diagonal covariance structure: log qφ (θ) = log N (θ; µθ , σ 2θ I) log qφ (z|x) = log N (z; µz , σ 2z I) (23) 13
14 .Algorithm 2 Pseudocode for computing a stochastic gradient using our estimator. See text for meaning of the functions fφ , gφ and hφ . Require: φ (Current value of variational parameters) g←0 for l is 1 to L do x ← Random draw from dataset X ← Random draw from prior p( ) ζ ← Random draw from prior p(ζ) g ← g + L1 ∇φ fφ (x, gφ ( , x), hφ (ζ)) end for return g where µz and σ z are yet unspecified functions of x. Since they are Gaussian, we can parameterize the variational approximate posteriors: qφ (θ) as θ = µθ + σ θ ζ where ζ ∼ N (0, I) qφ (z|x) as z = µz + σ z where ∼ N (0, I) With we signify an element-wise product. These can be plugged into the lower bound defined above (eqs (21) and (22)). In this case it is possible to construct an alternative estimator with a lower variance, since in this model pα (θ), pθ (z), qφ (θ) and qφ (z|x) are Gaussian, and therefore four terms of fφ can be solved analytically. The resulting estimator is: L J 1 1 (l) (l) (l) L(φ; X) N · 1 + log((σz,j )2 ) − (µz,j )2 − (σz,j )2 + log pθ (x(i) z(i) ) L 2 j=1 l=1 J 1 (l) (l) (l) + 1 + log((σθ,j )2 ) − (µθ,j )2 − (σθ,j )2 (24) 2 j=1 (i) (i) µj and σj simply denote the j-th element of vectors µ(i) and σ (i) . 14
3秒后跳转登录页面
去登陆

