展开查看详情
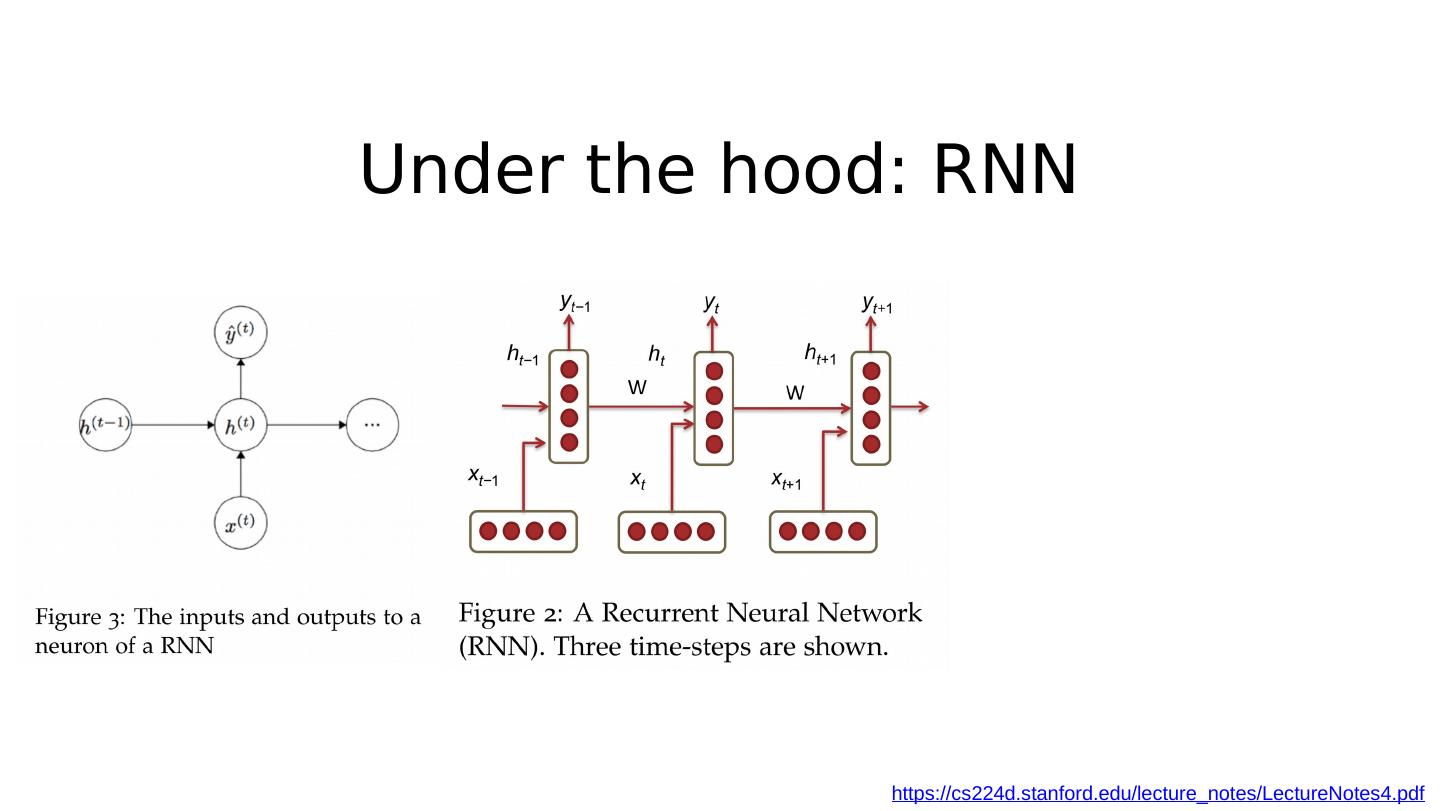
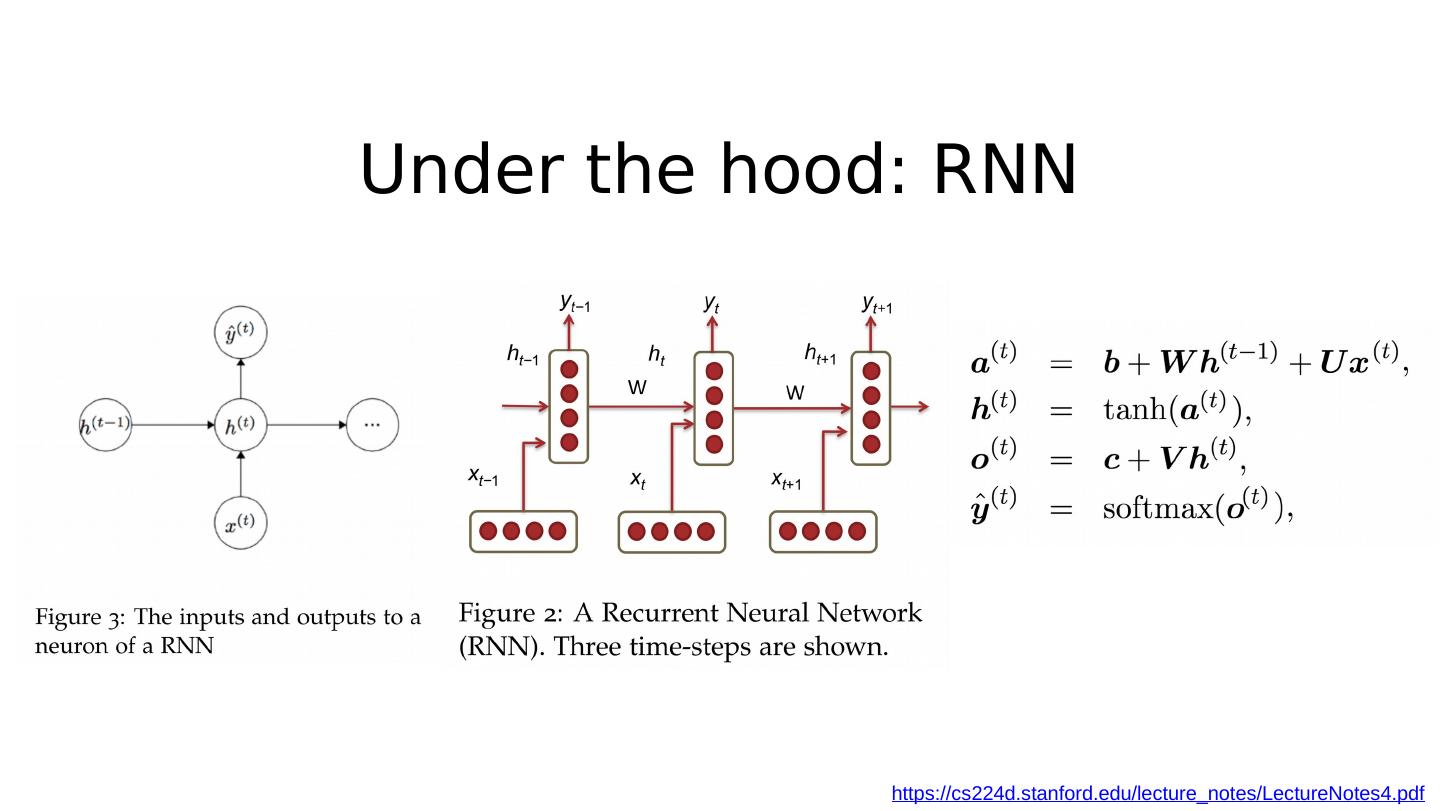
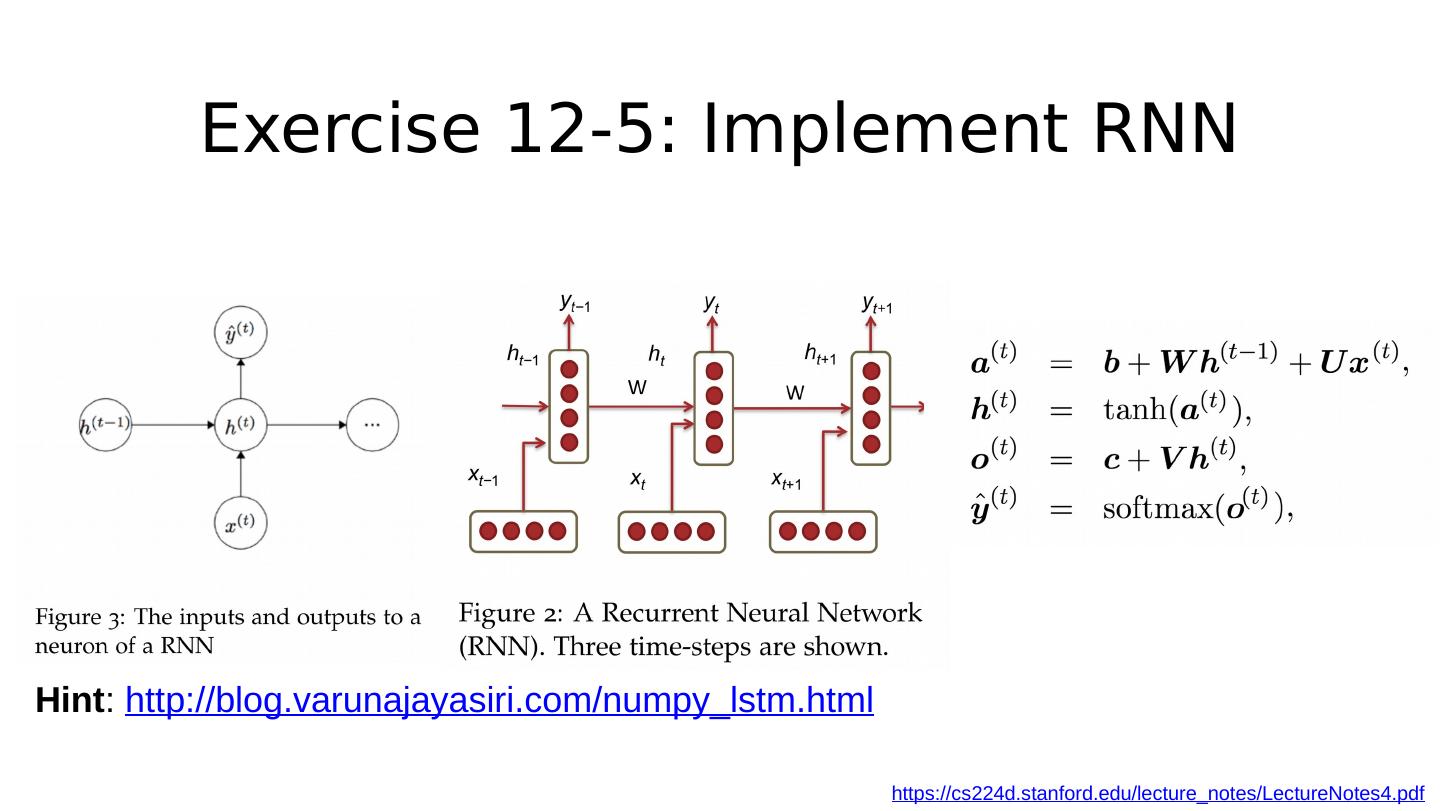
19 .Under the hood: RNN https://cs224d.stanford.edu/lecture_notes/LectureNotes4.pdf
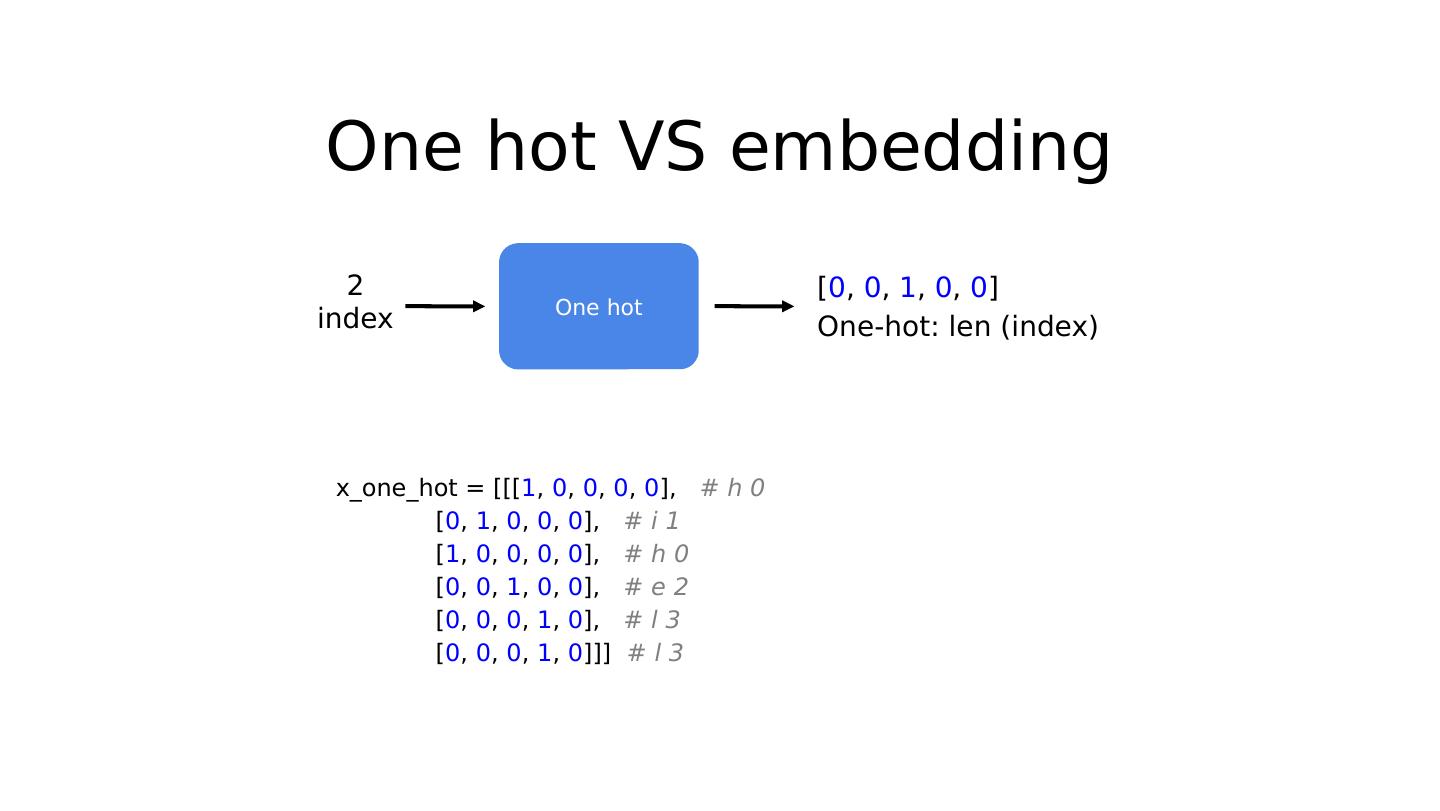
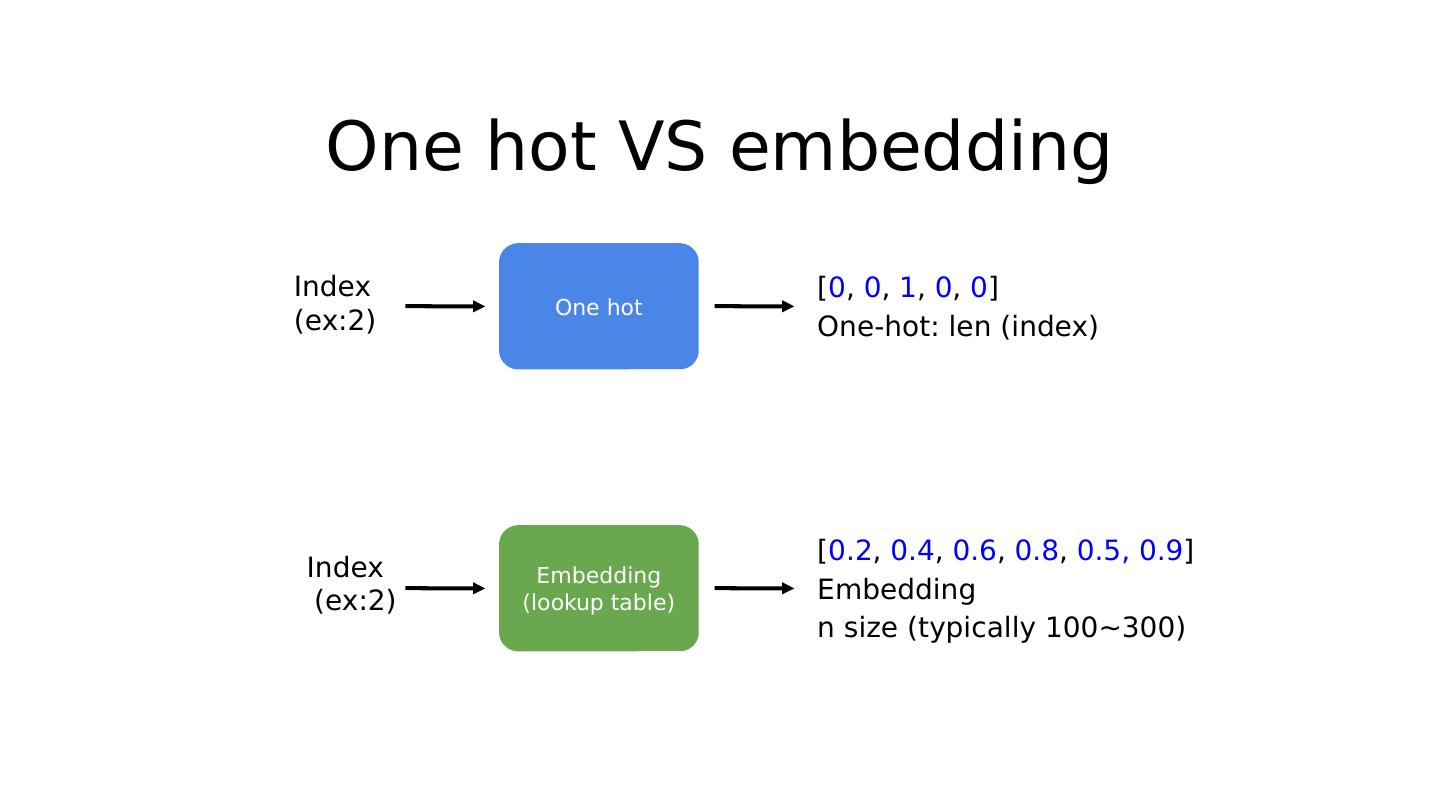
20 .RNN topics RNN Basics Teach RNN to say ‘hello’ One-hot VS embedding RNN classification (name) RNN on GPU RNN language modeling Teacher forcing Sequence to sequence
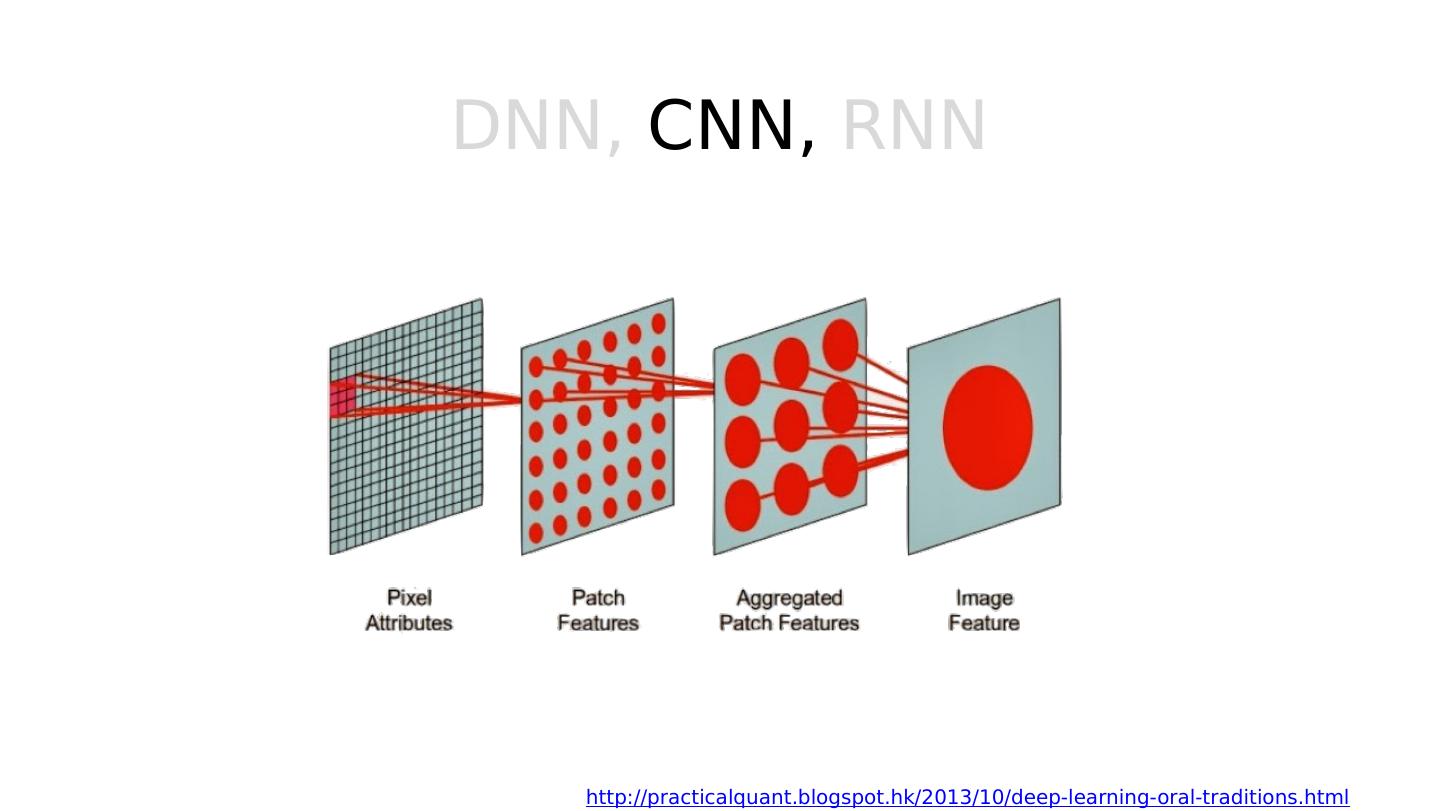
21 .DNN, CNN, RNN http://practicalquant.blogspot.hk/2013/10/deep-learning-oral-traditions.html
22 .DNN, CNN, RNN https://blog.ttro.com/artificial-intelligence-will-shape-e-learning-for-good/
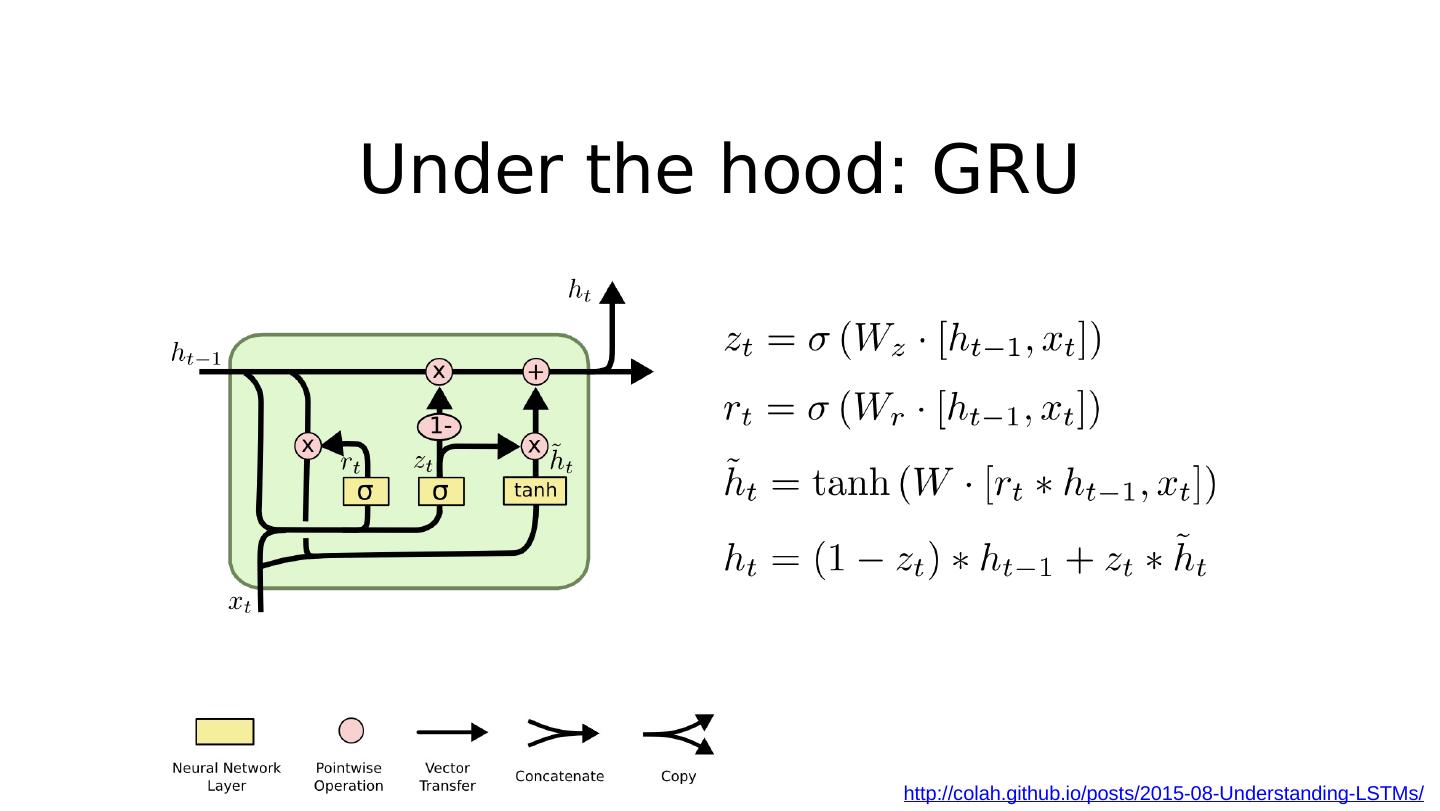
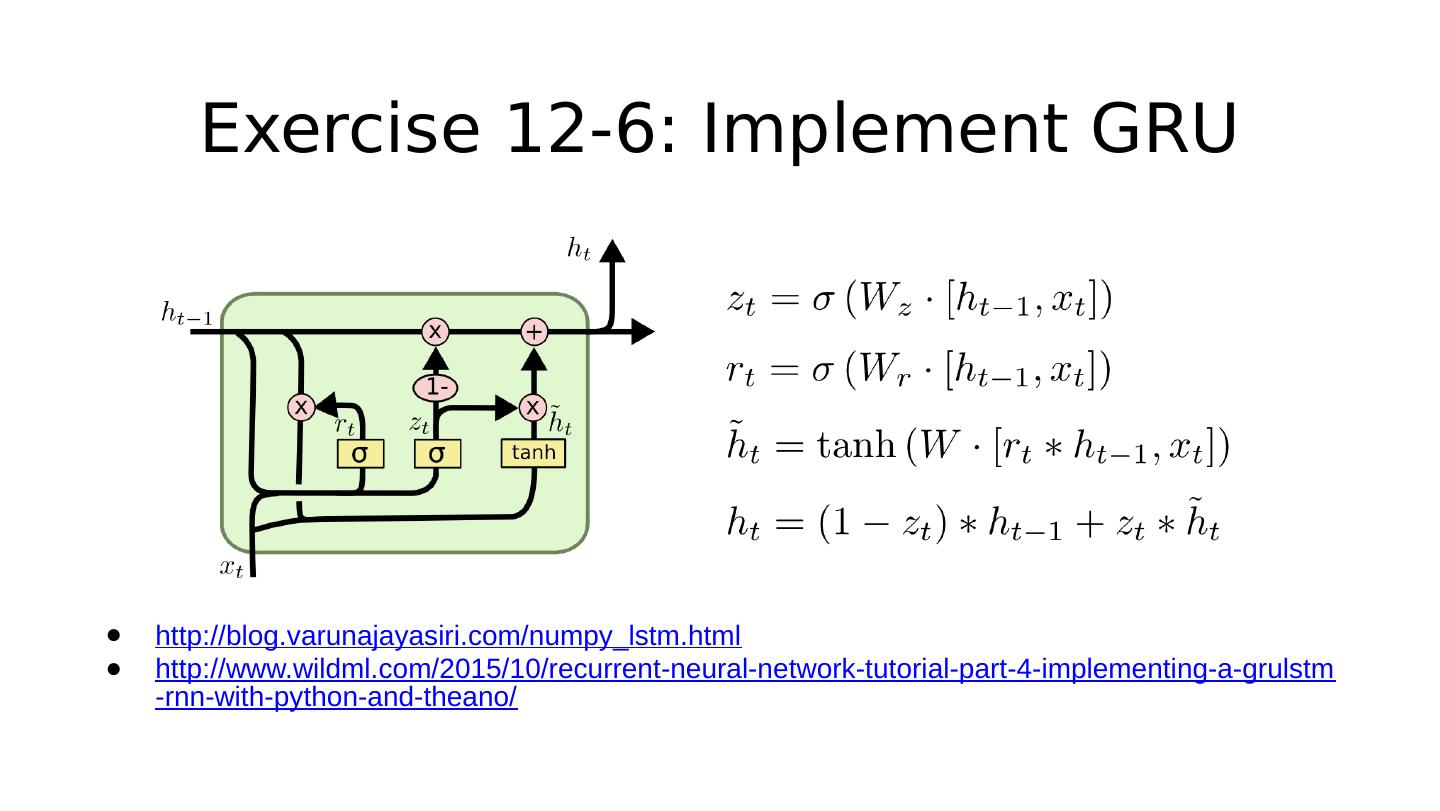
23 .Under the hood: GRU http://colah.github.io/posts/2015-08-Understanding-LSTMs/
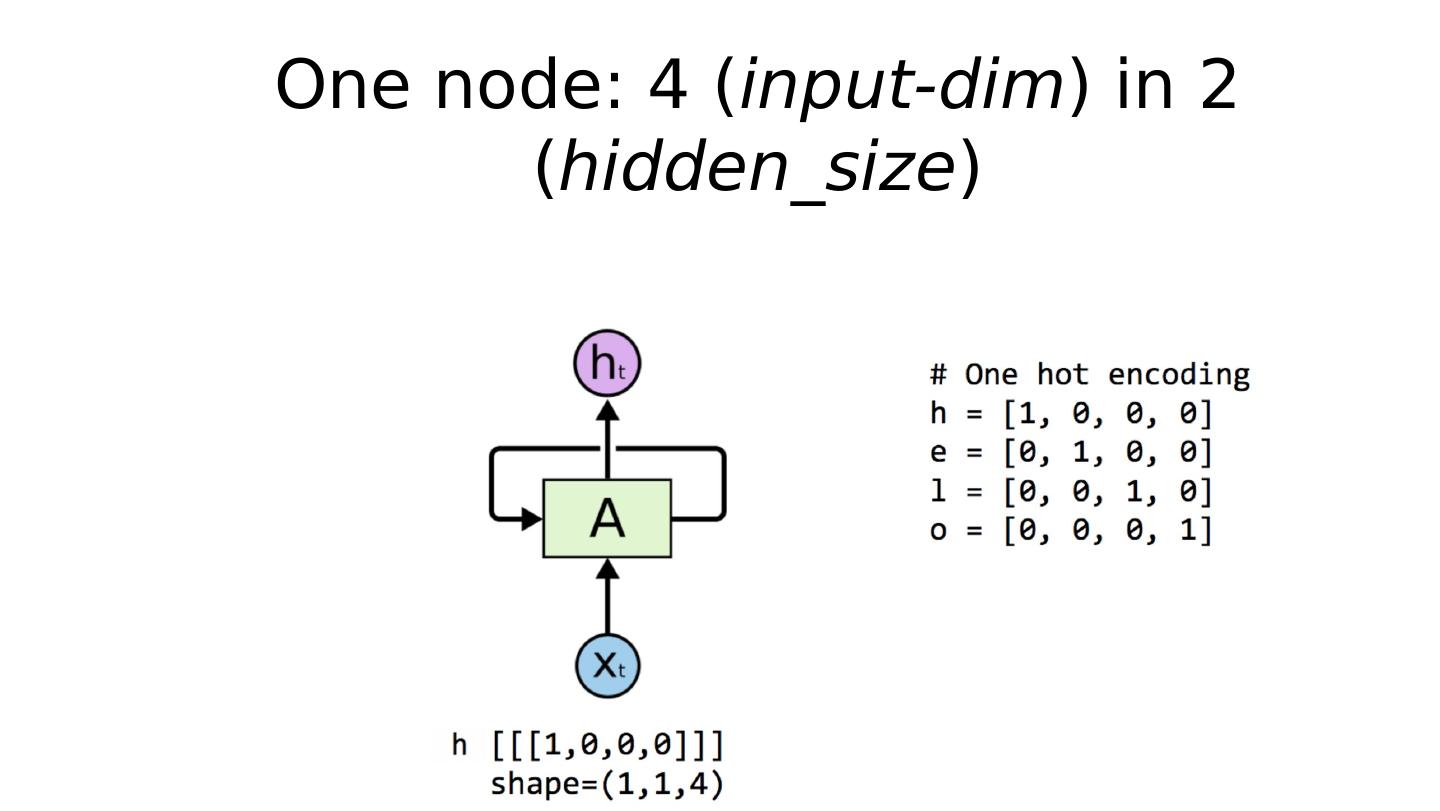
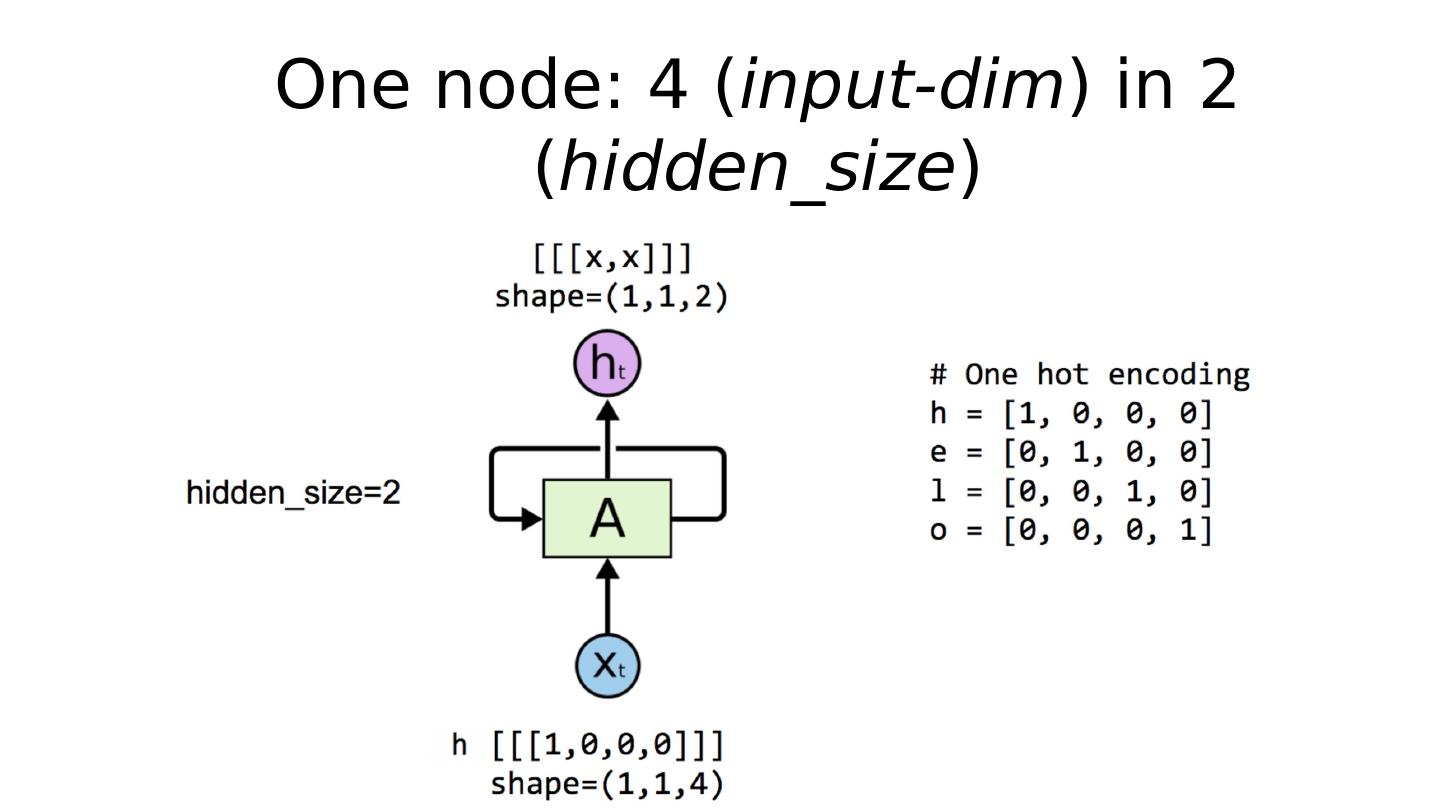
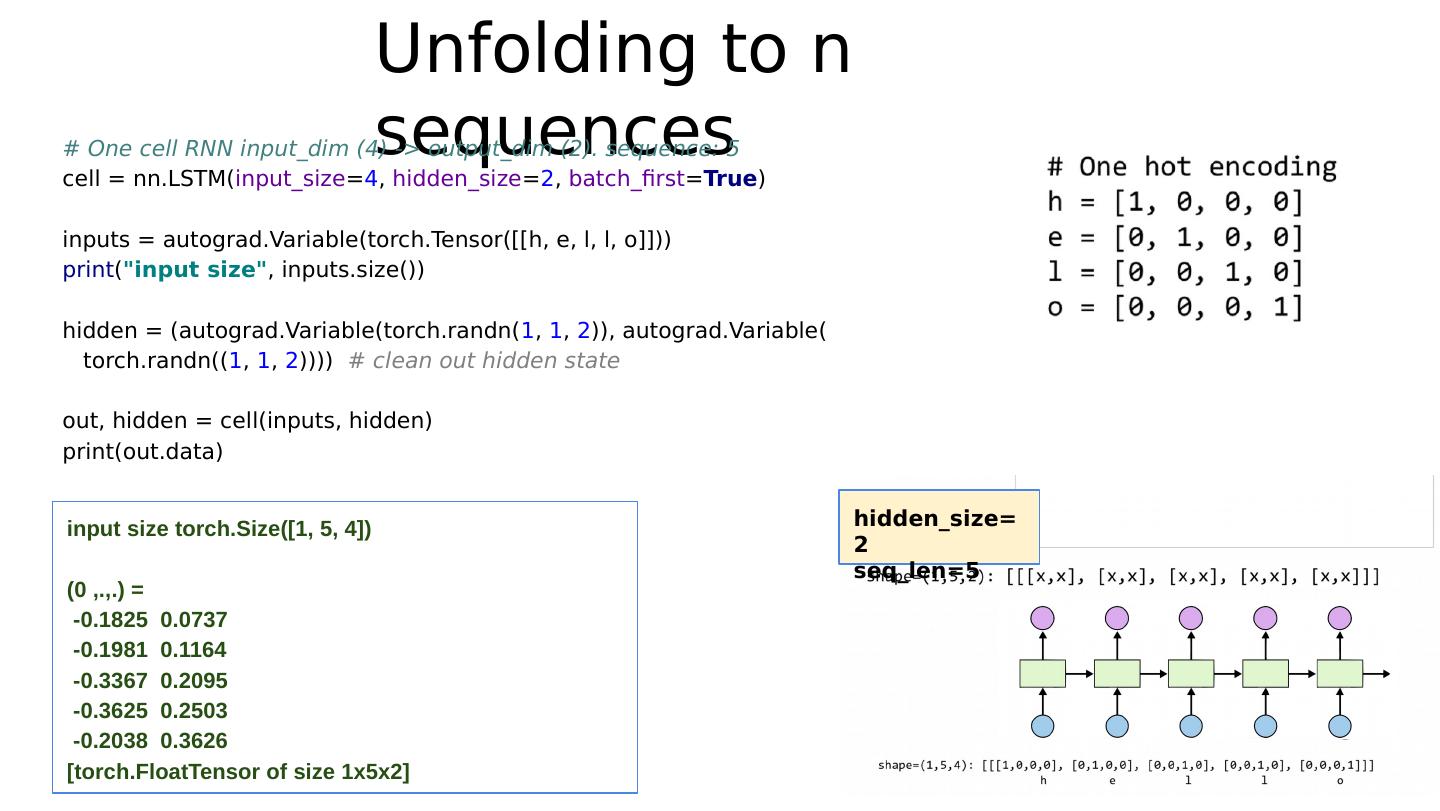
24 .One node: 4 ( input-dim ) in 2 ( hidden_size )
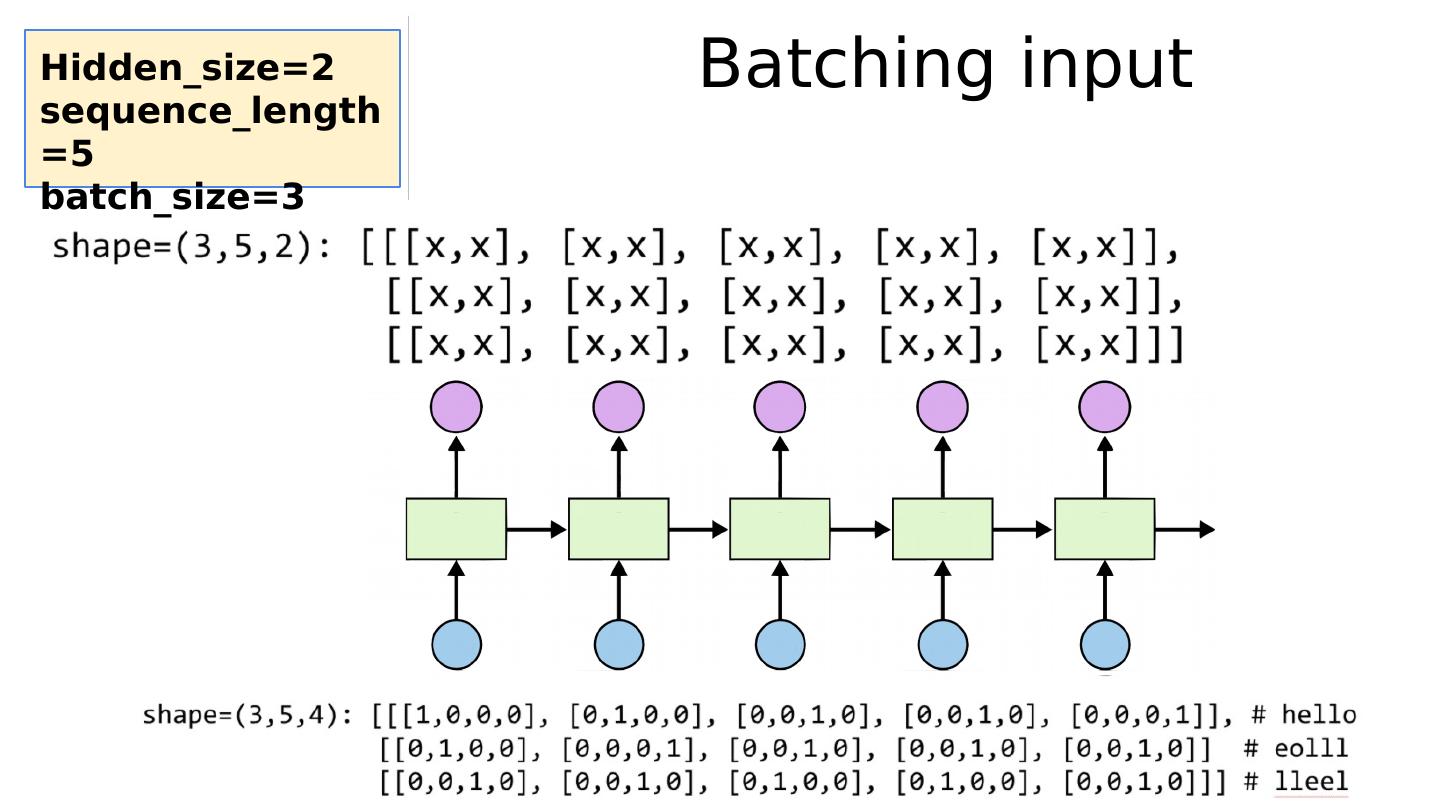
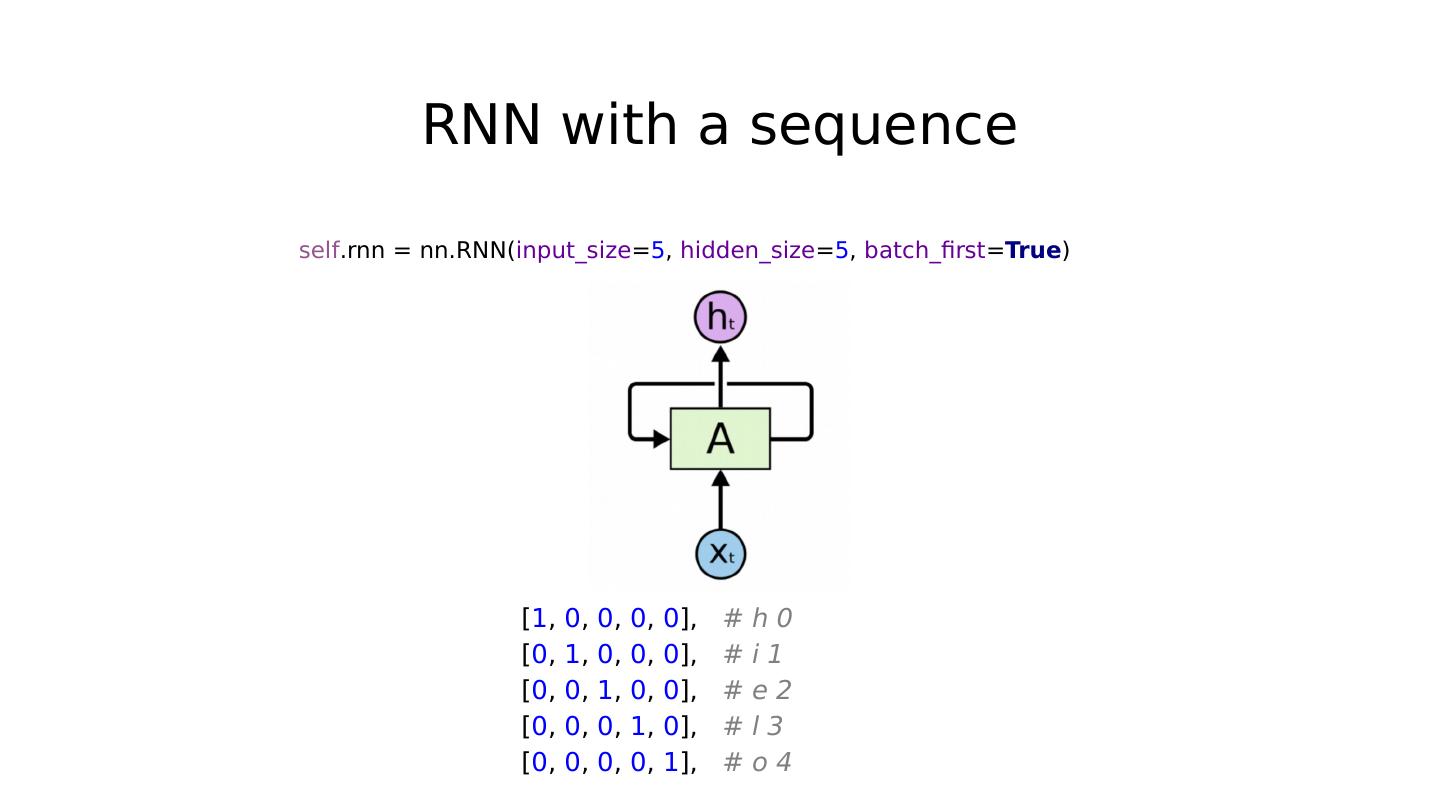
25 .Batching input Hidden_size=2 sequence_length=5 batch_size=3 # One cell RNN input_dim (4) -> output_dim (2). sequence: 5, batch 3 # 3 batches hello, eolll, lleel # rank = (3, 5, 4) inputs = autograd.Variable(torch.Tensor([[h, e, l, l, o], [e, o, l, l, l], [l, l, e, e, l]])) print ( "input size" , inputs.size()) # input size torch.Size([3, 5, 4]) # (num_layers * num_directions, batch, hidden_size) hidden = (autograd.Variable(torch.randn( 1 , 3 , 2 )), autograd.Variable( torch.randn(( 1 , 3 , 2 )))) out, hidden = cell(inputs, hidden) print ( "out size" , out.size()) # out size torch.Size([3, 5, 2])
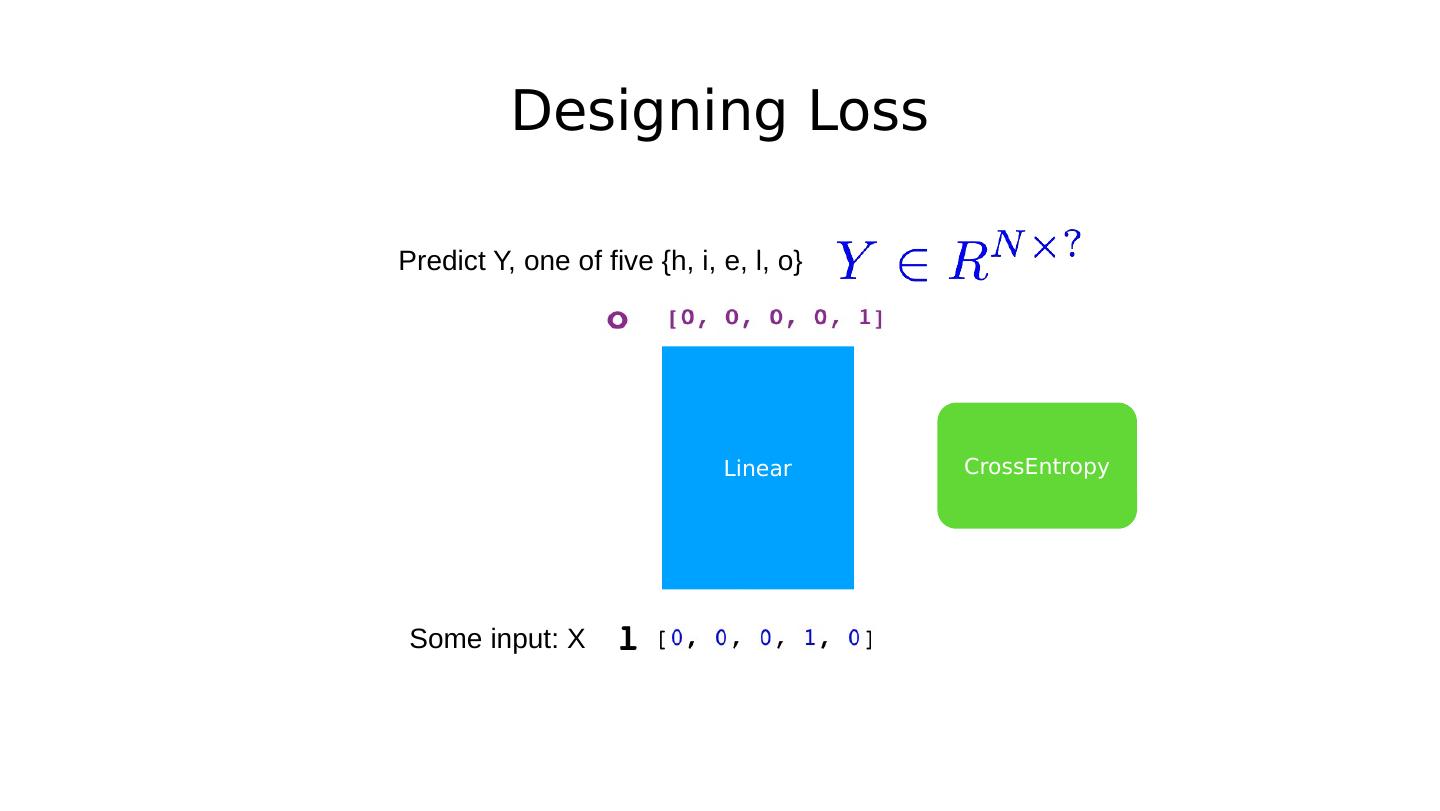
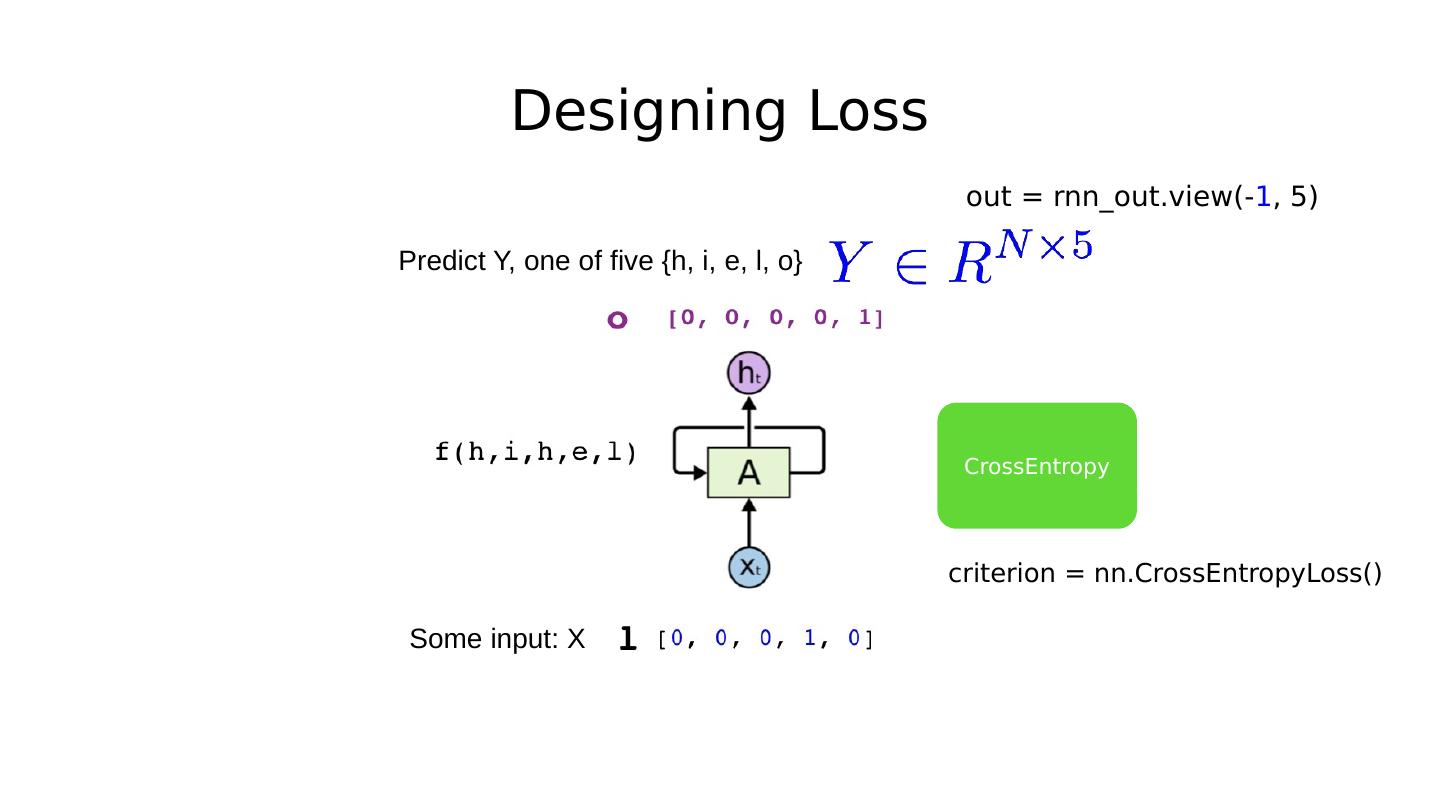
26 .Exercise 12-2: Combine RNN+Linear Why does it train faster (more stable)? Linear P(y=0) P(y=1) P(y=n) … With CrossEntropy Loss
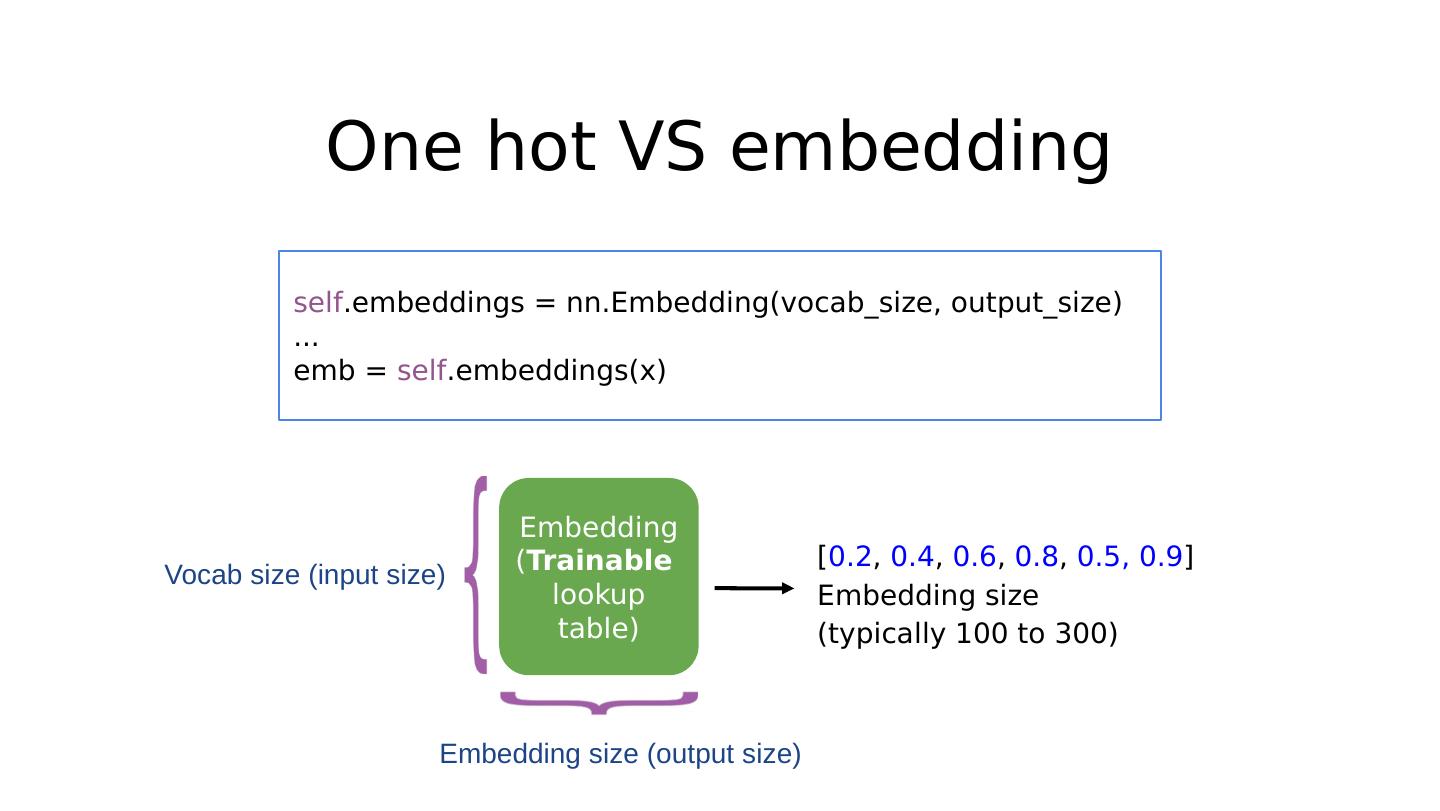
27 .One hot VS embedding Embedding ( T rainable lookup table) [ 0.2 , 0.4 , 0.6 , 0.8 , 0.5, 0.9 ] Embedding size (typically 100 to 300) self .embeddings = nn.Embedding(vocab_size, output_size) ... emb = self .embeddings(x) Embedding size (output size) Vocab size (input size)
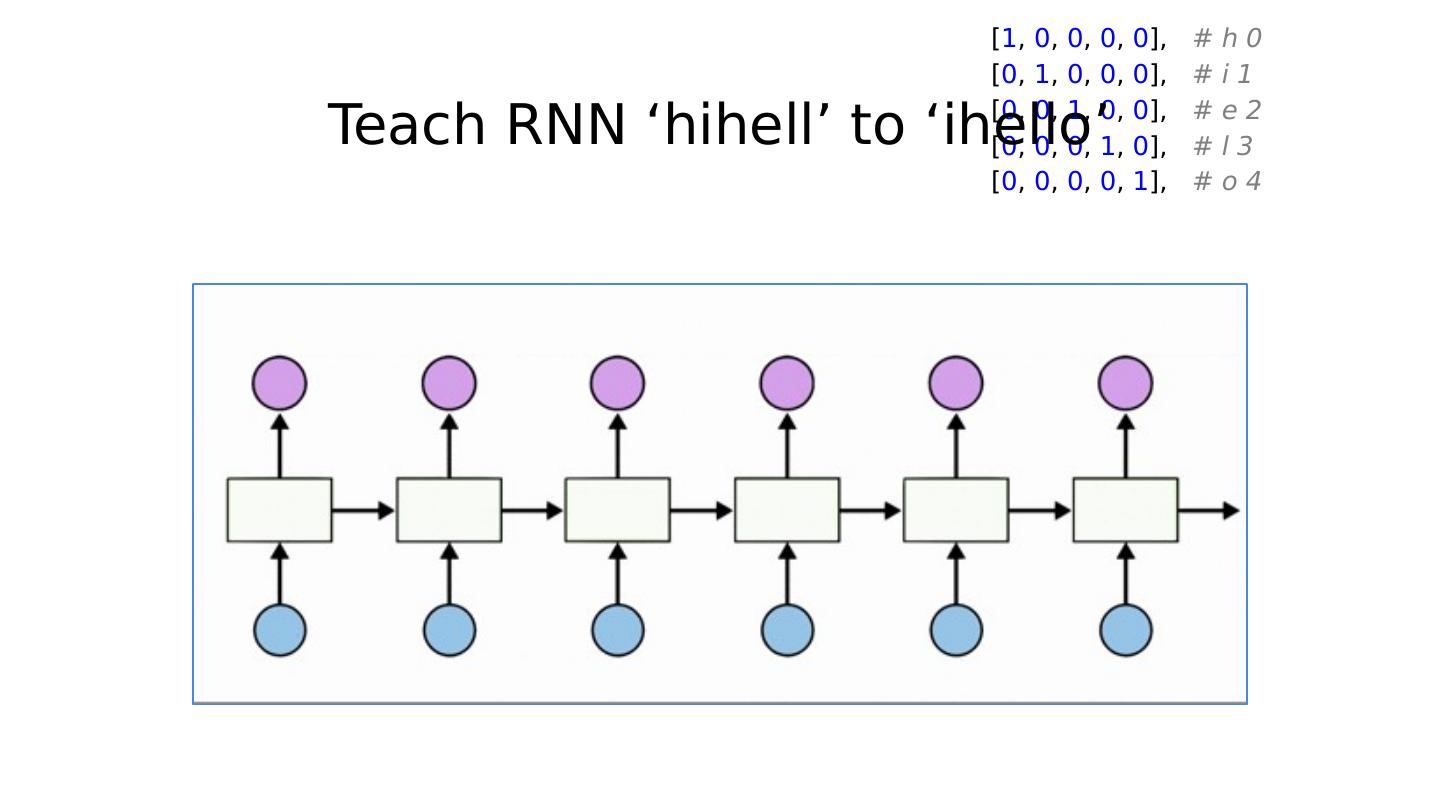
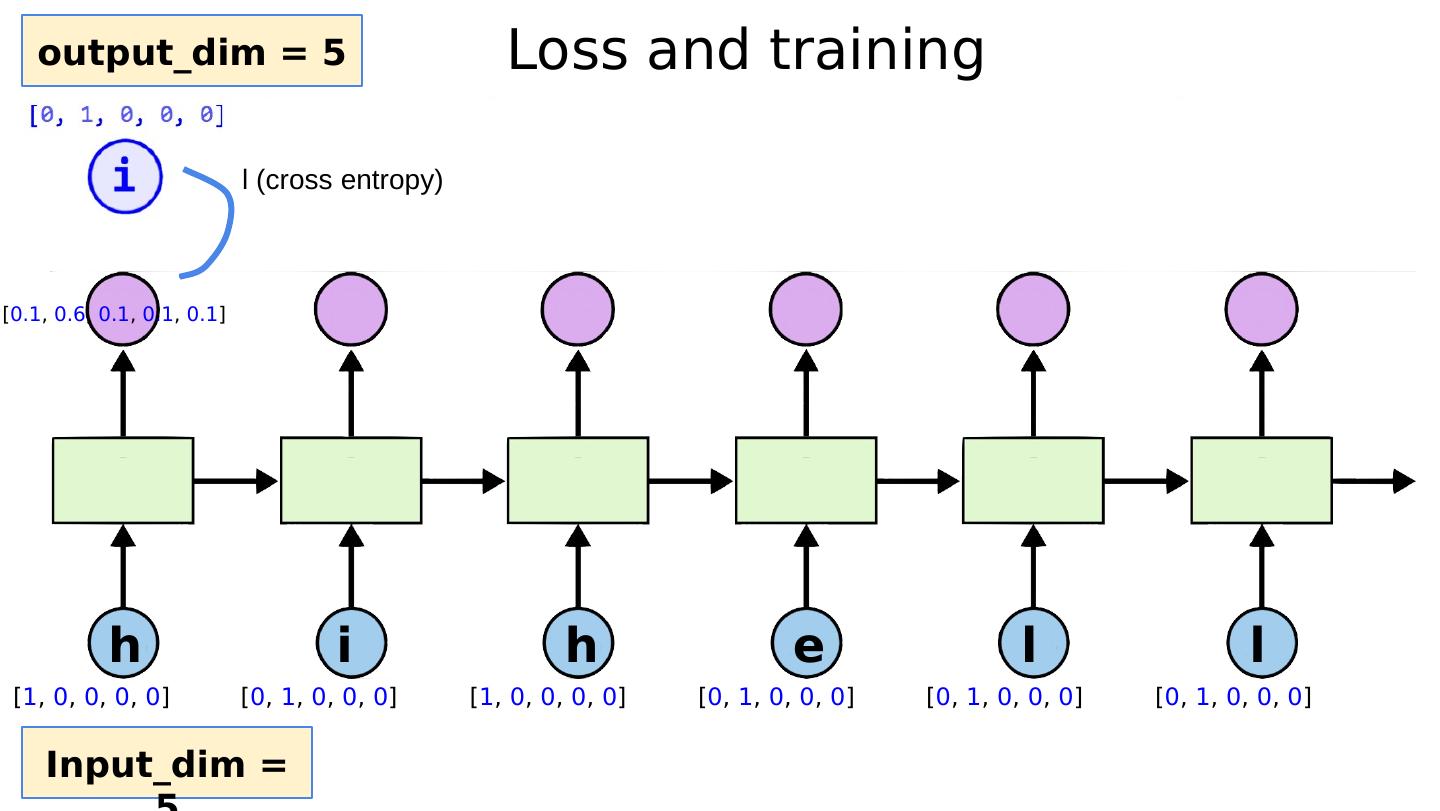
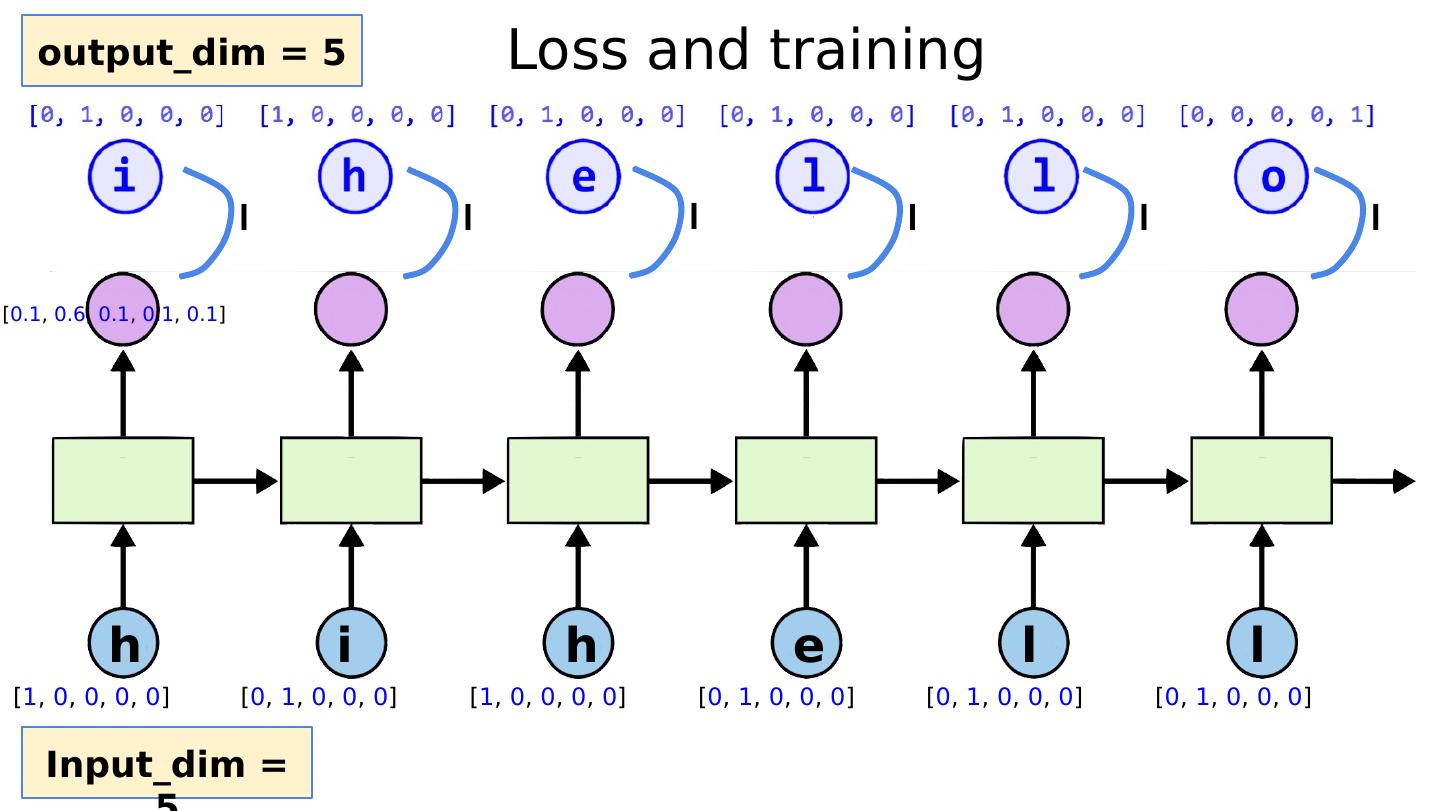
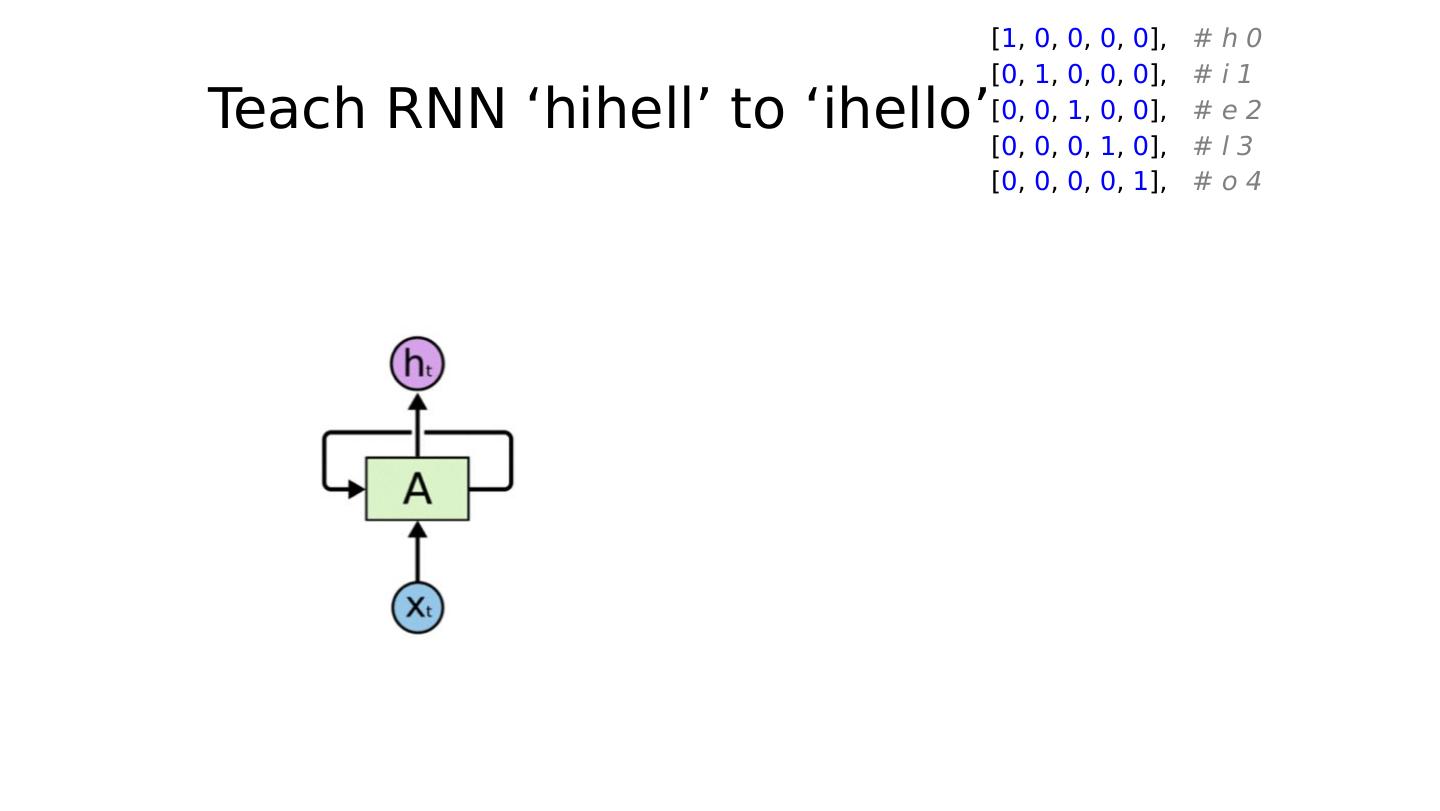
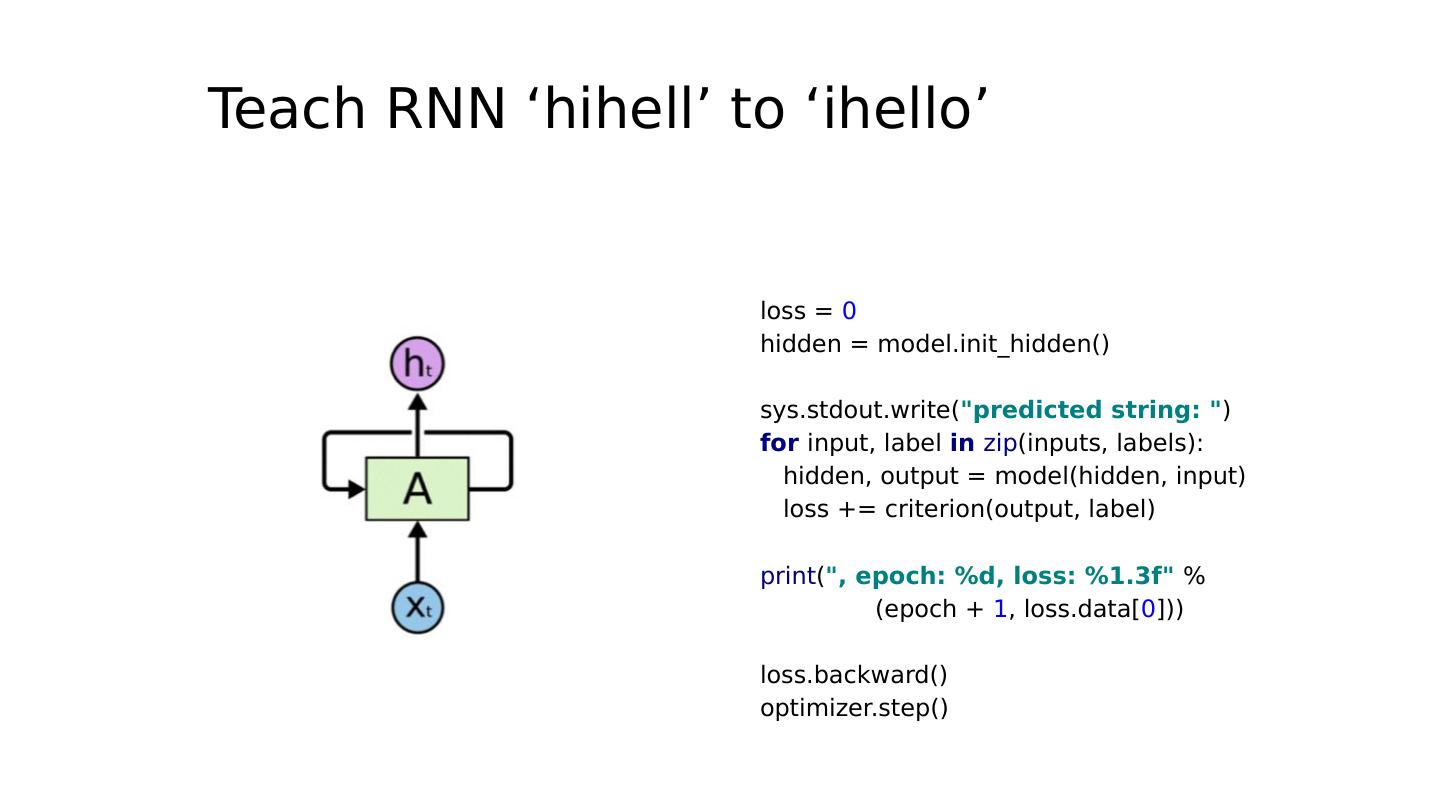
28 .Teach RNN ‘hihell’ to ‘ihello’ loss = 0 hidden = model.init_hidden() sys.stdout.write( "predicted string: " ) for input, label in zip (inputs, labels): hidden, output = model(hidden, input) loss += criterion(output, label) print ( ", epoch: %d, loss: %1.3f" % (epoch + 1 , loss.data[ 0 ])) loss.backward() optimizer.step()
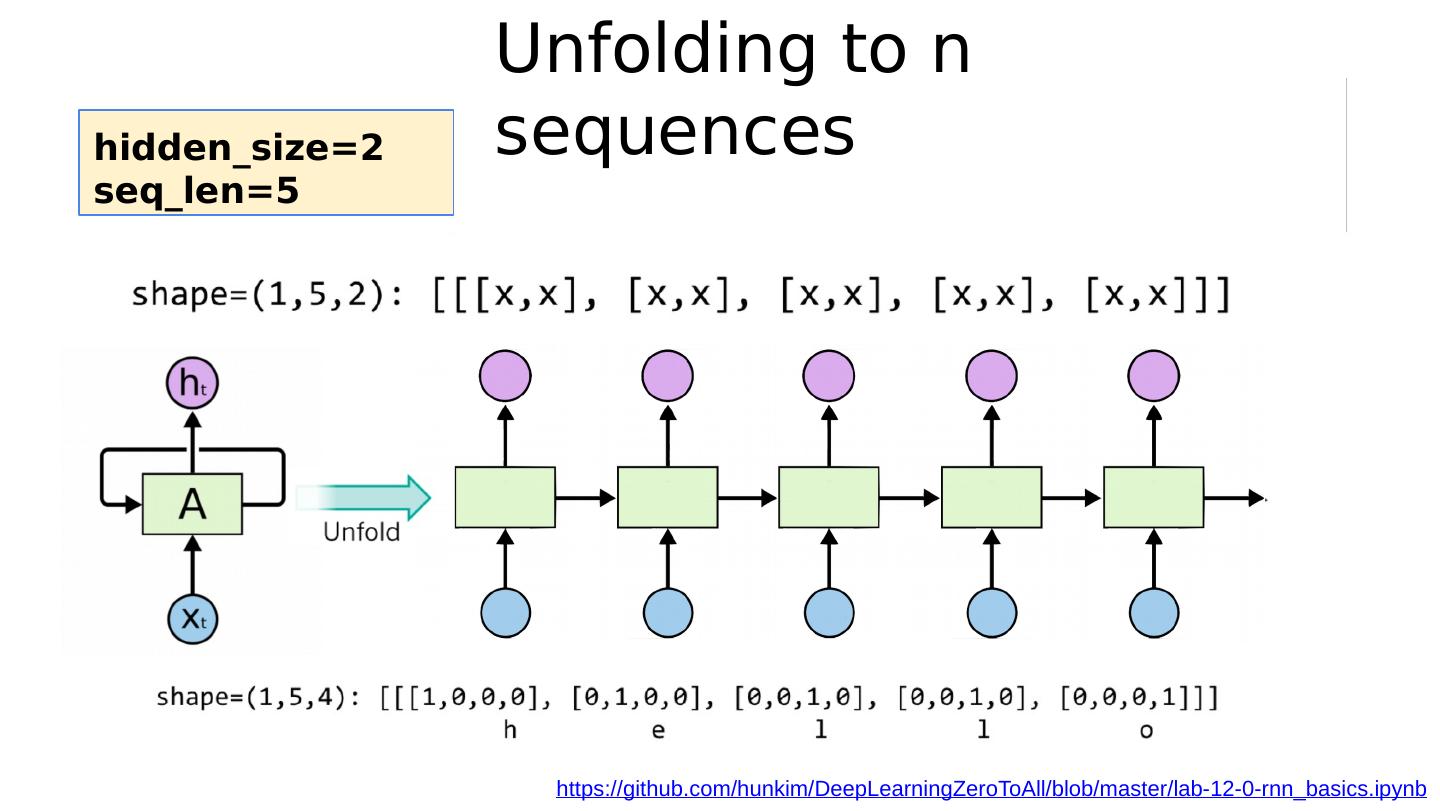
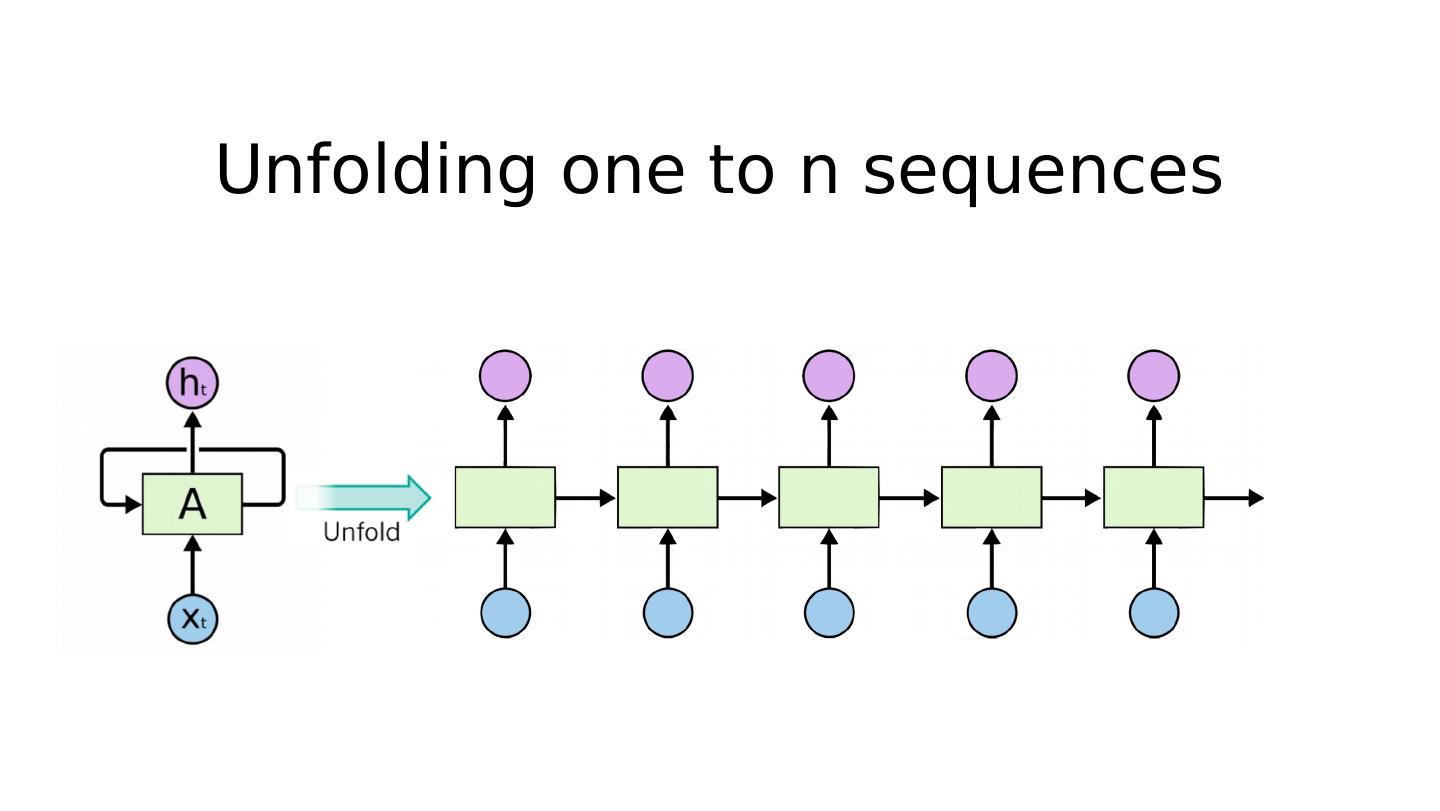
29 .Unfolding to n sequences https://github.com/hunkim/DeepLearningZeroToAll/blob/master/lab-12-0-rnn_basics.ipynb h idden_size=2 seq_len=5