08_ DataLoader
分享
点赞
9
收藏
3
下载 0
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
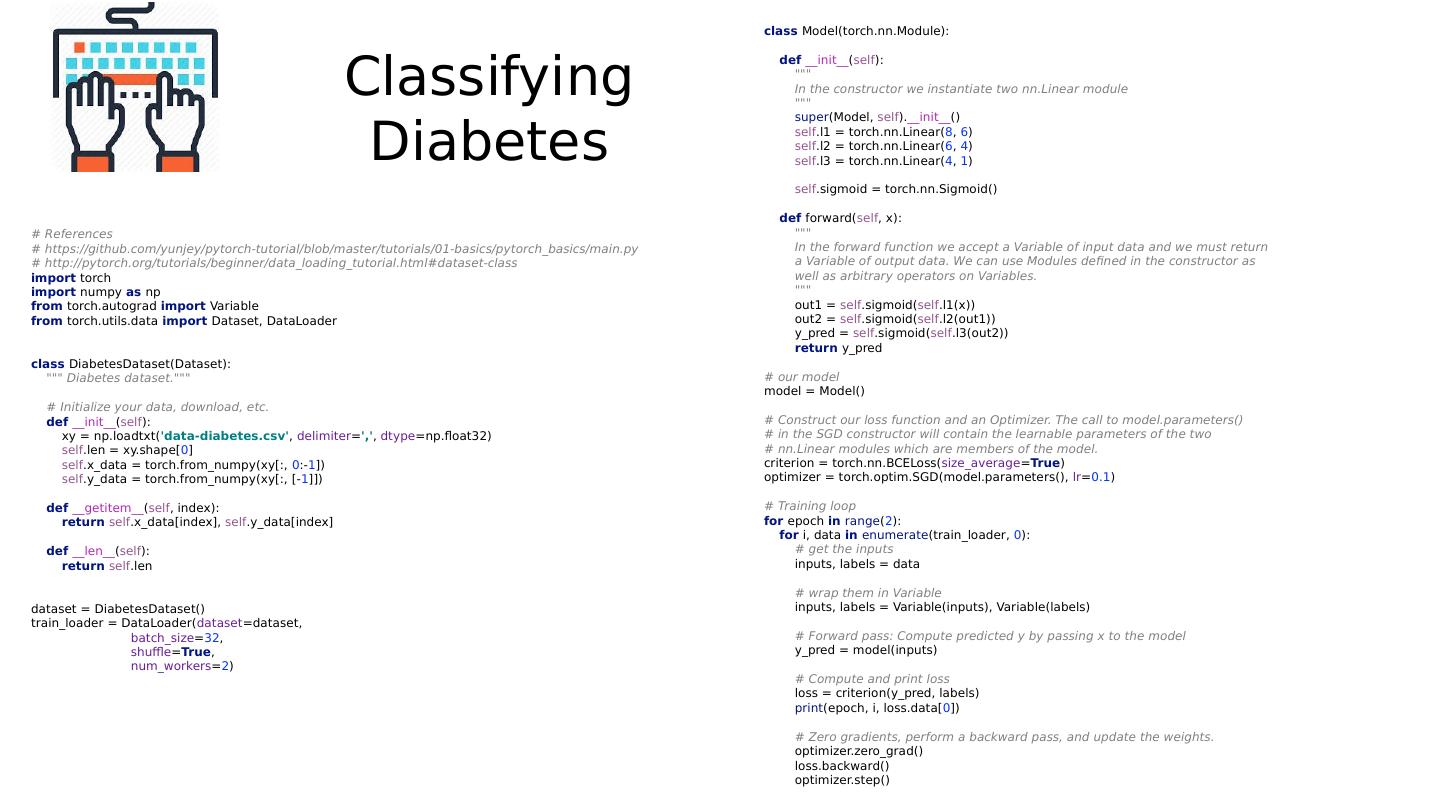
dataset = DiabetesDataset()
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
# Training loop
for epoch in range(2):
for i, data in enumerate(train_loader, 0):
# get the inputs
inputs, labels = data
# wrap them in Variable
inputs, labels = Variable(inputs), Variable(labels)
# Forward pass: Compute predicted y by passing x to the model
y_pred = model(inputs)
# Compute and print loss
loss = criterion(y_pred, labels)
print(epoch, i, loss.data[0])
# Zero gradients, perform a backward pass, and update the weights.
optimizer.zero_grad()
loss.backward()
optimizer.step()
展开查看详情
7 .ML/DL for Everyone with Lecture 8: DataLoader Sung Kim < hunkim+ml@gmail.com > HKUST Code: https://github.com/hunkim/PyTorchZeroToAll Slides: http://bit.ly/PyTorchZeroAll Videos: http://bit.ly/PyTorchVideo
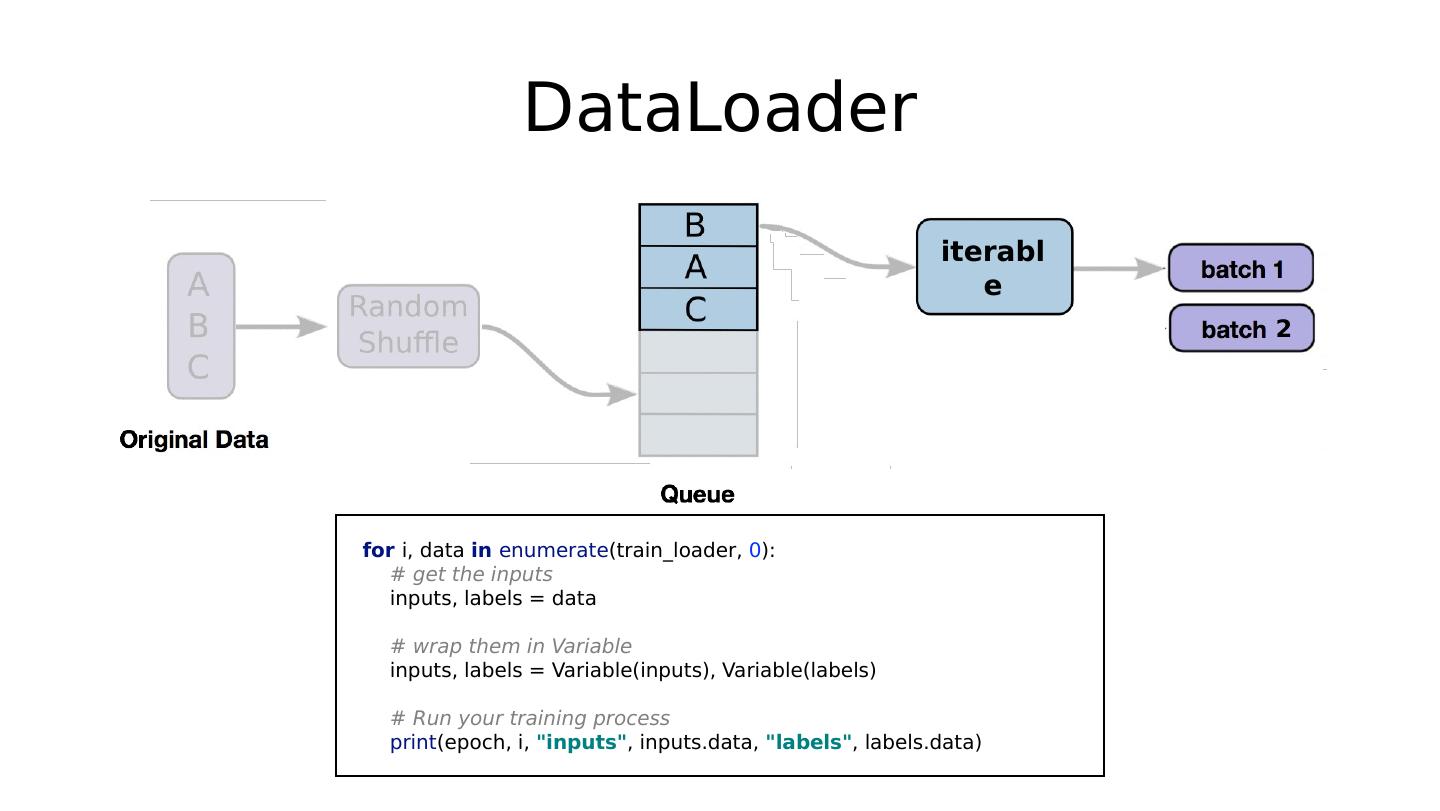
8 .Batch (batch size) # Training cycle for epoch in range (training_epochs): # Loop over all batches for i in range (total_batch): batch_xs, batch_ys = … https://stackoverflow.com/questions/4752626
9 .Exercise 8-1: Check out existing data sets (torch.vision) Build DataLoader for Titanic dataset: https://www.kaggle.com/c/titanic/download/train.csv Build a classifier using the DataLoader
10 .Custom DataLoader class DiabetesDataset(Dataset): """ Diabetes dataset.""" # Initialize your data, download, etc. def __init__ ( self ): xy = np.loadtxt( data-diabetes.csv , delimiter = , , dtype =np.float32) self .len = xy.shape[ 0 ] self .x_data = torch.from_numpy(xy[:, 0 :- 1 ]) self .y_data = torch.from_numpy(xy[:, [- 1 ]]) def __getitem__ ( self , index): return self .x_data[index], self .y_data[index] def __len__ ( self ): return self .len dataset = DiabetesDataset() train_loader = DataLoader( dataset =dataset, batch_size = 32 , shuffle = True , num_workers = 2 )
11 .The following dataset loaders are available MNIST and FashionMNIST COCO (Captioning and Detection) LSUN Classification ImageFolder Imagenet-12 CIFAR10 and CIFAR100 STL10 SVHN PhotoTour