1 .
2 .
3 .
4 .
5 .
6 .
7 .
8 .
9 .
10 .
11 .
12 .
13 .
14 .
15 .
16 .Exercise 4-5: compute gradients using PyTorch
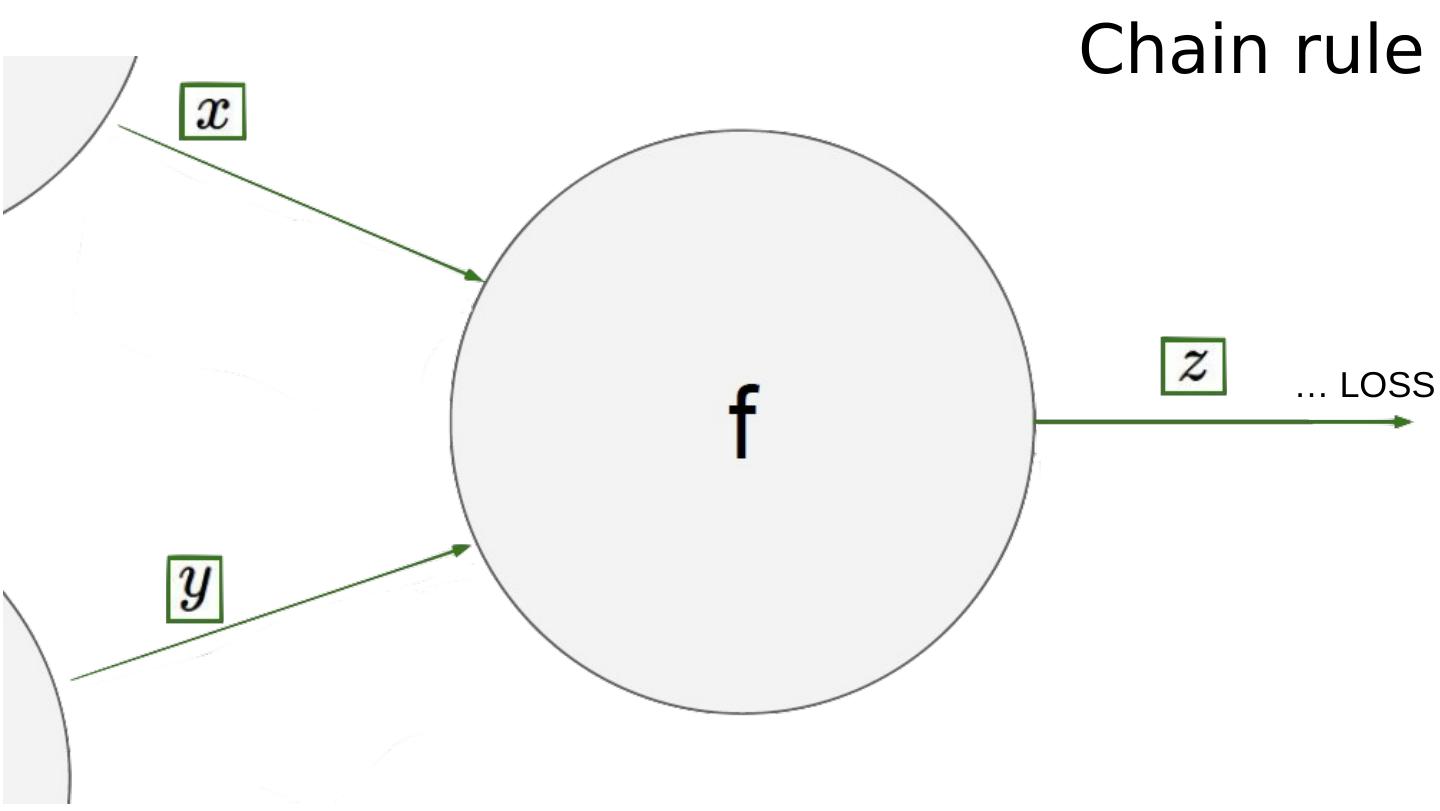
17 .Chain rule
18 .Chain rule
19 .ML/DL for Everyone with Sung Kim < hunkim+ml@gmail.com > HKUST Code: https://github.com/hunkim/PyTorchZeroToAll Slides: http://bit.ly/PyTorchZeroAll Videos: http://bit.ly/PyTorchVideo Lecture 4: Back-propagation & Autograd
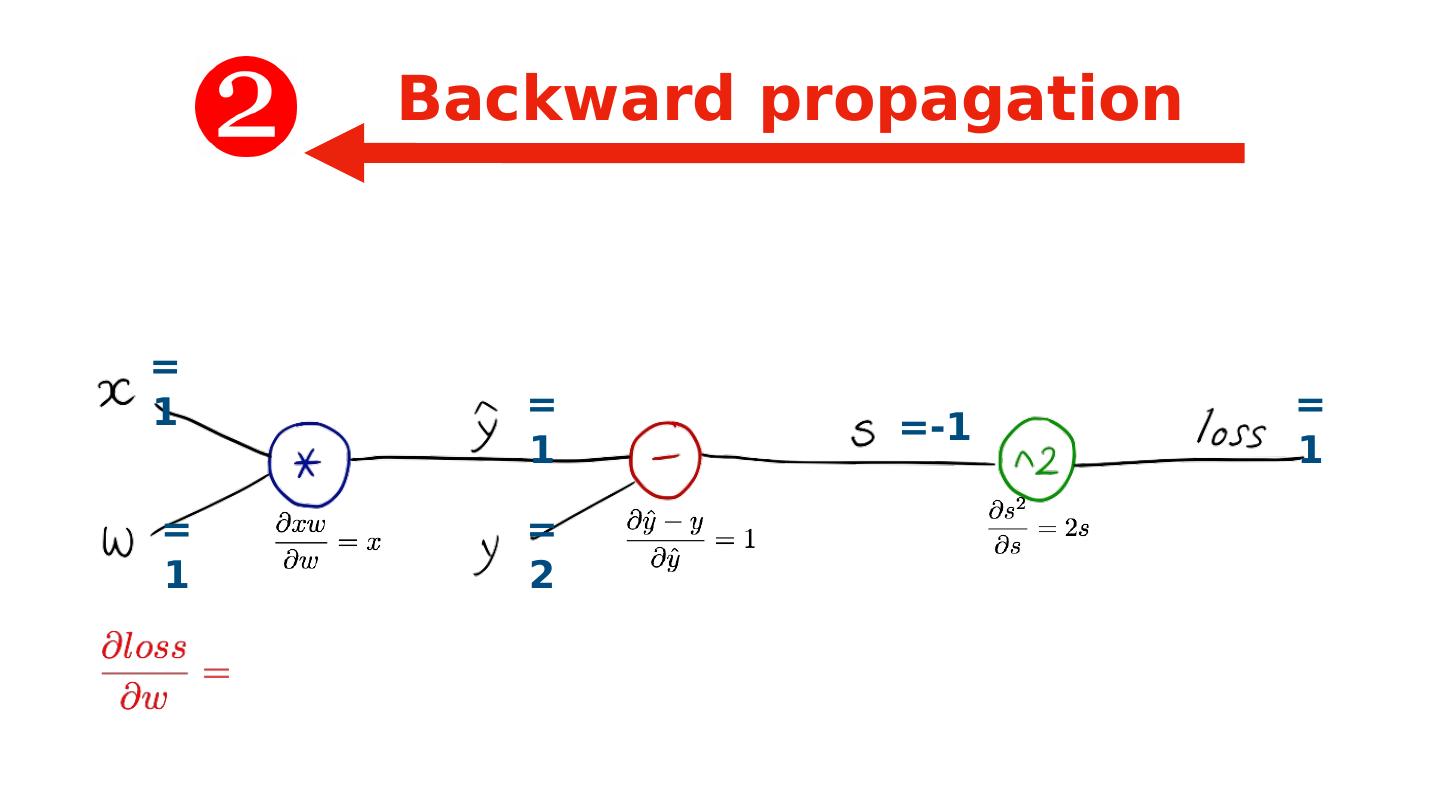
20 .=1 =1 =1 =2 =-1 =1 Backward propagation
21 .Better way? Computational graph + chain rule
22 .= 2 = 3 = 6 *
23 .PyTorch forward/backward
24 .Computational graph
25 .Output # Training loop for epoch in range ( 10 ): for x_val, y_val in zip (x_data, y_data): l = loss(x_val, y_val) l.backward() print ( " grad: " , x_val, y_val, w.grad.data[ 0 ]) w.data = w.data - 0.01 * w.grad.data # Manually zero the gradients after updating weights w.grad.data.zero_() print ( "progress:" , epoch, l.data[ 0 ]) # After training print ( "predict (after training)" , 4 , forward( 4 ).data[ 0 ])
26 .Data and Variable http://pytorch.org/docs/master/notes/autograd.html?highlight=variable
27 .=2 =1 =2 =4 =-2 =4 Weight update (step) w.data = w.data - 0.01 * w.grad.data w.grad
28 .= 2 = 3 = 6 * = y = x = 5 = 5*x = 10 = 5*y = 15 Backward propagation = 5 is given.
29 .Exercise 4-1: x = 2, y=4, w=1 =2 =1 =2 =4 =-2 =4
确定删除吗?