






















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Unsupervised Learning: Word Embedding
Word Embedding
• Machine learns the meaning of words from reading a lot of documents without supervision
• A word can be understood by its context
展开查看详情
1 .Unsupervised Learning: Word Embedding 1
2 .Word Embedding • Machine learns the meaning of words from reading a lot of documents without supervision Word Embedding tree flower dog rabbit run jump cat
3 . 1-of-N Encoding Word Embedding apple = [ 1 0 0 0 0] dog bag = [ 0 1 0 0 0] rabbit run cat = [ 0 0 1 0 0] jump cat dog = [ 0 0 0 1 0] tree flower elephant = [ 0 0 0 0 1] Word Class class 1 Class 2 Class 3 dog ran flower cat bird jumped walk tree apple
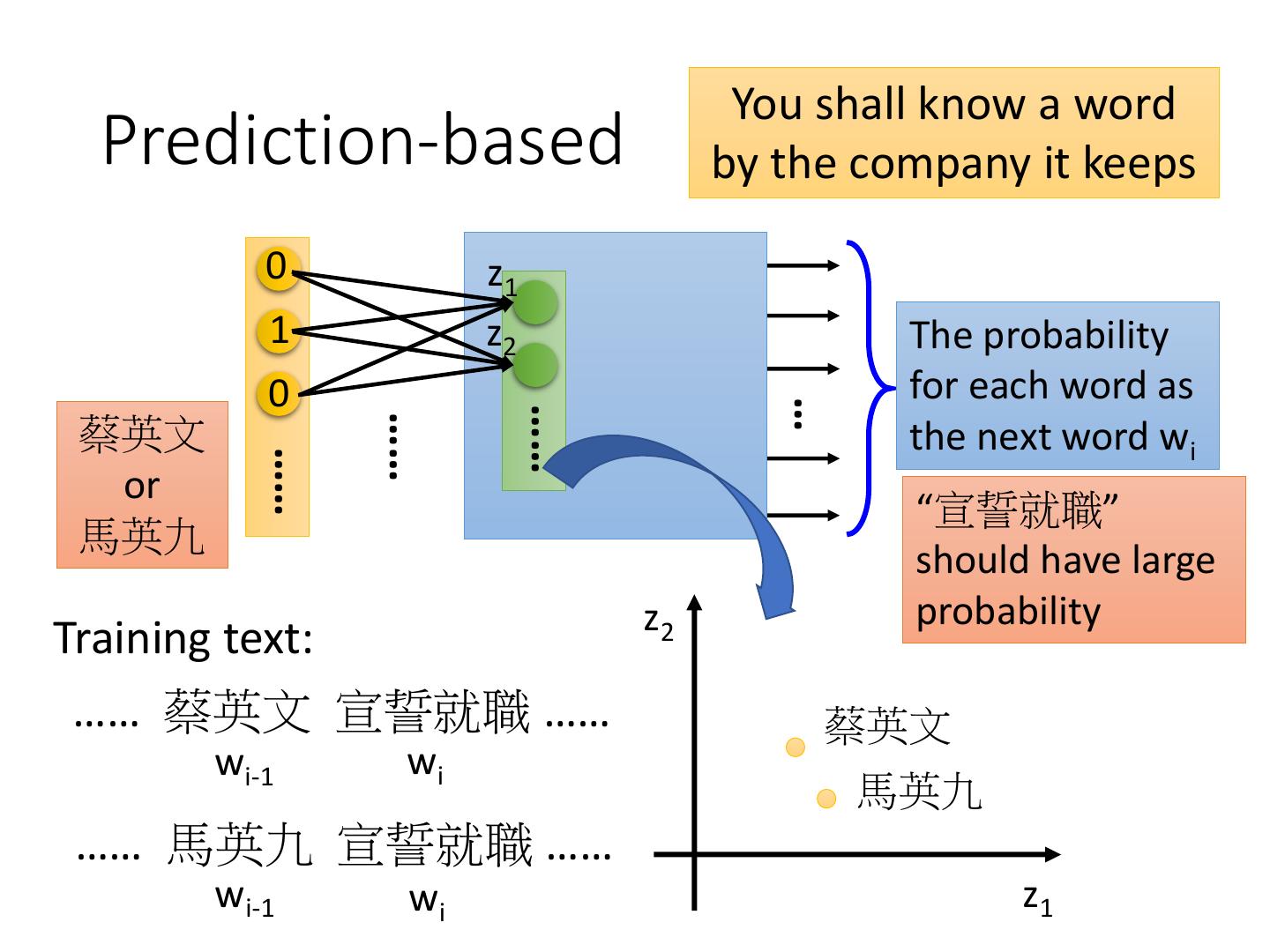
4 .Word Embedding • Machine learns the meaning of words from reading a lot of documents without supervision • A word can be understood by its context You shall know a word 蔡英文、馬英九 are by the company it keeps something very similar 馬英九 520宣誓就職 蔡英文 520宣誓就職
5 .How to exploit the context? • Count based • If two words wi and wj frequently co-occur, V(wi) and V(wj) would be close to each other • E.g. Glove Vector: http://nlp.stanford.edu/projects/glove/ V(wi) . V(wj) Ni,j Inner product Number of times wi and wj in the same document • Perdition based
6 . Prediction-based – Training 潮水 Neural 就 Collect data: Network 退了 潮水 退了 就 知道 誰 … 不爽 不要 買 … 退了 公道價 八萬 一 … Neural 知道 ……… 就 Network Minimizing 就 Neural cross entropy 誰 Network 知道
7 . Prediction-based - 推文接話 推 louisee :話說十幾年前我念公立國中時,老師也曾做過這種事,但 推 pttnowash :後來老師被我們出草了 → louisee :沒有送這麼多次,而且老師沒發通知單。另外,家長送 → pttnowash :老師上彩虹橋 血祭祖靈 https://www.ptt.cc/bbs/Teacher/M.1317226791.A.558.html 推 AO56789: 我同學才扯好不好,他有一次要交家政料理報告 → AO56789:其中一個是要寫一樣水煮料理的食譜,他居然給我寫 → linger:溫水煮青蛙 → AO56789:溫水煮青蛙,還附上完整實驗步驟,老師直接給他打0 → linger:幹還真的是溫水煮青蛙 著名簽名檔 (出處不詳)
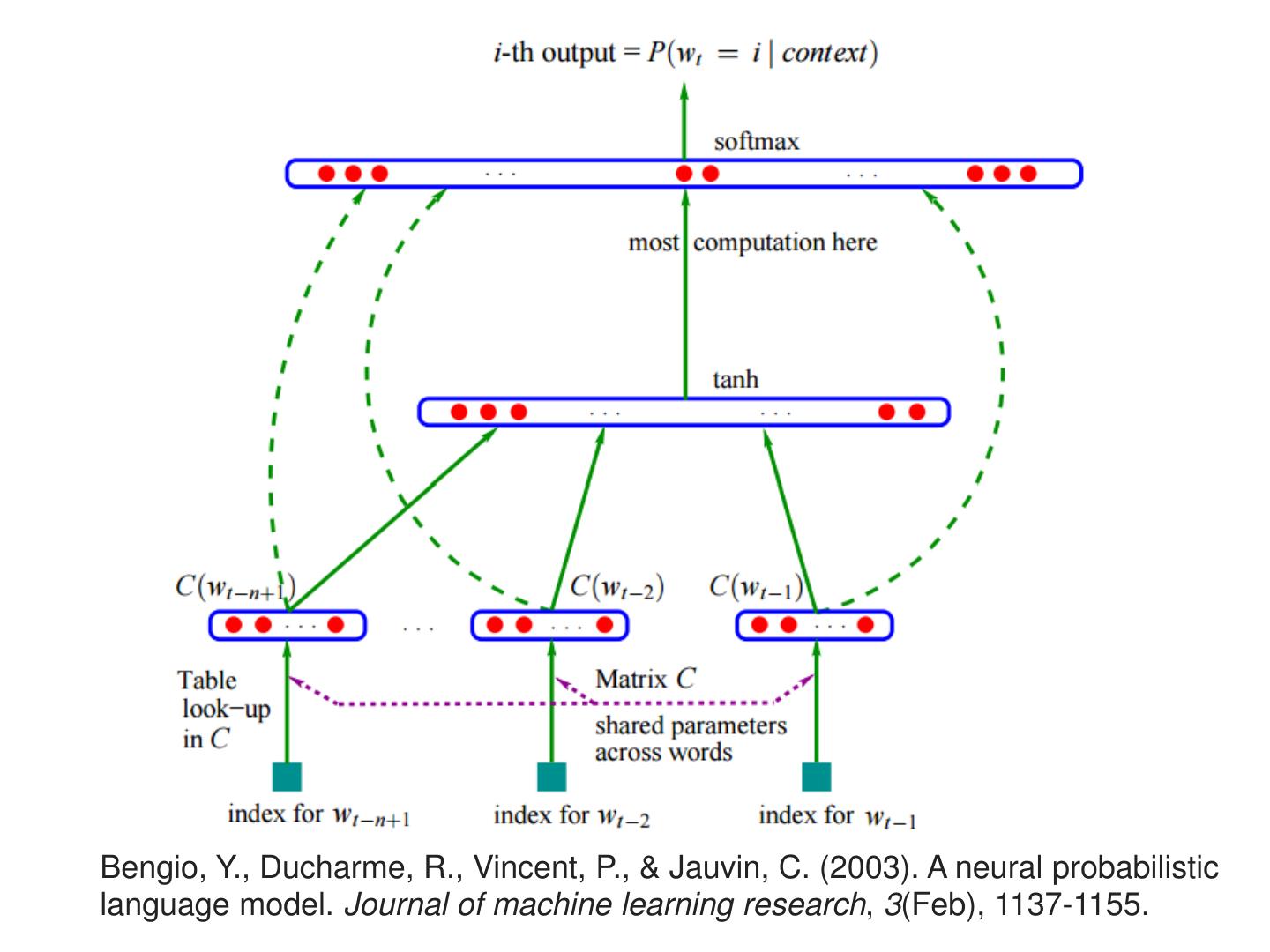
8 . Prediction-based – Language Modeling P(“wreck a nice beach”) =P(wreck|START)P(a|wreck)P(nice|a)P(beach|nice) P(b|a): the probability of NN predicting the next word. P(next word is P(next word is P(next word is P(next word is “wreck”) “a”) “nice”) “beach”) Neural Neural Neural Neural Network Network Network Network 1-of-N encoding 1-of-N encoding 1-of-N encoding 1-of-N encoding of “START” of “wreck” of “a” of “nice”
9 .Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003). A neural probabilistic language model. Journal of machine learning research, 3(Feb), 1137-1155.
10 . wi …… wi-2 wi-1 ___ Prediction-based 0 z1 1-of-N 1 z2 The probability encoding 0 for each word as of the … …… …… the next word wi word wi-1 …… ➢ Take out the input of the z2 tree neurons in the first layer flower ➢ Use it to represent a dog rabbit run word w jump cat ➢ Word vector, word embedding feature: V(w) z1
11 . You shall know a word Prediction-based by the company it keeps 0 z1 1 z2 The probability 0 for each word as … …… …… 蔡英文 the next word wi …… or “宣誓就職” 馬英九 should have large z2 probability Training text: …… 蔡英文 宣誓就職 …… 蔡英文 wi-1 wi 馬英九 …… 馬英九 宣誓就職 …… wi-1 wi z1
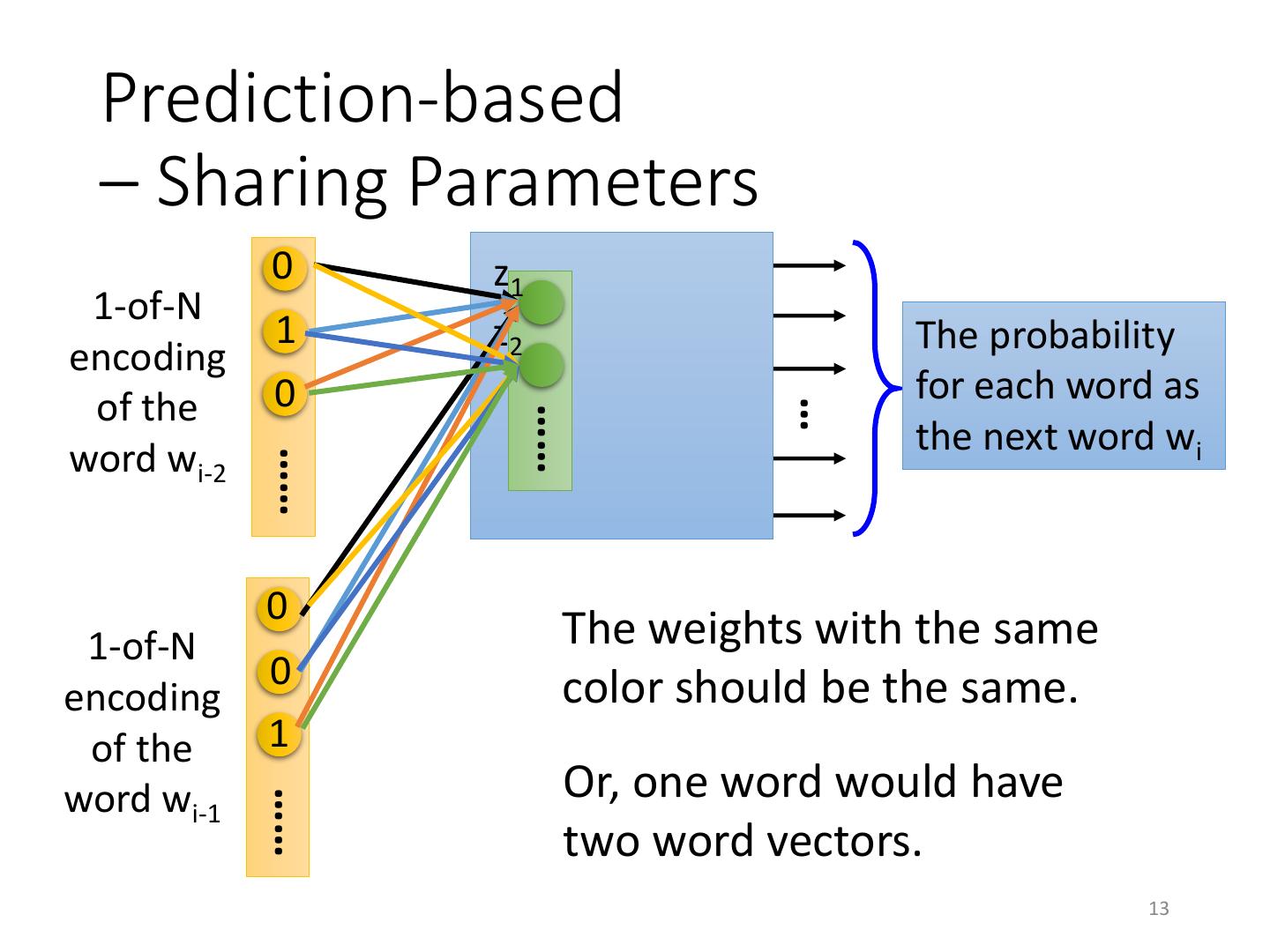
12 . Prediction-based – Sharing Parameters 0 z1 1-of-N 1 W1 z2 The probability encoding 0 for each word as of the … …… the next word wi word wi-2 …… z xi-2 0 The length of xi-1 and xi-2 are both |V|. 1-of-N W2 The length of z is |Z|. 1 encoding z = W1 xi-2 + W2 xi-1 of the 0 The weight matrix W1 and W2 are both word wi-1 …… |Z|X|V| matrices. xi-1 W1 = W2 = W z = W ( xi-2 + xi-1 ) 12
13 . Prediction-based – Sharing Parameters 0 z1 1-of-N 1 z2 The probability encoding 0 for each word as of the … …… the next word wi word wi-2 …… 0 1-of-N The weights with the same 0 color should be the same. encoding of the 1 word wi-1 Or, one word would have …… two word vectors. 13
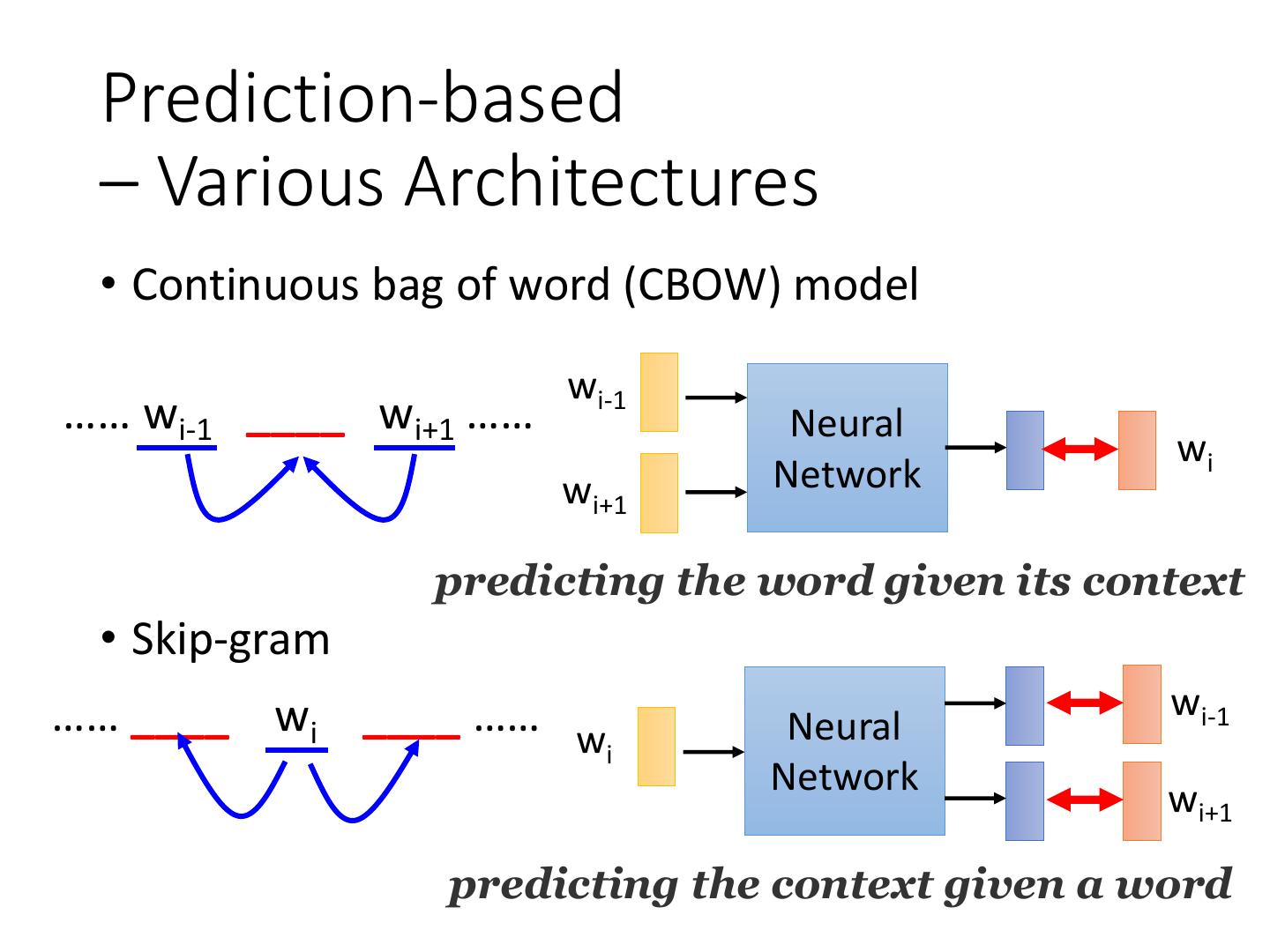
14 . Prediction-based – Various Architectures • Continuous bag of word (CBOW) model wi-1 …… wi-1 ____ wi+1 …… Neural wi wi+1 Network predicting the word given its context • Skip-gram …… ____ wi ____ …… w wi-1 Neural i Network wi+1 predicting the context given a word
15 .Word Embedding Source: http://www.slideshare.net/hustwj/cikm-keynotenov2014 15
16 . Word Embedding Fu, Ruiji, et al. "Learning semantic hierarchies via word embeddings."Proceedings of the 52th Annual Meeting of the Association for Computational Linguistics: Long Papers. Vol. 1. 2014. 16
17 .Word Embedding 𝑉 𝐺𝑒𝑟𝑚𝑎𝑛𝑦 • Characteristics ≈ 𝑉 𝐵𝑒𝑟𝑙𝑖𝑛 − 𝑉 𝑅𝑜𝑚𝑒 + 𝑉 𝐼𝑡𝑎𝑙𝑦 𝑉 ℎ𝑜𝑡𝑡𝑒𝑟 − 𝑉 ℎ𝑜𝑡 ≈ 𝑉 𝑏𝑖𝑔𝑔𝑒𝑟 − 𝑉 𝑏𝑖𝑔 𝑉 𝑅𝑜𝑚𝑒 − 𝑉 𝐼𝑡𝑎𝑙𝑦 ≈ 𝑉 𝐵𝑒𝑟𝑙𝑖𝑛 − 𝑉 𝐺𝑒𝑟𝑚𝑎𝑛𝑦 𝑉 𝑘𝑖𝑛𝑔 − 𝑉 𝑞𝑢𝑒𝑒𝑛 ≈ 𝑉 𝑢𝑛𝑐𝑙𝑒 − 𝑉 𝑎𝑢𝑛𝑡 • Solving analogies Rome : Italy = Berlin : ? Compute 𝑉 𝐵𝑒𝑟𝑙𝑖𝑛 − 𝑉 𝑅𝑜𝑚𝑒 + 𝑉 𝐼𝑡𝑎𝑙𝑦 Find the word w with the closest V(w) 17
18 .Demo • Machine learns the meaning of words from reading a lot of documents without supervision
19 .Demo • Model used in demo is provided by 陳仰德 • Part of the project done by 陳仰德、林資偉 • TA: 劉元銘 • Training data is from PTT (collected by 葉青峰) 19
20 .Multi-lingual Embedding Bilingual Word Embeddings for Phrase-Based Machine Translation, Will Zou, Richard Socher, Daniel Cer and Christopher Manning, EMNLP, 2013
21 .Document Embedding • word sequences with different lengths → the vector with the same length • The vector representing the meaning of the word sequence • A word sequence can be a document or a paragraph word sequence … (a document or paragraph) 21
22 .Semantic Embedding Reference: Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. "Reducing the dimensionality of data with neural networks." Science 313.5786 Bag-of-word (2006): 504-507
23 . Beyond Bag of Word • To understand the meaning of a word sequence, the order of the words can not be ignored. white blood cells destroying an infection positive different exactly the same bag-of-word meaning an infection destroying white blood cells negative 23
24 .Beyond Bag of Word • Paragraph Vector: Le, Quoc, and Tomas Mikolov. "Distributed Representations of Sentences and Documents.“ ICML, 2014 • Seq2seq Auto-encoder: Li, Jiwei, Minh-Thang Luong, and Dan Jurafsky. "A hierarchical neural autoencoder for paragraphs and documents." arXiv preprint, 2015 • Skip Thought: Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard S. Zemel, Antonio Torralba, Raquel Urtasun, Sanja Fidler, “Skip-Thought Vectors” arXiv preprint, 2015.
3秒后跳转登录页面
去登陆

