展开查看详情
1 . “Hello world”
of deep learning
�
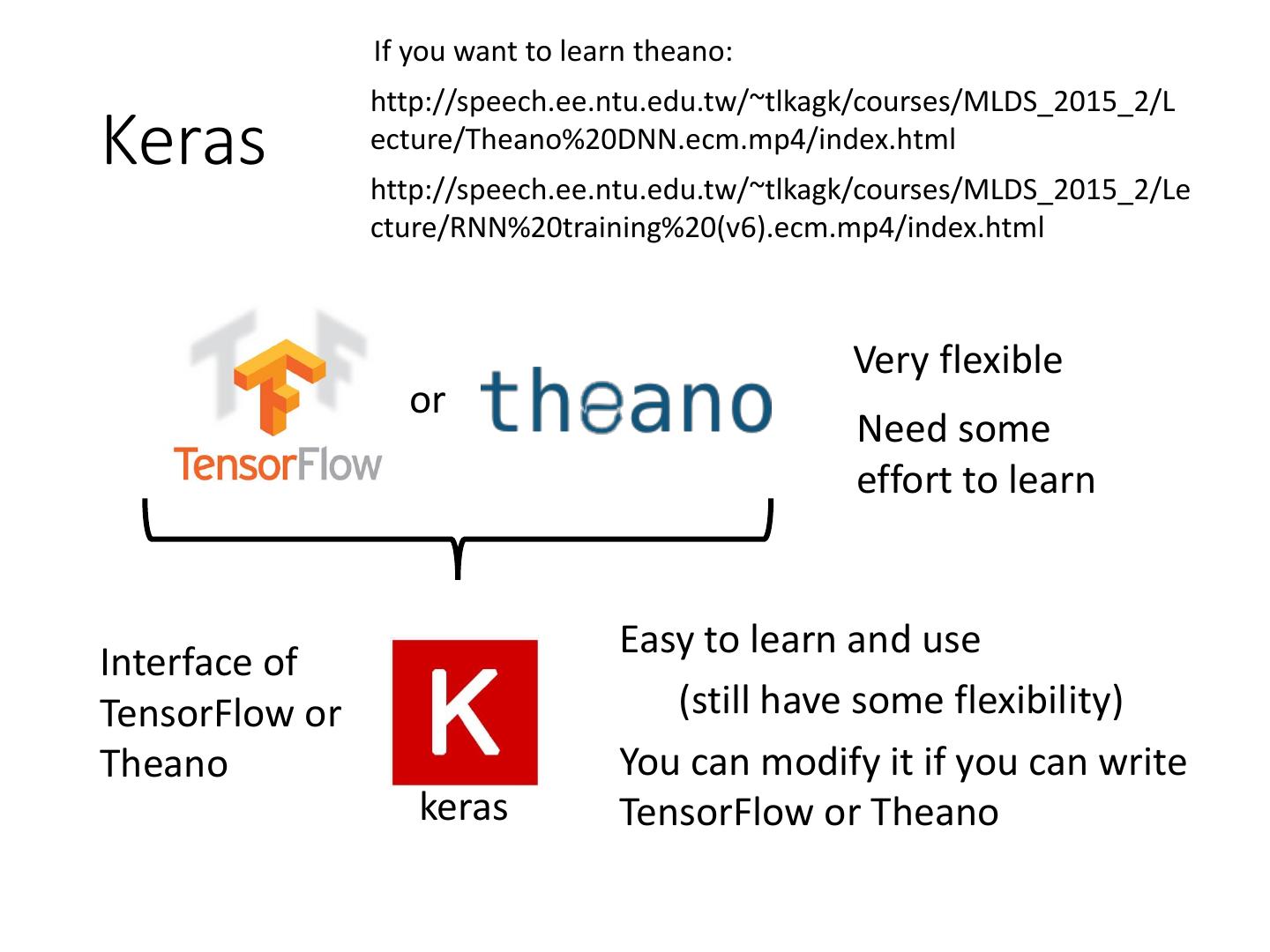
2 . If you want to learn theano:
http://speech.ee.ntu.edu.tw/~tlkagk/courses/MLDS_2015_2/L
Keras ecture/Theano%20DNN.ecm.mp4/index.html
http://speech.ee.ntu.edu.tw/~tlkagk/courses/MLDS_2015_2/Le
cture/RNN%20training%20(v6).ecm.mp4/index.html
Very flexible
or
Need some
effort to learn
Easy to learn and use
Interface of
TensorFlow or (still have some flexibility)
Theano You can modify it if you can write
keras TensorFlow or Theano
�
3 .Keras
• François Chollet is the author of Keras.
• He currently works for Google as a deep learning
engineer and researcher.
• Keras means horn in Greek
• Documentation: http://keras.io/
• Example:
https://github.com/fchollet/keras/tree/master/exa
mples
�
4 . 感謝 沈昇勳 同學提供圖檔
使用 Keras 心得
�
5 . “Hello world”
• Handwriting Digit Recognition
Machine “1”
28 x 28
MNIST Data: http://yann.lecun.com/exdb/mnist/
Keras provides data sets loading function: http://keras.io/datasets/
�
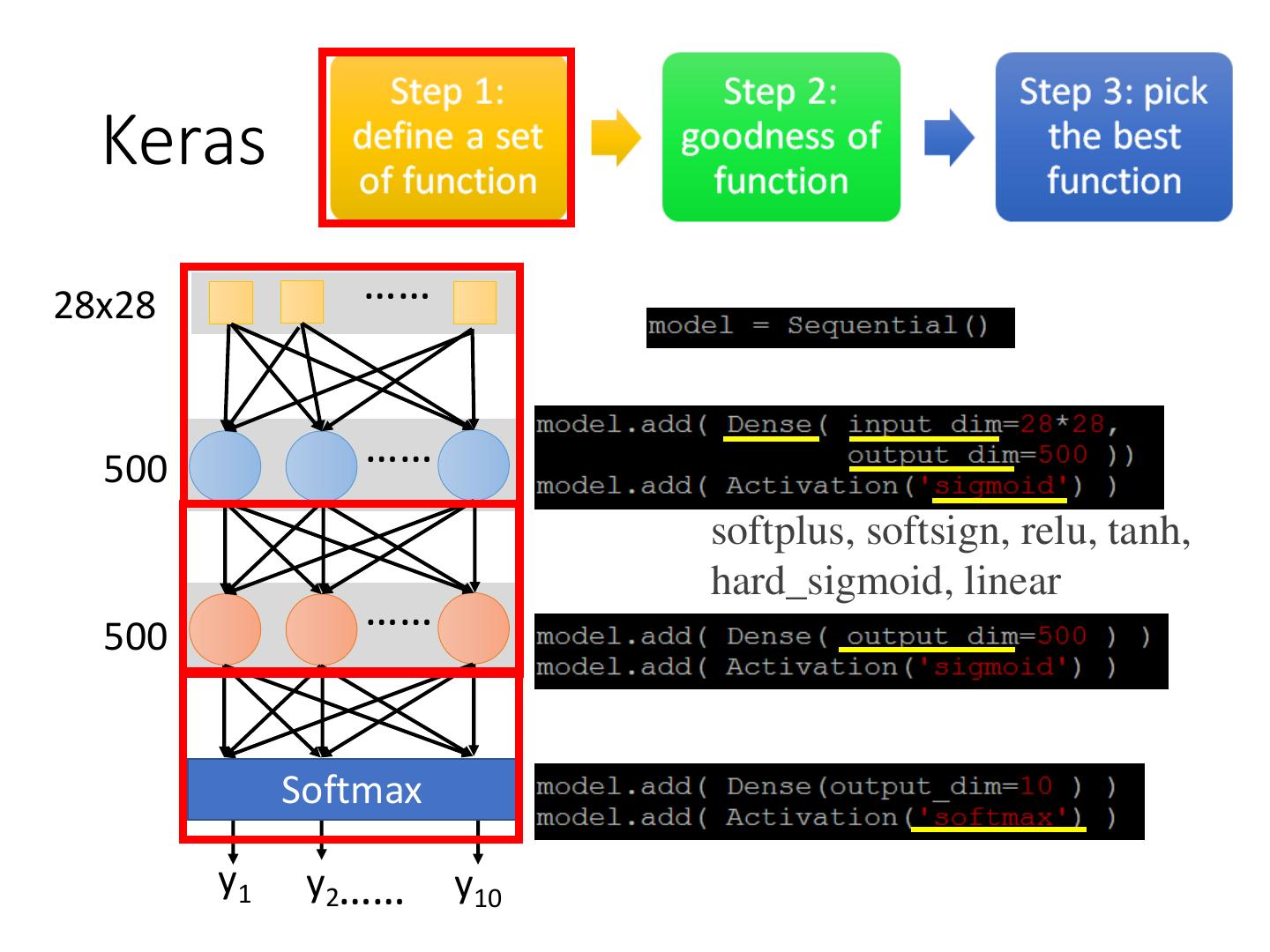
6 . Keras
……
28x28
……
500
softplus, softsign, relu, tanh,
hard_sigmoid, linear
……
500
Softmax
y1 y2
…… y10
�
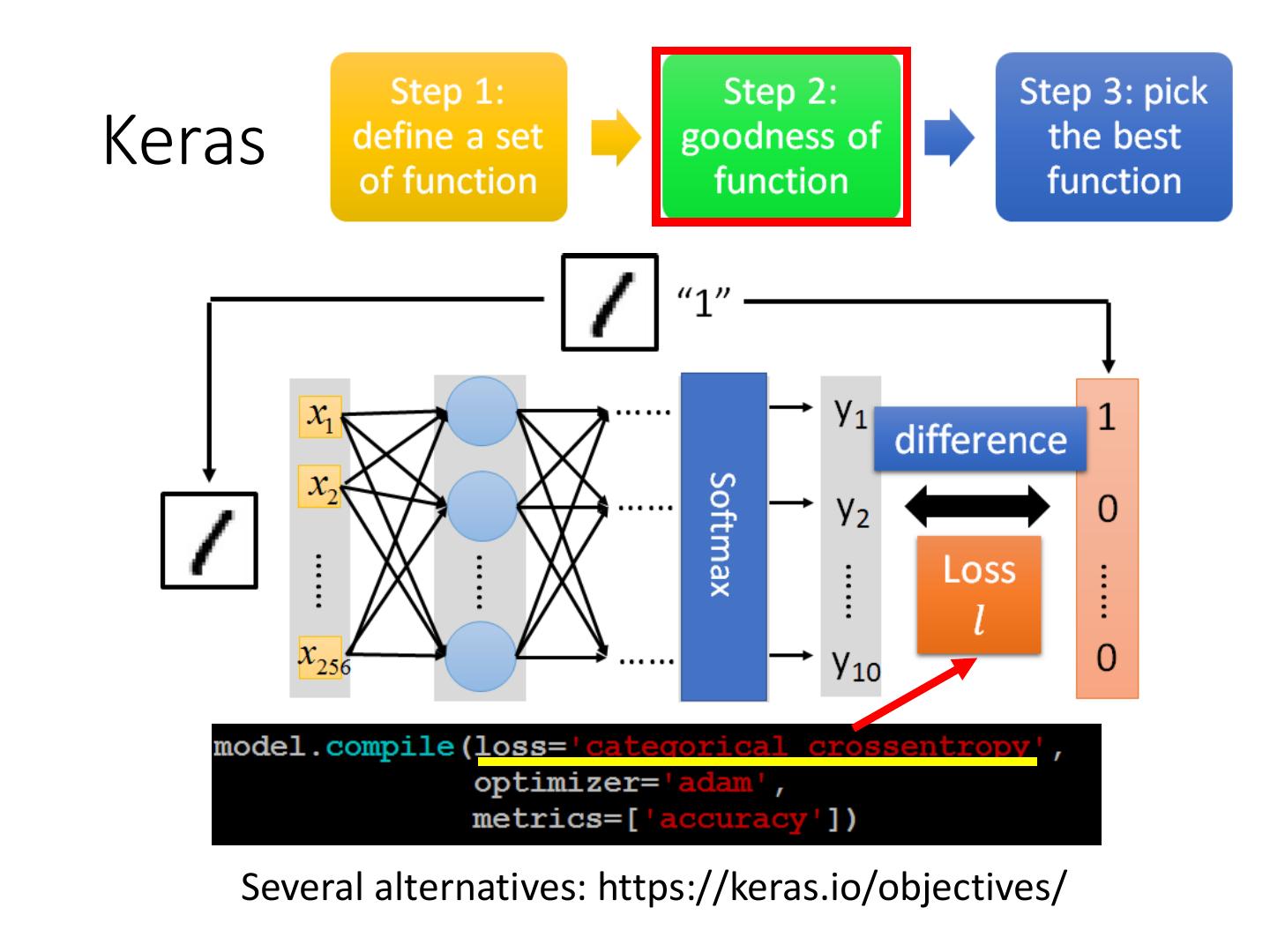
7 .Keras
Several alternatives: https://keras.io/objectives/
�
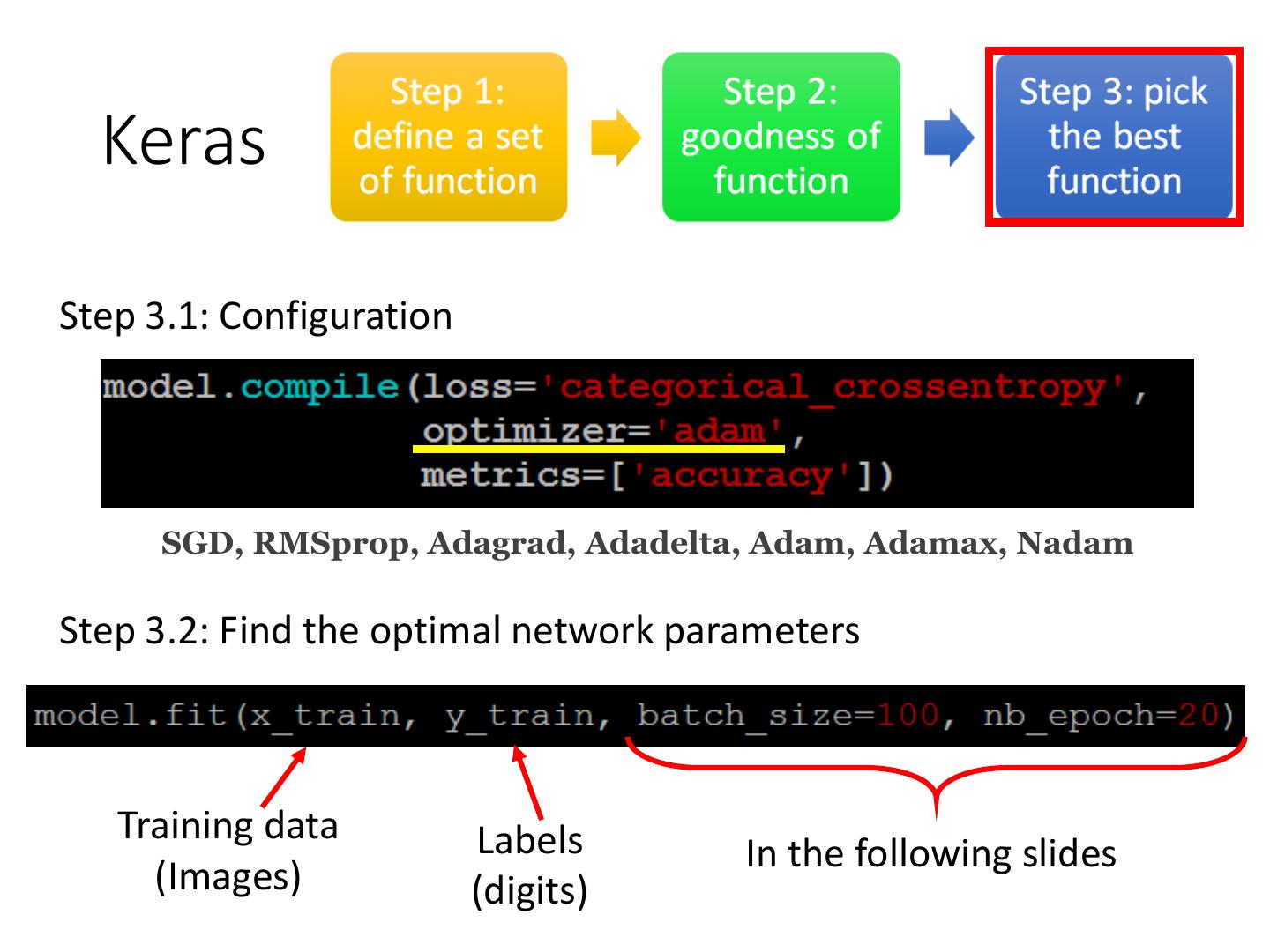
8 . Keras
Step 3.1: Configuration
SGD, RMSprop, Adagrad, Adadelta, Adam, Adamax, Nadam
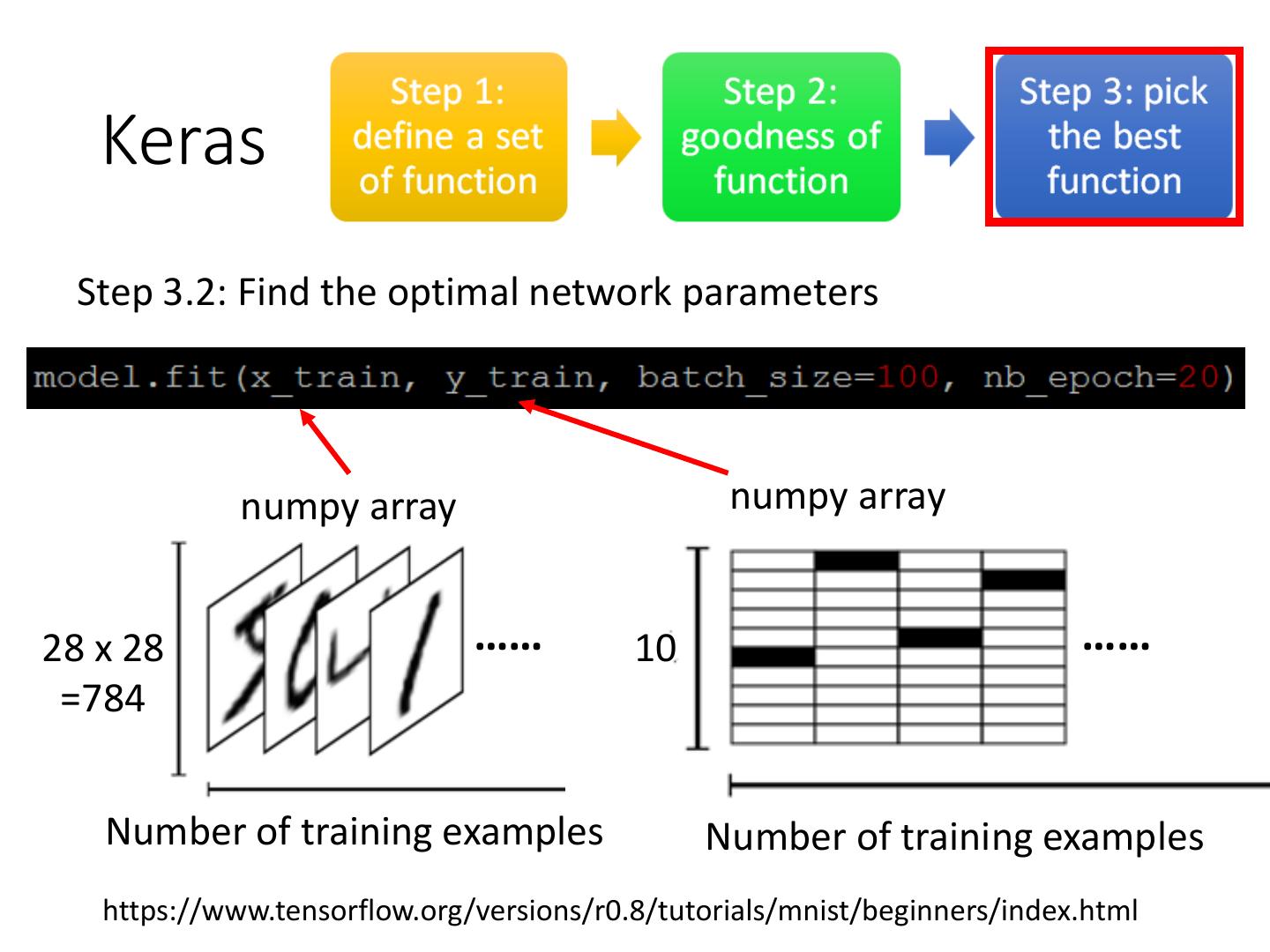
Step 3.2: Find the optimal network parameters
Training data Labels In the following slides
(Images) (digits)
�
9 . Keras
Step 3.2: Find the optimal network parameters
numpy array numpy array
28 x 28 …… 10 ……
=784
Number of training examples Number of training examples
https://www.tensorflow.org/versions/r0.8/tutorials/mnist/beginners/index.html
�
10 . We do not really minimize total loss!
Mini-batch ➢ Randomly initialize
network parameters
x1 NN y1 𝑦ො 1 ➢ Pick the 1st batch
Mini-batch
𝑙1 𝐿′ = 𝑙1 + 𝑙31 + ⋯
x31 NN y31 𝑦ො 31 Update parameters once
𝑙31 ➢ Pick the 2nd batch
……
𝐿′′ = 𝑙2 + 𝑙16 + ⋯
Update parameters once
x2 NN y2 𝑦ො 2
Mini-batch
…
𝑙2 ➢ Until all mini-batches
have been picked
x16 NN y16 𝑦ො 16
𝑙16 one epoch
……
Repeat the above process
�
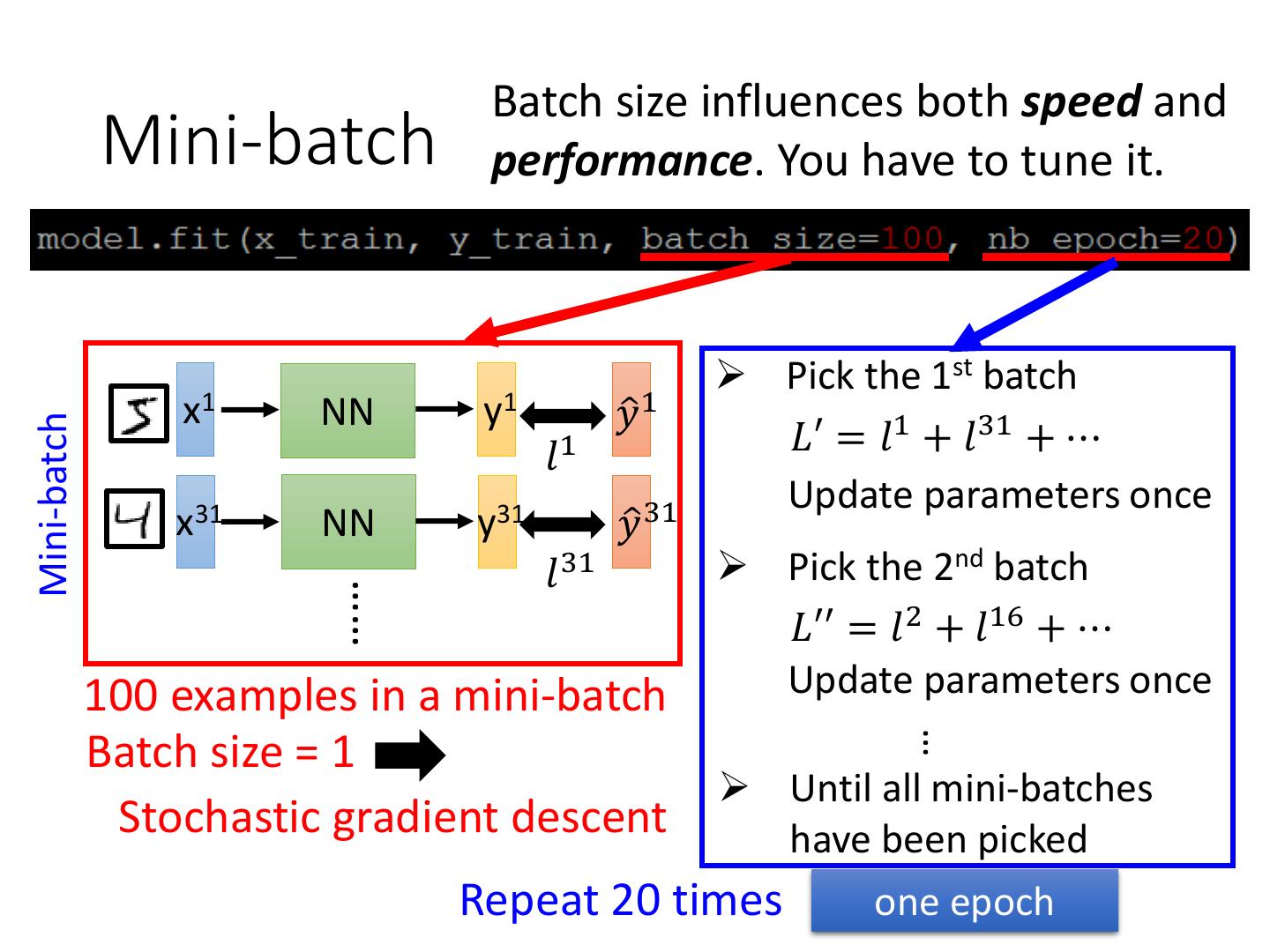
11 . Batch size influences both speed and
Mini-batch performance. You have to tune it.
➢ Pick the 1st batch
x1 NN y1 𝑦ො 1
𝐿′ = 𝑙1 + 𝑙31 + ⋯
Mini-batch
𝑙1
Update parameters once
x31 NN y31 𝑦ො 31
𝑙31 ➢ Pick the 2nd batch
……
𝐿′′ = 𝑙2 + 𝑙16 + ⋯
100 examples in a mini-batch Update parameters once
…
Batch size = 1
➢ Until all mini-batches
Stochastic gradient descent have been picked
Repeat 20 times one epoch
�
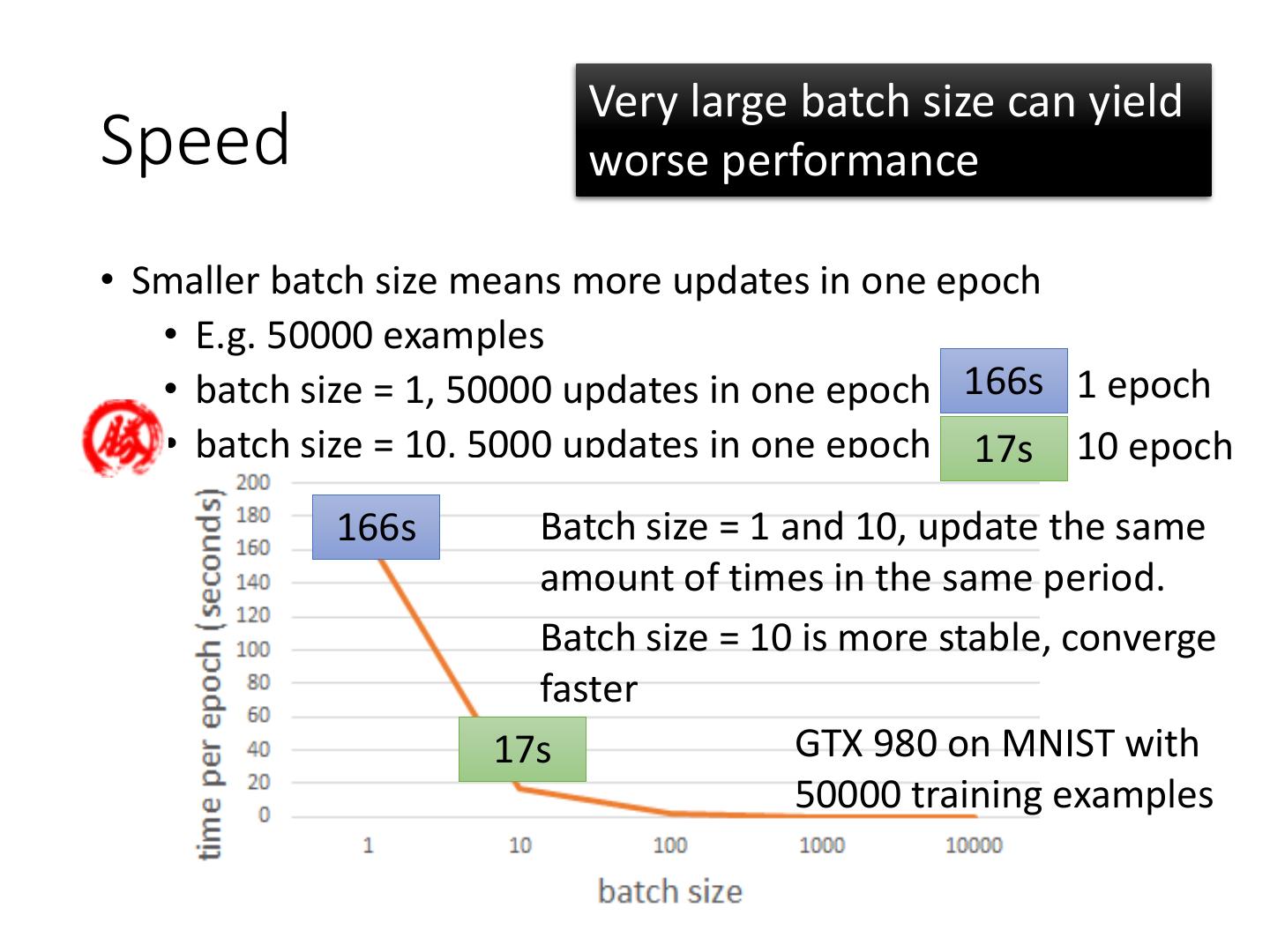
12 . Very large batch size can yield
Speed worse performance
• Smaller batch size means more updates in one epoch
• E.g. 50000 examples
• batch size = 1, 50000 updates in one epoch 166s 1 epoch
• batch size = 10, 5000 updates in one epoch 17s 10 epoch
166s Batch size = 1 and 10, update the same
amount of times in the same period.
Batch size = 10 is more stable, converge
faster
17s GTX 980 on MNIST with
50000 training examples
�
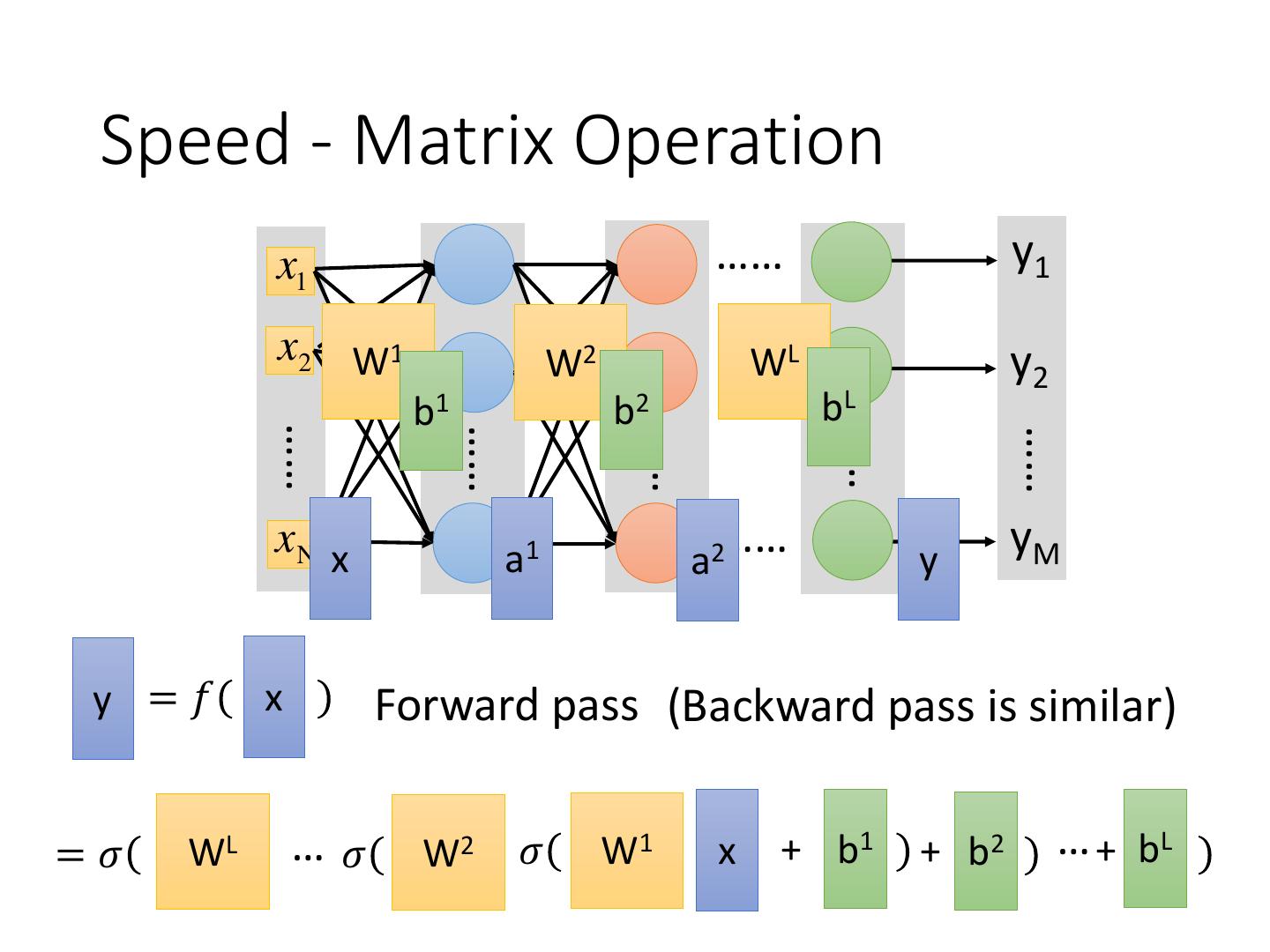
13 . Speed - Matrix Operation
x1 …… y1
x2 W1 W2 ……
WL y2
b1 b2 bL
……
……
……
……
……
xN x a1 ……
a2 y yM
y =𝑓 x Forward pass (Backward pass is similar)
=𝜎 WL …𝜎 W2 𝜎 W1 x + b1 + b2 … + bL
�
14 .Speed - Matrix Operation
• Why mini-batch is faster than stochastic gradient
descent?
Stochastic Gradient Descent
𝑧1 = 𝑊1 𝑥 𝑧1 = 𝑊1 𝑥 ……
Mini-batch
matrix
Practically, which
𝑧1 𝑧1 = 𝑊1 𝑥 𝑥
one is faster?
�
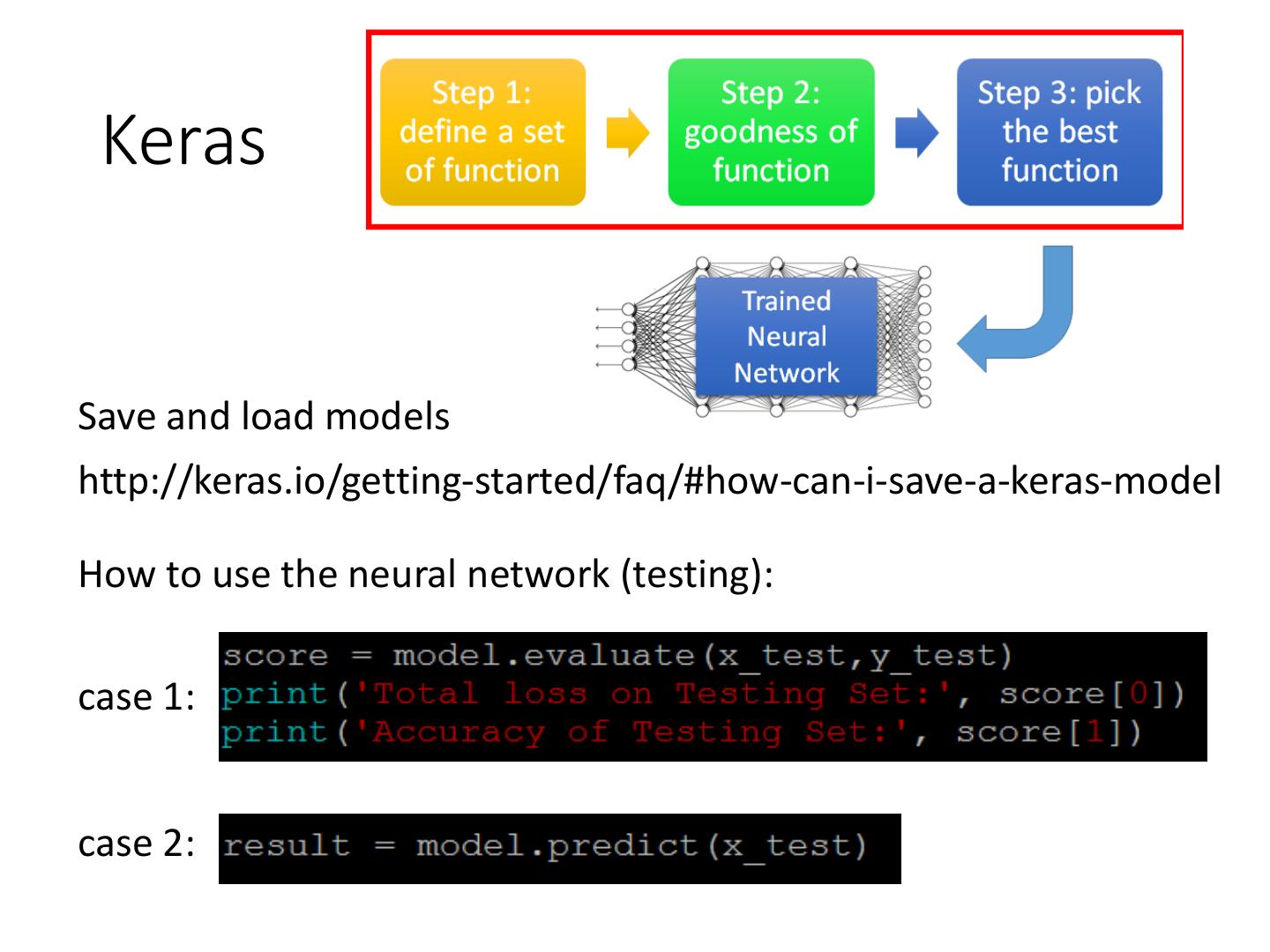
15 . Keras
Save and load models
http://keras.io/getting-started/faq/#how-can-i-save-a-keras-model
How to use the neural network (testing):
case 1:
case 2:
�
16 .Keras
• Using GPU to speed training
• Way 1
• THEANO_FLAGS=device=gpu0 python
YourCode.py
• Way 2 (in your code)
• import os
• os.environ["THEANO_FLAGS"] =
"device=gpu0"
�