展开查看详情
1 .Recurrent Neural Networks Introduction to memory cells Gene Olafsen
2 .overview Recurrent Neural Networks (RNN)are a class of neural networks that can predict the future... The idea behind RNNs is to make use of sequential information. In a traditional neural network it is assumed that all inputs (and outputs) are independent of each other. But for many tasks that approach is not best. If you want to predict the next word in a sentence you better know which words came before it. RNNs are called recurrent because they perform the same task for every element of a sequence, with the output being depended on the previous computations. For certain sequential machine learning tasks, such as speech recognition, RNNs are reaching levels of predictive accuracy, that no other algorithm can match.
3 .Class of RNN problems Analyze time series data- stock prices Anticipate trajectories- autonomous driving Natural language processing- Siri, Google Voice Sentiment Analysis- document, audio input
4 .Creative tasks RNN ability to predict the next state permits a certain level of creativity Google Magenta: composes melodies https://cdn2.vox-cdn.com/uploads/chorus_asset/file/6577761/Google_-_Magenta_music_sample.0.mp3 Generate sentences "Why do what that day," replied Natasha, and wishing to himself the fact the princess, Princess Mary was easier, fed in had oftened him. Pierre aking his soul came to the packs and drove up his father-in-law women. Image Captions https://arxiv.org/pdf/1411.4555v2.pdf
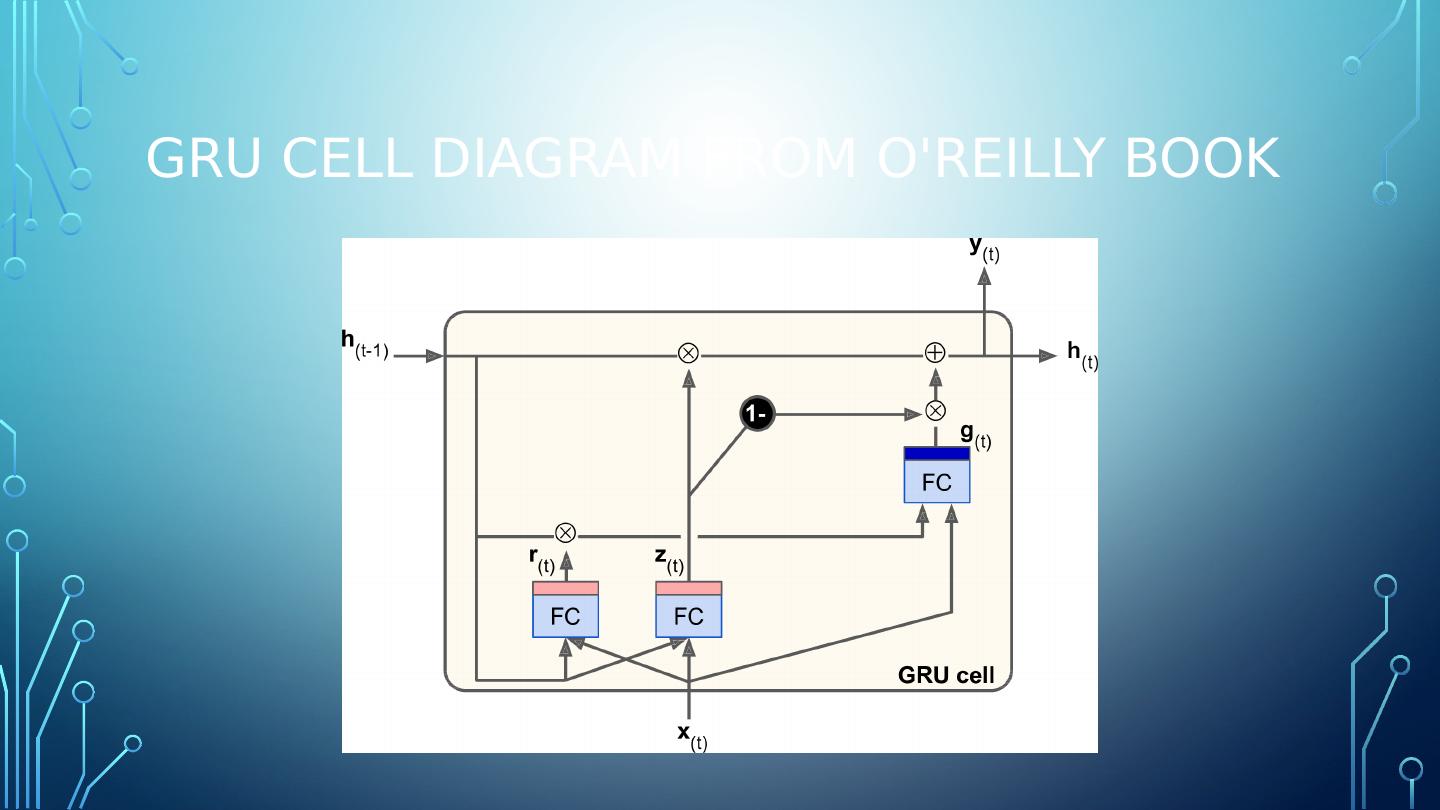
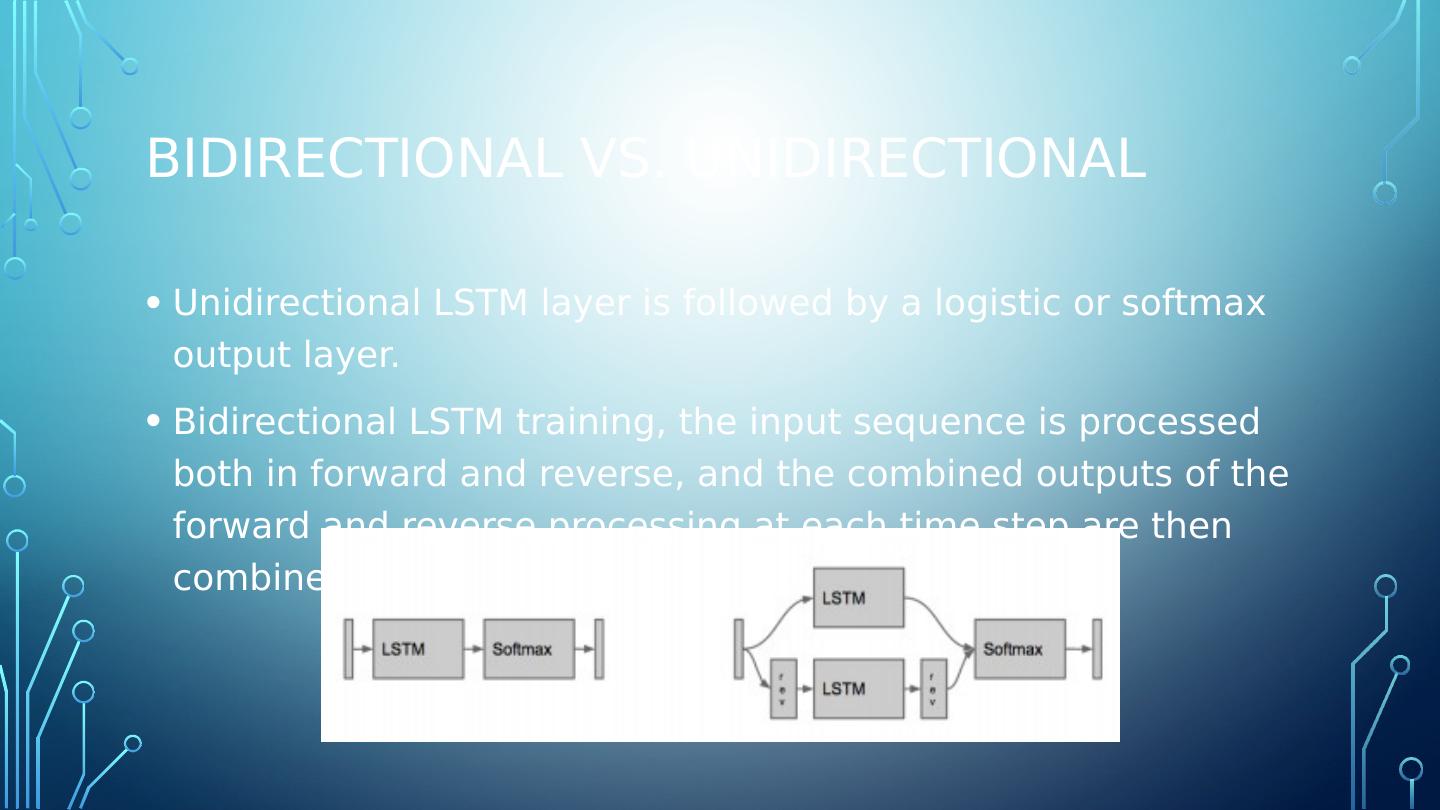
6 .RNN problems and solutions Problems faced by RNNs: Vanishing/Exploding Gradients Solutions to help alleviate these issues: LSTM (Long Short-Term Memory) GRU (Gated Recurrent Unit)
7 .Memory cell Memory Cell: That part of a neural network which preserves state across time steps .
8 .feedforward Network Review A feedforward network is the network topology that has been covered up to this point. Activations flow in one direction- from the input layer to the output layer.
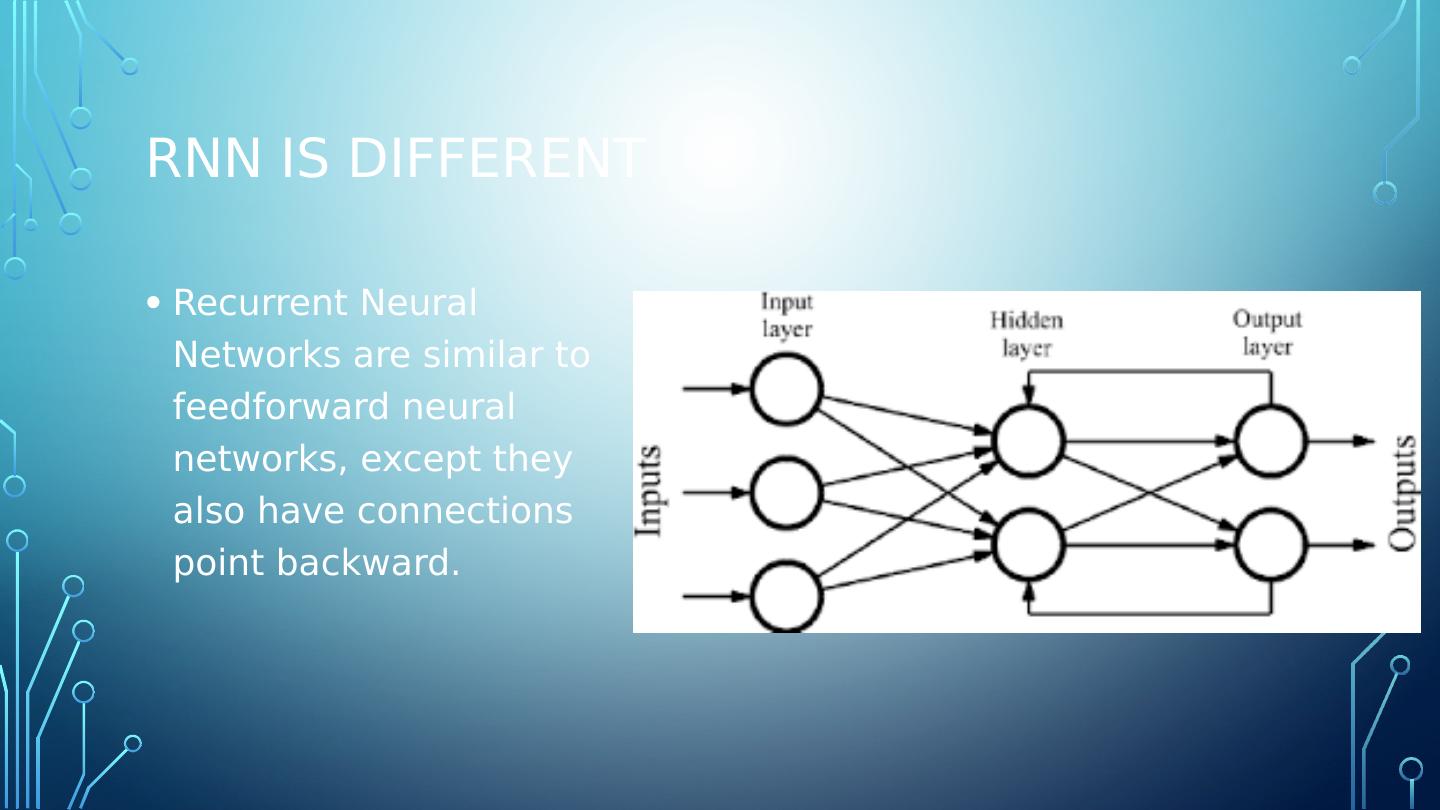
9 .RNN is Different Recurrent Neural Networks are similar to feedforward neural networks, except they also have connections point backward.
10 .Single recurrent neuron The simplest RNN contains a single neuron. The neuron receives input(s). The neuron produces an output. The output is sent back to itself. Σ X Y
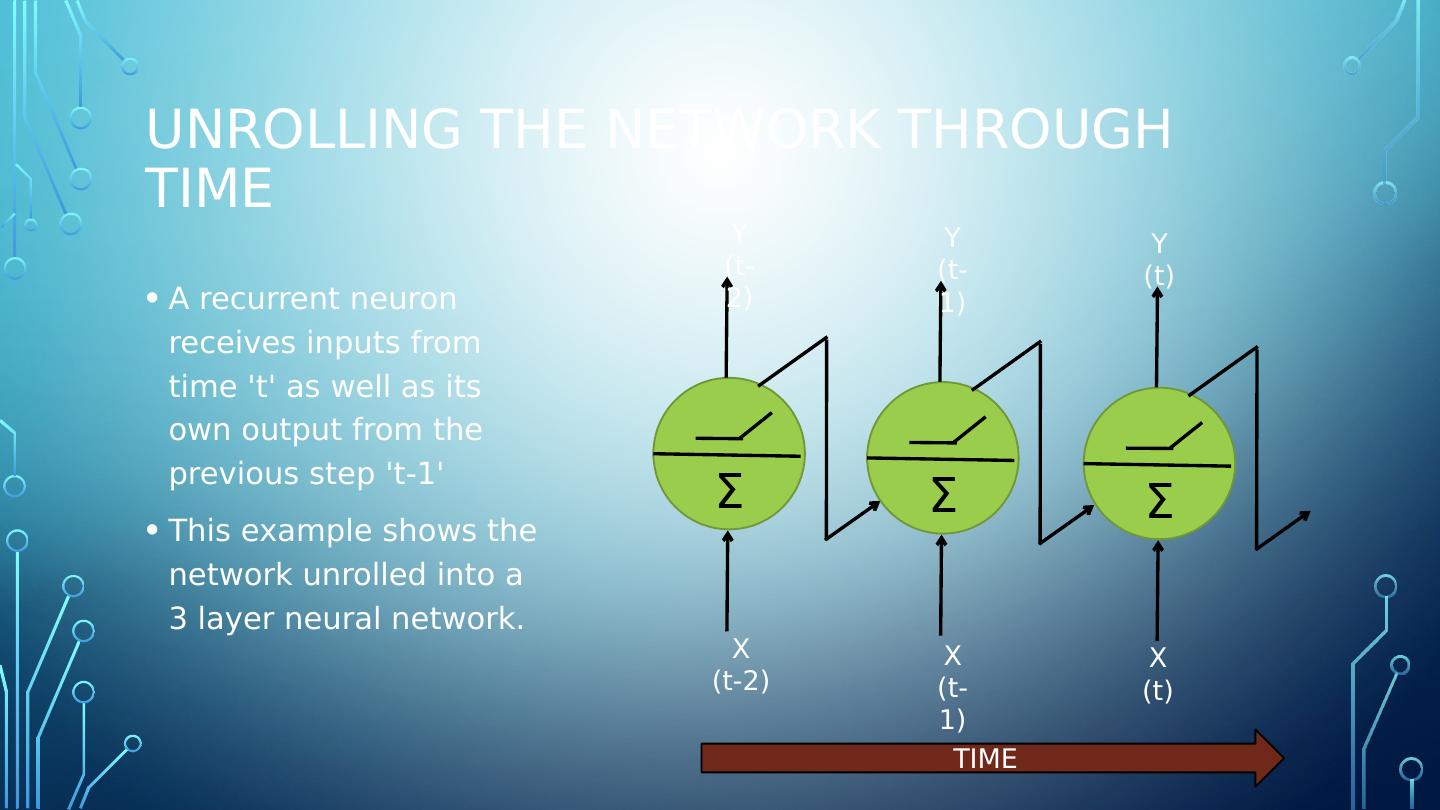
11 .Unrolling the network through time A recurrent neuron receives inputs from time t as well as its own output from the previous step t-1 This example shows the network unrolled into a 3 layer neural network. Σ X (t-2) Y (t-2) Σ X (t-1) Y (t-1) Σ X (t) Y (t) TIME
12 .RNN weights Each recurrent neuron has two set of weights: A weight for the inputs at X(t) A weight for the inputs at the previous time step X(t-1)
13 .Rnn activation function Many researchers prefer to use a (tanh) hyperbolic tangent activation function (over ReLU ) for RNNs. Refer to: "Dropout Improves Recurrent Neural Networks for Handwriting Recognition" "A Simple Way to Initialize Recurrent Networks of Rectified Linear Units"
14 .Unrolled showing variables
15 .Variables Defined X(sub)t is the input at time step t. For example, x1 could be a one-hot vector corresponding to the second word of a sentence. s(sub)t is the hidden state at time step t. It’s the “memory” of the network. Where s(sub)t is calculated based on the previous hidden state and the input at the current step. o(sub)t is the output at step t. For example, if we wanted to predict the next word in a sentence it would be a vector of probabilities across our vocabulary.
16 .Shared parameters Unlike a traditional deep neural network, which uses different parameters at each layer, a RNN shares the same parameters (U, V, W above) across all steps. This reflects the fact that we are performing the same task at each step, just with different inputs. This greatly reduces the total number of parameters needed to lean.
17 .RNN sequences Sequence to Sequence Simultaneously take a sequence of inputs and produce a sequence of outputs. Stock price prediction. Sequence to Vector (Encoder) Feed a sequence of inputs, ignore all outputs except for the last one. Sentiment analysis. (Feed movie review text, output a score) Vector to Sequence (Decoder) Feed the network a single input at the first time step and zeros for all other steps and output a sequence. Input an image, output a caption. Delayed Sequence to Sequence Link an Encoder with a Decoder. Feed an encoder a sentence in one language which converts it to a single vector. The vector is decoder would accept the vector and translate into a target language. Better than a sequence-to-sequence since the last words of the sentence can affect the first words of the translation.
18 .Tensorflow RNN Examples Hand coded RNN neuron Tf.contrib.rnn.static_rnn Tf.nn.dynamic_rnn
19 .Variable length input sequences Variable length input sequences are typical when using RNNs to process sentences. The tf.nn.dynamic_rnn method provides the sequence_length parameter to indicate length of the input sequence. Any input sequence that is shorter than the designated sequence_length must be padded with a zero vector, to fit the input tensor dimension.
20 .Variable-length output sequences When using RNNs to translate sentence, the input length variation can be zero padded as necessary; however, the translated sentence is generally different in length of the input sentence. The solution is to define a special output called an end-of-sequence token. (EOS token). Any output past the EOS token should be ignored.
21 .Training Rnn The trick used to train an RNN is to unroll it through time and then apply backpropagation. First there is a forward pass through the unrolled network. Then the output sequence is evaluated using a cost function. NOTE: the gradients flow backward through all the outputs used by the cost function, not just through the final output. ALSO: the same weight and bias parameters are used at each time step.
22 .Backpropogation through time ( bptt ) The RNN trains its units by adjusting their weights following a slight modification of a feedback process known as backpropogation . Recurrent neural networks use a heavier version of this process known as backpropogation through time (BPTT). This version extends the tweaking process to include the weight of the T-1 input values responsible for each unit’s memory of the prior moment.
23 .Rnn classifier A convolution neural network (CNN) is better suited for image classification, however the Geron book provides an example using RNNs to evaluate the MNIST data set. Surprisingly RNNs produce 98% accuracy without much work.
24 .Times series predictions The most common example is predicting a stock price.
25 .Vanishing gradients When training a deep neural network, the larger the gradient, the steeper the slope, the more quickly the system can roll downhill to the finish line and arrive at an optimal solution. As gradients get smaller and smaller, and thus flatter and flatter, training times grow unbearably long.
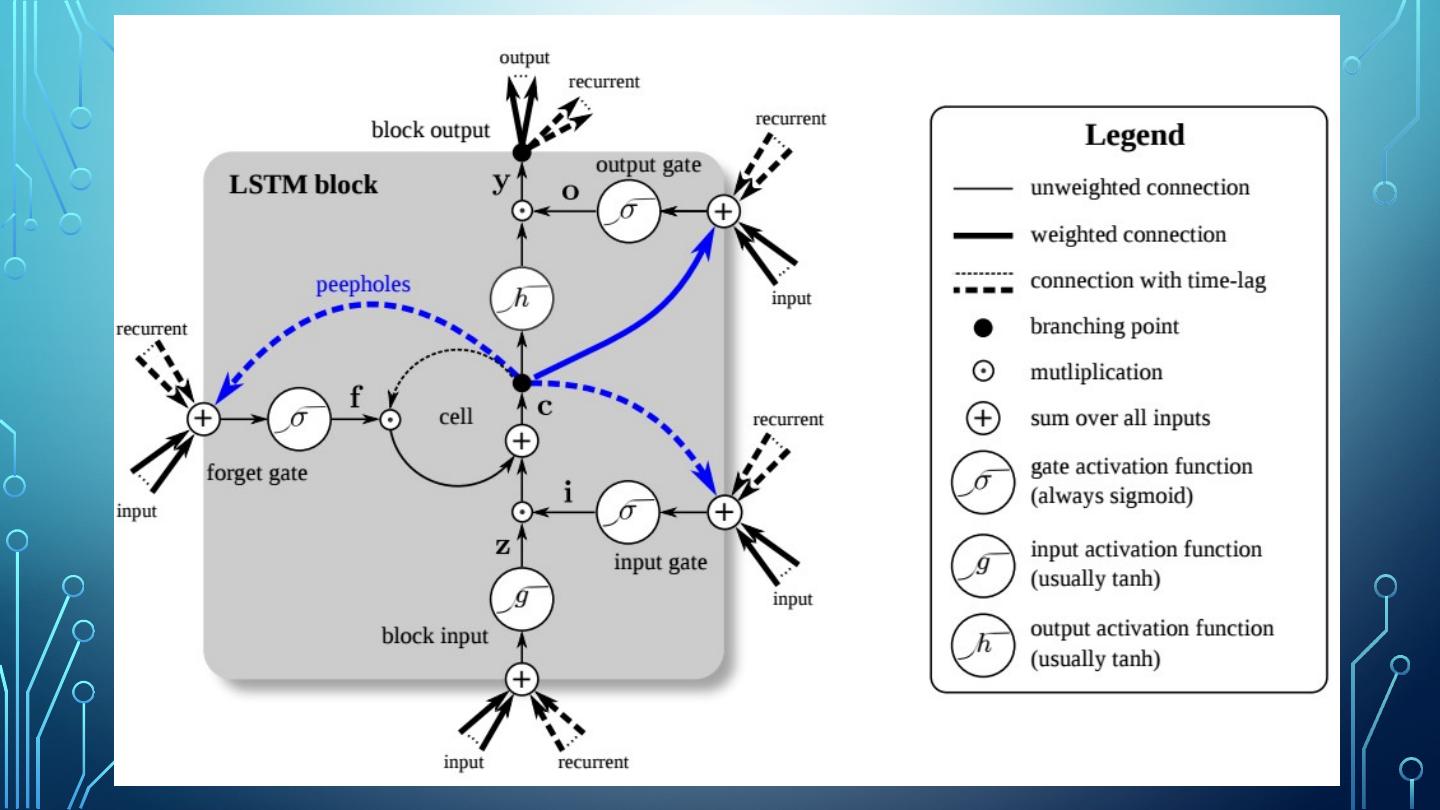
26 .Long Short-Term Memory (LSTM) In the late 90s, a major breakthrough solved the vanishing descent problem. Long Short-Term Memory (LSTM) gave a second wind to recurrent network development. LSTMs help preserve the error that can be backpropagated through time and layers. By maintaining a more constant error, they allow recurrent nets to continue to learn over many time steps, and open a channel to link causes and effects remotely.
27 .LSTM Advantages Perform much better than standard recurrent neural cell. Training will converge faster. Ability to detect long-term dependencies in data. In TensorFlow use BasicLSTMCell instead of BasicRNNCell
28 .Mind the gap Sometimes, there is only need to look at recent information to perform a task. Consider a language model trying to predict the next word based on the previous ones. Try to predict the last word in “The sky is ___” Unfortunately, as that gap grows, RNNs become unable to learn to connect the information. Consider trying to predict the last word in the text “I grew up in France… I speak fluent _____.”
29 .LSTM operation LSTM cell can learn to recognize an important input. Store the input in long-term memory. Implements a forget gate which allows input to be preserved only as long as necessary. Extracts memory state when necessary.