展开查看详情
1 .Potential of ML Based on recent interviews and publications from: Google AI Chief and former head of Google Brain Jeff Dean Gene Olafsen
2 .Overview Google AI Chief and former head of Google Brain Jeff Dean co-published the paper A New Golden Age in Computer Architecture: Empowering the Machine-Learning Revolution . https://ieeexplore.ieee.org/document/8259424/
3 .Model-Design guidelines Engineers are advised to look forward at least five years for hardware development. An appropriate design must remain relevant through at least a two-year design and three-year deployment window to maintain a competitive edge*. * assuming standard depreciation projections.
4 .ML growth trend has already surpassed Moore’s Law (1975)
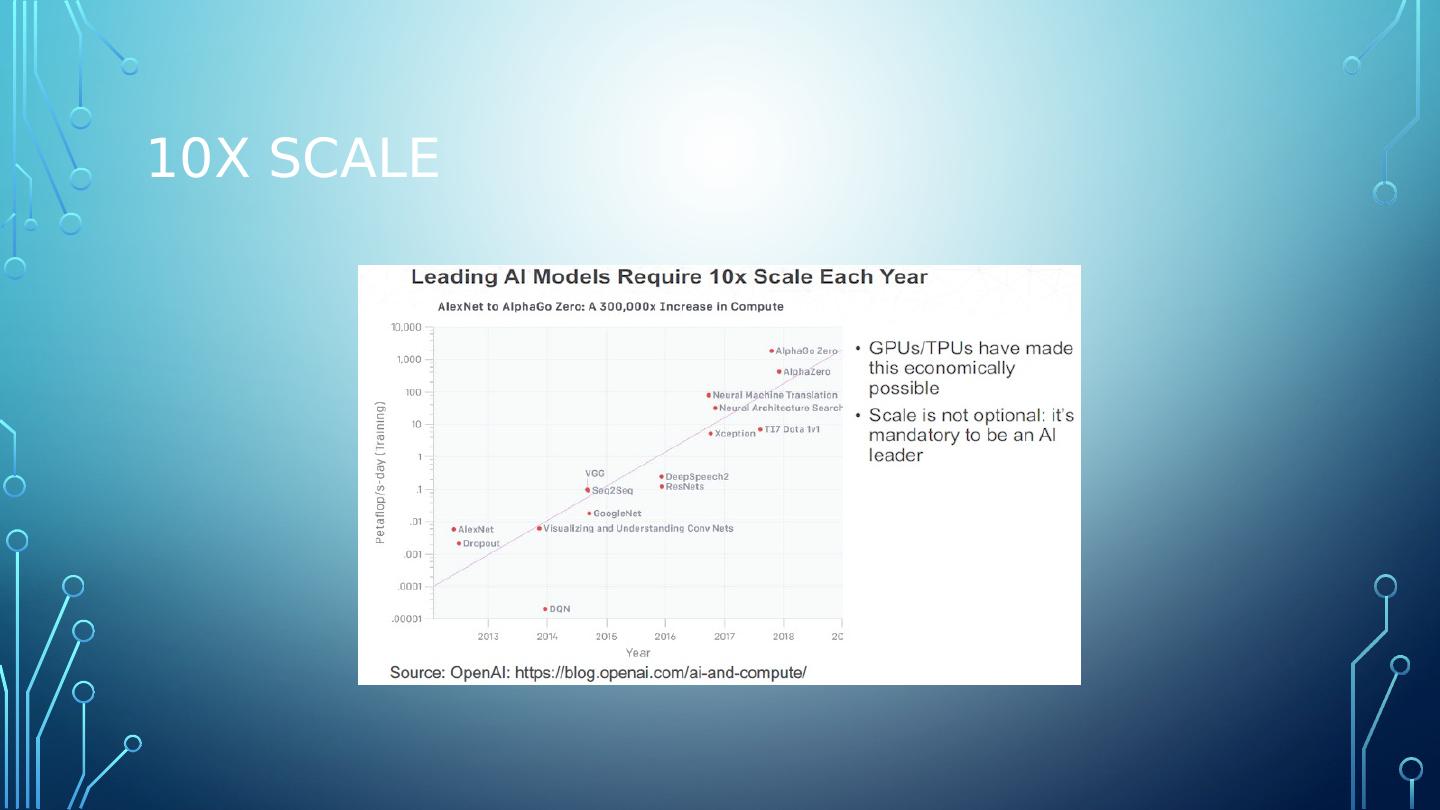
5 .Model Scaling According to Mathew Lodge, senior vice president of products and marketing at data science platform provider Anaconda. "AI models need to scale by factors of at least 10X each year."
7 .Following on the heels... Machine learning is following on the heels of ‘Big Data’, which typically means an enterprise has employed MapReduce with additional data manipulation done with Java. Machine learning engineers are working with R and Python.
8 .Go parallel... or go home Dask Provides advanced parallelism for analytics, enabling performance at scale Uses existing Python APIs and data structures to make it easy to switch between Numpy , Pandas, Scikit -learn to their Dask -powered equivalents Tensorflow Parallelization is built right in
9 .Package, and ship Once deployed and in product, the tasks of running and managing the model – such using containers and Kubernetes, scheduling, security, and upgrades – are automated.
10 .Issues impacting ML Hardware design in the next five years Training Batch Size Sparsity and Embeddings Quantization and Distillation Networks with Soft Memory Learning to Learn (L2L)
11 .Training vs inferencing Development Phase: Training Learning Production Phase: Inference Prediction
12 .Training overhead Requires 3X the arithmetic operations of inferencing Activation values calculated through feedforward must be saved for back-propagation and thus add to memory pressure Training cannot scale up like inference (many sequential steps)
13 .Batch size Batch size enables an important form of operand reuse. The setting of minibatch size can greatly affect the efficiency of gradient descent in ML training. However, the setting of minibatch size is still poorly understood.
14 .Empirical batch Empirical results are confusing: A recent sequence of articles has shown that image-oriented convolutional models can train effectively at minibatch sizes of 8,192 and 32,768. Note: multi-layer perceptron classifiers or for LSTM-based models are not as efficiently training on such large minibatch sizes.
15 .Large minibatch Such effective large batch size training is not compatible with parallel scaling strategies.
16 .Gradient Descent Options (review) Variants: Gradient Descent Stochastic Gradient Descent Batch Gradient Descent Minibatch Gradient Descent
17 .Gradient descent Computing the cost and gradient for the entire training set can be very slow Intractable on a single machine if the dataset is too big to fit in memory Doesn’t provide an easy way to incorporate new data in an ‘online’ set.
18 .SGD – Stochastic Gradient Descent On large datasets, SGD can converge faster because it updates weights after each training sample. Stochastic gradient descent does not readily lend itself to parallelization as the you need the feedback from one iteration to proceed with the next iteration. The path towards the global cost minimum is not "direct" as in GD, but may go "zig-zag" if we are visualizing the cost surface in a 2D space.
19 .Batch Gradient Descent Batch gradient descent is a variation of the gradient descent algorithm that calculates the error for each example in the training dataset, but only updates the model after all training examples have been evaluated. NOTE: Running through one cycle of the training dataset is called an epoch.
20 .Mini-Batch Gradient Descent Mini-batch gradient descent splits the training dataset into small batches that are used to calculate the model error and update the model coefficients. Since the model update frequency is higher than BGD it often provides more robust convergence, avoiding local minima. Error information must be accumulated across mini-batches The introduction of additional hyperparameters. Yann LeCun (Facebook Chief AI Scientist) does not favor large minibatch size. He recently tweeted, “Training with large minibatches is bad for your health. More importantly, it’s bad for your test error. Friends don’t let friends use minibatches larger than 32.”
21 .Sparsity and embeddings (sparcity first) Many AI researchers want to develop increasingly larger models, but want individual examples to activate a tiny part of the large model- thus large models, sparsely activated .
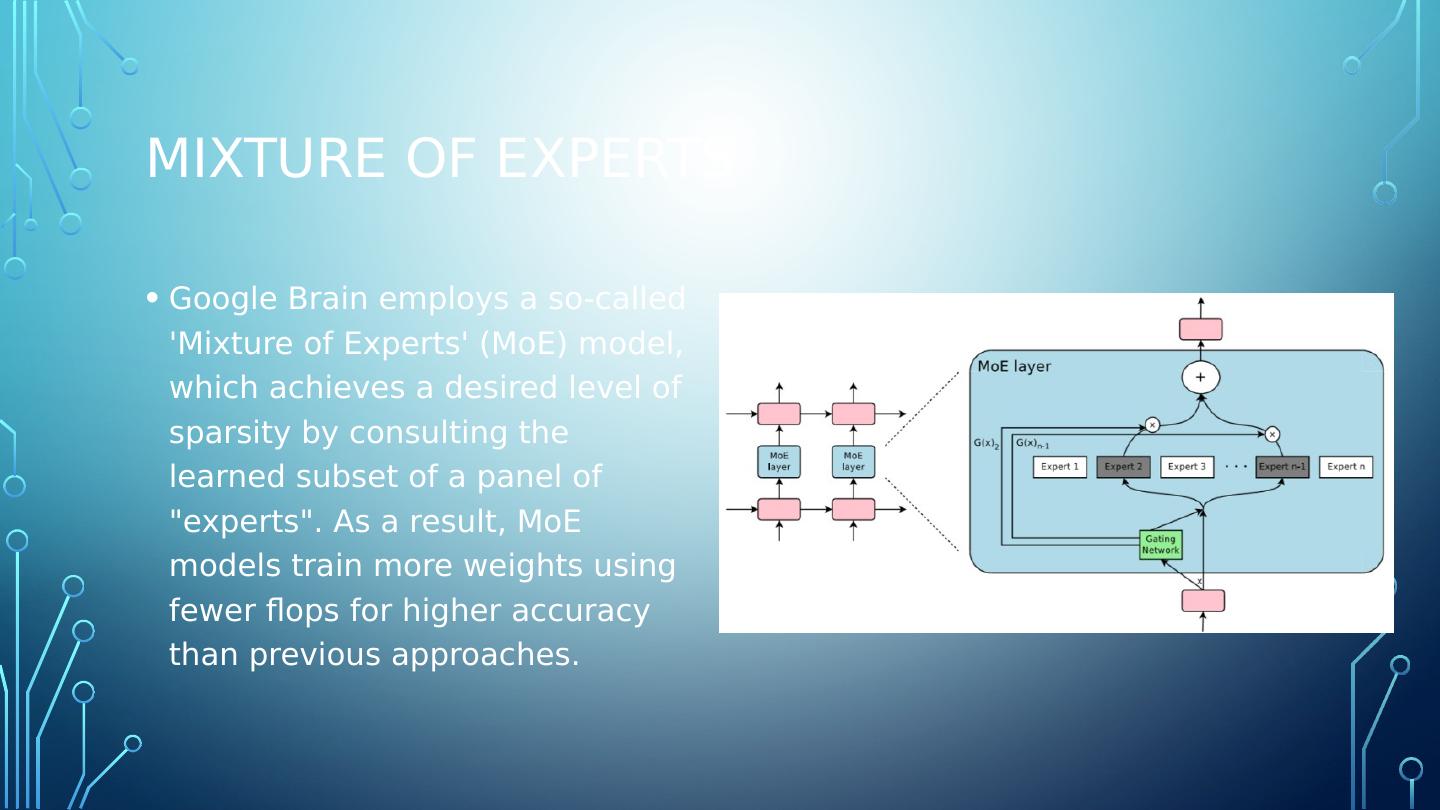
22 .Mixture of experts Google Brain employs a so-called Mixture of Experts (MoE) model, which achieves a desired level of sparsity by consulting the learned subset of a panel of "experts". As a result, MoE models train more weights using fewer flops for higher accuracy than previous approaches.
23 .embedding Embeddings are used to transform large sparse data into more compact, dense representations and are commonly used in web search and translation applications.
24 .Quantization and Distillation Quantization (reduced-precision computation) has already proved useful helping models run faster and use less power. Work is being done by NVidia and Baidu which involves mixed precision architectures. Distillation uses a larger model to bootstrap the training of a smaller model while achieving higher accuracy, instead of directly training the smaller model on the same inputs. (Hinton 2014)
25 .Soft memory networks Some deep-learning techniques provide functionality akin to random-access memory; doing so is complicated by preserving differentiability so the techniques can support back-propagation. Examples include Neural Turing Machines, memory networks, and attention. Attention allows Google Translate to map from a word in the target language to the corresponding word or phrase in the source language. Such soft mechanisms are expensive compared to traditional “hard” memories, because the soft memory computes a weighted average over all entries of a table. A hard memory simply loads a single entry from a table. We haven’t seen research into efficient or sparse implementations of these soft memory models.
26 .Soft memory networks Some deep-learning techniques provide functionality akin to random-access memory; doing so is complicated by preserving differentiability so the techniques can support back-propagation. Examples include Neural Turing Machines, memory networks, and attention. Attention allows Google Translate to map from a word in the target language to the corresponding word or phrase in the source language. Such soft mechanisms are expensive compared to traditional “hard” memories, because the soft memory computes a weighted average over all entries of a table. A hard memory simply loads a single entry from a table. We haven’t seen research into efficient or sparse implementations of these soft memory models.