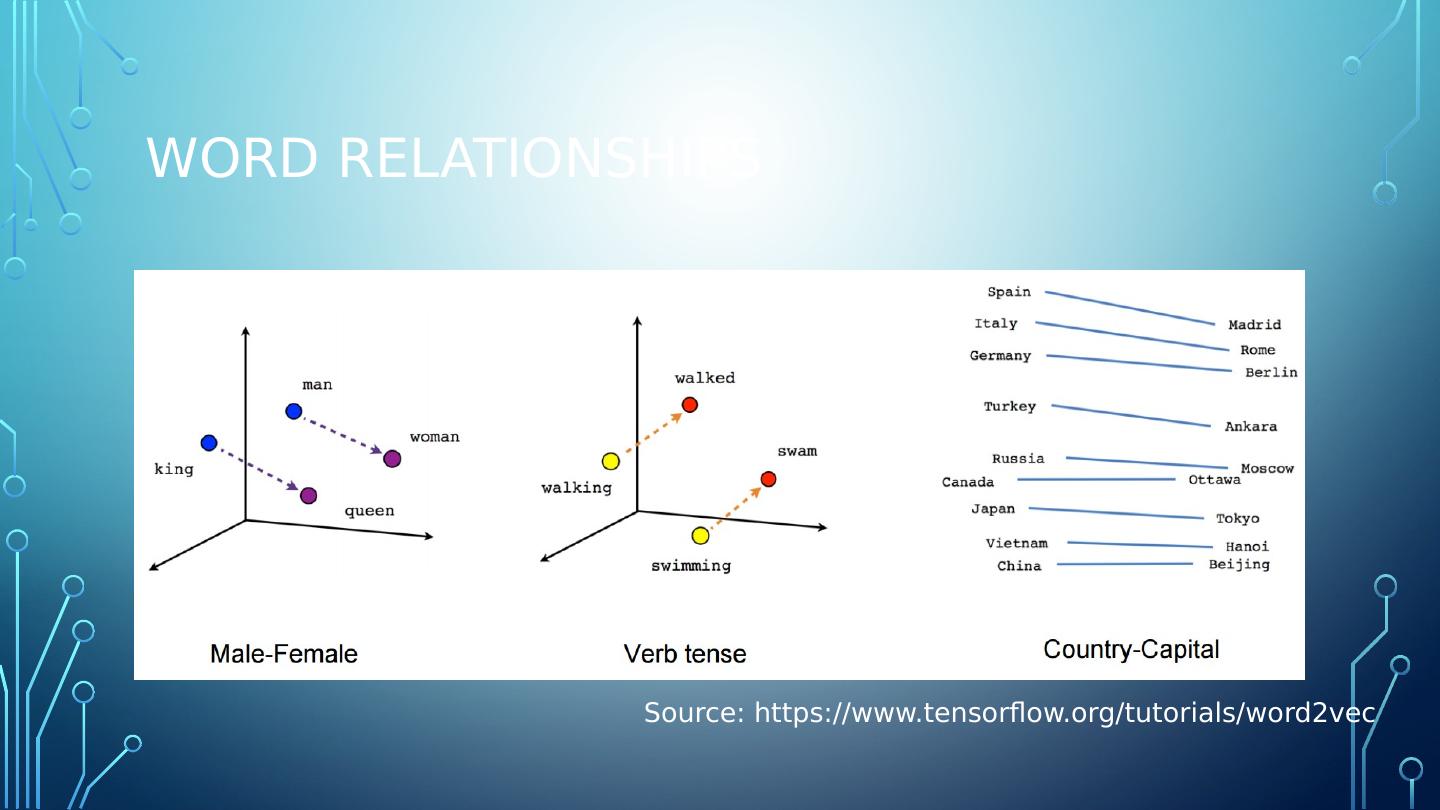
4 .Word encoding One-hot Vector 10,000 word vocabulary represented as an incredibly sparse 10,000 dimensional vector Embedding Operates in a small and dense vector The neural network training phase allows the model to learn the embedding position of words in a vector. Backpropagation moves the word embeddings around. "Similar" words typically cluster close to each other.
7 .Walk through the embedding process Create the variable representing the embeddings for every word in the vocabulary. Perform random initialization. Vocabulary_size = 50000 Embedding_size = 150 init_embedding = tf.random_uniform ([ vocabulary_size , embedding_size ], -1.0, 1.0) embeddings = tf.Variable ( init_embedding )
8 .Trained Embedding It is common to reuse your trained embeddings in other NLP applications. There are pretrained word embeddings that are available for download. Similar to transfer learning described in earlier slide decks, which froze specified layers, pretrained embedding layers can likewise be frozen. http://ahogrammer.com/2017/01/20/the-list-of-pretrained-word-embeddings/ https://github.com/Hironsan/awesome-embedding-models https://github.com/bheinzerling/bpemb