展开查看详情
1 .Inception Architecture Dimensionality and compute reduction Gene Olafsen
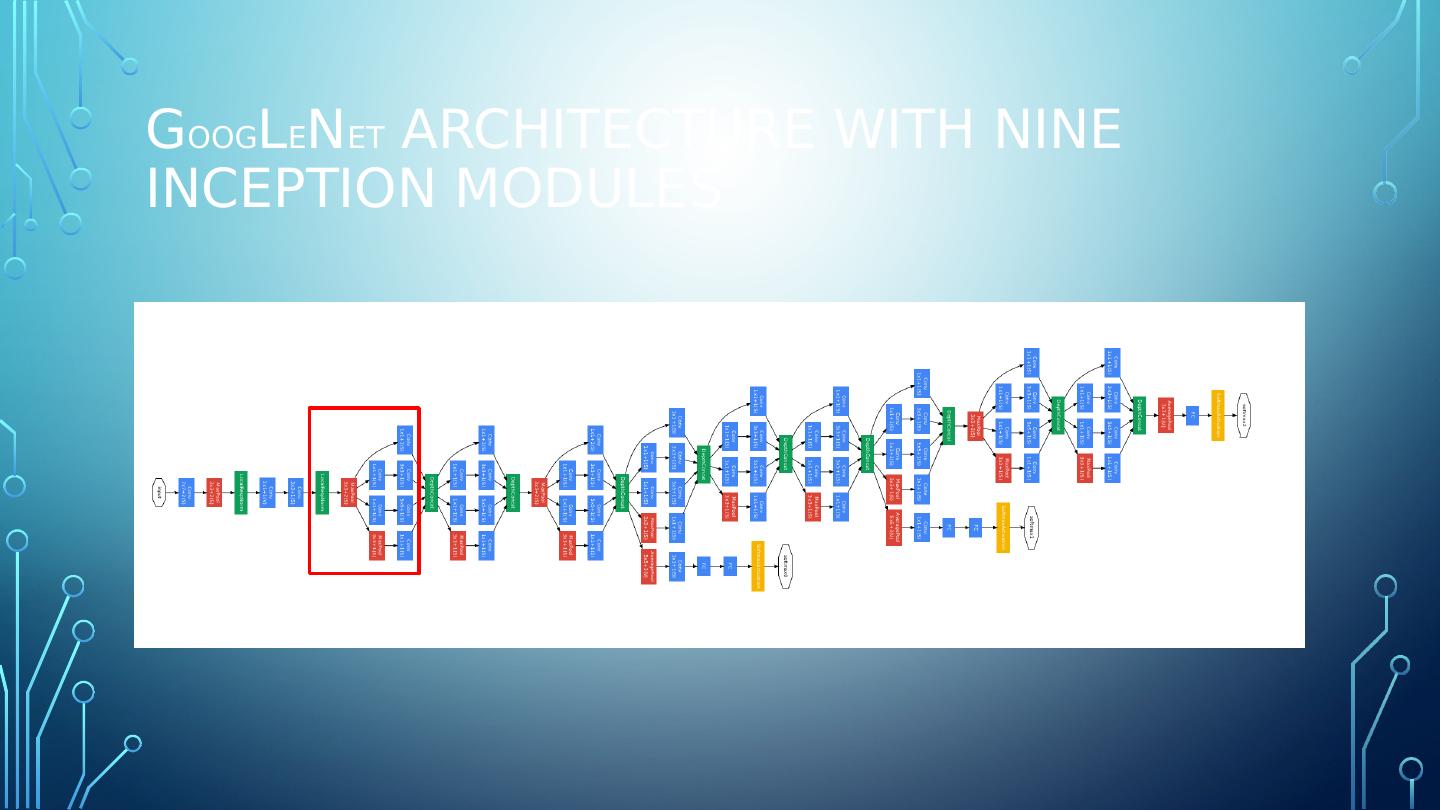
2 .G oog L e N et architecture with nine inception modules
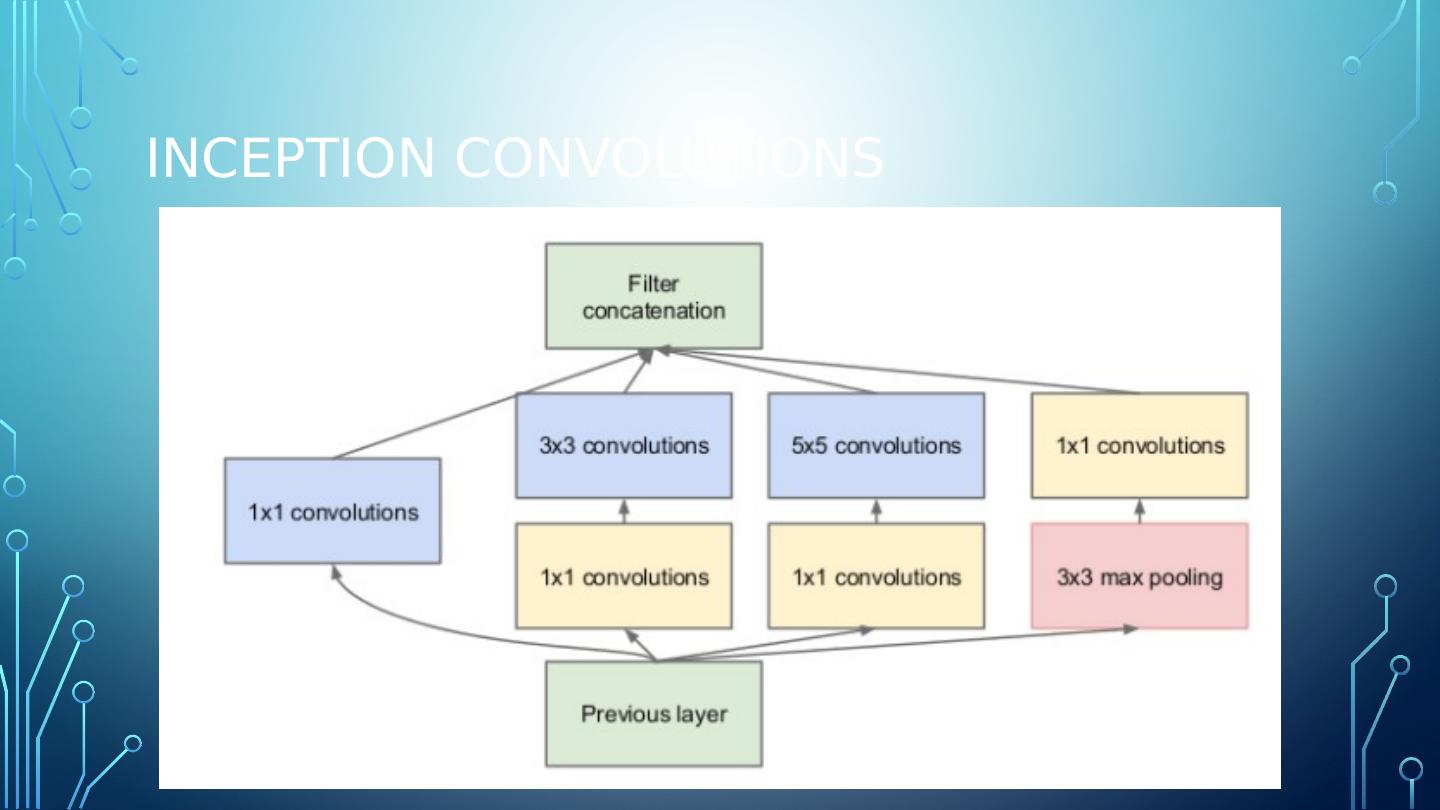
3 .Select a convolution... The inspiration for inception comes from the idea that you need to make a decision as to what type of convolution (3×3 or 5×5 or 1x1?) you want to perform at each layer. The answer pursued by Inception is to use all of them and let the model decide . Perform each convolution in parallel and concatenate the resulting feature maps before going to the next layer.
4 .Inception Convolutions
5 .Art not science What is max pooling is doing there with all the other convolutions? Pooling is added to the Inception module for no other reason than, historically, good networks having pooling.
6 .Inception Advantage This architecture allows the model to recover both local feature via smaller convolutions and high abstracted features with larger convolutions.
7 .1 x 1 convolution 1x1 convolution is a ‘feature pooling’ technique. The larger convolutions are more computationally expensive , so the paper suggests first doing a 1×1 convolution reducing the dimensionality of its feature map, passing the resulting feature map through a ReLU , and then doing the larger convolution (in this case, 5×5 or 3×3). The 1×1 convolution is used to reduce the dimensionality of its feature map. 1x1 convolutions are used to compute reductions before the expensive 3x3 and 5x5 convolutions.
8 .Rectified linear unit To add more non-linearity by having ReLU immediately after every 1x1 convolution. ReLu is nonlinear in nature, and combinations of ReLu remain nonlinear.
9 .Sample input to 1x1 Convolution layer A convolution layer whose output tensor is defined with the following shape: (N, F, H, W): N is the batch size F is the number of convolutional filters H, W are the spatial dimensions
10 .Sample input to 1x1 Convolution layer A convolution layer whose output tensor is defined with the following shape: (N, F, H, W): N is the batch size F is the number of convolutional filters H, W are the spatial dimensions
11 .Computation is reduced A reduction from 120+ million operations to about 12+ million operations. Computing resources is reduced by a factor of 10X.
12 .#Inception Module conv1_1x1_1 = conv2d_s1(x,W_conv1_1x1_1)+b_conv1_1x1_1 conv1_1x1_2 = tf.nn.relu (conv2d_s1(x,W_conv1_1x1_2)+b_conv1_1x1_2) conv1_1x1_3 = tf.nn.relu (conv2d_s1(x,W_conv1_1x1_3)+b_conv1_1x1_3) conv1_3x3 = conv2d_s1(conv1_1x1_2,W_conv1_3x3)+b_conv1_3x3 conv1_5x5 = conv2d_s1(conv1_1x1_3,W_conv1_5x5)+b_conv1_5x5 maxpool1 = max_pool_3x3_s1(x) conv1_1x1_4 = conv2d_s1(maxpool1,W_conv1_1x1_4)+b_conv1_1x1_4 #concatenate all the feature maps and apply relu inception1 = tf.nn.relu ( tf.concat (3,[conv1_1x1_1,conv1_3x3,conv1_5x5,conv1_1x1_4]))