展开查看详情
1 .Convolutional Neural Networks The advantages of partially connected layers
2 .The perception preprocessor "Perception largely takes place outside the realm of our consciousness, within specialized visual, auditory and other sensory modules in our brains. By the time sensory information reaches our consciousness, it is already adorned with high-level features." - Aurelien Geron
3 .Studying the Visual cortex Work by Hubel and Wiesel in the 1950s and 1960s showed that cat and monkey visual cortexes contain neurons that individually respond to small regions of the visual field. Neurons react to specific primitive visual characteristics – horizontal, vertical, diagonal line orientations. Some neurons react to larger receptive fields- suggesting that they process the outputs from primitive receptive field neurons.
4 .Local Receptive Field Neurons in the visual cortex only react to stimuli located in a specific region of the visual field. (local receptive fields of different neurons may overlap)
5 .neocognition A hierarchical, multilayered artificial neural network proposed by Kunihiko Fukushima in the 1980s.
6 .Convolution 1998- landmark paper Yann LeCun , Leon Bottou , Yoshua Bengio and Patrick Haffner – introduce the LeNet-5 architecture. Introduced Convolution layers and pooling layers. Widely used to identify handwritten numbers on checks.
7 .CNN Advantages Use relatively little pre-processing compared to other image classification algorithms. Not restricted to visual perception- processing tasks include: voice recognition and natural language processing. Have managed to achieve superhuman performance on some complex visual tasks.
8 .CNN Advantages Use relatively little pre-processing compared to other image classification algorithms. Not restricted to visual perception- processing tasks include: voice recognition and natural language processing. Have managed to achieve superhuman performance on some complex visual tasks.
9 .convolution Convolution – A convolution is an integral that expresses the amount of overlap of one function g as it is shifted over another function f. It therefore "blends" one function with another. Commonly used in signal processing.
11 .CNN processing is different CNNs do not process information in a single dimension as has been shown by all machine learning approaches to this point. CNNs operate on receptive fields- which are two dimensional.
12 .Two dimensional neural configuration
13 .Two dimensional neural configuration
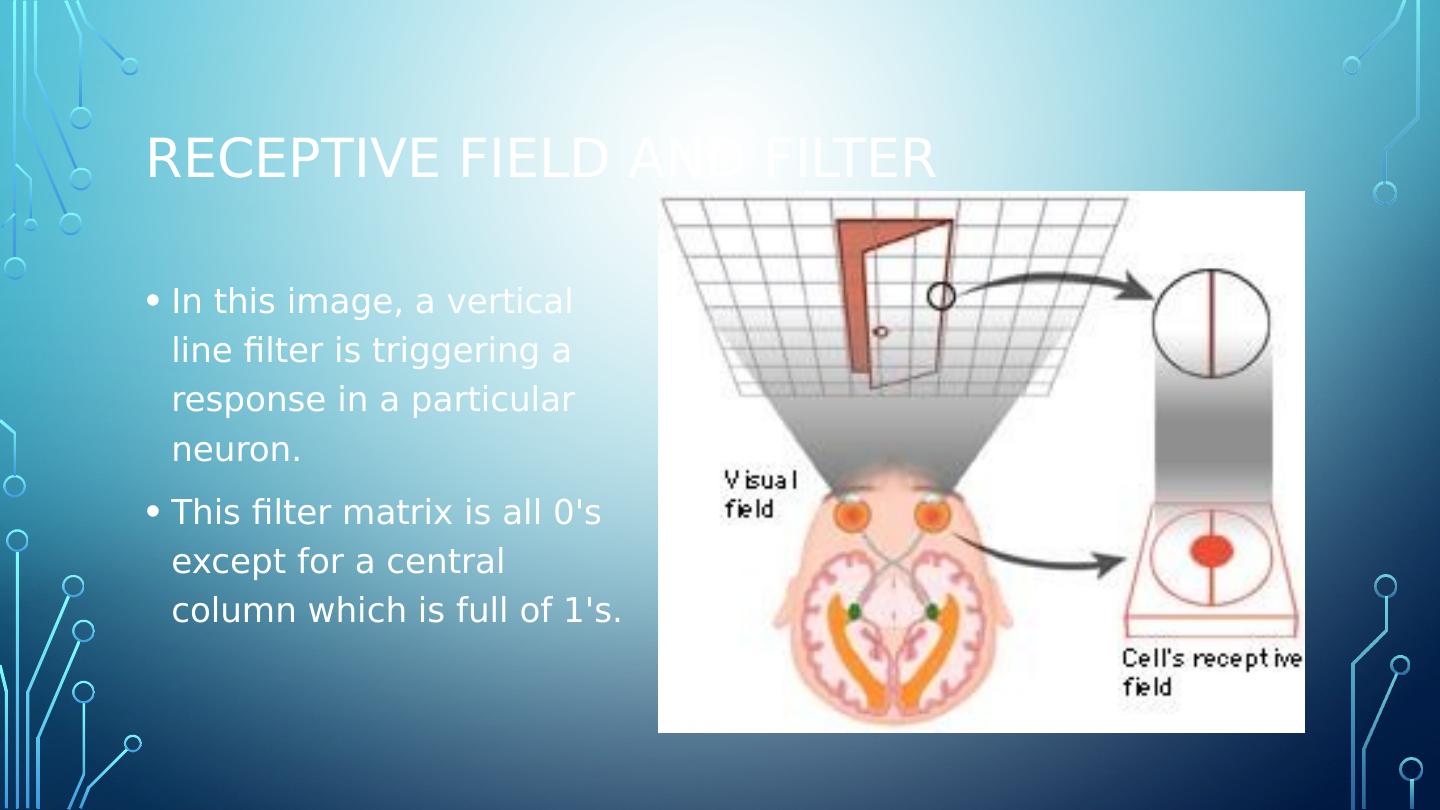
14 .Receptive field and filter In this image, a vertical line filter is triggering a response in a particular neuron. This filter matrix is all 0s except for a central column which is full of 1s.
15 .Feature map A feature map is a full layer of neurons using the same filter. Within a feature map, all neurons share the same weight and bias parameters.
16 .Stacking feature maps It is common to stack multiple feature maps into a single convolution layer. The image to the right shows feature maps that identify horizontal lines, vertical lines, diagonal lines, etc.
17 .Feature layers – Facial recognition
18 .Hidden CNN layers - transportation
19 .Zero padding Zero padding refers to the practice of adding zeroes to neural network input data to preserve a consistent aspect ratio.
20 .Zero padding Zero padding refers to the practice of adding zeroes to neural network input data to preserve a consistent aspect ratio.
21 .rgb For color images, a feature map is typically associated with a color channel. ( ie . RGB) Thus a given filter may be implemented multiple times- one for each color channel.
22 .stride Stride is how much a filter is shifted on an image with each step. The filter slides over the image, stopping at each stride length, and performs the necessary operations at that step.
23 .Stride in two dimensions
24 .padding In this example: Input width = 13 Filter width = 6 Stride = 5 Notes: "VALID" only drops the right-most columns (or bottom-most rows). "SAME" tries to pad evenly left and right, but if the number of columns to be added is odd, it will add the extra column to the right, as is the case in this example (the same logic applies vertically: there may be an extra row of zeros at the bottom).
25 .Cnn memory pressure Convolution layers require a huge amount of memory during training. The reverse pass of backpropagation requires all of the intermediate values computed during the forward pass. Reduce Memory: Reduce the mini-batch size Increase stride value Remove layers Distribute the training (using cloud resources)
26 .Pooling layer The purpose of pooling layers is to shrink or subsample an image in order to reduce the computational load and memory pressure. Mean or Max values are typically supplied to the pooling layer. Max Pooling
27 .Pooling Depth Pooling layers are typically created for every input channel. Thus for an RGB image, where each color component is processed on a separate layer- there is a corresponding pooling layer for each color component.